JuiceFS
背景
JuiceFS 是一款面向云原生设计的高性能分布式文件系统,在 Apache 2.0 开源协议下发布。提供完备的 POSIX 兼容性,可将几乎所有对象存储接入本地作为海量本地磁盘使用,亦可同时在跨平台、跨地区的不同主机上挂载读写。
JuiceFS
- 采用「数据」与「元数据」分离存储的架构,从而实现文件系统的分布式设计。
- 文件数据本身会被切分保存在对象存储(例如 Amazon S3),
- 而元数据则可以保存在 Redis、MySQL、TiKV、SQLite 等多种数据库中
JuiceFS 提供了丰富的 API,
- 适用于各种形式数据的管理、分析、归档、备份,
- 可以在不修改代码的前提下无缝对接大数据、机器学习、人工智能等应用平台,
- 为其提供海量、弹性、低价的高性能存储。
- 运维人员不用再为可用性、灾难恢复、监控、扩容等工作烦恼,专注于业务开发,提升研发效率。同时运维细节的简化,
- 对 DevOps 极其友好。
核心特性
- POSIX 兼容:像本地文件系统一样使用,无缝对接已有应用,无业务侵入性;
- HDFS 兼容:完整兼容 HDFS API,提供更强的元数据性能;
- S3 兼容:提供 S3 网关 实现 S3 协议兼容的访问接口;
- 云原生:通过 Kubernetes CSI 驱动 轻松地在 Kubernetes 中使用 JuiceFS;
- 分布式设计:同一文件系统可在上千台服务器同时挂载,高性能并发读写,共享数据;
- 强一致性:确认的文件修改会在所有服务器上立即可见,保证强一致性;
- 强悍性能:毫秒级延迟,近乎无限的吞吐量(取决于对象存储规模),查看性能测试结果;
- 数据安全:支持传输中加密(encryption in transit)和静态加密(encryption at rest),查看详情;
- 文件锁:支持 BSD 锁(flock)和 POSIX 锁(fcntl);
- 数据压缩:支持 LZ4 和 Zstandard 压缩算法,节省存储空间。
架构
架构
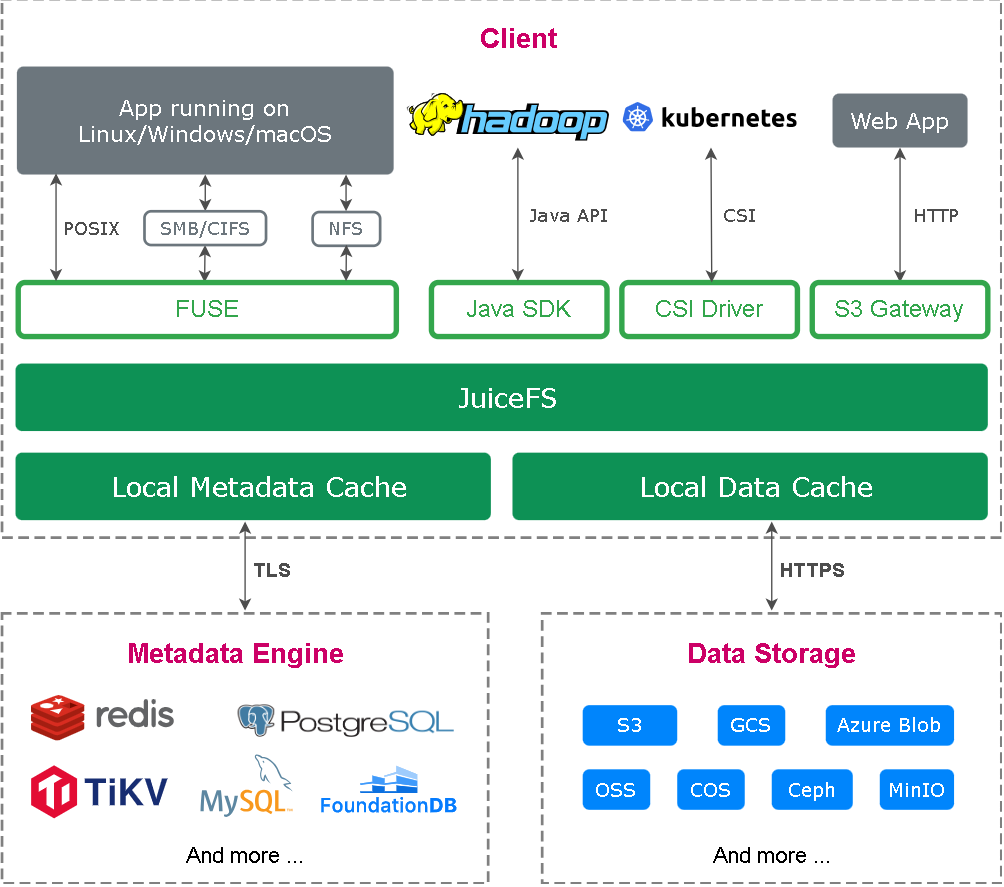
JuiceFS 客户端(Client):
- 所有文件读写,以及碎片合并、回收站文件过期删除等后台任务,均在客户端中发生。
- 客户端需要同时与对象存储和元数据引擎打交道。客户端支持多种接入方式:
- 通过 FUSE,JuiceFS 文件系统能够以 POSIX 兼容的方式挂载到服务器,将海量云端存储直接当做本地存储来使用。
- 通过 Hadoop Java SDK,JuiceFS 文件系统能够直接替代 HDFS,为 Hadoop 提供低成本的海量存储。
- 通过 Kubernetes CSI 驱动,JuiceFS 文件系统能够直接为 Kubernetes 提供海量存储。
- 通过 S3 网关,使用 S3 作为存储层的应用可直接接入,同时可使用 AWS CLI、s3cmd、MinIO client 等工具访问 JuiceFS 文件系统。
- 通过 WebDAV 服务,以 HTTP 协议,以类似 RESTful API 的方式接入 JuiceFS 并直接操作其中的文件。
数据存储(Data Storage):
- 文件将会被切分上传至对象存储服务。
- JuiceFS 支持几乎所有的公有云对象存储,
- 同时也支持 OpenStack Swift、Ceph、MinIO 等私有化的对象存储。
元数据引擎(Metadata Engine):
- 用于存储文件元数据(metadata),包含以下内容:
- 常规文件系统的元数据:文件名、文件大小、权限信息、创建修改时间、目录结构、文件属性、符号链接、文件锁等。
- 文件数据的索引:文件的数据分配和引用计数、客户端会话等。
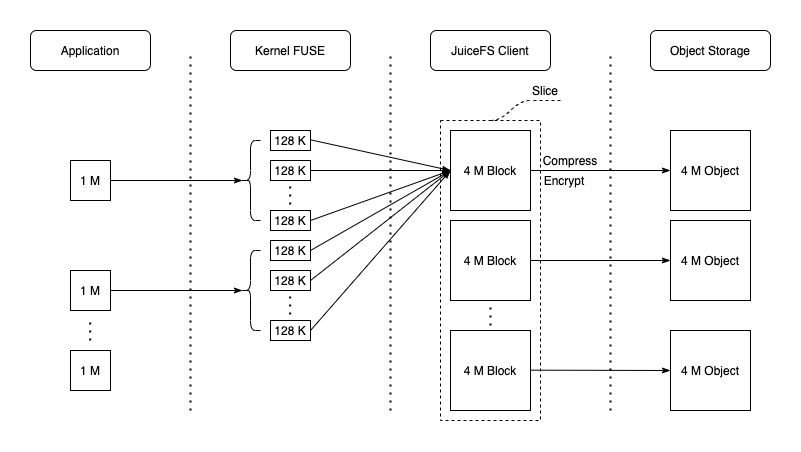
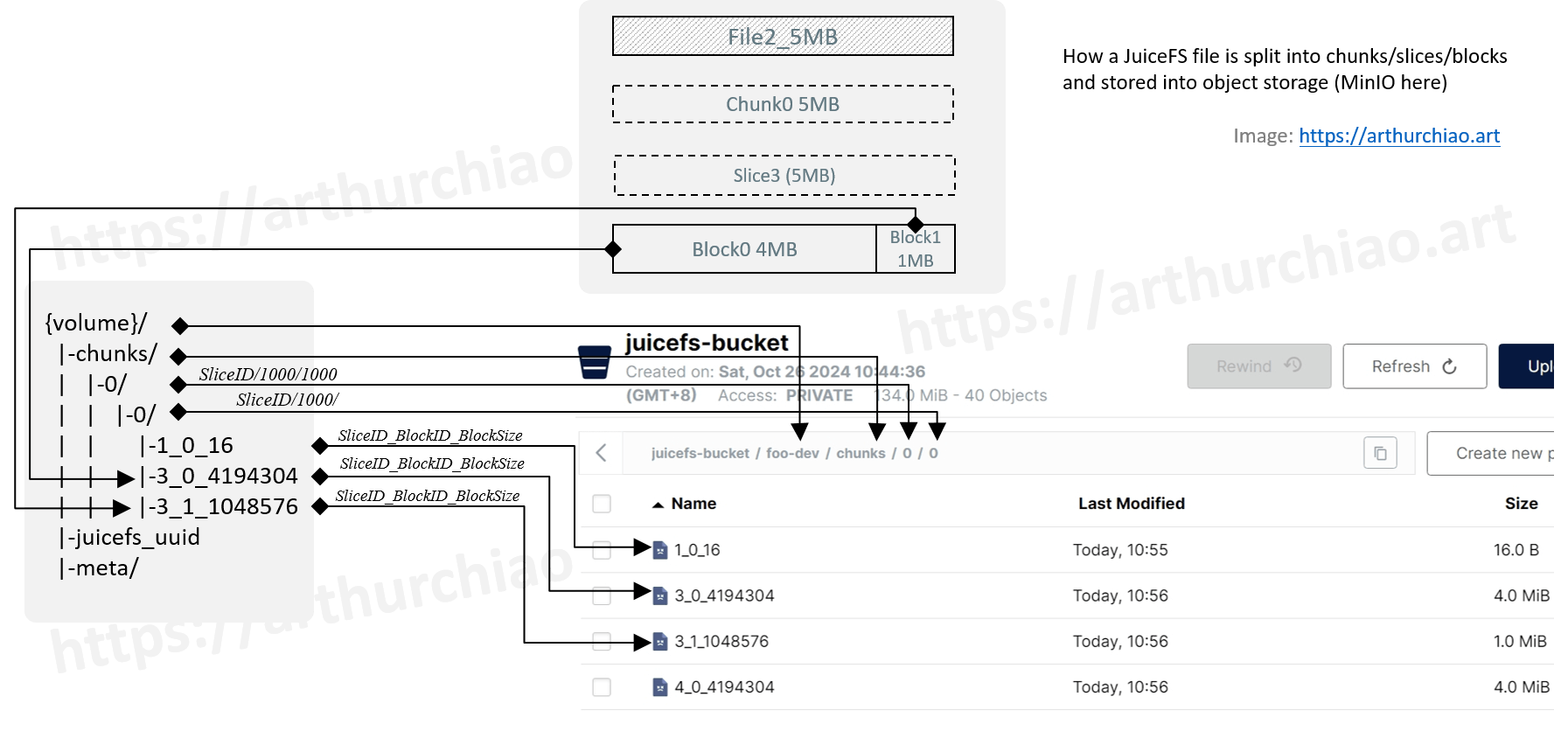
数据按照 chunk 划分的,一个 chunk 64M
而 chunk 内部包括多个 clice
一次写入对应一个 clice
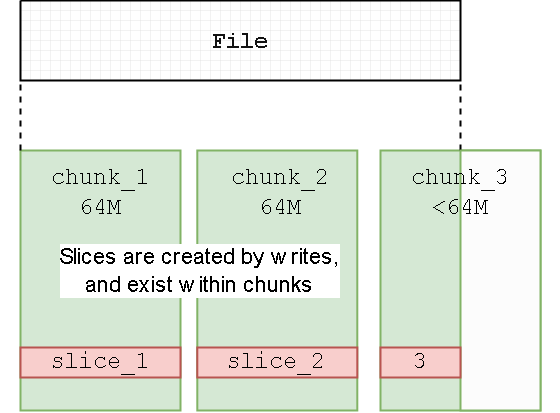
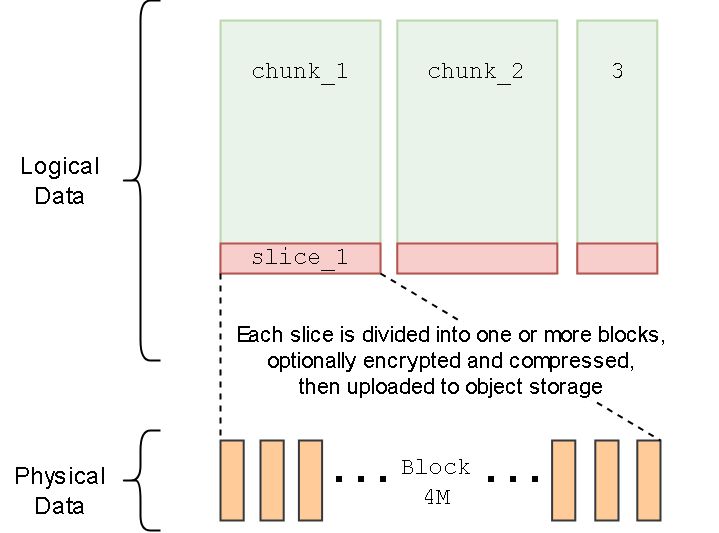
chunk -> slice 只是逻辑概念
真正存储的数据是按照 block 来存储的
如果一次性连续写入一批数据,chunk 只包含一个 slice
而 slice 则会按照 4M 划分成多个 block,并发写入
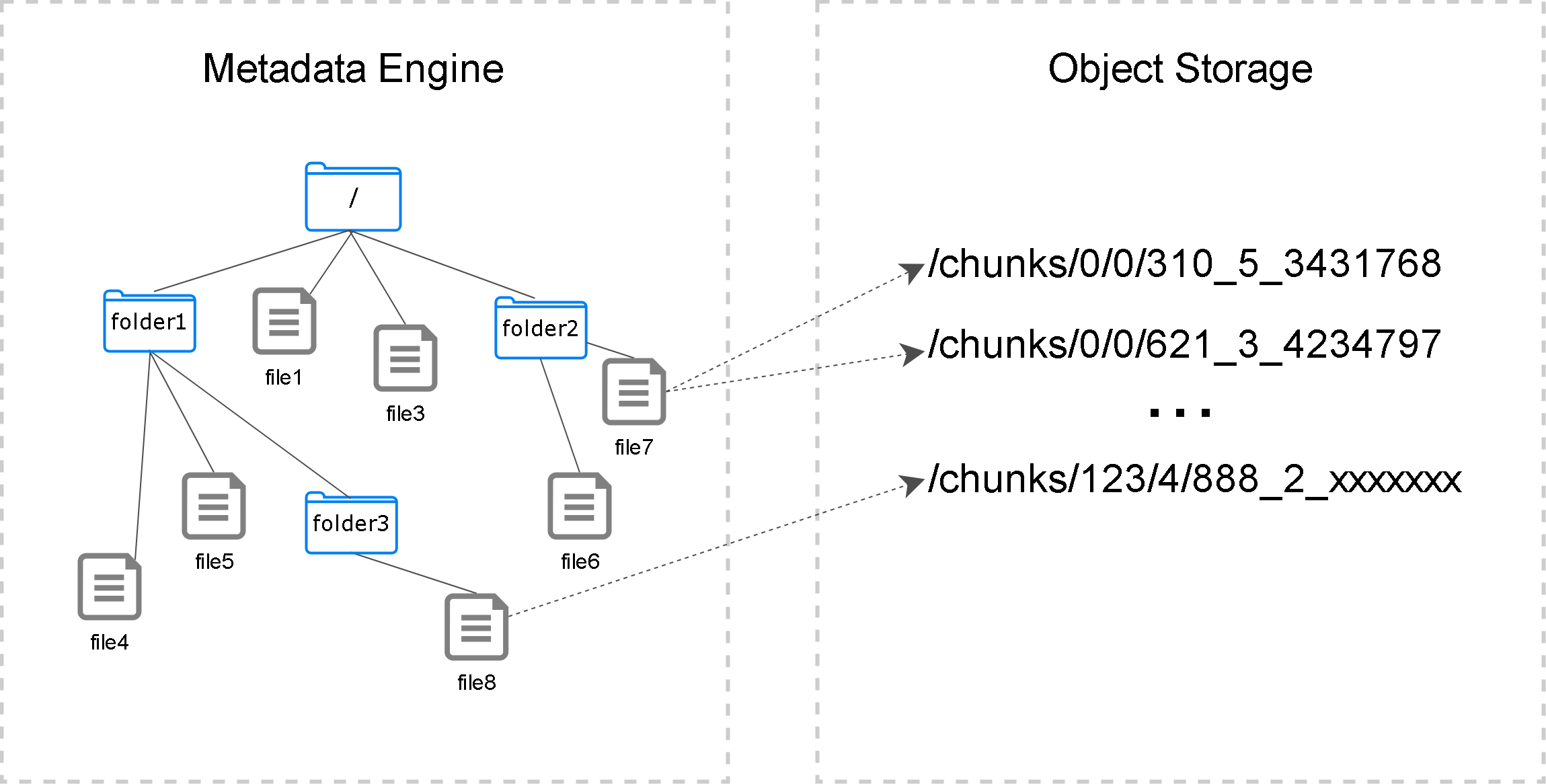
对象存储中的文件是扁平结构
层次结构是存储在元数据中的
通过元数据就能定位到真实数据
同时,元数据中还包含了文件大小,属性,权限等信息
对于多次写入,会按照 4M 大小写入对象存储
不到 4M 的数据则会独立生成一个文件
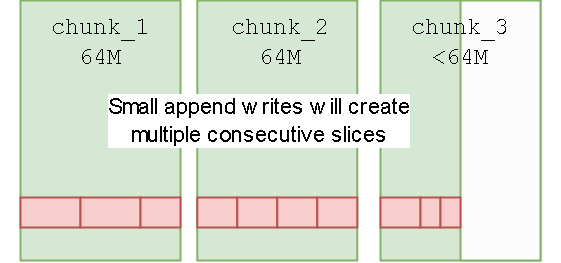
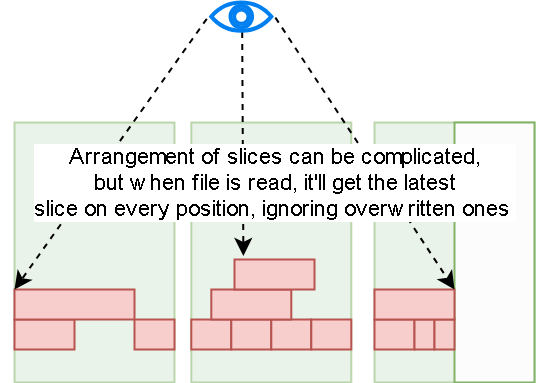
如果一个文件中的一段有反复写入,或者删除
自上而下看,就会出现覆盖
读取的时候会忽略掉下层,只读取最上面的数据
而读取的时候需要读多个文件再合并会有读放大
对象存储一般不支持部分删除,所以写入只是墓碑,实际是写入一个新文件,最后再合并
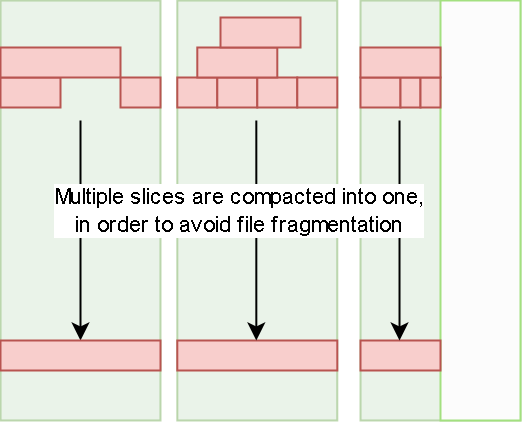
由于文件碎片会影响性能,所以后台会定期做文件合并
以下是文件的写入过程
安装
元数据使用:mysql
存储使用: minio
命令:
|
|
返回结果:
|
|
mysql 中的表如下:
挂载到本地磁盘
|
|
进入 /data1 目录,写几个文件
|
|
minio 中的根目录文件组件
数据文件组织结构
minio 中的目录结构
|
|
如果在 juicefs mount 时指定了 –backup-meta,JuiceFS 就会定期把元数据(存在在 TiKV 中)备份到这个目录中, 用途:
- 元数据引擎故障时,可以从这里恢复;
- 在不同元数据引擎之间迁移元数据。
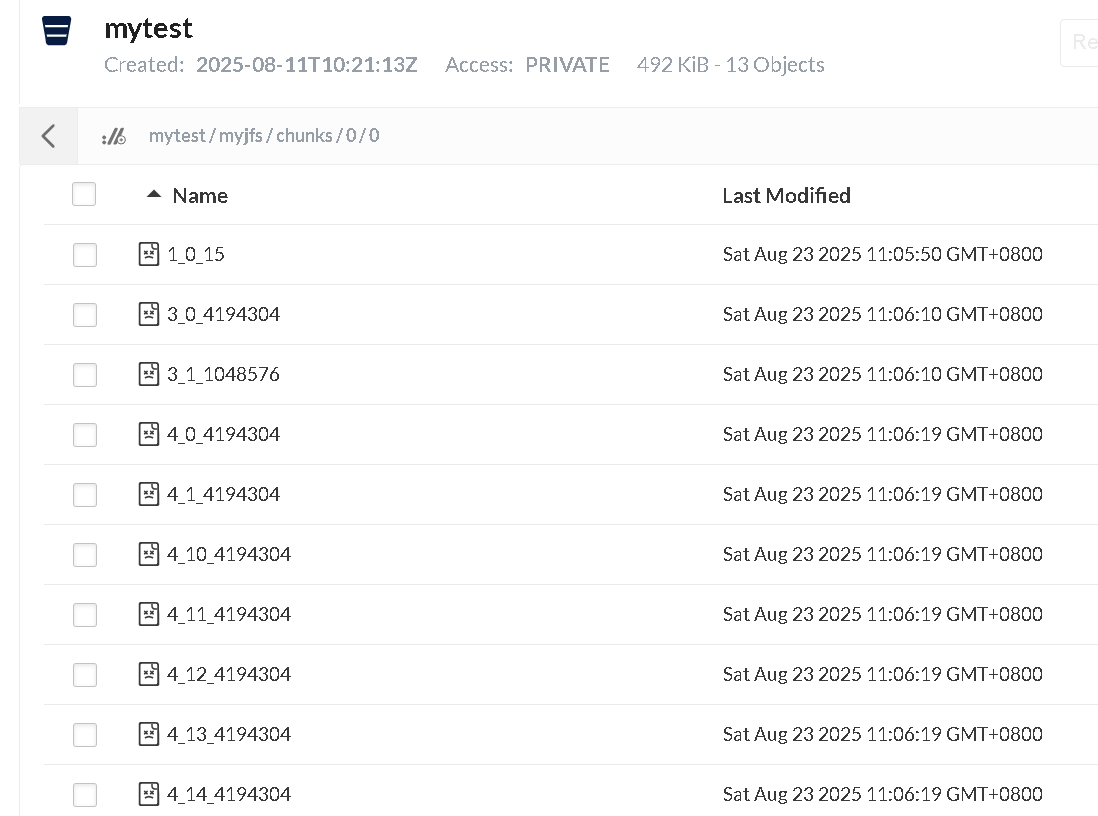
chunks/ 内的目录结构如下,
|
|
如上,所有的文件在 bucket 中都是用数字命名和存放的,分为三个层级:
- 第一层级:纯数字,是 sliceID 除以 100 万得到的;
- 第二层级:纯数字,是 sliceID 除以 1000 得到的;
- 第三层级:纯数字加下划线,{slice_id}{block_id}{size_of_this_block},表示的是这个 chunk 的这个 slice 内的 block_id 和 block 的大小。
元数据和 存储的映射结构
查看文件信息
- juicefs info -r file2_5MB,还有更相信的信息
|
|
stats 统计
|
|
summary
|
|
关键特性
cache
架构
graph TD
A[JuiceFS Client] --> B["Kernel Cache<br>(Metadata & Data)"];
A --> C["Client Memory Buffer<br>(Read/Write)"];
A --> D["Local Disk Cache<br>(Persistent Data)"];
B --> E["Microsecond Latency"];
C --> F["Low Latency"];
D --> G["Millisecond Latency<br>High Throughput"];
E --> H[Application];
F --> H;
G --> H;
I["Remote Object Storage<br>High Latency, High Durability"] --> D;
命令:
|
|
包括
- Kernel Cache (Metadata & Data)
- Client Memory Buffer (Read/Write Buffer)
- Local Disk Cache (Persistent Cache)
其他
包括
- Storage Quota
- Directory Statistics
- JuiceFS S3 Gateway
- Clone Files or Directories
- Data Synchronization
S3 geteway
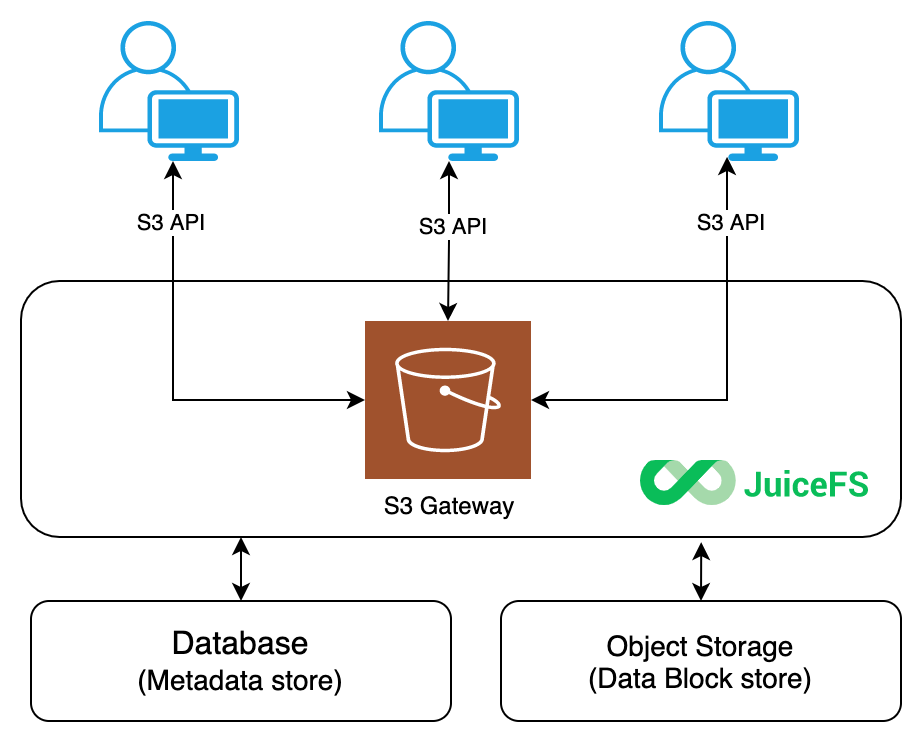
文件 clone,只是元数据clone,数据不变

数据同步
- 利用多机器同步
- 将 S3 数据拷贝到多台机器,再传到 OSS
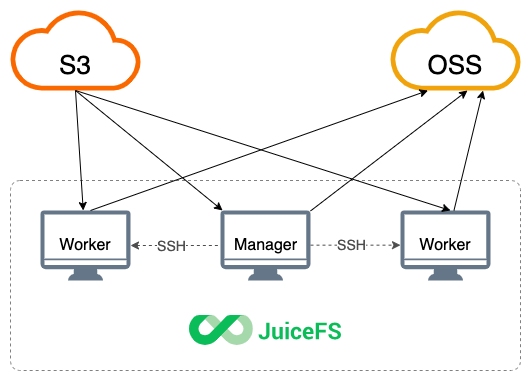
整合 bigdata
整合 spark,spark-defaults.conf
|
|
读取
|
|
Performance Tips:
- Enable client-side caching: –conf spark.executor.extraJavaOptions="-Djuicefs.cache-size=20480"
- Use SSD cache dir: /mnt/ssd/juicefs_cache
- Tune parallelism: spark.hadoop.jfs.max-connections=500
整合 flink,flink-conf.yaml
|
|
例子
|
|
Key Benefits:
- Exactly-once semantics with cloud-native durability
- 10x cheaper than HDFS for petabyte-scale state storage
- Cross-cluster recovery via shared storage
整合 doris
Query external data directly
|
|
Accelerate queries with caching
|
|
架构
graph TD
S3[(MinIO/S3 Storage)] -->|Object Layer| JuiceFS
MySQL[(MySQL/TiKV)] -->|Metadata| JuiceFS
JuiceFS -->|POSIX Interface| Spark
JuiceFS -->|Checkpoints| Flink
JuiceFS -->|External Tables| Doris
Spark -->|ETL Results| DataLake[JuiceFS Data Lake]
Flink -->|Real-time Data| DataLake
Doris -->|Query| DataLake
案例
文章
- ClickHouse 存算分离架构探索
- 理想汽车:从 Hadoop 到云原生的演进与思考
- 稳定且高性价比的大模型存储:携程 10PB 级 JuiceFS 工程实践
- JuiceFS 在 VIVO AI 计算平台的存储应用
- 存算分离实践:JuiceFS 在中国电信日均 PB 级数据场景的应用
- 突破存储数据量限制,JuiceFS 在携程海量冷数据场景下的实践
- 从 Hadoop 到云原生, 大数据平台如何做存算分离