CPU
BPF 跟踪工具可以提供更多细节信息,可回答以下这些问题:
- 创建了哪些新进程?运行时长是多长?
- 为什么 CPU 系统时间很高?是由于系统调用导致的吗?具体是哪些系统调用?
- 线程每次唤醒时在 CPU 上花费多长时间?
- 线程在运行队列中等待的时间有多长?
- 运行队列最长的时候有多少线程在等待执行?
- 不同 CPU 之间的运行队列是否均衡?
- 为什么某个线程会主动脱离 CPU?脱离时间有多长?
- 哪些软中断和硬中断占用了 CPU 时间?
- 当其他运行队列中有需要运行的程序时,哪些 CPU 仍然处于空闲状态?
- 应用程序处理每个请求时的 LLC 的命中率是多少?
测量 cpu 用量的各种事件源
| 事件类型 |
事件源 |
| 内核态函数 |
kprobes、kretprobes |
| 用户态函数 |
uprobes、uretprobes |
| 系统调用 |
系统调用跟踪点 |
| 软中断 |
irq:softirq* 跟踪点 |
| 硬中断 |
irq:irq_handler* 跟踪点 |
| 运行队列 |
workqueue 跟踪点(见第 14 章) |
| 定时采样 |
PMC 或是基于定时器的采样器 |
| CPU 电源控制事件 |
power 跟踪点 |
| CPU 周期 |
PMC 数据 |
传统工具
perf vs bpf
graph TD
perf[perf] -->|Collects| A[Hardware/Software Events]
perf -->|Records| B[Sampled Data]
perf -->|Analyzes| C[Performance Profiles]
BPF[BPF/eBPF] -->|Executes| D[Custom Programs]
BPF -->|Processes| E[In-Kernel Data]
BPF -->|Enforces| F[Security Policies]
perf:
- Event recorder: Samples pre-defined system events
- Passive analysis: Collects data for post-processing
- Fixed capabilities: Limited to predefined event types
BPF:
- Programmable runtime: Executes custom logic in kernel space
- Active processing: Filters/aggregates data in real-time
- Extensible: Creates new observability/security primitives
perf的事件处理
- 内核态采样每个事件
- 记录在buffer 中
- 定期用户态全量拷贝
graph LR
A[Event Trigger] --> B[Perf Ring Buffer]
B --> C[Kernel Space]
C --> D{Scheduled Copy}
D -->|Full Event Data| E[User Space]
E --> F[perf.data]
style D stroke:#f90
bpf 事件记录
- filter + agg 过滤事件
- 记录在映射表中
- 异步拷贝数据到用户态
graph LR
A[Event Trigger] --> B[BPF Program]
B -->|Filter/Aggregate| C[BPF Maps]
C -->|Async Pull| D[User Space]
D --> E[Processed Data]
style B stroke:#09f
style C stroke:#3f3
与 cpu 相关的工具
| 工具 |
源 |
分析对象 |
描述 |
| execsnoop |
BCC/BT |
调度 |
列出新进程的运行信息 |
| exitsnoop |
BCC |
调度 |
列出进程运行时长和退出的原因 |
| runqlat |
BCC/BT |
调度 |
统计 CPU 运行队列的延迟信息 |
| runqlen |
BCC/BT |
调度 |
统计 CPU 运行队列的长度 |
| runqslower |
BCC |
调度 |
当运行队列中等待时长超过阈值时打印 |
| cpudist |
BCC |
调度 |
统计在 CPU 上运行的时间 |
| cpufreq |
本书 |
CPU |
按进程来采样 CPU 运行频率信息 |
| profile |
BCC |
CPU |
采样 CPU 运行的调用栈信息 |
| offcputime |
BCC/本书 |
调度 |
统计线程脱离 CPU 时的跟踪信息和等待时长 |
| syscount |
BCC/BT |
系统调用 |
按类型和进程统计系统调用次数 |
| argdist |
BCC |
系统调用 |
可以用来进行系统调用分析 |
| trace |
BCC |
系统调用 |
可以用来进行系统调用分析 |
| funccount |
BCC |
软件 |
统计函数调用次数 |
| softirqs |
BCC |
中断 |
统计软中断时间 |
| hardirqs |
BCC |
中断 |
统计硬中断时间 |
| smpcalls |
本书 |
内核 |
统计 SMP 模式下的远程 CPU 调用信息 |
| llcstat |
BCC |
PMC |
按进程统计 LLC 命中率 |
runqlat 的 bpftrace 脚本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
#!/usr/bin/env bpftrace
#include <linux/sched.h>
BEGIN
{
printf("Tracing CPU scheduler... Hit Ctrl-C to end.\n");
}
tracepoint:sched:sched_wakeup,
tracepoint:sched:sched_wakeup_new
{
@qtime[args->pid] = nsecs;
}
tracepoint:sched:sched_switch
{
if (args->prev_state == TASK_RUNNING) {
@qtime[args->prev_pid] = nsecs;
}
$ns = @qtime[args->next_pid];
if ($ns) {
@usecs = hist((nsecs - $ns) / 1000);
}
delete(@qtime[args->next_pid]);
}
END
{
clear(@qtime);
}
root@node2:~#
root@node2:~# bpftrace -e '
#include <linux/sched.h>
tracepoint:sched:sched_wakeup,
tracepoint:sched:sched_wakeup_new
{
@qtime[args->pid] = nsecs;
}
tracepoint:sched:sched_switch
{
if (args->prev_state == TASK_RUNNING) {
@qtime[args->prev_pid] = nsecs;
}
$ns = @qtime[args->next_pid];
if ($ns) {
@usecs = hist((nsecs - $ns) / 1000);
}
delete(@qtime[args->next_pid]);
}
|
执行过程
sequenceDiagram
participant Wakeup
participant Runqueue
participant ContextSwitch
participant CPU
Note right of Wakeup: Task becomes runnable
Wakeup->>Runqueue: @qtime[pid] = nsecs (Timestamp recorded)
Note over ContextSwitch: CPU switches tasks
ContextSwitch->>Runqueue: For PREV task:
alt Still runnable?
ContextSwitch->>Runqueue: Update @qtime[prev_pid] = nsecs
end
ContextSwitch->>CPU: For NEXT task:
ContextSwitch->>Runqueue: Get $ns = @qtime[next_pid]
ContextSwitch->>CPU: Calculate latency: current_time - $ns
ContextSwitch->>Histogram: Record to @usecs
ContextSwitch->>Runqueue: Delete @qtime[next_pid]
一些 bpftrace 命令
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
|
# 跟踪新进程,包括进程参数:
bpftrace -e 'tracepoint:syscalls:sys_enter_execve { join(args->argv); }'
# 输出哪个进程执行了哪个新进程:
bpftrace -e 'tracepoint:syscalls:sys_enter_execve { printf("%s -> %s\n", comm, str(args->filename)); }'
# 按进程统计系统调用的数量:
bpftrace -e 'tracepoint:raw_syscalls:sys_enter { @[comm] = count(); }'
# 按系统调用的探针名字来统计系统调用的数量:
bpftrace -e 'tracepoint:syscalls:sys_enter_* { @[probe] = count(); }'
# 按系统调用的函数名来统计系统调用的数量:
bpftrace -e 'tracepoint:raw_syscalls:sys_enter {
@[sym(*(kaddr("sys_call_table") + args->id * 8))] = count(); }'
# 以 99Hz 的频率采样正在运行的进程名:
bpftrace -e 'profile:hz:99 { @[comm] = count(); }'
# 以 49Hz 的频率采样进程 ID 为 189 的用户态调用栈信息:
bpftrace -e 'profile:hz:49 /pid == 189/ { @[ustack] = count(); }'
# 采样所有的进程名和调用栈信息:
bpftrace -e 'profile:hz:49 { @[ustack, stack, comm] = count(); }'
# 按 99Hz 的频率采样正在运行的 CPU,并且以线性直方图输出:
bpftrace -e 'profile:hz:99 { @cpu = lhist(cpu, 0, 256, 1); }'
# 统计内核中以 "vfs_" 开头的函数调用频率:
bpftrace -e 'kprobe:vfs_* { @[func] = count(); }'
# 按名字和内核调用栈来统计 SMP 调用:
bpftrace -e 'kprobe:smp_call* { @[probe, kstack(5)] = count(); }'
# 按名字和内核调用栈来统计 Intel x2APIC 调用:
bpftrace -e 'kprobe:x2apic_send_IPI* { @[probe, kstack(5)] = count(); }'
# 跟踪通过 pthread_create () 创建的新线程:
bpftrace -e 'u:/lib/x86_64-linux-gnu/libpthread-2.27.so:pthread_create {
printf("%s by %s (%d)\n", probe, comm, pid); }'
|
内存
PF 跟踪工具可以给各种内存行为提供更多的信息,可以回答以下问题:
- 为什么进程的物理内存占用(RSS)不停增长?
- 哪些代码路径会导致缺页错误的发生?
- 缺页错误来自哪些文件?
- 哪些进程阻塞于页换入操作?
- 全系统范围内创建了哪些内存映射?
- 内存溢出(OOM Kill)事件发生时系统状态如何?
- 哪些应用程序代码路径正在申请内存分配?
- 应用程序分配了哪些类型的对象?
- 是否有分配一段时间后还是没有释放的内存?(这意味着可能是泄漏的内存。)
| 事件类型 |
事件源 |
| 用户态内存分配 |
使用 uprobes 跟踪内存分配器函数,使用 USDT probes 跟踪 libc |
| 内核态内存分配 |
使用 kprobes 跟踪内存分配器函数,以及 kmem 跟踪点 |
| 堆内存扩展 |
brk 系统调用跟踪点 |
| 共享内存函数 |
系统调用跟踪点 |
| 缺页错误 |
kprobes、软件事件,以及 exception 跟踪点 |
| 页迁移 |
migration 跟踪点 |
| 页压缩 |
compaction 跟踪点 |
| VM 扫描器 |
vmscan 跟踪点 |
| 内存访问周期 |
PMC |
查看 libc 支持的 usdt
1
|
bpftrace -l 'usdt:/lib/x86_64-linux-gnu/libc.so.6:libc:*'s
|
如果你刚刚开始学习内存性能分析,那么下面是一个推荐采用的分析策略:
- 检查系统信息中是否有 OOM Killer 杀掉进程的信息(例如,使用 dmesg (1))。
- 检查系统中是否配置了换页设备,以及使用的换页空间大小;并且检查这些换页设备是否有活跃的 I/O 操作(例如,使用 swap (1)、iostat (1)、vmstat (1))。
- 检查系统中空闲内存的数量,以及整个系统的缓存使用情况(例如,使用 free (1))。
- 按进程检查内存用量(例如,使用 top (1) 和 ps (1))。
- 检查系统中缺页错误的发生频率,并且检查缺页错误发生时的调用栈信息,这可以解释 RSS 增长的原因。
- 检查缺页错误和哪些文件有关。
- 通过跟踪 brk () 和 mmap () 调用来从另一个角度审查内存用量。
- 从本章中列出的 BPF 工具中寻找合适的工具并执行。
- 使用 PMC 测量硬件缓存命中率和内存访问(最好启用 PEBS),以便分析导致内存 I/O 发生的函数和指令信息(例如,使用 perf (1))。
传统工具
| 工具 |
类型 |
描述 |
| dmesg |
内核日志 |
OOM Killer 事件的详细信息 |
| swapon |
内核统计数据 |
换页设备的使用量 |
| free |
内核统计数据 |
全系统的内存用量 |
| ps |
内核统计数据 |
每进程的统计信息,包括内存用量 |
| pmap |
内核统计数据 |
按内存段列出进程内存用量 |
| vmstat |
内核统计数据 |
各种各样的统计信息,包括内存 |
| sar |
内核统计数据 |
可以显示换页错误和页扫描的频率 |
| perf |
软件事件、硬件统计、硬件采样 |
内存相关的 PMC 统计信息和事件采样信息 |
BPF 工具
| 工具 |
来源 |
目标 |
介绍 |
| oomkill |
BCC/BT |
OOM |
展示 OOM Killer 事件的详细信息 |
| memleak |
BCC |
调度 |
展示可能有内存泄漏的代码路径 |
| mmapsnoop |
本书 |
系统调用 |
跟踪全系统的 mmap(2) 调用 |
| brkstack |
本书 |
系统调用 |
展示 brk() 调用对应的用户态代码调用栈 |
| shmsnoop |
BCC |
系统调用 |
跟踪共享内存相关的调用信息 |
| faults |
本书 |
Faults |
按用户调用栈展示缺页错误 |
| ffaults |
本书 |
Faults |
按文件名展示缺页错误 |
| vmscan |
本书 |
VM |
测量 VM 扫描器的收缩和回收时间 |
| drsnoop |
BCC |
VM |
跟踪直接回收时间,并且显示延迟信息 |
| swapin |
本书 |
VM |
按进程展示页换入信息 |
| hfaults |
本书 |
Faults |
按进程展示巨页的缺页错误信息 |
ffaults 的 bpftrace代码
1
2
3
4
5
6
7
8
9
10
|
#!/usr/local/bin/bpftrace
#include <linux/mm.h>
kprobe:handle_mm_fault
{
$vma = (struct vm_area_struct *)arg0;
$file = $vma->vm_file->f_path.dentry->d_name.name;
@[str($file)] = count();
}
|
vmscan.bt
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
#!/usr/local/bin/bpftrace
tracepoint:vmscan:mm_shrink_slab_start { @start_ss[tid] = nsecs; }
tracepoint:vmscan:mm_shrink_slab_end /@start_ss[tid]/
{
$dur_ss = nsecs - @start_ss[tid];
@sum_ss = @sum_ss + $dur_ss;
@shrink_slab_ns = hist($dur_ss);
delete(@start_ss[tid]);
}
tracepoint:vmscan:mm_vmscan_direct_reclaim_begin { @start_dr[tid] = nsecs; }
tracepoint:vmscan:mm_vmscan_direct_reclaim_end /@start_dr[tid]/
{
$dur_dr = nsecs - @start_dr[tid];
@sum_dr = @sum_dr + $dur_dr;
@direct_reclaim_ns = hist($dur_dr);
delete(@start_dr[tid]);
}
tracepoint:vmscan:mm_vmscan_memcg_reclaim_begin { @start_mr[tid] = nsecs; }
tracepoint:vmscan:mm_vmscan_memcg_reclaim_end /@start_mr[tid]/
{
$dur_mr = nsecs - @start_mr[tid];
@sum_mr = @sum_mr + $dur_mr;
@memcg_reclaim_ns = hist($dur_mr);
delete(@start_mr[tid]);
}
tracepoint:vmscan:mm_vmscan_wakeup_kswapd { @count_wk++; }
tracepoint:vmscan:mm_vmscan_writepage { @count_wp++; }
BEGIN
{
printf("%-10s %10s %12s %12s %6s %9s\n", "TIME",
"S-SLABms", "D-RECLAIMms", "M-RECLAIMms", "KSWAPD", "WRITEPAGE");
}
interval:s:1
{
time("%H:%M:%S");
printf(" %10d %12d %12d %6d %9d\n",
@sum_ss / 1000000, @sum_dr / 1000000, @sum_mr / 1000000,
@count_wk, @count_wp);
clear(@sum_ss);
clear(@sum_dr);
clear(@sum_mr);
clear(@count_wk);
clear(@count_wp);
}
|
每秒输出的列包括如下几个。
- S-SLABms:收缩 slab 所花的全部时间,以毫秒为单位。这是从各种内核缓存中回收内存。
- D-RECLAIMms:直接回收所花的时间,以毫秒为单位。这是前台回收过程,在此期间内存被换入磁盘中,并且内存分配处于阻塞状态。
- M-RECLAIMms:内存 cgroup 回收所花的时间,以毫秒为单位。如果使用了内存 cgroups,此列显示当 cgroup 超出内存限制,导致该 cgroup 进行内存回收的时间。
- KSWAPD:kswapd 唤醒的次数。
- WRITEPAGE:kswapd 写入页的数量。
swapin 的 bpftrace 代码
1
2
3
4
5
6
7
8
9
10
11
12
13
|
#!/usr/local/bin/bpftrace
kprobe:swap_readpage
{
@[comm, pid] = count();
}
interval:s:1
{
time();
print(@);
clear(@);
}
|
hfaults.bt 的 bpftrace 代码
1
2
3
4
5
6
7
8
9
10
11
|
#!/usr/local/bin/bpftrace
BEGIN
{
printf("Tracing Huge Page faults per process... Hit Ctrl-C to end.\n");
}
kprobe:hugetlb_fault
{
@[pid, comm] = count();
}
|
BCC 单行程序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# 根据用户态调用栈信息统计进程堆内存扩展(brk ()):
stackcount -U t:syscalls:sys_enter_brk
# 根据用户态调用栈信息统计缺页错误:
stackcount -U t:exceptions:page_fault_user
# 通过跟踪点来统计 vmscan 操作:
funccount 't:vmscan:*'
# 按进程展示 hugepage_madvise () 调用:
trace hugepage_madvise
# 统计页迁移事件:
funccount t:migrate:mm_migrate_pages
# 统计页压缩事件:
trace t:compaction:mm_compaction_begin
|
bpftrace 单行程序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
# 根据用户态调用栈信息统计进程堆内存扩展(brk ()):bpftrace -e tracepoint:syscalls:sys_enter_brk { @[ustack, comm] = count(); }
# 按进程统计缺页错误:
bpftrace -e 'software:page-fault:1 { @[comm, pid] = count(); }'
# 根据用户态调用栈信息统计缺页错误:
bpftrace -e 'tracepoint:exceptions:page_fault_user { @[ustack, comm] = count(); }'
# 通过跟踪点来统计 vmscan 操作:
bpftrace -e 'tracepoint:vmscan:* { @[probe] = count(); }'
# 按进程展示 hugepage_madvise () 调用:
bpftrace -e 'kprobe:hugepage_madvise { printf("%s by PID %d\n", probe, pid); }'
# 统计页迁移事件:
bpftrace -e 'tracepoint:migrate:mm_migrate_pages { @ = count(); }'
# 统计页压缩事件:
bpftrace -e 't:compaction:mm_compaction_begin { time(); }'
|
文件系统
BPF 能够帮助回答以下问题:
- 发往文件系统的请求有哪些?可以按类型分别计数。
- 文件系统的读请求大小如何?
- 有多少写 I/O 是同步请求?
- 文件访问模式是随机请求还是顺序请求?
- 哪些文件正在被访问?按进程和代码路径统计?按字节数和 I/O 数量统计?
- 发生了哪些文件系统错误?哪些类型的文件错误,是哪个进程造成的?
- 文件系统的延迟来源是哪里?是磁盘,某段代码调用路径,还是锁?
- 文件系统延迟的分布情况如何?
- Dcache 和 Icache 的命中率和命空率的比例如何?
- 对读操作来说,页缓存的命中率如何?
- 预读取/ 预缓存的效果如何? 这些是否需要调整?
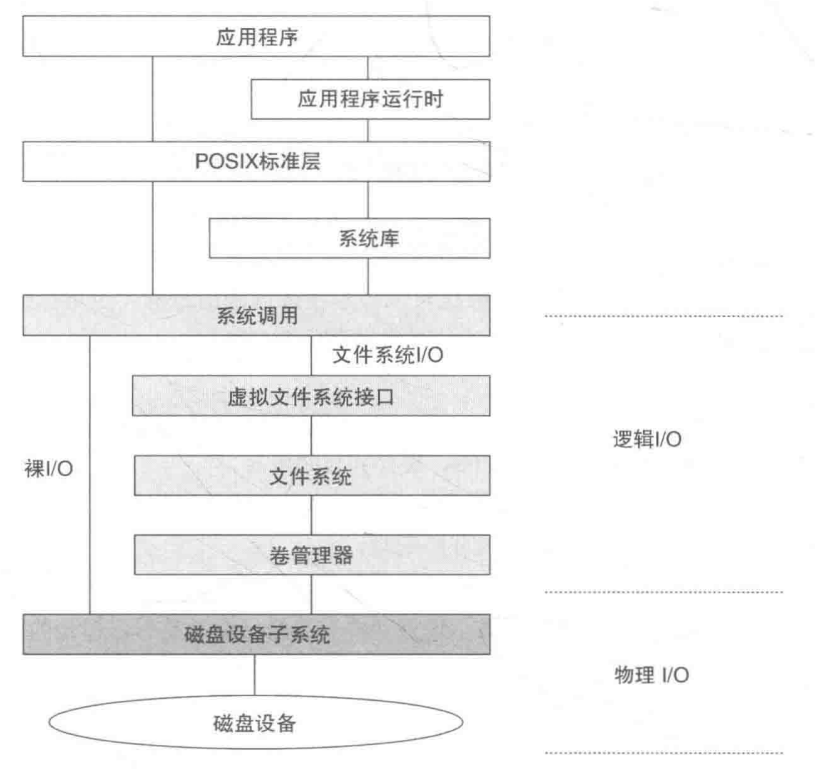
I/O 服务栈
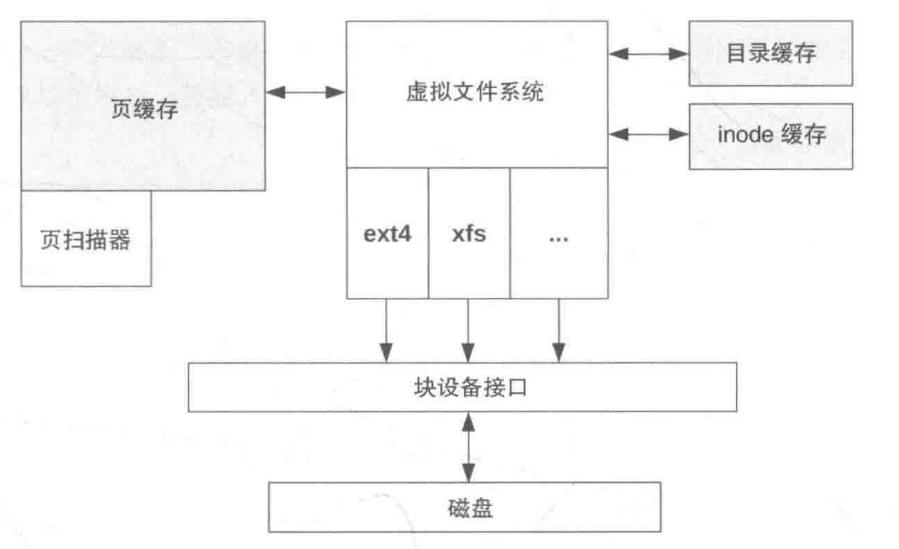
Linux 文件系统缓存
I/O 类型和事件源
| I/O 类型 |
事件源 |
| 应用程序和库函数 I/O |
uprobes |
| 系统调用 I/O |
系统调用跟踪点 |
| 文件系统 I/O |
ext4(…) 跟踪点、kprobes |
| 缓存命中(读)、写回(写) |
kprobes |
| 缓存命空(读)、写入(写) |
kprobes |
| 页缓存写回 |
writeback 跟踪点 |
| 物理磁盘 I/O |
block 跟踪点、kprobes |
| 裸 I/O |
kprobes |
传统工具,主要关注性能,几乎没有观察文件系统的
- df
- mount
- strace
- perf
- fatrace
- 基准测试工具: fio
BPF 工具
| 工具 |
来源 |
目标 |
介绍 |
| opensnoop |
BCC/BT |
系统调用 |
跟踪文件打开信息 |
| statsnoop |
BCC/BT |
系统调用 |
跟踪 stat(2) 调用的各种变体 |
| syncsnoop |
BCC/BT |
系统调用 |
跟踪 sync(2) 调用以及各种变体,带时间戳信息 |
| mmapfiles |
本书 |
系统调用 |
统计 mmap(2) 涉及的文件 |
| scread |
本书 |
系统调用 |
统计 read(2) 涉及的文件 |
| fmapfault |
本书 |
页缓存 |
统计文件映射相关的缺页错误 |
| filelife |
BCC/本书 |
VFS |
跟踪短时文件,按秒记录它们的生命周期 |
| vfsstat |
BCC/BT |
VFS |
统计常见的 VFS 操作 |
| vfscount |
BCC/BT |
VFS |
统计所有的 VFS 操作 |
| vfssize |
本书 |
VFS |
展示 VFS 读/写的尺寸 |
| fsrwstat |
本书 |
VFS |
按文件系统类型展示 VFS 读/写数量 |
| fileslower |
BCC/本书 |
VFS |
展示较慢的文件读/写操作 |
| filetop |
BCC |
VFS |
按 IOPS 和字节数排序展示文件 |
| filetype |
本书 |
VFS |
按文件类型和进程显示 VFS 读/写操作 |
| writesync |
本书 |
VFS |
按 sync 开关展示文件写操作 |
| cachestat |
BCC |
页缓存 |
页缓存相关统计 |
| writeback |
BT |
页缓存 |
展示写回事件和对应的延迟信息 |
| dcstat |
BCC/本书 |
Dcache |
目录缓存命中率统计信息 |
| dcsnoop |
BCC/BT |
Dcache |
跟踪目录缓存的查找操作 |
| mountsnoop |
BCC |
VFS |
跟踪系统中的挂载和卸载操作 (mount) |
| xfsslower |
BCC |
XFS |
统计过慢的 XFS 操作 |
| xfsdist |
BCC |
XFS |
以直方图统计常见的 XFS 操作延迟 |
| ext4dist |
BCC/本书 |
ext4 |
以直方图统计常见的 ext4 操作延迟 |
| icstat |
本书 |
Icache |
inode 缓存的命中率统计 |
| bufgrow |
本书 |
缓冲缓存 |
按进程和字节数统计缓冲缓存的增长 |
| readahead |
本书 |
VFS |
展示预读取的命中率和效率 |
mmapfiles 的 bpftrace 代码
1
2
3
4
5
6
7
8
9
10
11
12
13
|
#!/usr/local/bin/bpftrace
#include <linux/mm.h>
kprobe:do_mmap
{
$file = (struct file *)arg0;
$name = $file->f_path.dentry;
$dir1 = $name->d_parent;
$dir2 = $dir1->d_parent;
@[str($dir2->d_name.name), str($dir1->d_name.name),
str($name->d_name.name)] = count();
}
|
scread 的 bpftrace 代码
1
2
3
4
5
6
7
8
9
10
11
12
|
#!/usr/local/bin/bpftrace
#include <linux/sched.h>
#include <linux/fs.h>
#include <linux/fdtable.h>
tracepoint:syscalls:sys_enter_read
{
$task = (struct task_struct *)curtask;
$file = (struct file *)*($task->files->fdt->fd + args->fd);
@filename[str($file->f_path.dentry->d_name.name)] = count();
}
|
fmapfault 的bpftrace 代码
1
2
3
4
5
6
7
8
9
10
|
#!/usr/local/bin/bpftrace
#include <linux/mm.h>
kprobe:filemap_fault
{
$vf = (struct vm_fault *)arg0;
$file = $vf->vma->vm_file->f_path.dentry->d_name.name;
@[comm, str($file)] = count();
}
|
vfssize 的 bpftrace 代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
#!/usr/local/bin/bpftrace
#include <linux/fs.h>
kprobe:vfs_read,
kprobe:vfs_readv,
kprobe:vfs_write,
kprobe:vfs_writev
{
@file[tid] = arg0;
}
kretprobe:vfs_read,
kretprobe:vfs_readv,
kretprobe:vfs_write,
kretprobe:vfs_writev
/@file[tid]/
{
if (retval >= 0) {
$file = (struct file *)@file[tid];
$name = $file->f_path.dentry->d_name.name;
if ((($file->f_inode->i_mode >> 12) & 15) == DT_FIFO) {
@[comm, "FIFO"] = hist(retval);
} else {
@[comm, str($name)] = hist(retval);
}
}
delete(@file[tid]);
}
END
{
clear(@file);
}
|
fsrwstat 的 bpftrace 代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
#!/usr/local/bin/bpftrace
#include <linux/fs.h>
BEGIN
{
printf("Tracing VFS reads and writes... Hit Ctrl-C to end.\n");
}
kprobe:vfs_read,
kprobe:vfs_readv,
kprobe:vfs_write,
kprobe:vfs_writev
{
@[str(((struct file *)arg0)->f_inode->i_sb->s_type->name), func] = count();
}
interval:s:1
{
time(); print(@); clear(@);
}
END
{
clear(@);
}
|
filetype 的 bpftrace 代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
#!/usr/local/bin/bpftrace
#include <linux/fs.h>
BEGIN
{
// from uapi/linux/stat.h:
@type[0xc000] = "socket";
@type[0xa000] = "link";
@type[0x8000] = "regular";
@type[0x6000] = "block";
@type[0x4000] = "directory";
@type[0x2000] = "character";
@type[0x1000] = "fifo";
@type[0] = "other";
}
kprobe:vfs_read,
kprobe:vfs_readv,
kprobe:vfs_write,
kprobe:vfs_writev
{
$file = (struct file *)arg0;
$mode = $file->f_inode->i_mode;
@[@type[$mode & 0xf000], func, comm] = count();
}
END
{
clear(@type);
}
|
writesync 的 bpftrace 代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
#!/usr/local/bin/bpftrace
#include <linux/fs.h>
#include <asm-generic/fcntl.h>
BEGIN
{
printf("Tracing VFS write sync flags... Hit Ctrl-C to end.\n");
}
kprobe:vfs_write,
kprobe:vfs_writev
{
$file = (struct file *)arg0;
$name = $file->f_path.dentry->d_name.name;
if (((($file->f_inode->i_mode >> 12) & 15) == DT_REG)) {
if ($file->f_flags & O_DSYNC) {
@sync[comm, str($name)] = count();
} else {
@regular[comm, str($name)] = count();
}
}
}
|
writeback 的 bpftrace 代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
#!/usr/local/bin/bpftrace
BEGIN
{
printf("Tracing writeback... Hit Ctrl-C to end.\n");
printf("%-9s %-8s %-8s %-16s %s\n", "TIME", "DEVICE", "PAGES", "REASON", "ms");
// see /sys/kernel/debug/tracing/events/writeback/writeback_start/format
@reason[0] = "background";
@reason[1] = "vmscan";
@reason[2] = "sync";
@reason[3] = "periodic";
@reason[4] = "laptop_timer";
@reason[5] = "free_more_memory";
@reason[6] = "fs_free_space";
@reason[7] = "forker_thread";
}
tracepoint:writeback:writeback_start
{
@start[args->sb_dev] = nsecs;
@pages[args->sb_dev] = args->nr_pages;
}
tracepoint:writeback:writeback_written
/@start[args->sb_dev]/
{
$sb_dev = args->sb_dev;
$s = @start[$sb_dev];
$lat = $s ? (nsecs - $s) / 1000 : 0;
$pages = @pages[args->sb_dev] - args->nr_pages;
time("%H:%M:%S ");
printf("%-8s %-8d %-16s %d.%03d\n", args->name, $pages, @reason[args->reason], $lat / 1000, $lat % 1000);
delete(@start[$sb_dev]);
delete(@pages[$sb_dev]);
}
END
{
clear(@reason);
clear(@start);
}
|
dcstat 的 bpftrace 代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
#!/usr/local/bin/bpftrace
BEGIN
{
printf("Tracing dcache lookups... Hit Ctrl-C to end.\n");
printf("%10s %10s %5s\n", "REFS", "MISSES", "HIT%");
}
kprobe:lookup_fast { @hits++; }
kretprobe:d_lookup /retval == 0/ { @misses++; }
interval:s:1
{
$refs = @hits + @misses;
$percent = $refs > 0 ? 100 * @hits / $refs : 0;
printf("%10d %10d %4d%%\n", $refs, @misses, $percent);
clear(@hits);
clear(@misses);
}
END
{
clear(@hits);
clear(@misses);
}
|
bufgrow 的 bpftrace 代码
1
2
3
4
5
6
7
8
9
10
11
12
13
|
#!/usr/local/bin/bpftrace
#include <linux/fs.h>
kprobe:add_to_page_cache_lru
{
$as = (struct address_space *)arg1;
$mode = $as->host->i_mode;
// match block mode, uapi/linux/stat.h:
if ($mode & 0x6000) {
@kb[comm] = sum(4); // page size
}
}
|
readahead 的 bpftrace 代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
#!/usr/local/bin/bpftrace
kprobe:__do_page_cache_readahead { @in_readahead[tid] = 1; }
kretprobe:__do_page_cache_readahead { @in_readahead[tid] = 0; }
kretprobe:__page_cache_alloc
/@in_readahead[tid]/
{
@birth[retval] = nsecs;
@rapages++;
}
kprobe:mark_page_accessed
/@birth[arg0]/
{
@age_ms = hist((nsecs - @birth[arg0]) / 1000000);
delete(@birth[arg0]);
@rapages--;
}
END
{
printf("\nReadahead unused pages: %d\n", @rapages);
printf("\nReadahead used page age (ms):\n");
print(@age_ms); clear(@age_ms);
clear(@birth); clear(@in_readahead); clear(@rapages);
}
|
单行程序
例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
# 按进程名跟踪通过 creat (2) 创建的文件:
trace 't:syscalls:sys_enter_creat "%s", args->pathname'
# 按文件名统计 newstat (2) 调用:
argdist -C 't:syscalls:sys_enter_newstat():char*:args->filename'
# 按系统调用方式统计 read 系统调用:
funccount 't:syscalls:sys_enter_*read*'
# 按系统调用方式统计 write 系统调用:
funccount 't:syscalls:sys_enter_*write*'
#展示 read () 系统调用的请求大小分布:
argdist -H 't:syscalls:sys_enter_read():int:args->count'
# 展示 read () 系统调用的实际读取字节数(以及错误):
argdist -H 't:syscalls:sys_exit_read():int:args->ret'
# 按错误代码统计 read () 系统调用的错误:
argdist -C 't:syscalls:sys_exit_read():int:args->ret:args->ret<0'
# 统计 VFS 调用:
funccount 'vfs_*'
# 统计 ext4 跟踪点:
funccount 't:ext4:*'
# 统计 XFS 跟踪点:
funccount 't:xfs:*'
# 按进程名和调用栈信息统计 ext4 文件读取操作:
stackcount ext4_file_read_iter
# 跟踪 ZFS spa_sync () 时间:
trace -T 'spa_sync "ZFS spa_sync()"'
# 按进程名和调用栈信息统计使用 read_pages 向存储设备进行的文件系统读取操作:
stackcount -P read_pages
# 按调用栈和进程名统计所有通过 ext4 向存储设备进行的读取操作:
stackcount -P ext4_readpages
|
例子程序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
|
#按进程名统计通过 open (2) 打开的文件:
bpftrace -e '
t:syscalls:sys_enter_open {
printf("%s %s\n", comm, str(args->filename));
}'
#按进程名统计通过 creat (2) 创建的文件:
bpftrace -e '
t:syscalls:sys_enter_creat {
printf("%s %s\n", comm, str(args->pathname));
}'
# 按文件名统计 newstat (2) 调用:
bpftrace -e '
t:syscalls:sys_enter_newstat {
@[str(args->filename)] = count();
}'
# 按系统调用方式统计 read 系统调用:
bpftrace -e '
tracepoint:syscalls:sys_enter_*read* { @[probe] = count();
}'
# 按系统调用方式统计 write 系统调用:
bpftrace -e '
tracepoint:syscalls:sys_enter_*write* { @[probe] = count();
}'
# 展示 read () 系统调用的请求大小分布:
bpftrace -e '
tracepoint:syscalls:sys_enter_read { @ = hist(args->count);
}'
# 展示 read () 系统调用的实际读取字节数(以及错误):
bpftrace -e '
tracepoint:syscalls:sys_exit_read {
@ = hist(args->ret);
}'
# 统计 VFS 调用:
bpftrace -e '
kprobe:vfs_* {
@[probe] = count();
}'
# 统计 ext4 跟踪点:
bpftrace -e '
tracepoint:ext4:* { @[probe] = count();
}'
# 统计 XFS 跟踪点:
bpftrace -e '
tracepoint:xfs:* {
@[probe] = count();
}'
# 按进程名和调用栈信息统计 ext4 文件读取操作:
bpftrace -e '
kprobe:ext4_file_read_iter {
@[comm] = count();
}'
# 按进程名和用户态调用栈信息统计 ext4 文件读取操作:
bpftrace -e '
kprobe:ext4_file_read_iter {
@[ustack, comm] = count();
}'
|
磁盘
BPF 跟踪工具可以针对磁盘操作提供更多的信息,并能回答以下问题:
- 具体都有哪些磁盘 I/O 请求?分别是什么类型的,各有多少,以及 I/O 请求的尺寸是多少?
- 请求时长是多少?排队等待时长是多少?
- 是否存在延迟超标的情况
- 延迟分布是否呈多峰分布?
- 是否有任何磁盘错误?
- 具体发布了哪些 SCSI 命令?
- 是否有任何超时情况?
要回答这些问题,可以通过跟踪 I/O 在块 I/O 软件栈中的传递过程来完成。
传统工具
- iostat
- perf
- blktrace
- SCSI 日志
- dmesg
| 工具 |
来源 |
目标 |
介绍 |
| biolatency |
BCC/BT |
块I/O |
以直方图形式统计块I/O延迟 |
| biosnoop |
BCC/BT |
块I/O |
按PID和延迟阈值跟踪块I/O |
| biotop |
BCC |
块I/O |
top工具的磁盘版:按进程统计块I/O |
| bitesize |
BCC/BT |
块I/O |
按进程统计磁盘I/O请求尺寸直方图 |
| seeksize |
本书 |
块I/O |
展示I/O寻址(seek)的平均距离 |
| biopattern |
本书 |
块I/O |
识别随机/顺序式磁盘访问模式 |
| biostacks |
本书 |
块I/O |
展示磁盘I/O相关的初始化软件栈信息 |
| bioerr |
本书 |
块I/O |
跟踪磁盘错误 |
| mdflush |
BCC/BT |
MD |
跟踪MD的写空请求 |
| iosched |
本书 |
I/O sched |
统计I/O调度器的延迟 |
| scsilatency |
本书 |
SCSI |
展示SCSI命令延迟分布情况 |
| scsiresult |
本书 |
SCSI |
展示SCSI命令结果代码 |
| nvmelatency |
本书 |
NVME |
统计NVME驱动程序的命令延迟 |
bpftrace 例子
seeksize
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
#!/usr/local/bin/bpftrace
BEGIN
{
printf("Tracing block I/O requested seeks... Hit Ctrl-C to end.\n");
}
tracepoint:block:block_rq_issue
{
if (@last[args->dev]) {
// calculate requested seek distance
$last = @last[args->dev];
$dist = (args->sector - $last) > 0 ?
args->sector - $last : $last - args->sector;
// store details
@sectors[args->comm] = hist($dist);
}
// save last requested position of disk head
@last[args->dev] = args->sector + args->nr_sector;
}
END
{
clear(@last);
}
|
biopattern
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
#!/usr/local/bin/bpftrace
BEGIN
{
printf("%-8s %5s %5s %8s %10s\n", "TIME", "%RND", "%SEQ", "COUNT", "KBYTES");
}
tracepoint:block:block_rq_complete
{
if (@lastsector[args->dev] == args->sector) {
@sequential++;
} else {
@random++;
}
@bytes = @bytes + args->nr_sector * 512;
@lastsector[args->dev] = args->sector + args->nr_sector;
}
interval:s:1
{
$count = @random + @sequential;
$div = $count;
if ($div == 0) {
$div = 1;
}
time("%H:%M:%S ");
printf("%5d %5d %8d %10d\n", @random * 100 / $div,
@sequential * 100 / $div, $count, @bytes / 1024);
clear(@random); clear(@sequential); clear(@bytes);
}
END
{
clear(@lastsector);
clear(@random); clear(@sequential); clear(@bytes);
}
|
biostacks
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
#!/usr/local/bin/bpftrace
BEGIN
{
printf("Tracing block I/O with init stacks. Hit Ctrl-C to end.\n");
}
kprobe:blk_account_io_start
{
@reqstack[arg0] = kstack;
@reqts[arg0] = nsecs;
}
kprobe:blk_start_request,
kprobe:blk_mq_start_request
/@reqts[arg0]/
{
@usecs[@reqstack[arg0]] = hist(nsecs - @reqts[arg0]);
delete(@reqstack[arg0]);
delete(@reqts[arg0]);
}
END
{
clear(@reqstack); clear(@reqts);
}
|
bioerr
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
#!/usr/local/bin/bpftrace
BEGIN
{
printf("Tracing block I/O errors. Hit Ctrl-C to end.\n");
}
tracepoint:block:block_rq_complete
/args->error != 0/
{
time("%H:%M:%S ");
printf("device: %d,%d, sector: %d, bytes: %d, flags: %s, error: %d\n",
args->dev >> 20, args->dev & ((1 << 20) - 1), args->sector,
args->nr_sector * 512, args->rwbs, args->error);
}
|
iosched
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
#!/usr/local/bin/bpftrace
#include <linux/blkdev.h>
BEGIN
{
printf("Tracing block I/O schedulers. Hit Ctrl-C to end.\n");
}
kprobe:__elv_add_request
{
@start[arg1] = nsecs;
}
kprobe:blk_start_request,
kprobe:blk_mq_start_request
/@start[arg0]/
{
$r = (struct request *)arg0;
@usecs[$r->q->elevator->type->elevator_name] = hist((nsecs - @start[arg0]) / 1000);
delete(@start[arg0]);
}
END
{
clear(@start);
}
|
scsilatency
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
#!/usr/local/bin/bpftrace
#include <scsi/scsi_cmnd.h>
BEGIN
{
printf("Tracing scsi latency. Hit Ctrl-C to end.\n");
// SCSI opcodes from scsi/scsi_proto.h; add more mappings if desired:
@opcode[0x00] = "TEST_UNIT_READY";
@opcode[0x03] = "REQUEST_SENSE";
@opcode[0x08] = "READ_6";
@opcode[0x0a] = "WRITE_6";
@opcode[0x0b] = "SEEK_6";
@opcode[0x12] = "INQUIRY";
@opcode[0x18] = "ERASE";
@opcode[0x28] = "READ_10";
@opcode[0x2a] = "WRITE_10";
@opcode[0x2b] = "SEEK_10";
@opcode[0x35] = "SYNCHRONIZE_CACHE";
}
kprobe:scsi_init_io
{
@start[arg0] = nsecs;
}
kprobe:scsi_done,
kprobe:scsi_mq_done
/@start[arg0]/
{
$cmnd = (struct scsi_cmnd *)arg0;
$opcode = *$cmnd->req.cmd & 0xff;
@usecs[$opcode, @opcode[$opcode]] = hist((nsecs - @start[arg0]) / 1000);
}
END
{
clear(@start); clear(@opcode);
}
|
scsiresult
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
|
#!/usr/local/bin/bpftrace
BEGIN
{
printf("Tracing scsi command results. Hit Ctrl-C to end.\n");
// host byte codes, from include/scsi/scsi.h:
@host[0x00] = "DID_OK";
@host[0x01] = "DID_NO_CONNECT";
@host[0x02] = "DID_BUS_BUSY";
@host[0x03] = "DID_TIME_OUT";
@host[0x04] = "DID_BAD_TARGET";
@host[0x05] = "DID_ABORT";
@host[0x06] = "DID_PARITY";
@host[0x07] = "DID_ERROR";
@host[0x08] = "DID_RESET";
@host[0x09] = "DID_BAD_INTR";
@host[0x0a] = "DID_PASSTHROUGH";
@host[0x0b] = "DID_SOFT_ERROR";
@host[0x0c] = "DID_IMM_RETRY";
@host[0x0d] = "DID_REQUEUE";
@host[0x0e] = "DID_TRANSPORT_DISRUPTED";
@host[0x0f] = "DID_TRANSPORT_FAILFAST";
@host[0x10] = "DID_TARGET_FAILURE";
@host[0x11] = "DID_NEXUS_FAILURE";
@host[0x12] = "DID_ALLOC_FAILURE";
@host[0x13] = "DID_MEDIUM_ERROR";
// status byte codes, from include/scsi/scsi_proto.h:
@status[0x00] = "SAM_STAT_GOOD";
@status[0x02] = "SAM_STAT_CHECK_CONDITION";
@status[0x04] = "SAM_STAT_CONDITION_MET";
@status[0x08] = "SAM_STAT_BUSY";
@status[0x10] = "SAM_STAT_INTERMEDIATE";
@status[0x14] = "SAM_STAT_INTERMEDIATE_CONDITION_MET";
@status[0x18] = "SAM_STAT_RESERVATION_CONFLICT";
@status[0x22] = "SAM_STAT_COMMAND_TERMINATED";
@status[0x28] = "SAM_STAT_TASK_SET_FULL";
@status[0x30] = "SAM_STAT_ACA_ACTIVE";
@status[0x40] = "SAM_STAT_TASK_ABORTED";
}
tracepoint:scsi:scsi_dispatch_cmd_done
{
@[@host[(args->result >> 16) & 0xff], @status[args->result & 0xff]] = count();
}
END
{
clear(@status);
clear(@host);
}
|
nvmelatency
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
#!/usr/local/bin/bpftrace
#include <linux/blkdev.h>
#include <linux/nvme.h>
BEGIN
{
printf("Tracing nvme command latency. Hit Ctrl-C to end.\n");
// from linux/nvme.h:
@iopcode[0x00] = "nvme_cmd_flush";
@iopcode[0x01] = "nvme_cmd_write";
@iopcode[0x02] = "nvme_cmd_read";
@iopcode[0x04] = "nvme_cmd_write_uncor";
@iopcode[0x05] = "nvme_cmd_compare";
@iopcode[0x08] = "nvme_cmd_write_zeros";
@iopcode[0x09] = "nvme_cmd_dsm";
@iopcode[0x0d] = "nvme_cmd_resv_register";
@iopcode[0x0e] = "nvme_cmd_resv_report";
@iopcode[0x11] = "nvme_cmd_resv_acquire";
@iopcode[0x15] = "nvme_cmd_resv_release";
}
kprobe:nvme_setup_cmd
{
$req = (struct request *)arg1;
if ($req->rq_disk) {
@start[arg1] = nsecs;
@cmd[arg1] = arg2;
} else {
@admin_commands = count();
}
}
kprobe:nvme_complete_rq
/@start[arg0]/
{
$req = (struct request *)arg0;
$cmd = (struct nvme_command *)@cmd[arg0];
$disk = $req->rq_disk;
$opcode = $cmd->common.opcode & 0xff;
@usecs[$disk->disk_name, @iopcode[$opcode]] = hist((nsecs - @start[arg0]) / 1000);
delete(@start[tid]); delete(@cmd[tid]);
}
END
{
clear(@iopcode); clear(@start); clear(@cmd);
}
|
bpftrace 程序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
# 统计块 I/O 跟踪点:
bpftrace -e 'tracepoint:block:* { @[probe] = count(); }'
# 以直方图方式统计块 I/O 尺寸:
bpftrace -e 't:block:block_rq_issue { @bytes = hist(args->bytes); }'
# 统计块 I/O 请求的用户态调用栈:
bpftrace -e 't:block:block_rq_issue { @[ustack] = count(); }'
# 统计块 I/O 的类型标记:
bpftrace -e 't:block:block_rq_issue { @[args->rwbs] = count(); }'
# 按 I/O 类型统计总字节数:
bpftrace -e 't:block:block_rq_issue { @[args->rwbs] = sum(args->bytes); }'
# 按设备和 I/O 类型跟踪块 I/O 错误:
bpftrace -e 't:block:block_rq_complete /args->error/ { printf("dev %d type %s error %d\n", args->dev, args->rwbs, args->error); }'
# 以直方图方式统计块 I/O plug 时间:
bpftrace -e 'k:blk_start_plug { @ts[arg0] = nsecs; } k:blk_flush_plug_list /@ts[arg0]/ { @plug_ns = hist(nsecs - @ts[arg0]); delete(@ts[arg0]); }'
# 统计 SCSI opcode:
bpftrace -e 't:scsi:scsi_dispatch_cmd_start { @opcode[args->opcode] = count(); }'
# 统计 SCSI 结果代码(包括全部 4 字节):
bpftrace -e 't:scsi:scsi_dispatch_cmd_done { @result[args->result] = count(); }'
# 统计 blk_mq 请求的 CPU 分布:
bpftrace -e 'k:blk_mq_start_request { @swqueues = lhist(cpu, 0, 100, 1); }'
# 统计 scsi 驱动程序函数:
bpftrace -e 'kprobe:scsi* { @[func] = count(); }'
# 统计 nvme 驱动程序函数:
funccount 'nvme*'
|
网络
linux 网络栈
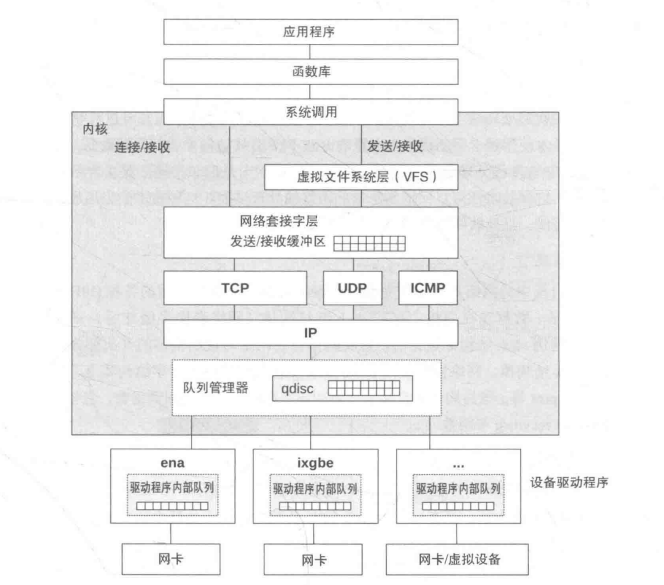
传统网络性能工具使用的是内核内部的统计信息,以及网络抓包能力。BPF 跟踪工具可以提供更多信息,回答类似下面的问题:
- 目前发生的网络套接字 I/O 有哪些,为什么会发生?对应的用户态调用栈是什么?
- 有哪些新 TCP 连接被创建,是哪个进程创建的?
- 目前是否有网络套接字、TCP,以及 IP 级的错误发生?
- TCP 窗口的尺寸是多少?是否有 0 字节传送发生?
- 各个软件栈层面的 I/O 尺寸分别是多少?发送给设备的 I/O 尺寸是多少?
- 哪些包是被网络软件栈丢弃了的?原因是什么?
- TCP 连接延迟、首字节延迟、连接时长分别是多少?
- 内核网络软件栈各层之间的延迟是多少?
- 网络包在 qdisc 队列中的等待时间是多长?在网络驱动程序内置队列中的等待时长是多长?
- 目前正在使用哪些高层协议?
传统工具
| 工具 |
类型 |
介绍 |
| ss |
内核统计 |
网络套接字统计 |
| ip |
内核统计 |
IP统计 |
| nstat |
内核统计 |
网络软件栈统计 |
| netstat |
内核统计 |
显示网络软件栈统计和状态的复合工具 |
| sar |
内核统计 |
显示网络和其他统计信息的复合工具 |
| nicstat |
内核统计 |
网络接口统计 |
| ethtool |
驱动程序统计 |
网络接口驱动程序统计 |
| tcpdump |
抓包 |
抓包分析 |
BPF 网络相关工具表
| 工具 |
来源 |
目标 |
介绍 |
| sockstat |
本书 |
套接字 |
套接字统计信息总览 |
| sofamily |
本书 |
套接字 |
按进程统计新套接字协议 |
| soprotocol |
本书 |
套接字 |
按进程统计新套接字传输协议 |
| soconnect |
本书 |
套接字 |
跟踪套接字的IP协议主动连接的细节信息 |
| soaccept |
本书 |
套接字 |
跟踪套接字的IP协议被动连接的细节信息 |
| socketio |
本书 |
套接字 |
套接字细节信息统计,包括I/O统计 |
| socksize |
本书 |
套接字 |
按进程展示套接字I/O尺寸直方图 |
| sormem |
本书 |
套接字 |
展示套接字接收缓冲区用量和溢出情况 |
| soconnlat |
本书 |
套接字 |
统计IP套接字连接延迟,带调用栈信息 |
| solstbyte |
本书 |
套接字 |
统计IP套接字的首字节延迟 |
| tcpconnect |
BCC/BT/本书 |
TCP |
跟踪TCP主动连接(connect()) |
| tcpaccept |
BCC/BT/本书 |
TCP |
跟踪TCP被动连接(accept()) |
| tcplife |
BCC/本书 |
TCP |
跟踪TCP连接时长,带连接细节信息 |
| tcptop |
BCC |
TCP |
按目的地展示TCP发送和接收吞吐量 |
| tcpretrans |
BCC/BT |
TCP |
跟踪TCP重传,带地址和TCP状态 |
| tcpsynbl |
本书 |
TCP |
以直方图展示TCP SYN积压队列 |
| tcpwin |
本书 |
TCP |
跟踪TCP发送中的阻塞窗口的细节信息 |
| tcpnagle |
本书 |
TCP |
跟踪TCP中nagle算法的用量,以及发送延迟 |
| udpconnect |
本书 |
UDP |
跟踪本机发起的UDP连接 |
| gethostlatency |
本书/BT |
DNS |
通过库函数调用跟踪DNS查找延迟 |
| ipecn |
本书 |
IP |
跟踪IP入栈显式阻塞通知(ECN)的细节 |
| superping |
本书 |
ICMP |
测量网络软件栈中的ICMP echo时间 |
| qdisc-fq(…) |
本书 |
qdiscs |
展示FQ队列管理器的延迟 |
| netsize |
本书 |
网络 |
展示网络设备I/O尺寸 |
| nettxlat |
本书 |
网络 |
展示网络设备发送延迟 |
| skbdrop |
本书 |
skbs |
跟踪sk_buff丢弃情况,带内核调用栈信息 |
| skblife |
本书 |
skbs |
在网络软件栈各层之间跟踪sk_buff的延迟 |
| ieee80211scan |
本书 |
WiFi |
跟踪IEEE 802.11 WiFi扫描情况 |
其他值得一提的 BPF 工具有如下几个
- solisten (8):BCC 工具,可以打印套接字 listen () 调用的细节。
- tcpstates (8):BCC 工具,在每个 TCP 连接状态变化时就打印一行输出,包括 IP 地址、端口信息,以及每个状态所经历的时间。
- tcpdrop (8):BCC 和 bpftrace 工具,当在内核中通过 tcp_drop () 函数丢弃 tcp 包时,打印 IP 地址、TCP 状态信息,以及内核调用栈信息。
- sofsdsnoop (8):BCC 工具,跟踪所有通过 UNIX 套接字传递的文件描述符信息。
- profile (8):在第 6 章中有详细描述,通过采样内核调用栈信息来分析网络相关代码路径所占的时间比例。
- hardirq (8) 和 softirq (8):第 6 章中有详细描述,可以测量网络硬中断和软中断所消耗的时间。
- filetype (8):第 8 章中介绍过的工具,跟踪 vfs_read () 和 vfs_write (),通过 inode 识别网络套接字的读写。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
# 按错误代码统计失败的 socket 调用
argdist -C 't:syscalls:sys_exit_connect():int:args->ret:args->ret<0'
# 按用户态调用栈统计套接字 connect (2) 调用:
stackcount -U t:syscalls:sys_enter_connect
# 以直方图形式统计 TCP 发送的字节数:
argdist -H 'p:tcp_sendmsg(void *sk, void *msg, int size):int:size'
# 以直方图形式统计 TCP 接收的字节数:
argdist -H 'r:tcp_recvmsg():int:$retval:$retval>0'
# 统计所有的 TCP 函数的调用频率(对所有的 TCP 操作都添加额外开销):
funccount 'tcp_*'
# 以直方图形式统计 UDP 发送的字节数:
argdist -H 'p:udp_sendmsg(void *sk, void *msg, int size):int:size'
# 以直方图形式统计 UDP 接收的字节数:
argdist -H 'r:udp_recvmsg():int:$retval:$retval>0'
# 统计所有的 UDP 函数的调用频率(对所有的 UDP 操作都添加额外开销):
funccount 'udp_*'
# 统计网络包发送的调用栈信息:
stackcount t:net:net_dev_xmit
# 统计 ieee80211 层的函数的调用频率(对所有网络包都添加额外开销):
funccount 'ieee80211_*'
# 统计所有 ixgbevf 设备驱动函数的调用频率(对 ixgbevf 驱动添加额外开销):
funccount 'ixgbevf_*'
|
bpftrace 程序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
|
# 按 PID 和进程名统计套接字 accept (2) 调用:
bpftrace -e 't:syscalls:sys_enter_accept* { @[pid, comm] = count(); }'
# 按 PID 和进程名统计套接字 connect (2) 调用:
bpftrace -e 't:syscalls:sys_enter_connect { @[pid, comm] = count(); }'
# 按进程名和错误代码统计失败的 connect (2) 调用:
bpftrace -e 't:syscalls:sys_exit_connect /args->ret < 0/ { @[comm, - args->ret] = count(); }'
# 按用户态调用栈统计套接字 connect (2) 调用:
bpftrace -e 't:syscalls:sys_enter_connect { @[ustack] = count(); }'
# 按发送 / 接收、在 CPU 上运行的、进程名统计套接字发送和接收的次数:
bpftrace -e 'k:sock_sendmsg,k:sock_recvmsg { @[func, pid, comm] = count(); }'
# 按在 CPU 上运行的 PID 和进程名统计套接字发送和接收的字节数:
bpftrace -e 'kr:sock_sendmsg,kr:sock_recvmsg /(int32)retval > 0/ { @[pid, comm] = sum((int32)retval); }'
# 按在 CPU 上运行的 PID 和进程名统计 TCP connect 调用:
bpftrace -e 'k:tcp_v*_connect { @[pid, comm] = count(); }'
# 按在 CPU 上运行的 PID 和进程名统计 TCP accept 调用:
bpftrace -e 'k:inet_csk_accept { @[pid, comm] = count(); }'
# 统计 TCP 的发送和接收次数:
bpftrace -e 'k:tcp_sendmsg,k:tcp*recvmsg { @[func] = count(); }'
# 按在 CPU 上运行的 PID 和进程名统计 TCP 发送 / 接收的次数:
bpftrace -e 'k:tcp_sendmsg,k:tcp_recvmsg { @[func, pid, comm] = count(); }'
# 以直方图形式统计 TCP 发送的字节数:
bpftrace -e 'k:tcp_sendmsg { @send_bytes = hist(arg2); }'
# 以直方图形式统计 TCP 接收的字节数:
bpftrace -e 'kr:tcp_recvmsg /retval >= 0/ { @recv_bytes = hist(retval); }'
# 按类型与远端主机(仅支持 IPv4)统计 TCP 重传:
bpftrace -e 't:tcp:tcp_retransmit_* { @[probe, ntop(2, args->saddr)] = count(); }'
# 统计所有的 TCP 函数的调用频率(对所有的 TCP 函数添加额外开销):
bpftrace -e 'k:tcp_* { @[func] = count(); }'
# 按在 CPU 上运行的 PID 和进程名统计 UDP 发送和接收的次数:
bpftrace -e 'k:udp*_sendmsg,k:udp*_recvmsg { @[func, pid, comm] = count(); }'
# 以直方图形式统计 UDP 发送的字节数:
bpftrace -e 'k:udp_sendmsg { @send_bytes = hist(arg2); }'
# 以直方图形式统计 UDP 接收的字节数:
bpftrace -e 'kr:udp_recvmsg /retval >= 0/ { @recv_bytes = hist(retval); }'
# 统计所有的 UDP 函数的调用频率(为所有 UDP 包增加额外开销):
bpftrace -e 'k:udp_* { @[func] = count(); }'
# 统计发送数据包时的内核态调用栈:
bpftrace -e 't:net:net_dev_xmit { @[kstack] = count(); }'
# 按每个设备进行 CPU 直方图统计:
bpftrace -e 't:net:netif_receive_skb { @[str(args->name)] = lhist(cpu, 0, 128, 1); }'
# 统计所有 ieee80211 层函数的调用频率(对所有数据包增加额外开销):
bpftrace -e 'k:ieee80211_* { @[func] = count(); }'
# 统计所有 ixgbevf 设备驱动函数的调用频率(对所有 ixgbevf 添加额外开销):
bpftrace -e 'k:ixgbevf_* { @[func] = count(); }'
# 统计所有 iwl 设备驱动中的跟踪点的调用频率(对 iwl 添加额外开销):
bpftrace -e 't:iwlwifi:*;t:iwlwifi_io:* { @[probe] = count(); }'
|
安全
很多策略都是用了 BPF 来执行
- seccomp:安全计算(seccomp)工具可以执行 BPF 程序(目前仅限于经典 BPF)来制定有关允许系统调用的决策
- Cilium:Cilium 为工作负载 —— 不论是应用程序容器还是进程 —— 都提供了透明安全的网络连接和负载均衡功能
- bpfilter:bpfilter 是一个用 BPF 完全替代 iptables 防火墙的概念证明程序
- Landlock:Landlock 是一个基于 BPF 的安全模块,使用 BPF 来提供内核资源的细粒度访问控制
- KRSI:内核运行时安全插桩(Kernel Runtime Security Instrumentation)是一个来自 Google 的 Linux 安全模块,用于可扩展的审计和策略执行
安全相关的工具表
| 工具 |
来源 |
目标 |
描述 |
| execsnoop |
BCC/BT |
系统调用 |
列出新程序的执行 |
| elfsnoop |
本书 |
内核 |
显示ELF文件加载 |
| modsnoop |
本书 |
内核 |
显示内核模块加载 |
| bashreadline |
BCC/BT |
bash |
列出输入的bash命令行命令 |
| shellsnoop |
本书 |
shells |
镜像shell输出 |
| ttysnoop |
BCC/本书 |
TTY |
镜像tty输出 |
| opensnoop |
BCC/BT |
系统调用 |
列出打开的文件 |
| eperm |
本书 |
系统调用 |
统计失败的EPERM和EACCES系统调用 |
| tcpconnect |
BCC/BT |
TCP |
跟踪TCP出站连接(主动) |
| tcpaccept |
BCC/BT |
TCP |
跟踪TCP入站连接(被动) |
| tcpreset |
本书 |
TCP |
显示TCP连接重置:检测端口扫描 |
| capable |
BCC/BT |
安全 |
跟踪内核安全能力检查 |
| setuids |
本书 |
系统调用 |
跟踪setuid系统调用:权限提升 |
bcc 程序
1
2
3
4
5
6
7
8
|
#为 PID 为 1234 的进程统计安全审计事件数:
funccount -p 1234 'security_*'
# 跟踪可插入身份验证模块(PAM)会话的开始:
trace 'pam:pam_start "%s: %s", arg1, arg2'
# 跟踪内核模块加载:
trace 't:module:module_load "load: %s", args->name'
|
bpftrace 程序
1
2
3
4
5
6
7
8
|
#为 PID 为 1234 的进程统计安全审计事件数:
bpftrace -e 'k:security_* /pid == 1234 { @[func] = count(); }'
# 跟踪可插入身份验证模块(PAM)会话的开始:
bpftrace -e 'u:/lib/x86_64-linux-gnu/libpam.so.0:pam_start { printf("%s: %s\n", str(arg0), str(arg1)); }'
# 跟踪内核模块加载:
bpftrace -e 't:module:module_load { printf("load: %s\n", str(args->name)); }'
|
bashreadline
1
2
3
4
5
6
7
8
9
10
11
12
13
|
#!/usr/local/bin/bpftrace
BEGIN
{
printf("Tracing bash commands... Hit Ctrl-C to end.\n");
printf("%-9s %-6s %s\n", "TIME", "PID", "COMMAND");
}
uretprobe:/bin/bash:readline
{
time("%H:%M:%S ");
printf("%-6d %s\n", pid, str(retval));
}
|
参考