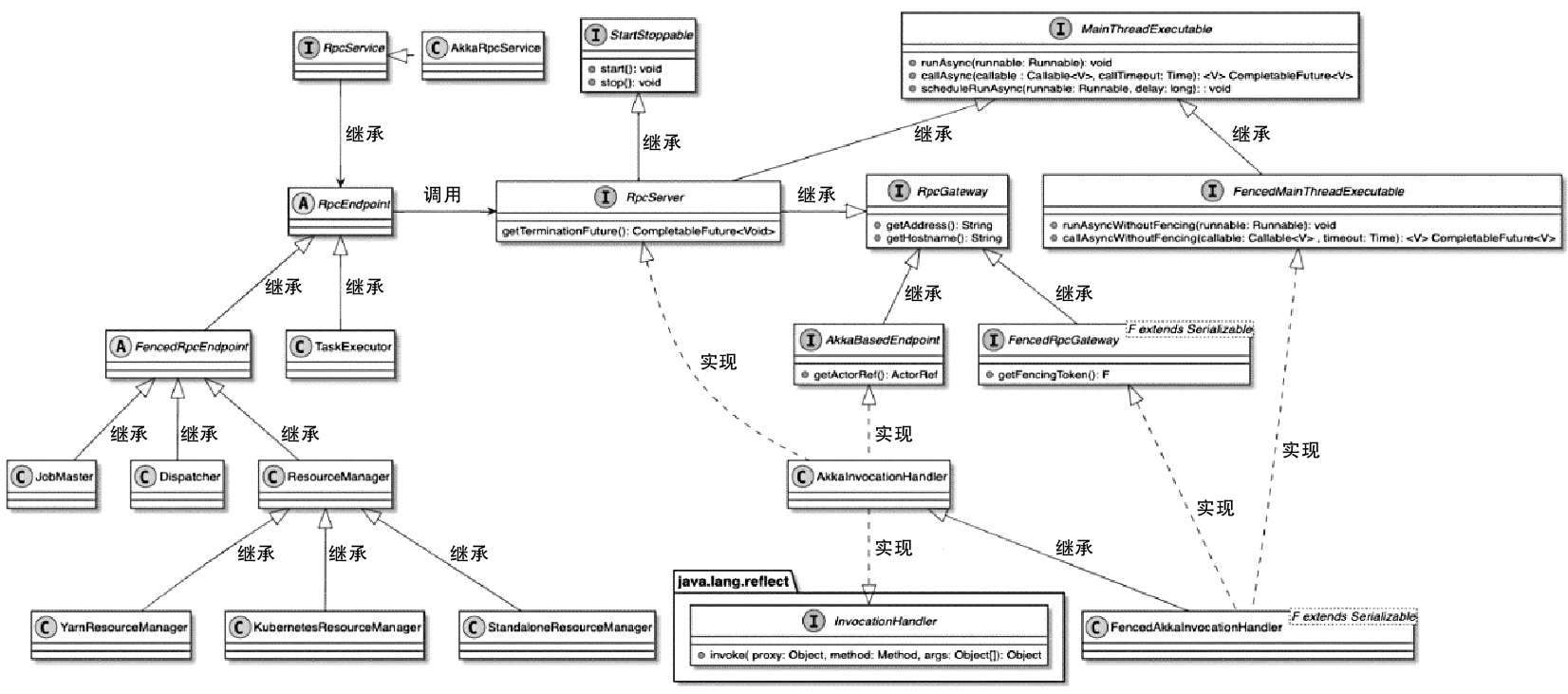
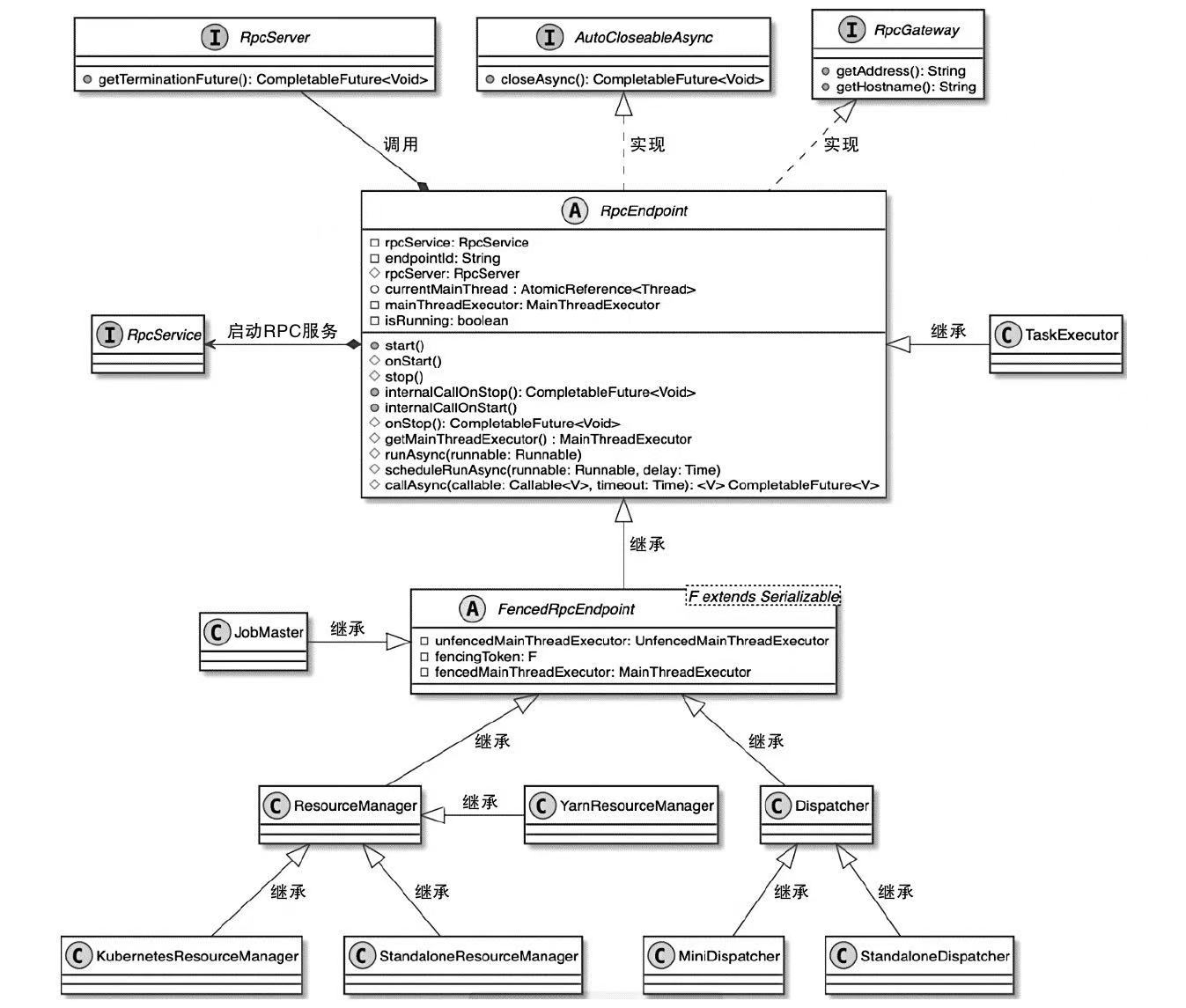
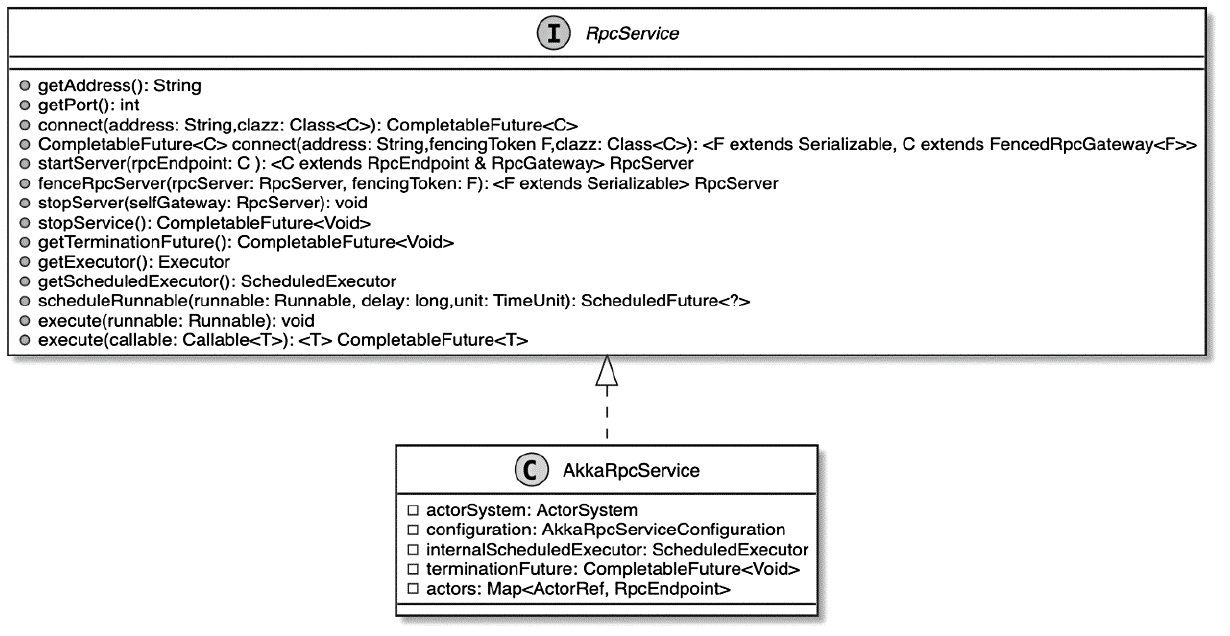
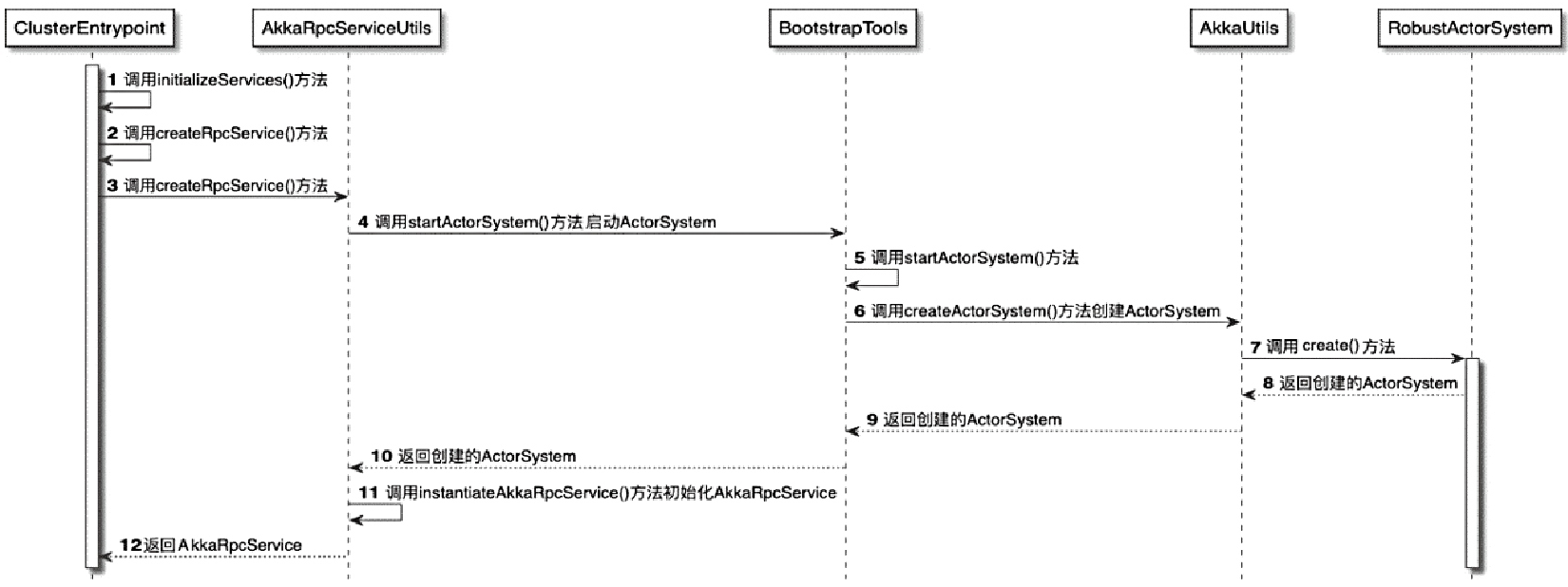
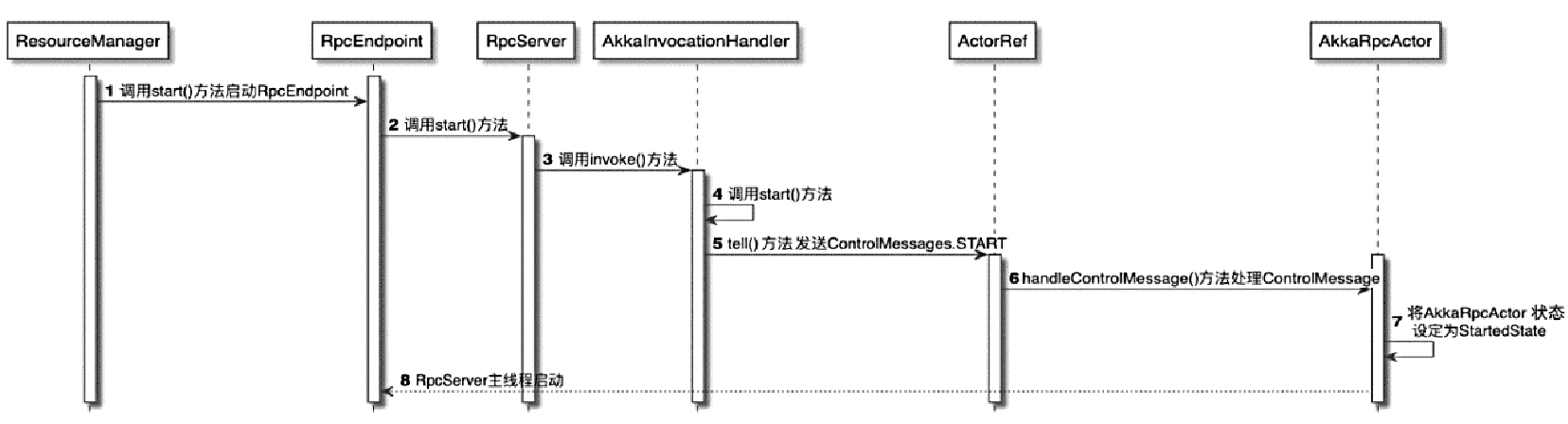
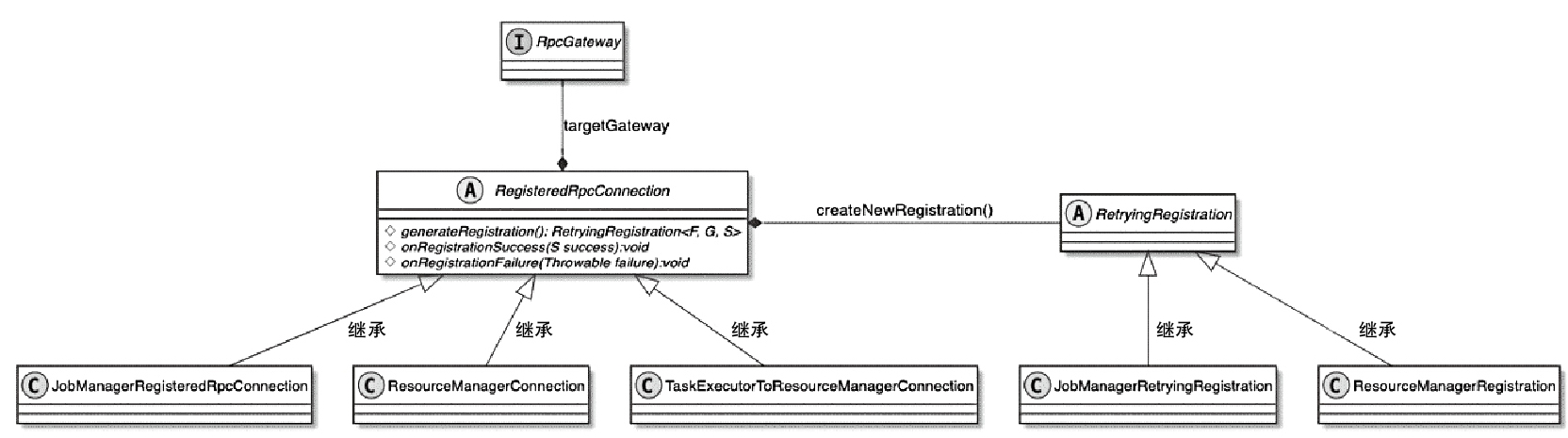
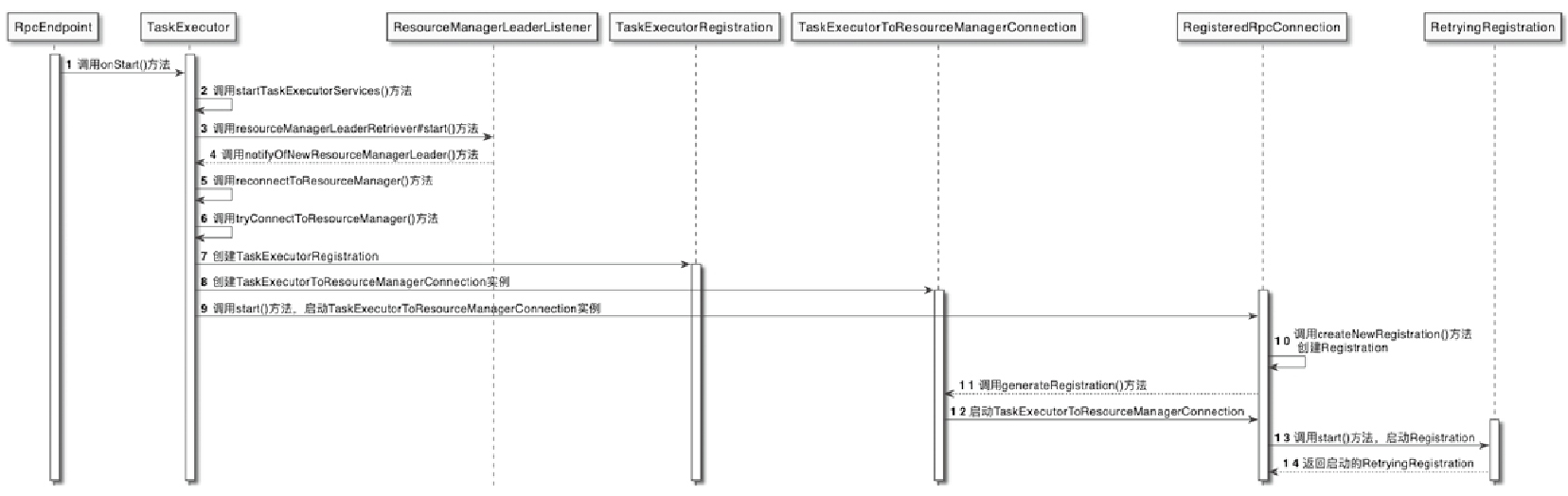
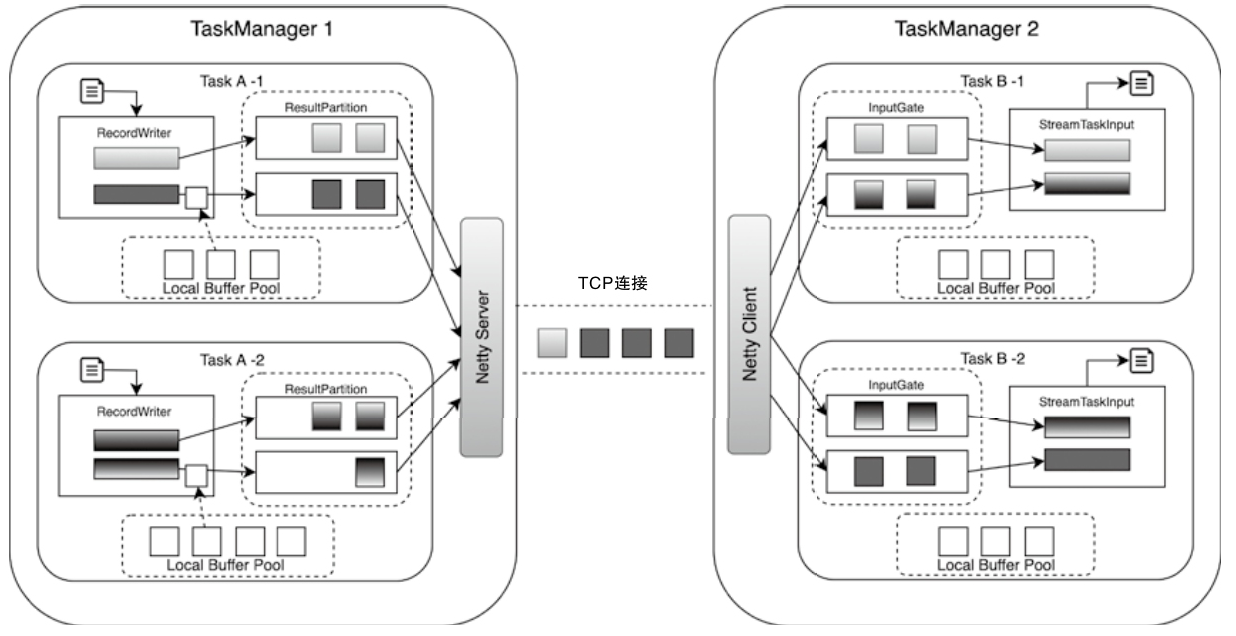
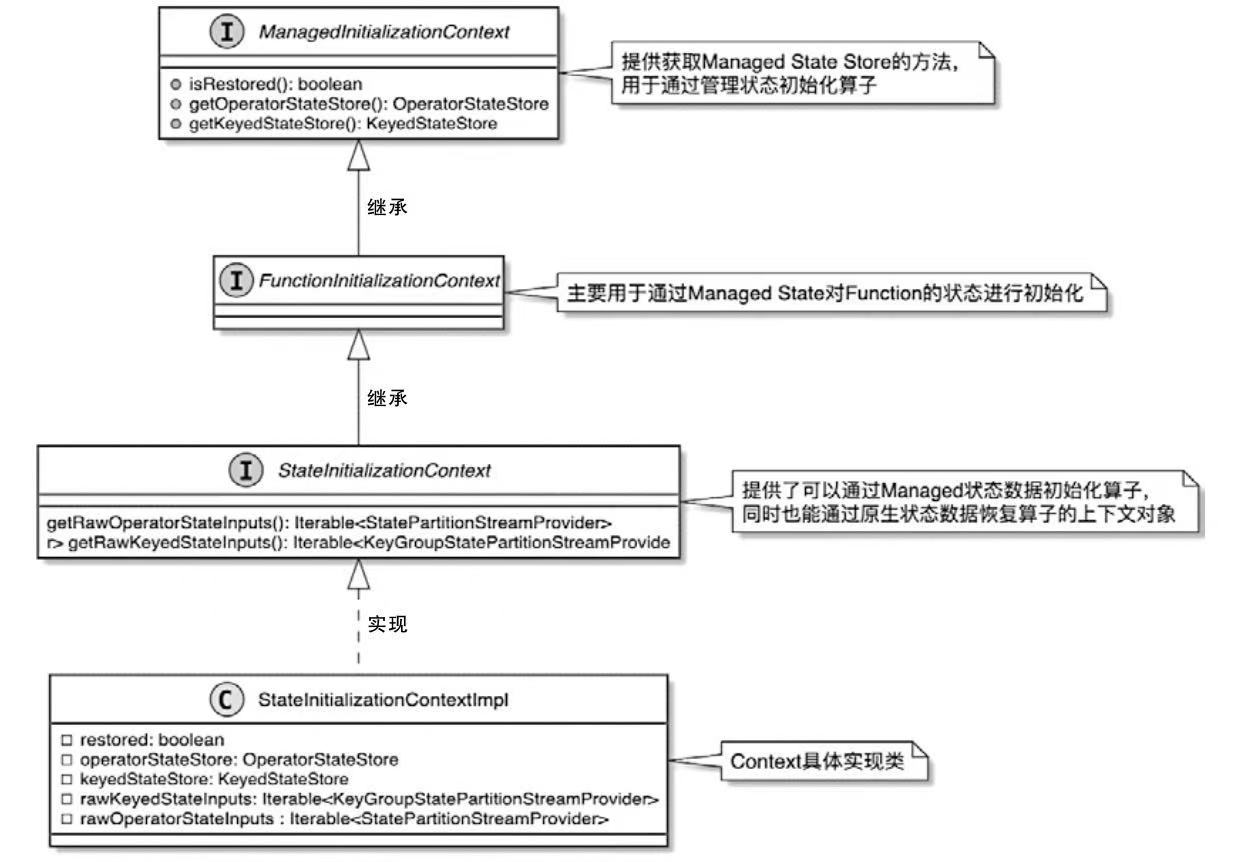
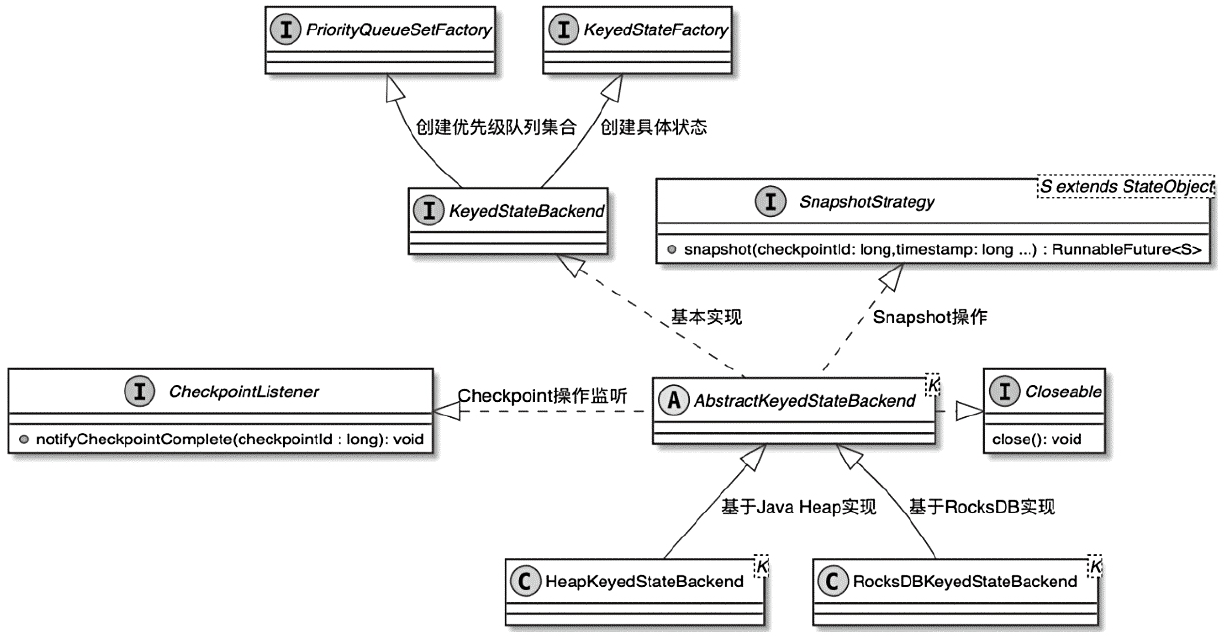
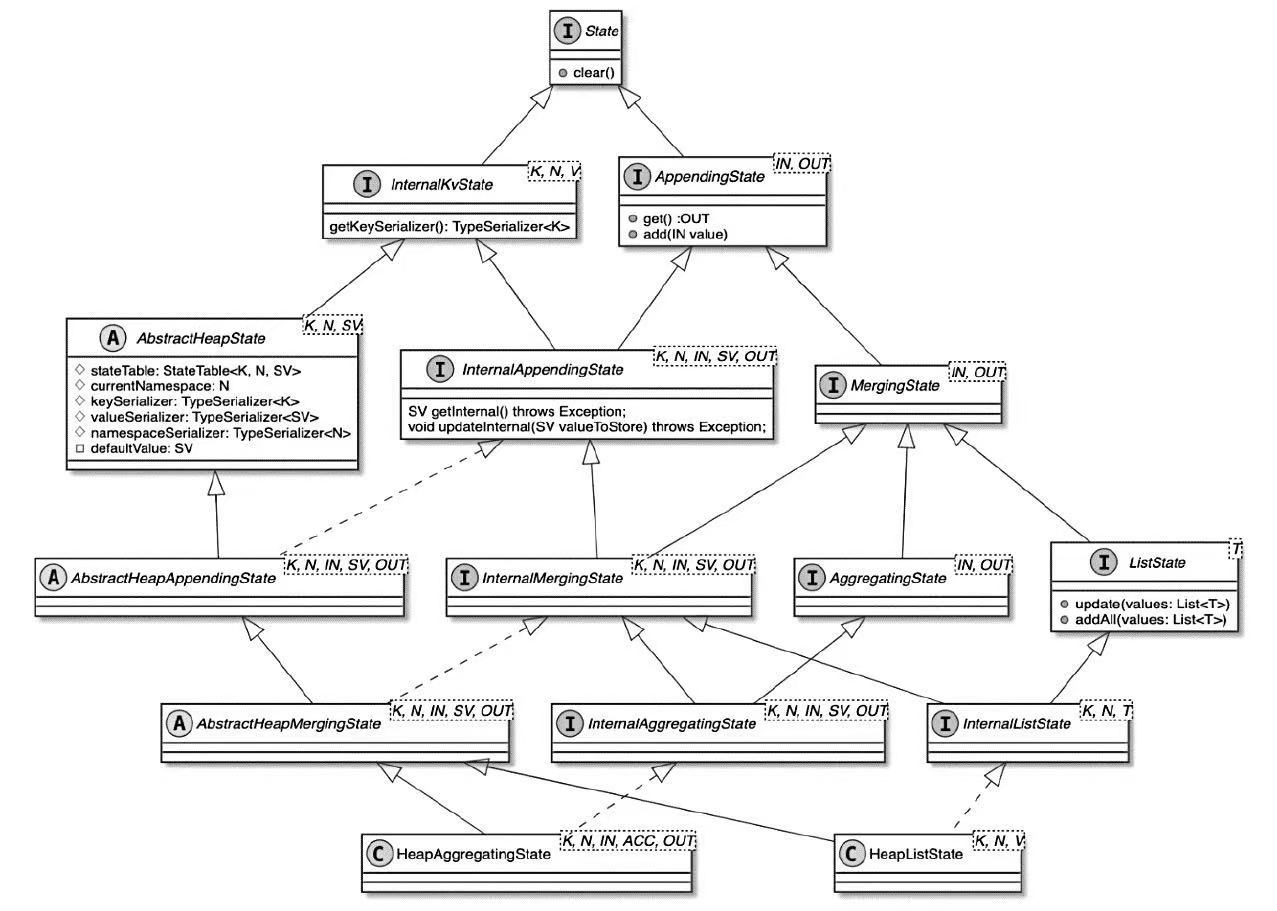
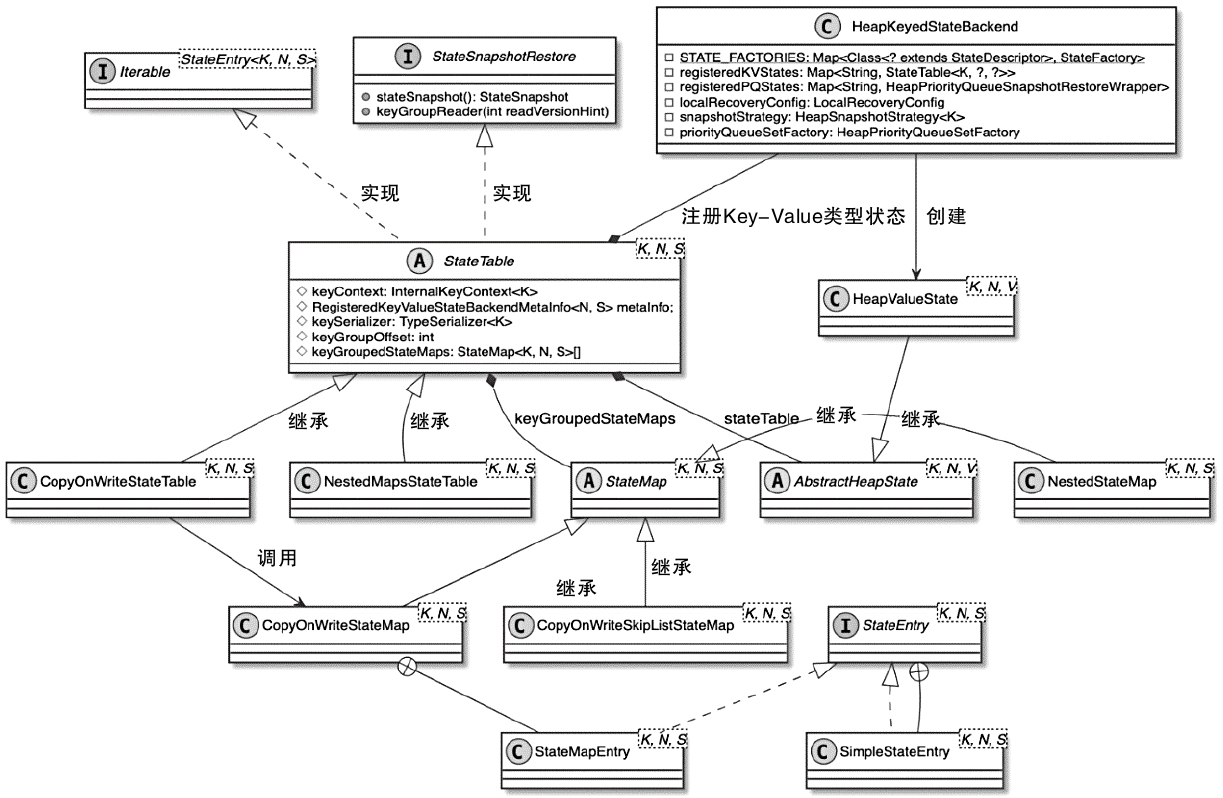
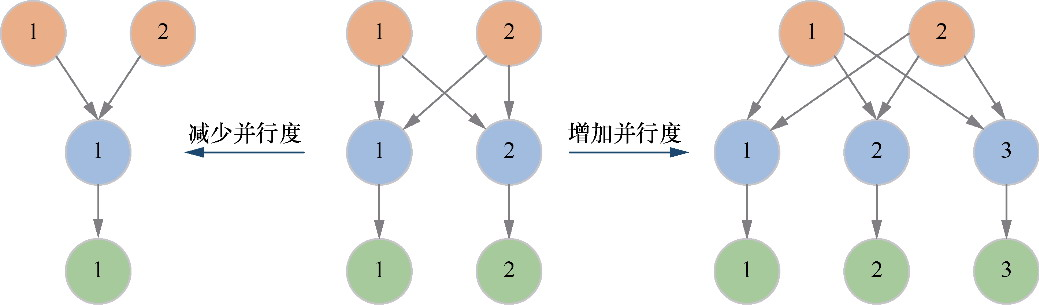
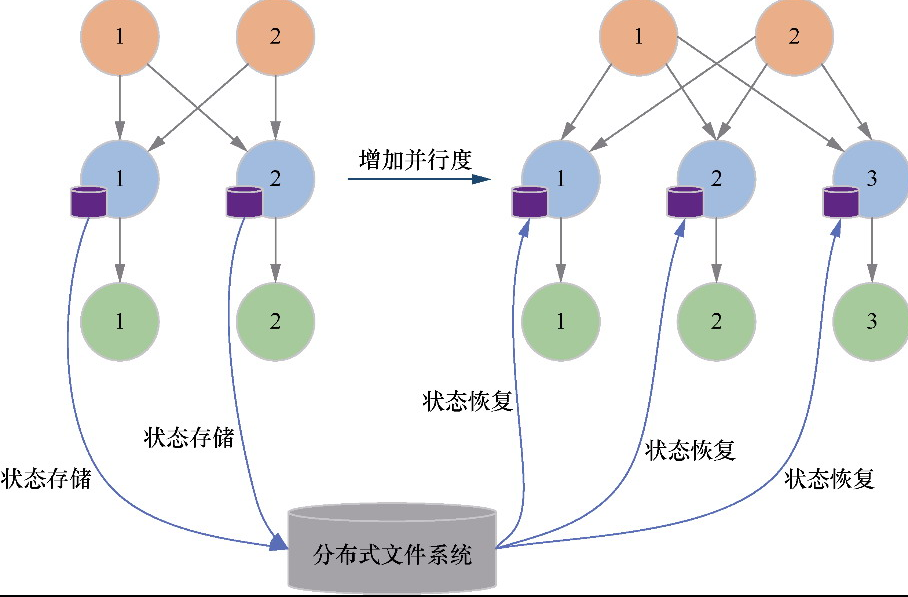
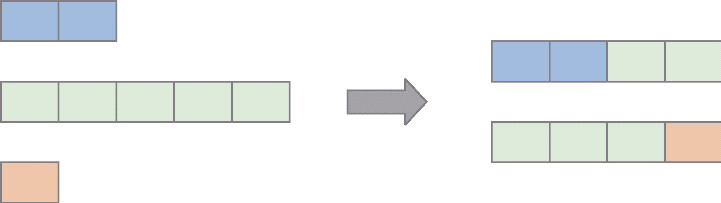
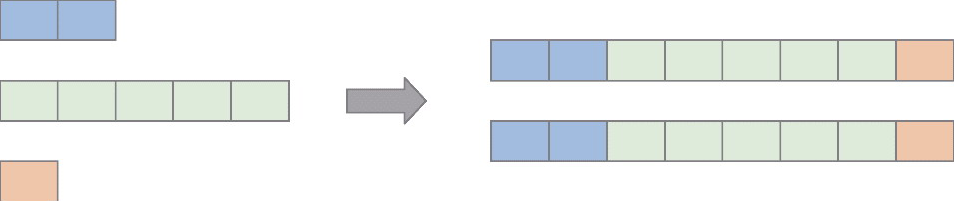
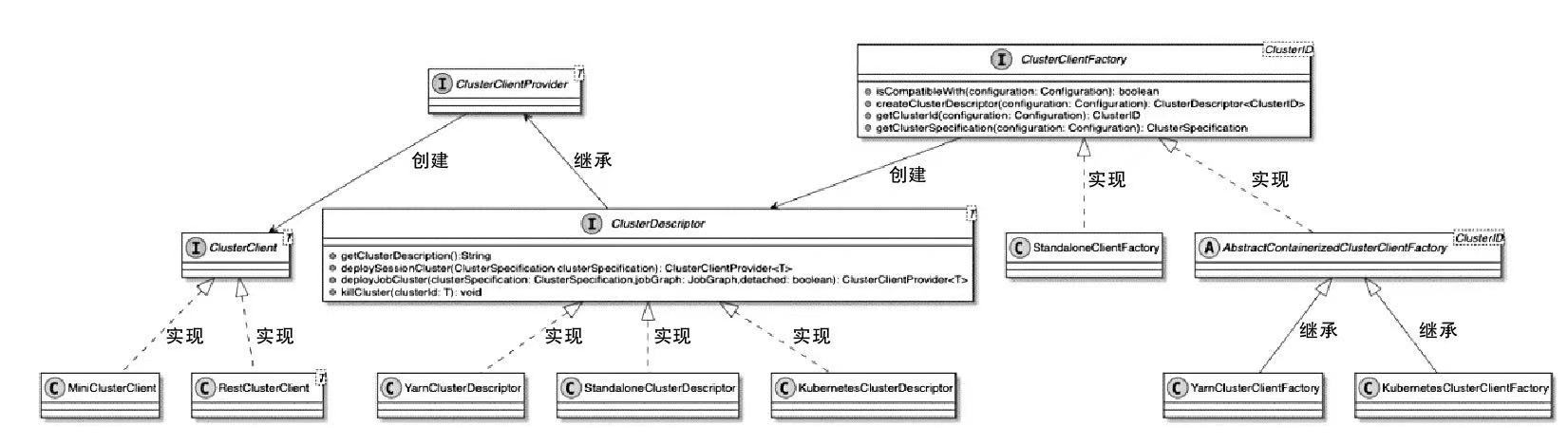
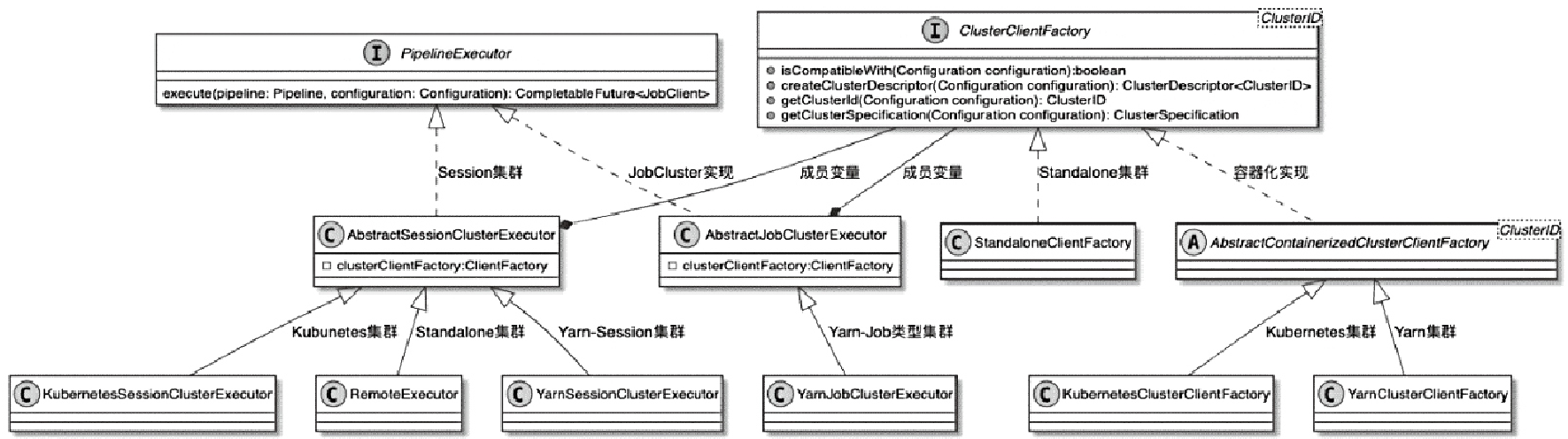
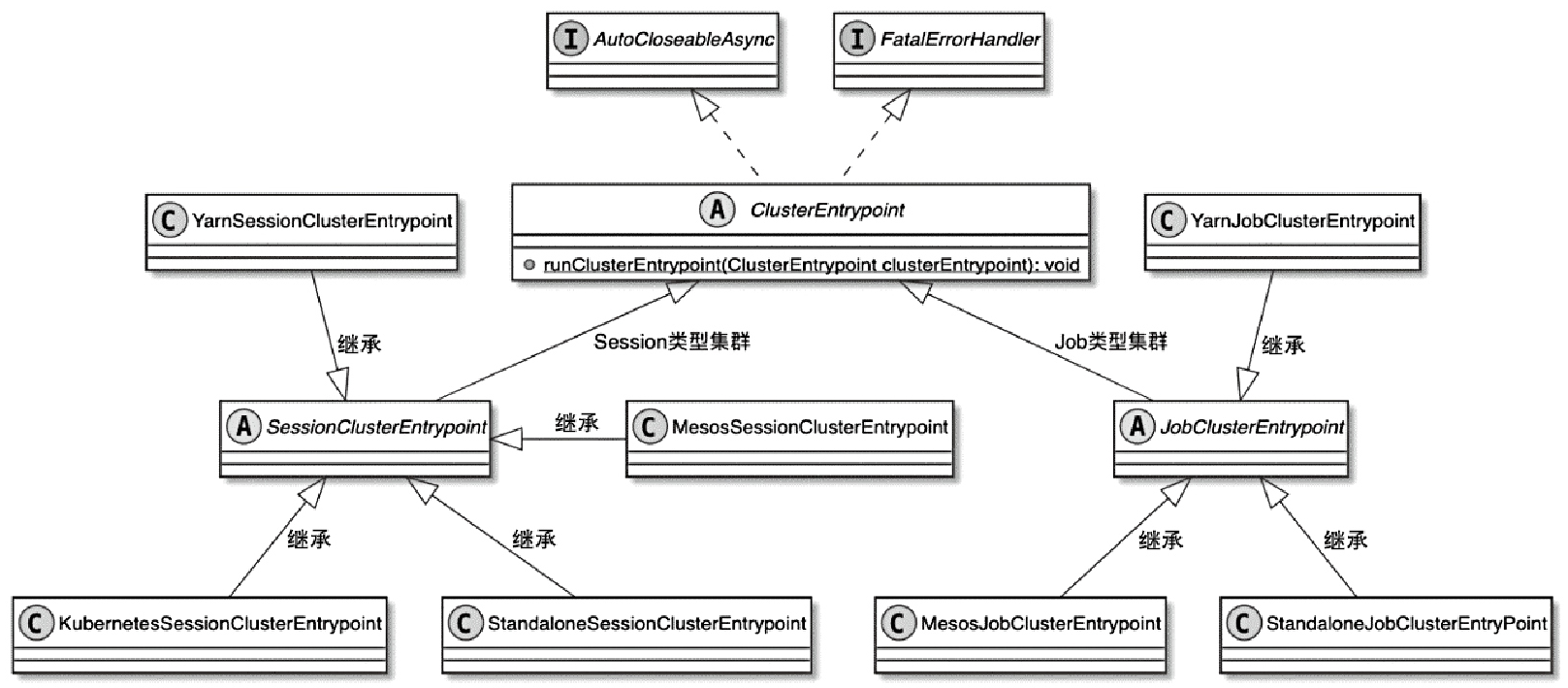
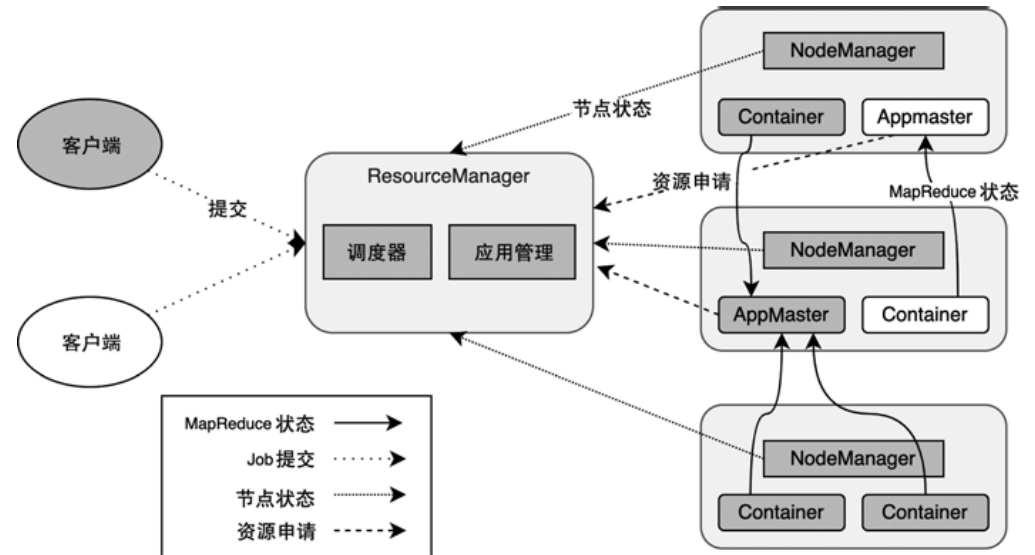
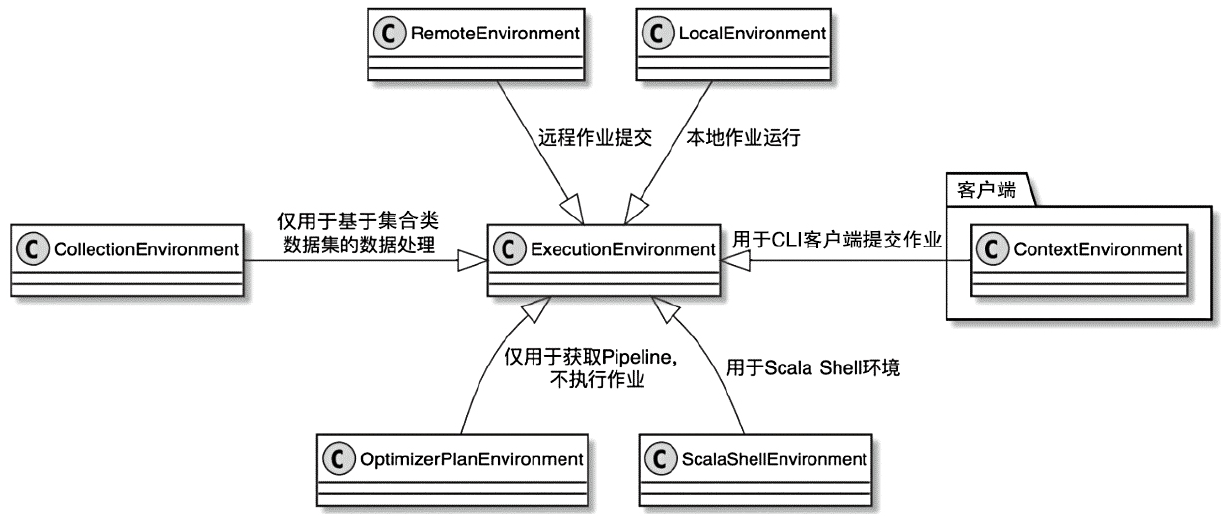
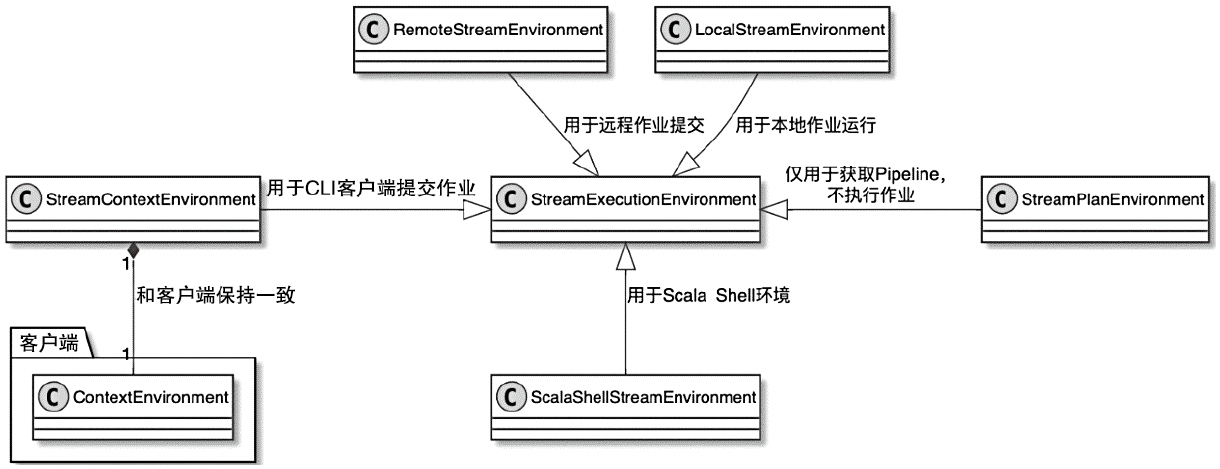
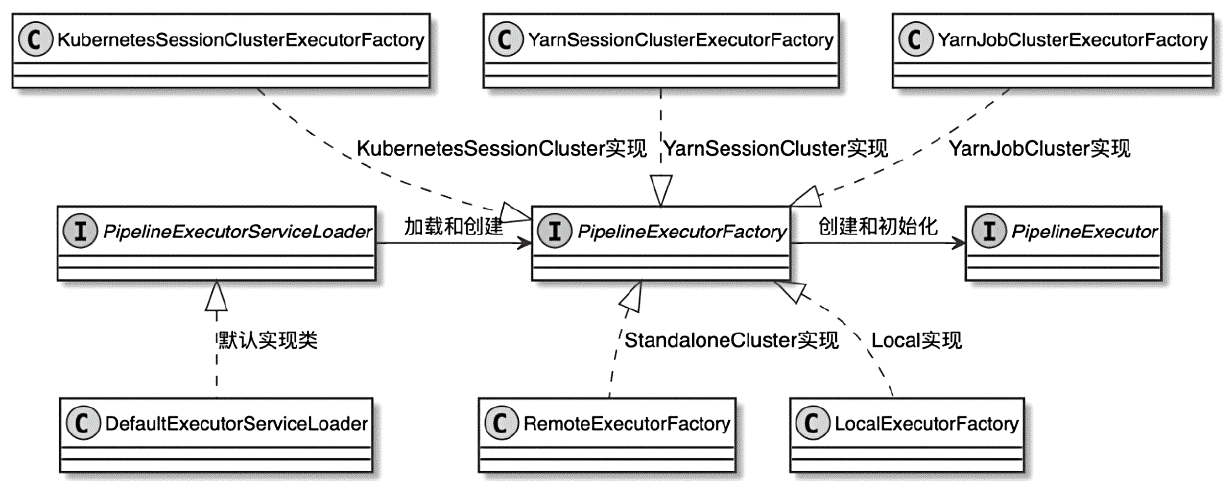
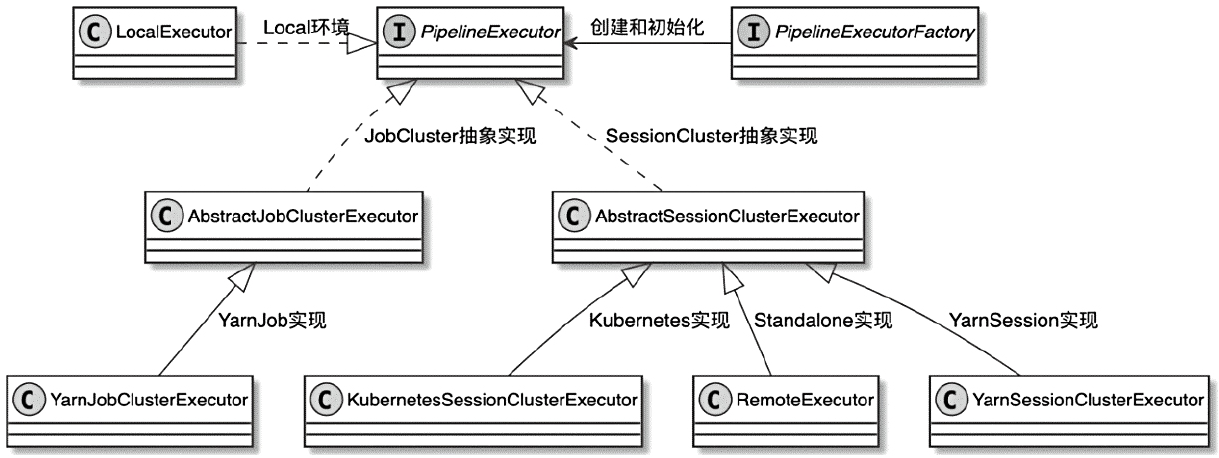
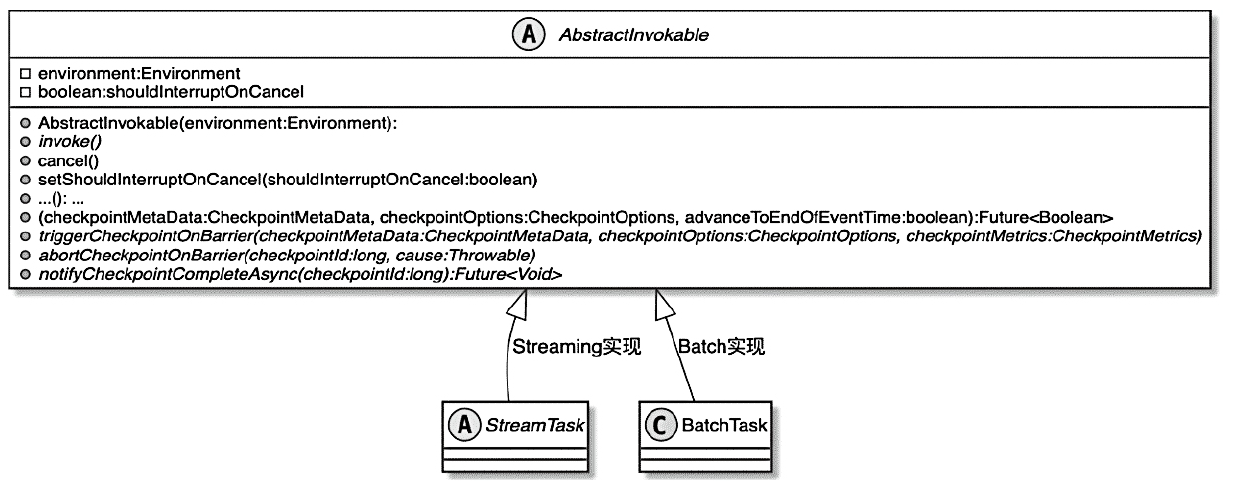
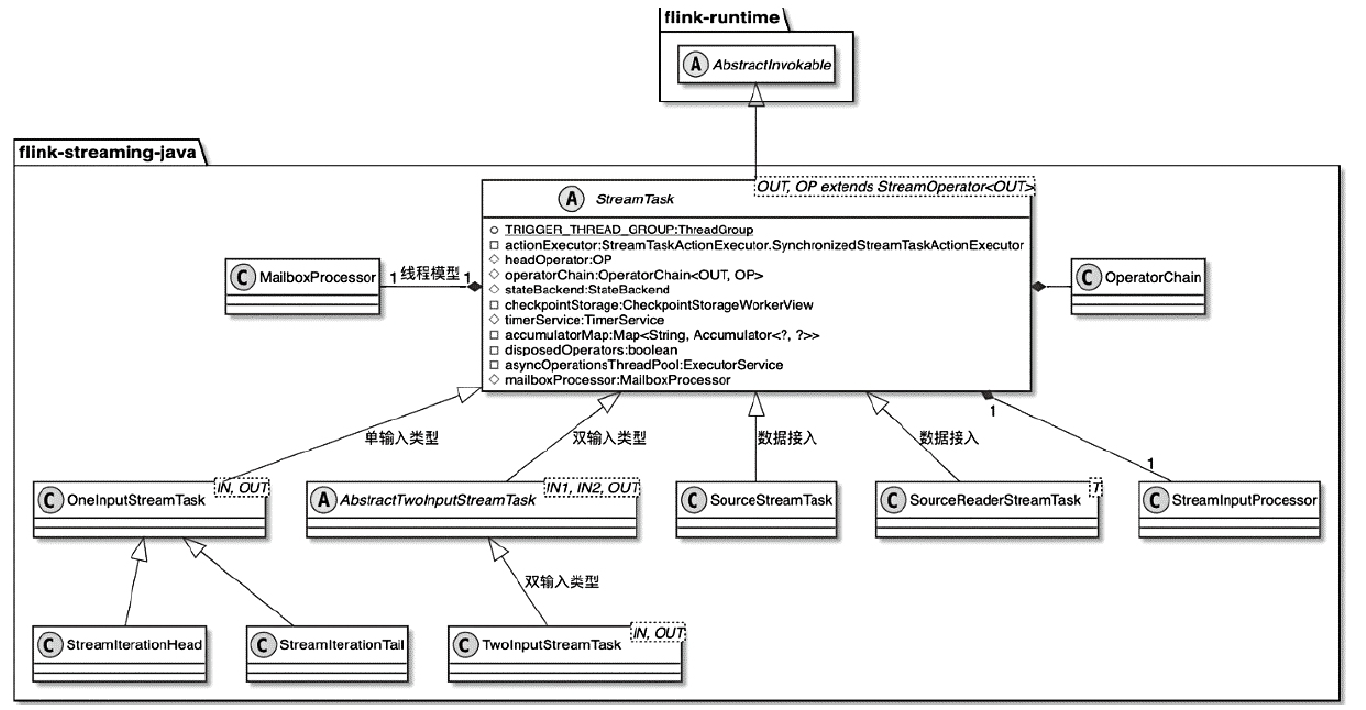
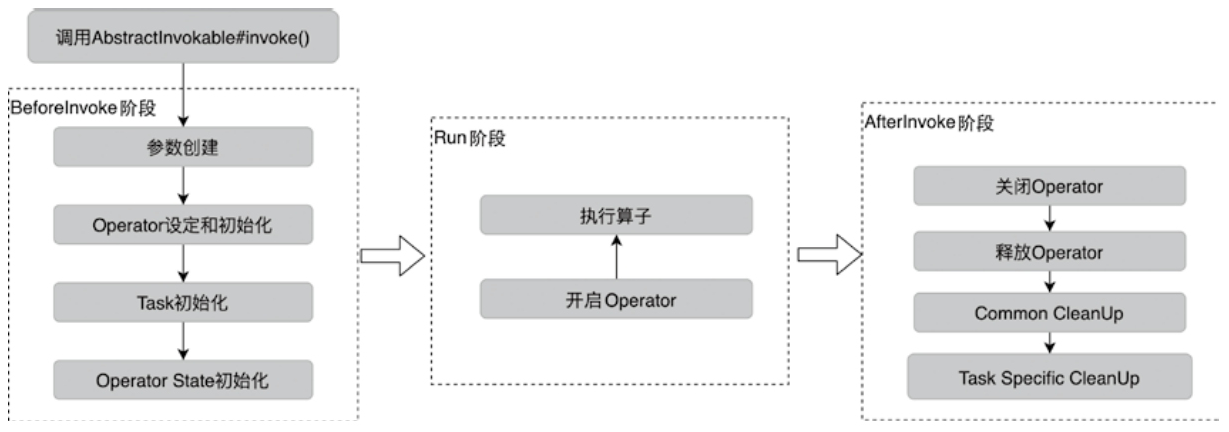
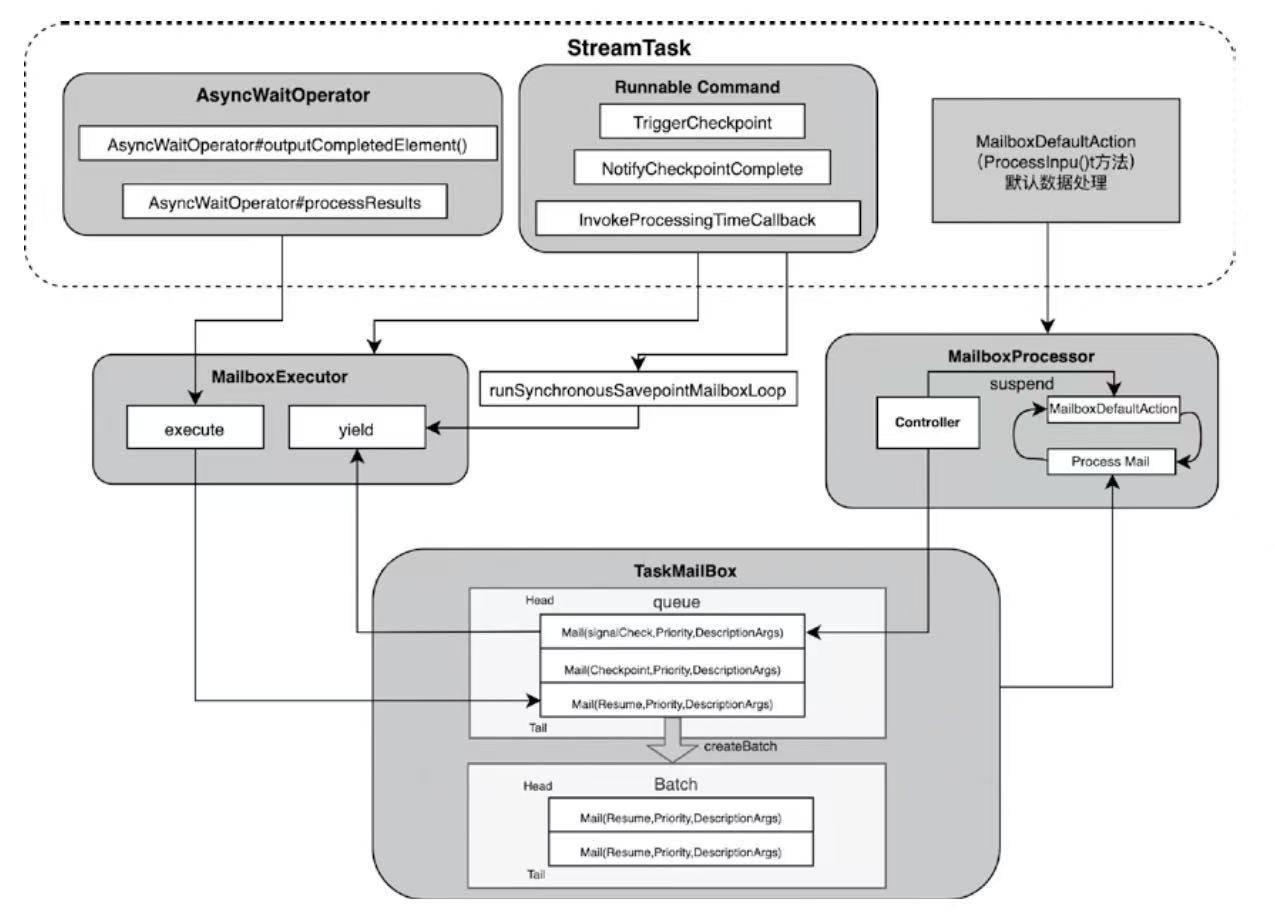
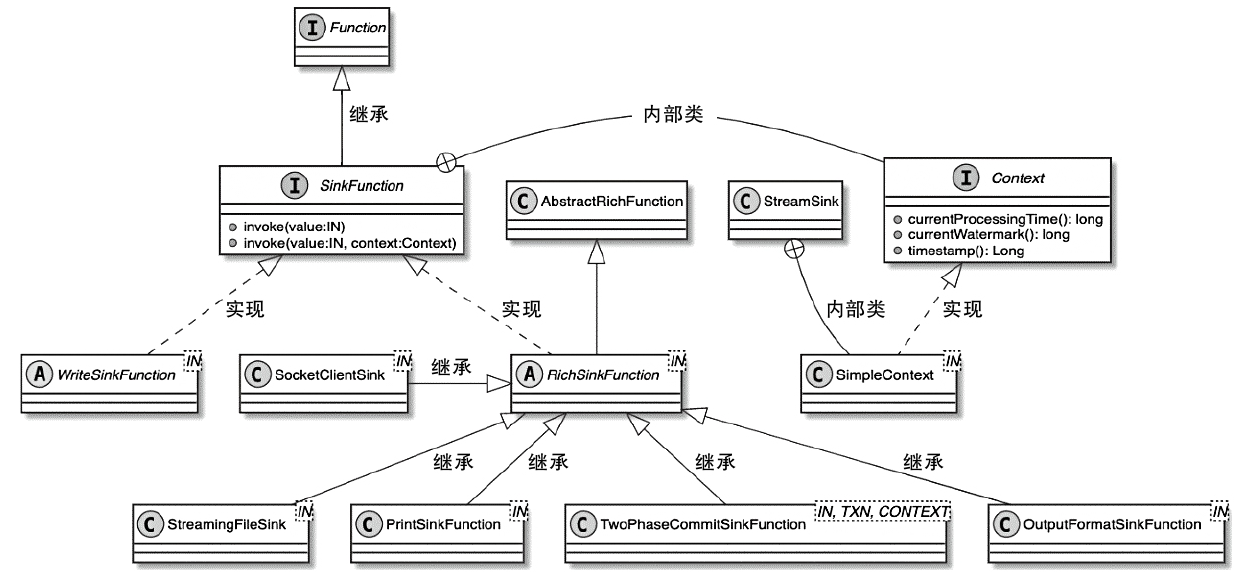
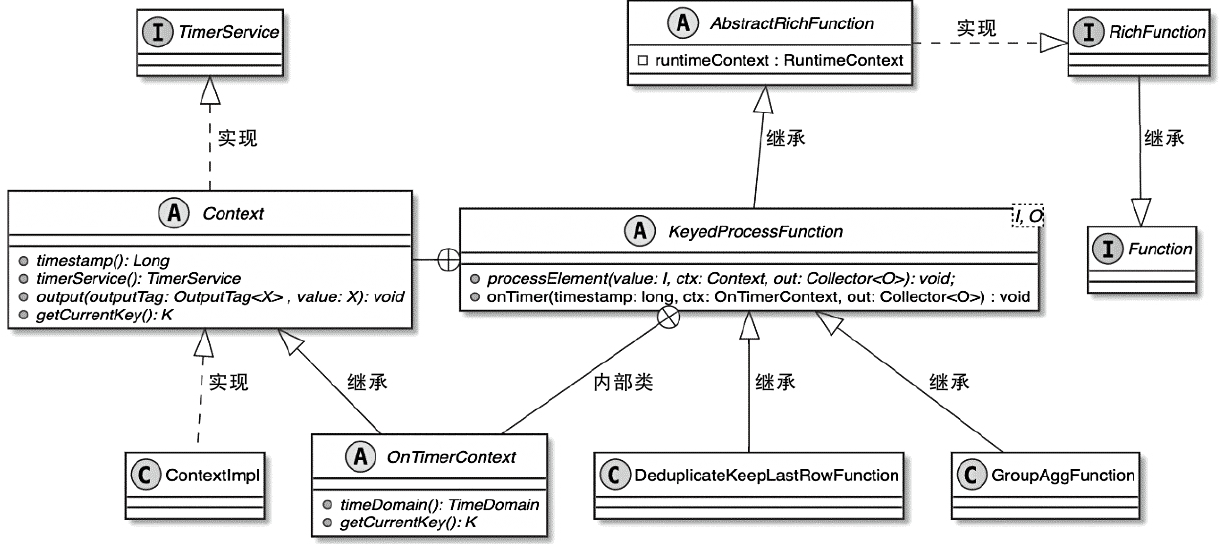
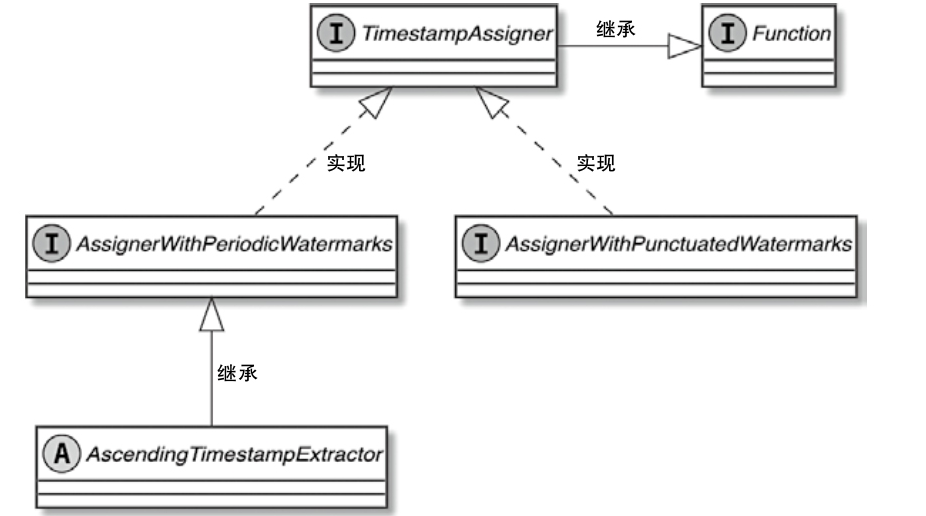
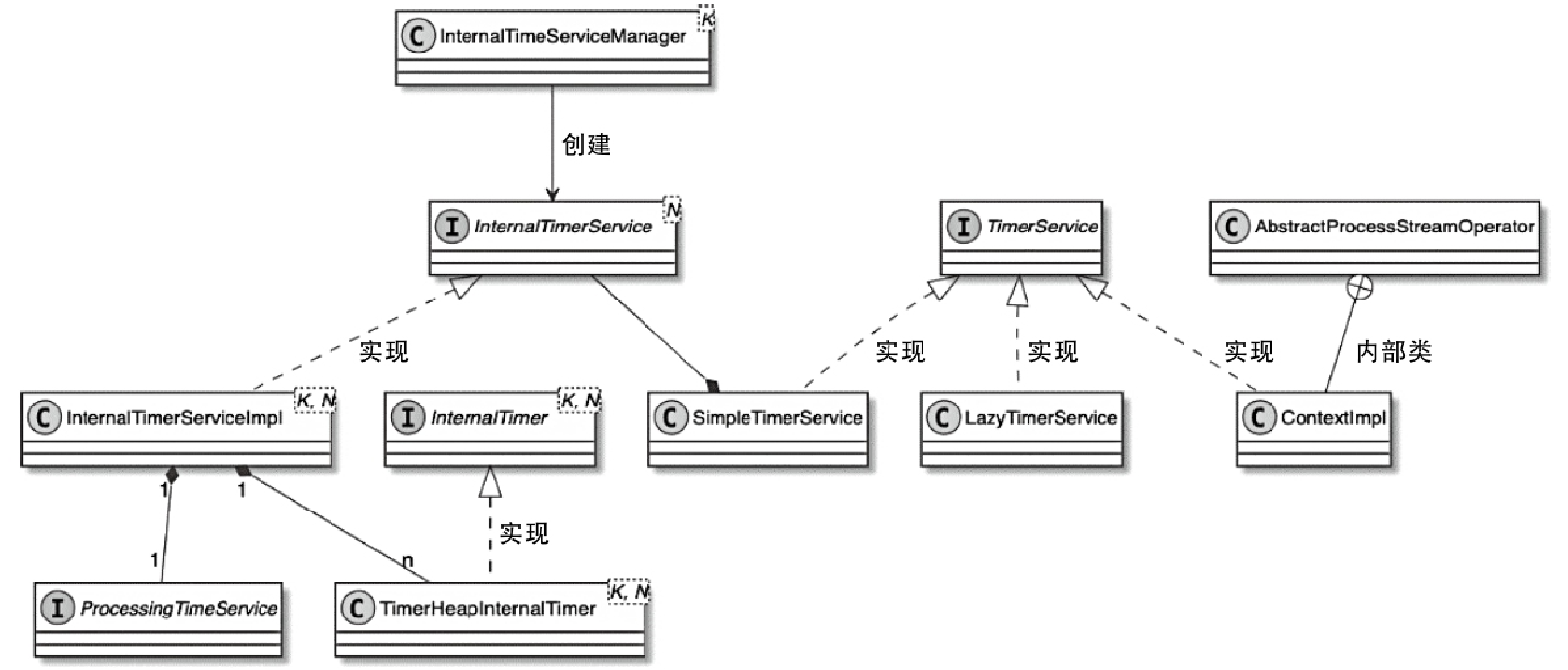
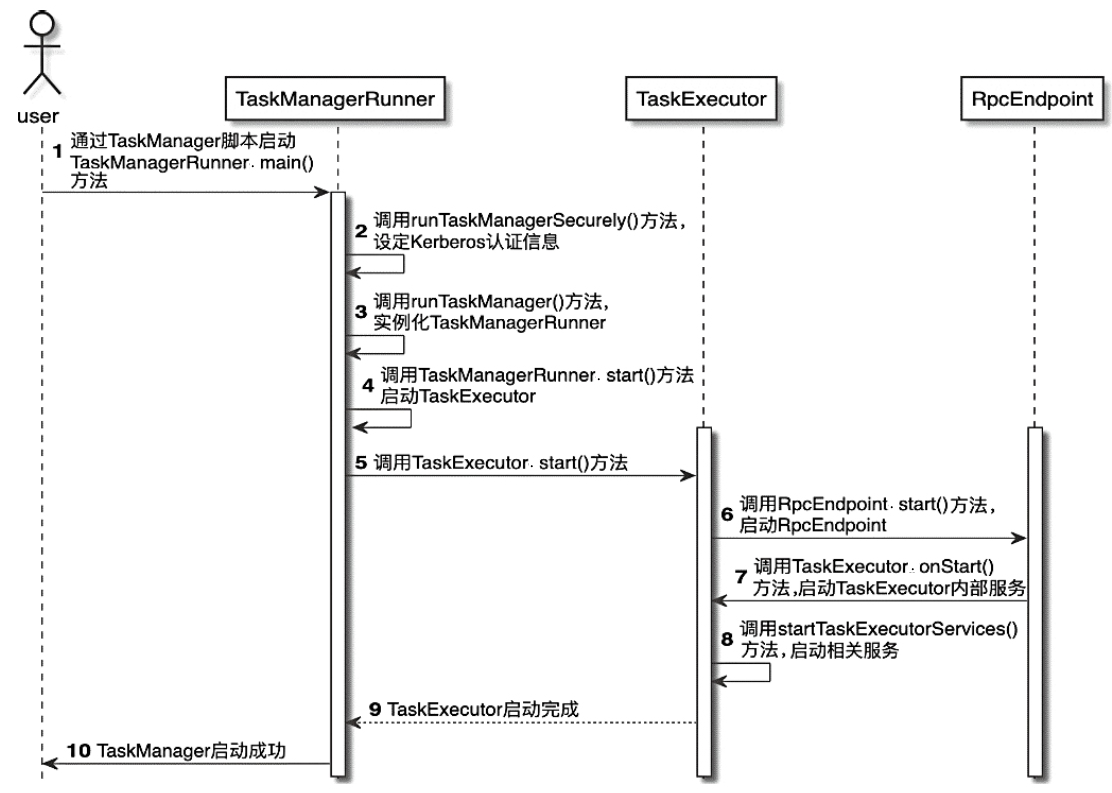
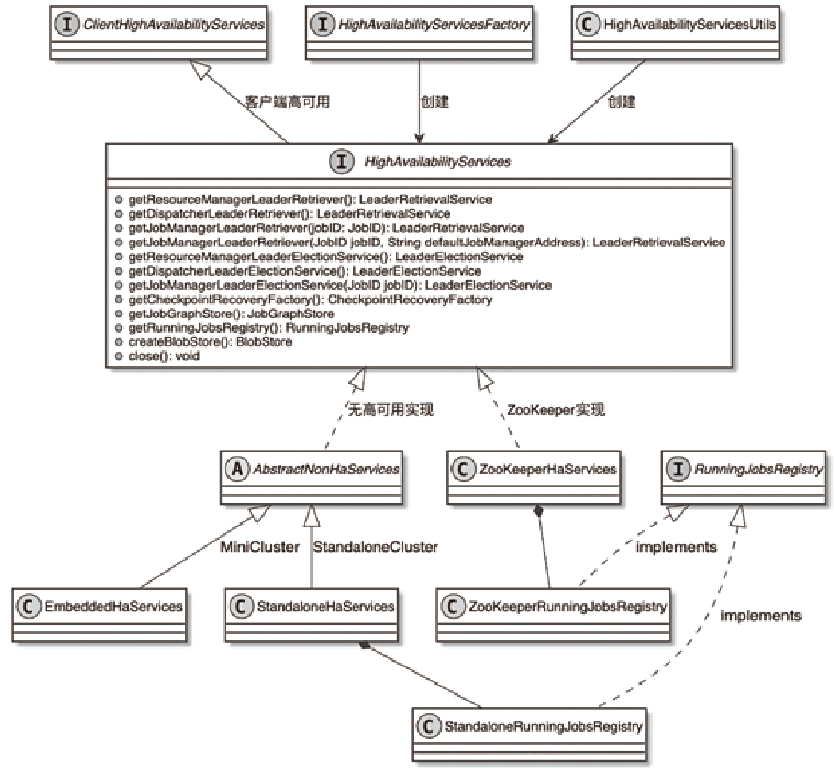
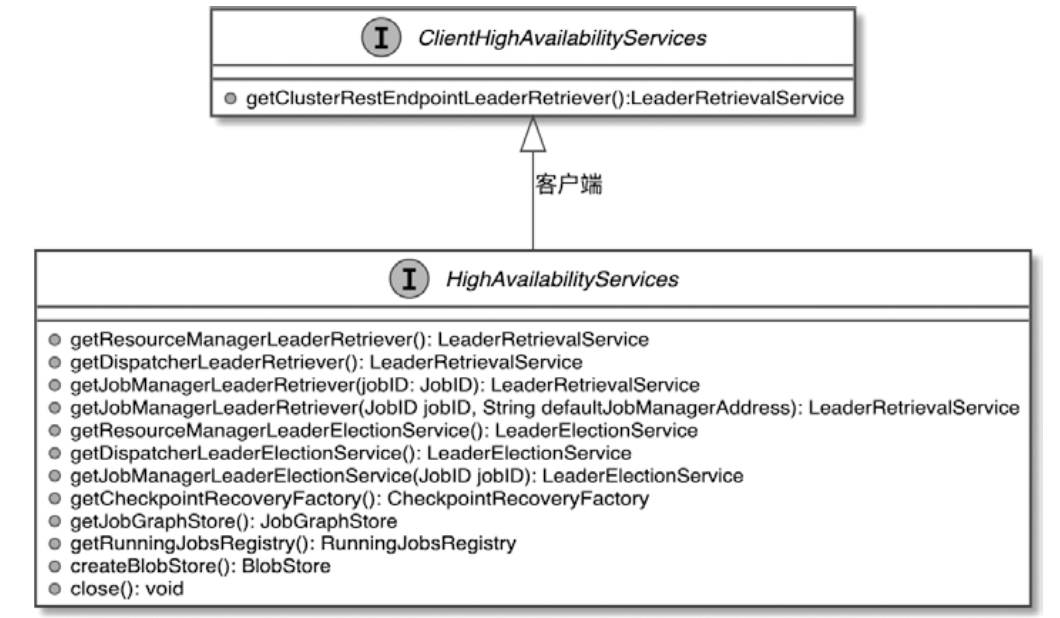
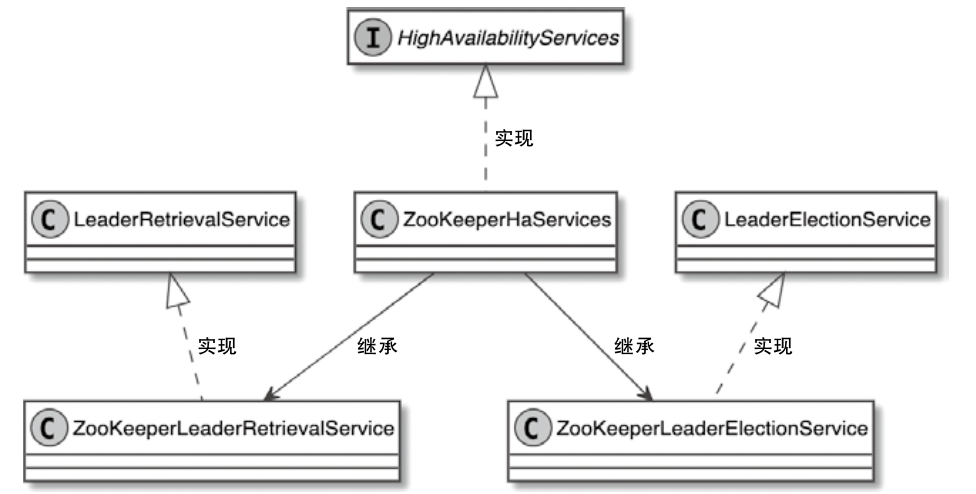
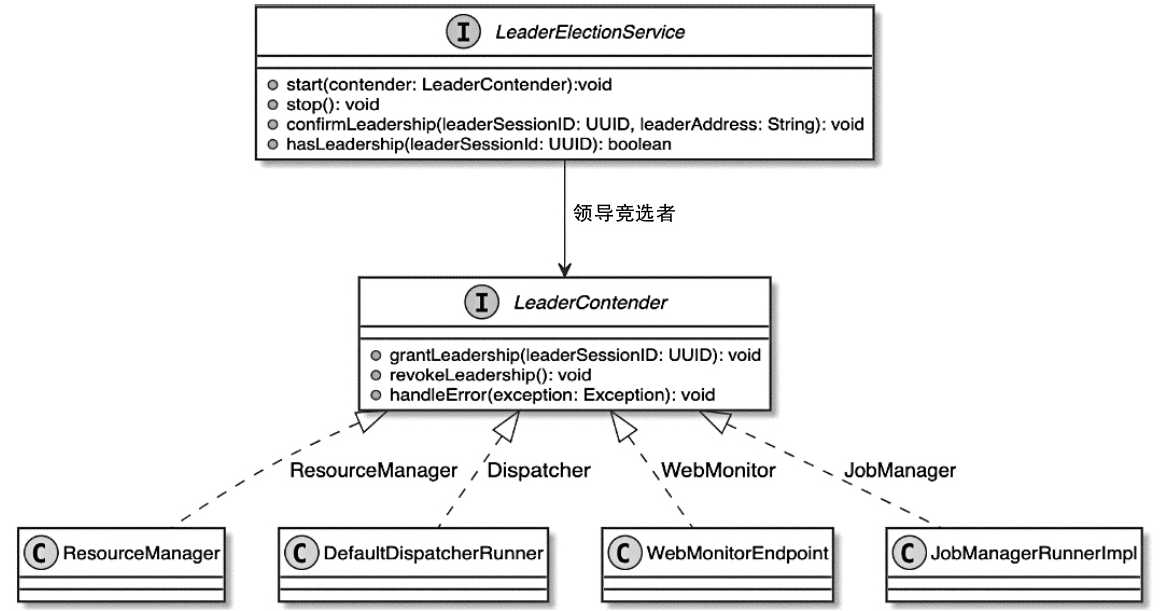
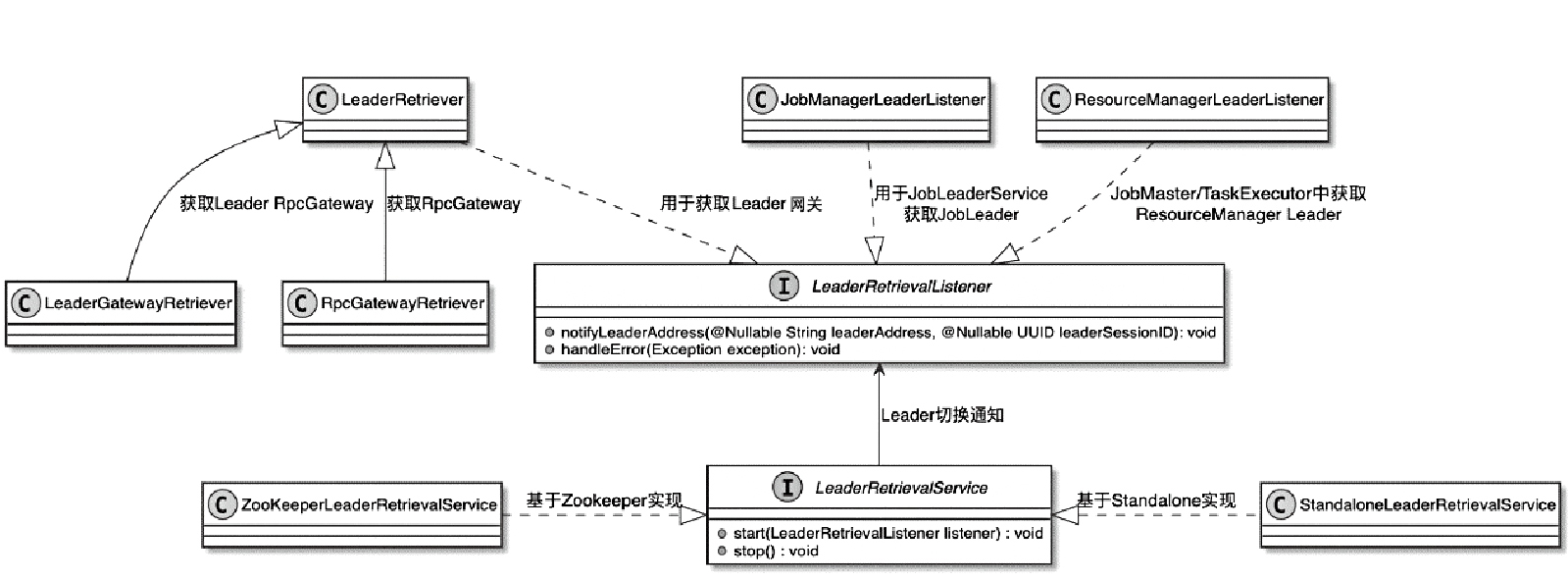
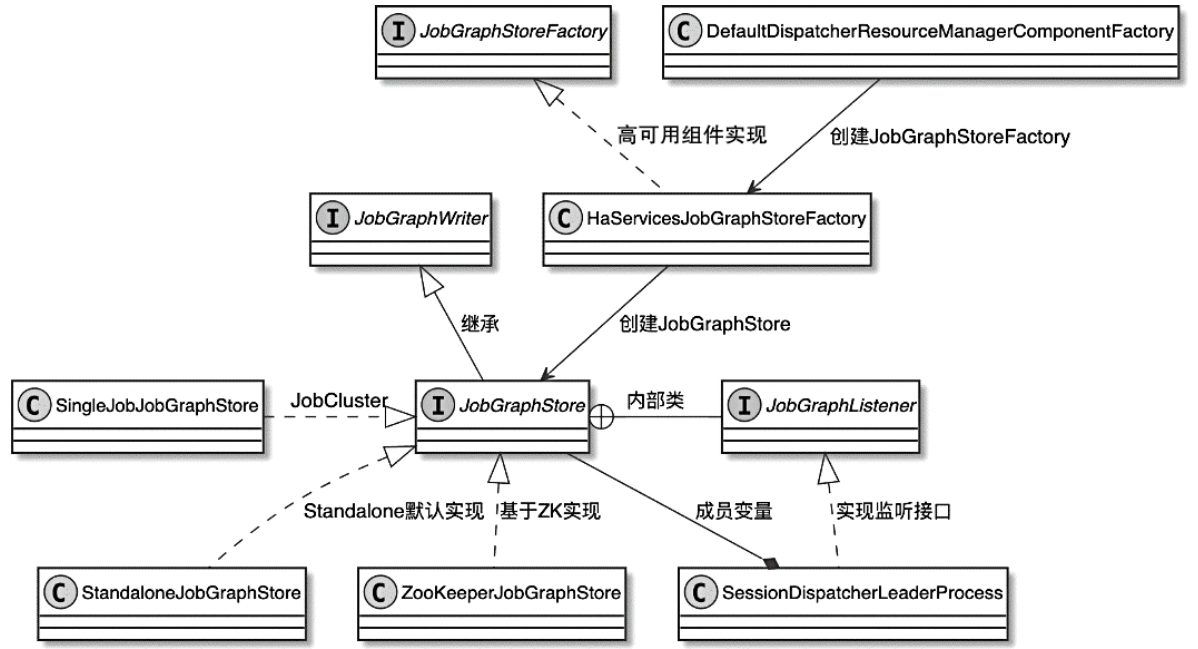
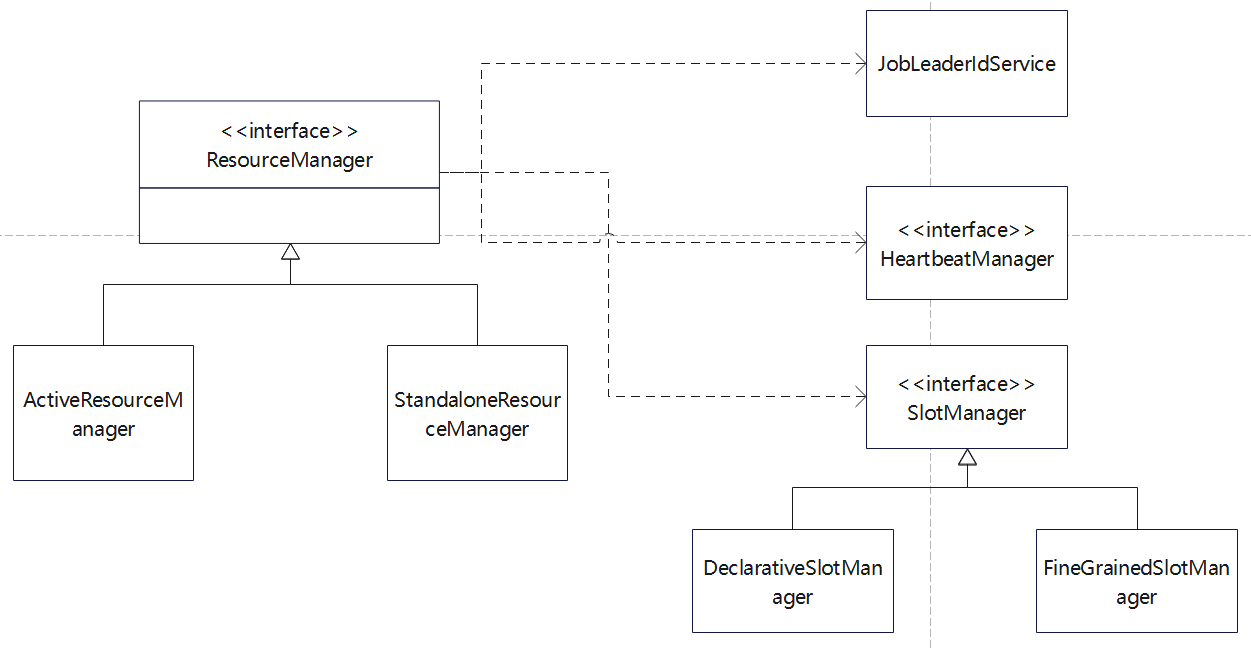
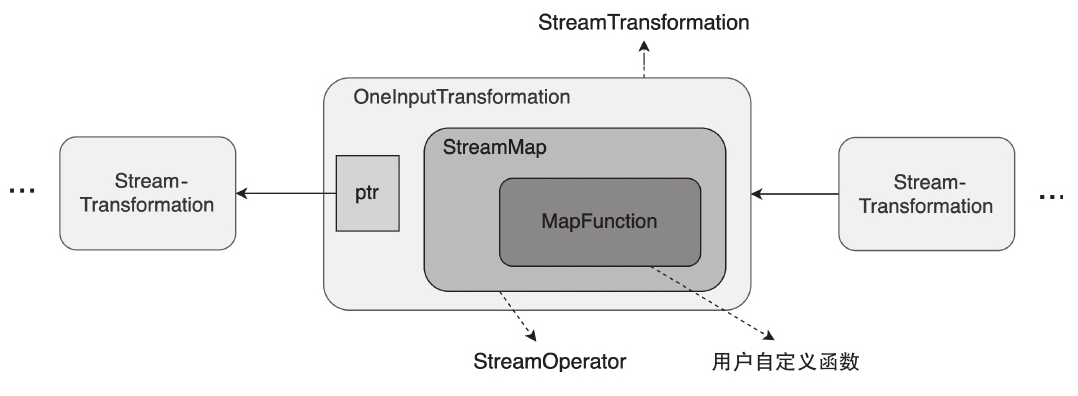
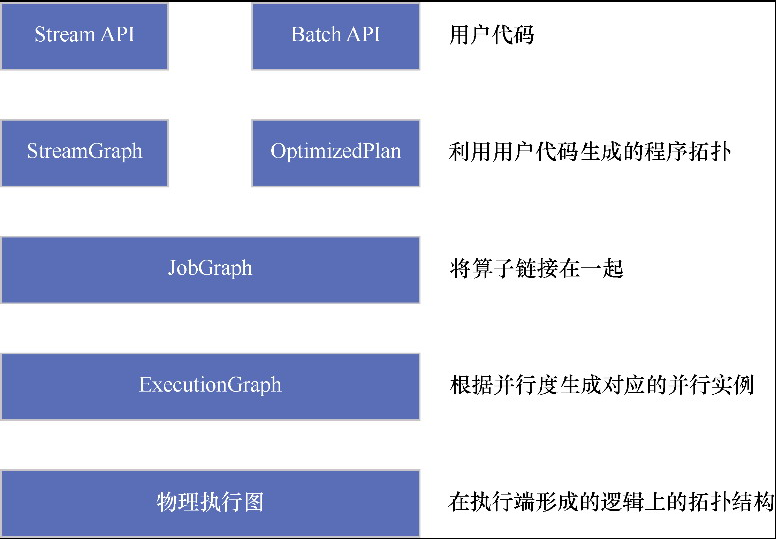
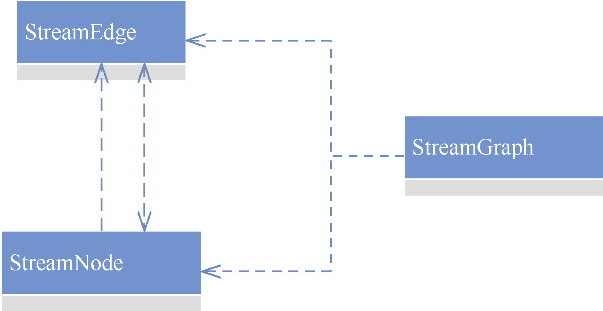
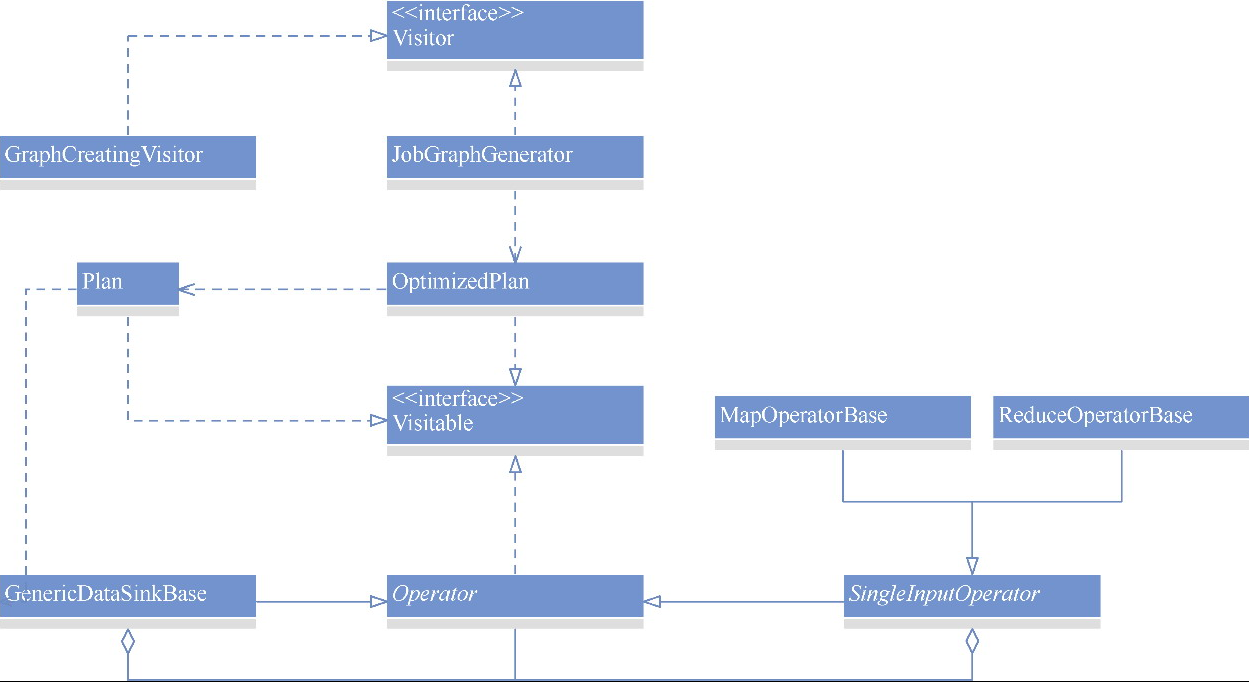
Spark和Flink的对比总结(包含Operator)
把Spark和Flink在计算模型和运维方式上的差异放到一起看,重点包括:
- 先看 Spark 处理流 与 Flink 处理批 的天然短板,理解为什么 Spark 更偏微批、Flink 更偏实时,而不是简单说谁“全能”
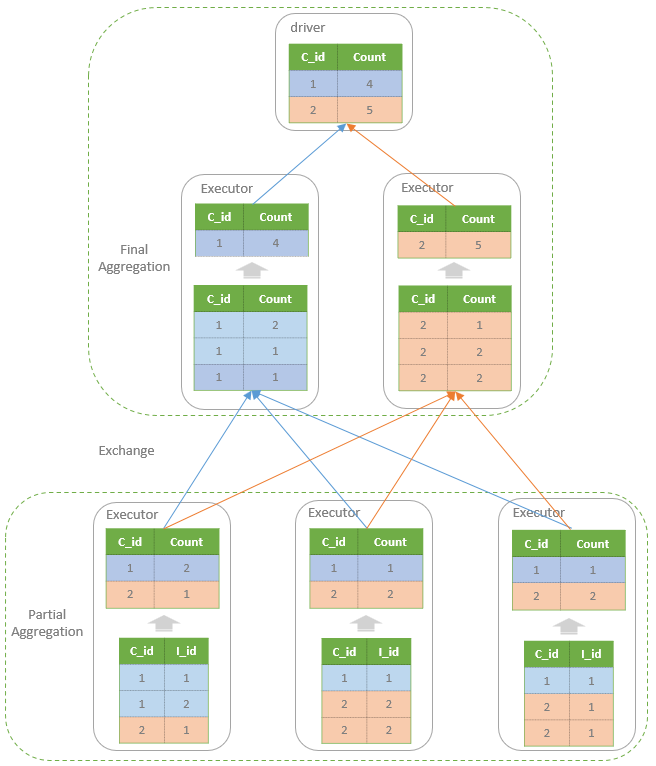
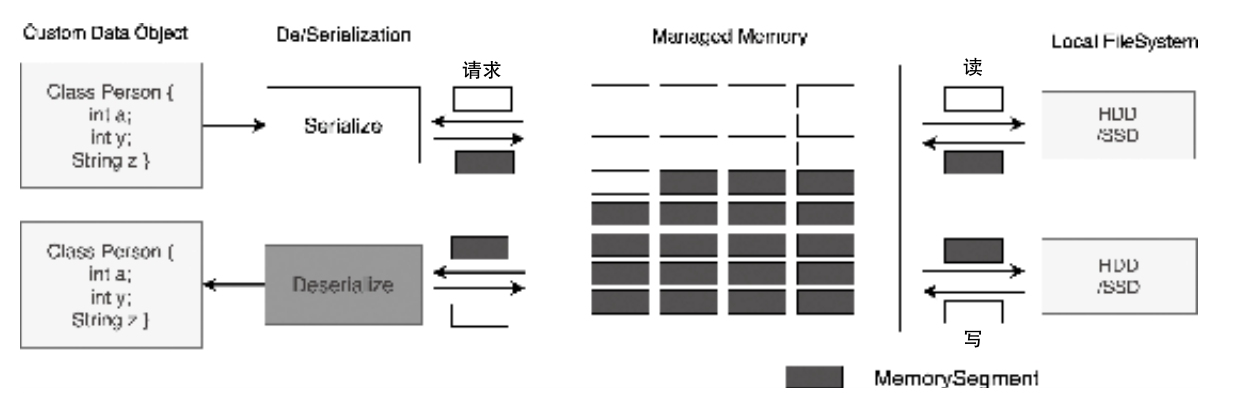
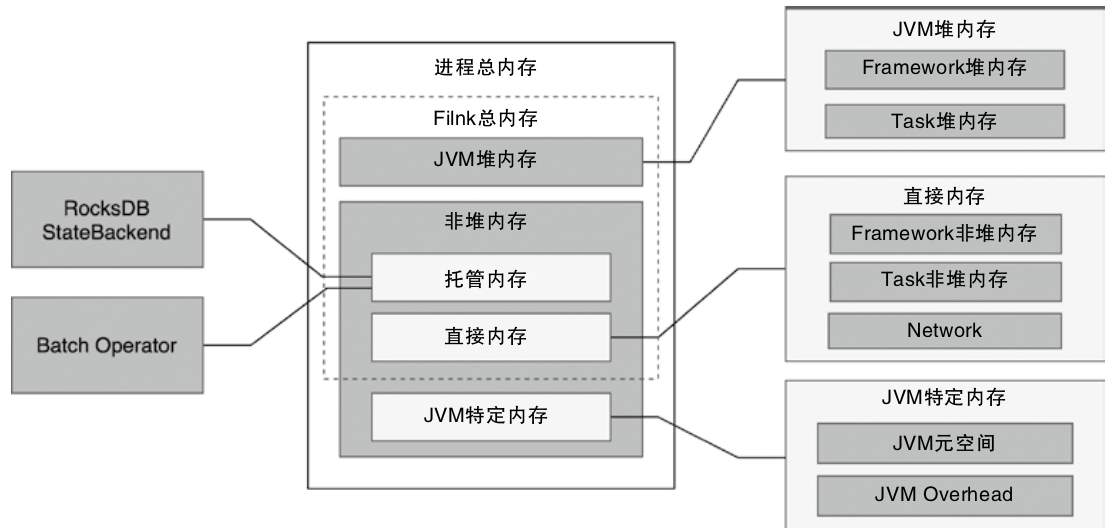
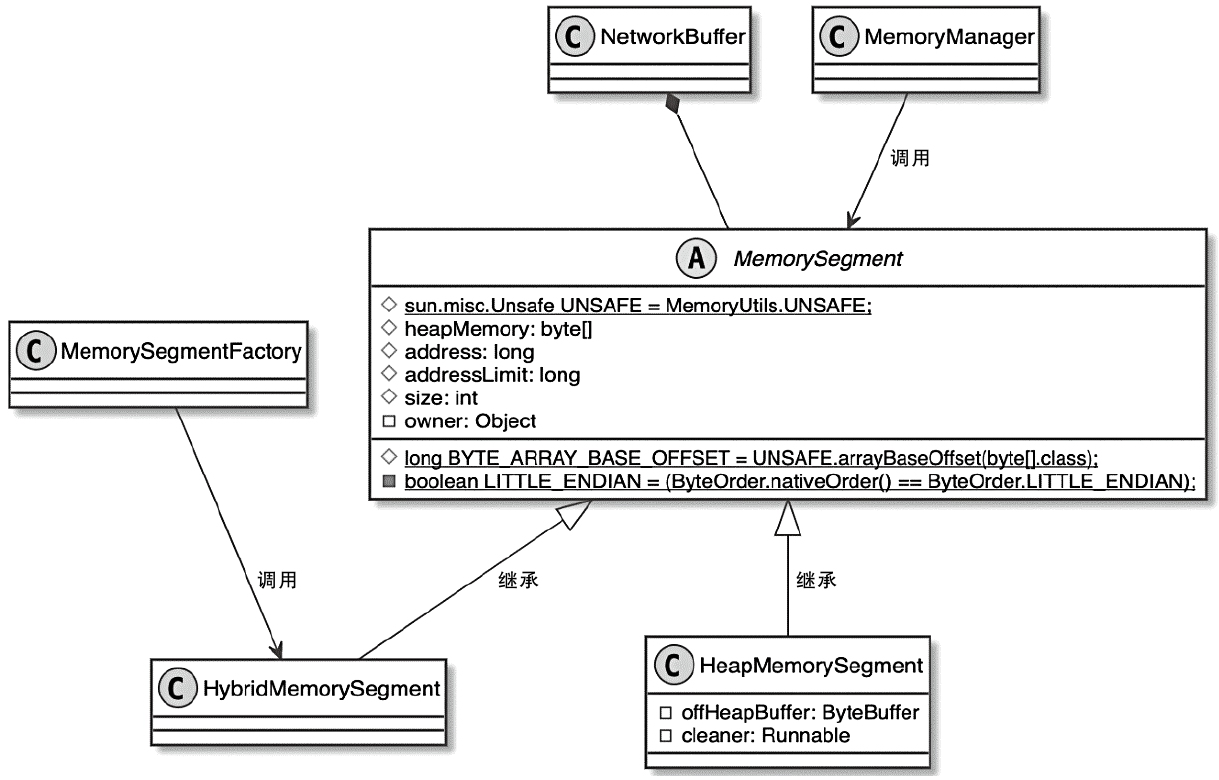
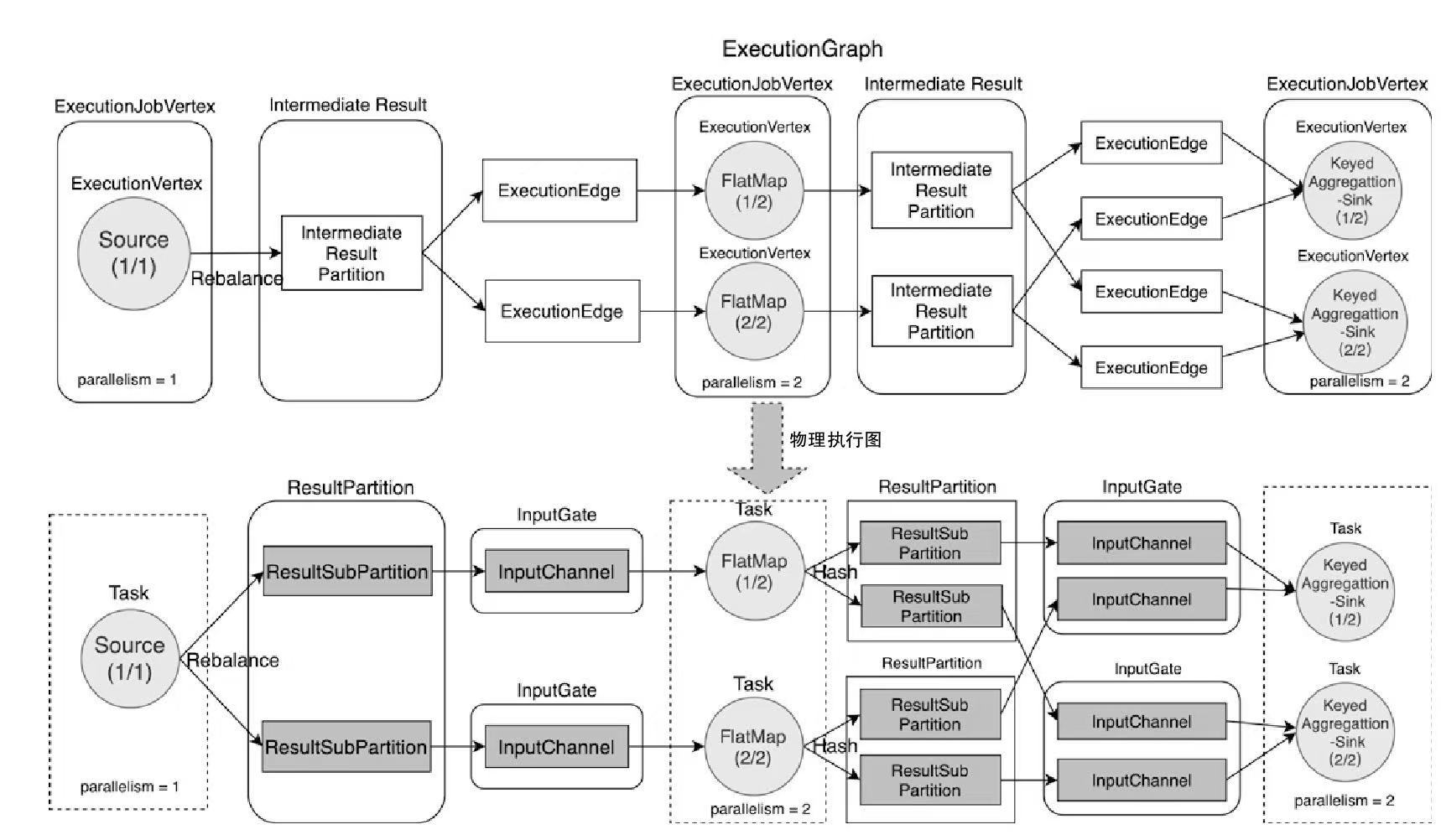
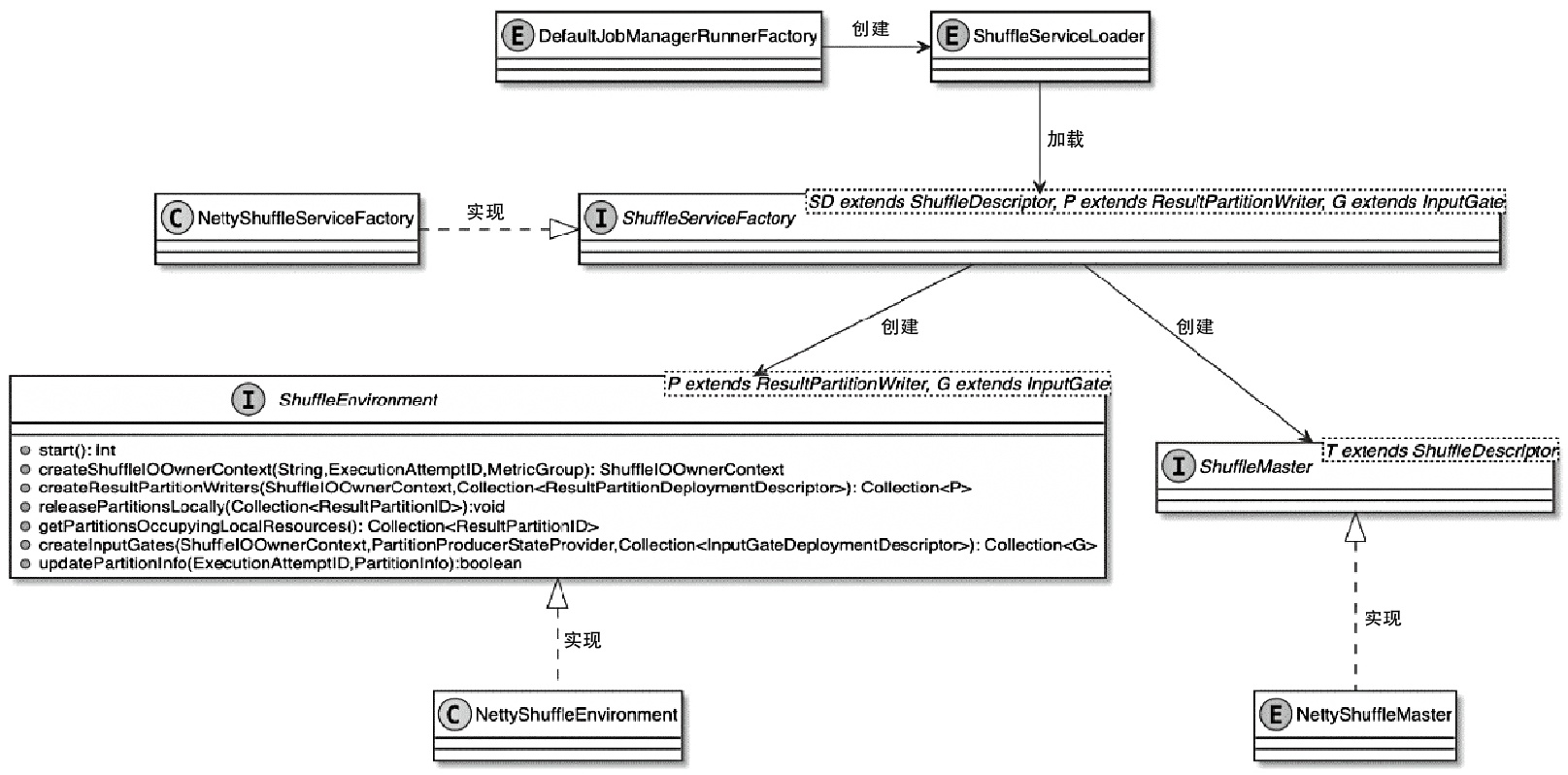
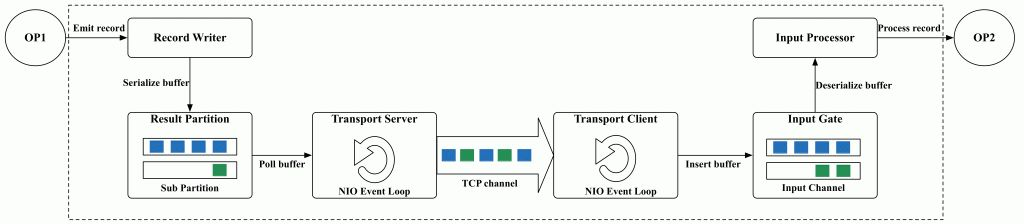
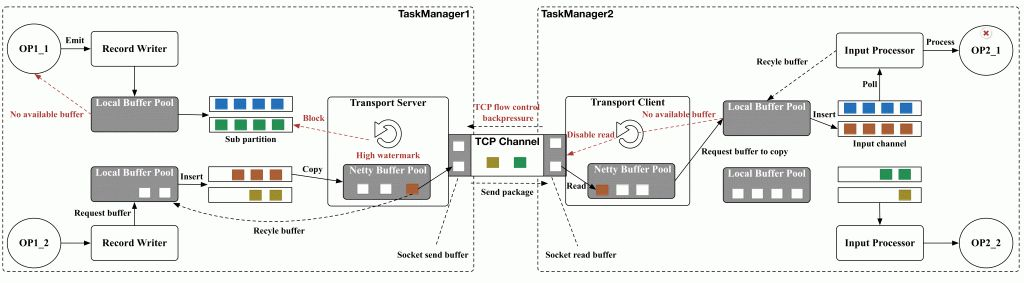
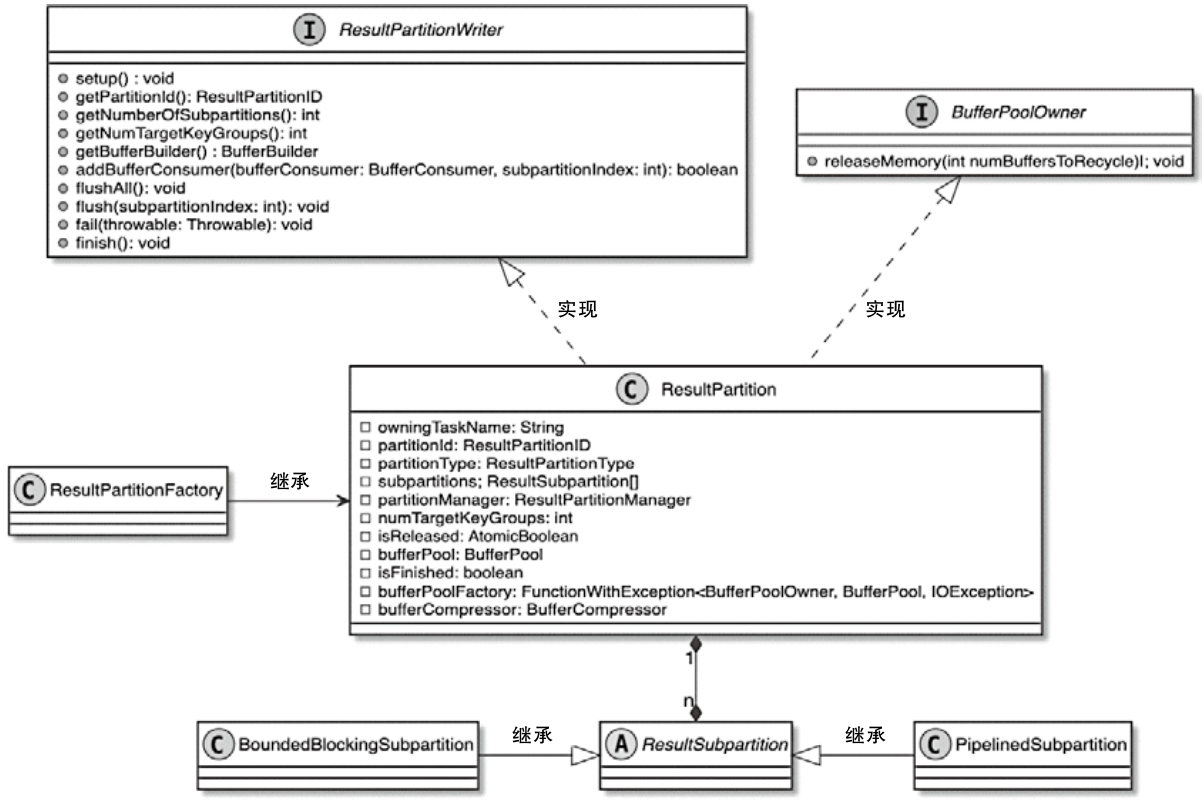
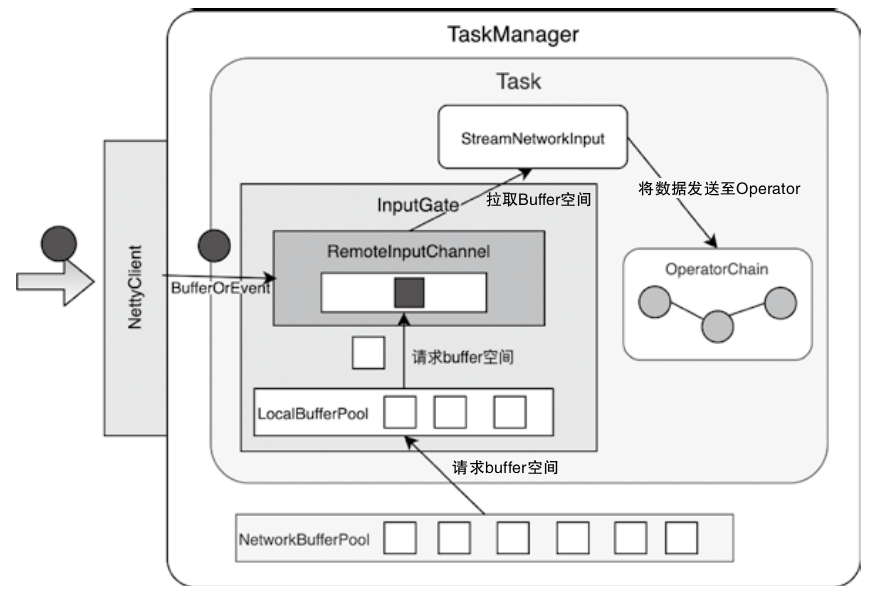
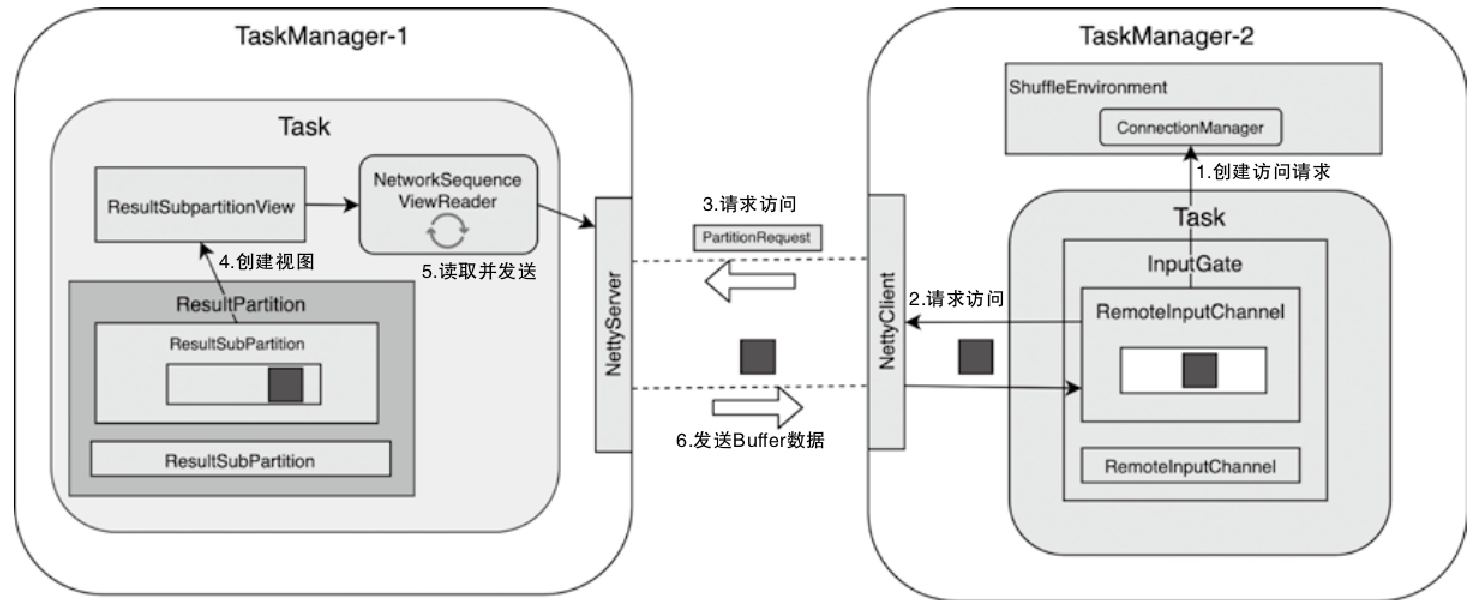
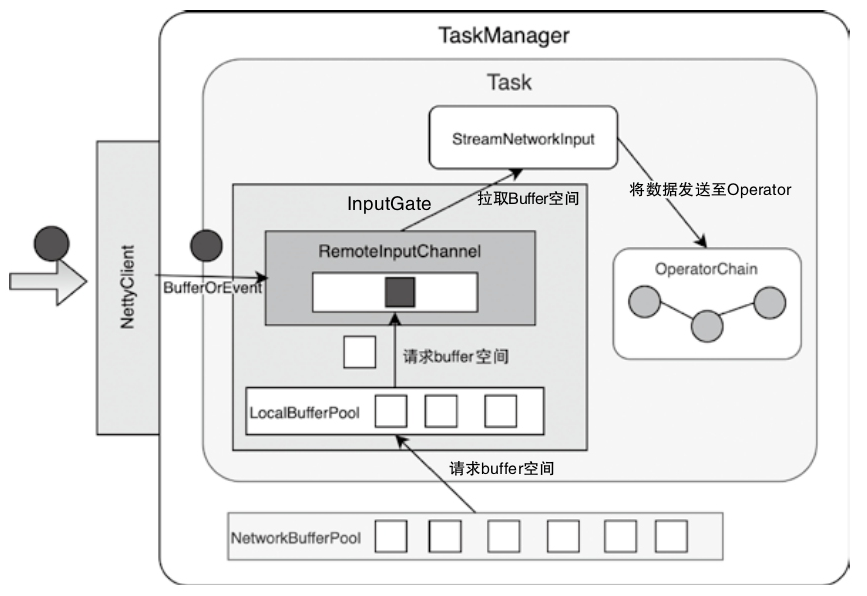
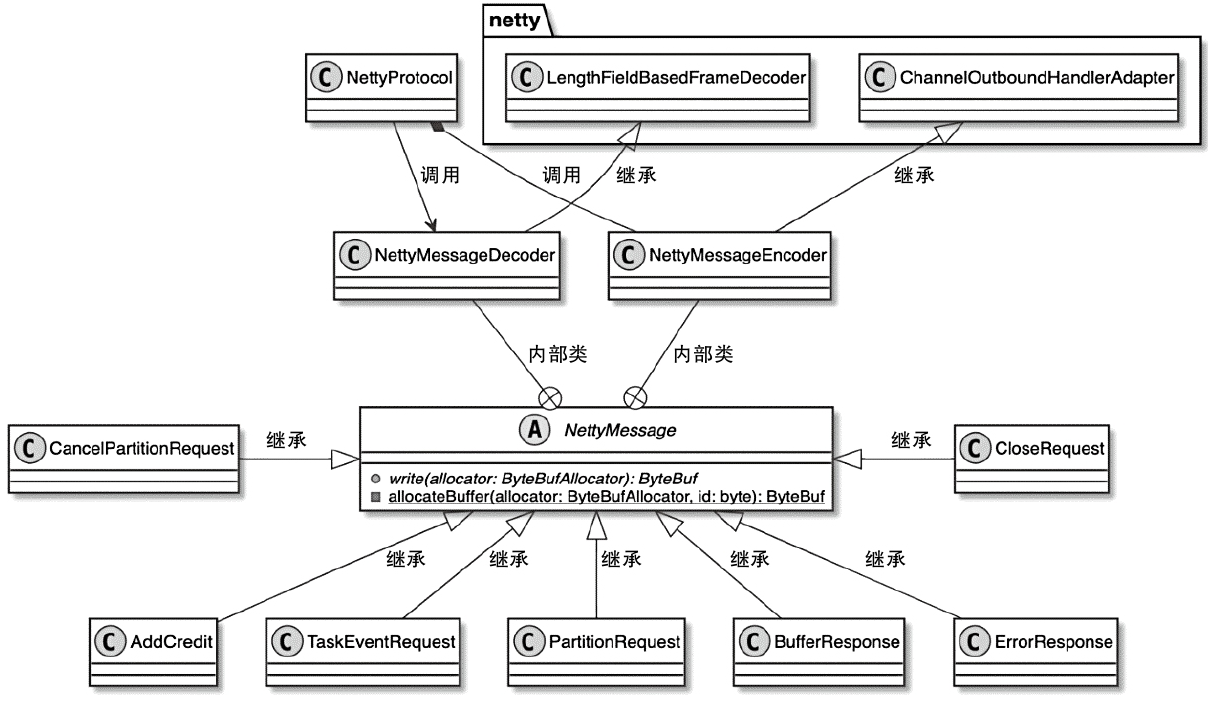
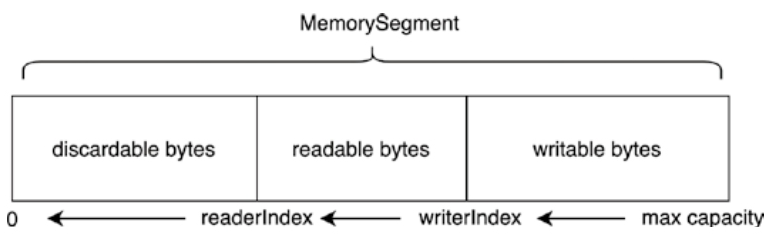
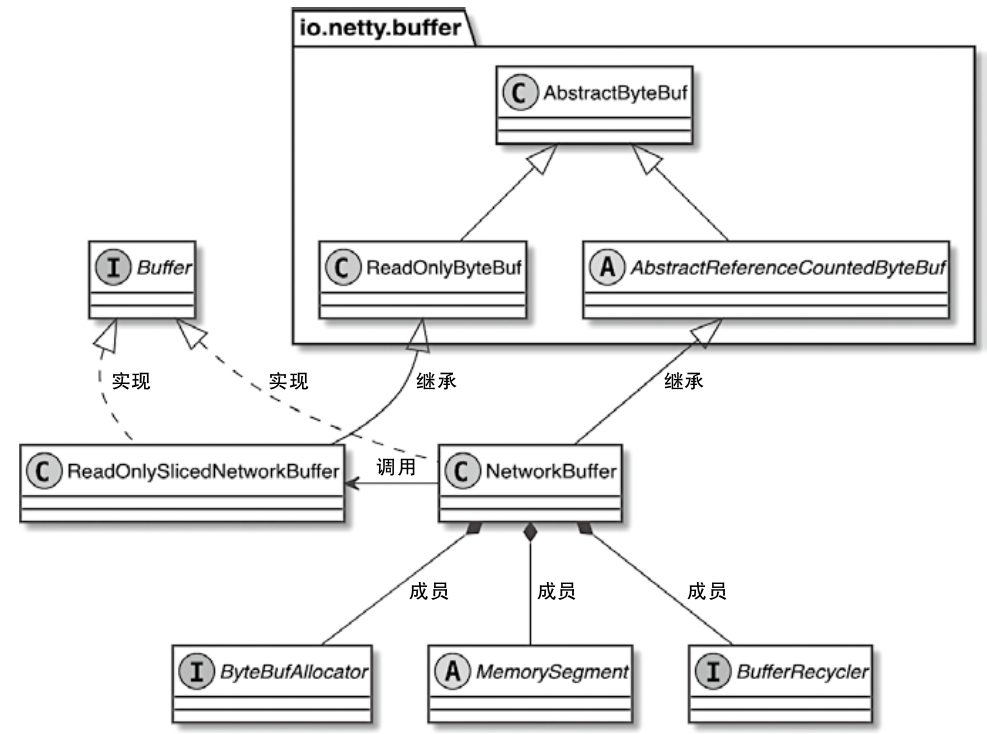
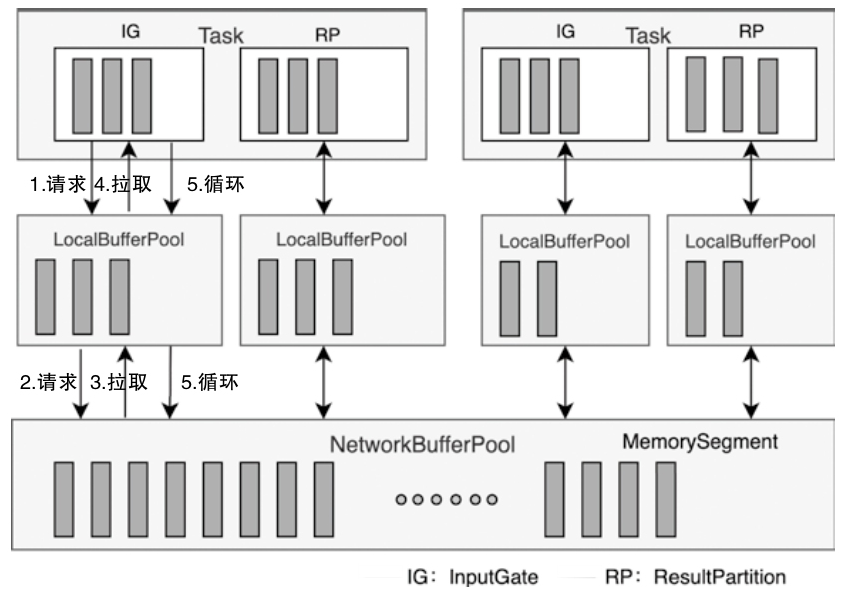
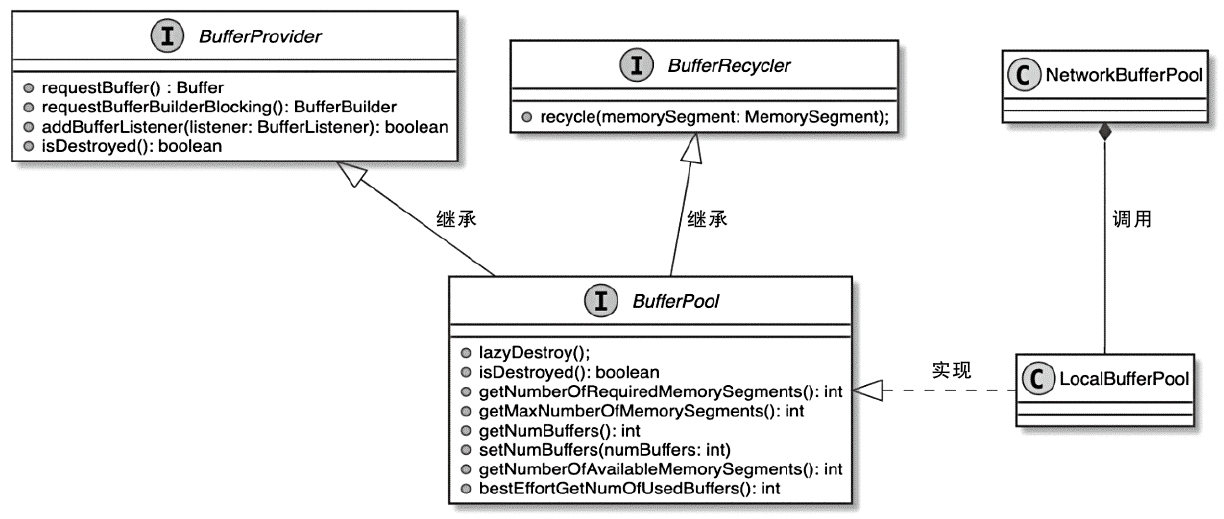
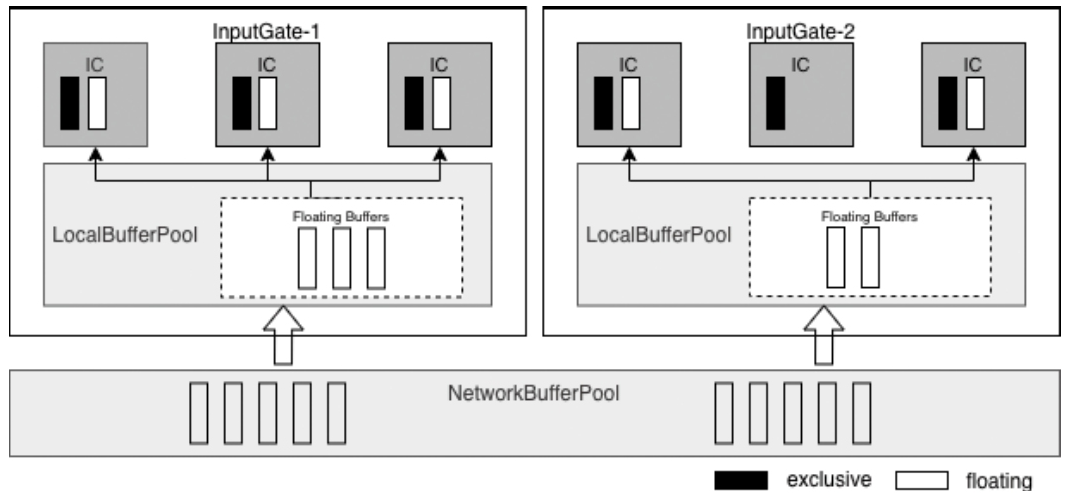
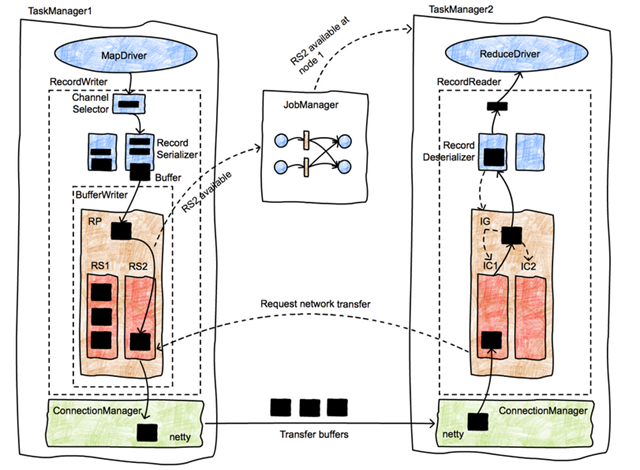
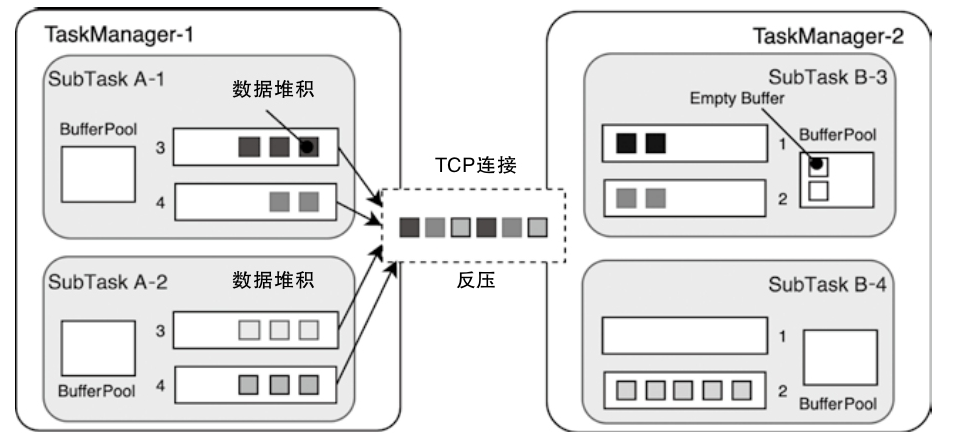
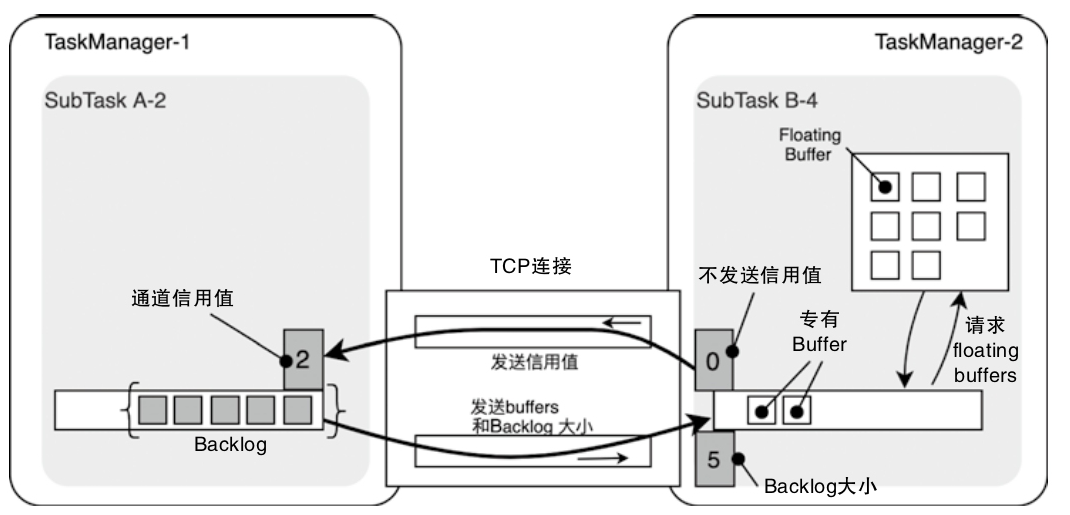
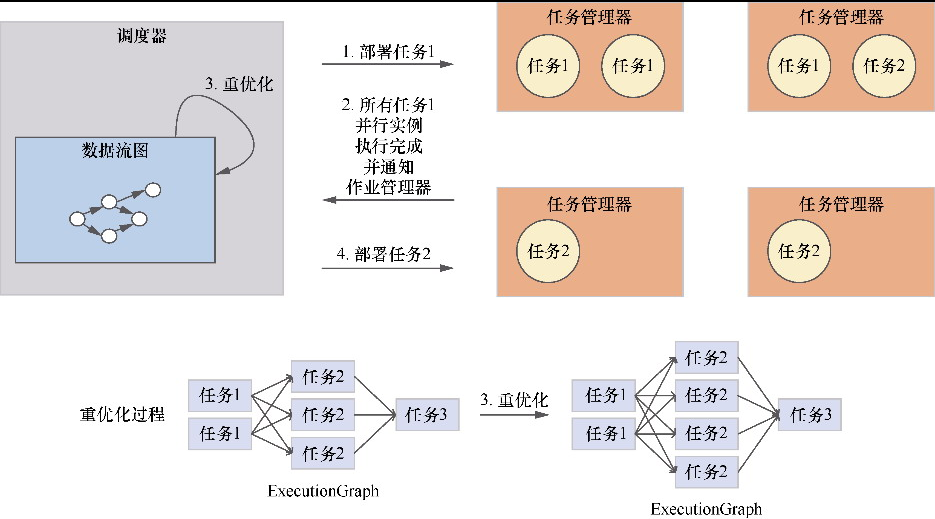
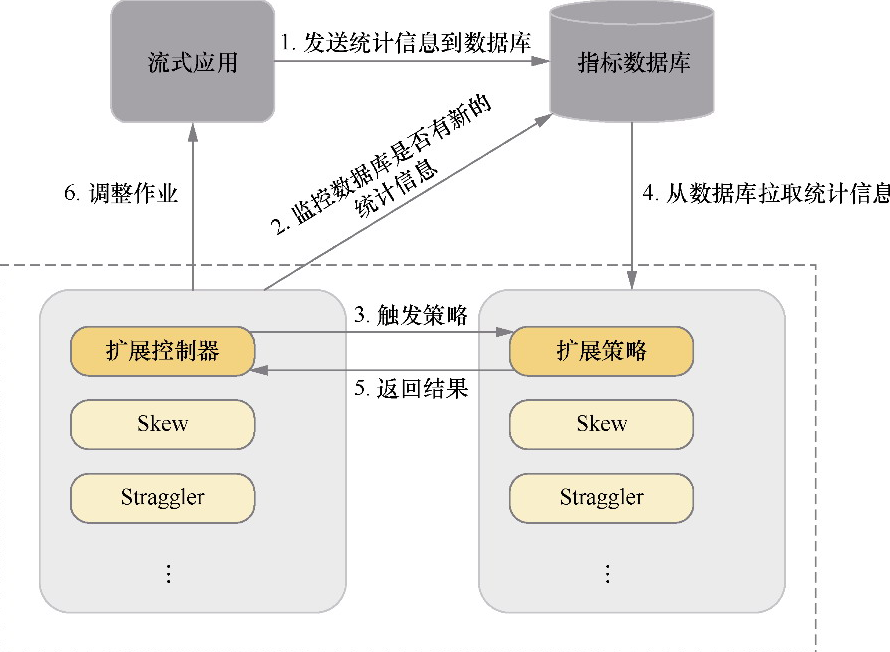
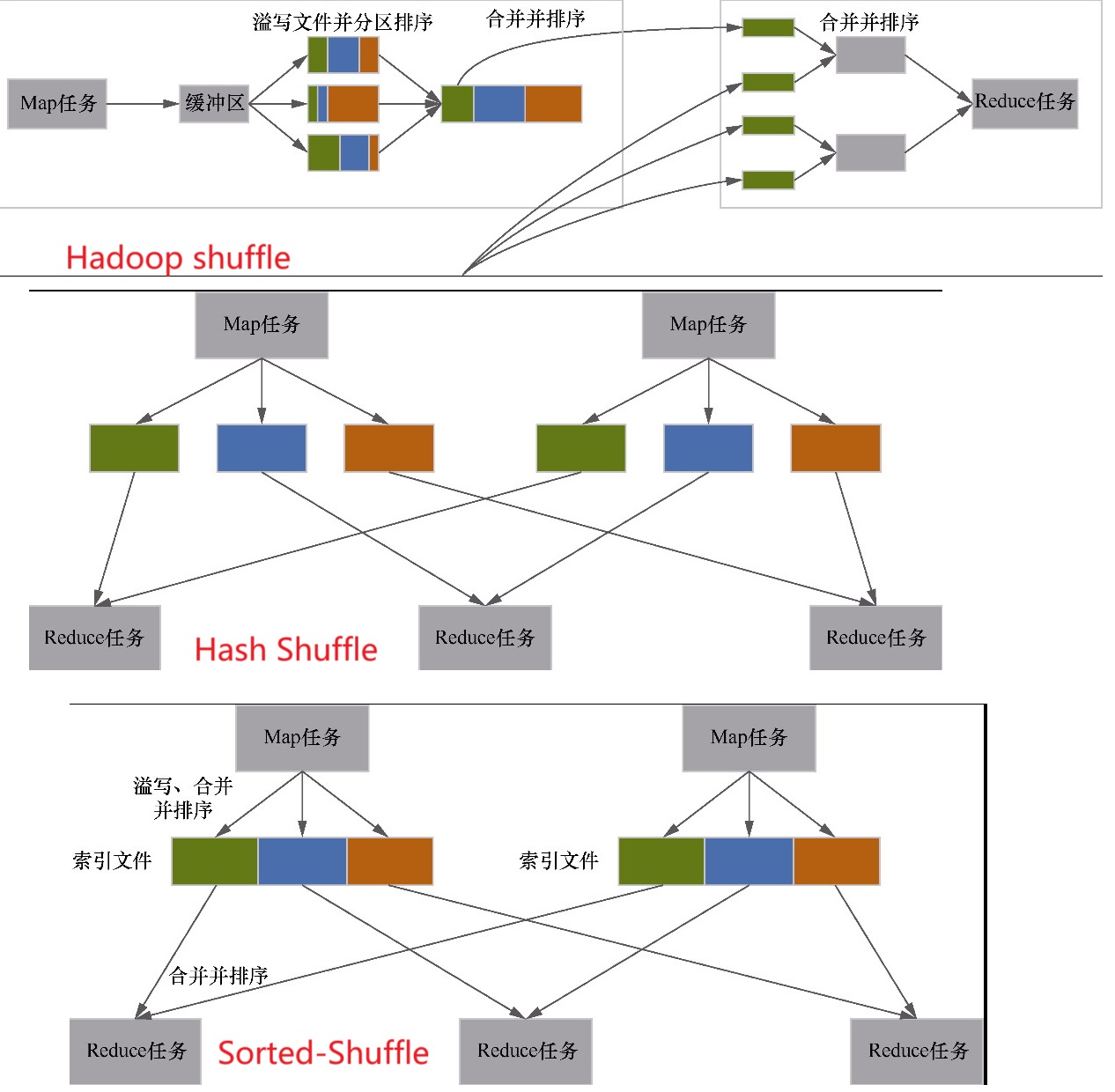
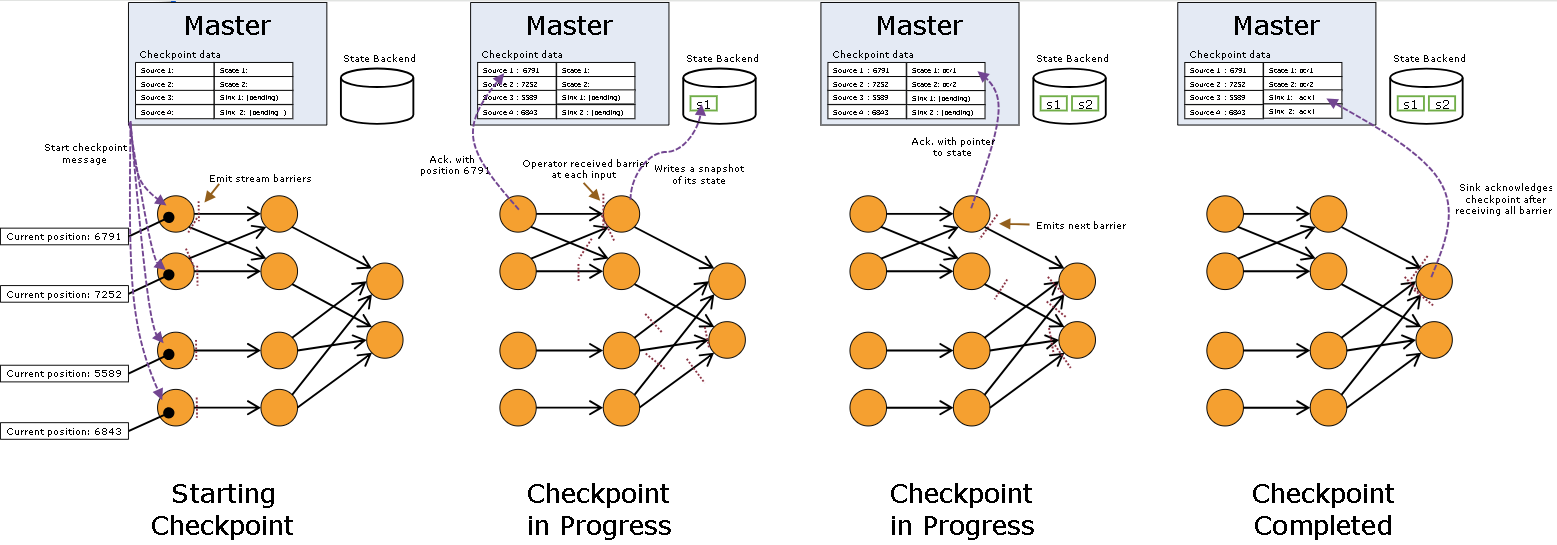
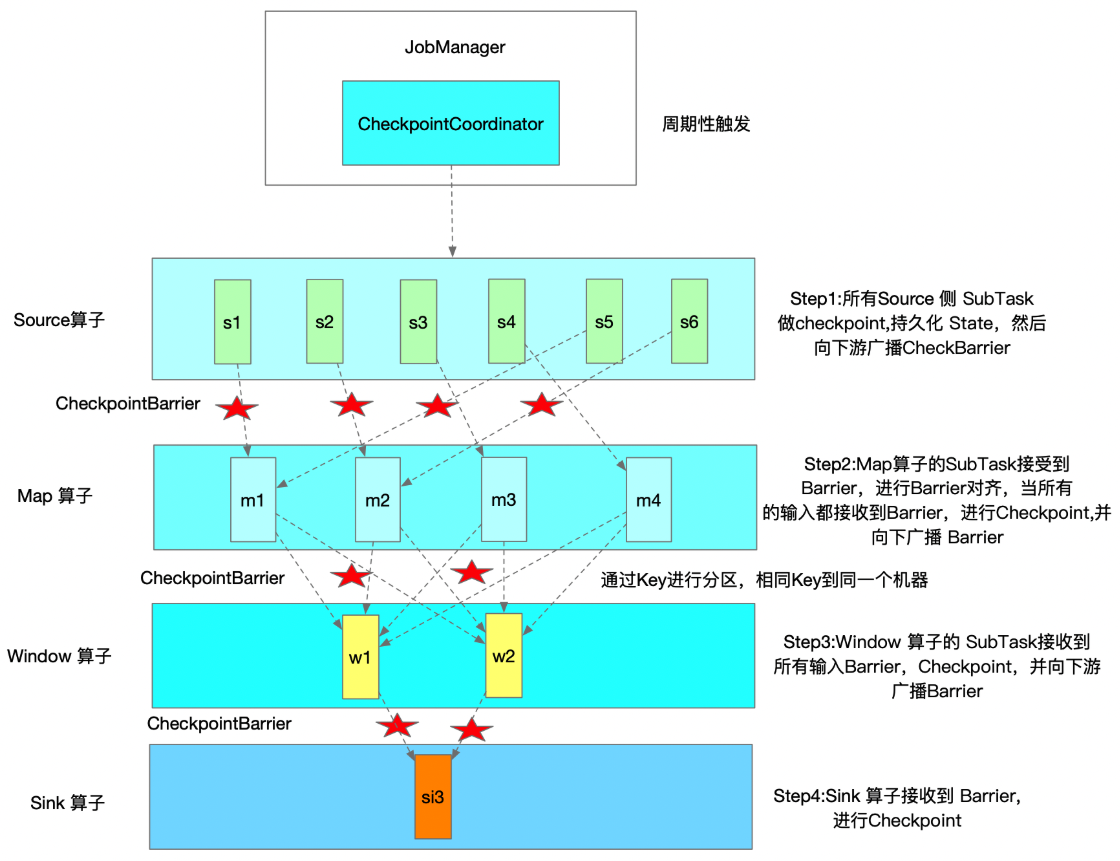
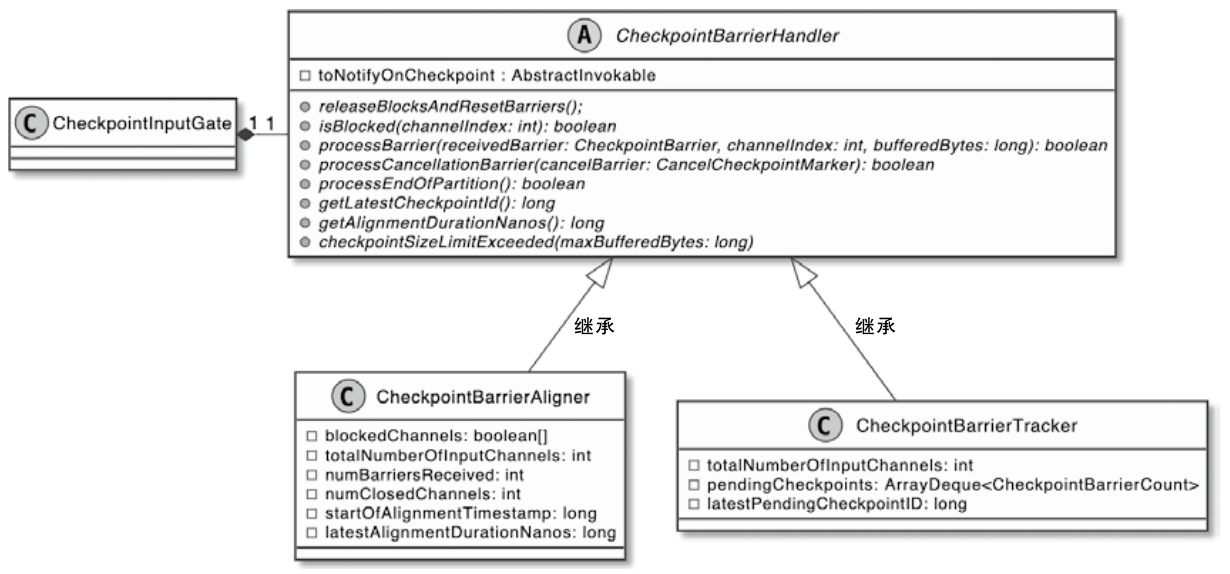
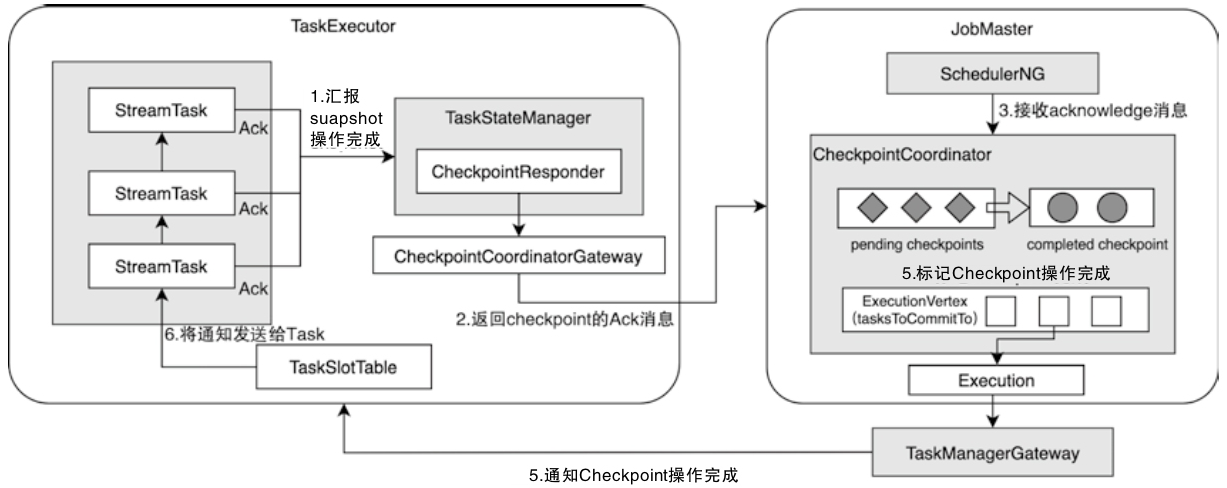
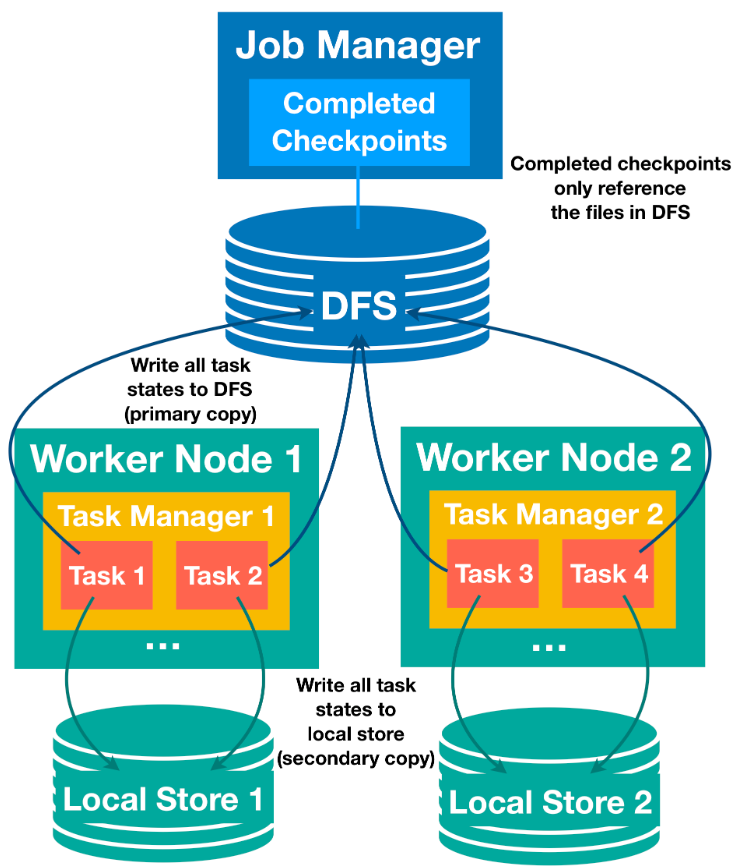
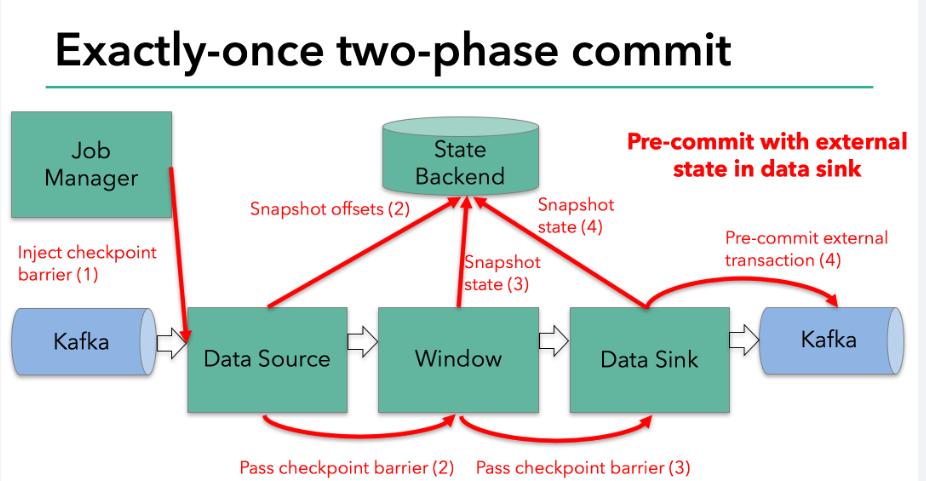
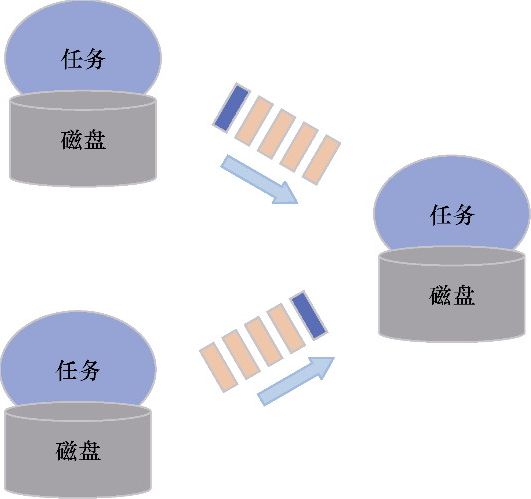
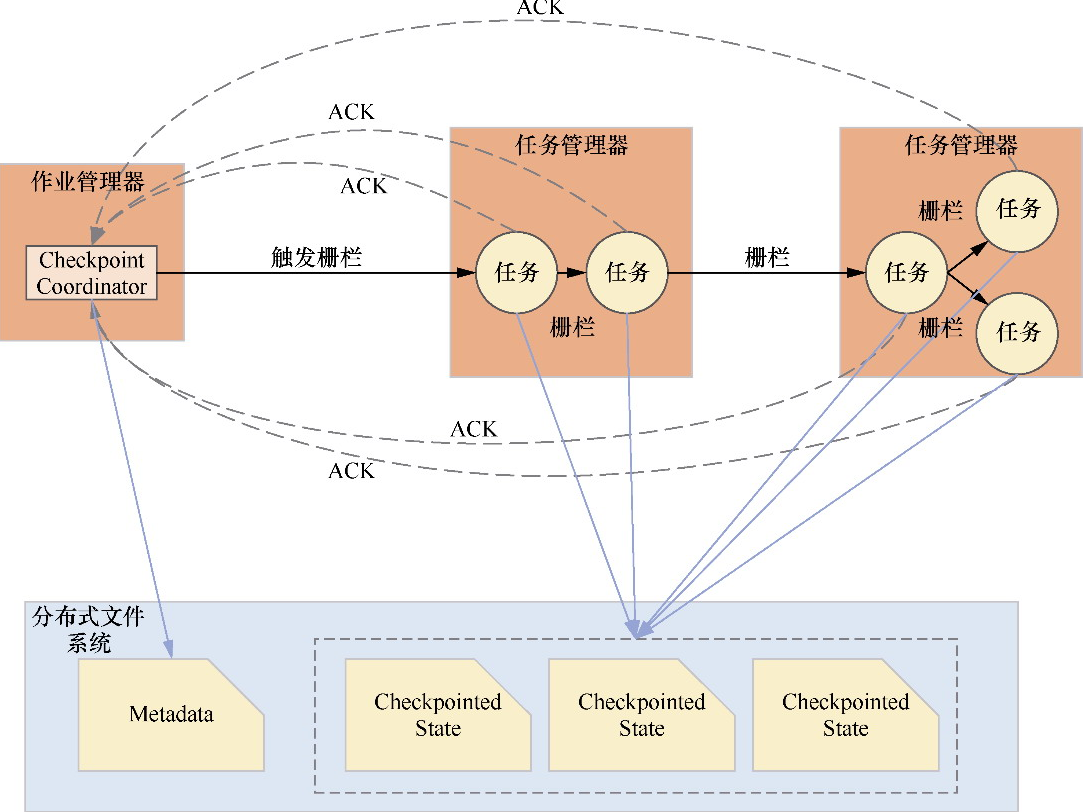
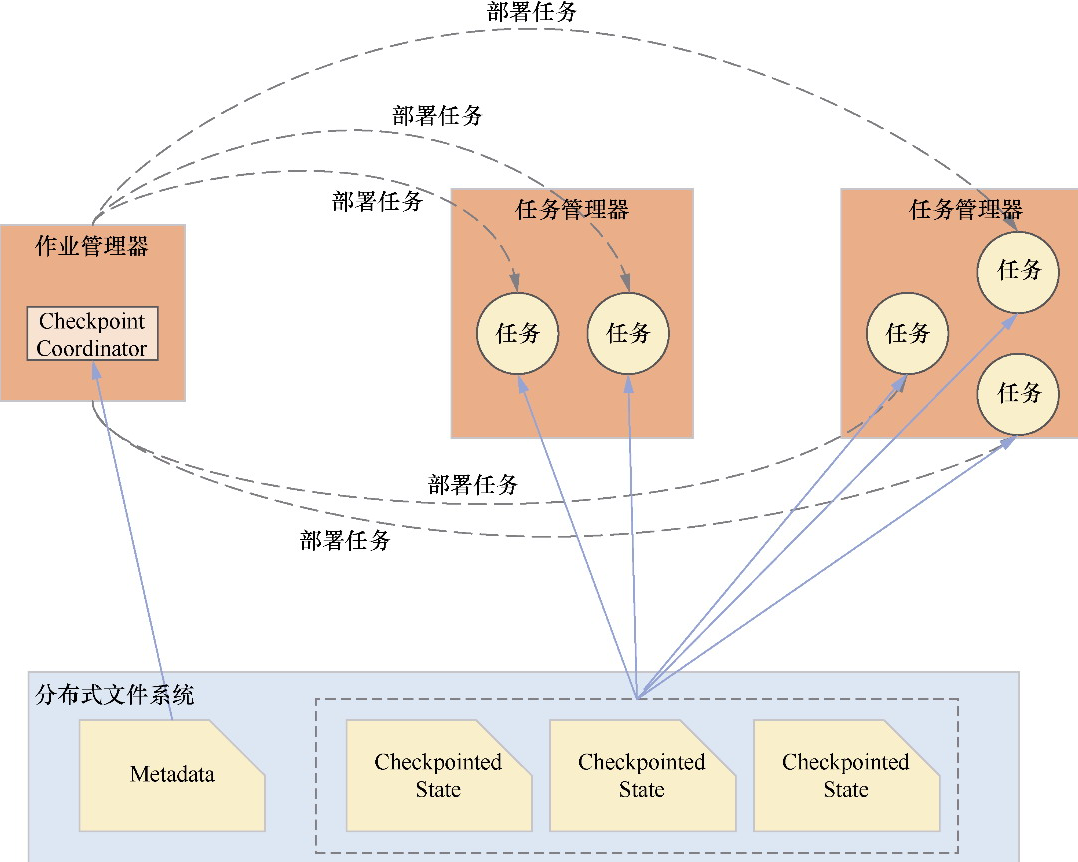
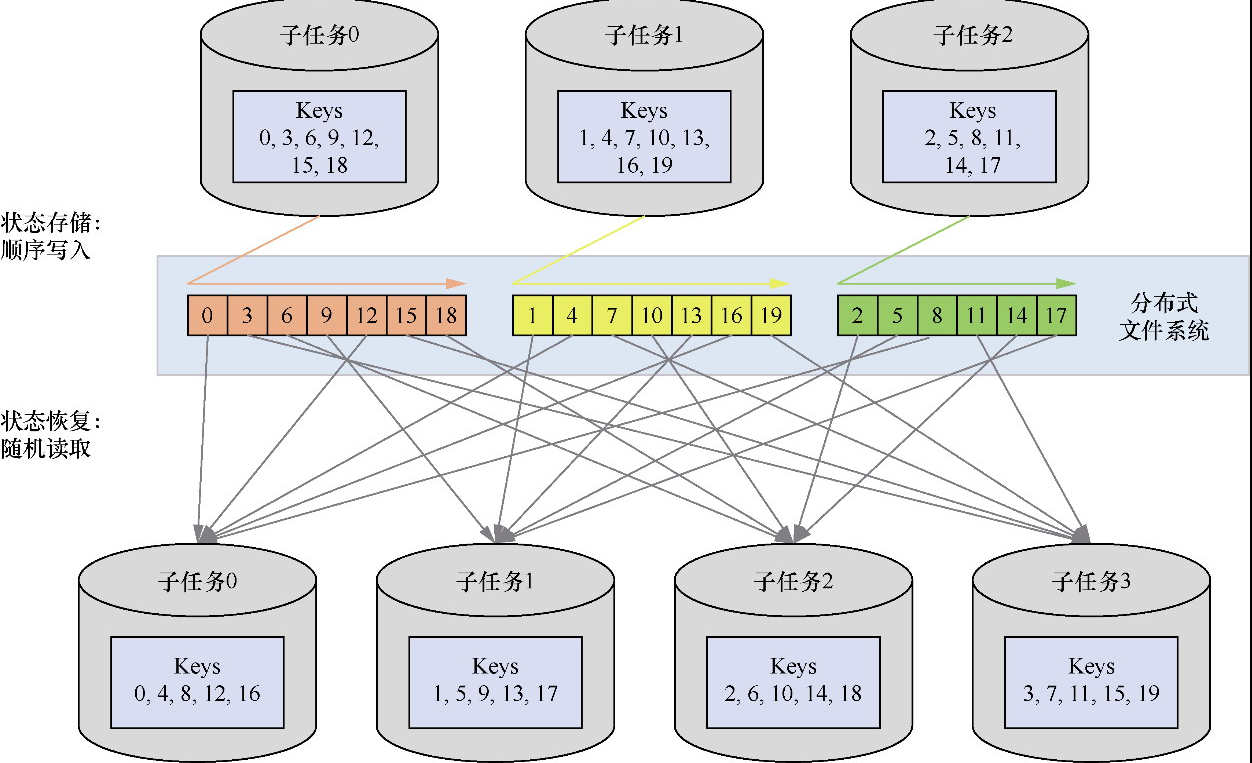
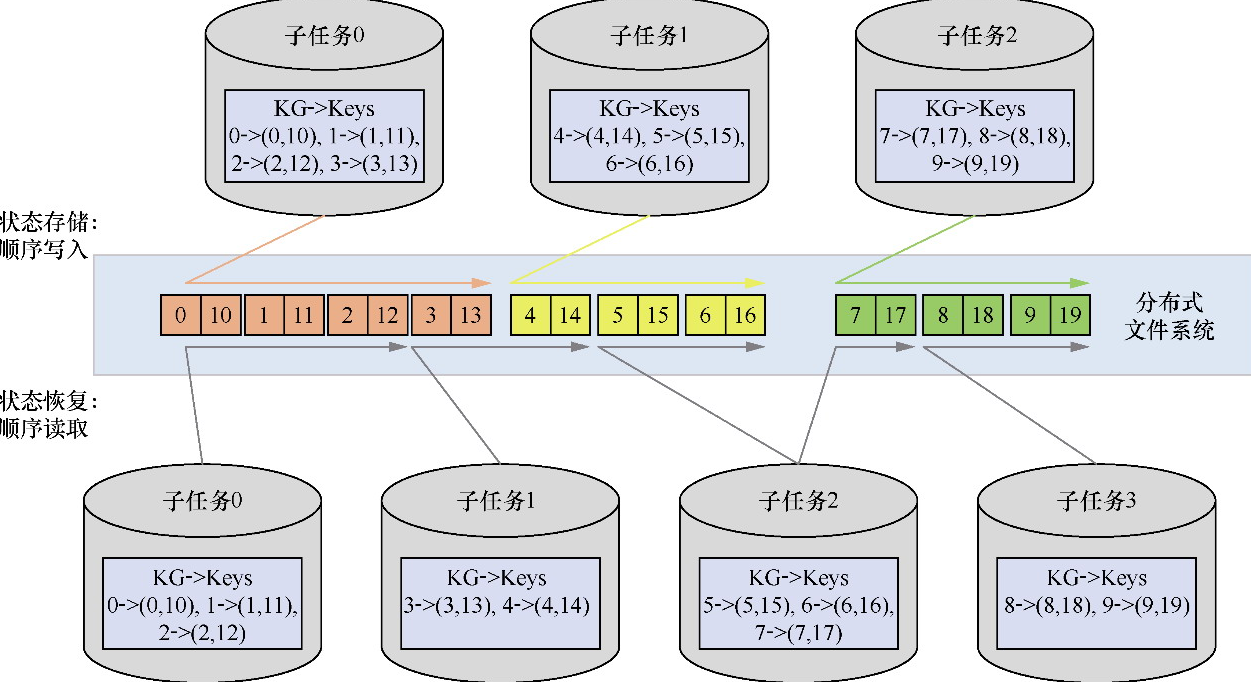
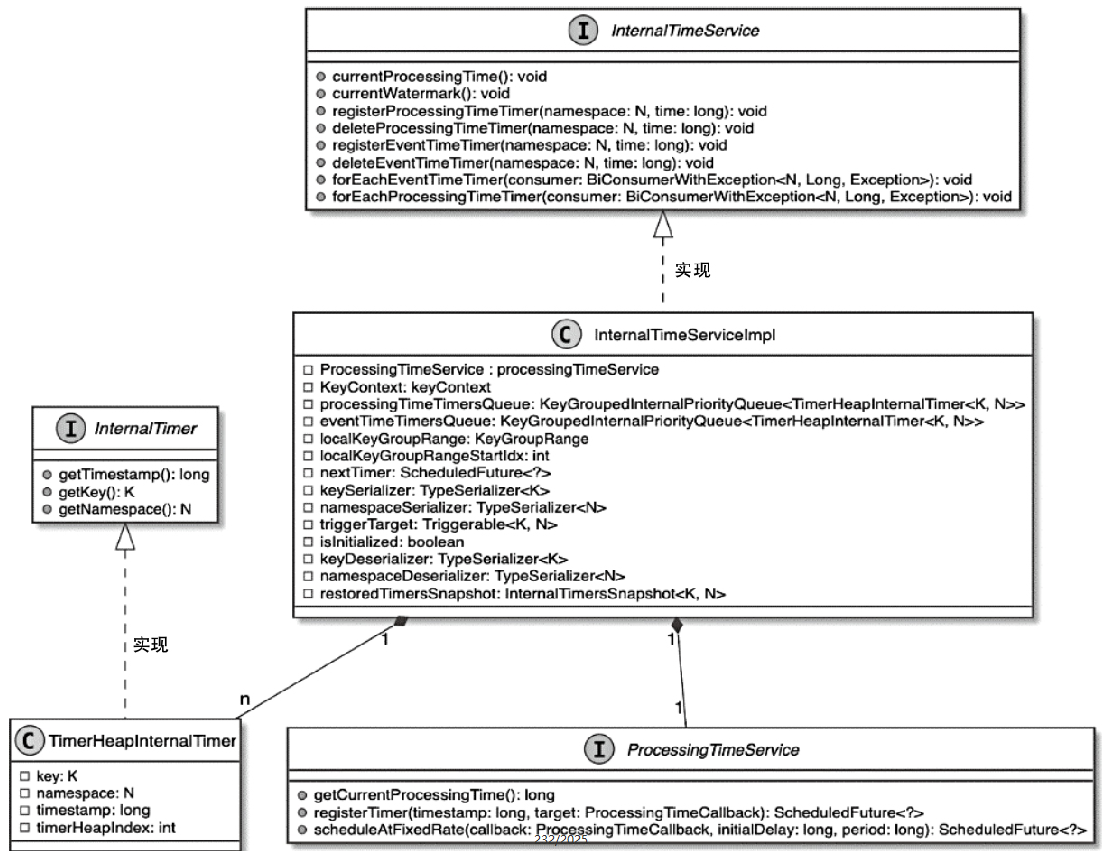
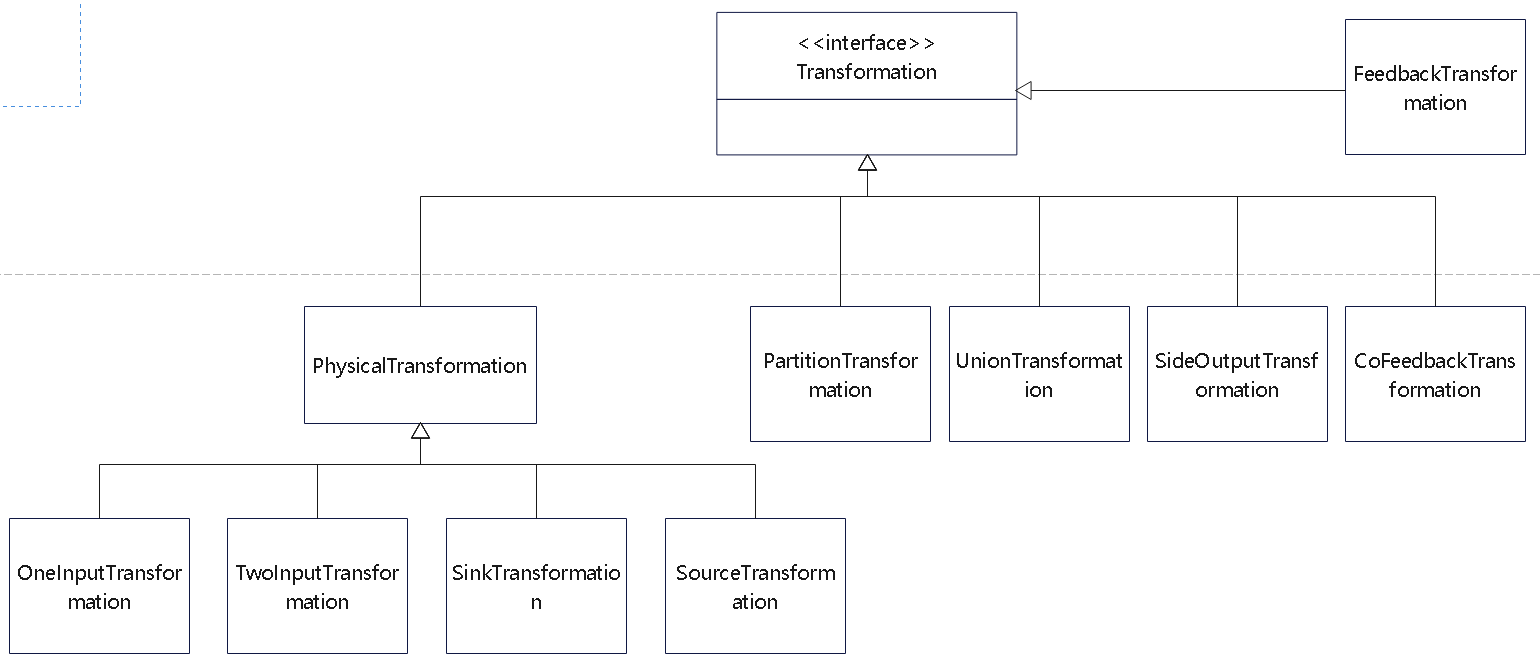
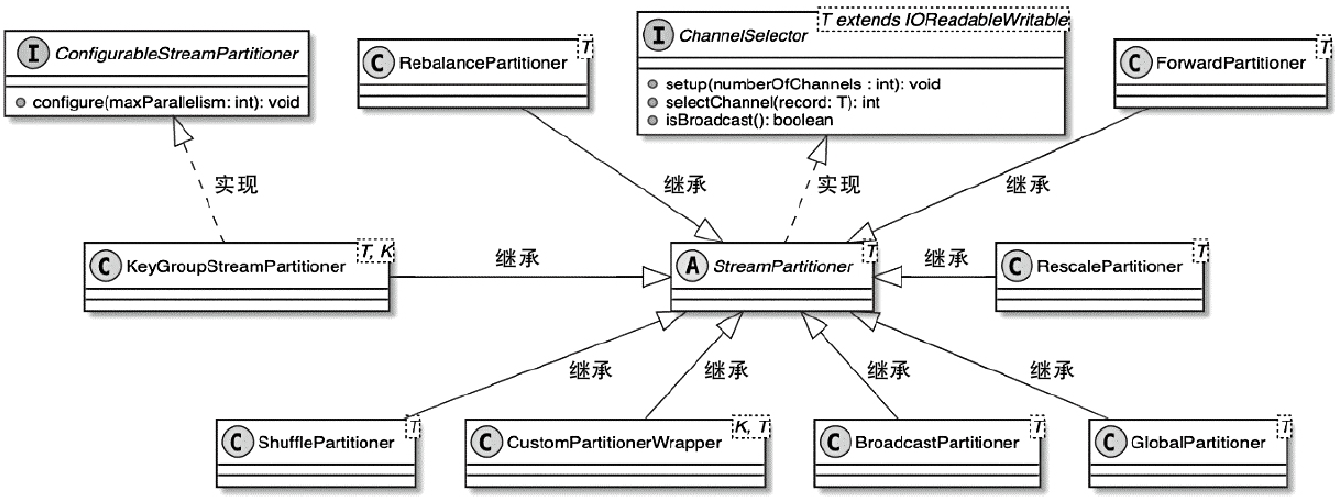
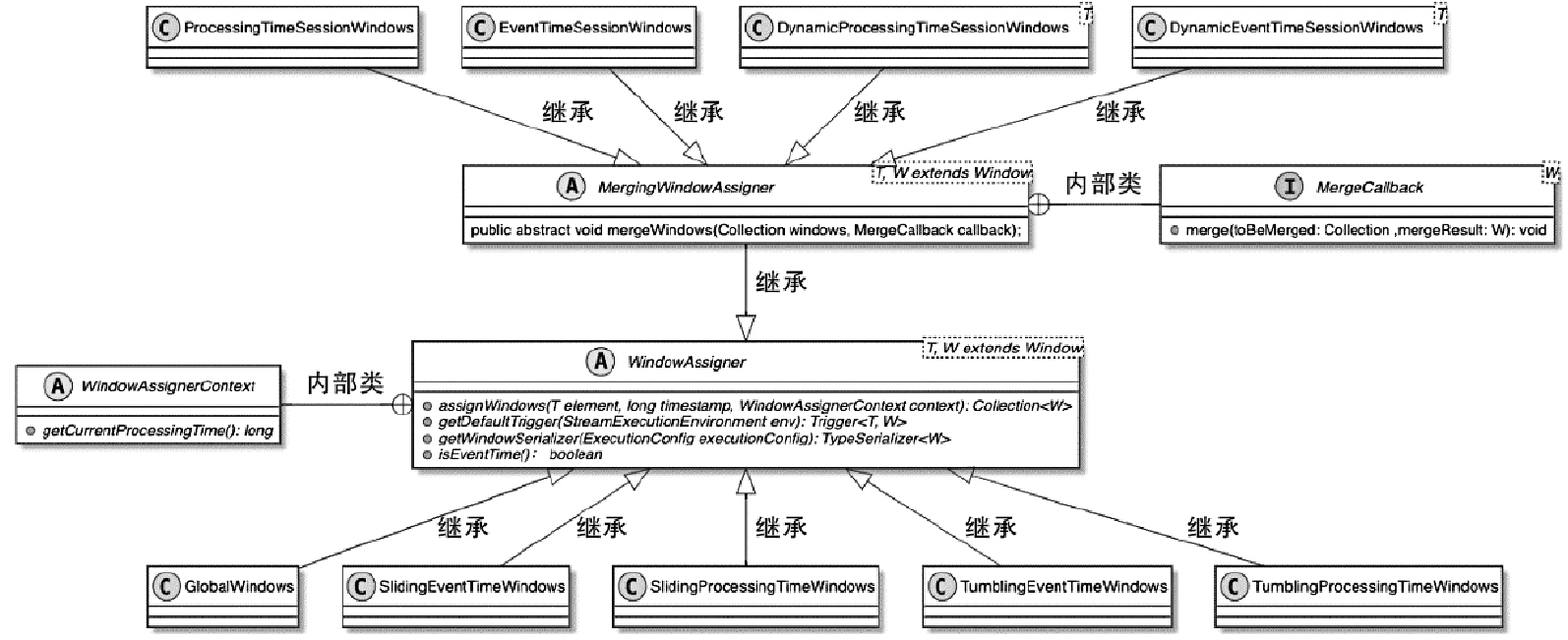
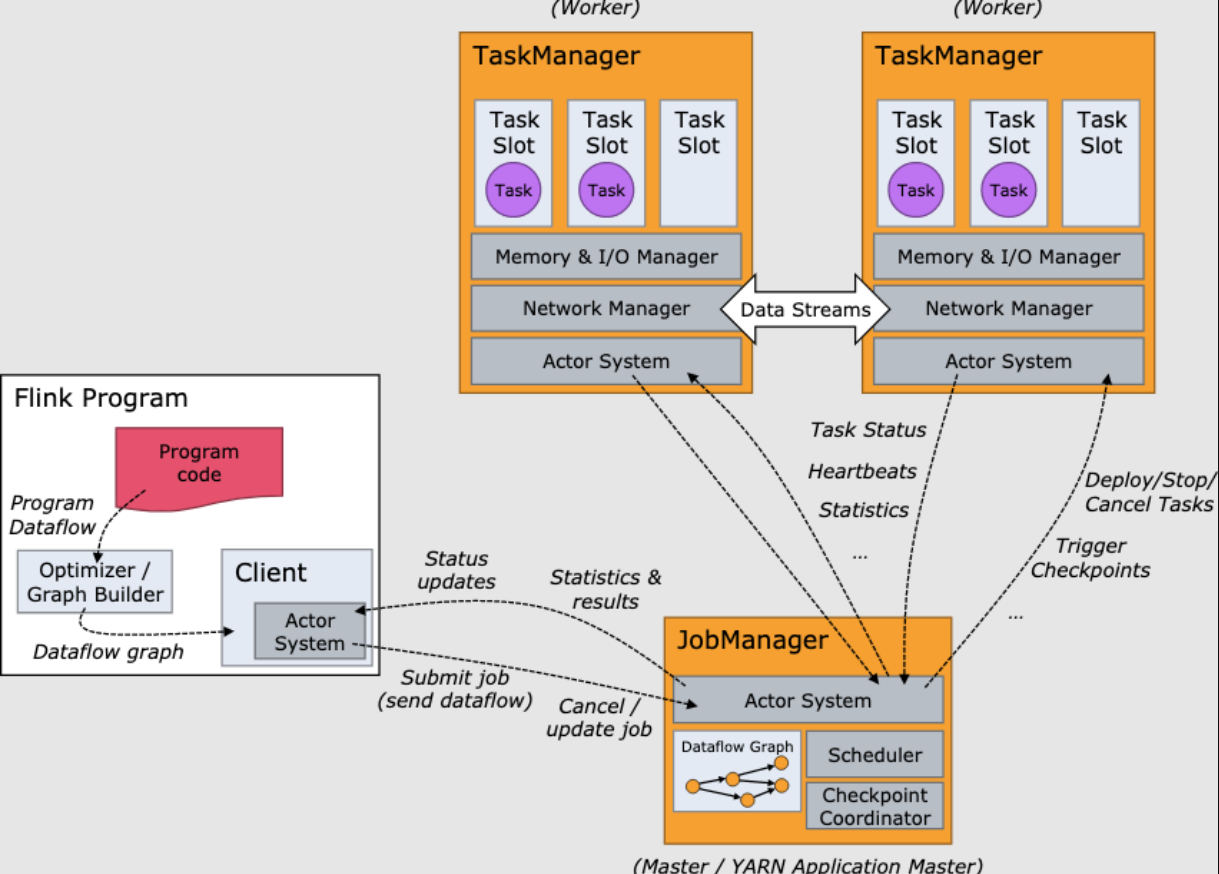
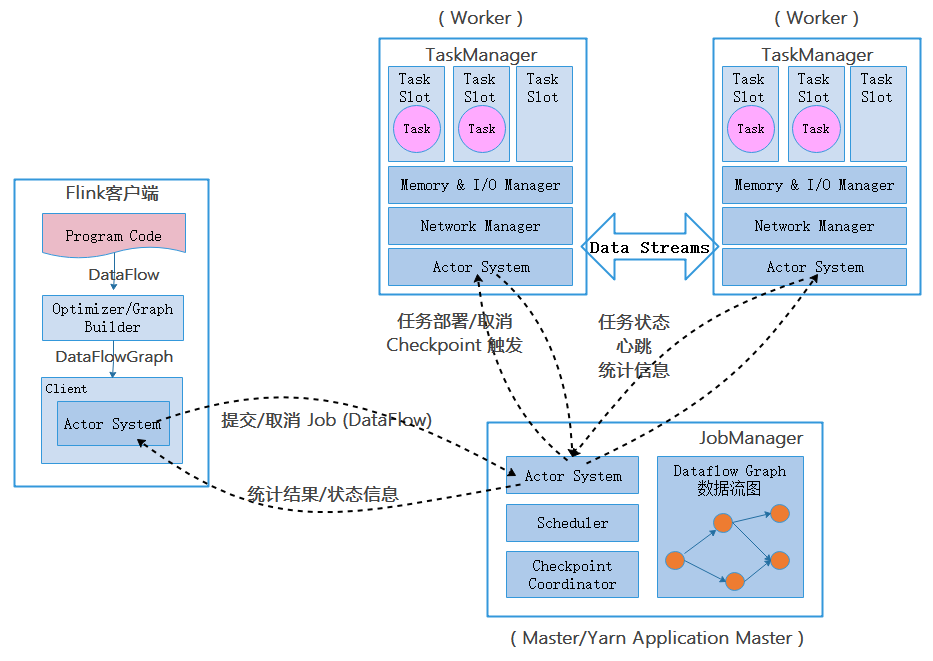
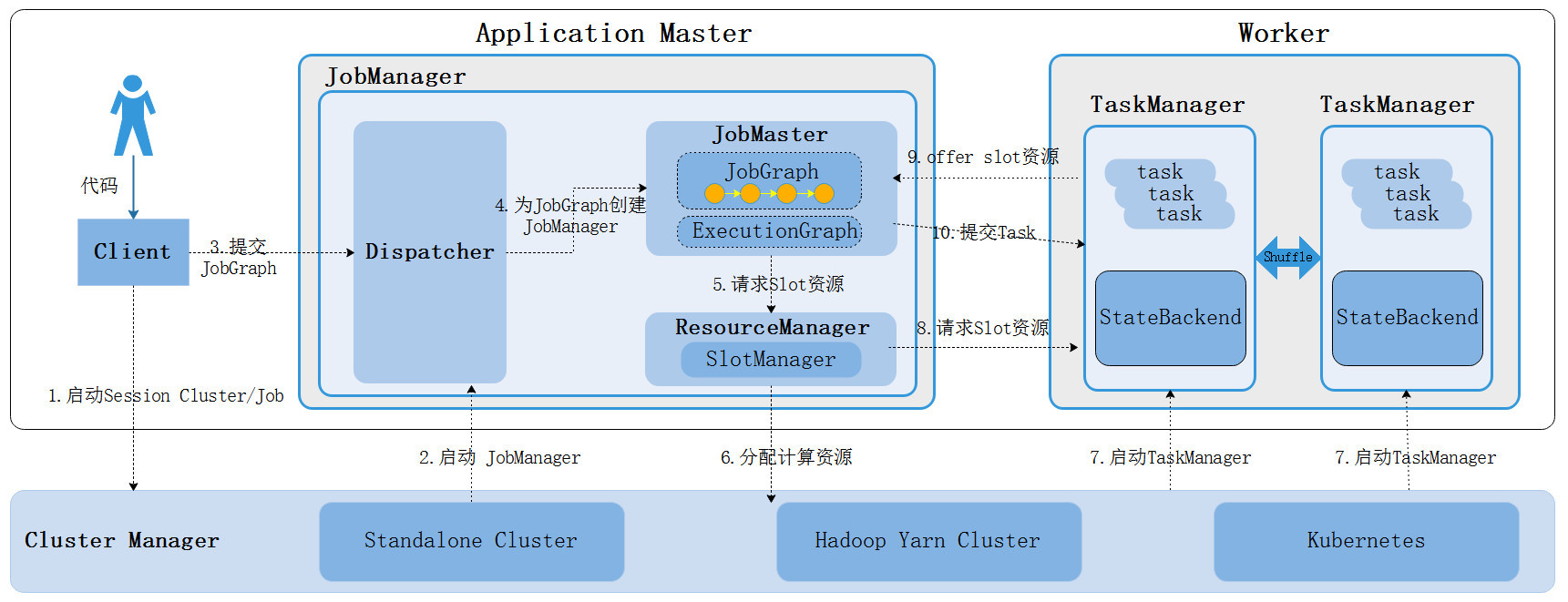
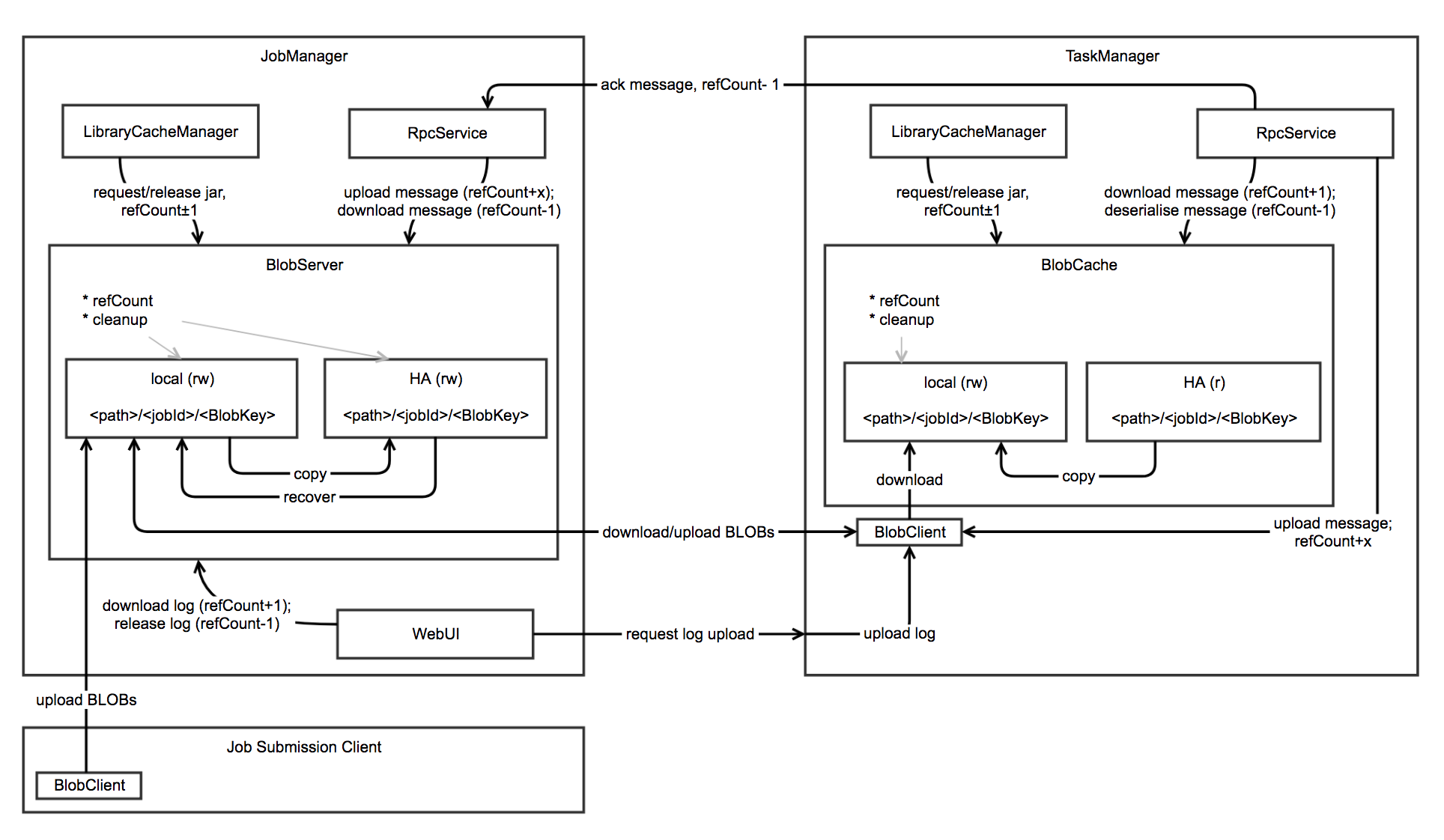
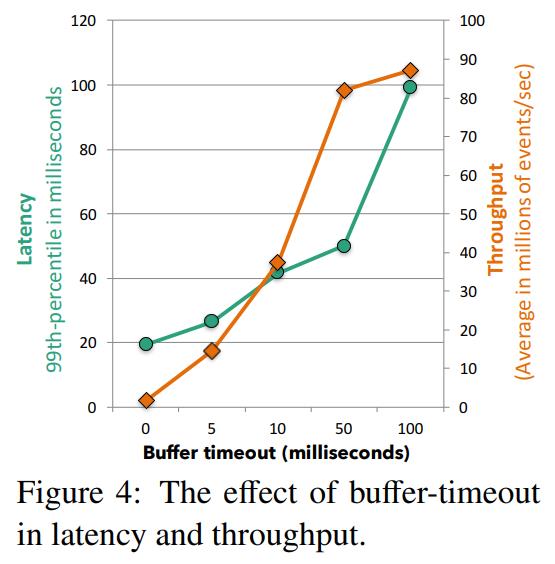
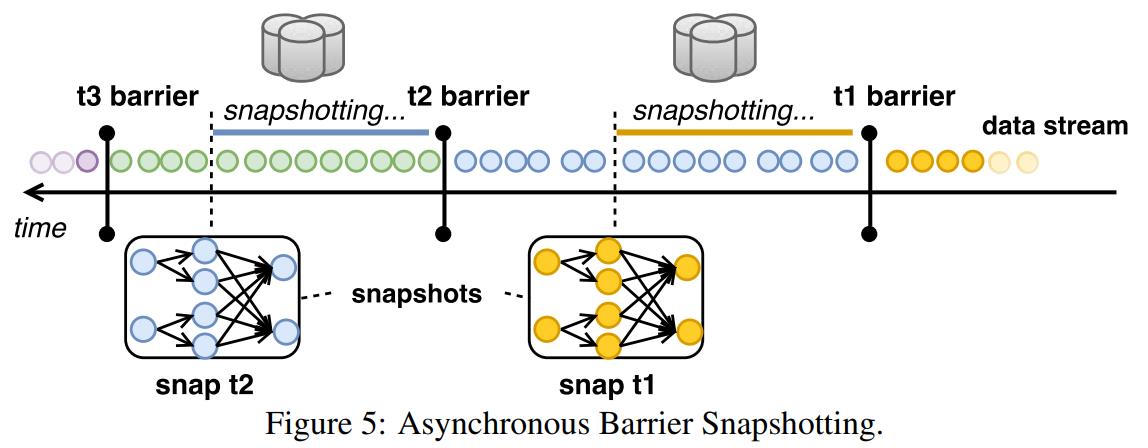
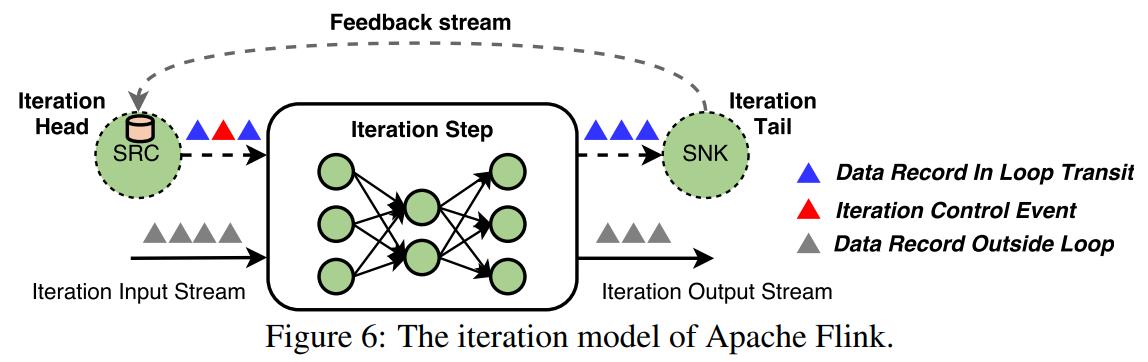
- 重点拆 Shuffle、checkpoint、反压、内存模型、代码生成 这些底层机制,解释两者性能差异为什么会落到 I/O、CPU 和延迟上
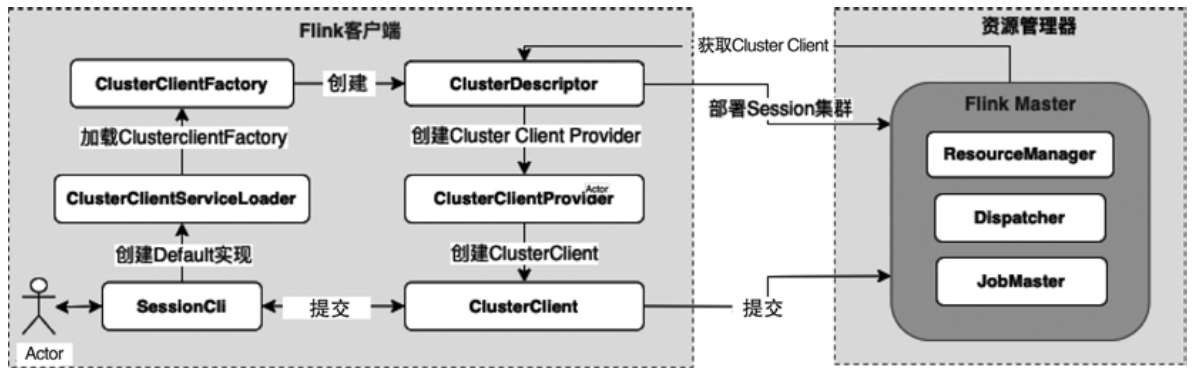
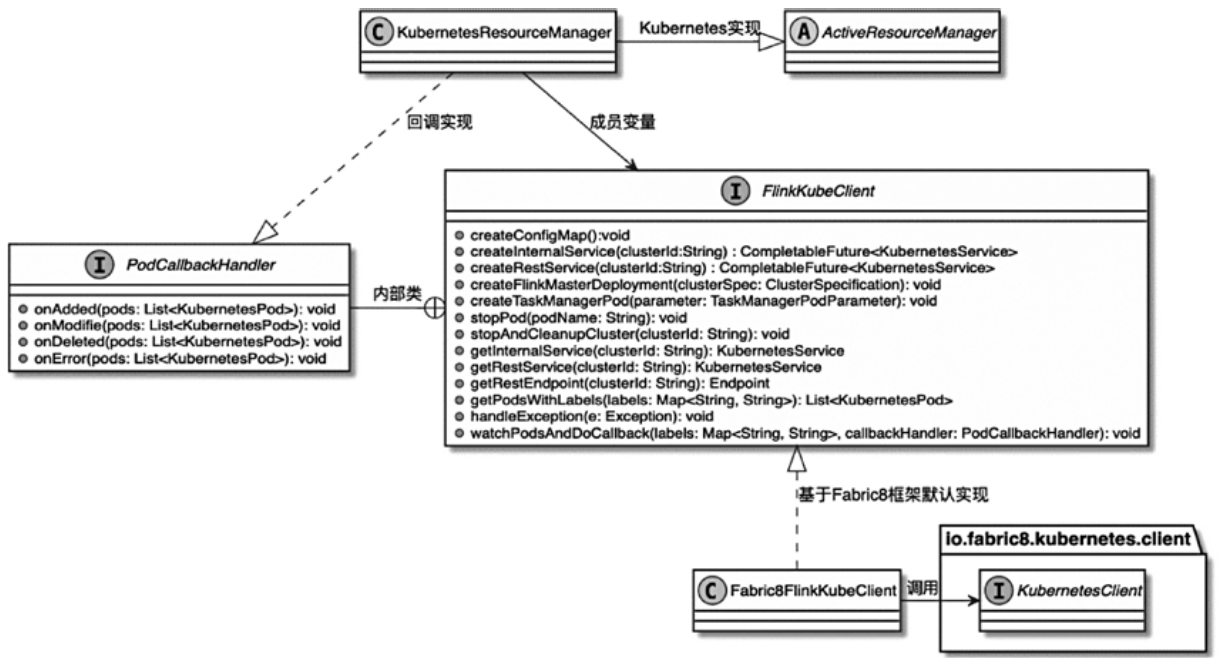
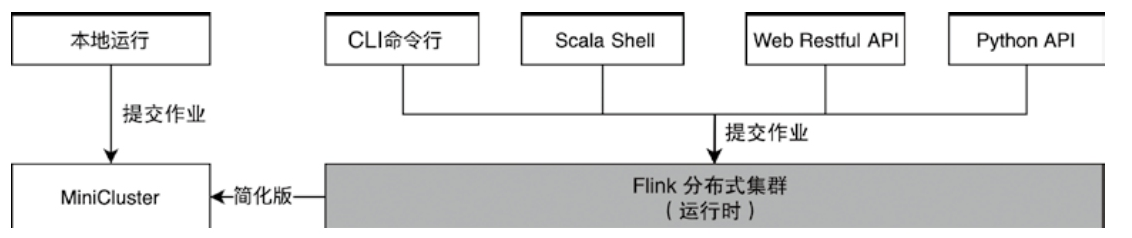
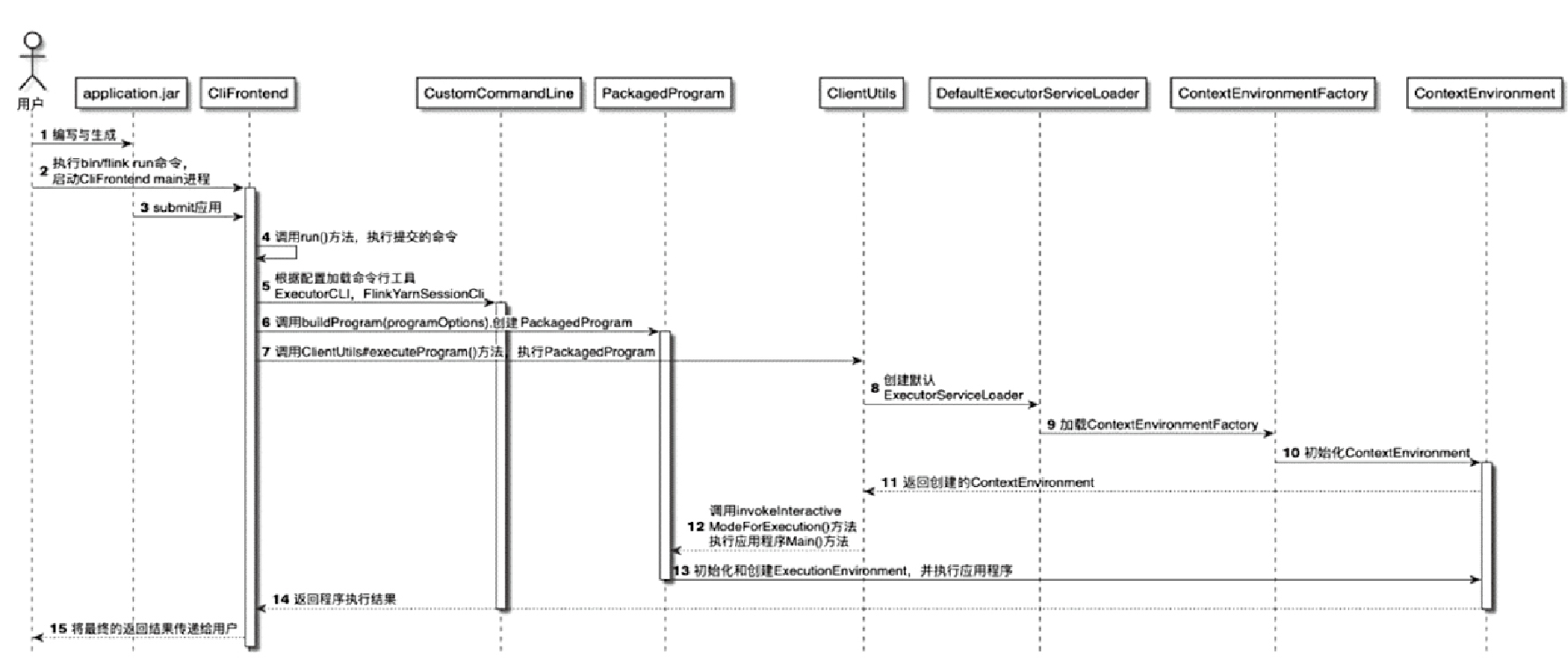
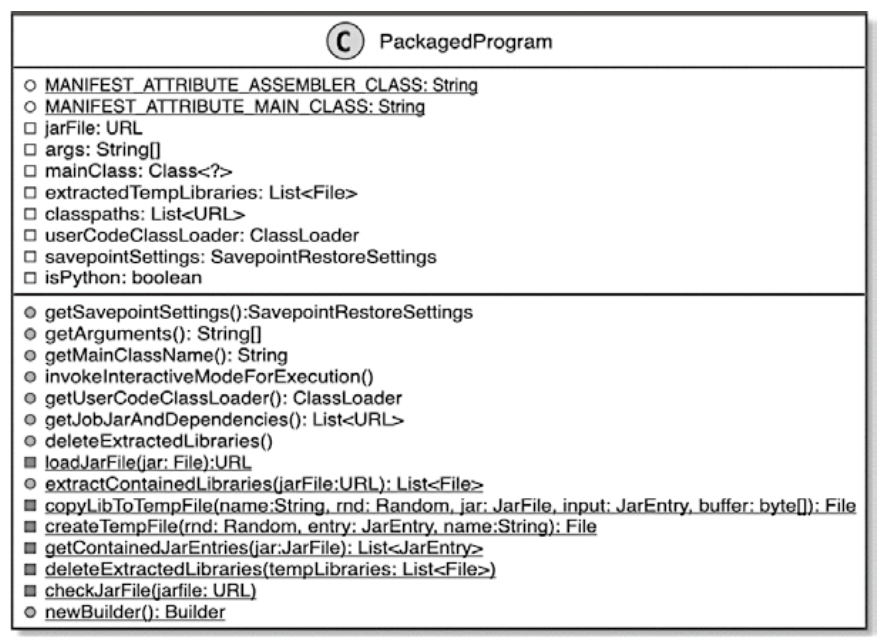
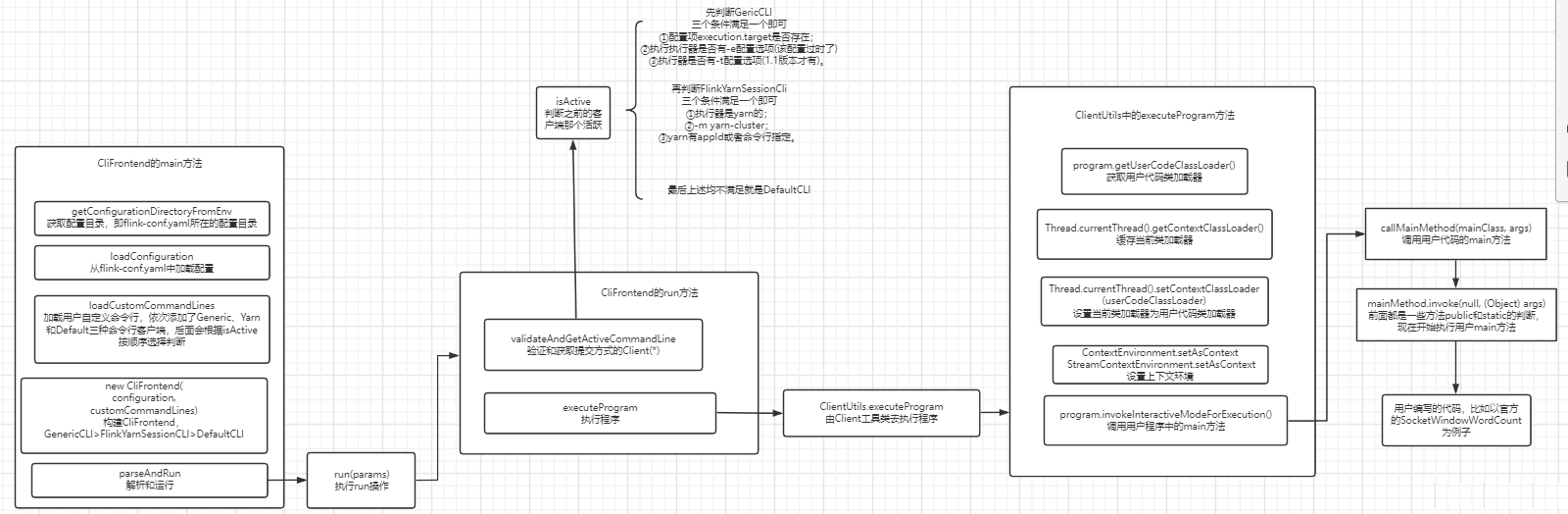
- 再把 spark-submit、Thrift Server、Spark Operator、Livy 与 flink run、Flink Kubernetes Operator、REST API、SQL Client、Application Mode 摆在一起比较
- 最后落到实用选择:如果目标是 批处理吞吐、流式低延迟、K8s 原生部署、CI/CD 自动化、SQL 接入,Spark 和 Flink 分别更适合什么场景