大连,11年后的再相见
11年后再次重游大连之游记,所到之处:
- 东港五街、东港音乐喷泉、威尼斯水城
- 海之韵公园、东部栈道、棒棰岛沿途海边栈道、石槽海滨浴场
- 星海公园、星海广场、滨海路栈道、渔人码头、银沙滩
- 俄罗斯广场、南山街、明泽湖、中山广场、西安路夜市
- 金石滩国家地质公园
- 旅顺博物馆、日俄监控旧址博物馆、潜艇博物馆、大连博物馆
11年后再次重游大连之游记,所到之处:
按:一个任务的一生来梳理 Volcano,重点包括:
围绕分布式系统的“修好”错觉和八大谬误展开,重点包括:
给软件工程画一张“跨代际地图”,重点包括:
按:Kubernetes 的扩展机制很多,理解时不要把它们看成零散插件,重点包括:
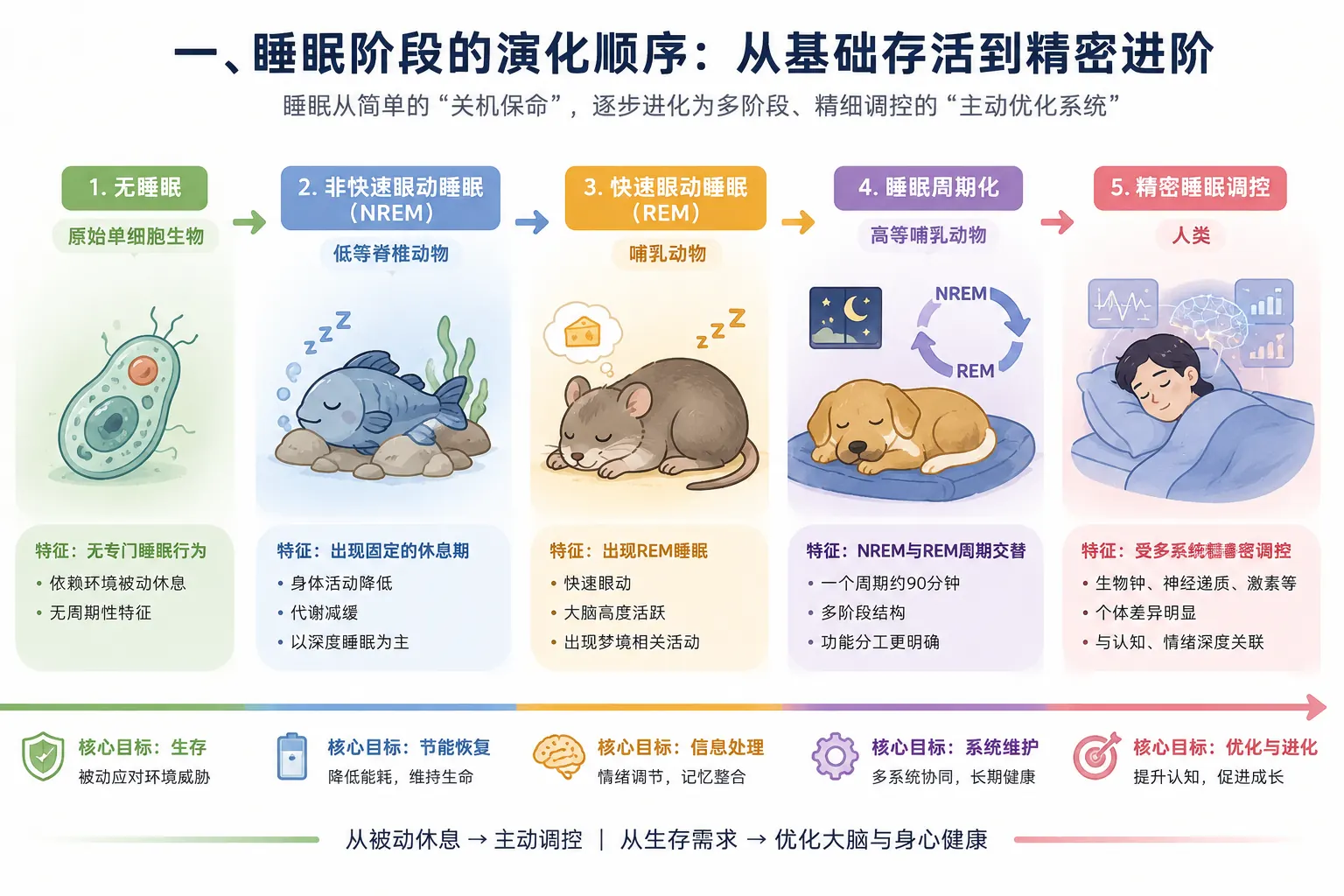
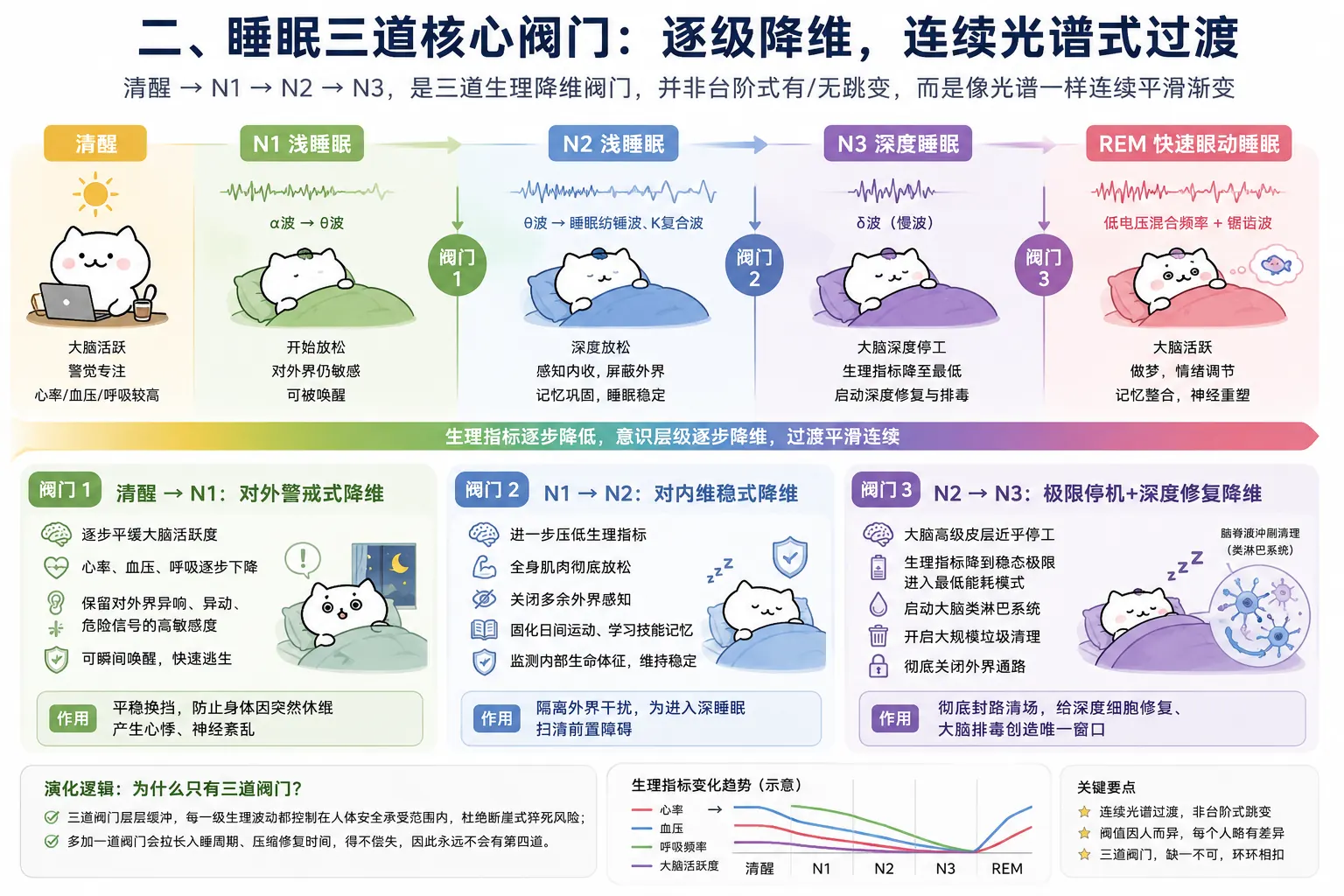
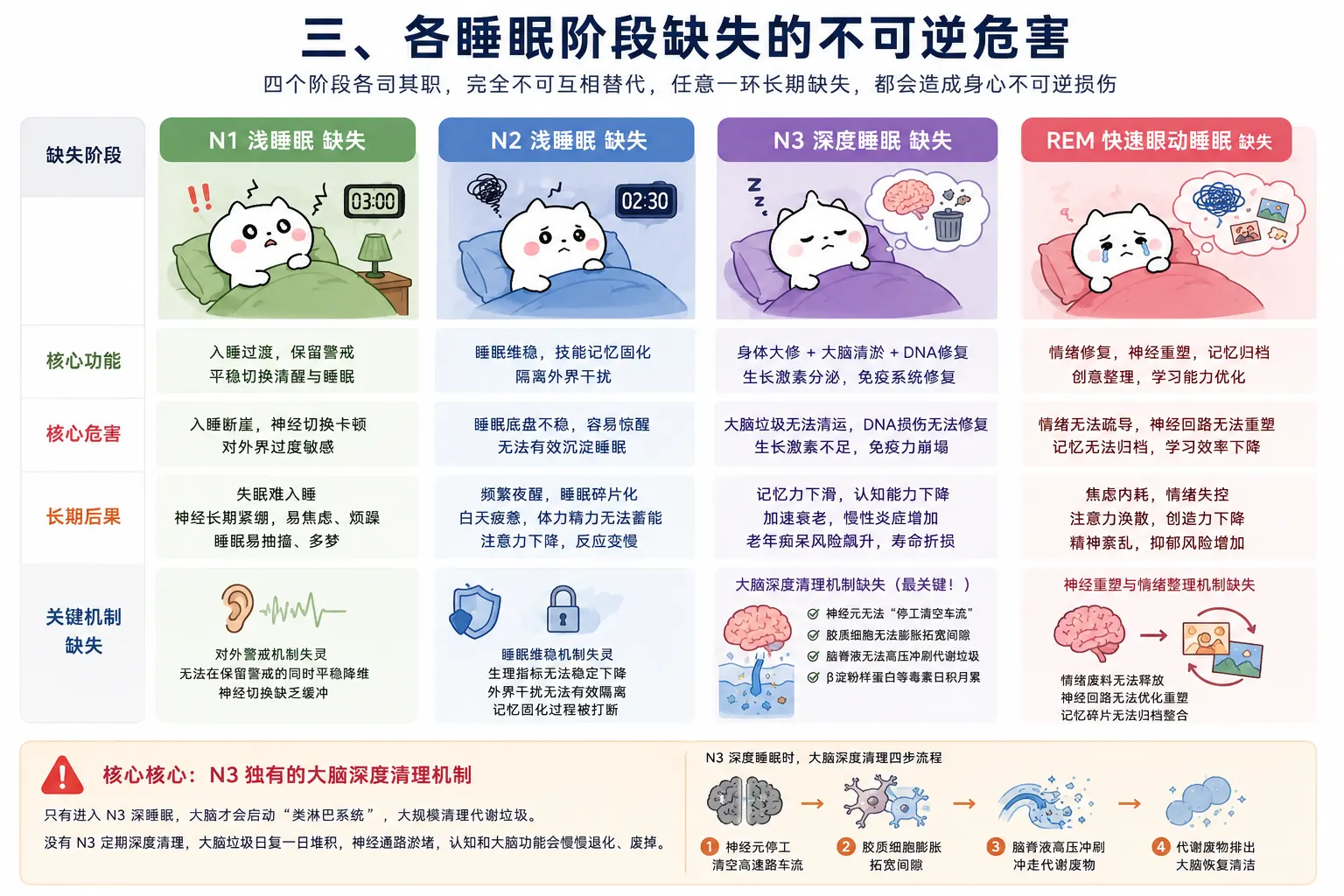
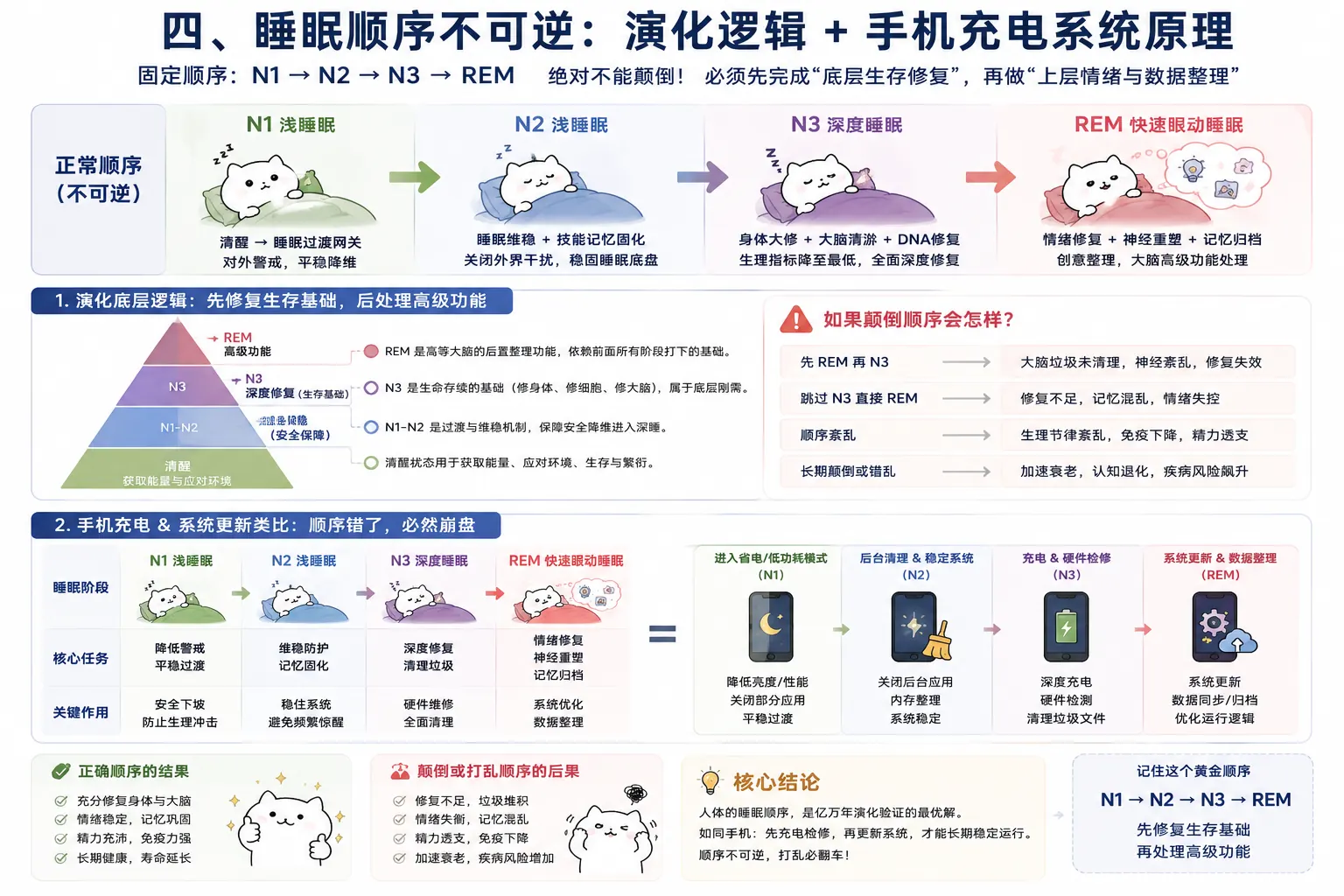
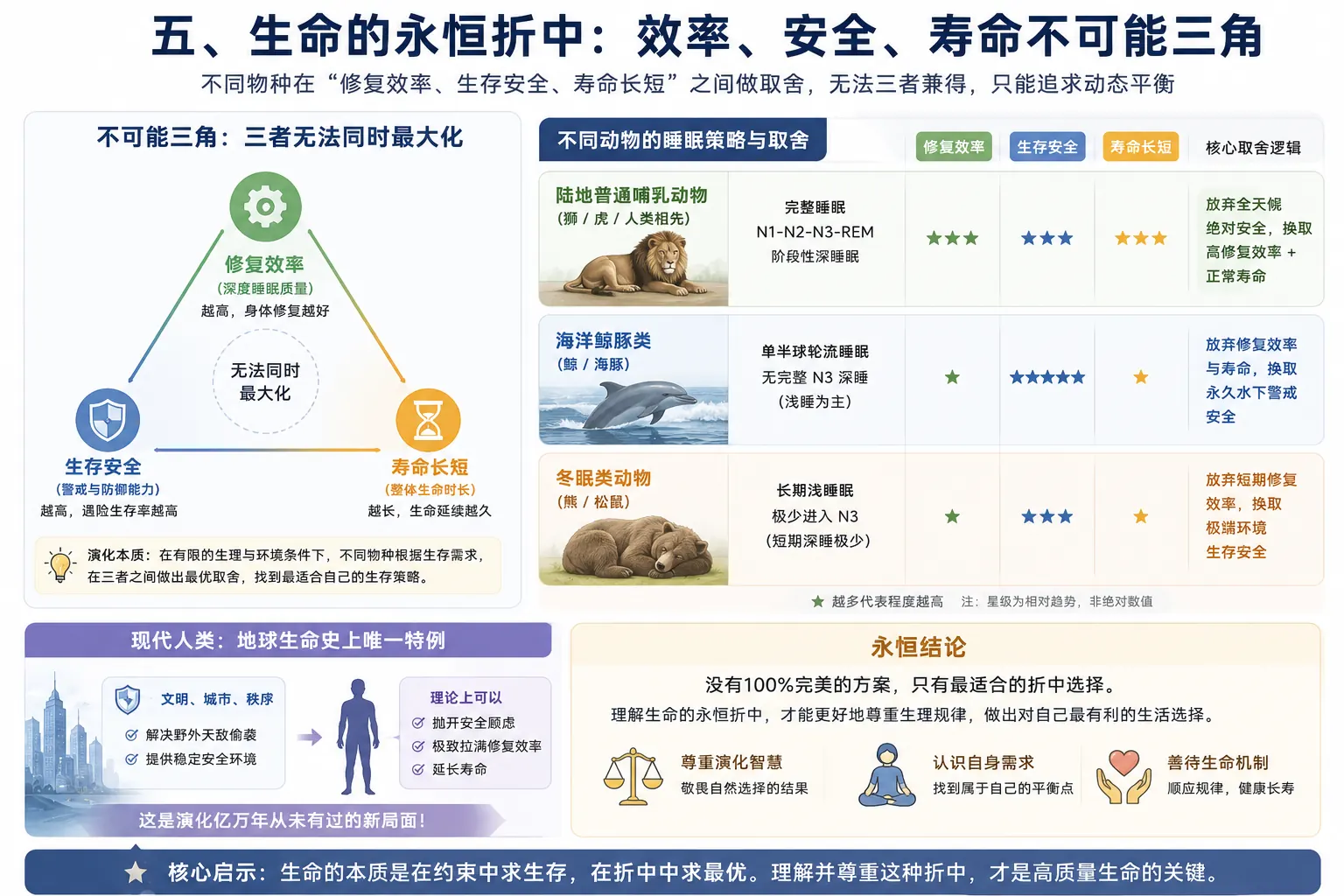
把睡眠看成生命演化打磨出来的生存机制,重点包括:
借阿富汗近半个世纪的战乱,梳理塔利班的历史背景和形成路径,重点包括:

围绕 AI 平台配额管理里的“双写一致性”问题展开,重点包括:
把主流消息队列做一次完整盘点,重点包括:
顺着一次请求在 Claude Code 里的流转过程做源码拆解,重点包括:


















