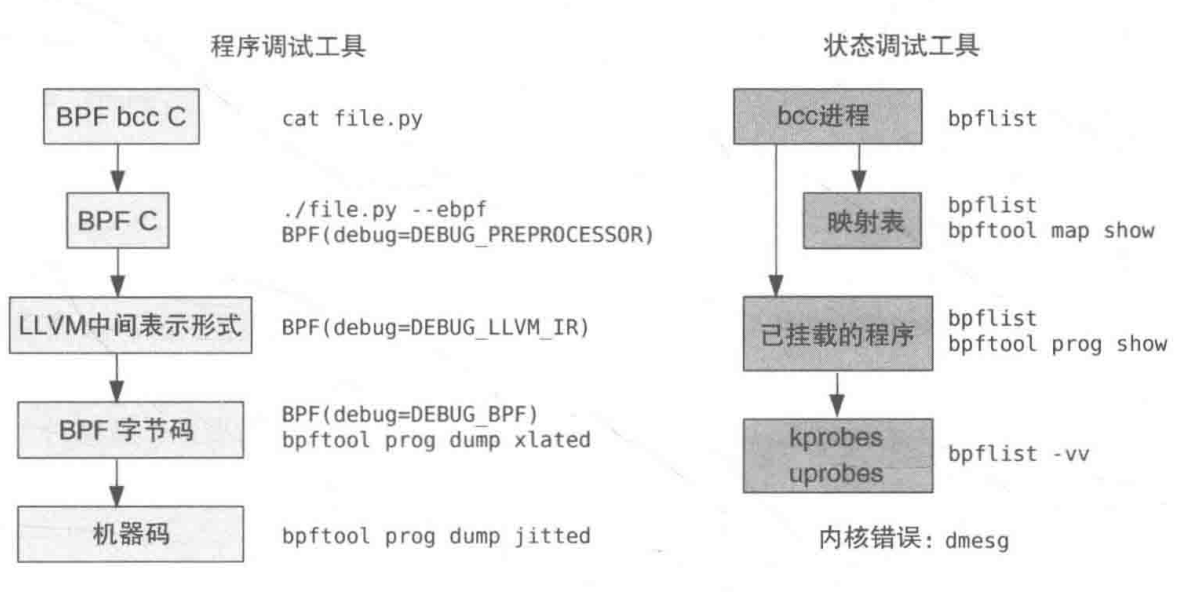
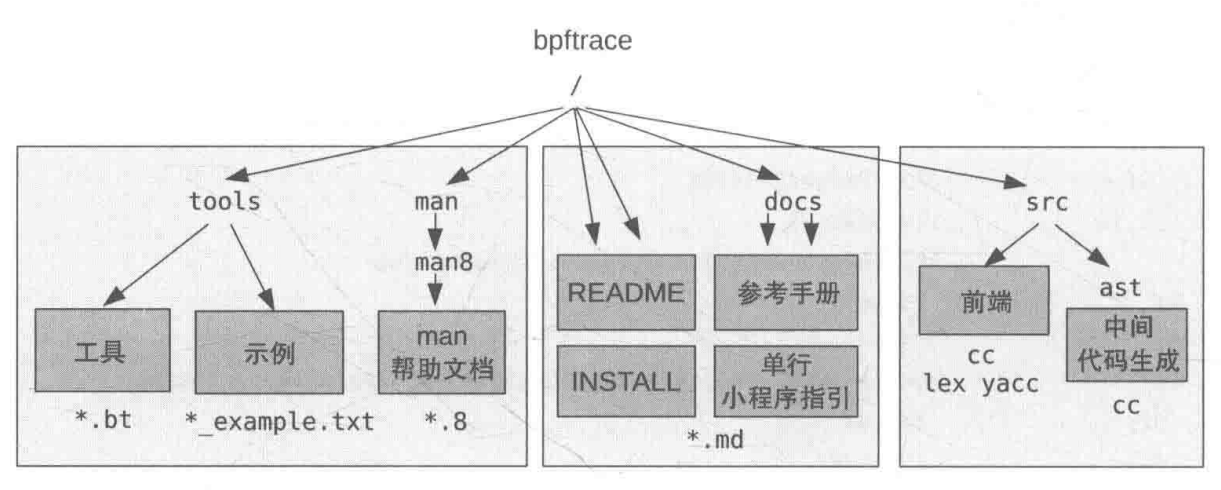
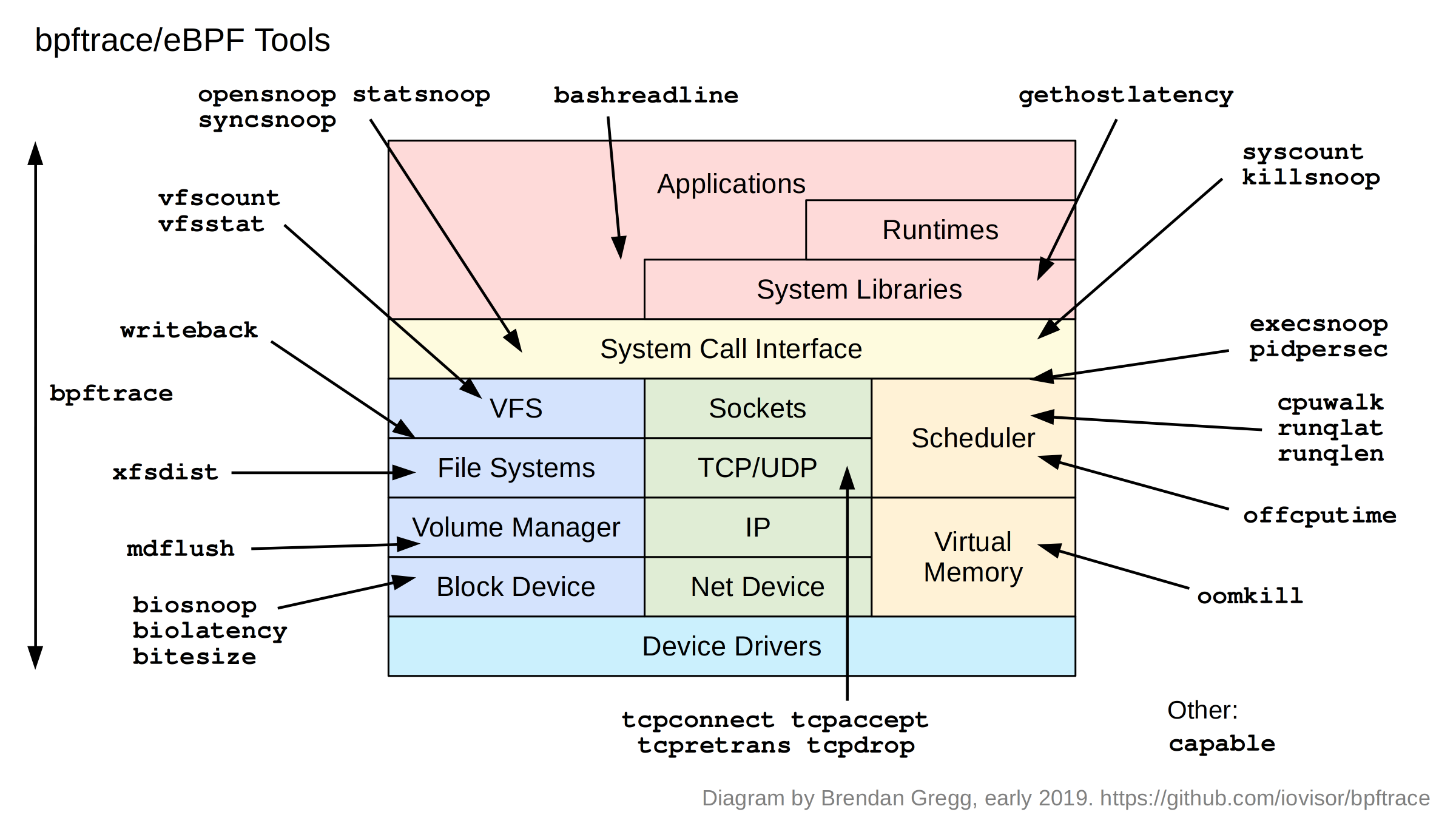
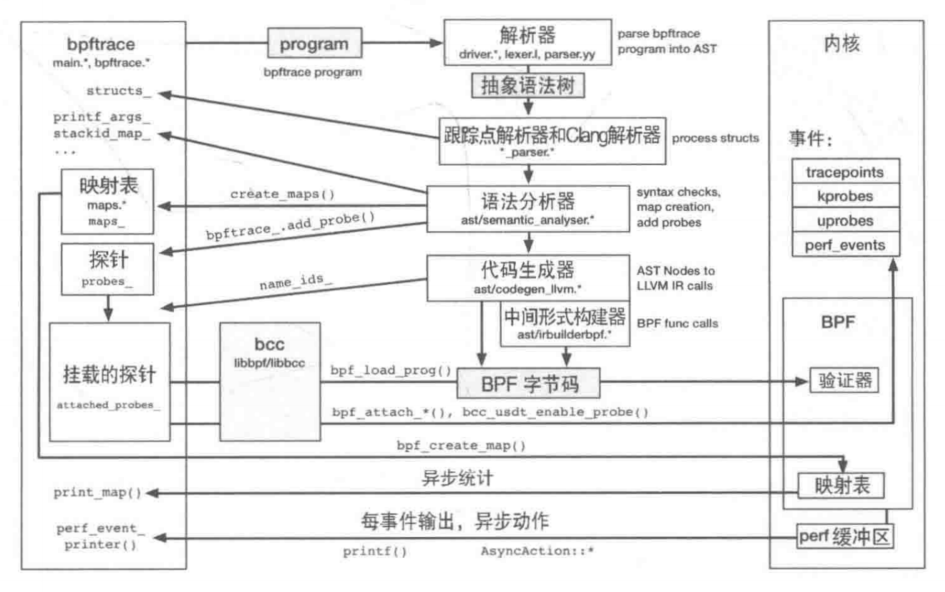
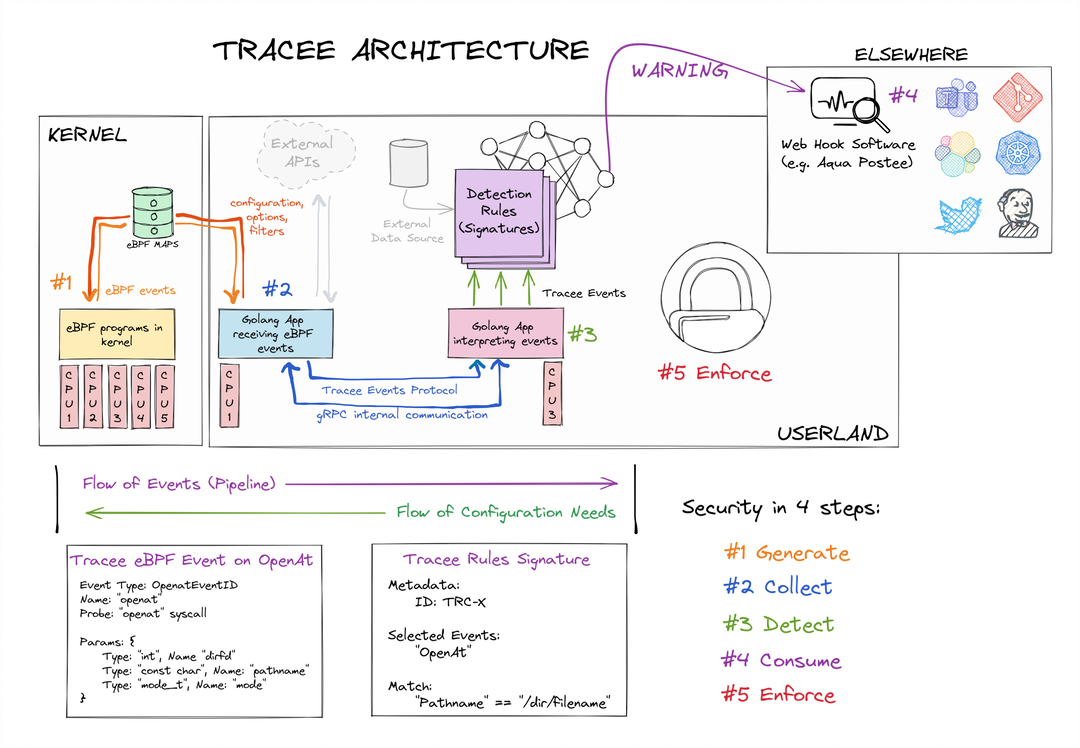
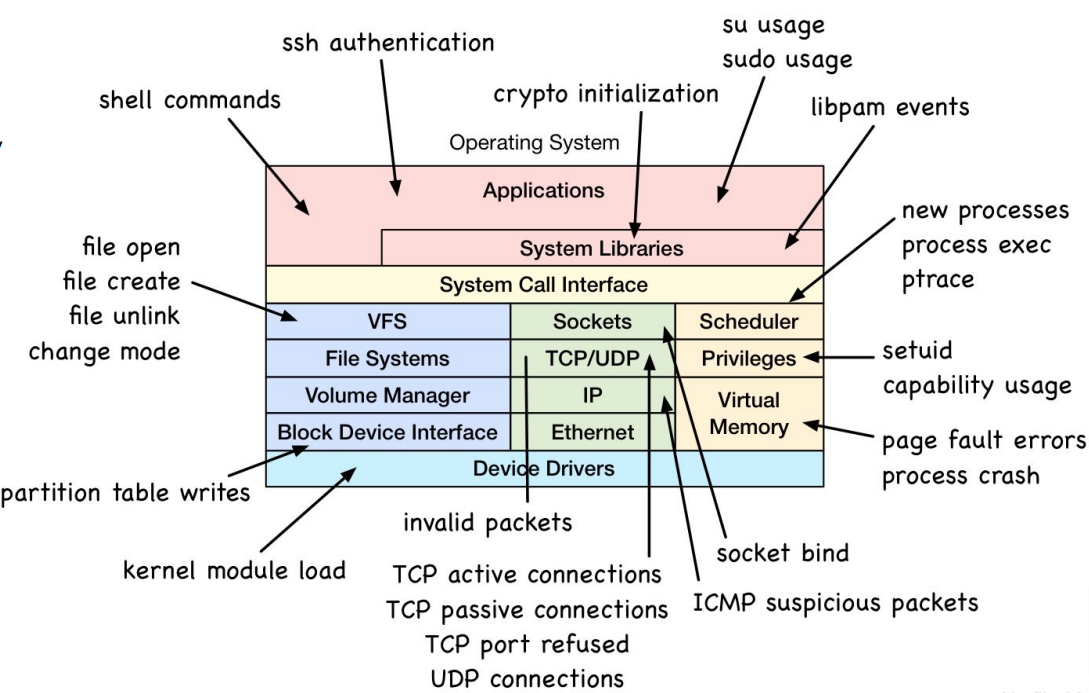
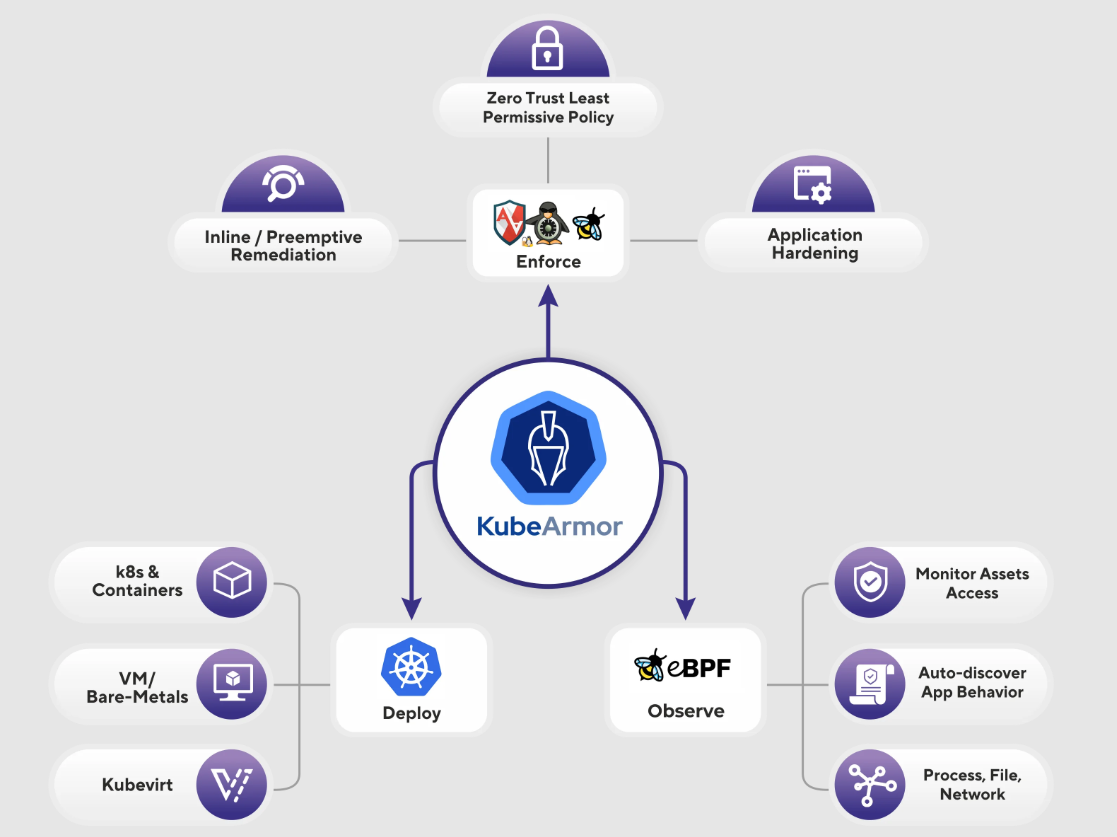
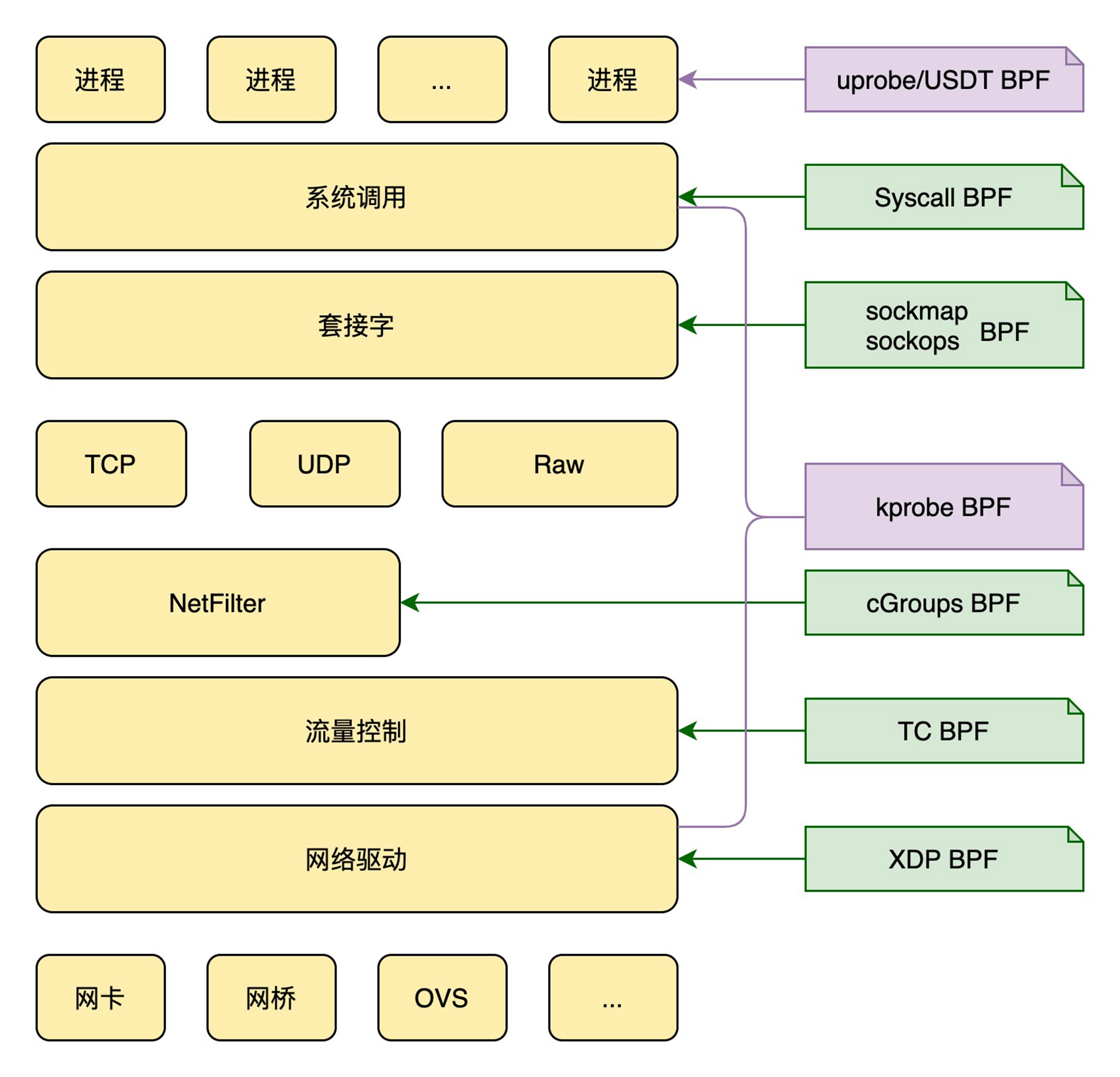
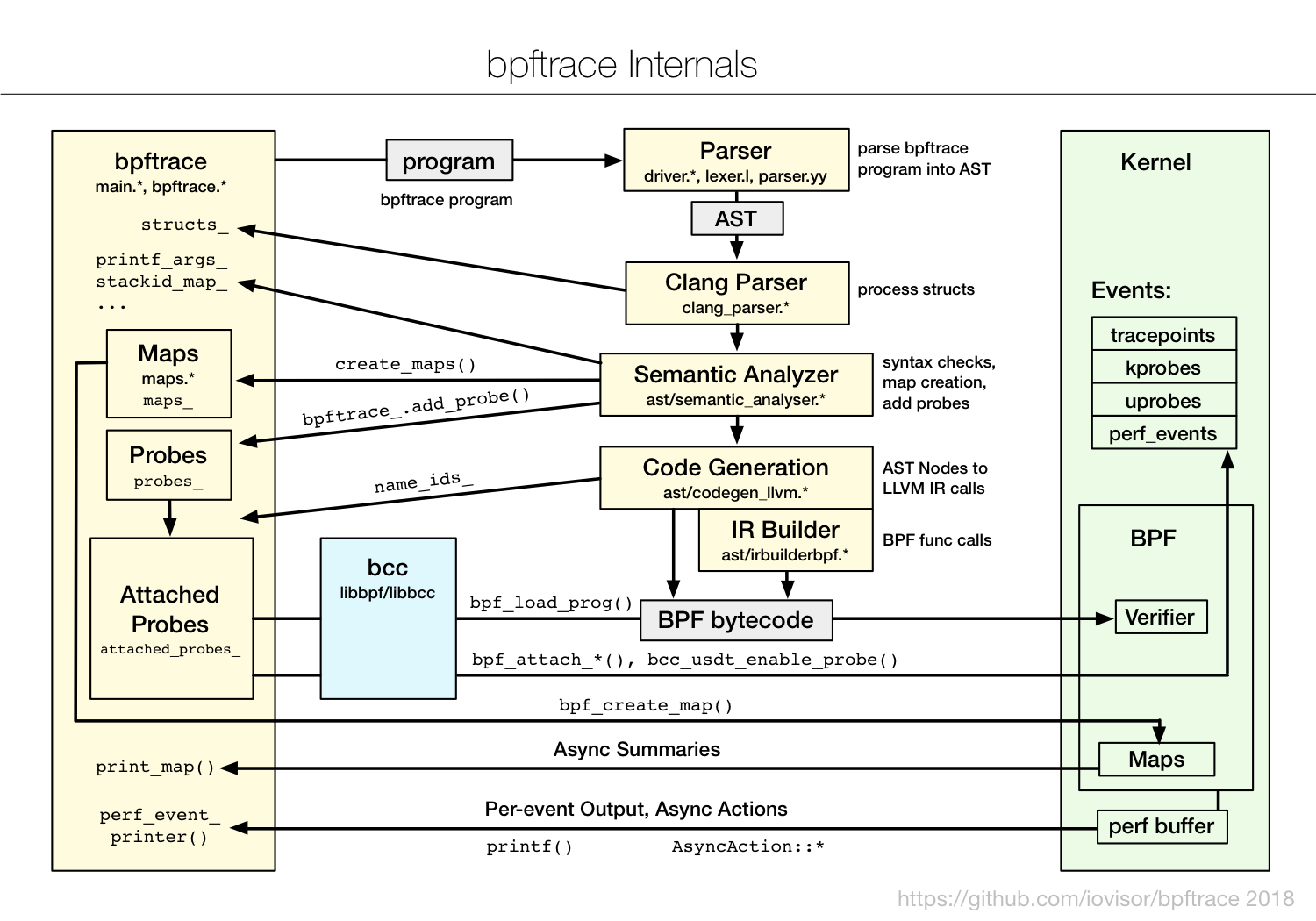
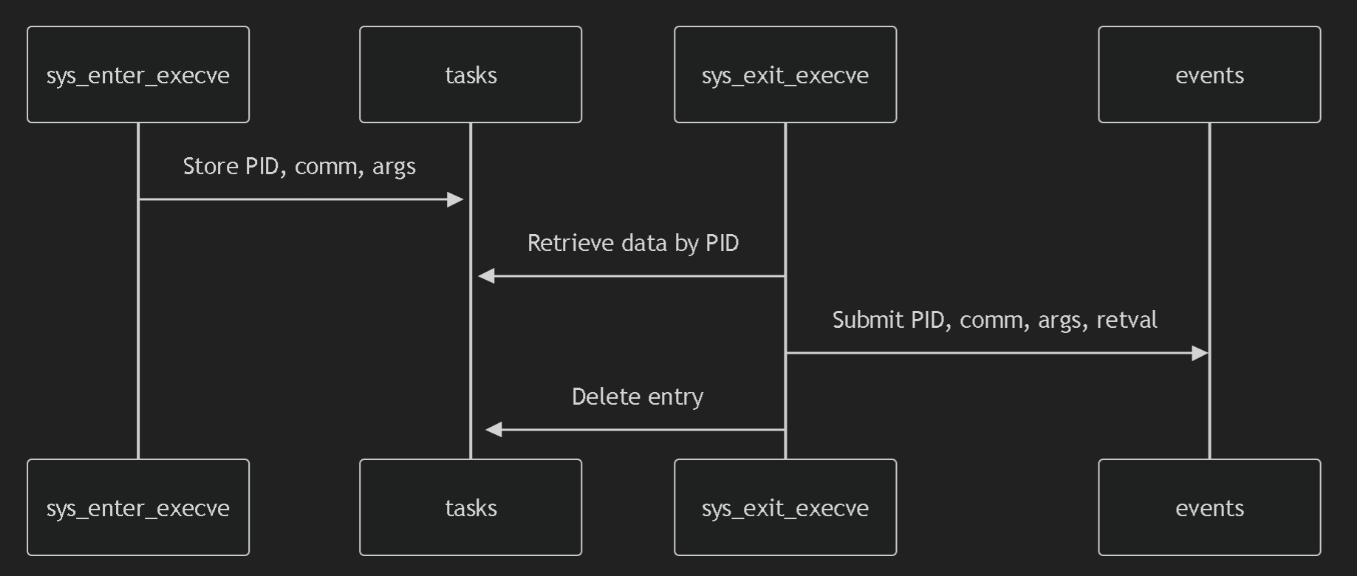
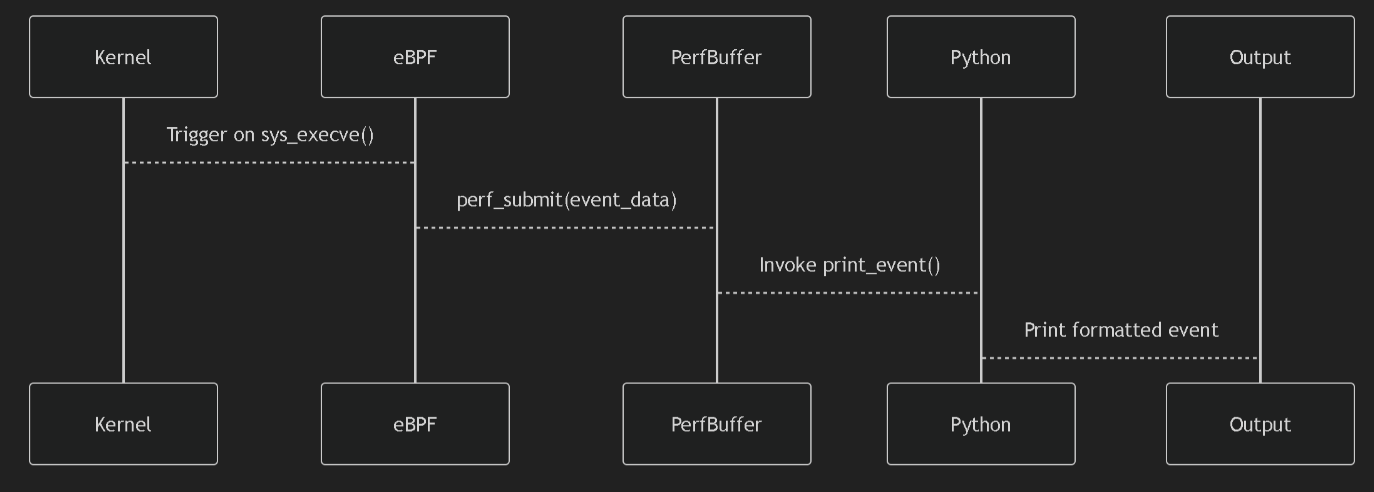
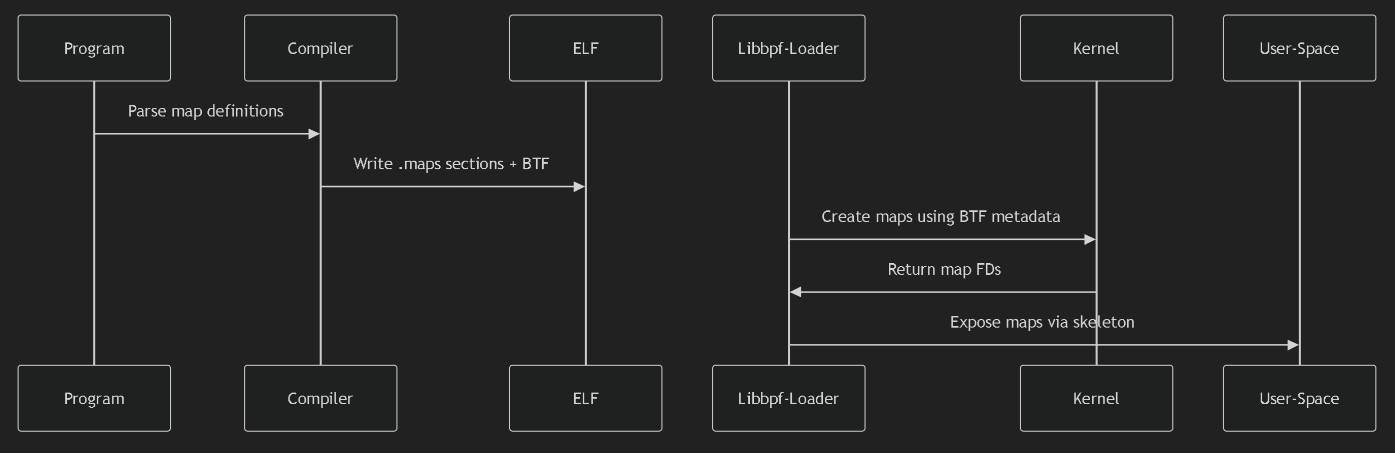
JuiceFS
包括:
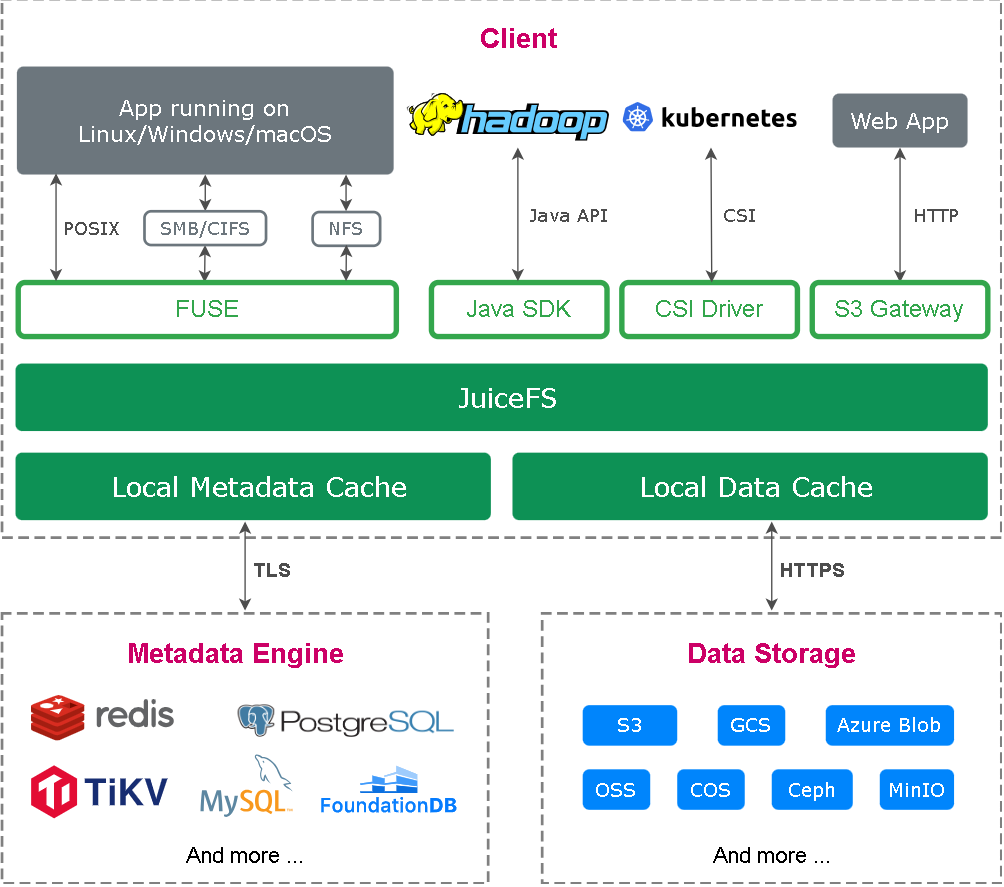
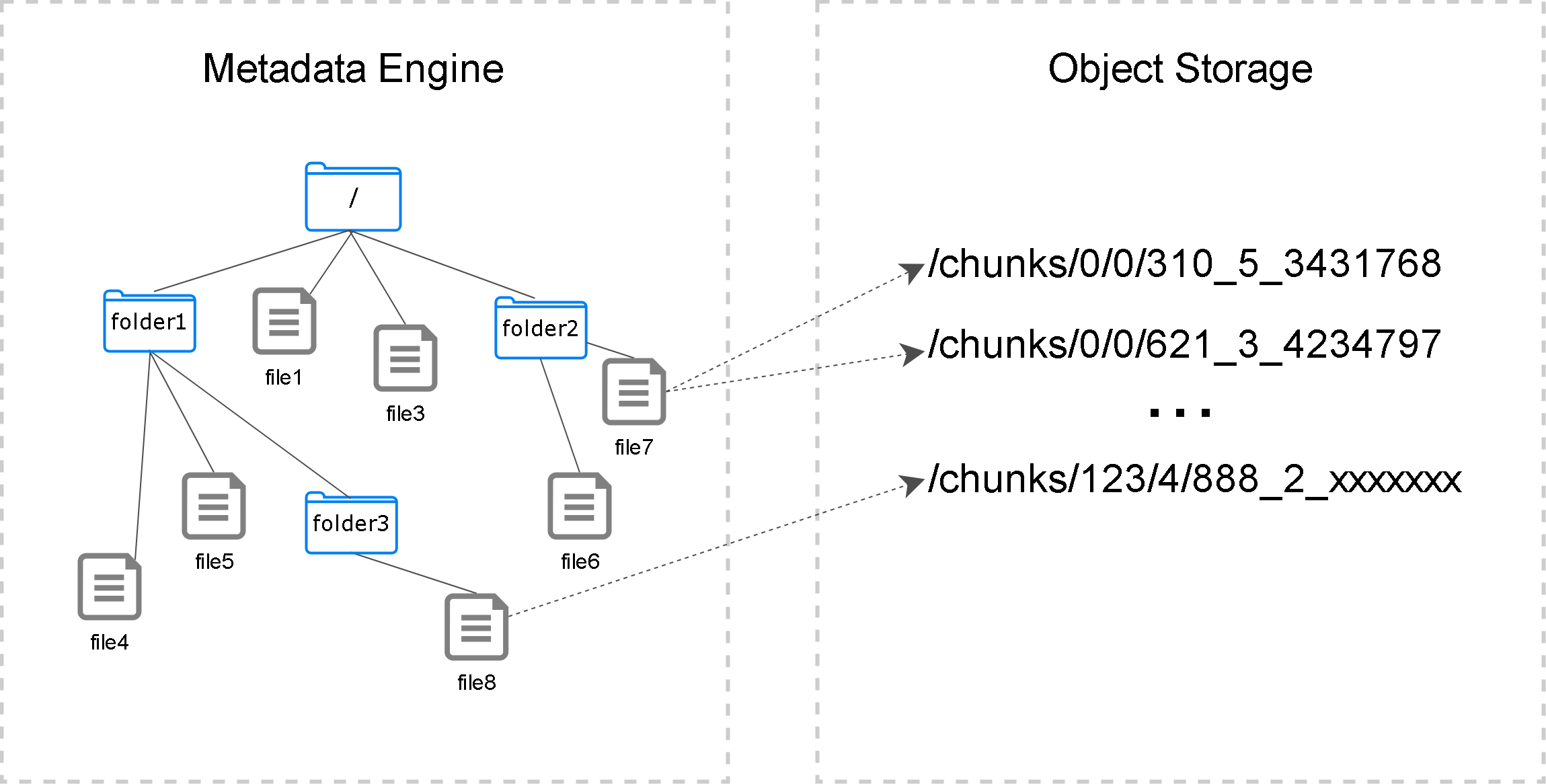
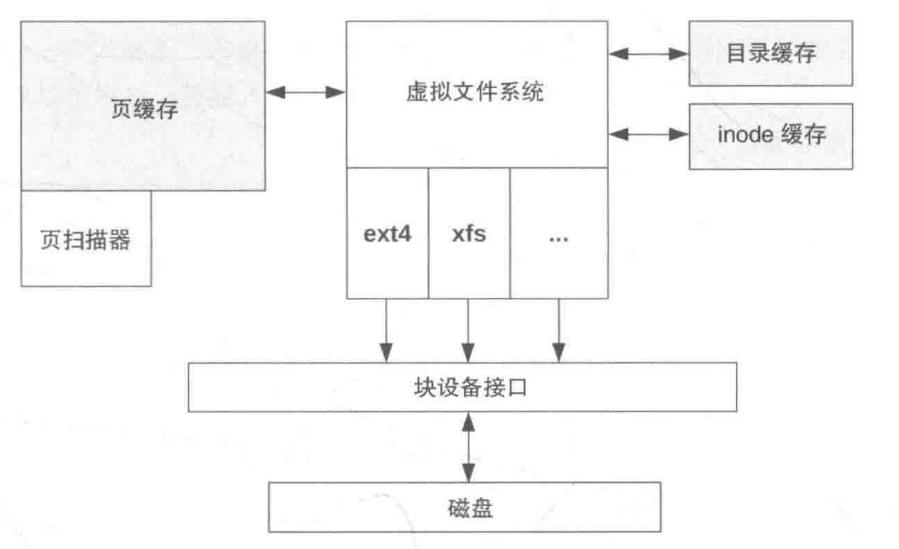
- 从 数据与元数据分离 这个核心设计入手,理解 JuiceFS 为什么能把对象存储包装成一个分布式文件系统
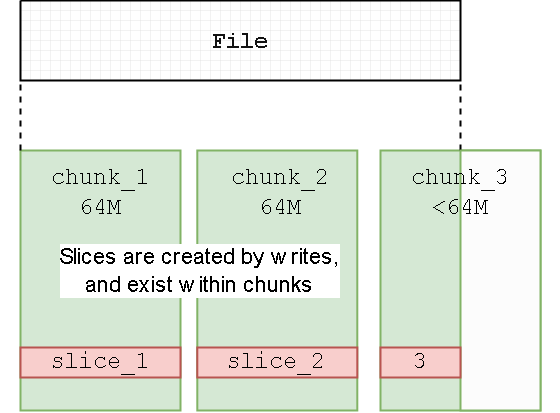
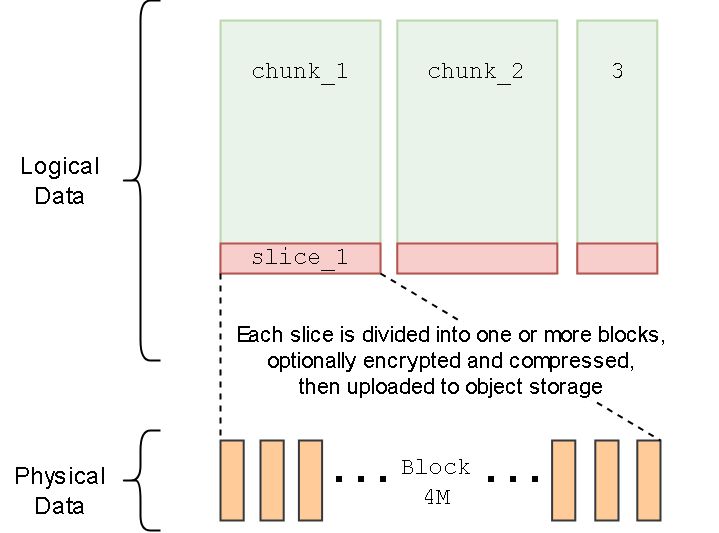
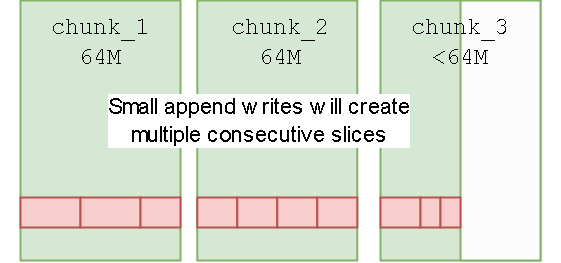
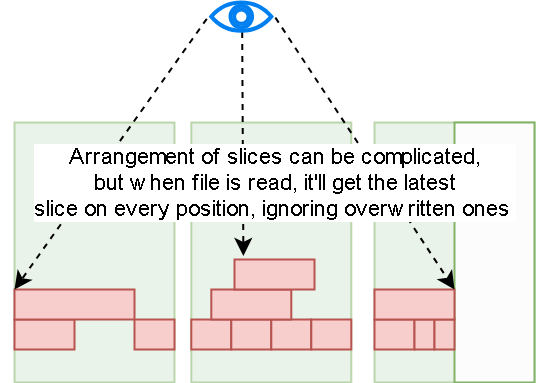
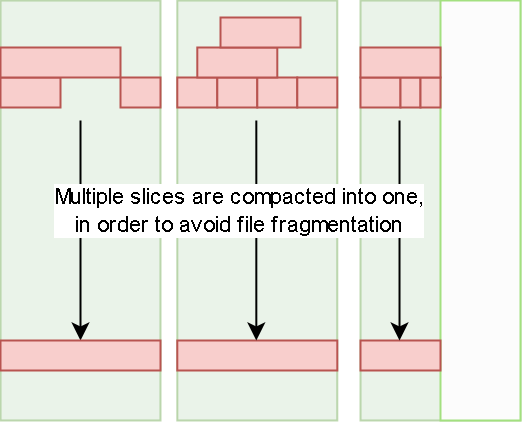
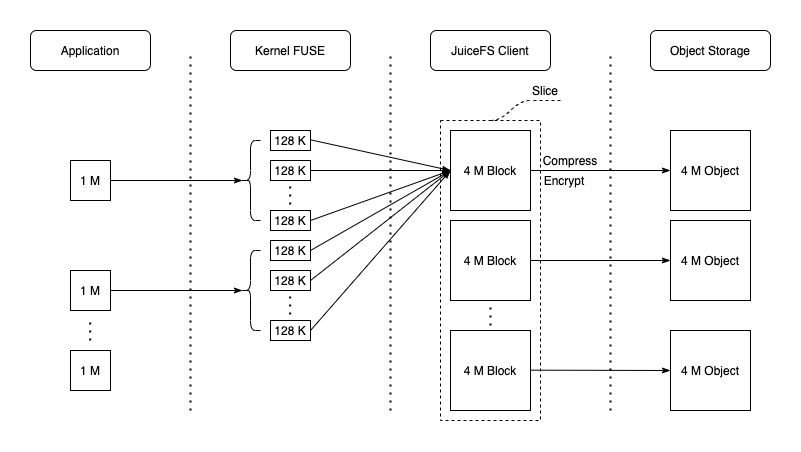
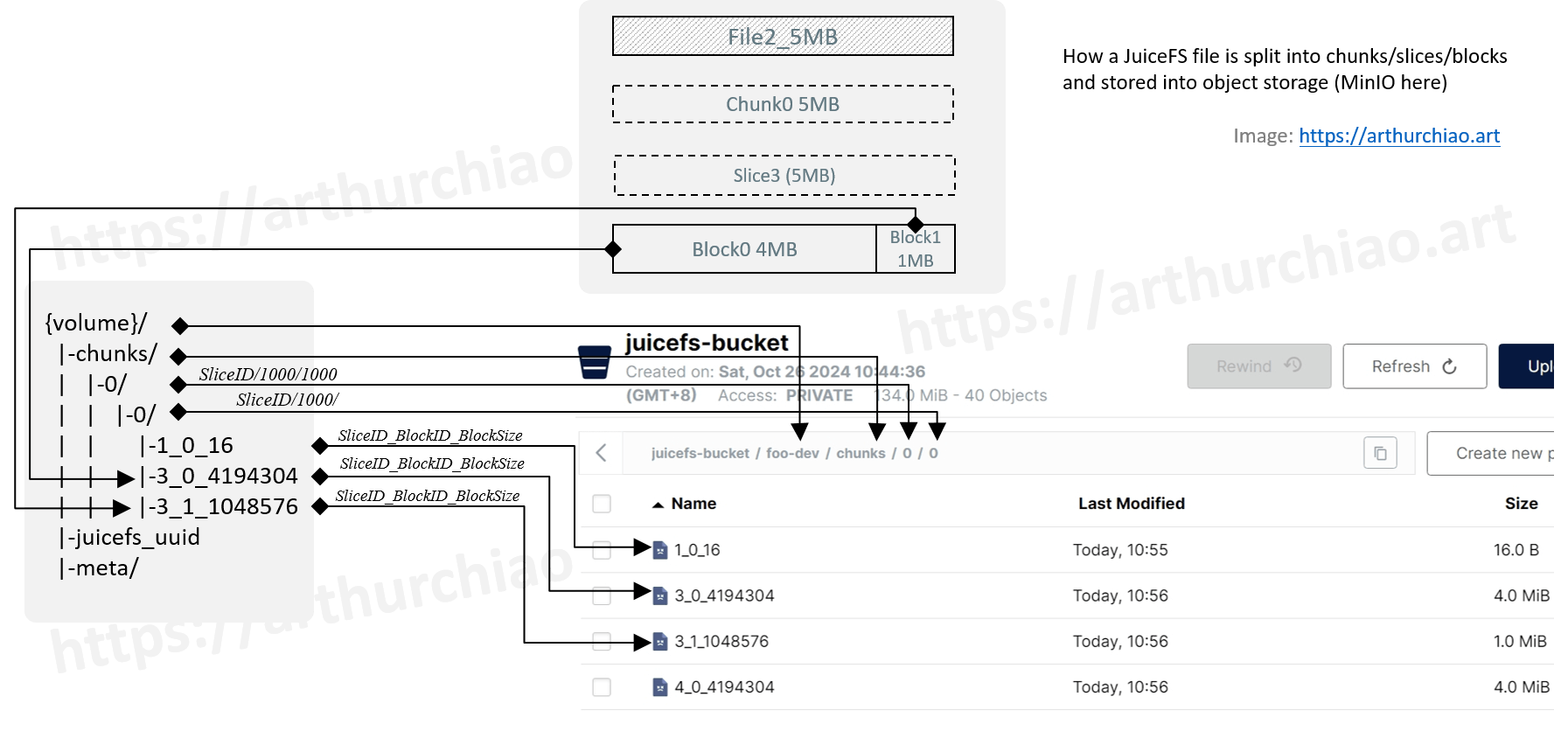
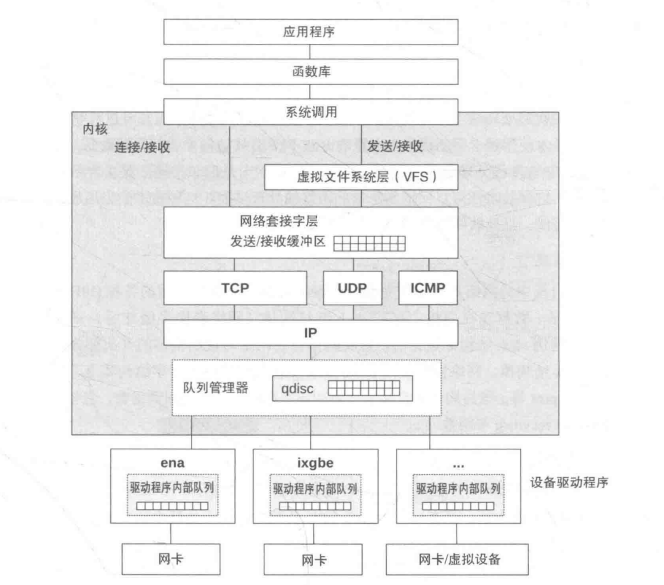
- 把 chunk、slice、block 的组织方式、对象存储里的命名规则、元数据与真实数据的映射关系讲清楚,方便定位读写放大和碎片问题
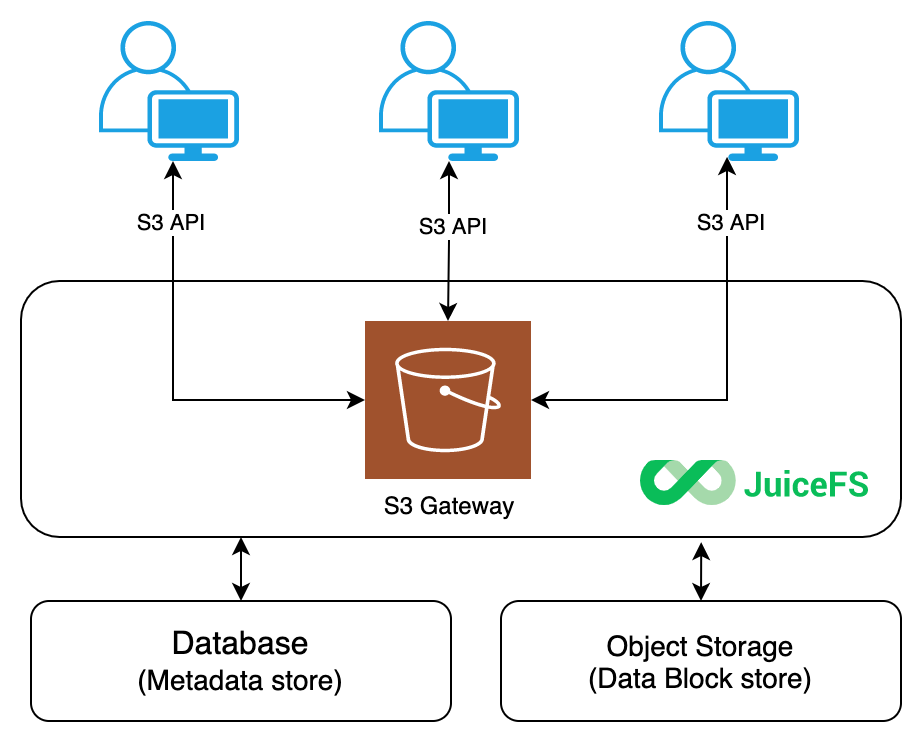
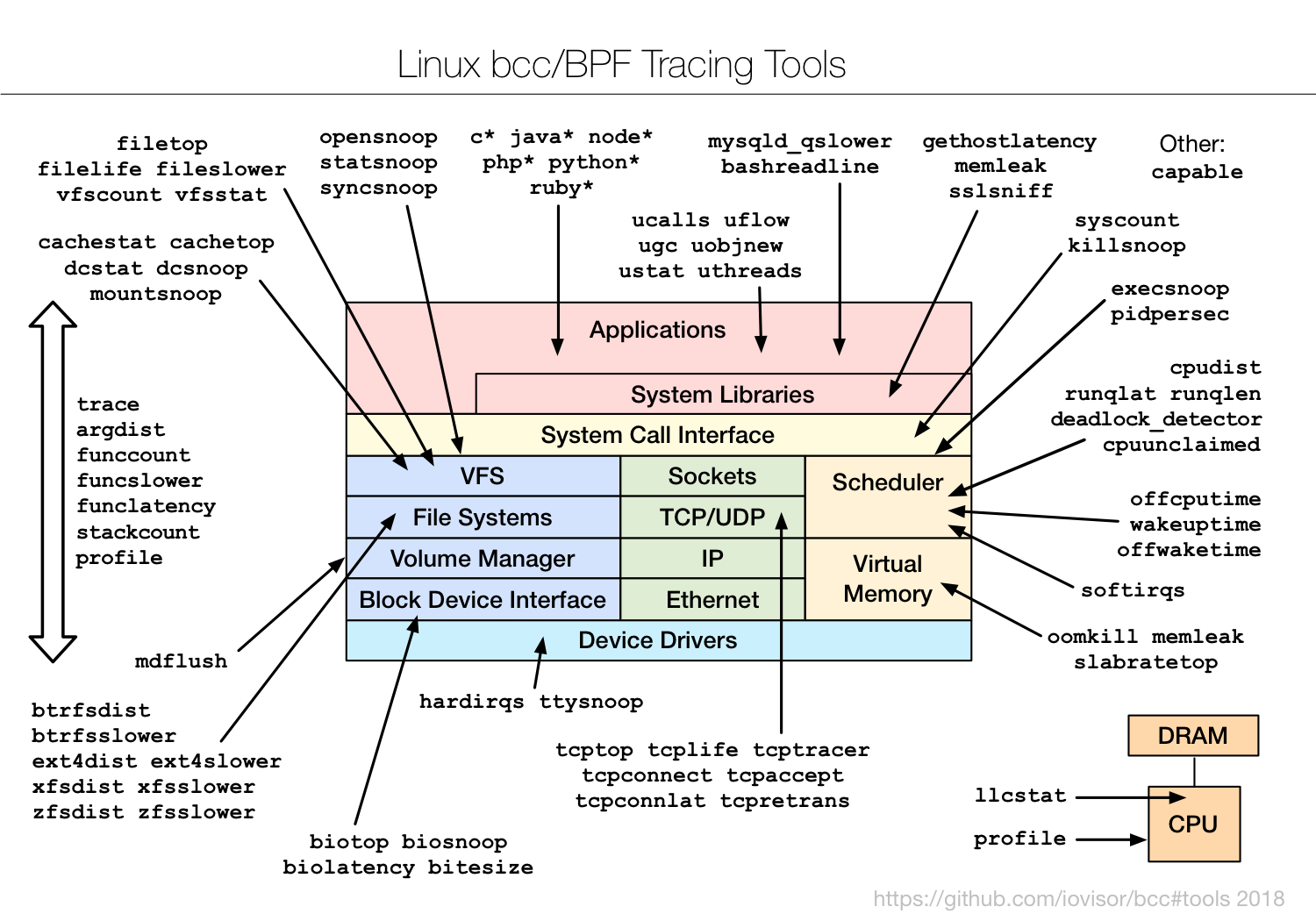
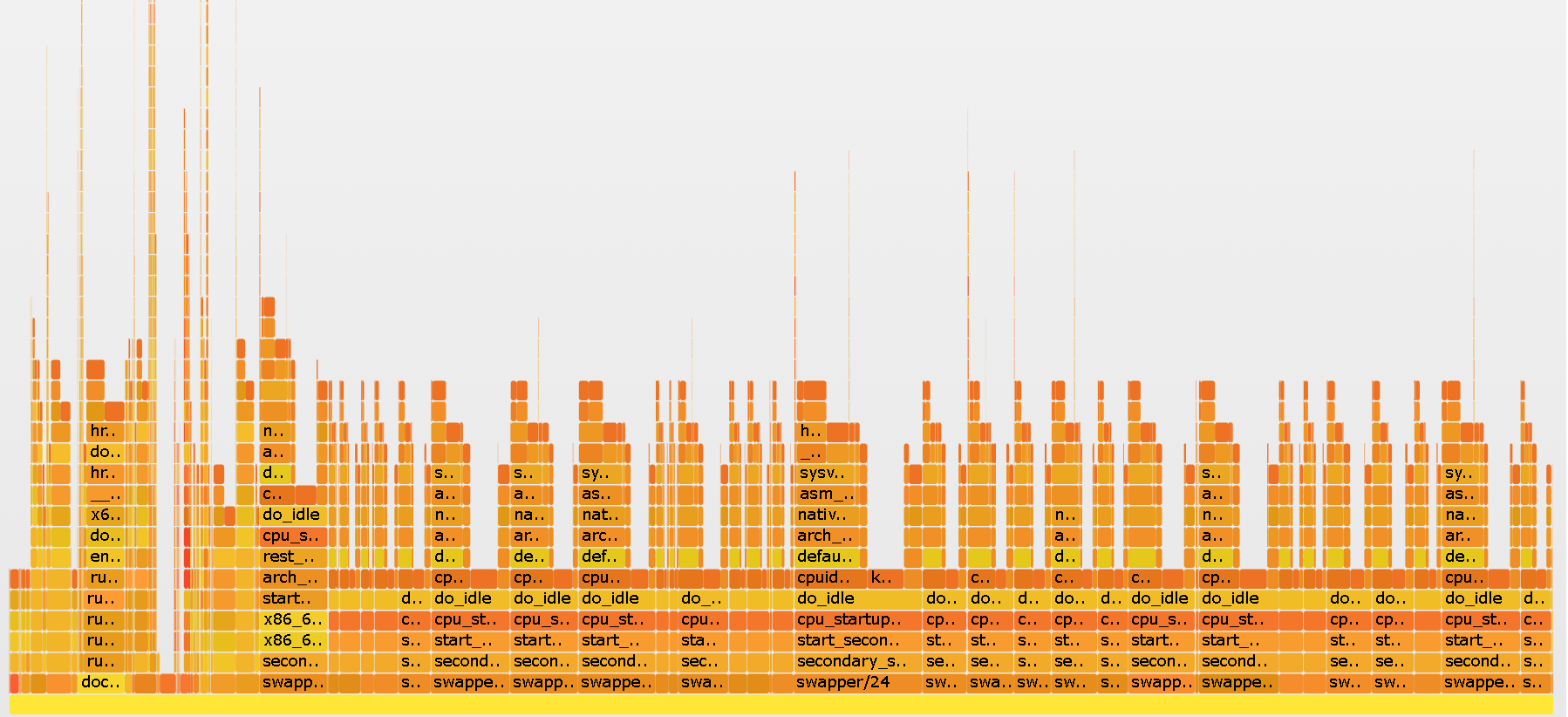
- 补充 格式化、挂载、本地验证、缓存、S3 Gateway、clone、同步 这些高频运维与功能点,避免只停留在概念层
- 最后看它如何和 Spark、Flink、Kubernetes CSI 集成,理解 JuiceFS 在大数据和云原生场景里最常见的落点