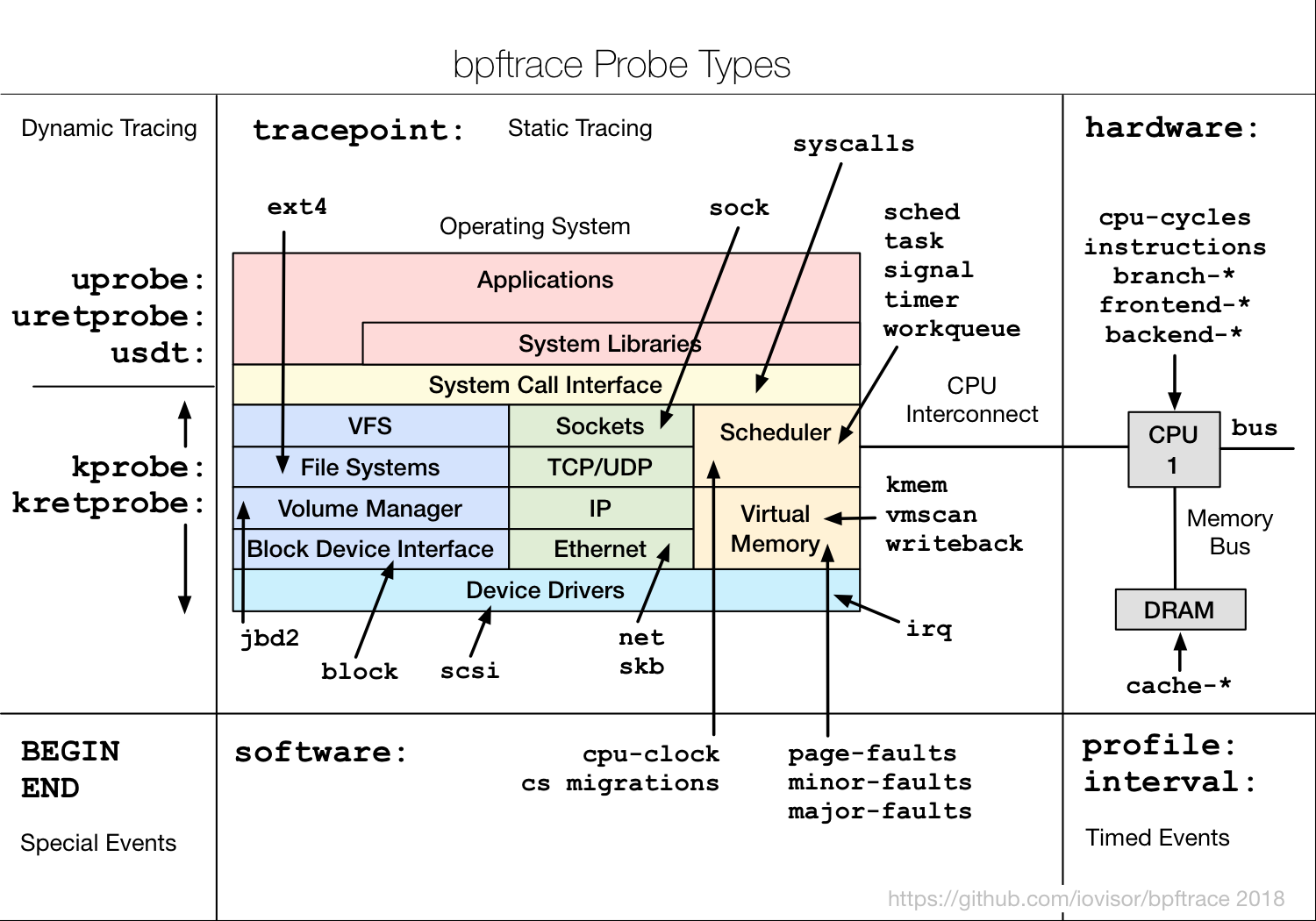
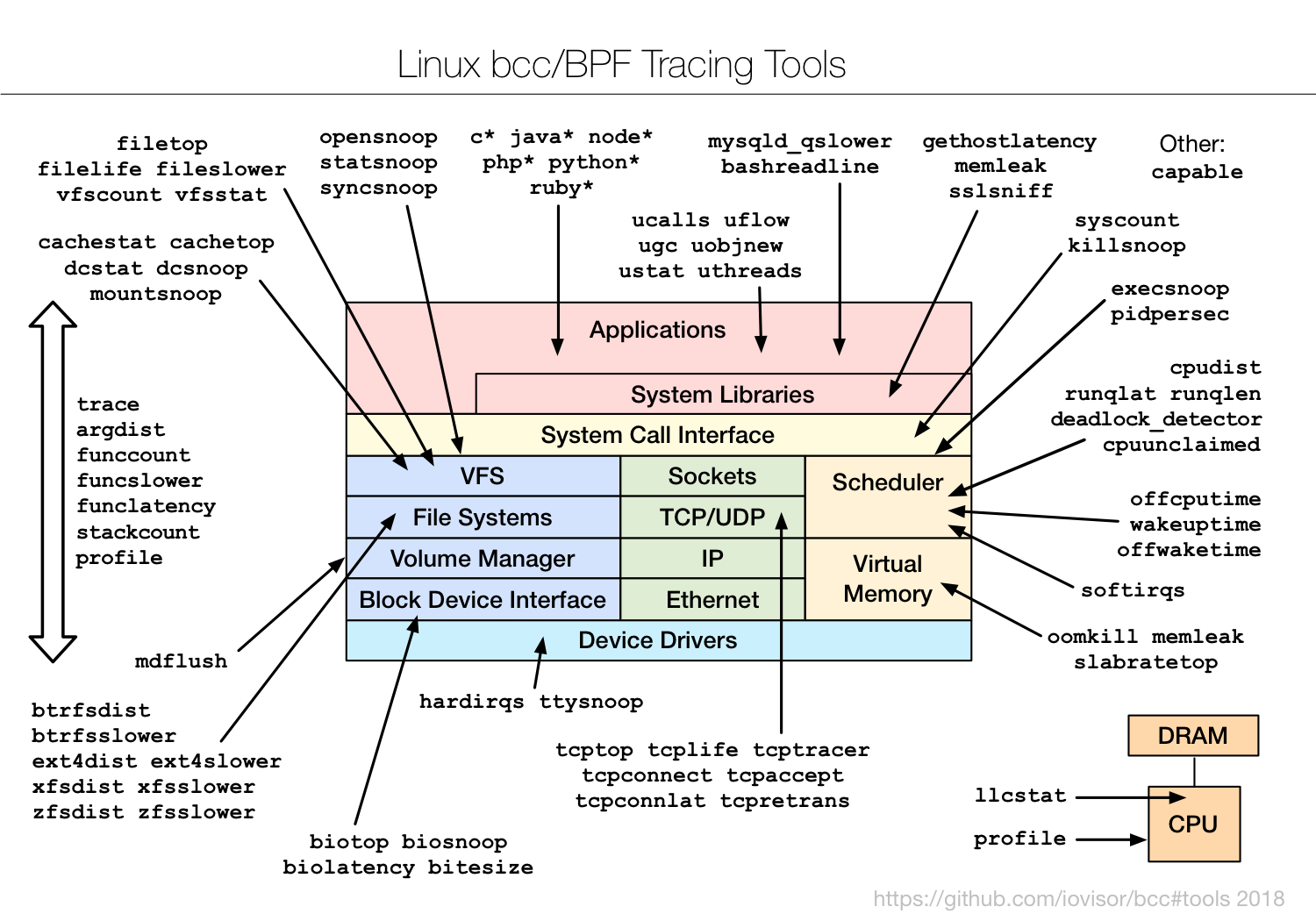
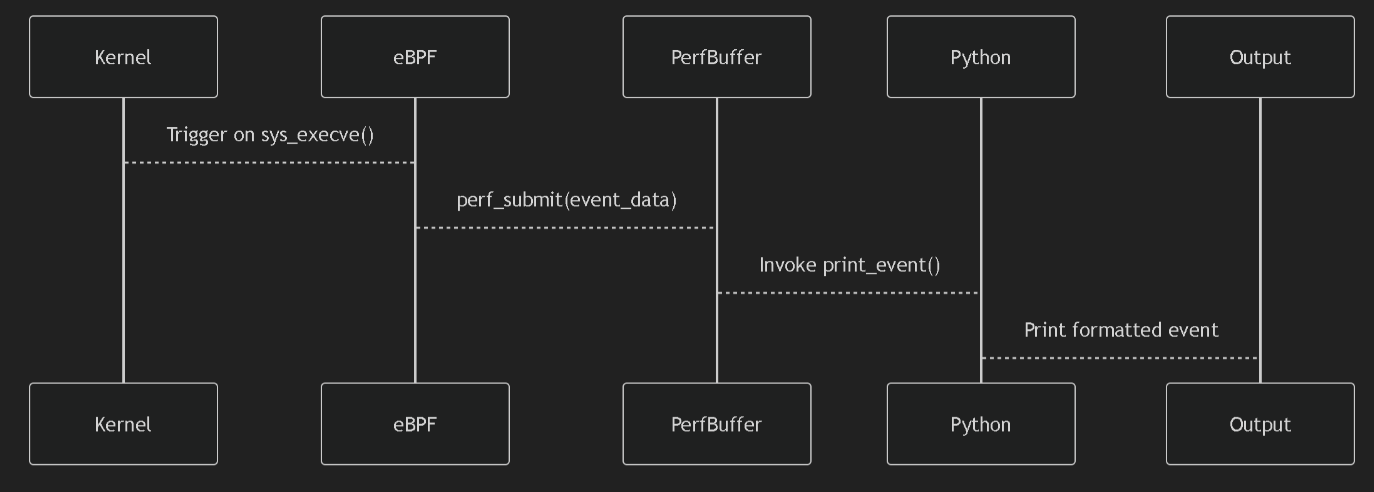
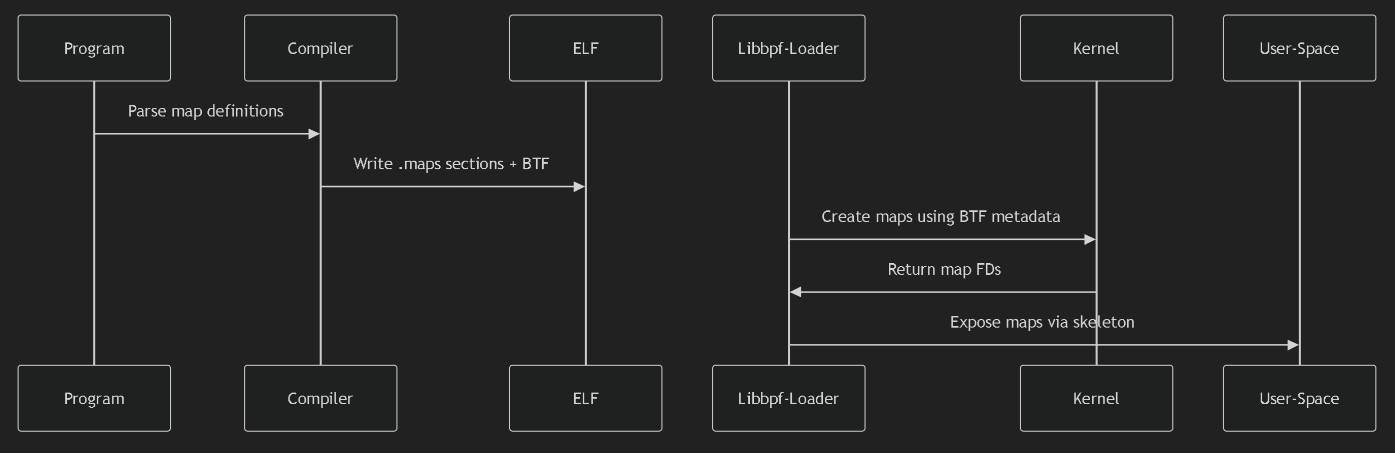
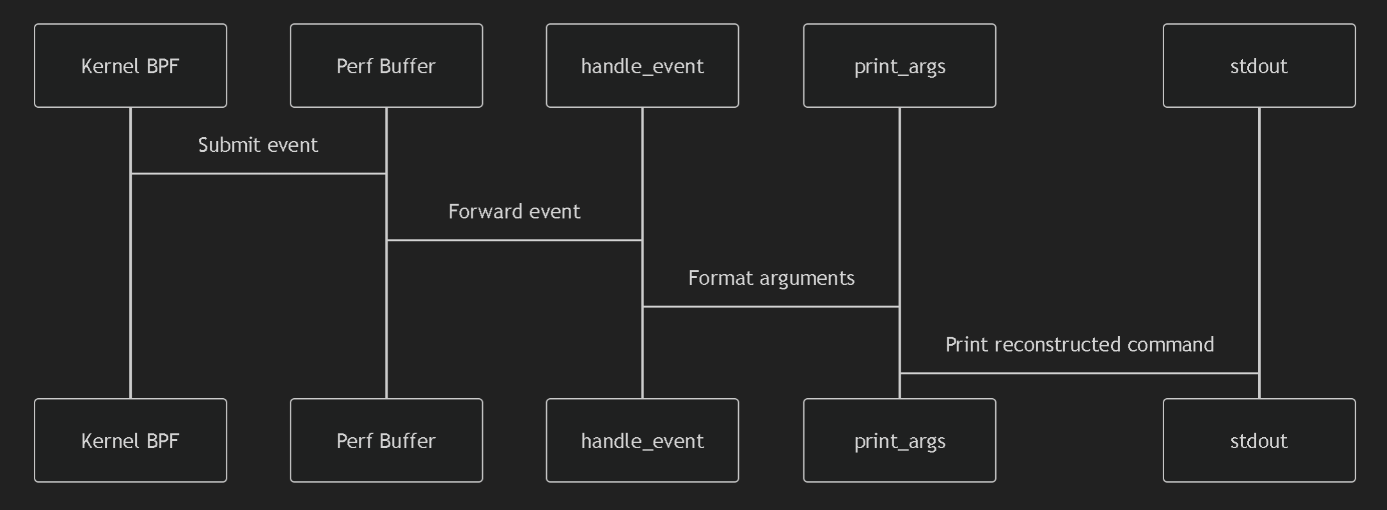
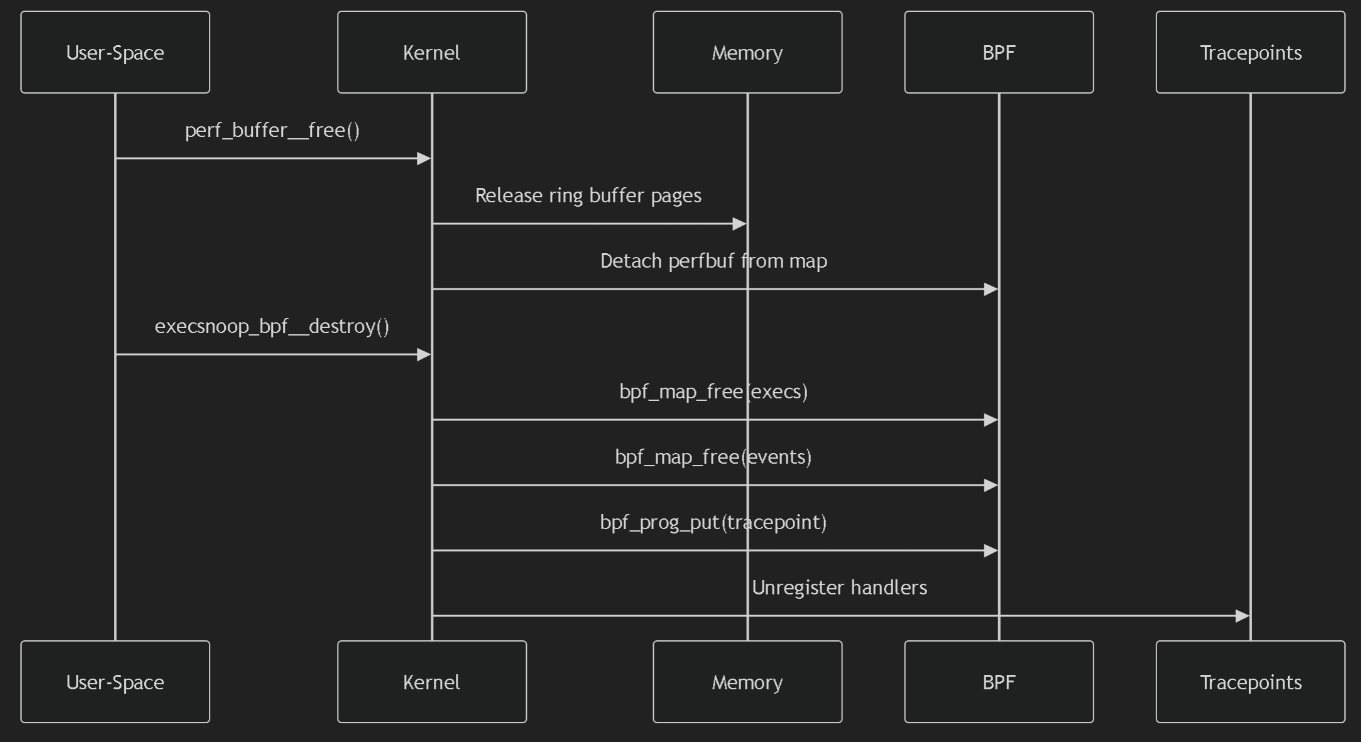
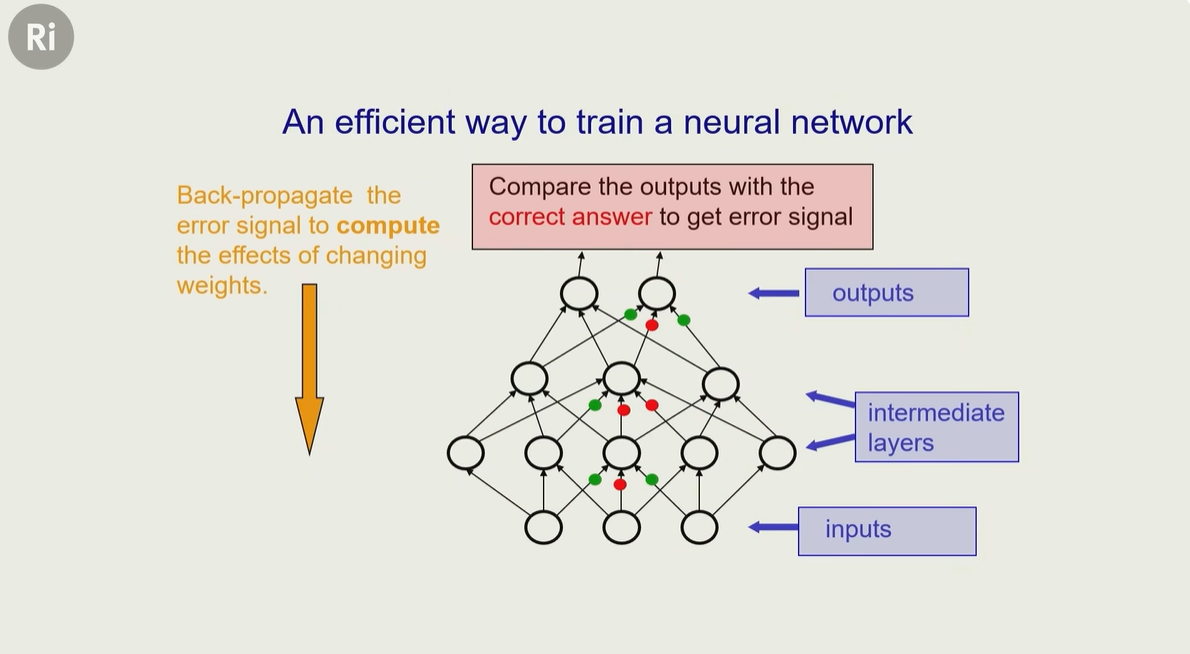
海边徒步和骑行 2025年6月3日 | 旅行 一次日照、青岛旅行。包括:日照滨海国家森林公园、东夷小镇、万平海口风景区、湖边骑行;栈桥、琴屿路、鲁迅公园、八大关、中山公园小麦岛、唐岛湾骑行 < +23 > 阅读全文