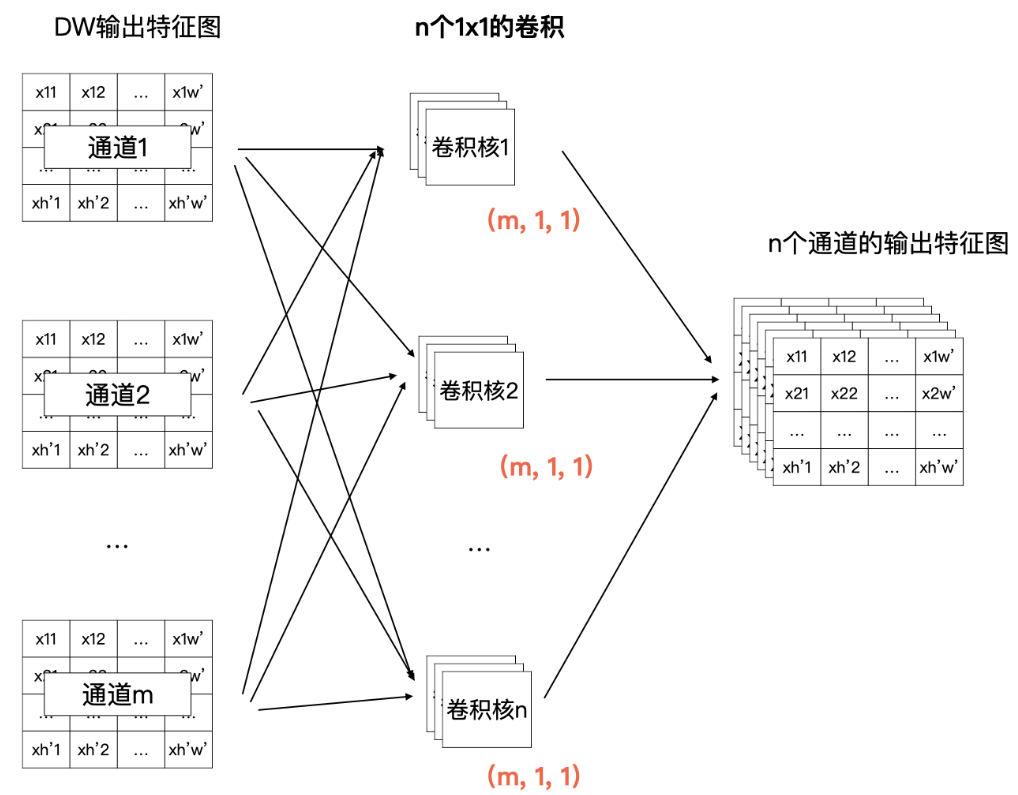
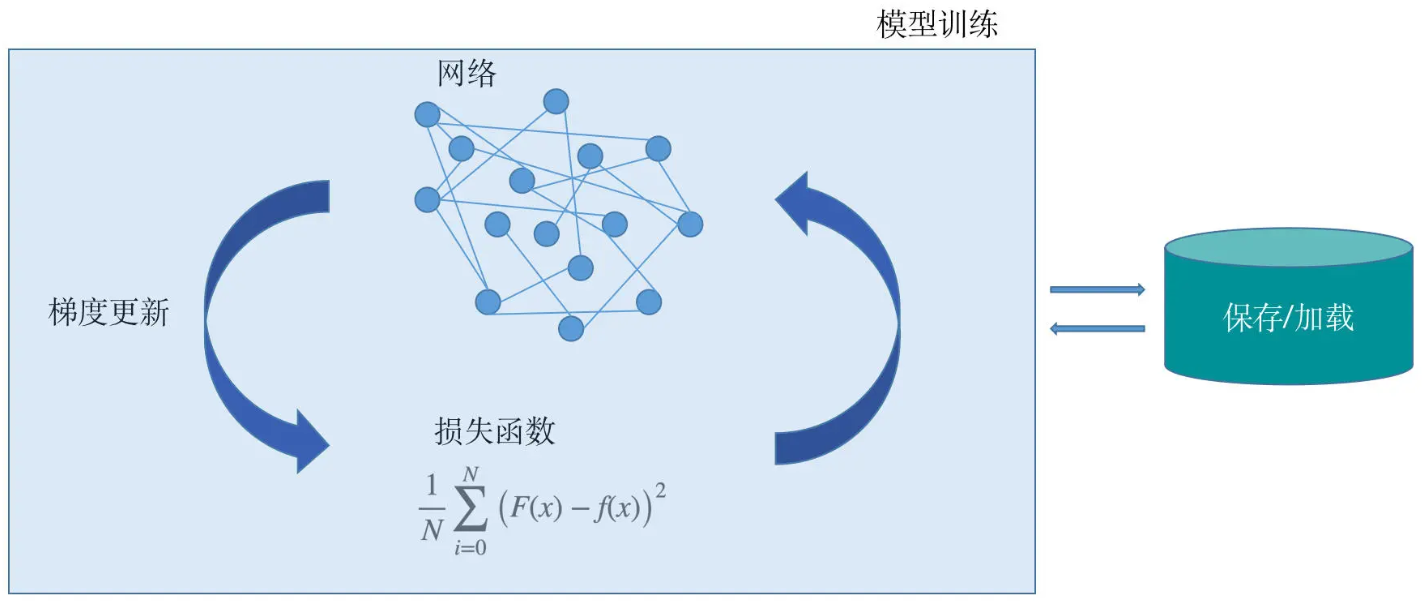
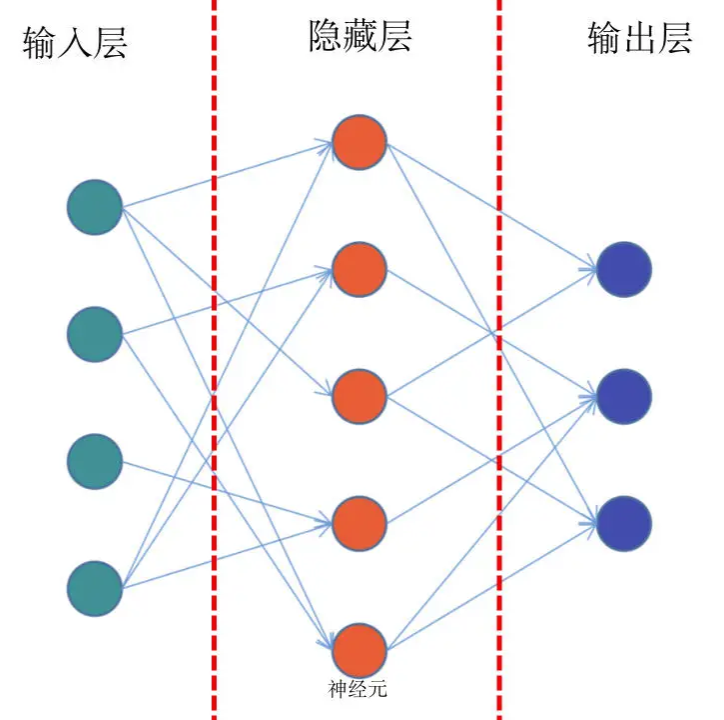
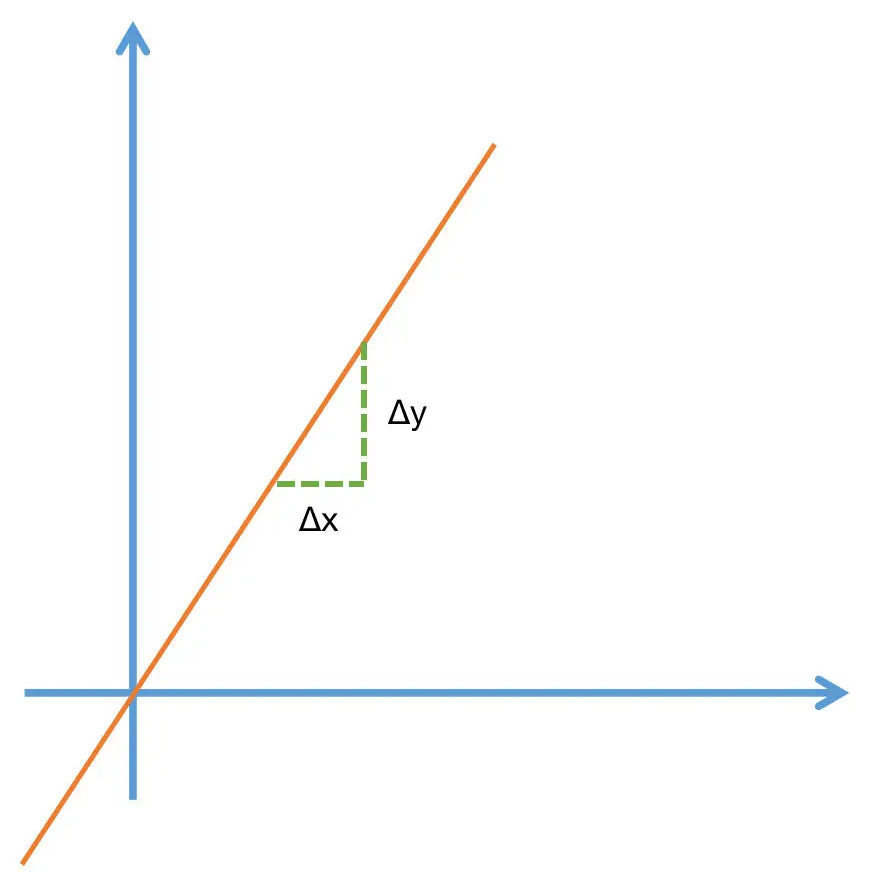
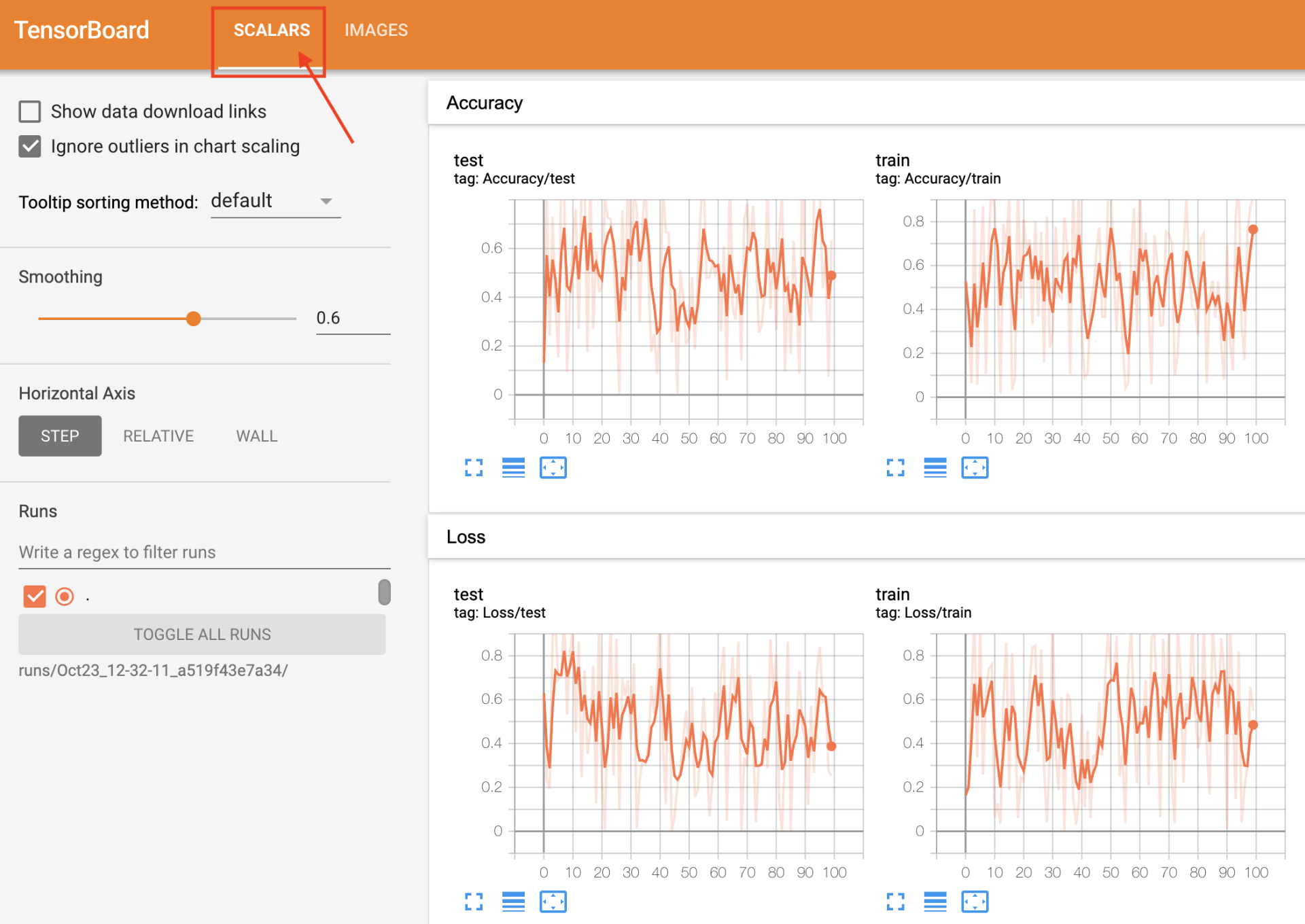
模型微调步骤
包括:
- 按任务类型拆开看图像、视频、音频、文本、多模态的微调差异
- 把数据准备、冻结层、学习率、LoRA/全参微调、评估与部署这些通用步骤串起来
- 补上梯度下降、导数这些基础概念,方便把工程流程和模型原理接上
包括:
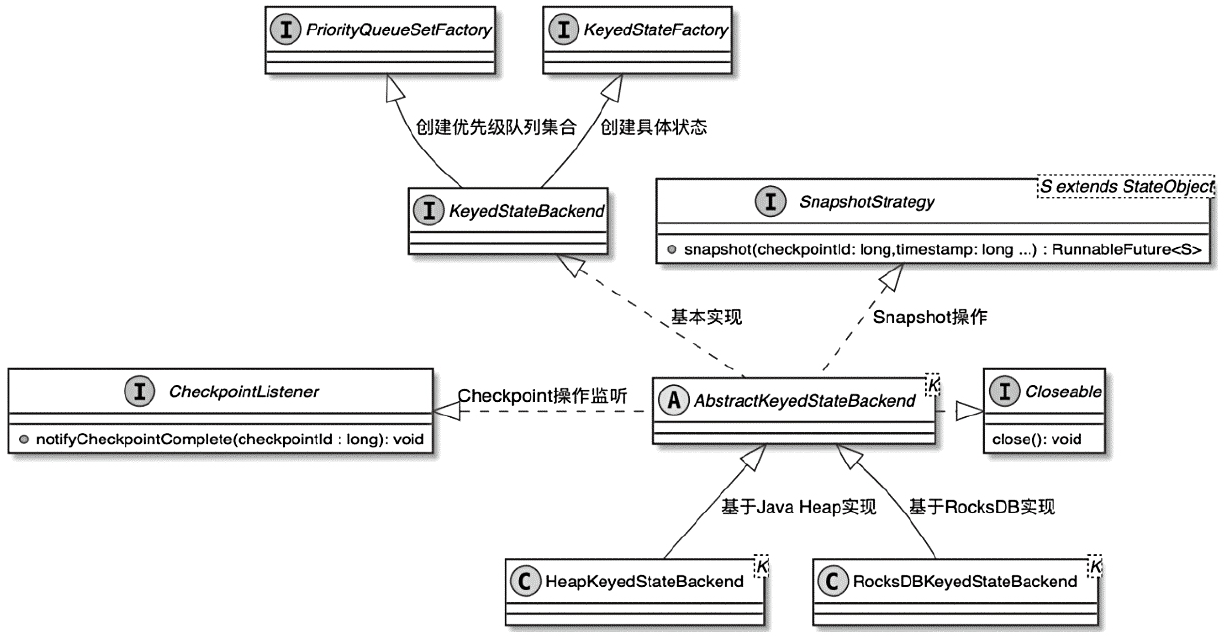
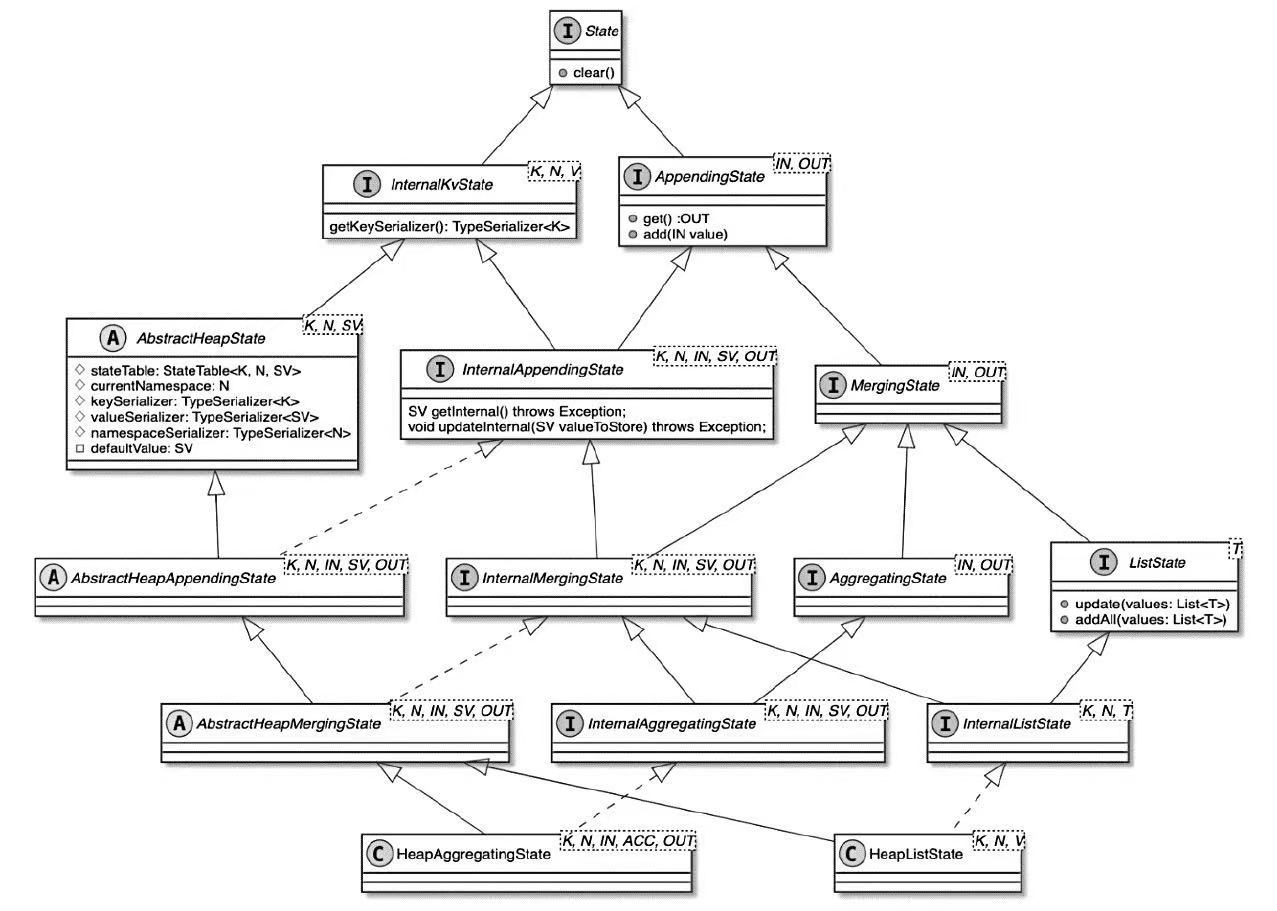
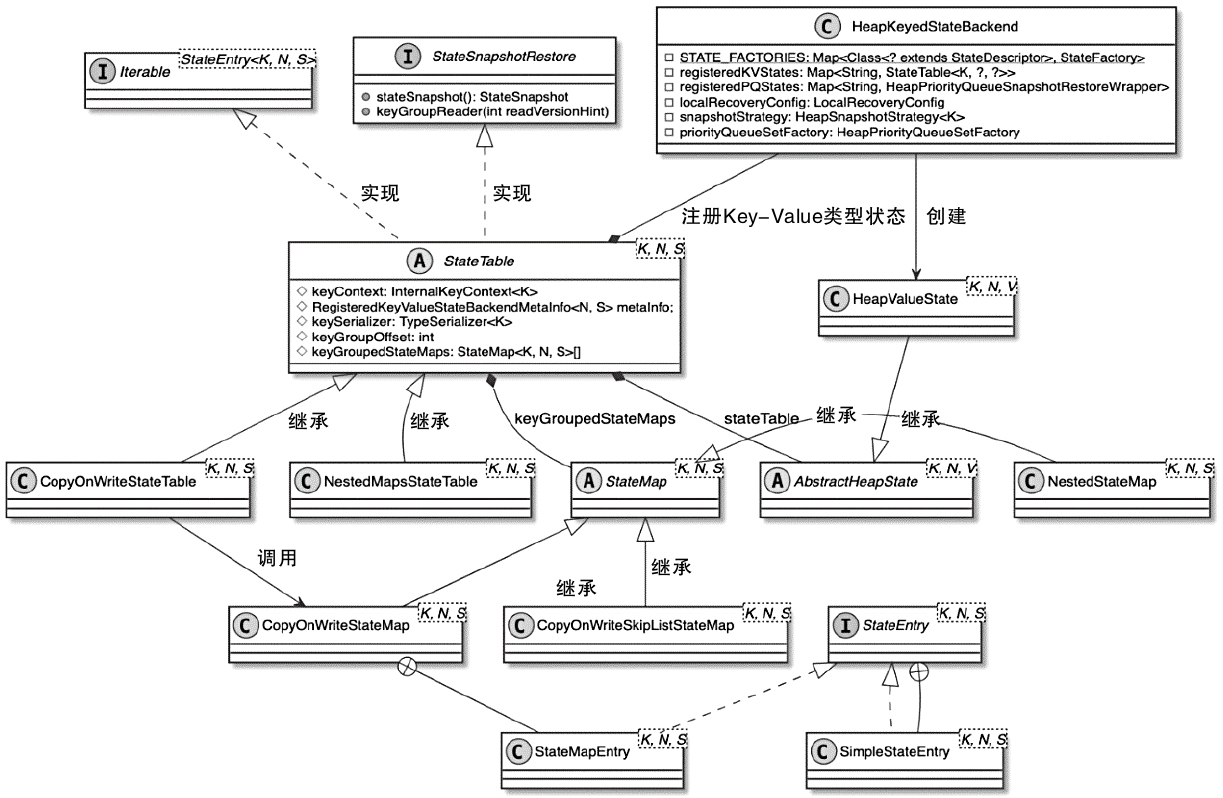
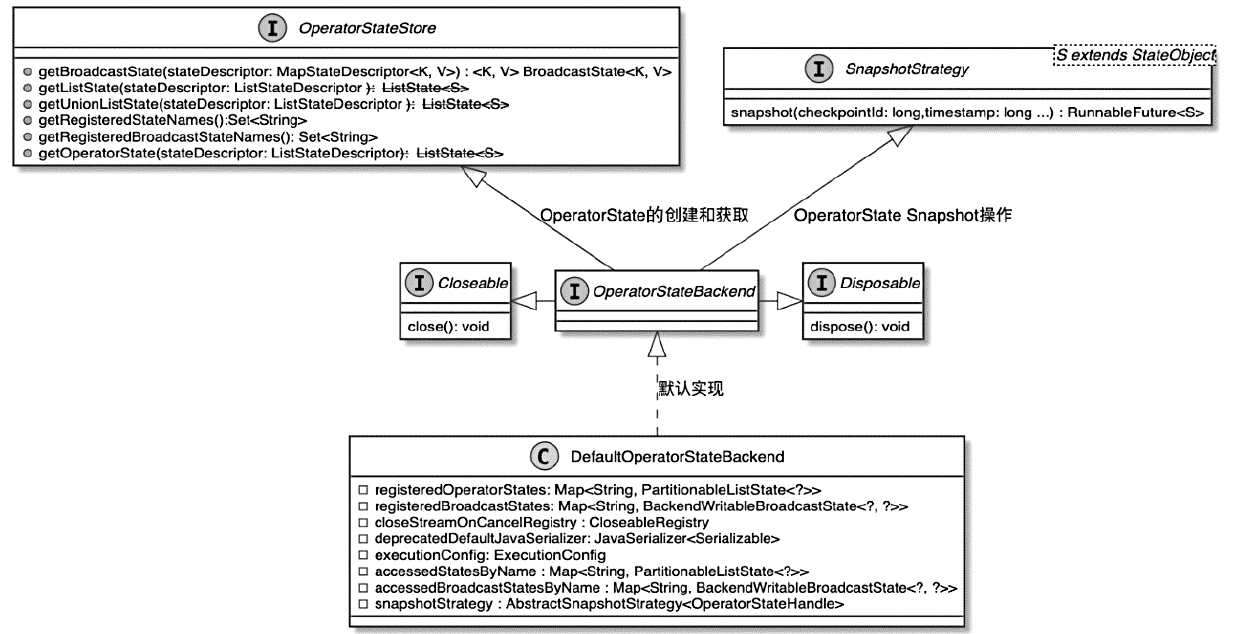
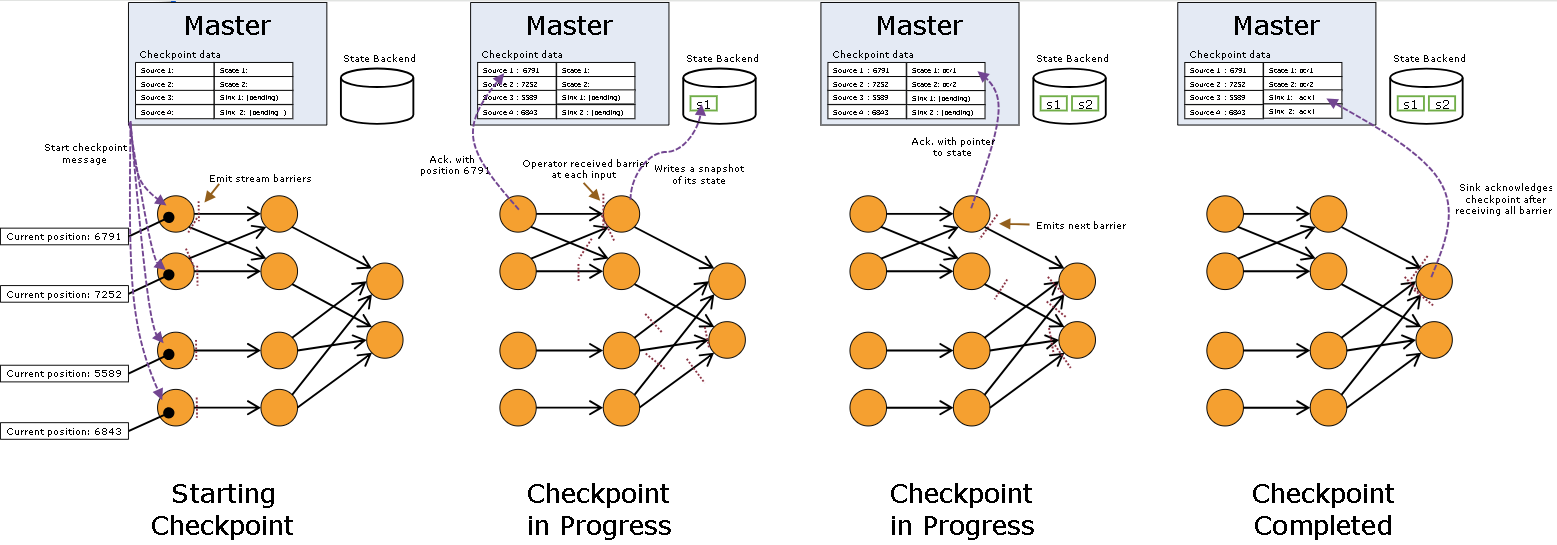
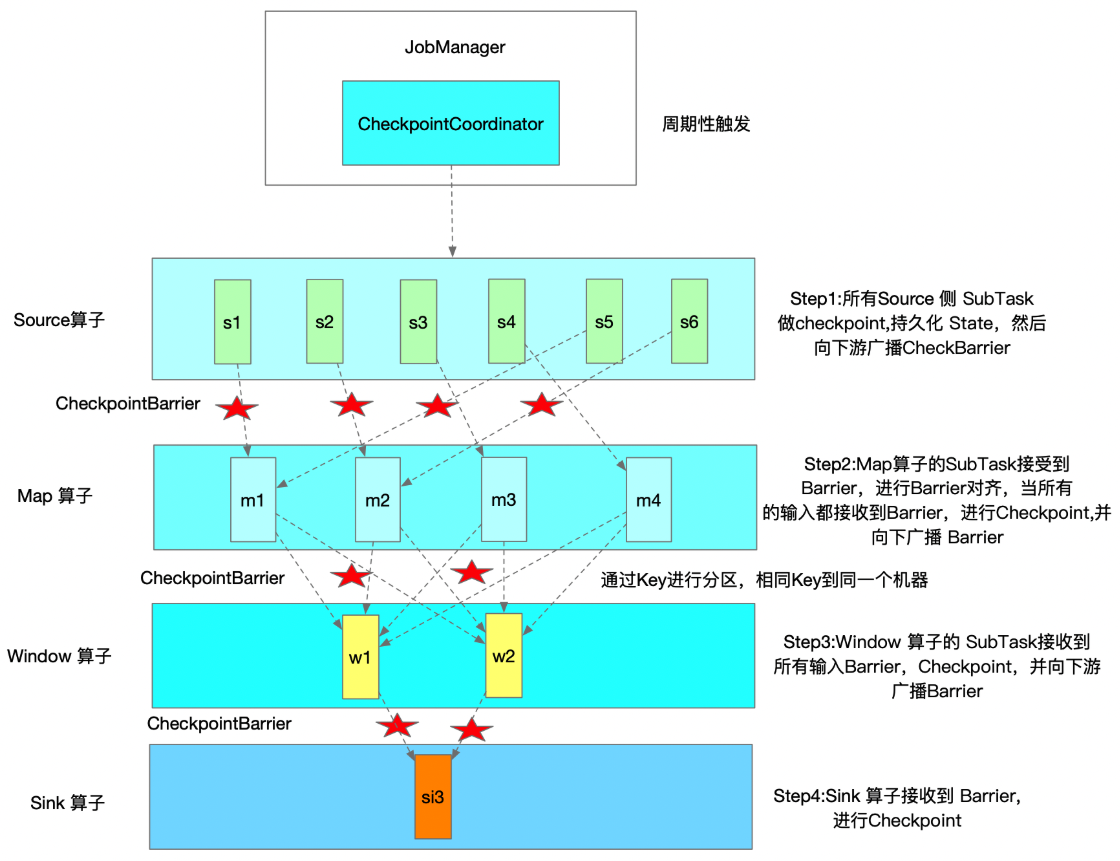
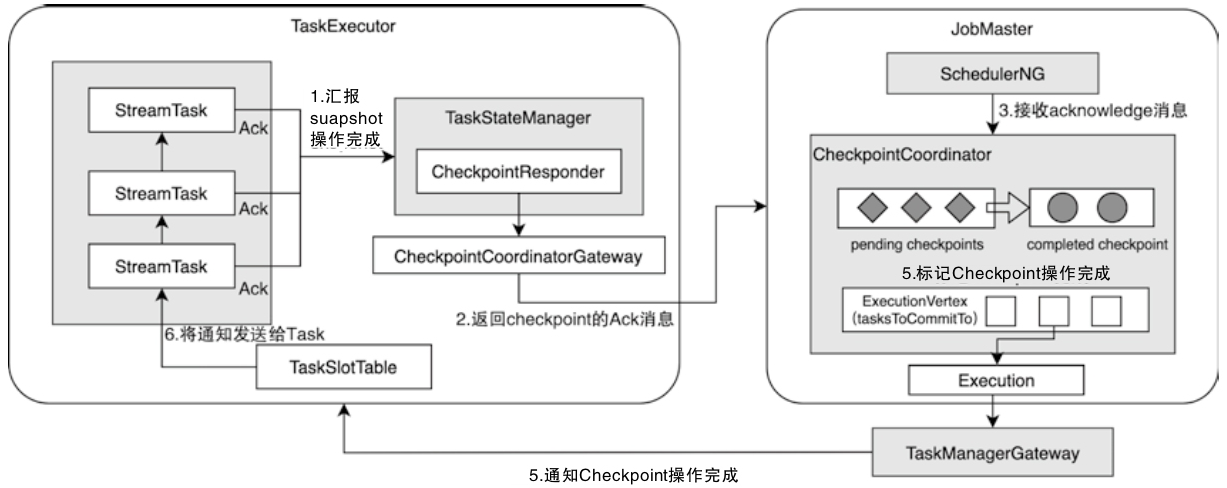
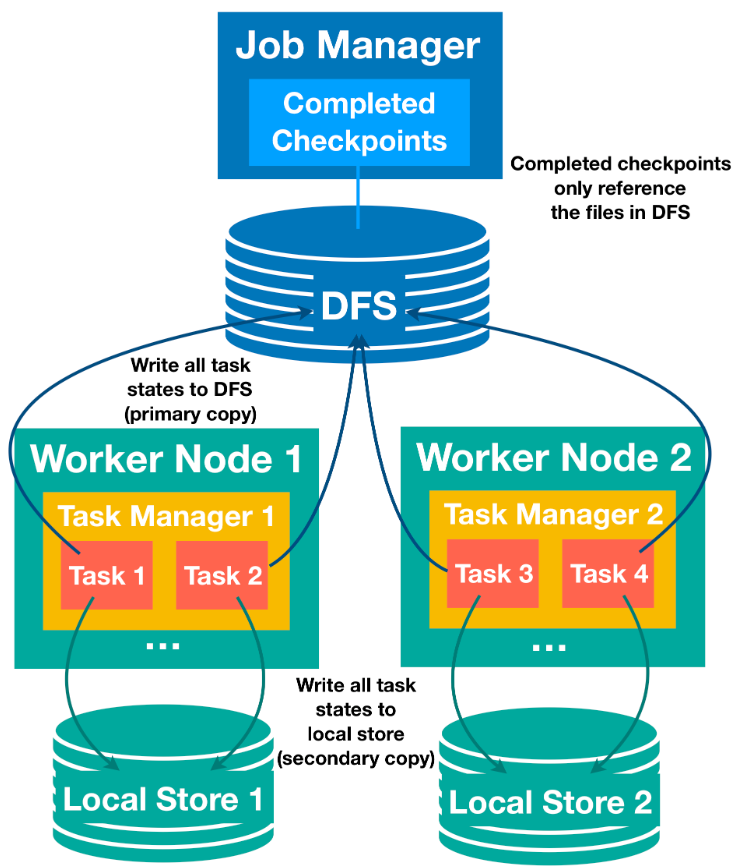
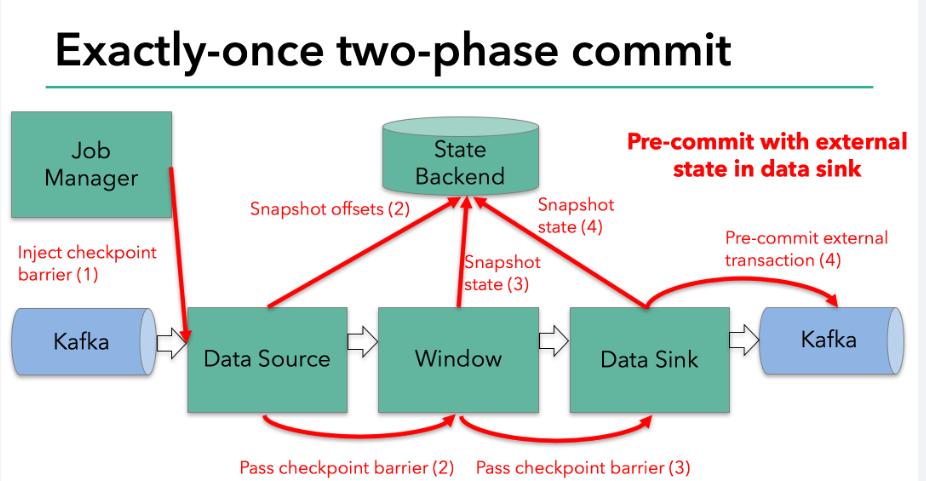
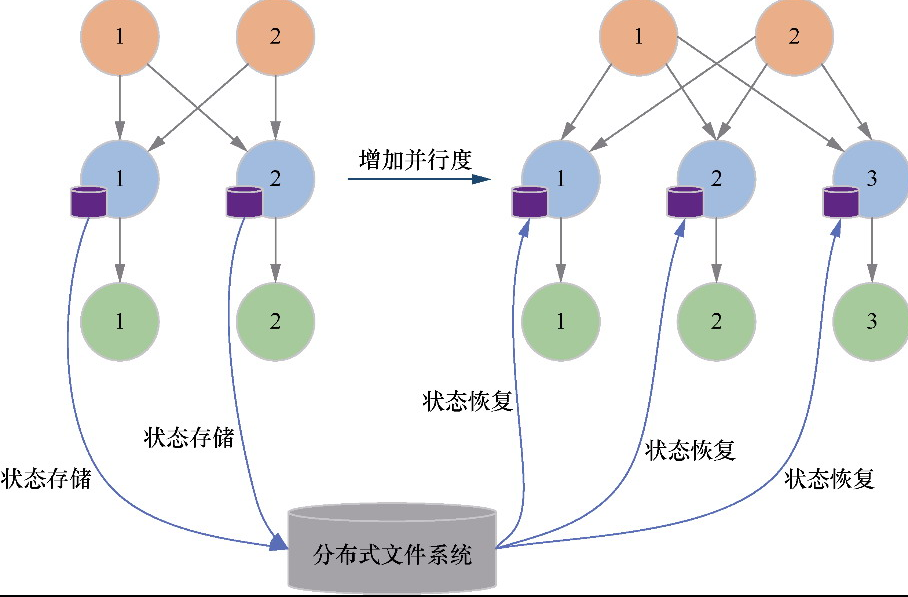
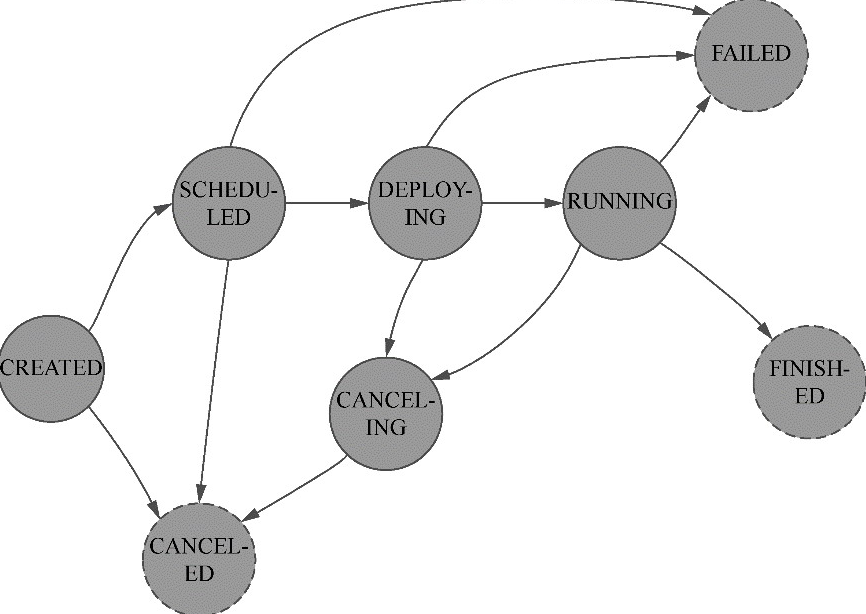
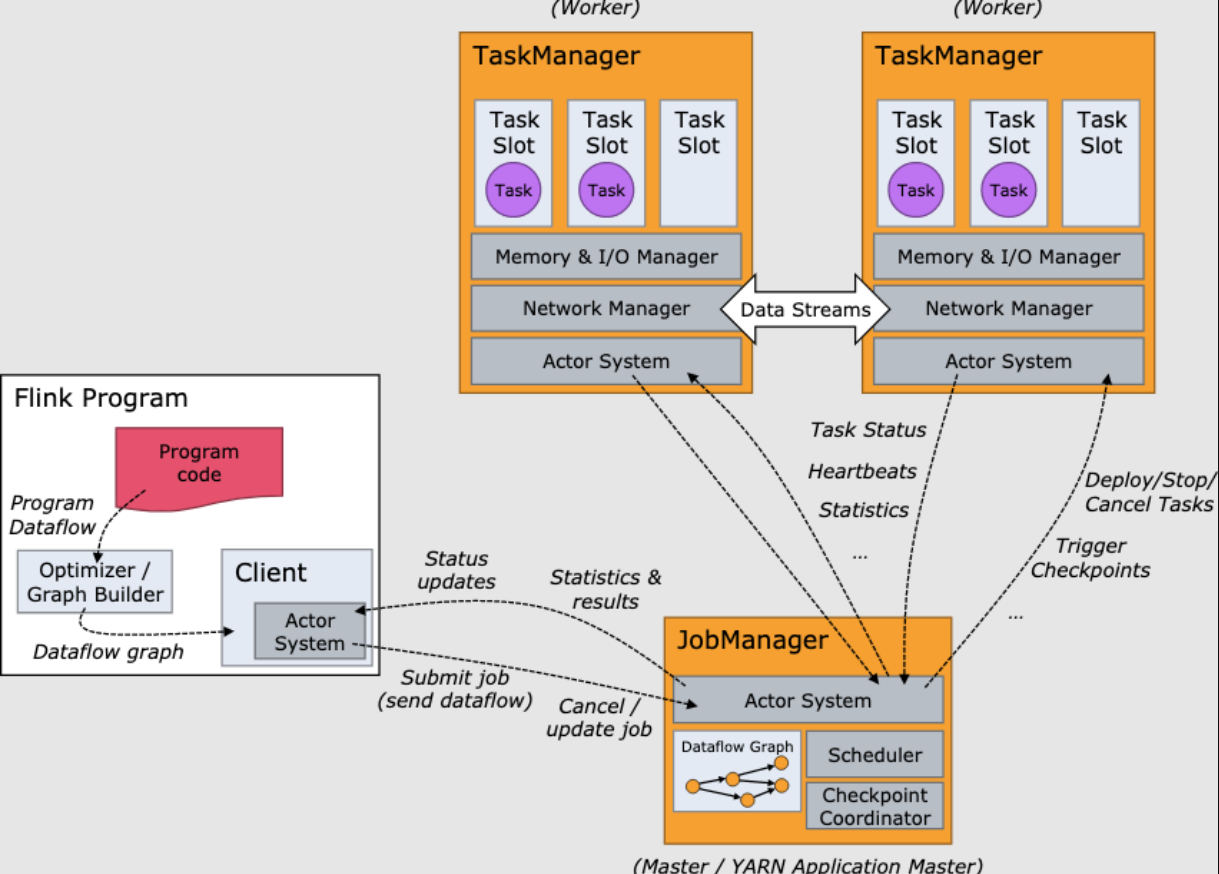
把 Flink 的状态数据、后端实现和 checkpoint 主线串起来:
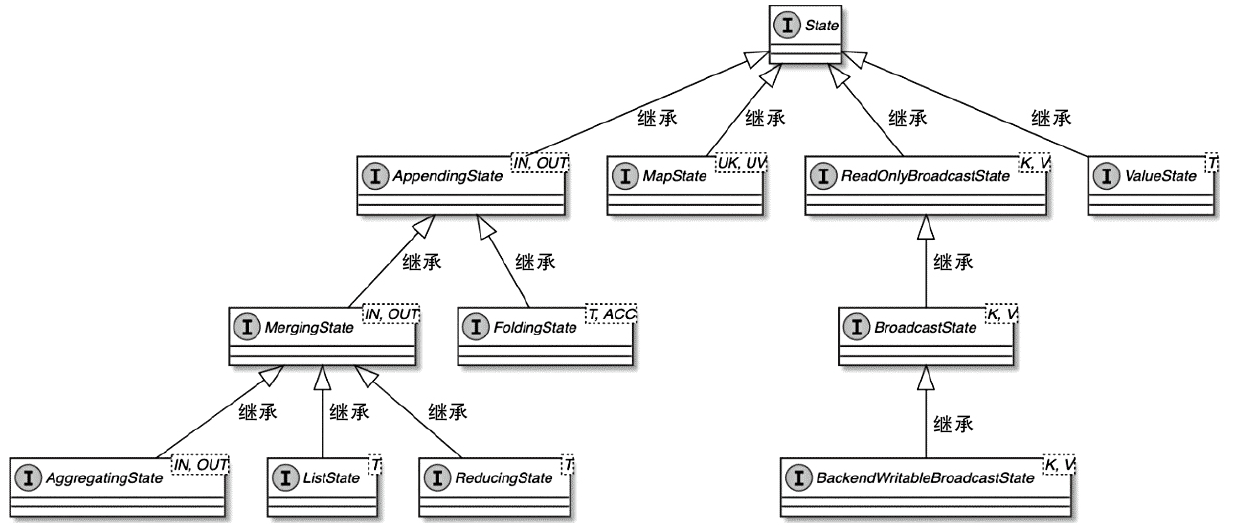
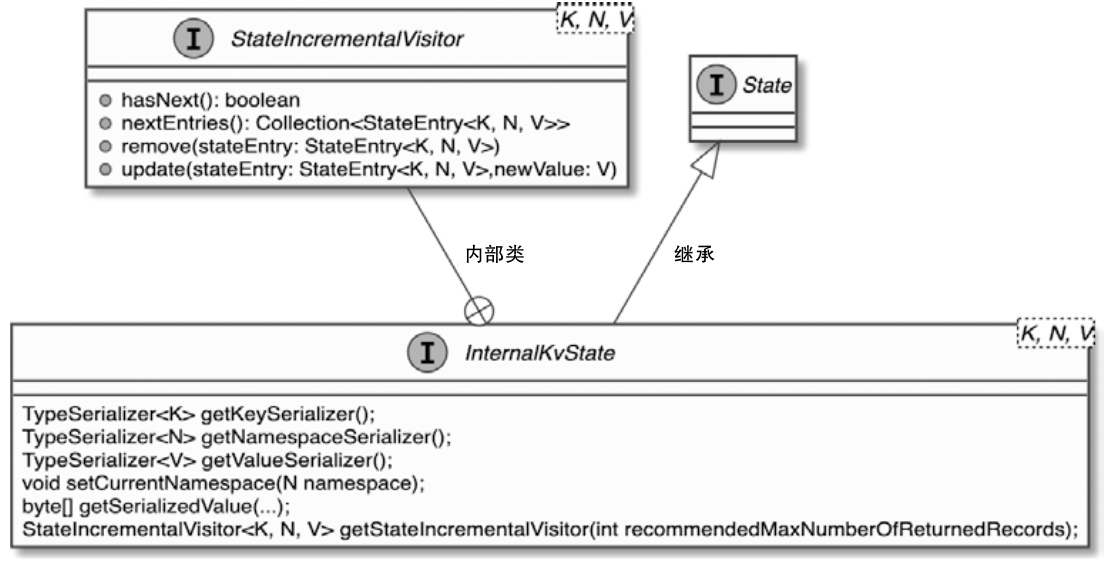
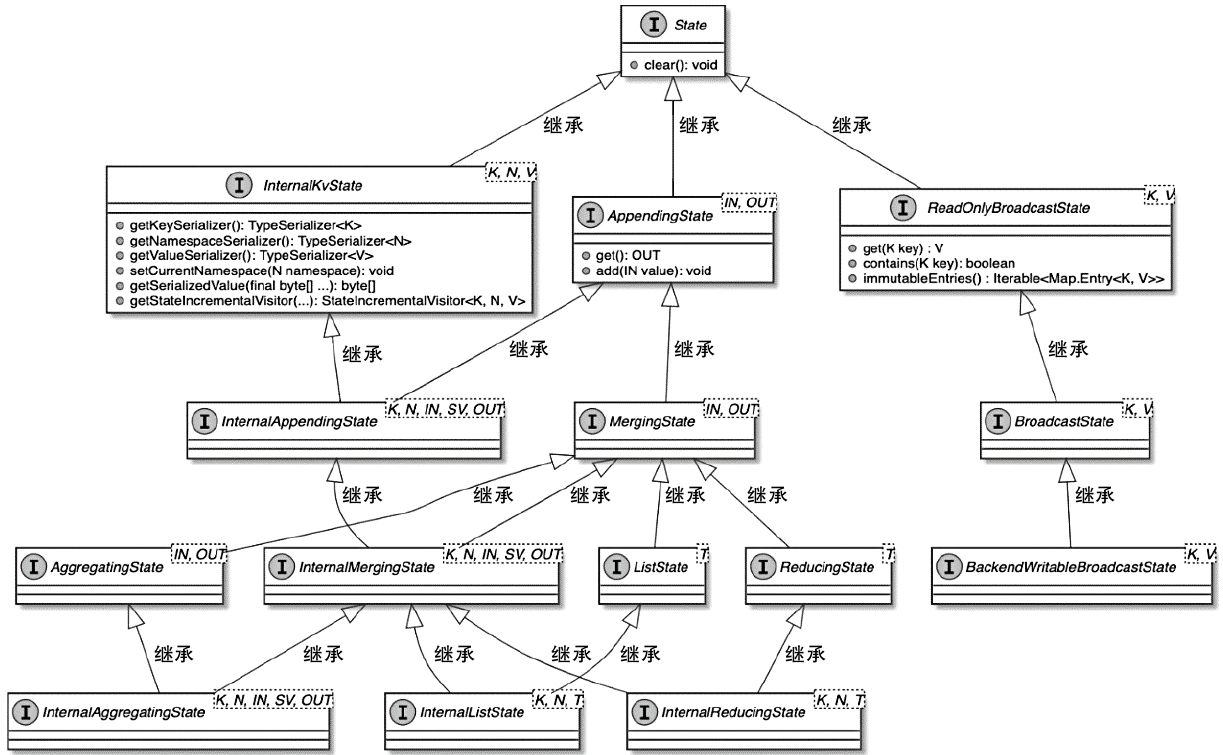
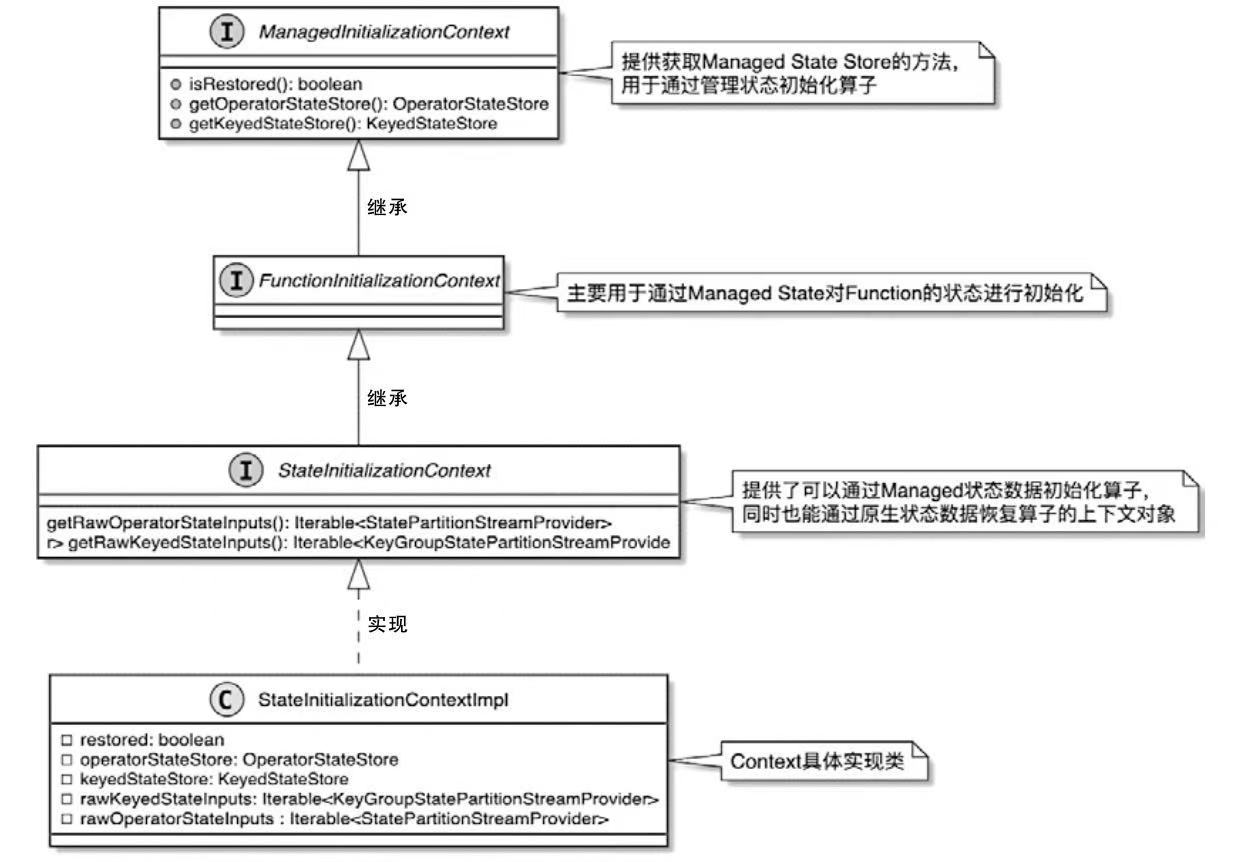
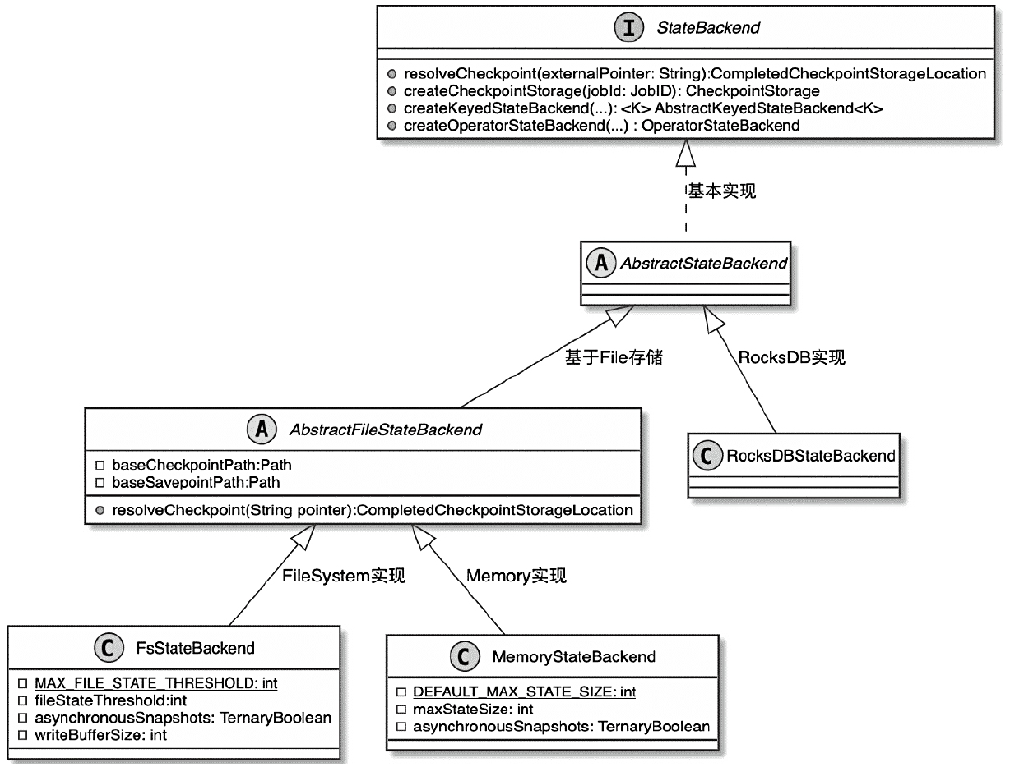
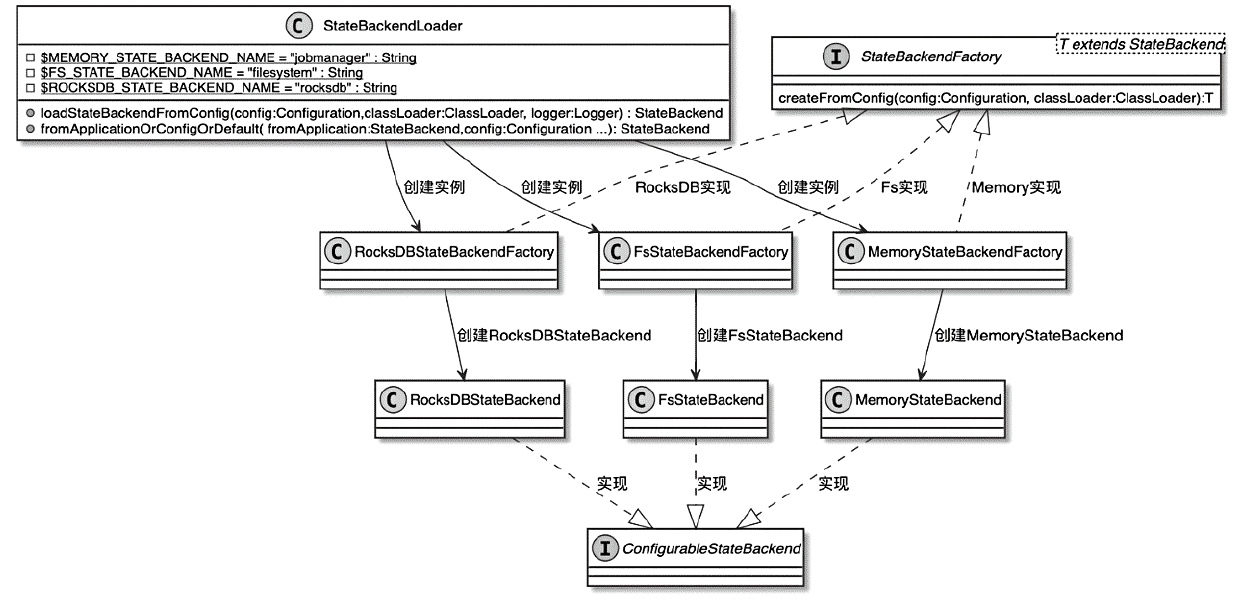
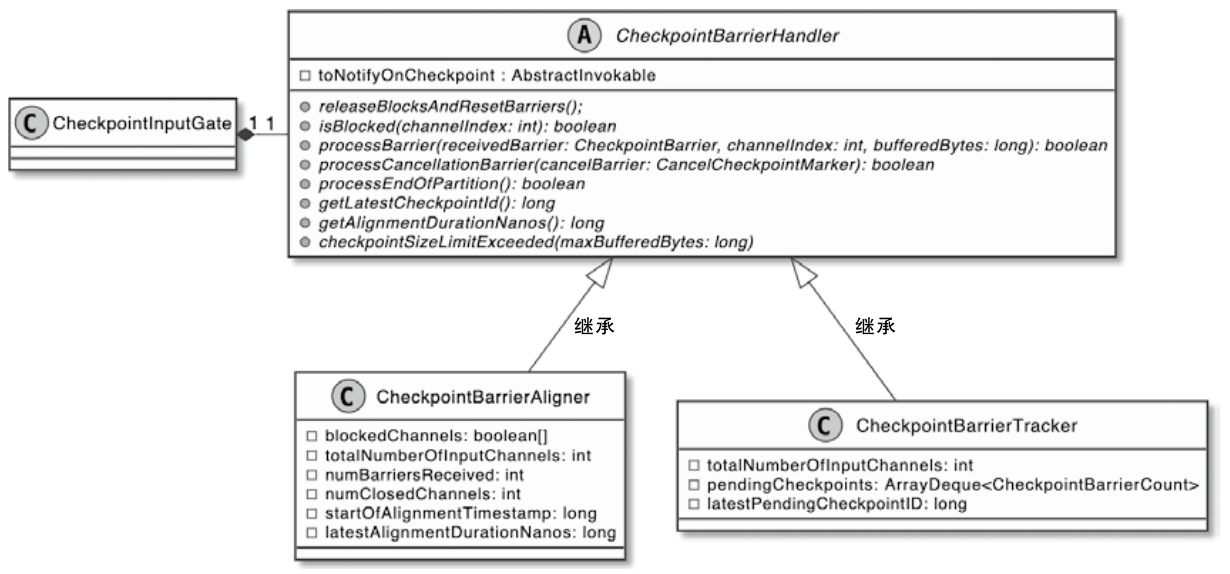
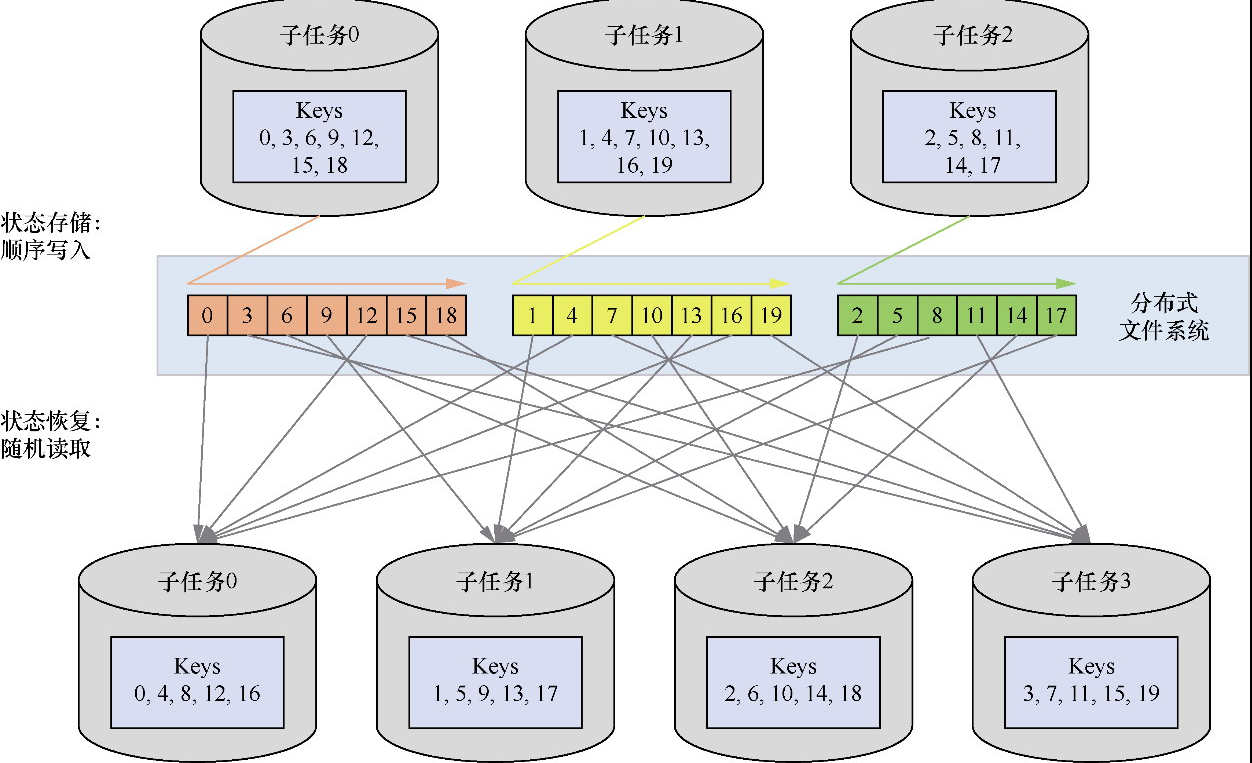
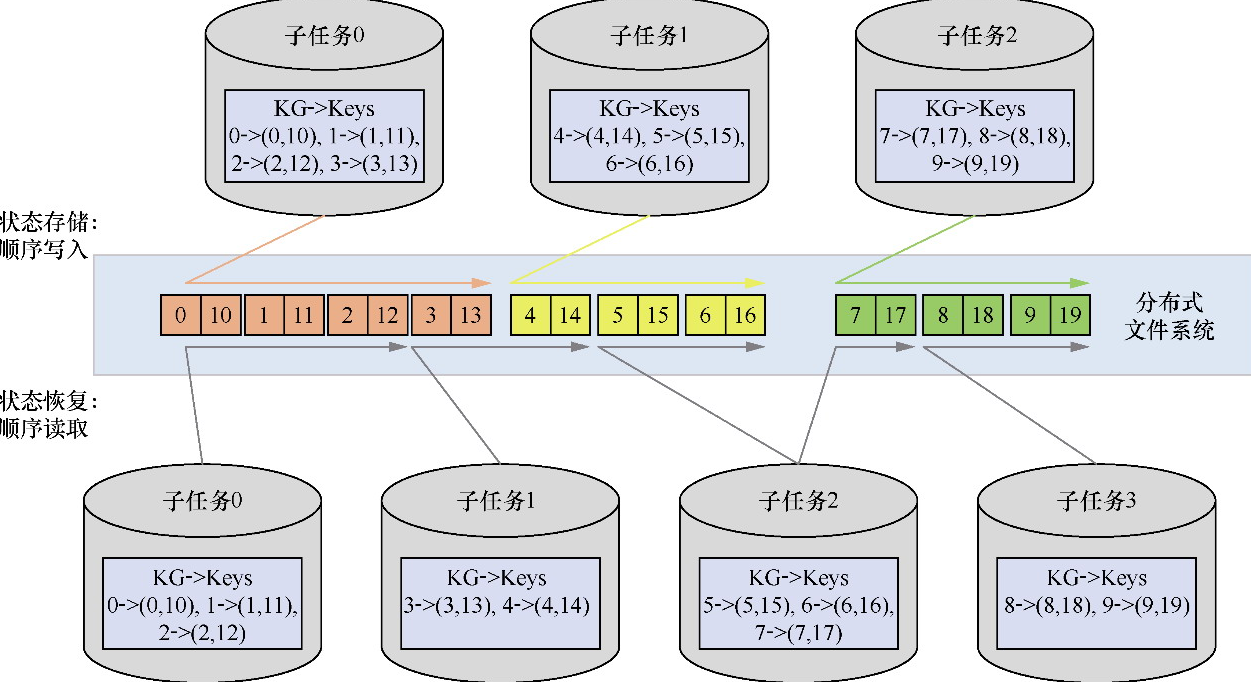
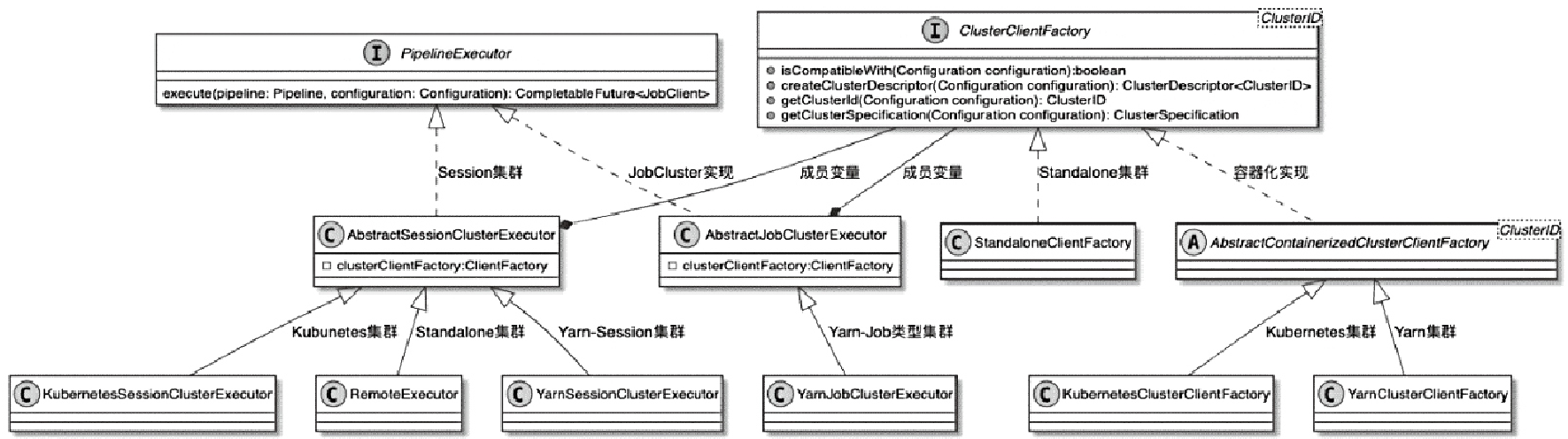
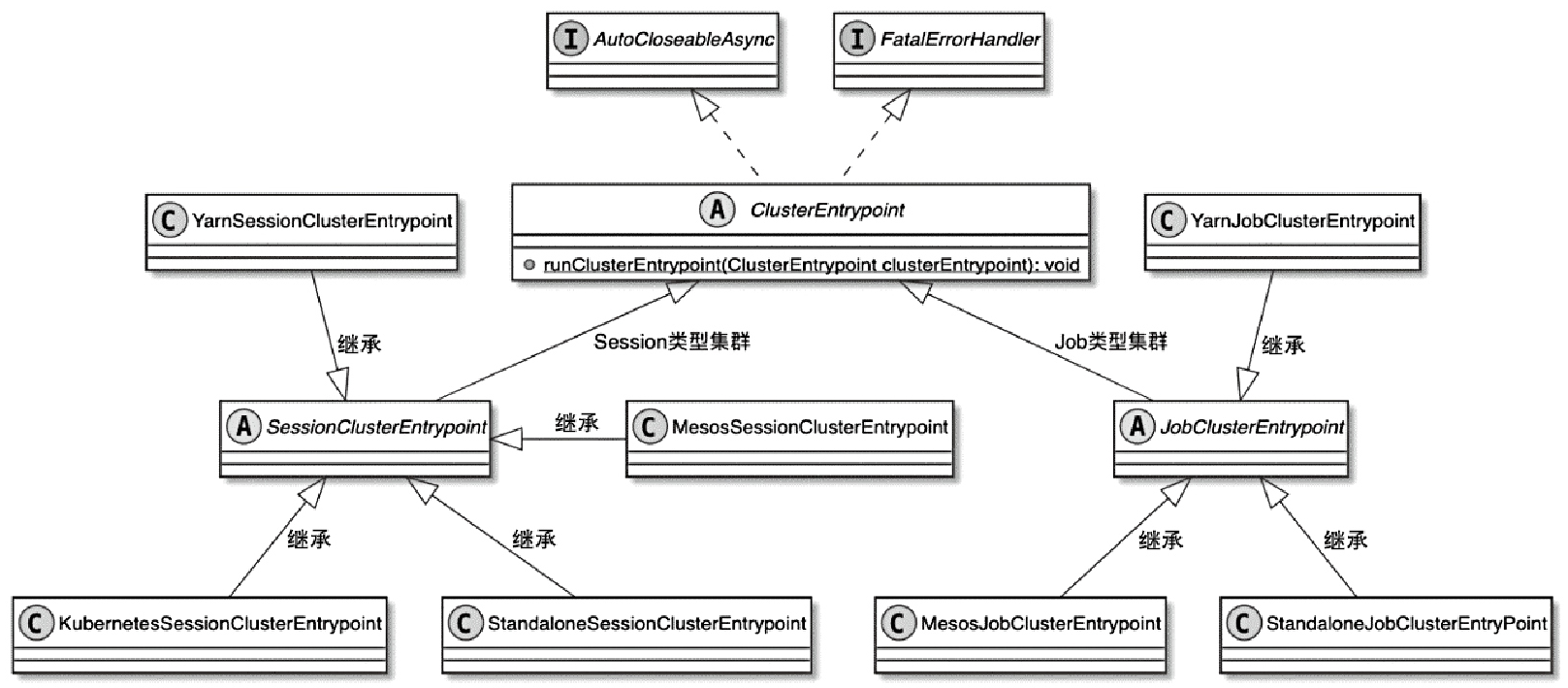
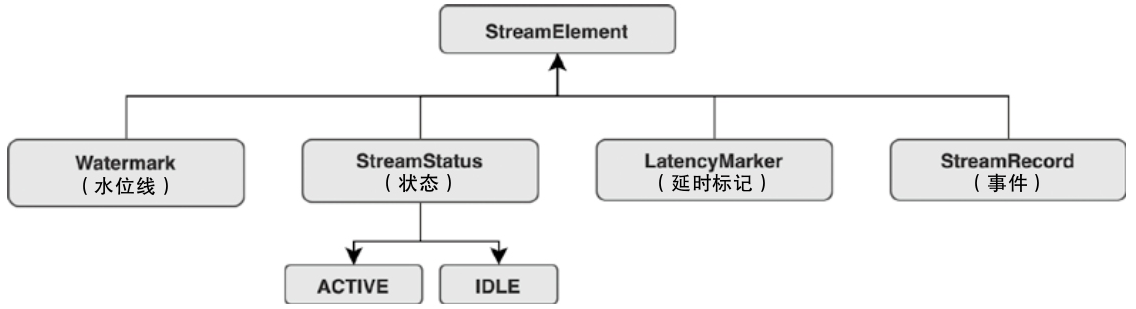
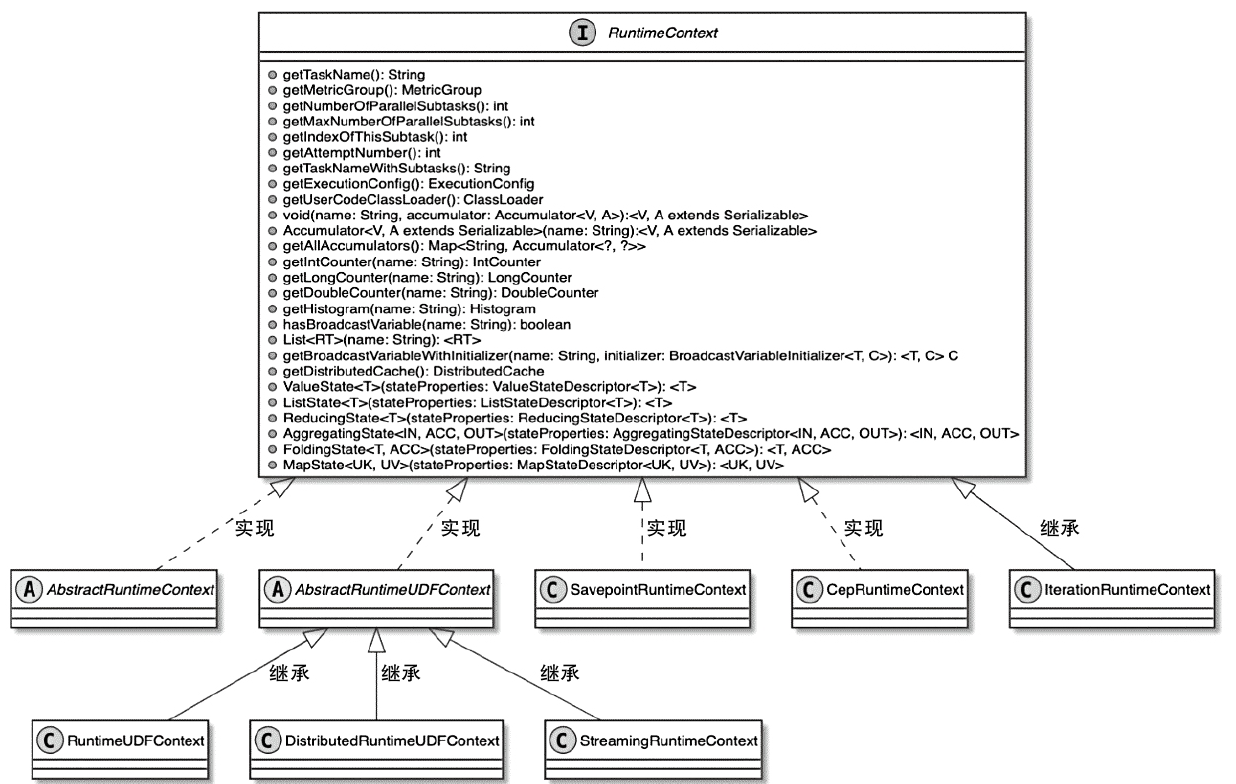
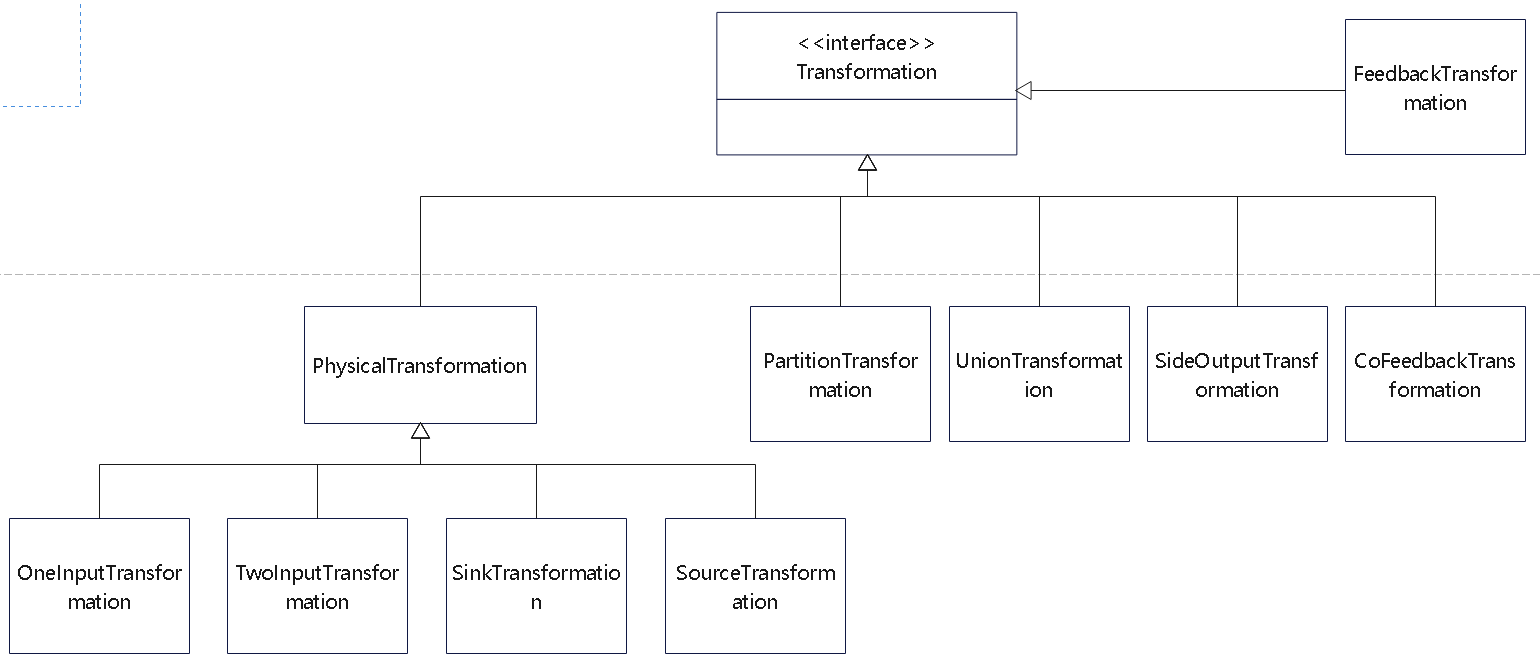
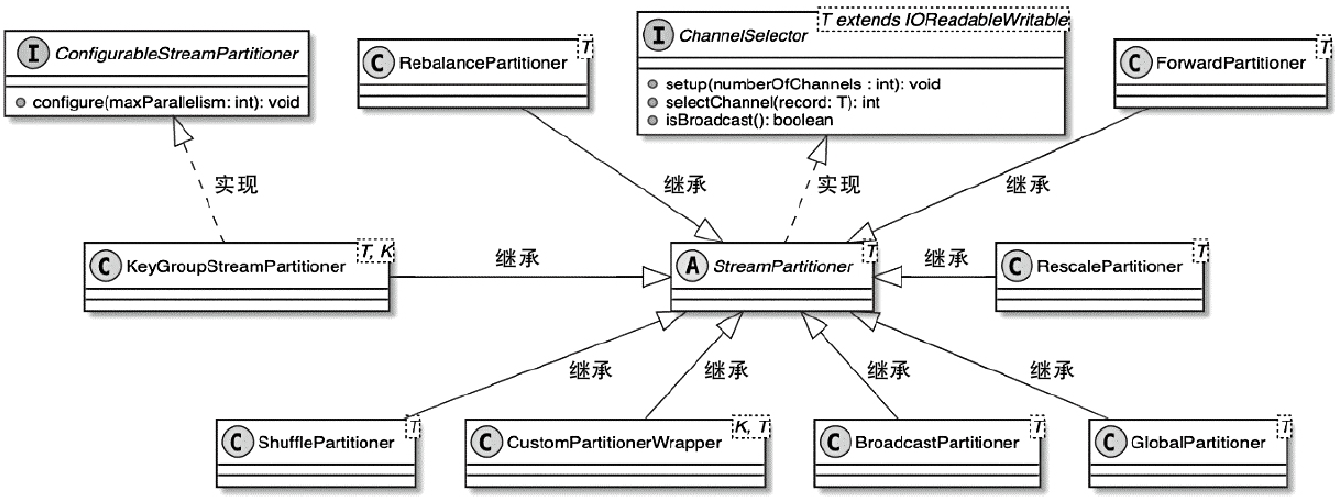
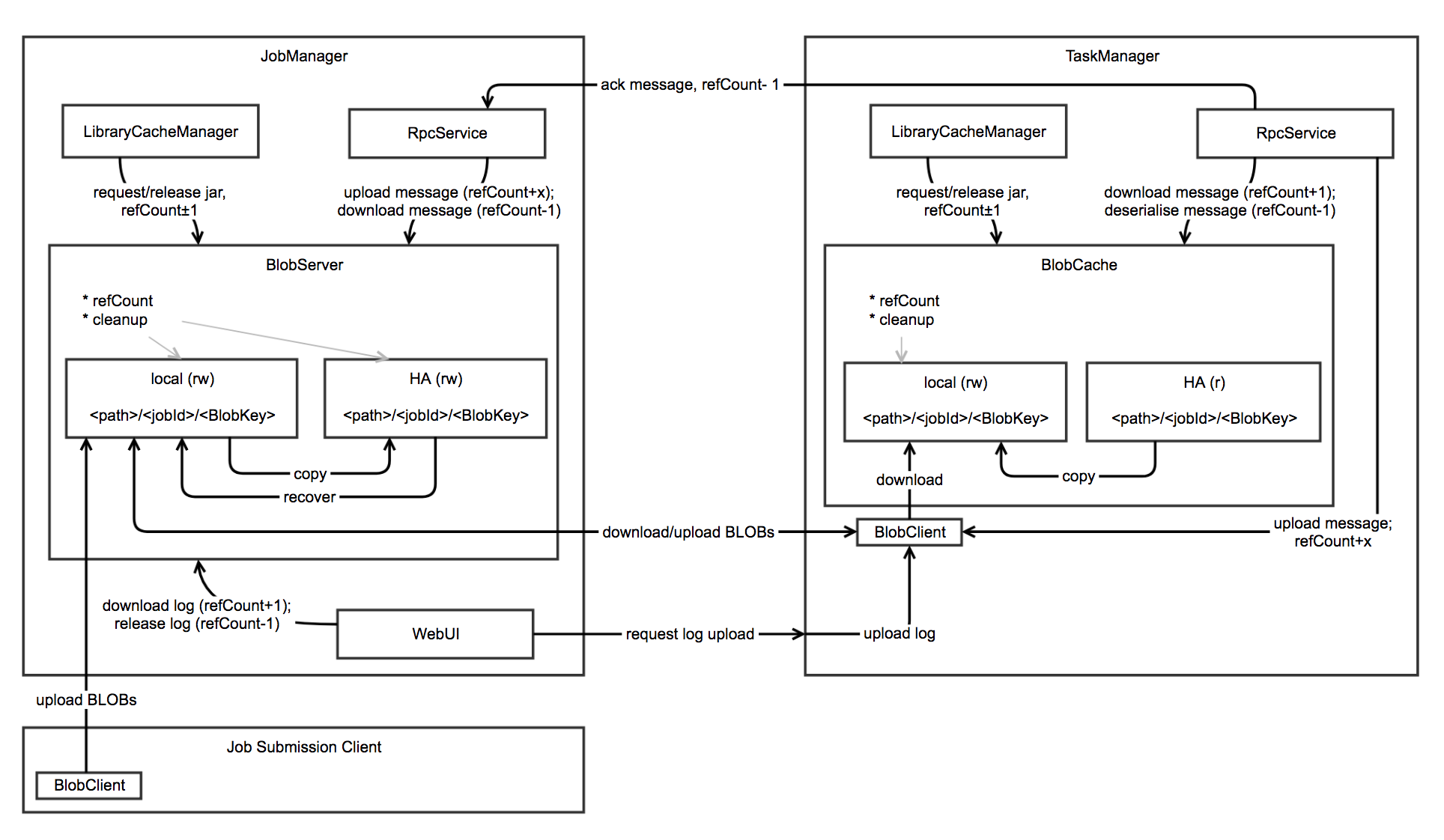
State 体系本身,包括 MapState、ValueState、BroadcastState 以及内部使用的 InternalKvStateKeyedState 和 OperatorState 两条实现路径,以及 Heap、RocksDB、StateTable、OperatorStateBackend 这些核心组件主要看 Flink 集群是怎么被创建出来、怎么和外部资源管理器打交道的,重点包括:
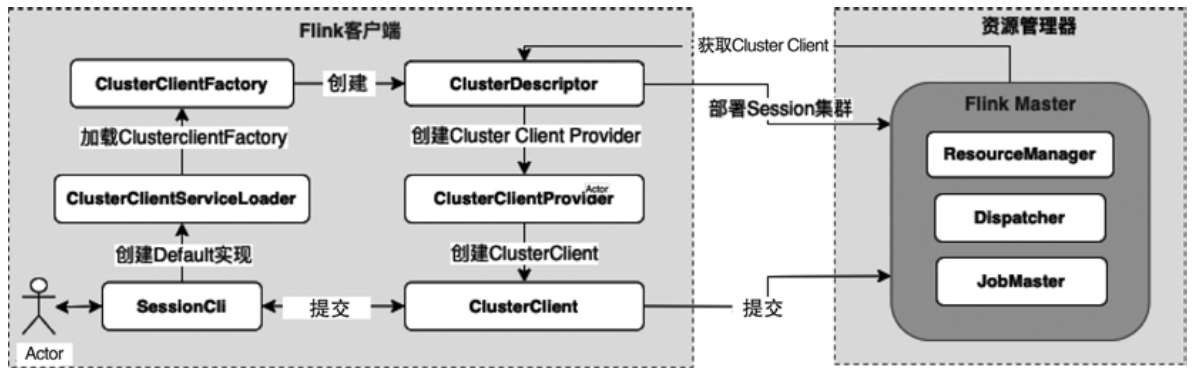
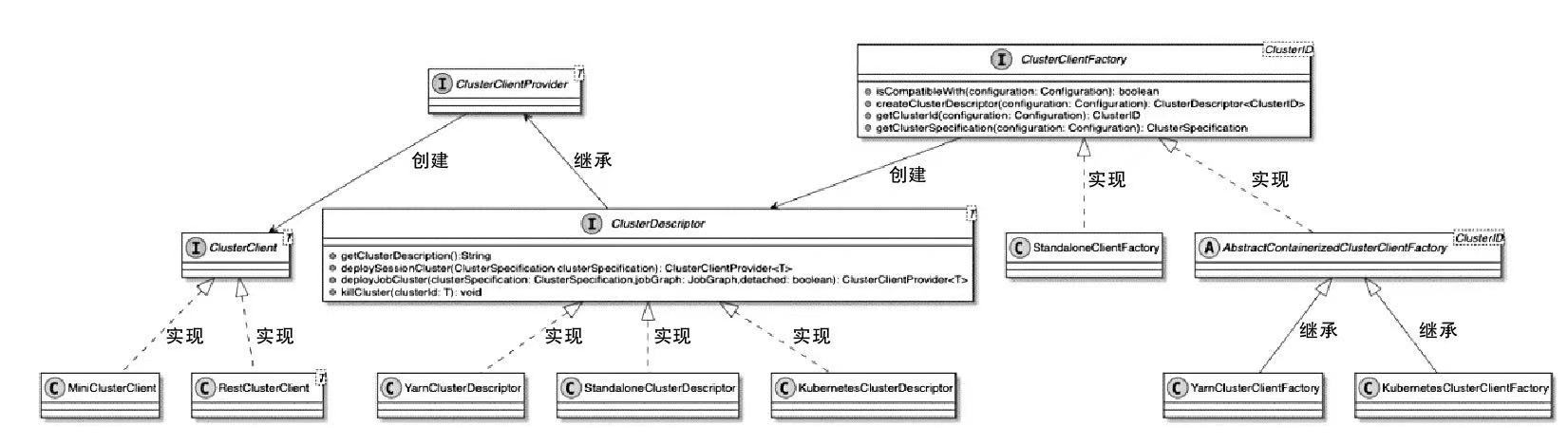
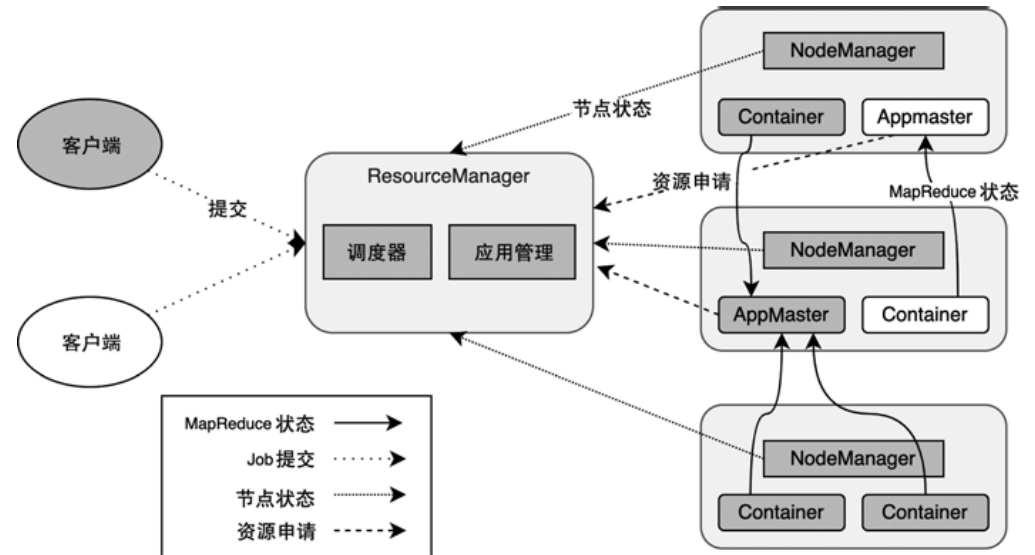
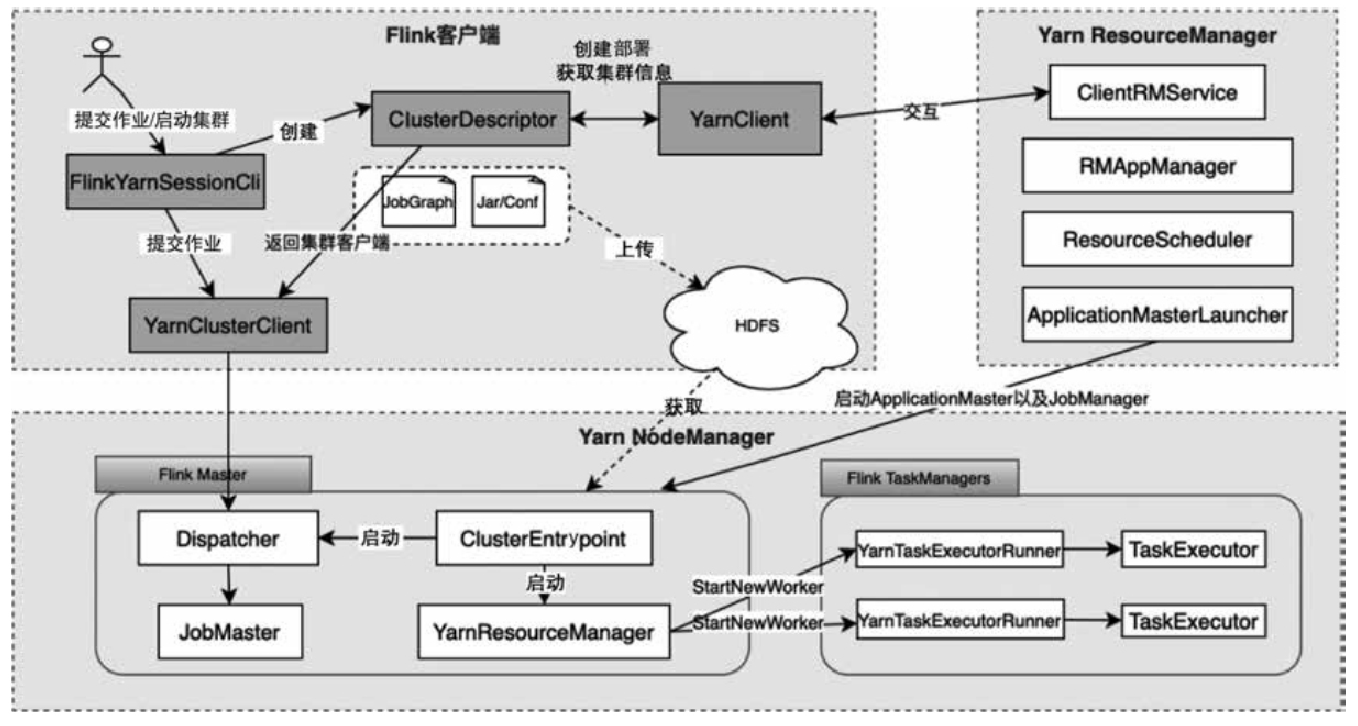
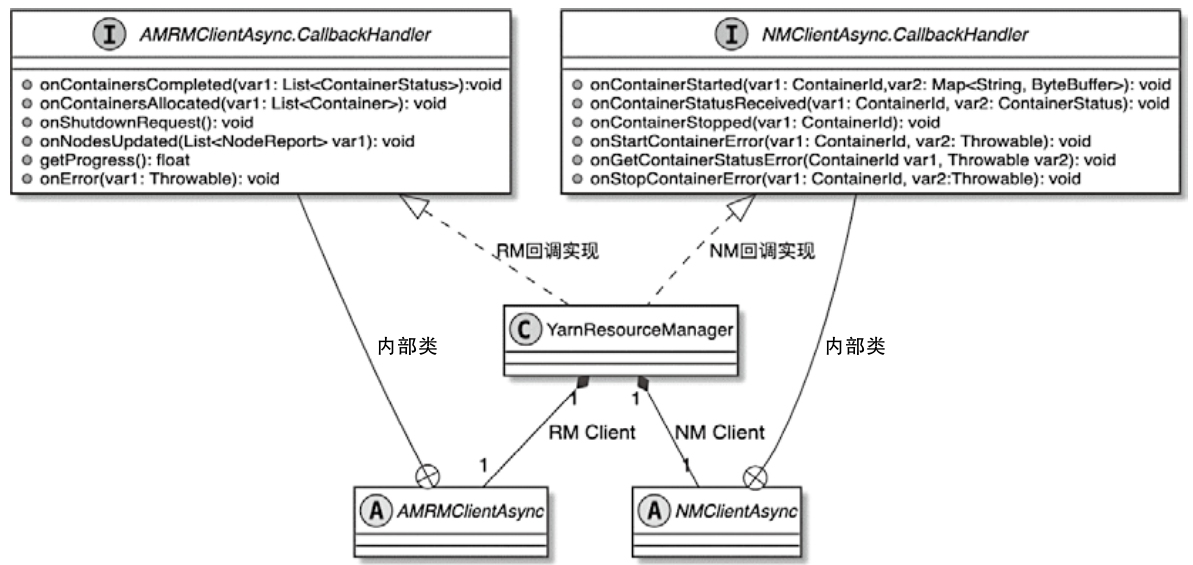
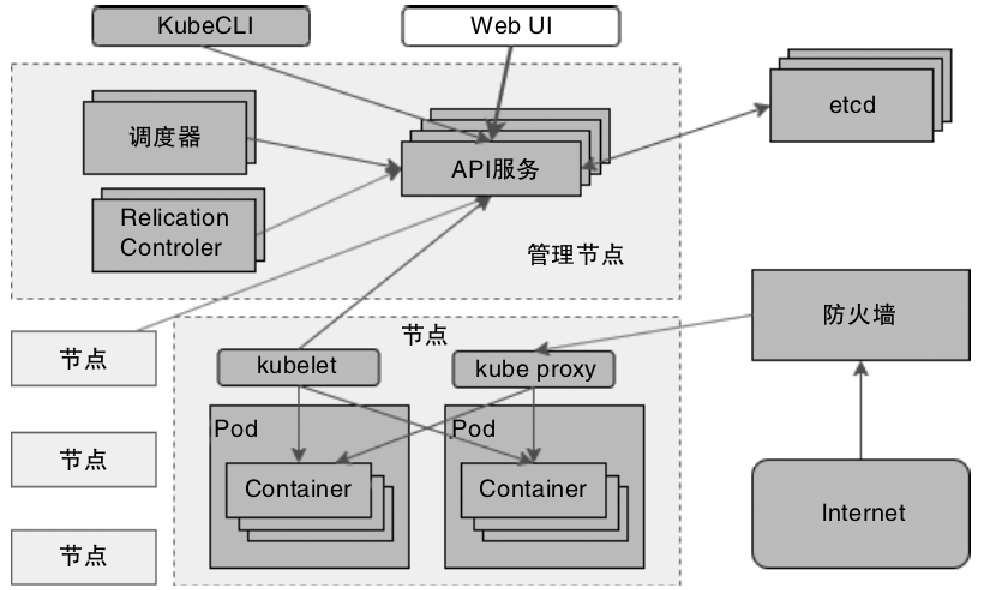
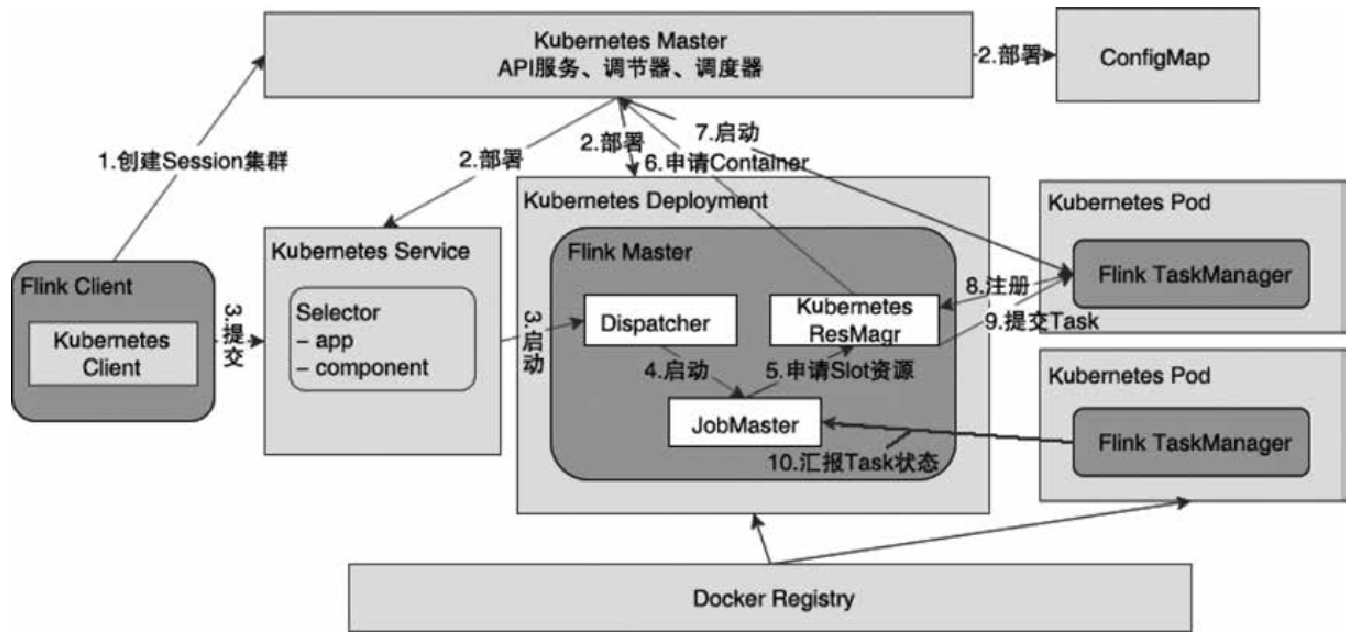
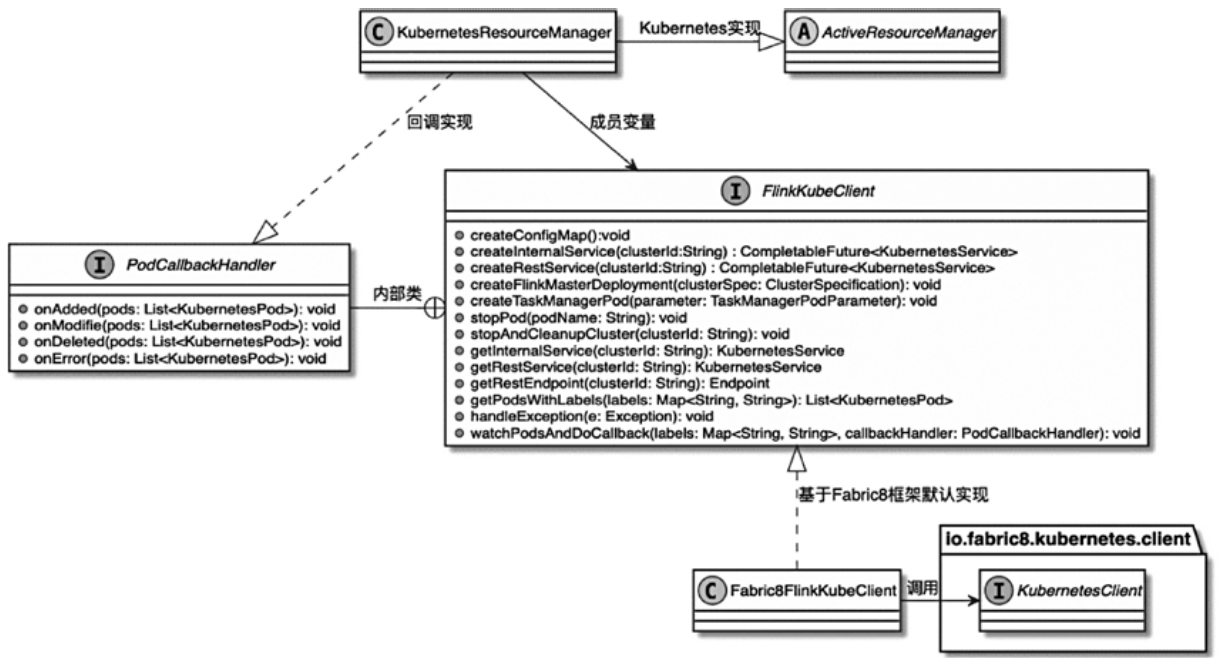
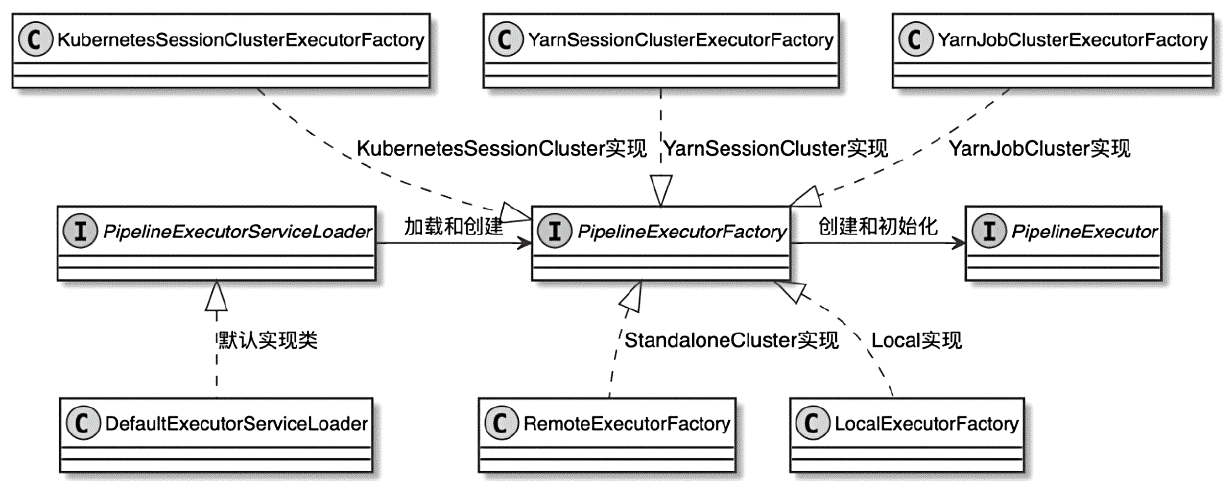
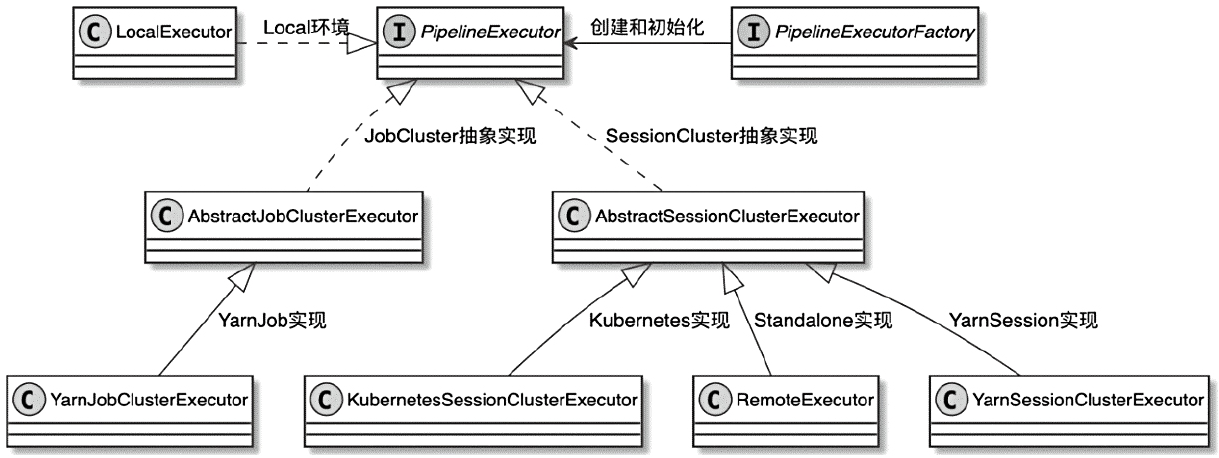
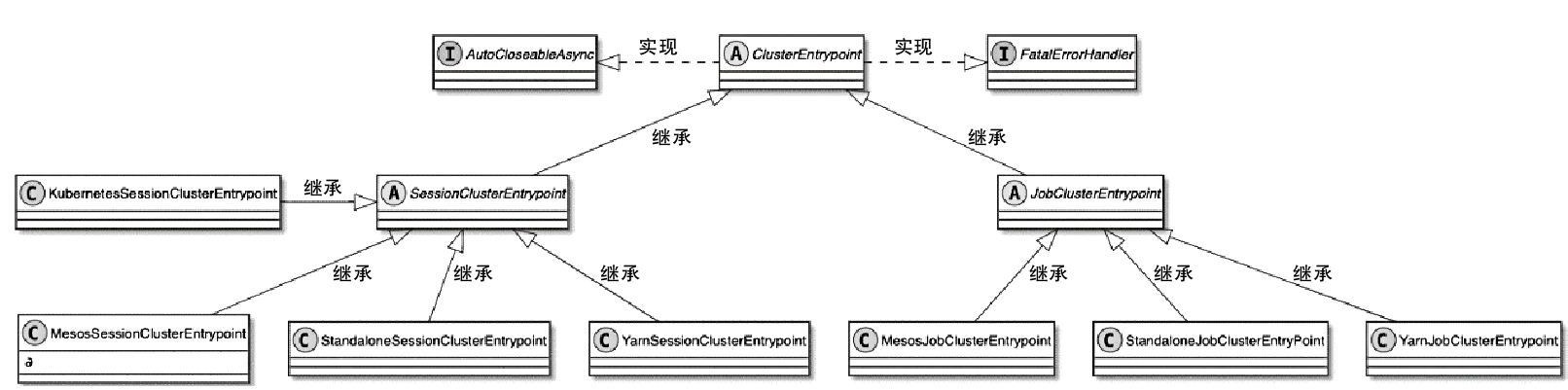
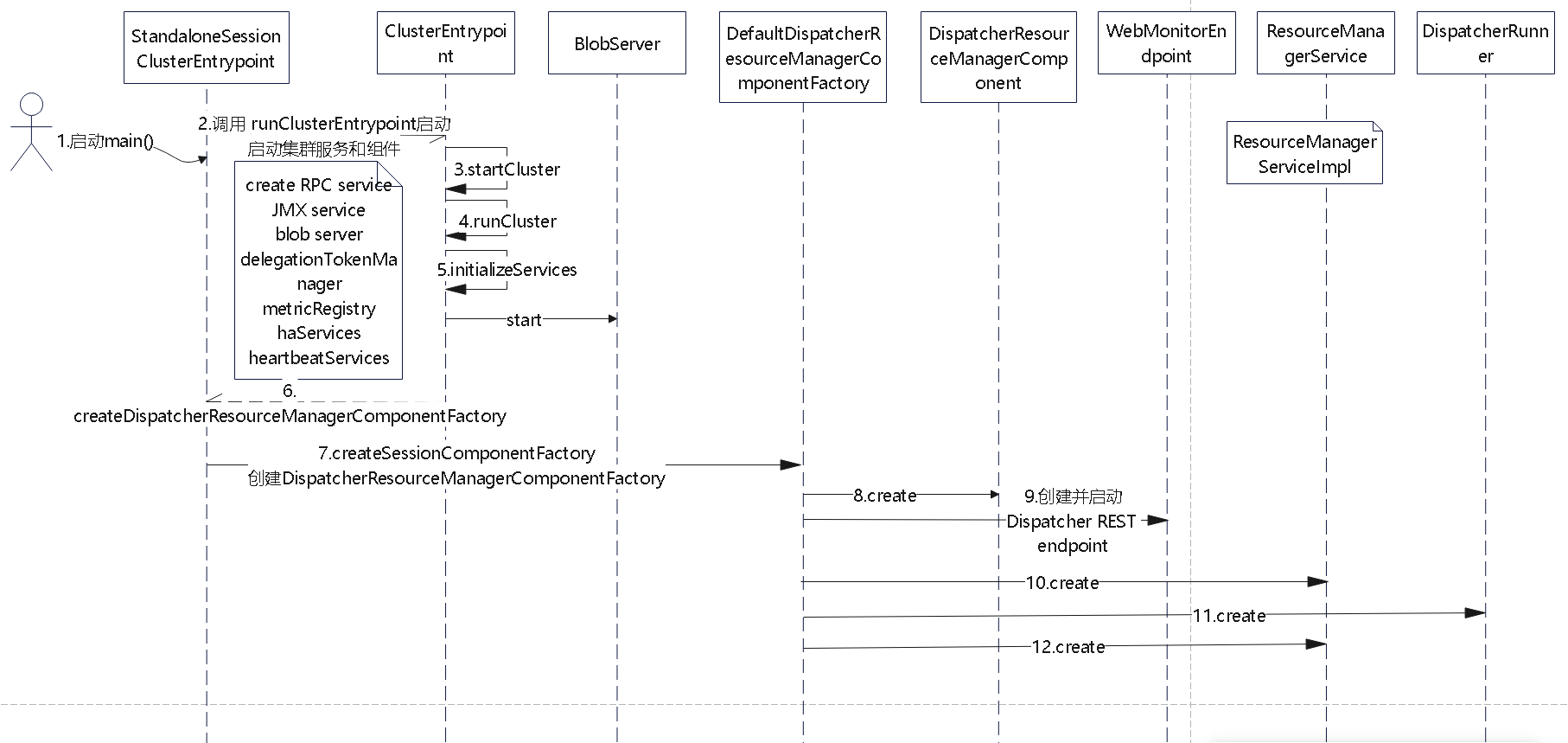
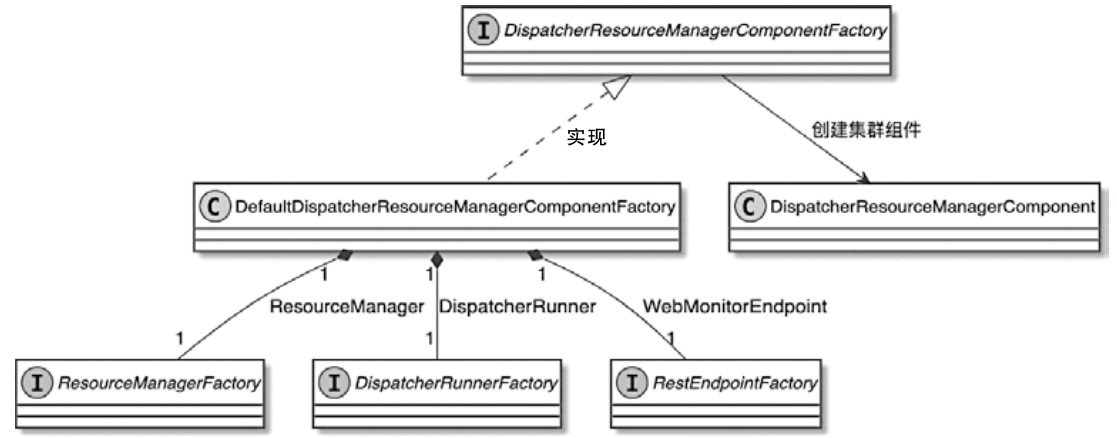
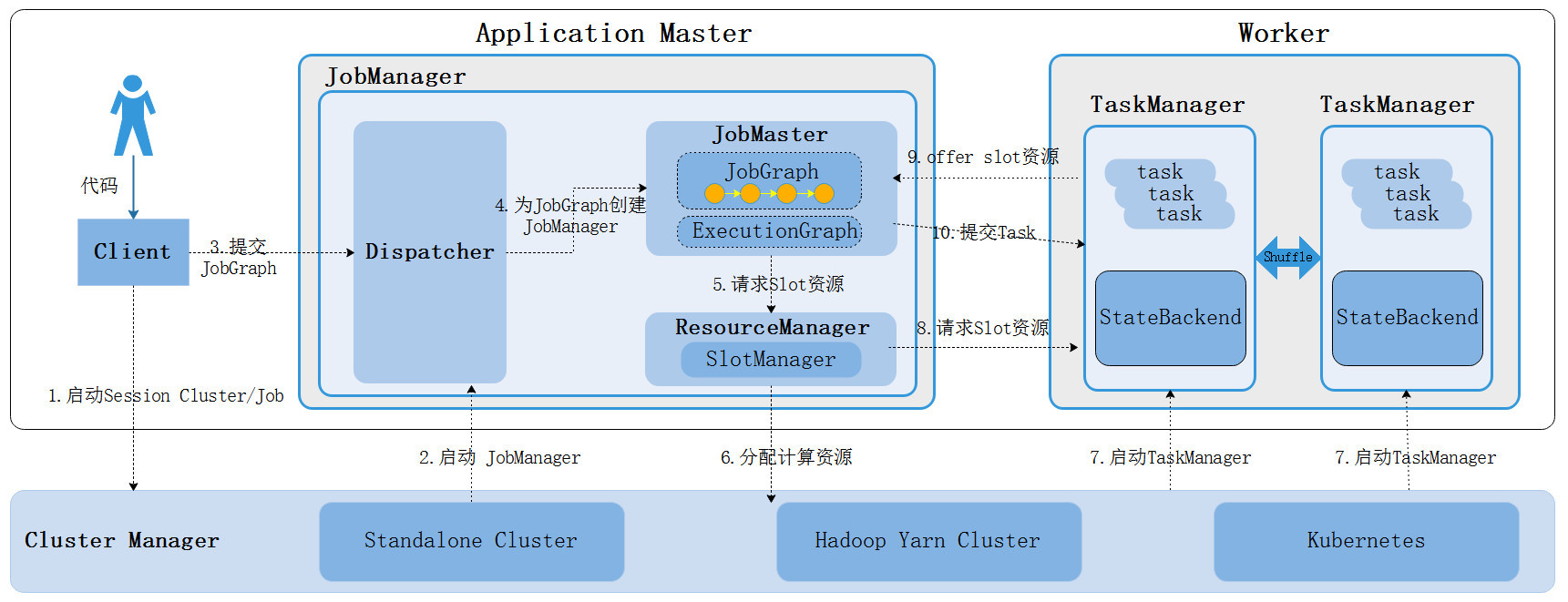
ClusterClientFactory -> ClusterDescriptor -> ClusterClientProvider -> ClusterClient 这条客户端侧的入口链路AbstractContainerizedClusterClientFactory、StandaloneClientFactory 这些不同部署模式下的工厂实现ResourceManager、TaskExecutor、fabric8、pod/Container 启动之间的关系重点是把“提交一个 Flink 作业”拆成几个明确阶段:
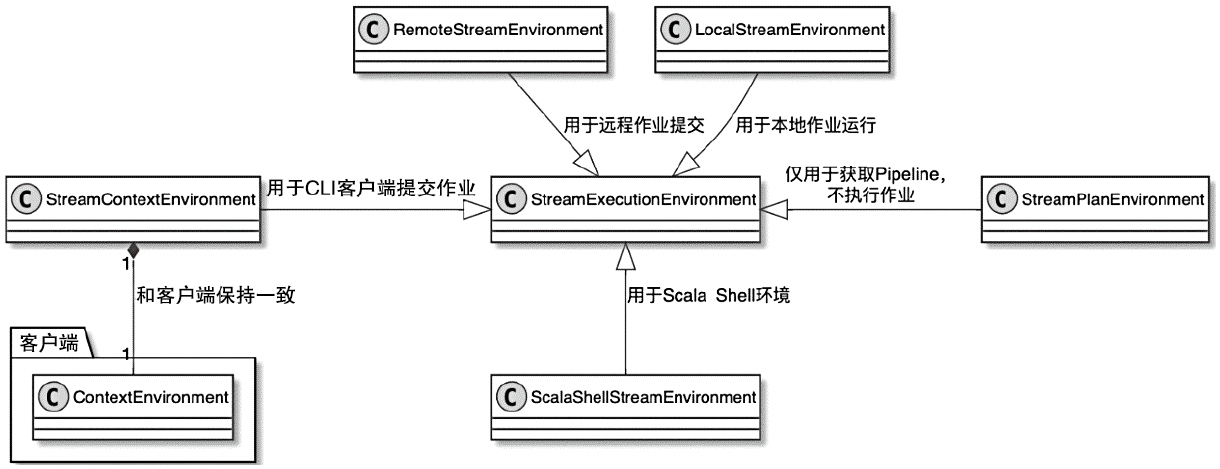
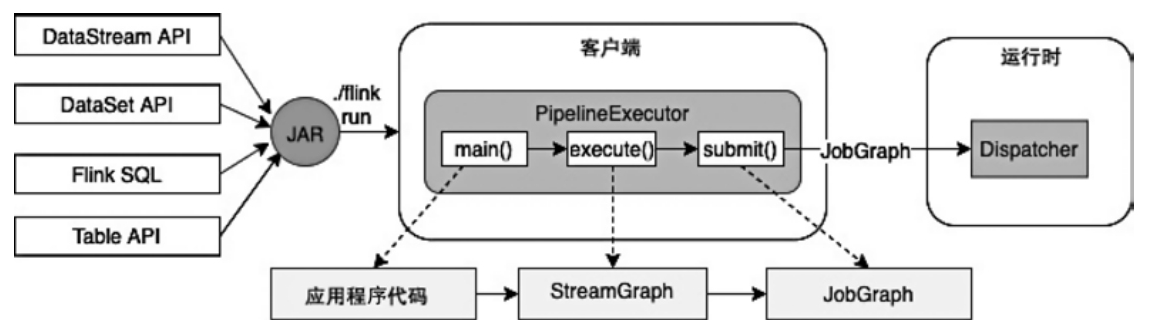
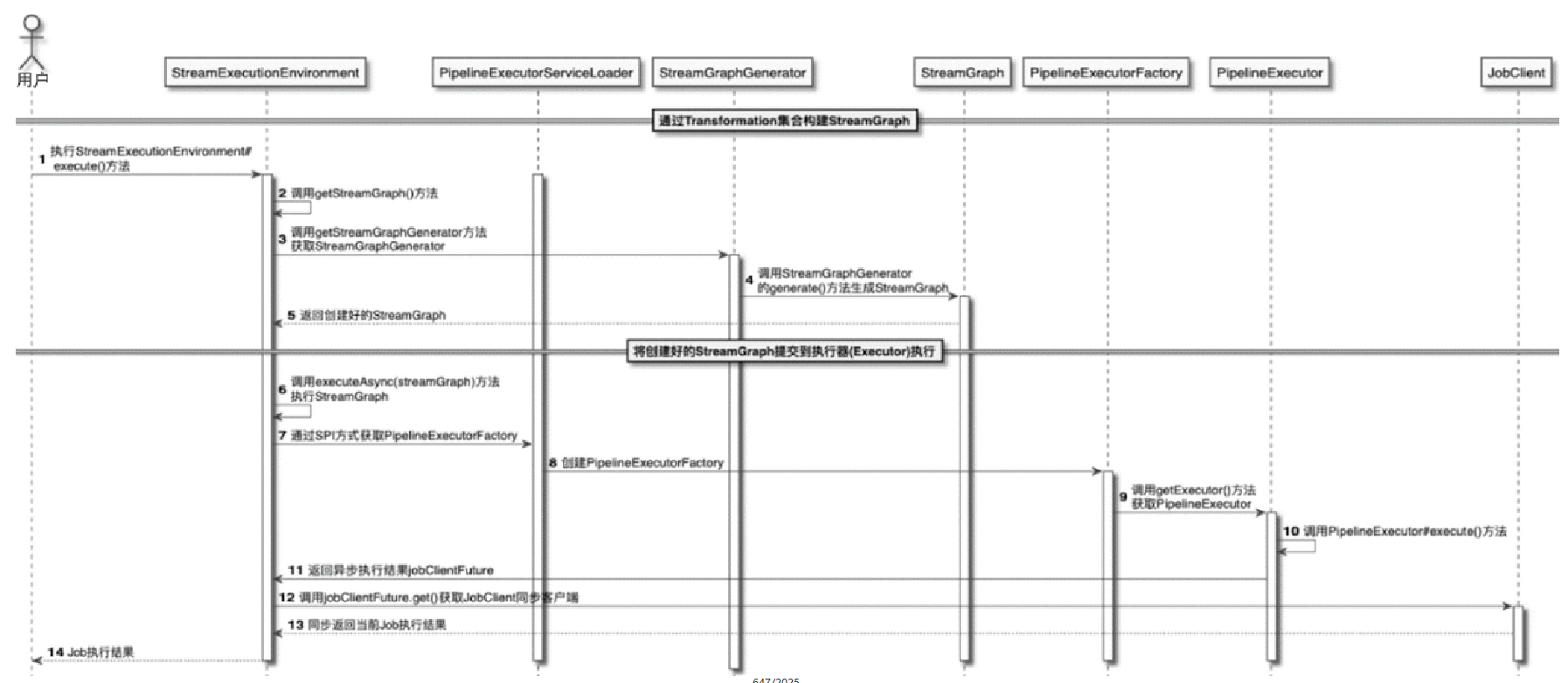
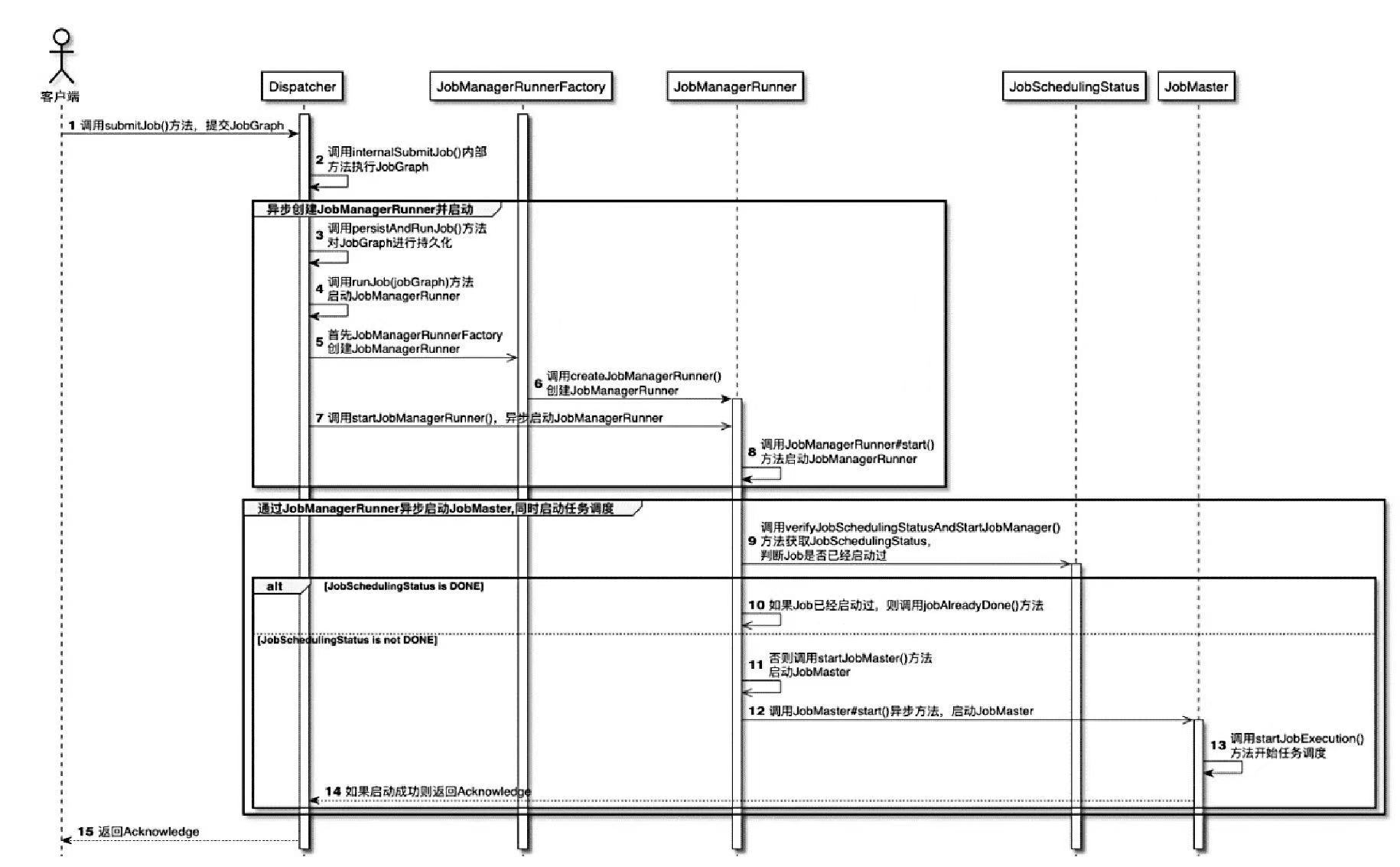
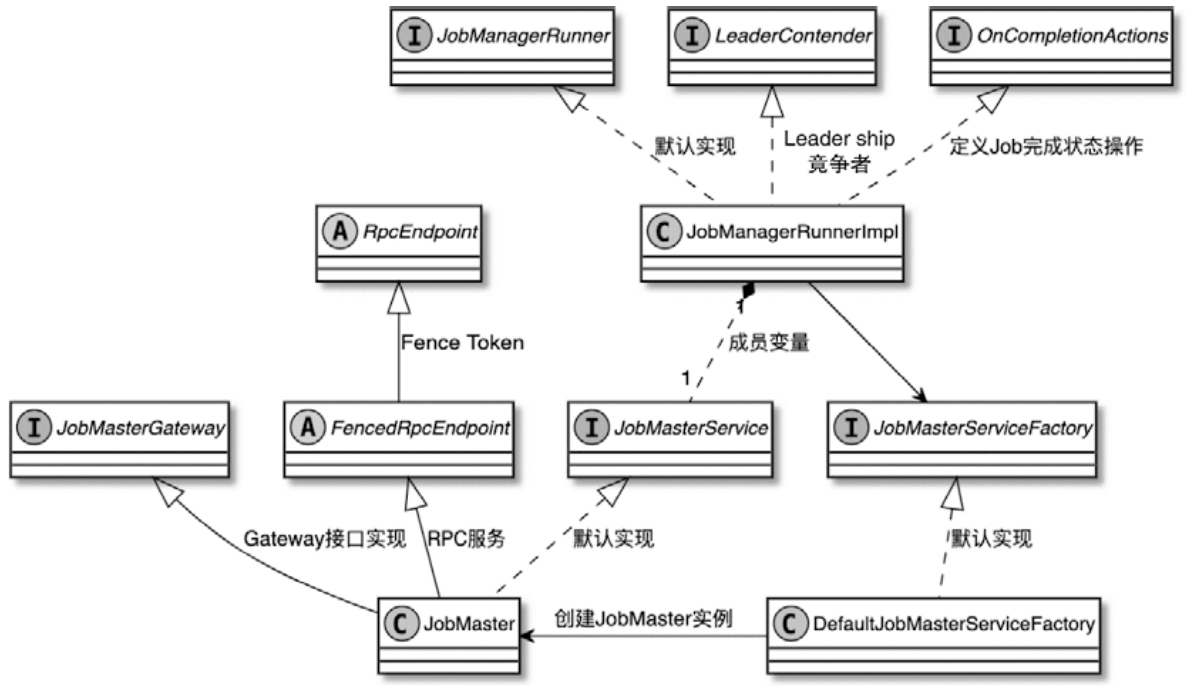
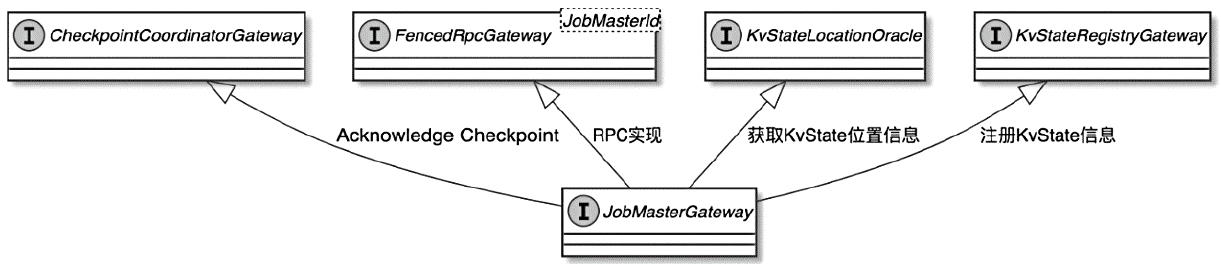
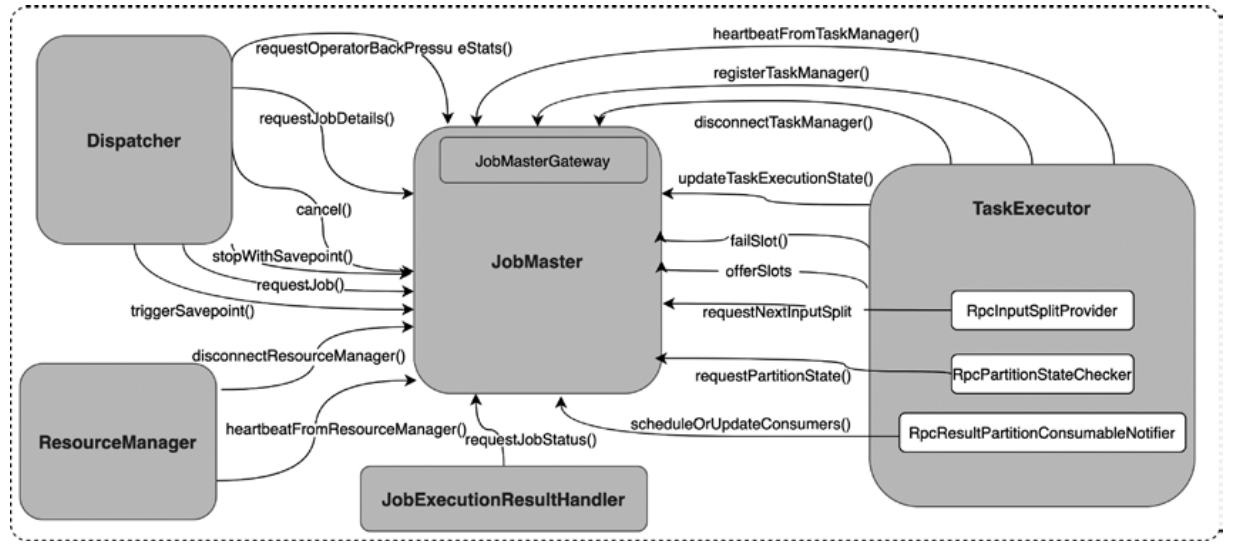
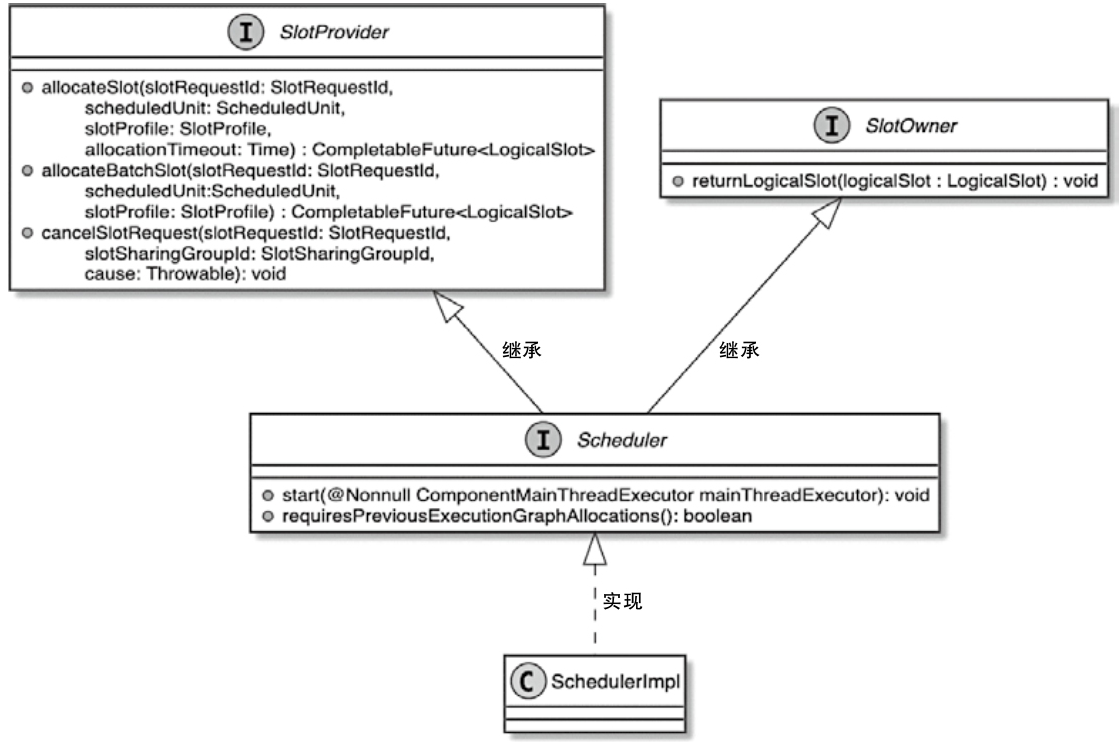
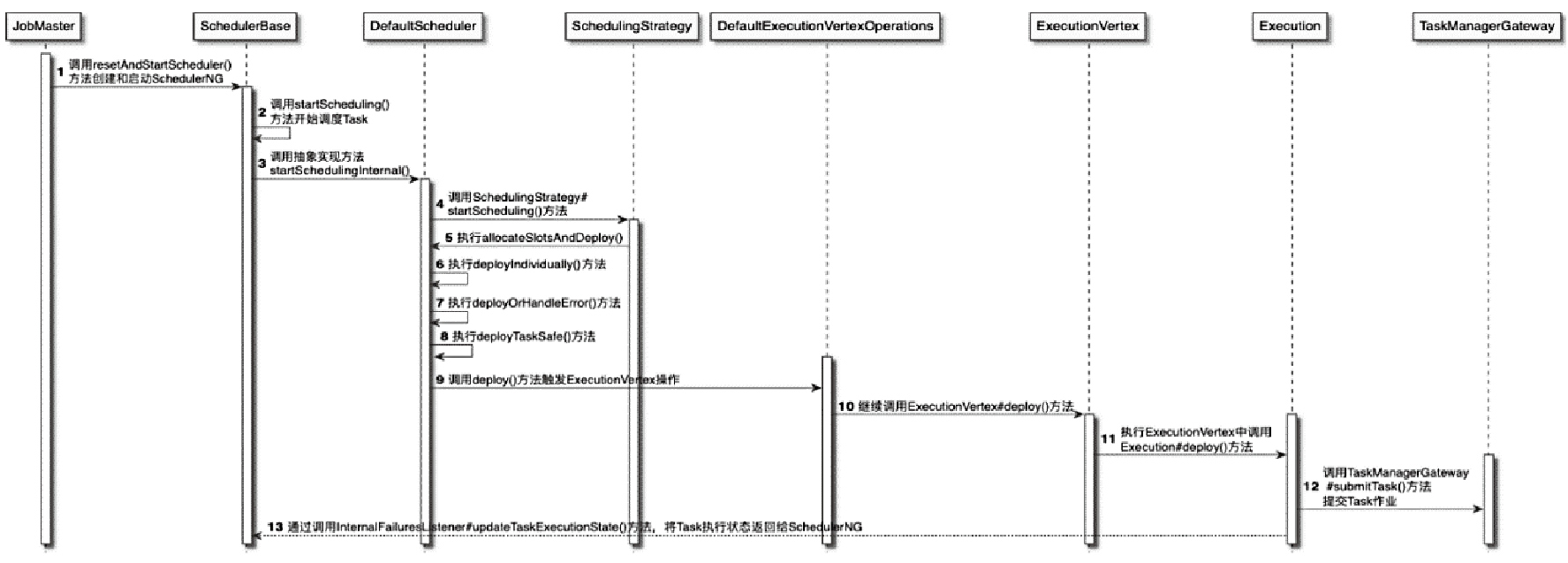
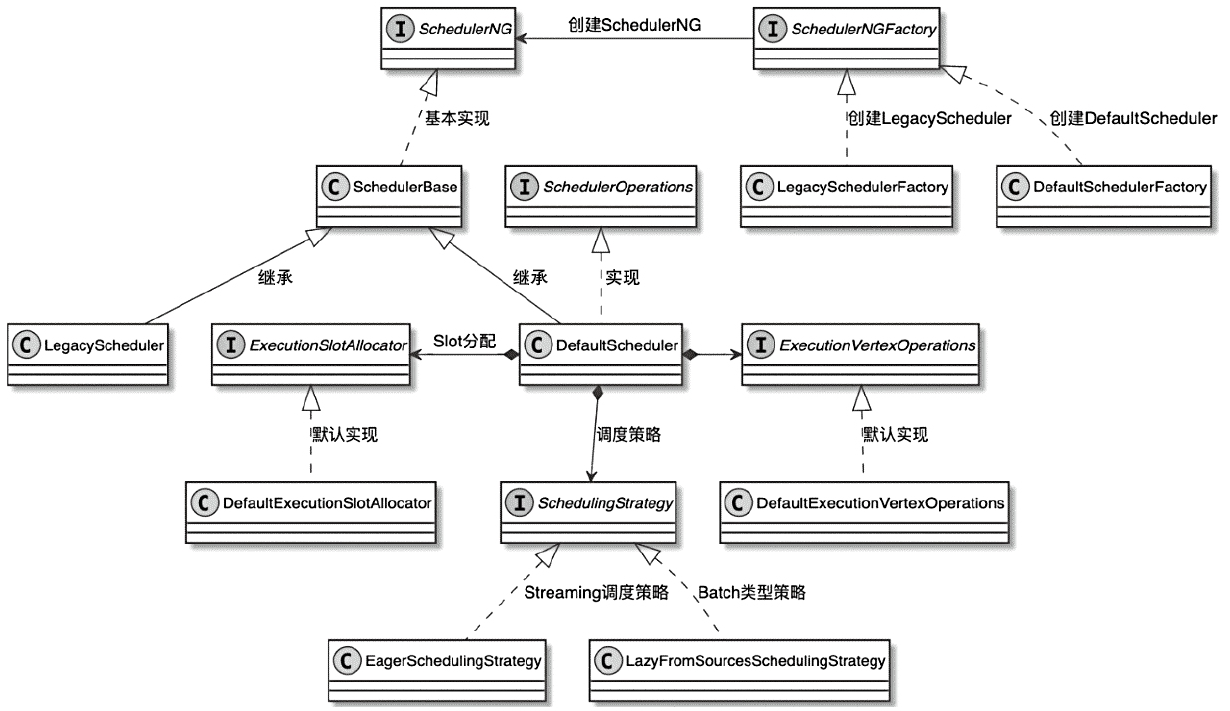
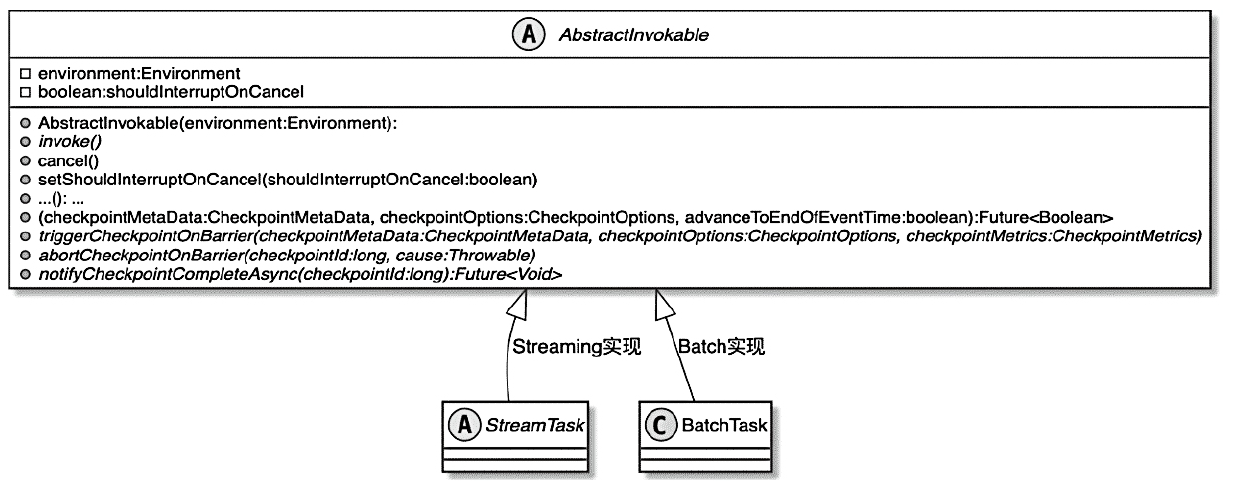
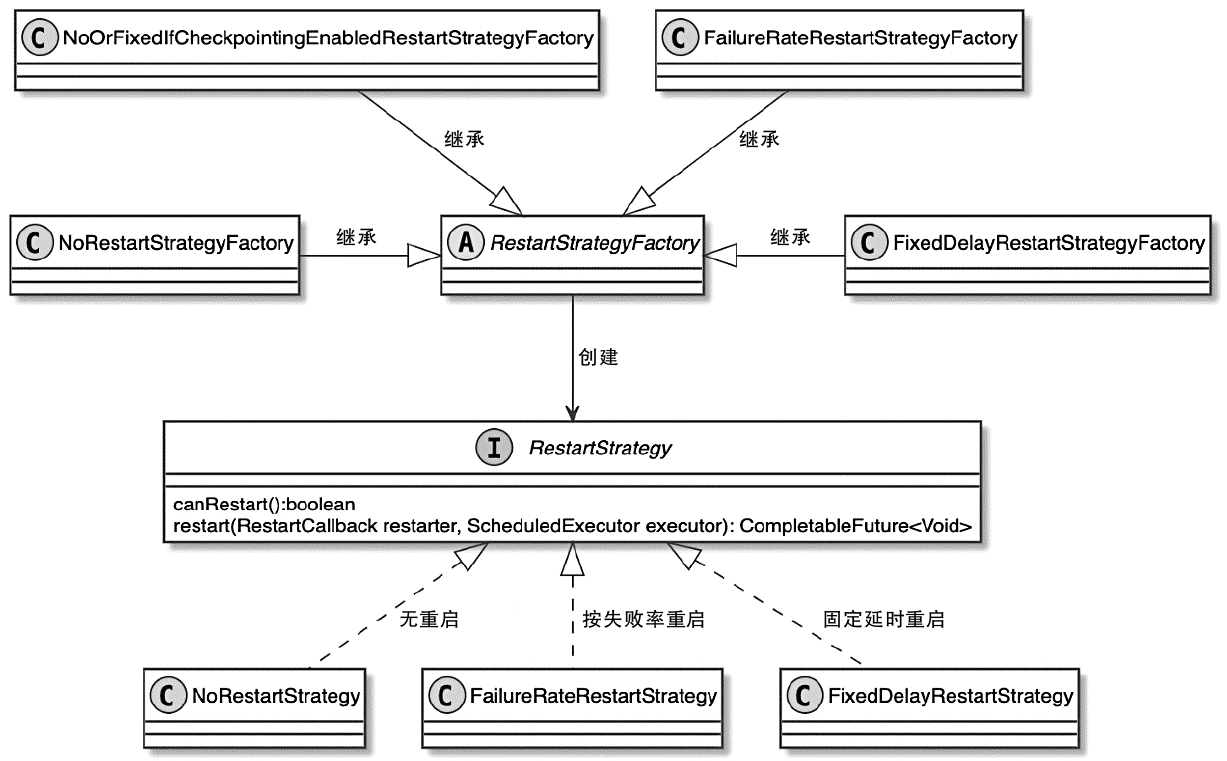
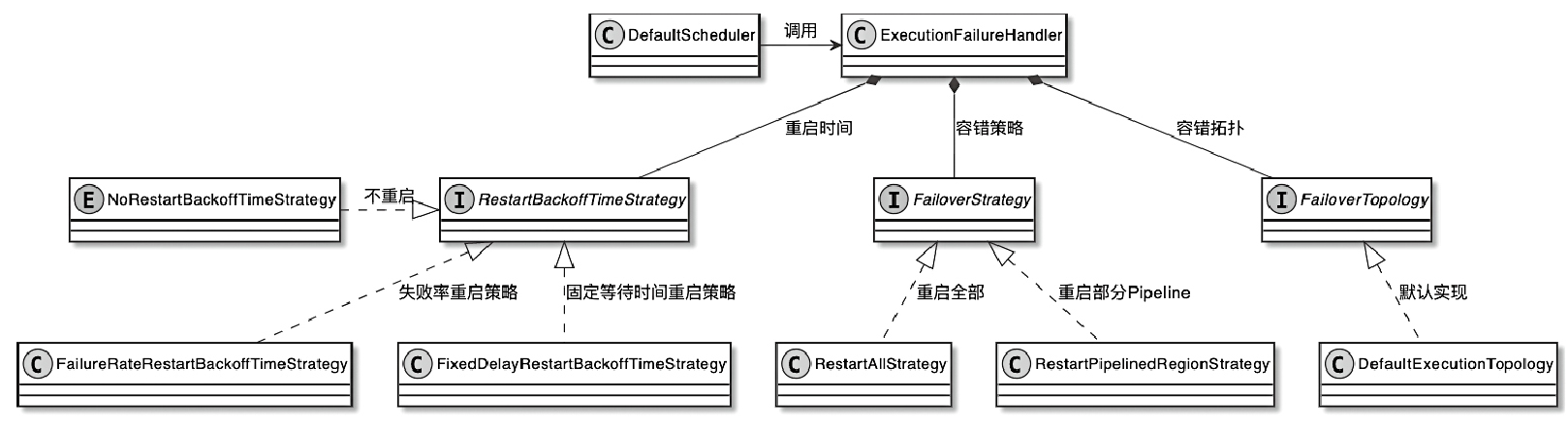
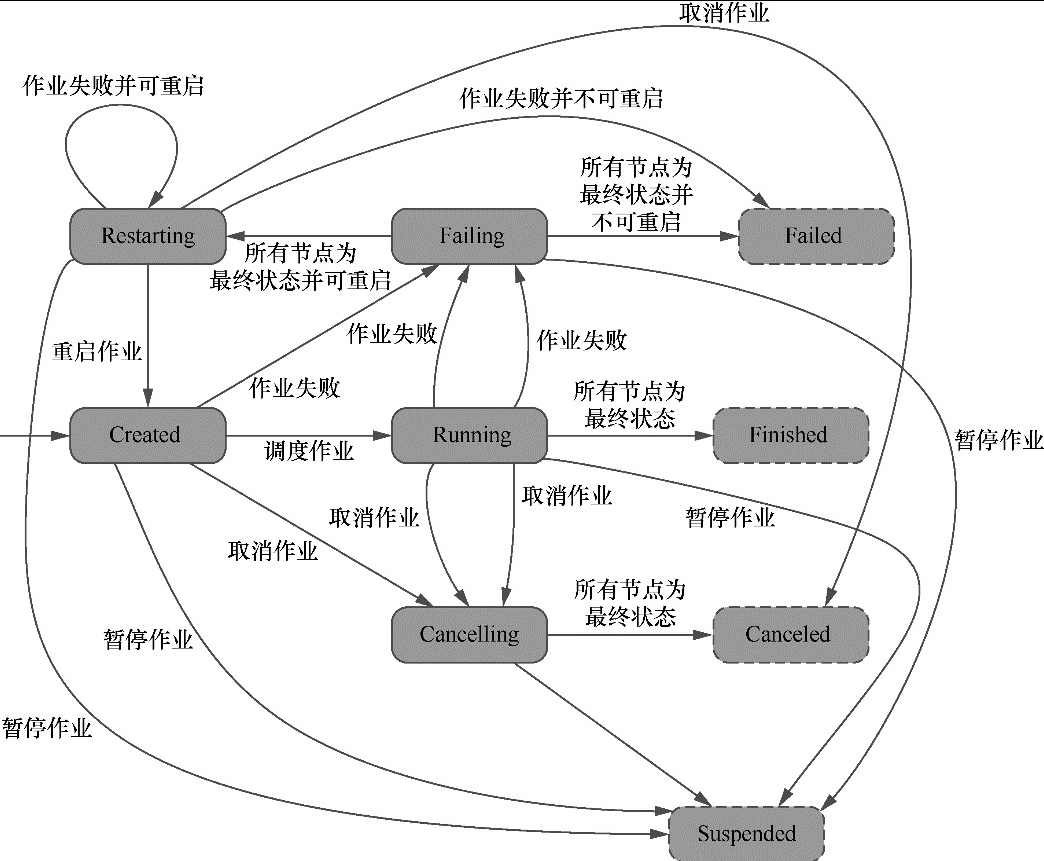
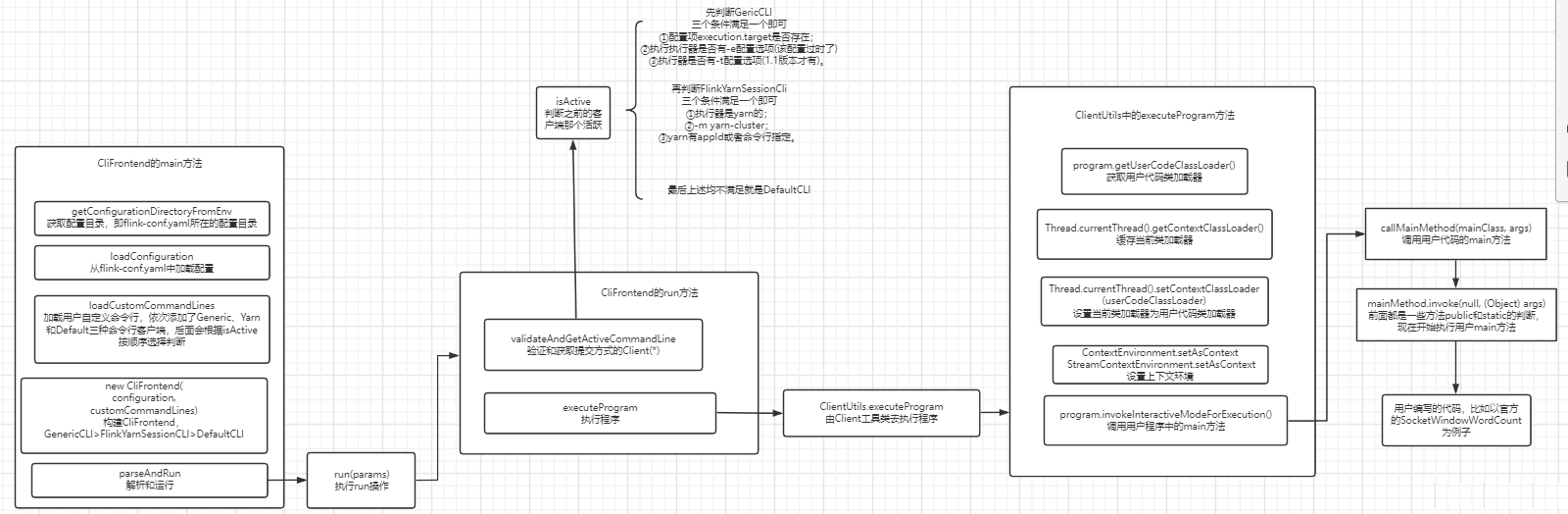
CLIFrontend、PackagedProgram、DefaultExecutorServiceLoader 到不同集群类型下的 PipelineExecutorExecutionEnvironment、StreamExecutionEnvironment 生成 StreamGraph / JobGraph,再交给运行时调度Dispatcher、JobMaster、SlotPool、TaskDeploymentDescriptor、StreamTask、Mailbox、重启策略这些运行阶段的关键组件DataStream 在运行时到底会落到哪些算子和线程模型上:
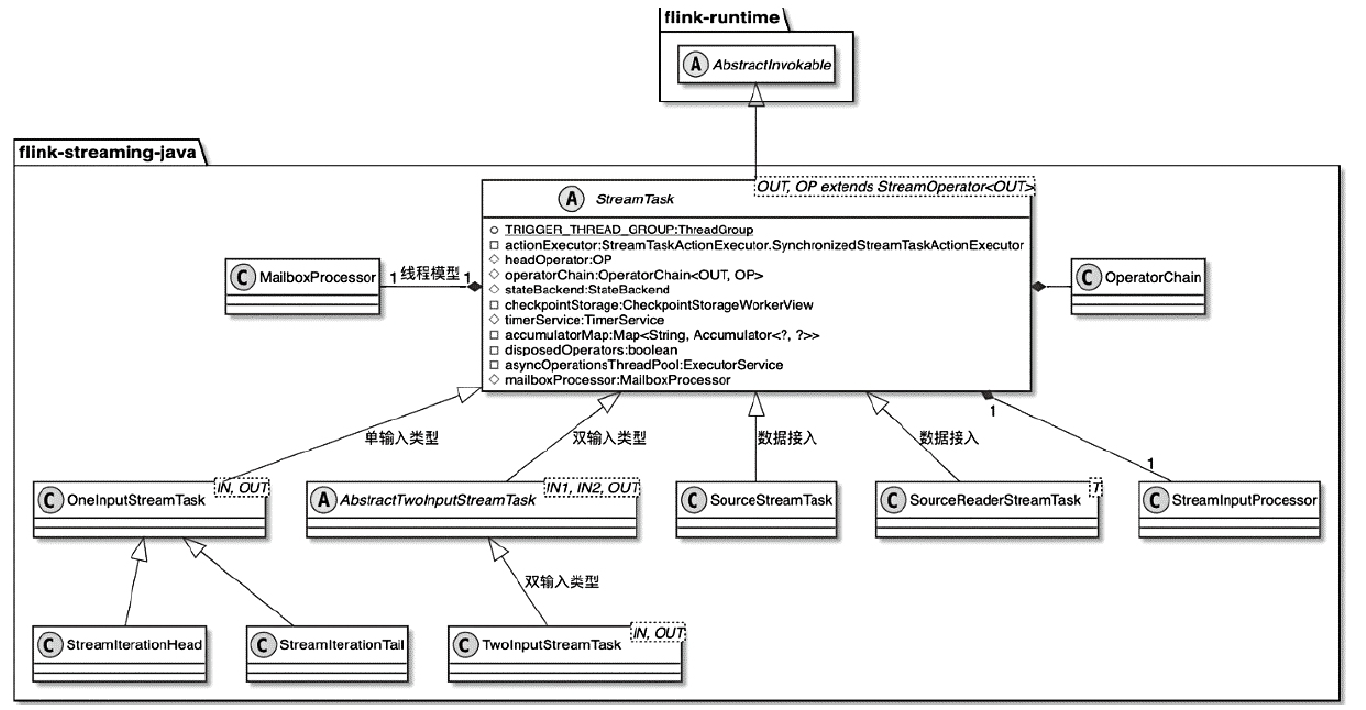
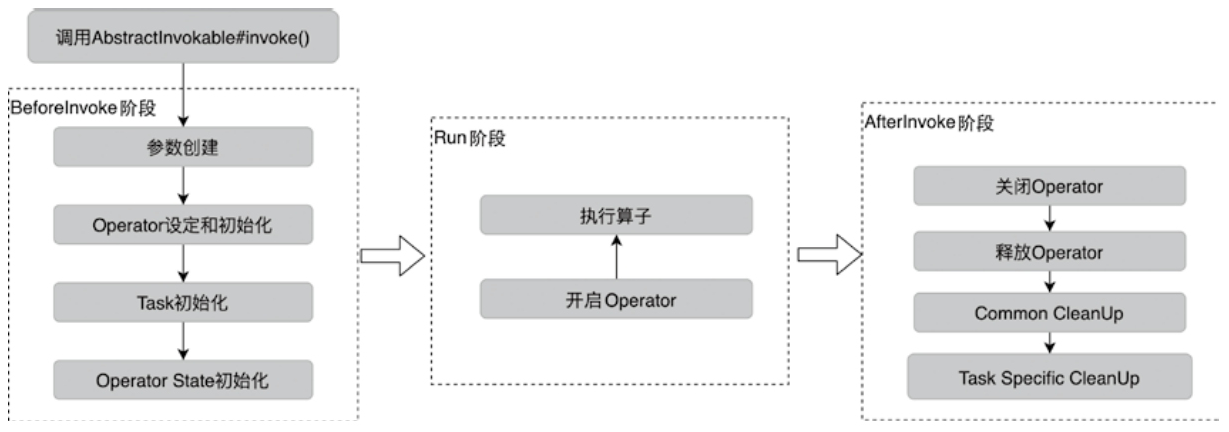
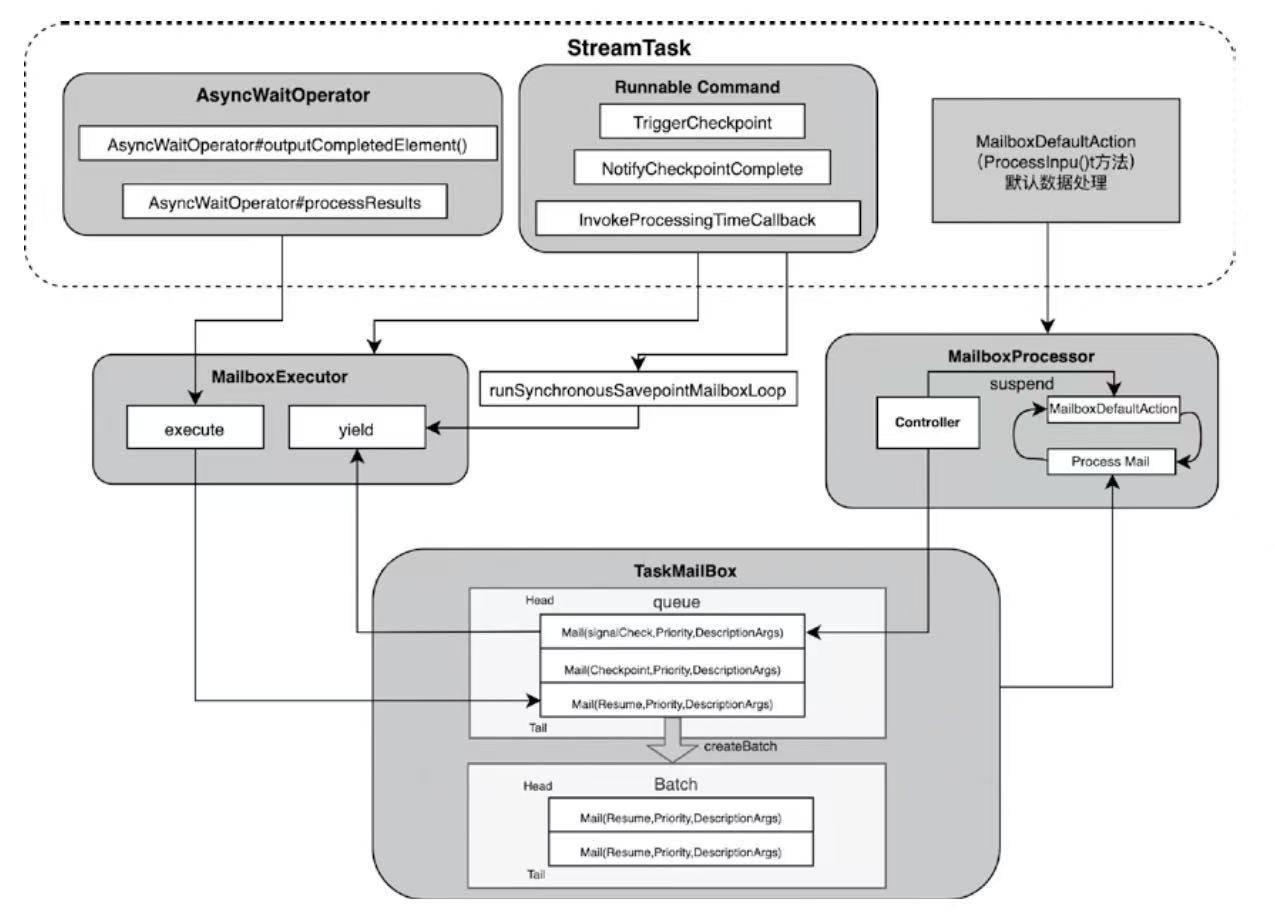
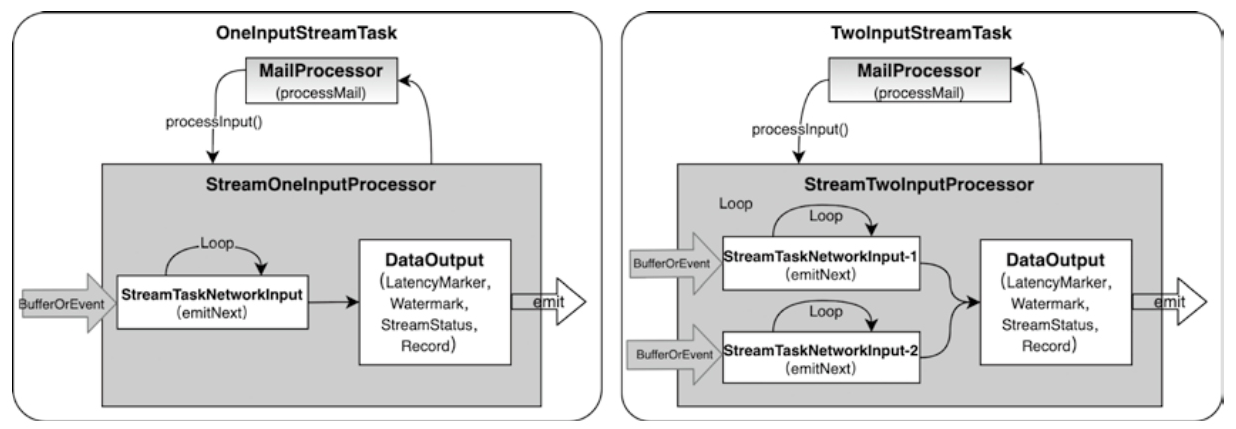
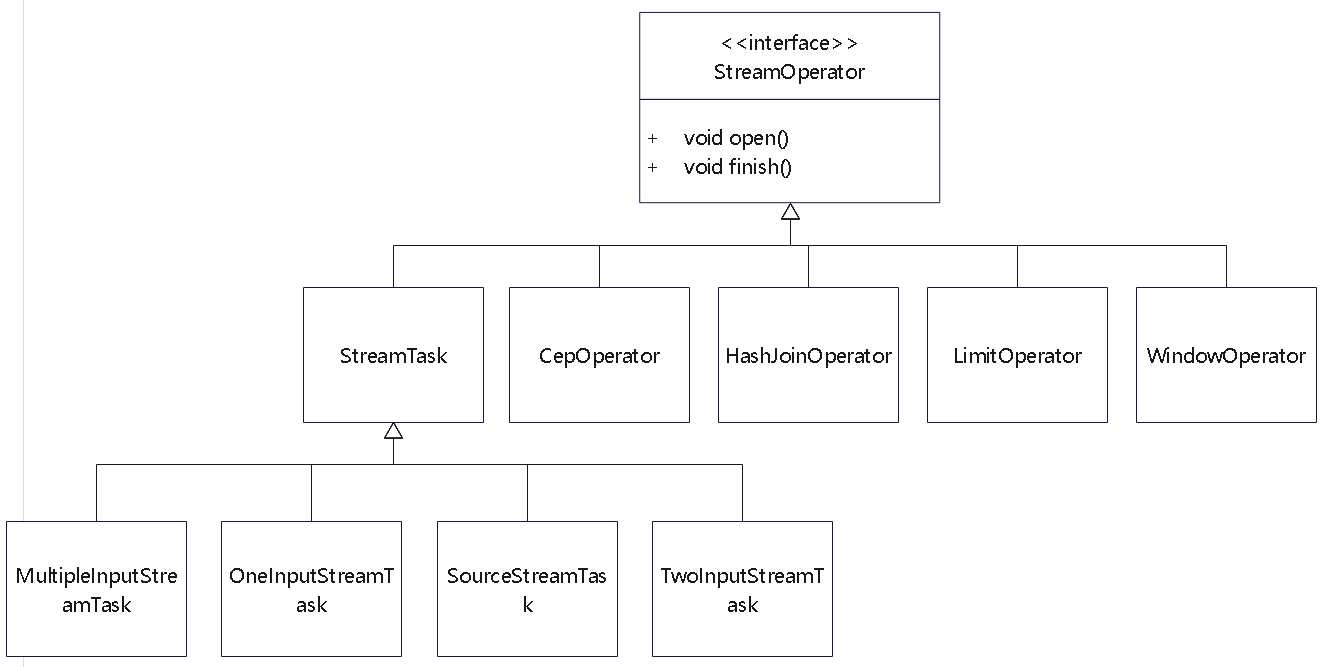
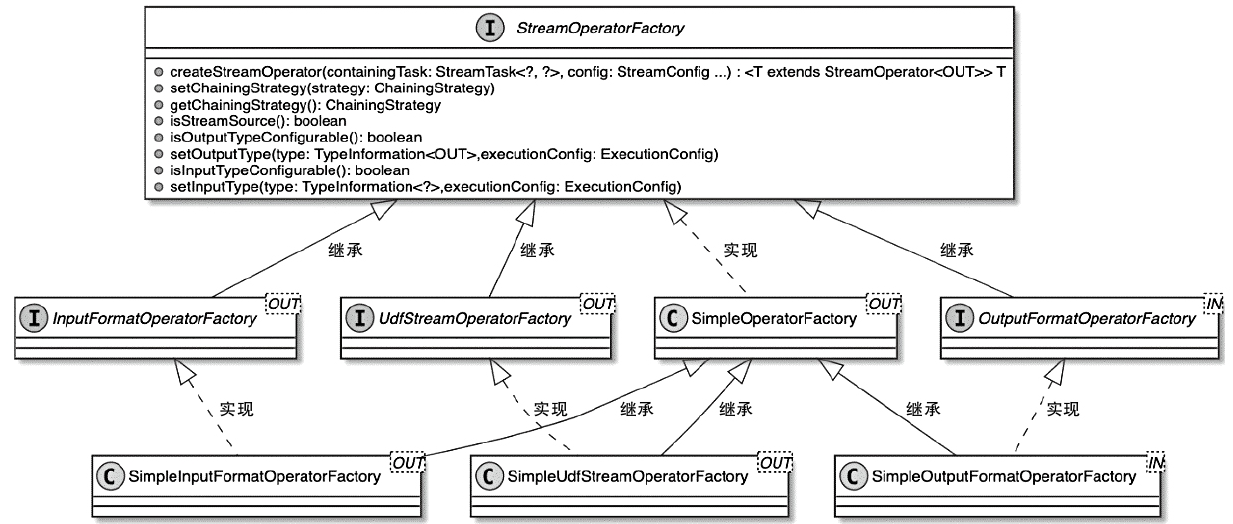
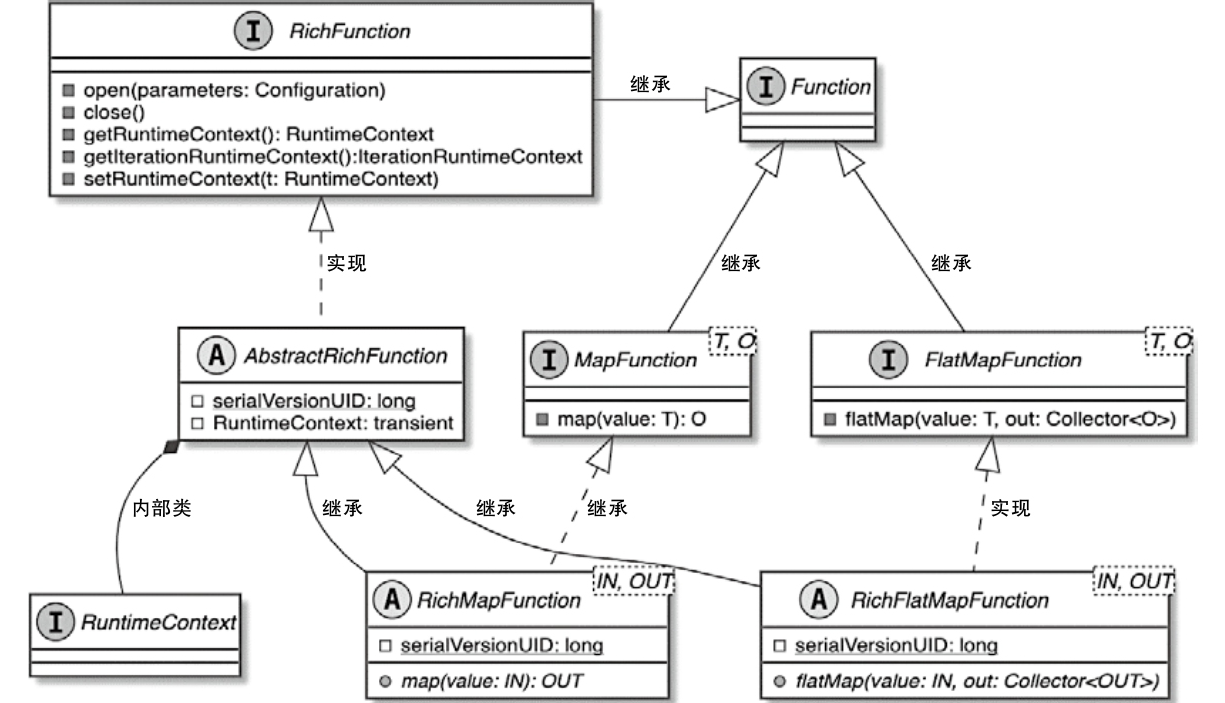
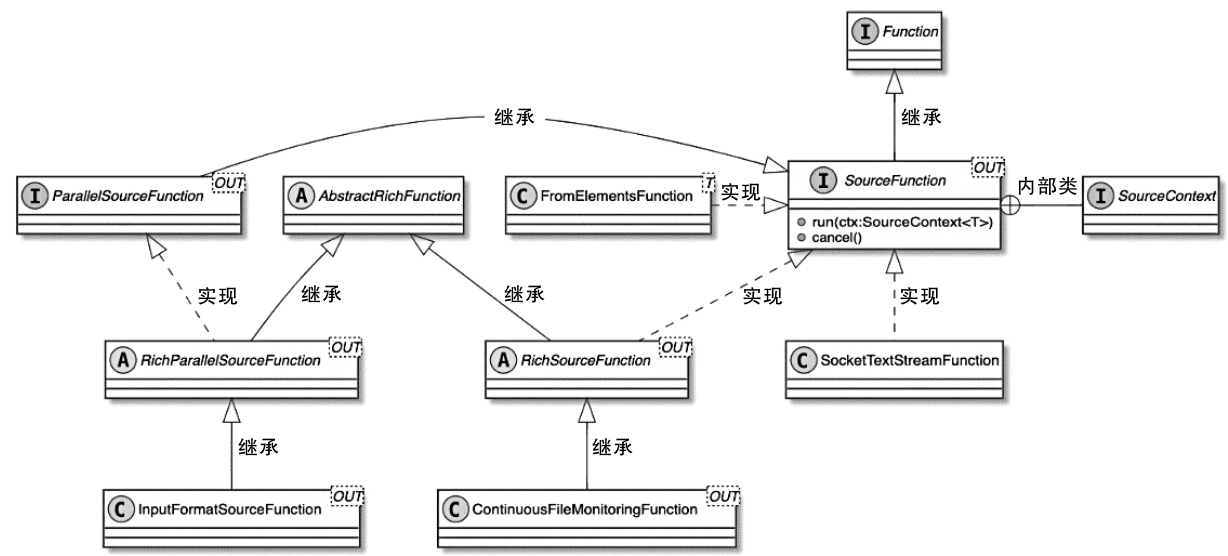
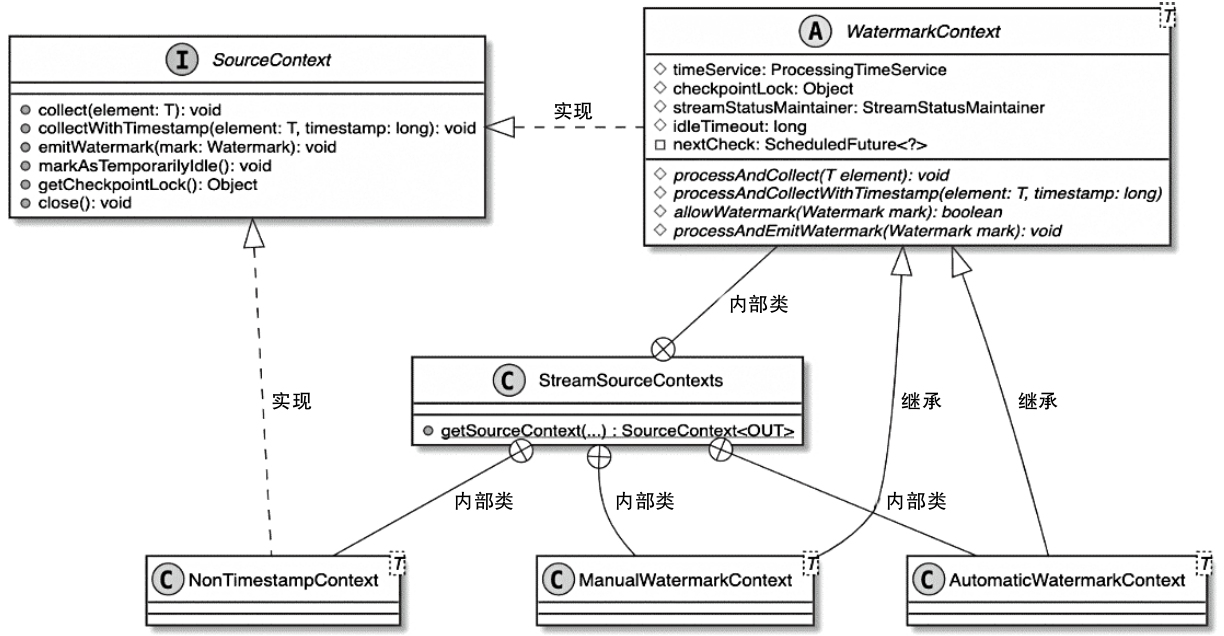
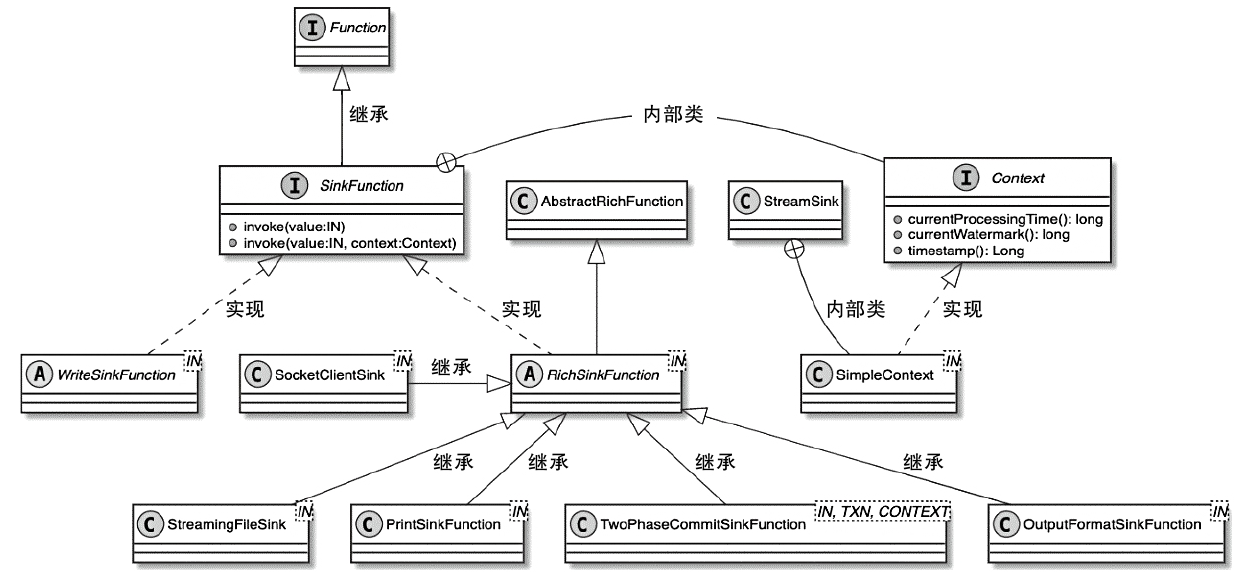
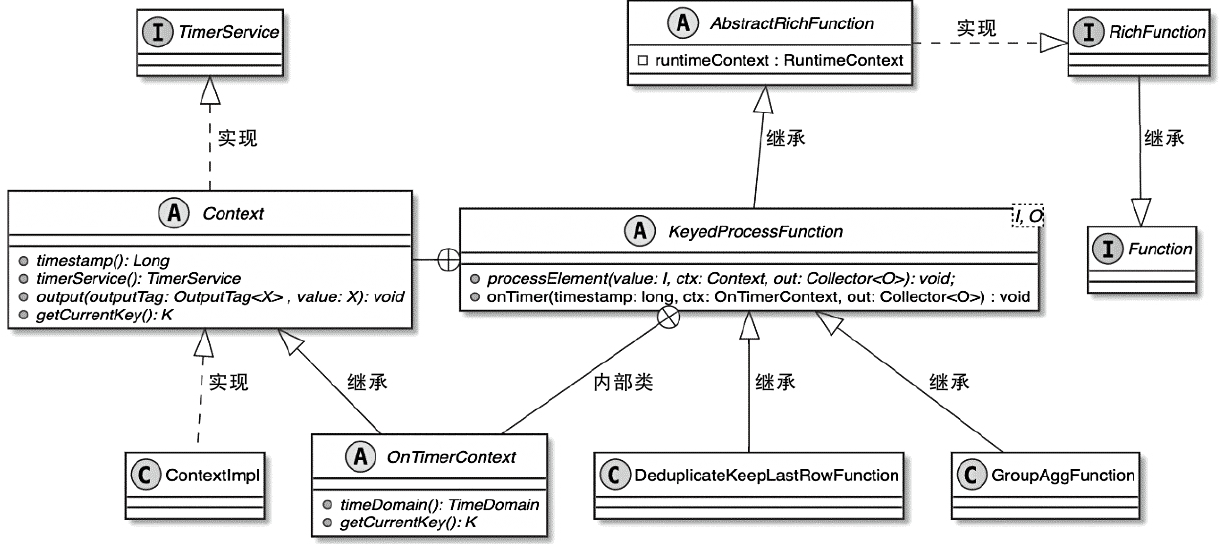
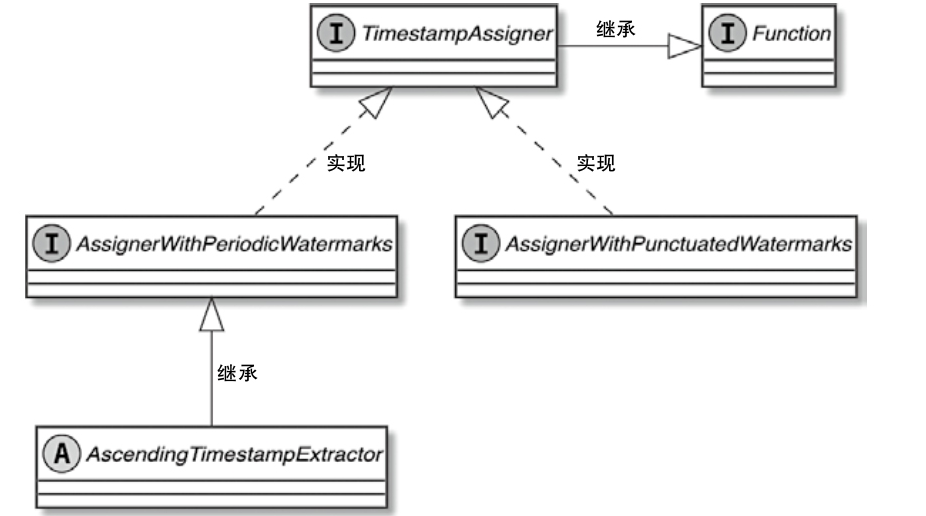
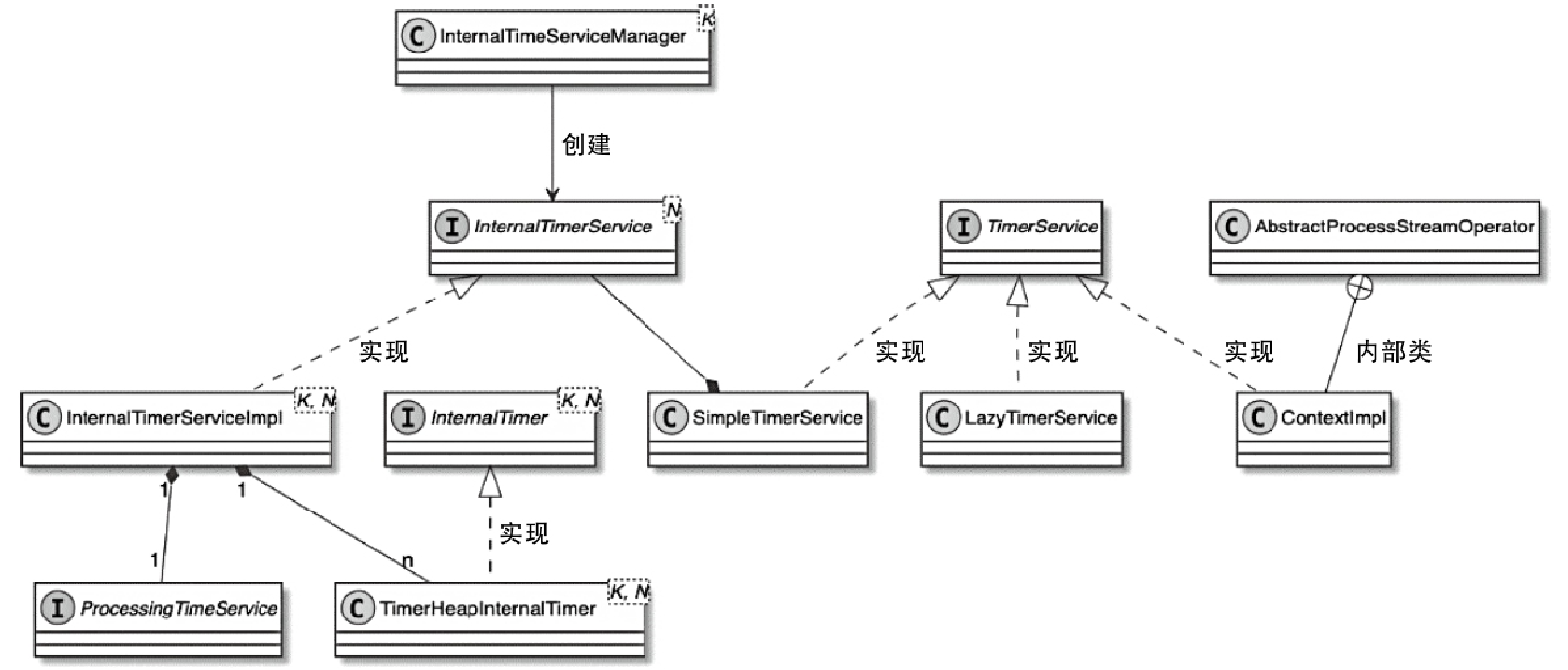
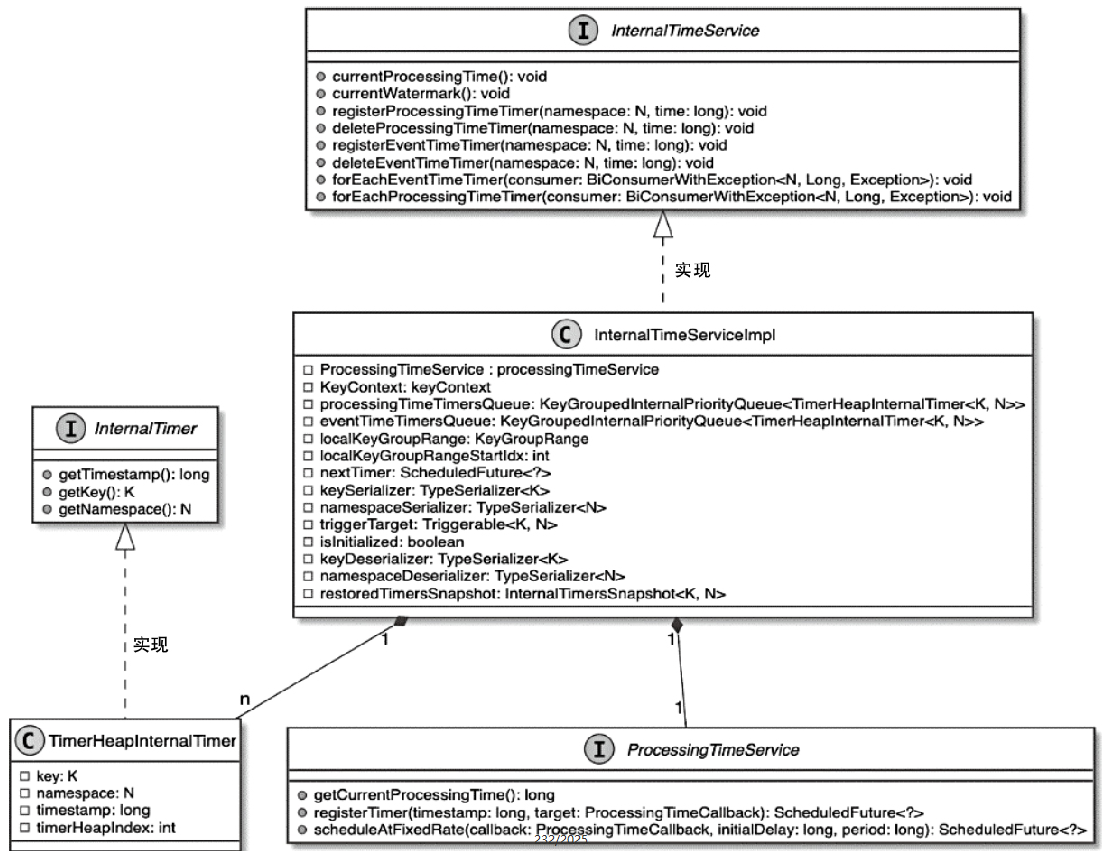
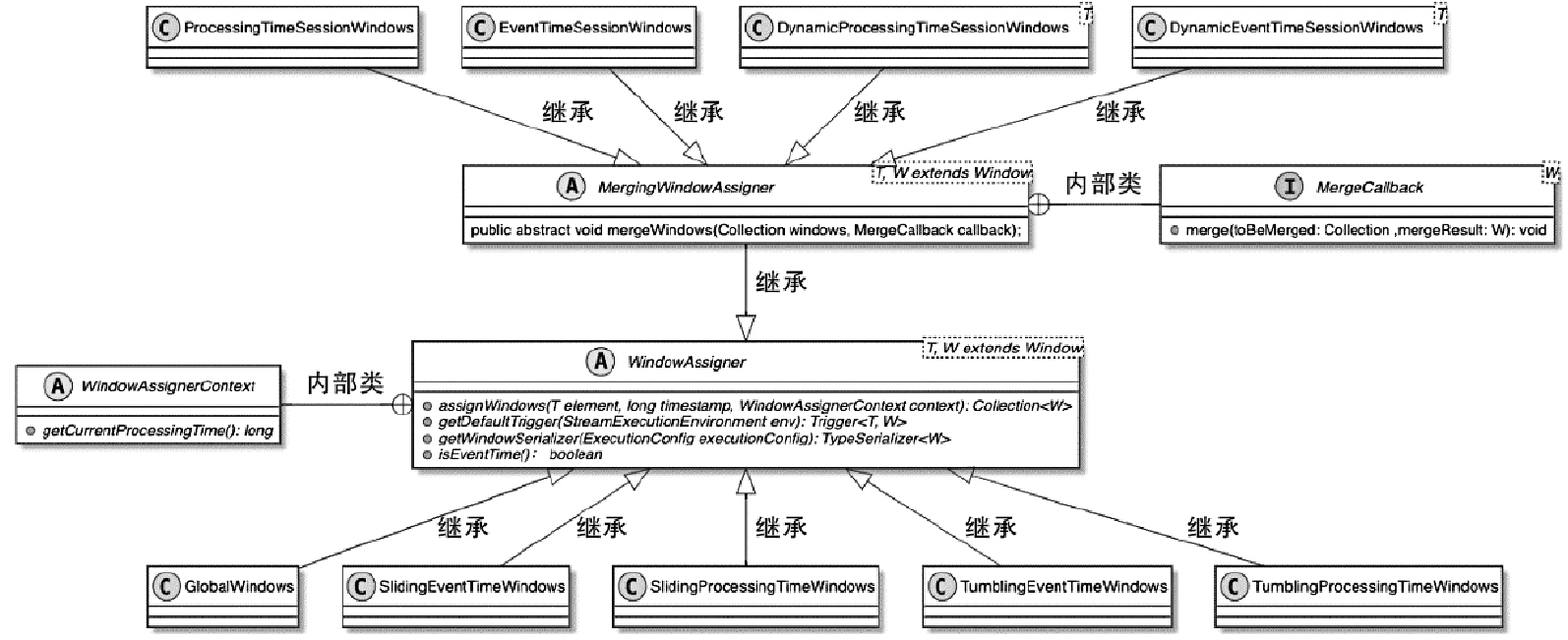
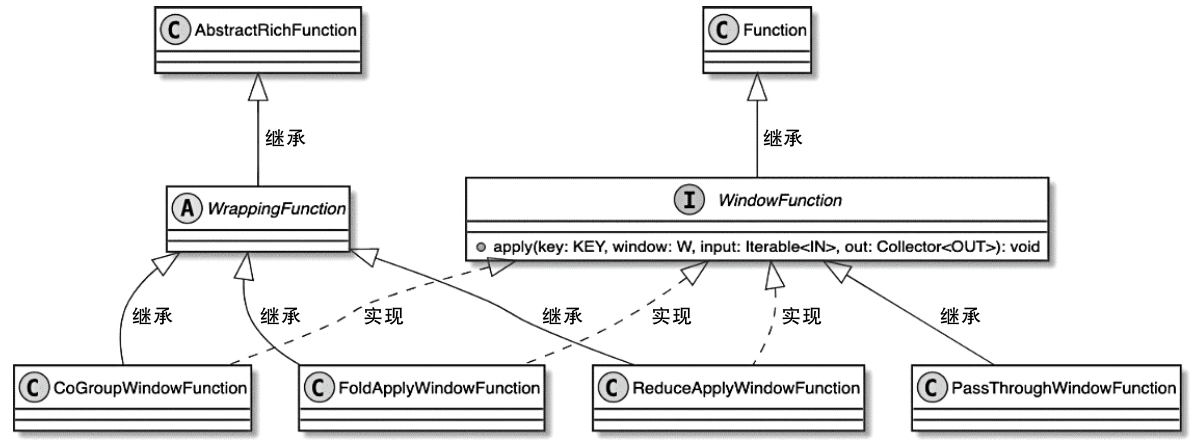
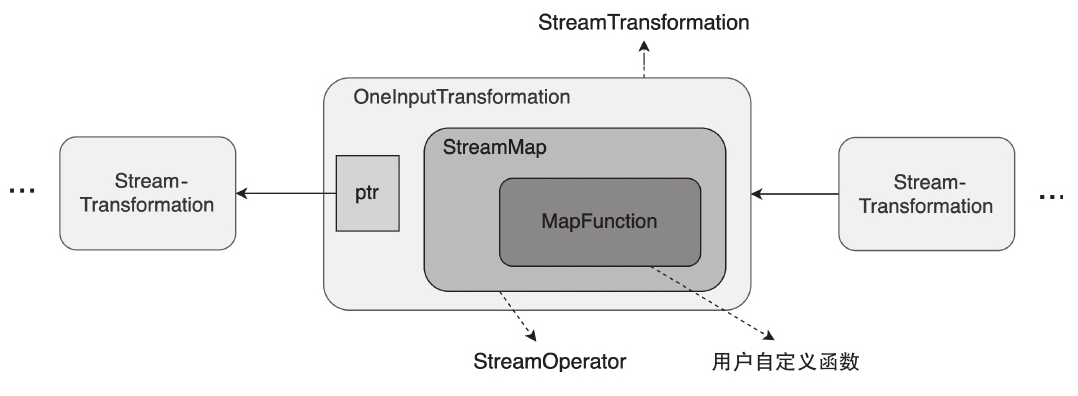
StreamOperator、AbstractStreamOperator、AbstractUdfStreamOperator 一路看到单输入、双输入算子的继承体系SourceFunction、SinkFunction、TwoPhaseCommitSinkFunction、ProcessFunction、KeyedProcessFunction 这些常用扩展点SourceStreamTask -> StreamSource -> user function 和 StreamSink -> invoke() 这条路径,把 Watermark、TimerService、端到端一致性串起来Flink 运行时的脑图,重点包括:
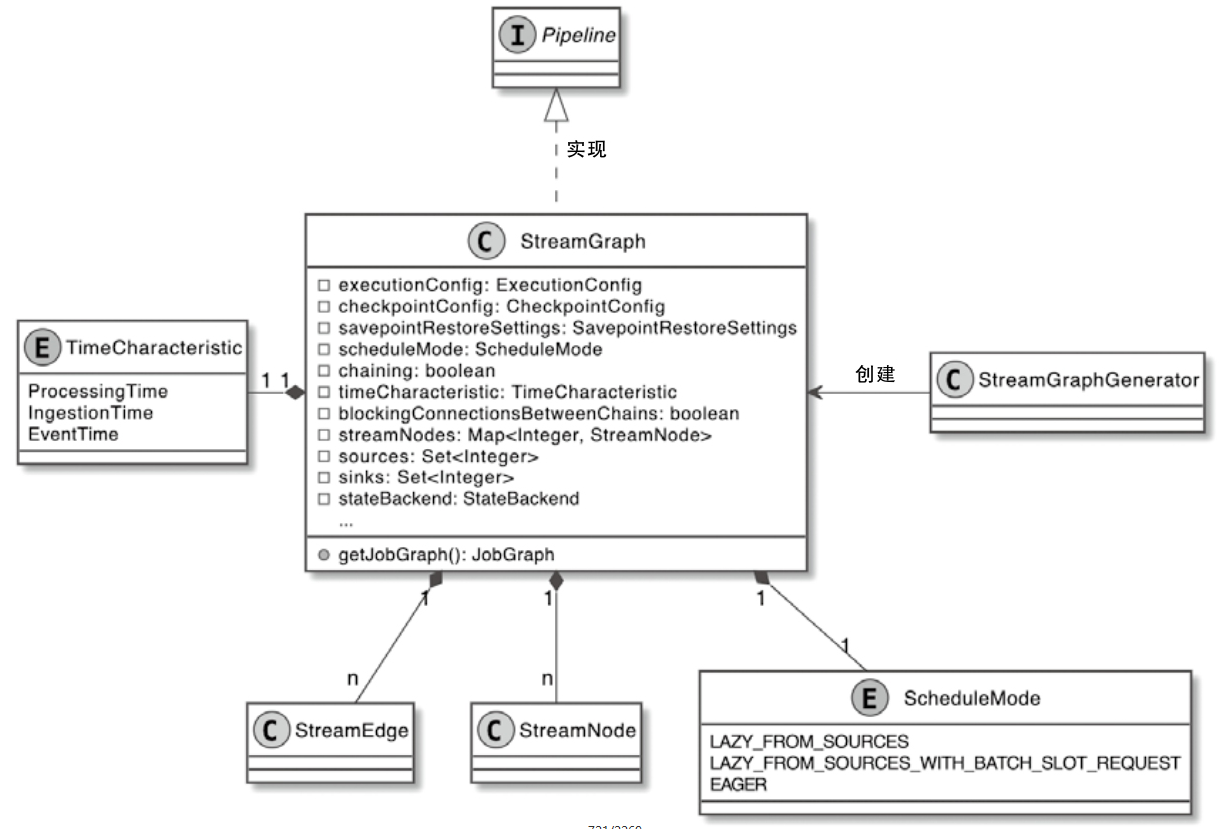
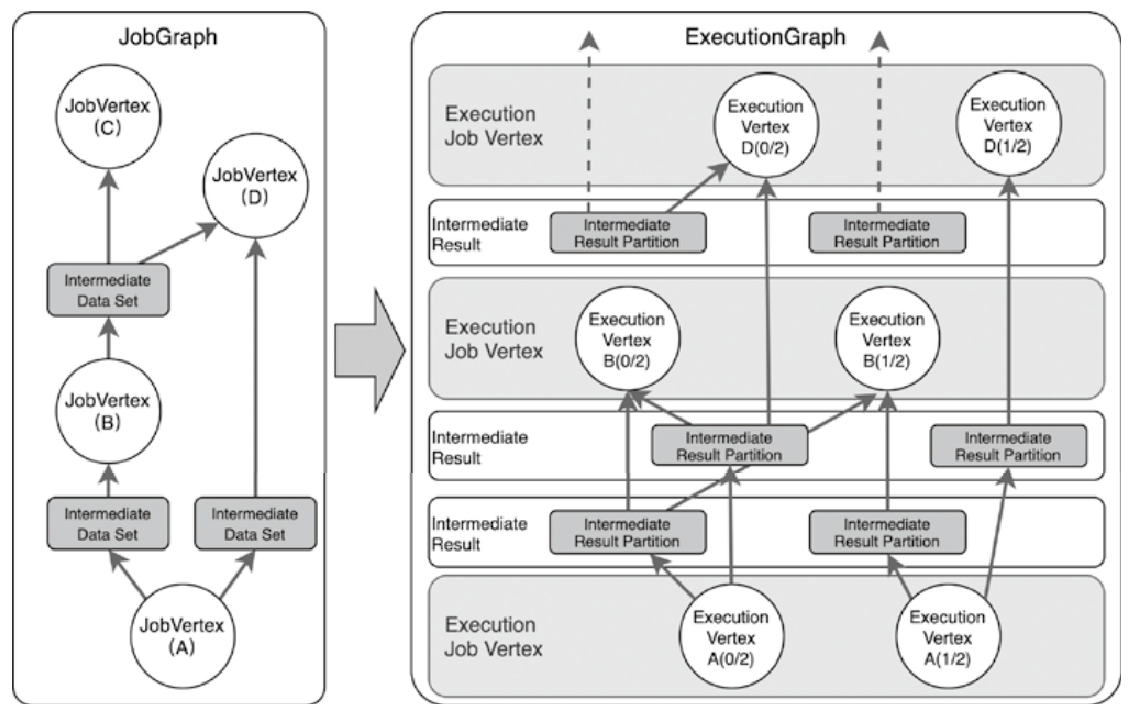
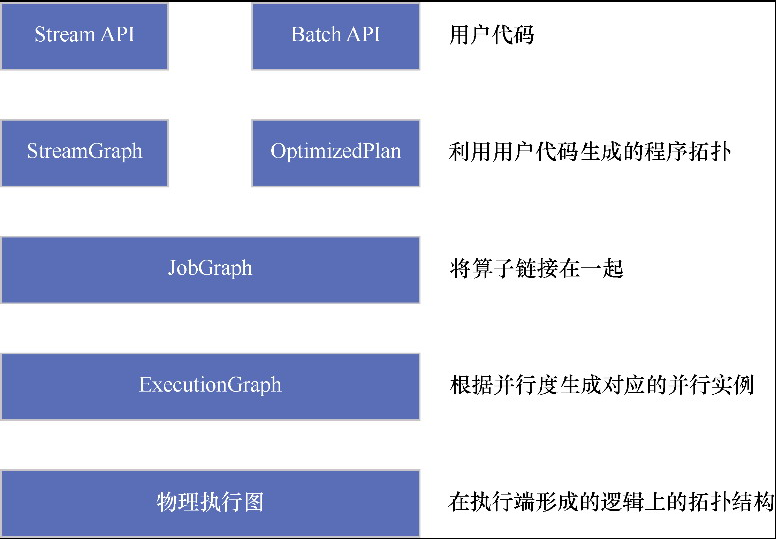
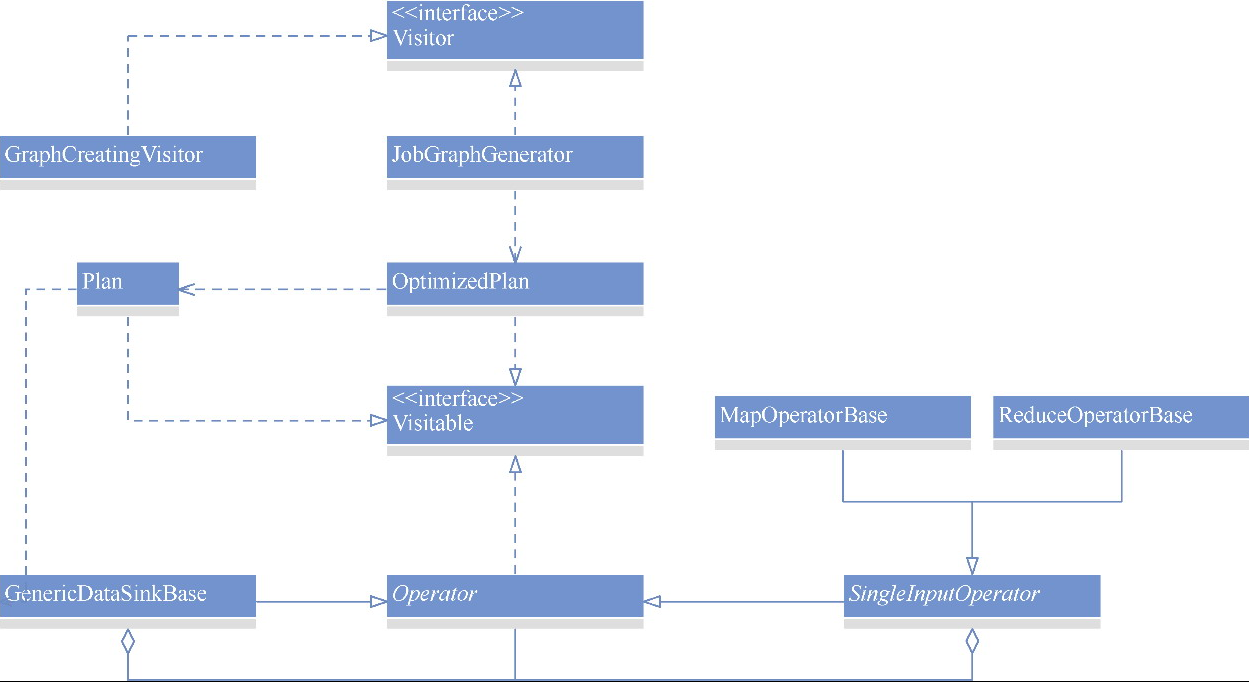
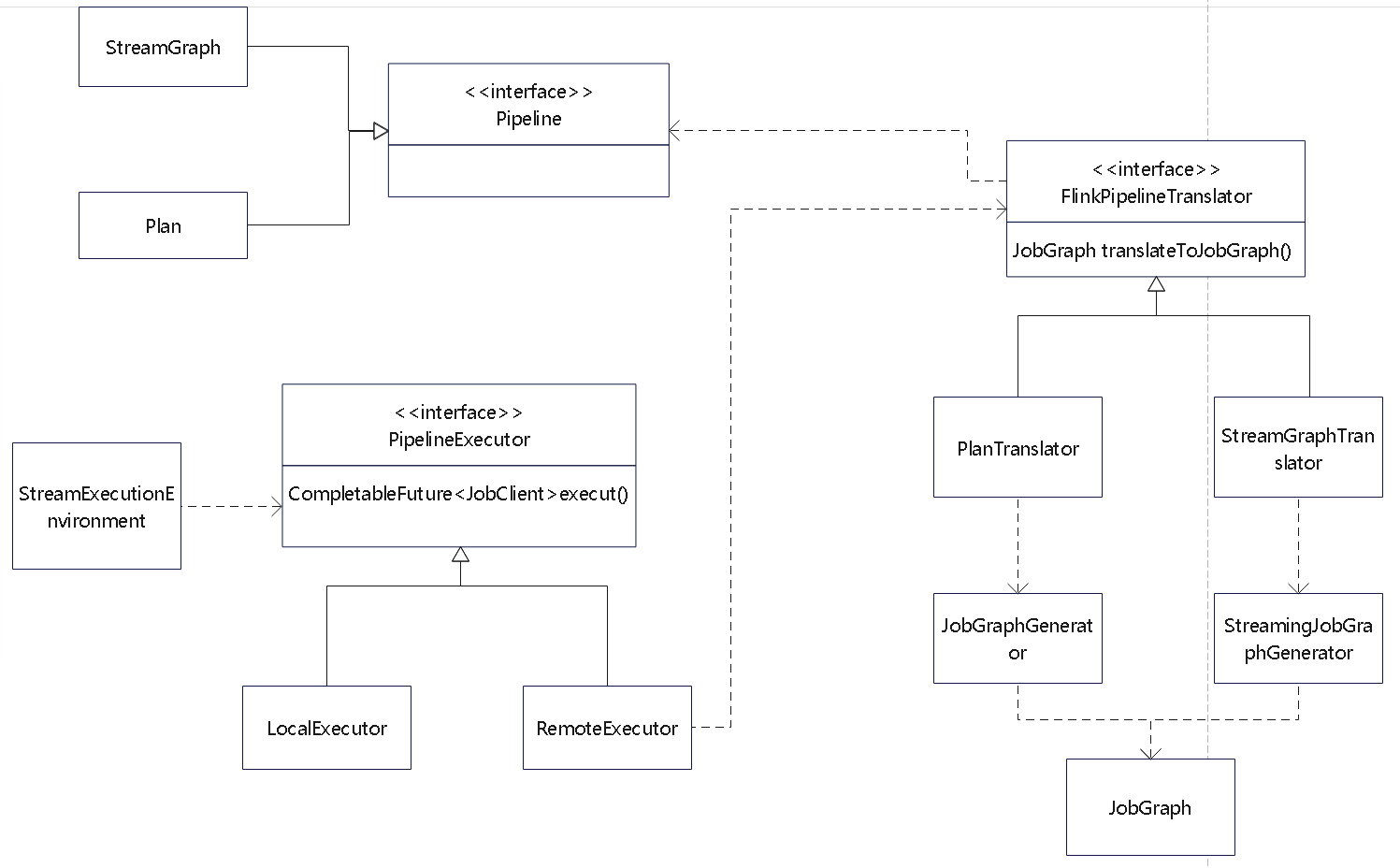
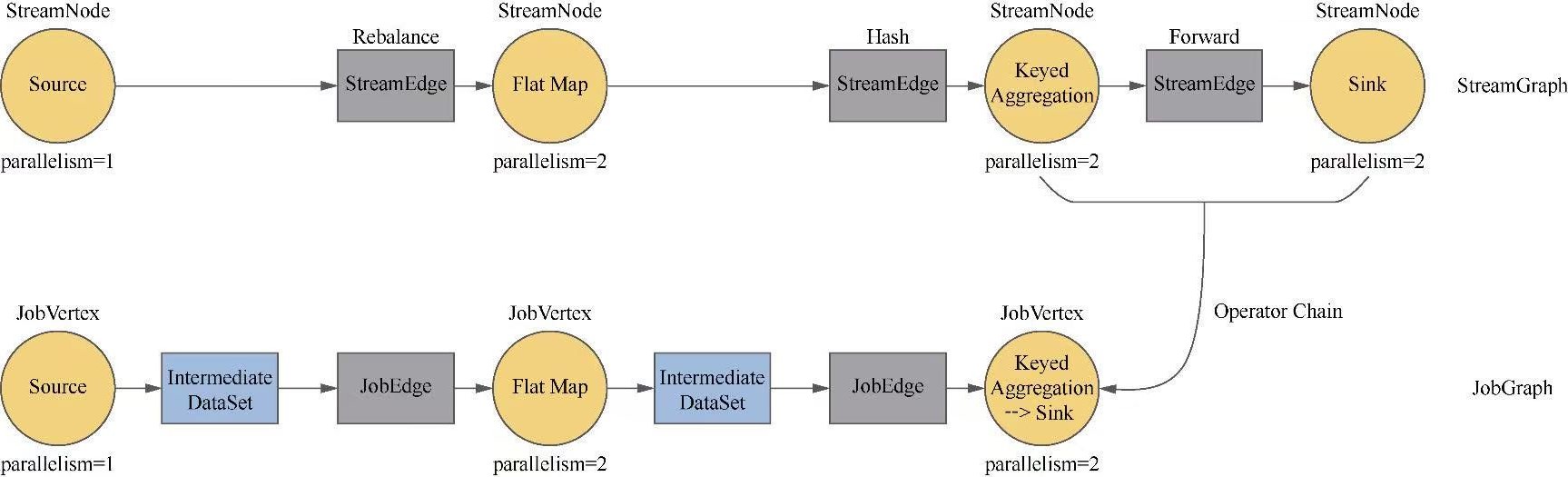
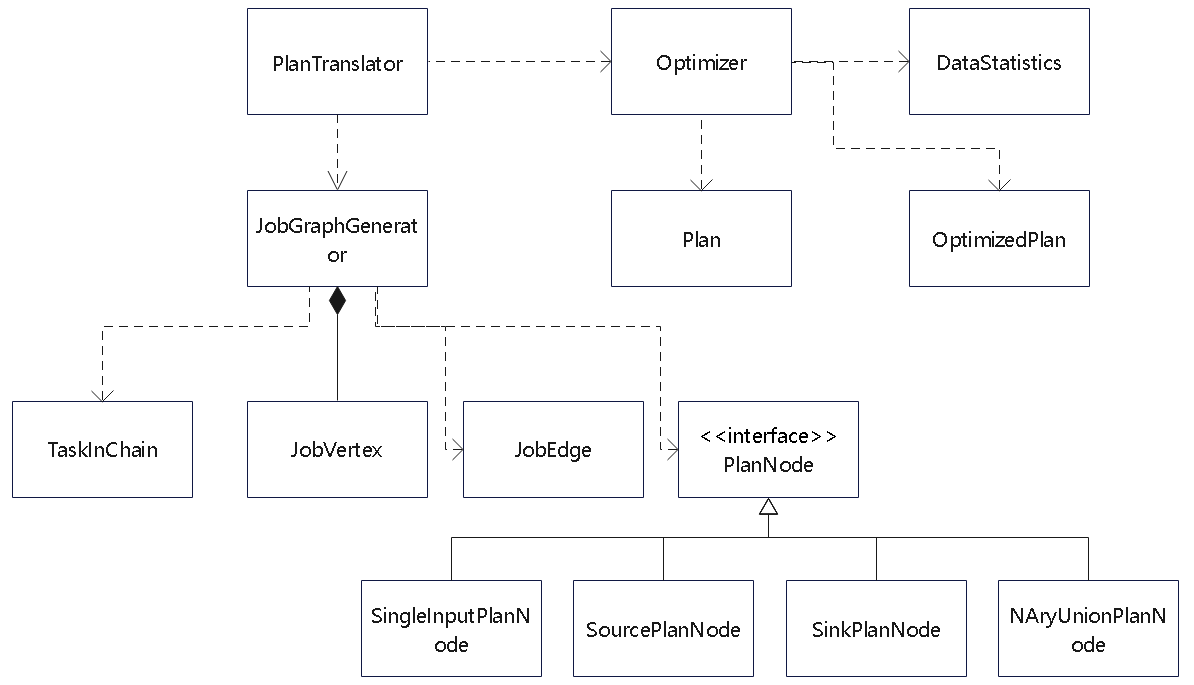
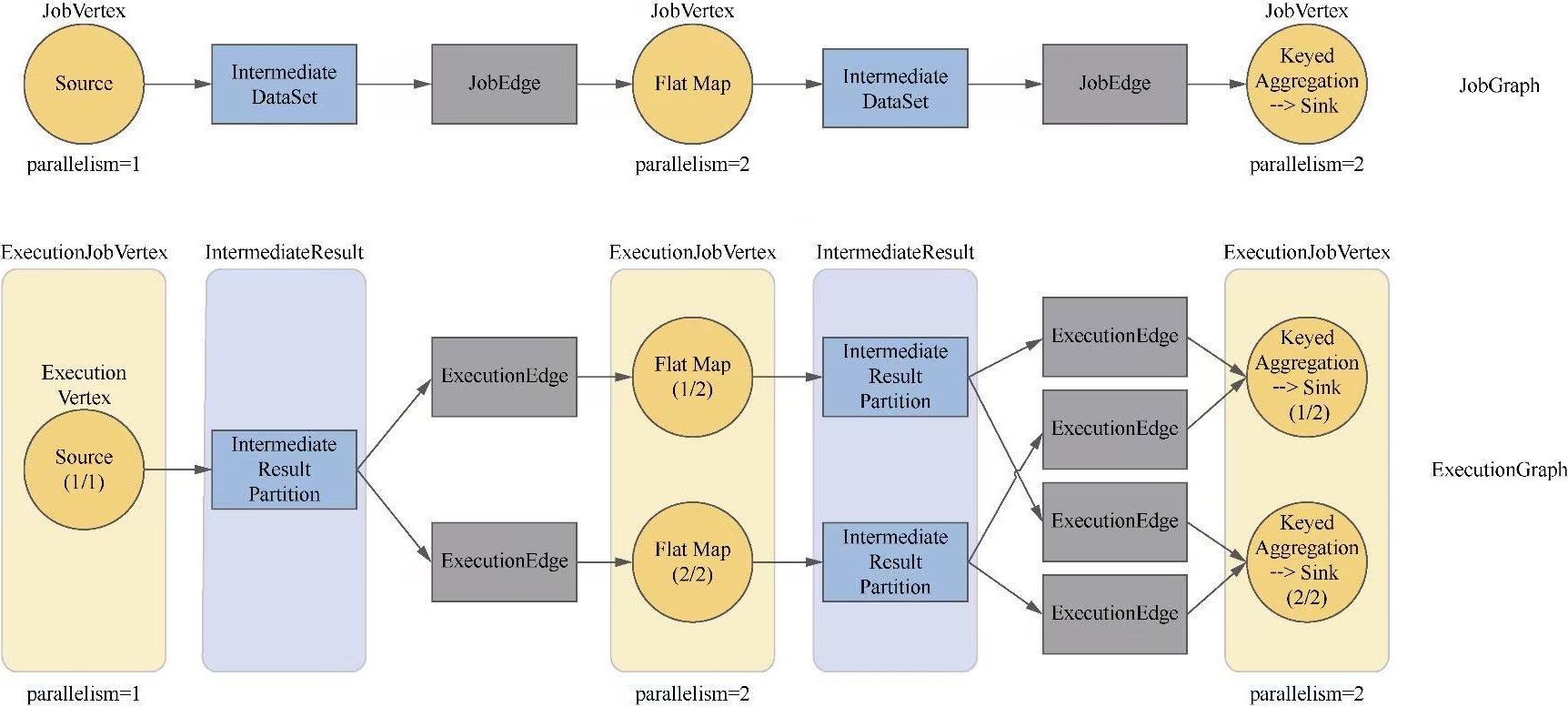
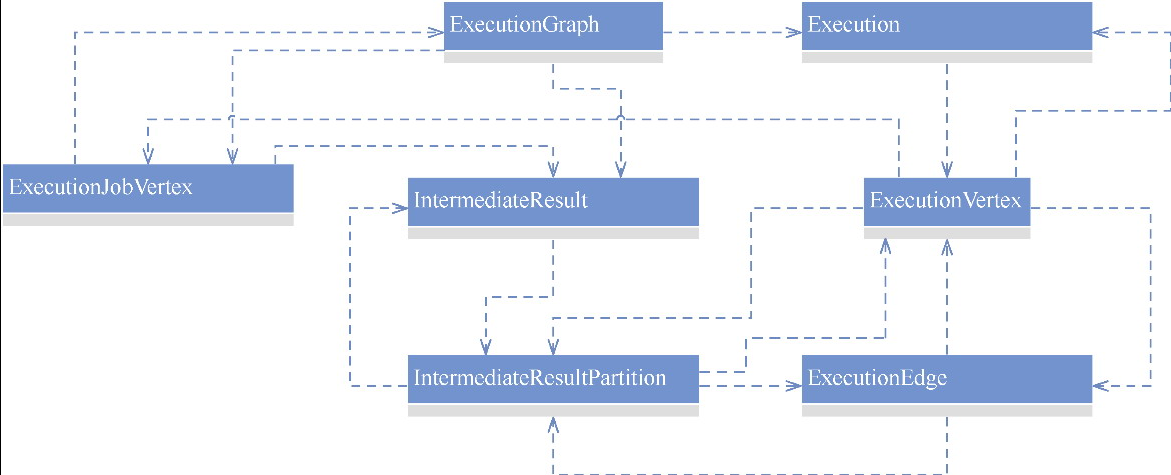
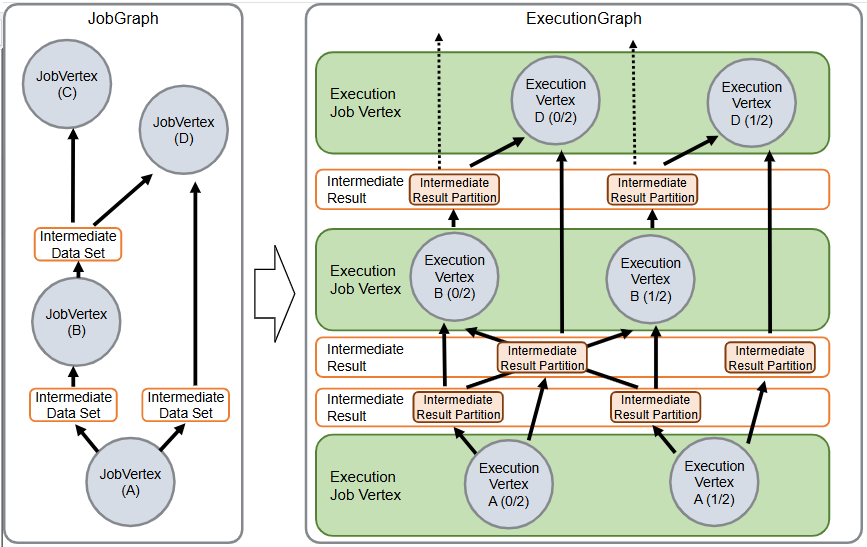
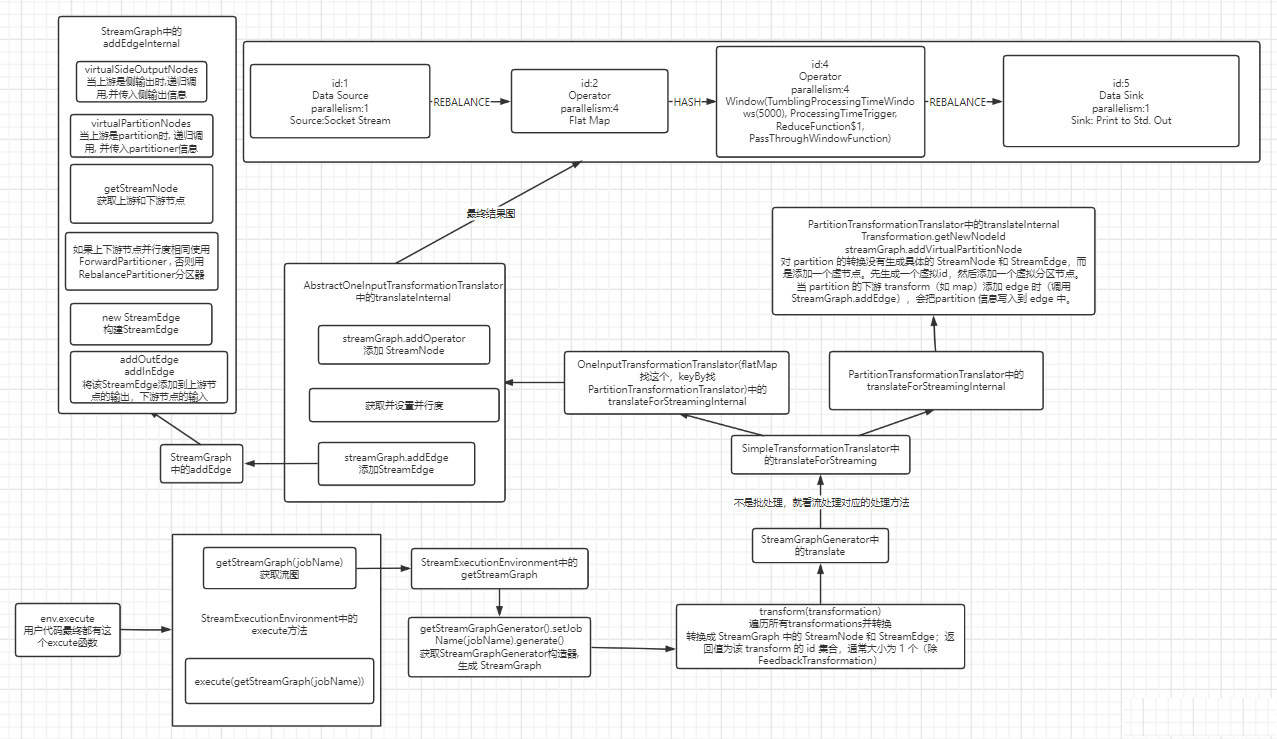
Flink 逻辑计划到物理执行的主线整理,重点包括:
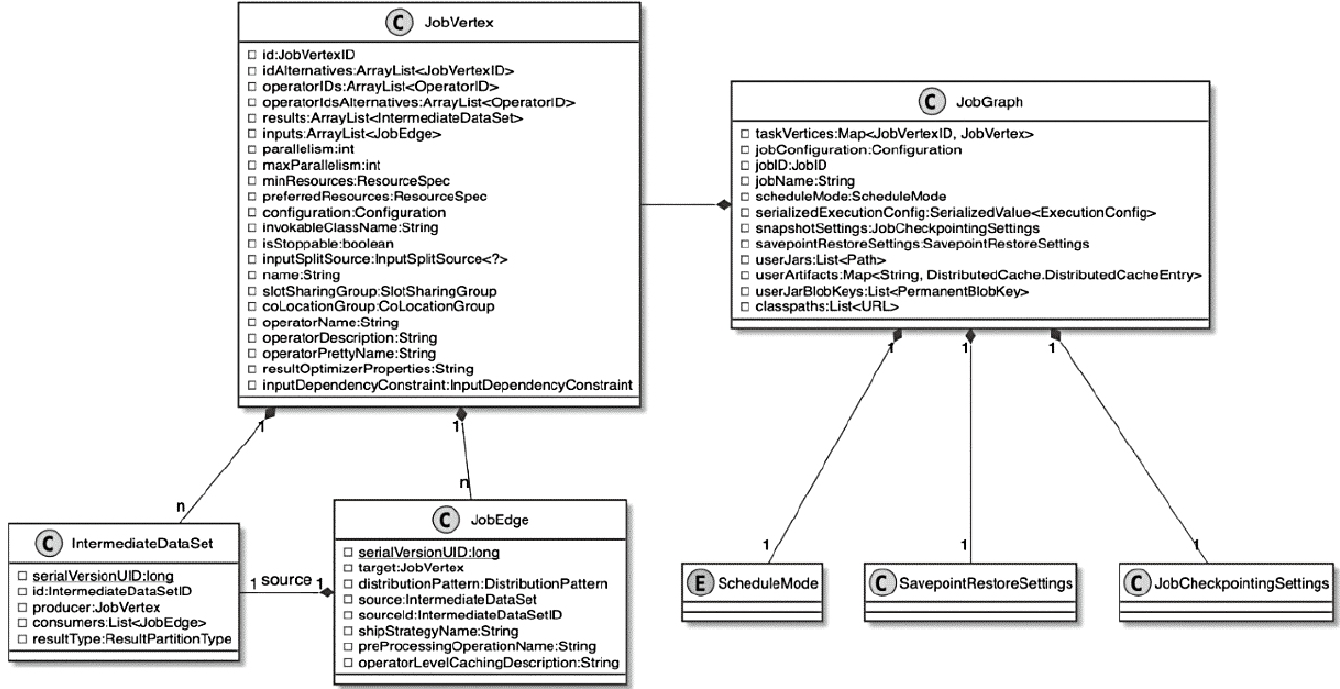
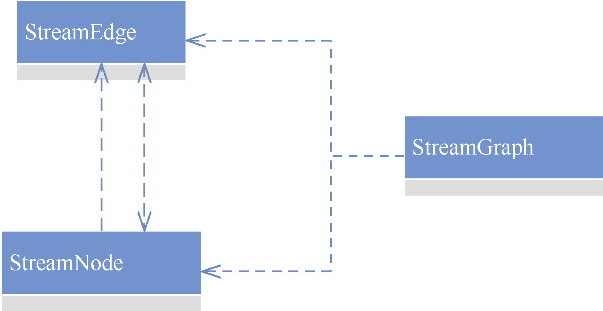
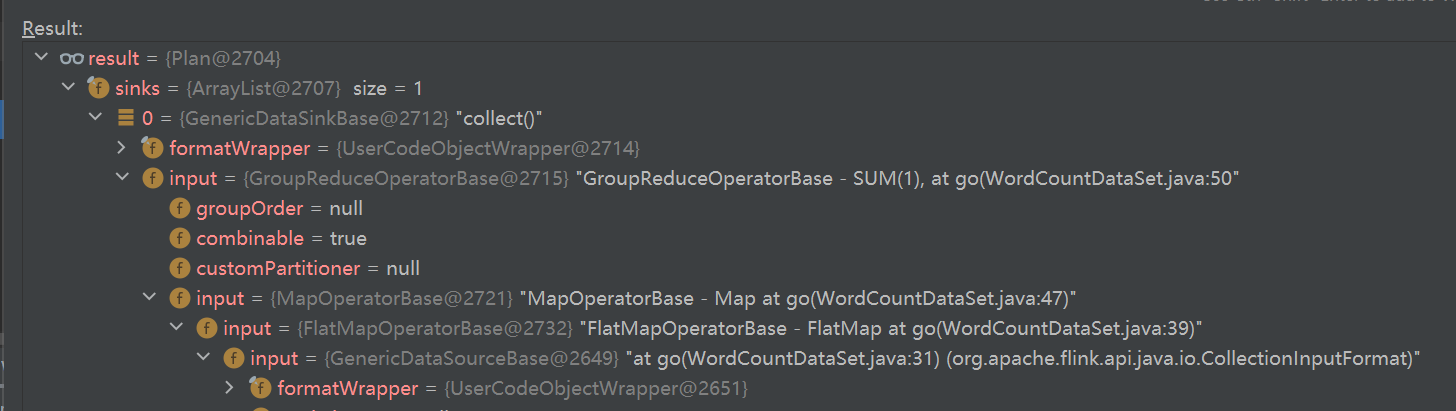
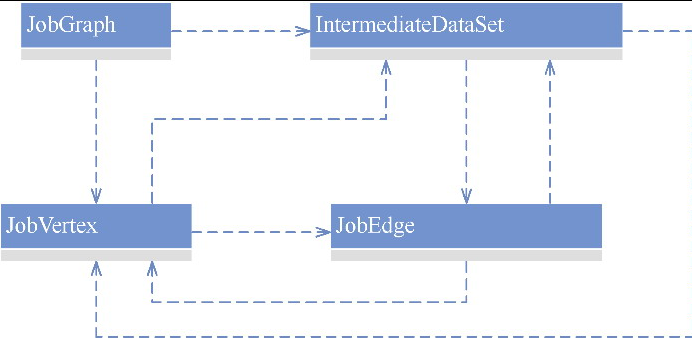
StreamGraph,批任务如何进入 OptimizedPlan,最后统一落到 JobGraphStreamNode、StreamEdge、JobVertex、JobEdge、IntermediateDataSet 这些图结构节点和边分别代表什么ExecutionGraph 并进入物理执行PyTorch 入门学习单,内容比较散,这里把主线收一下:
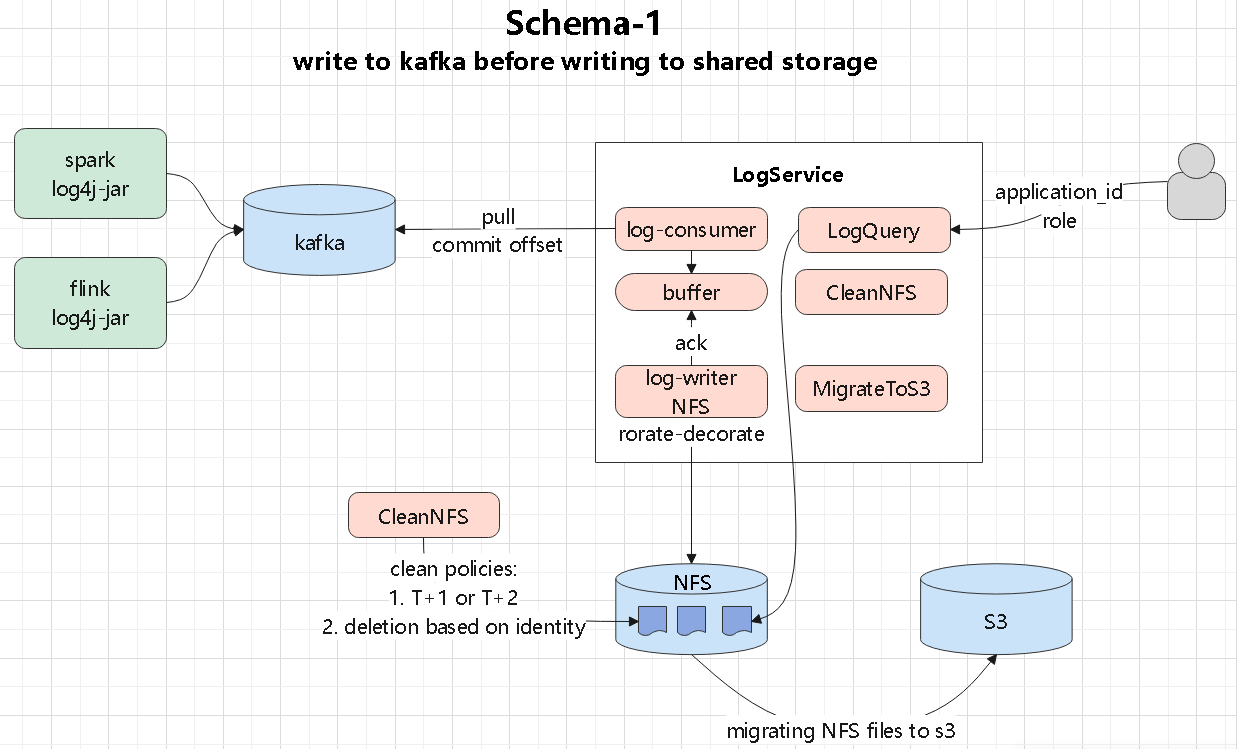
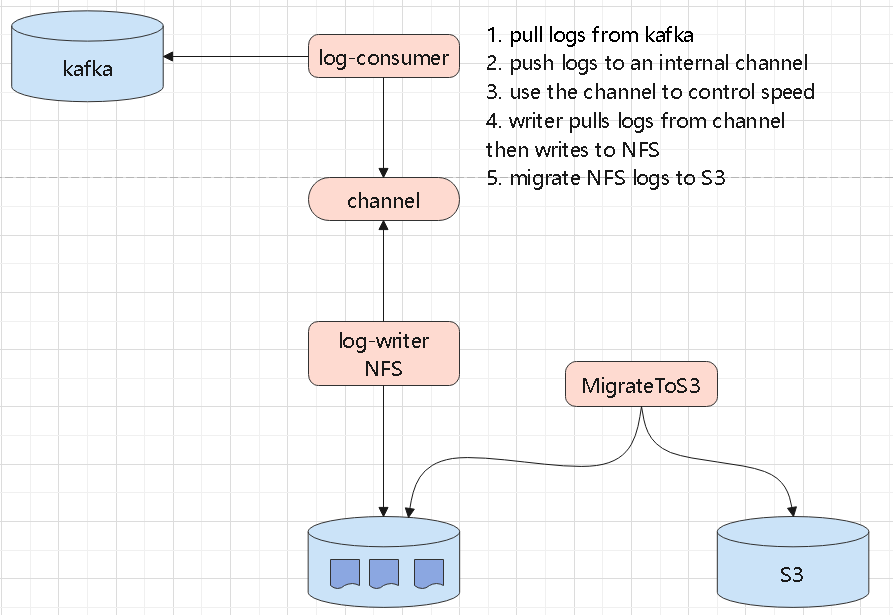
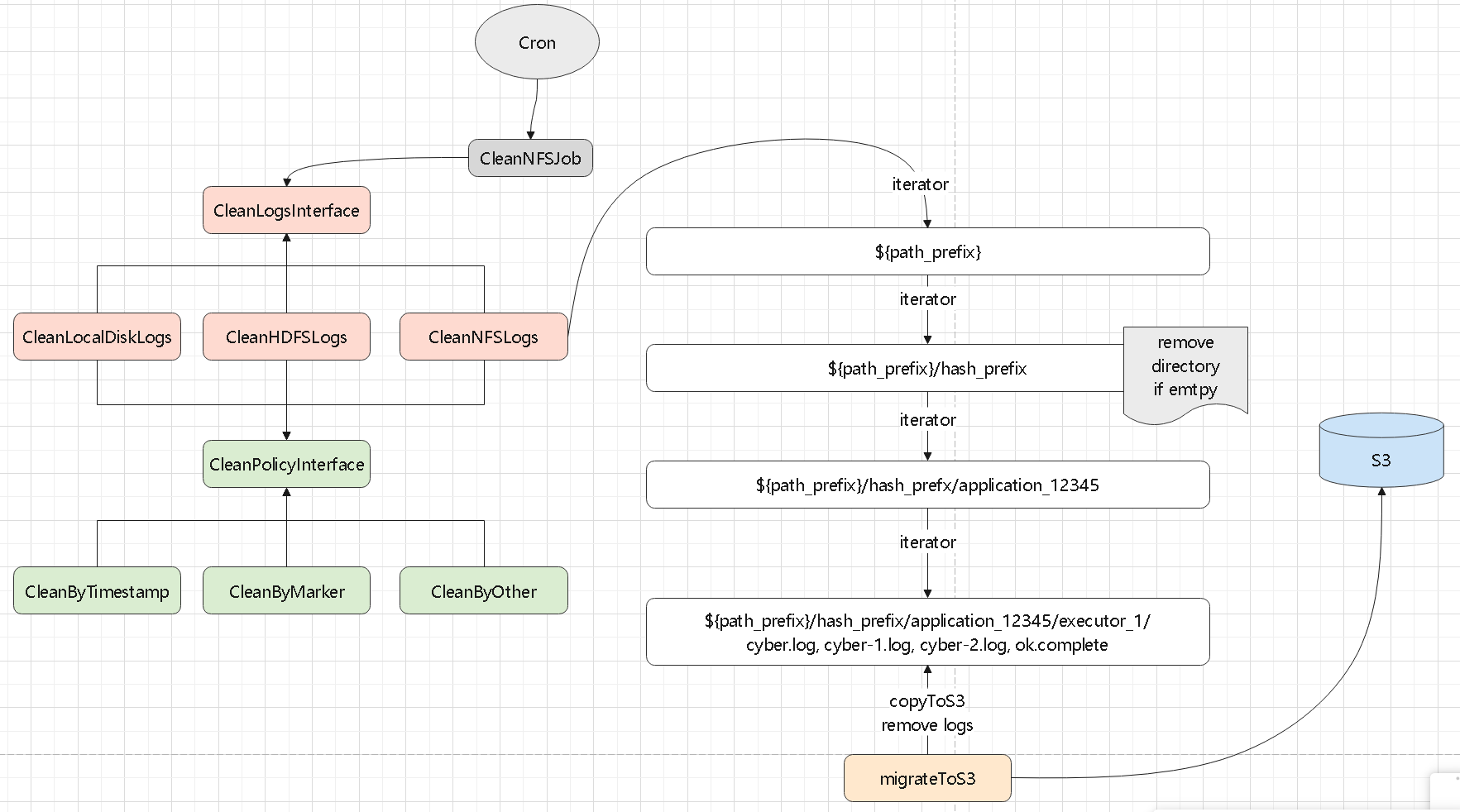
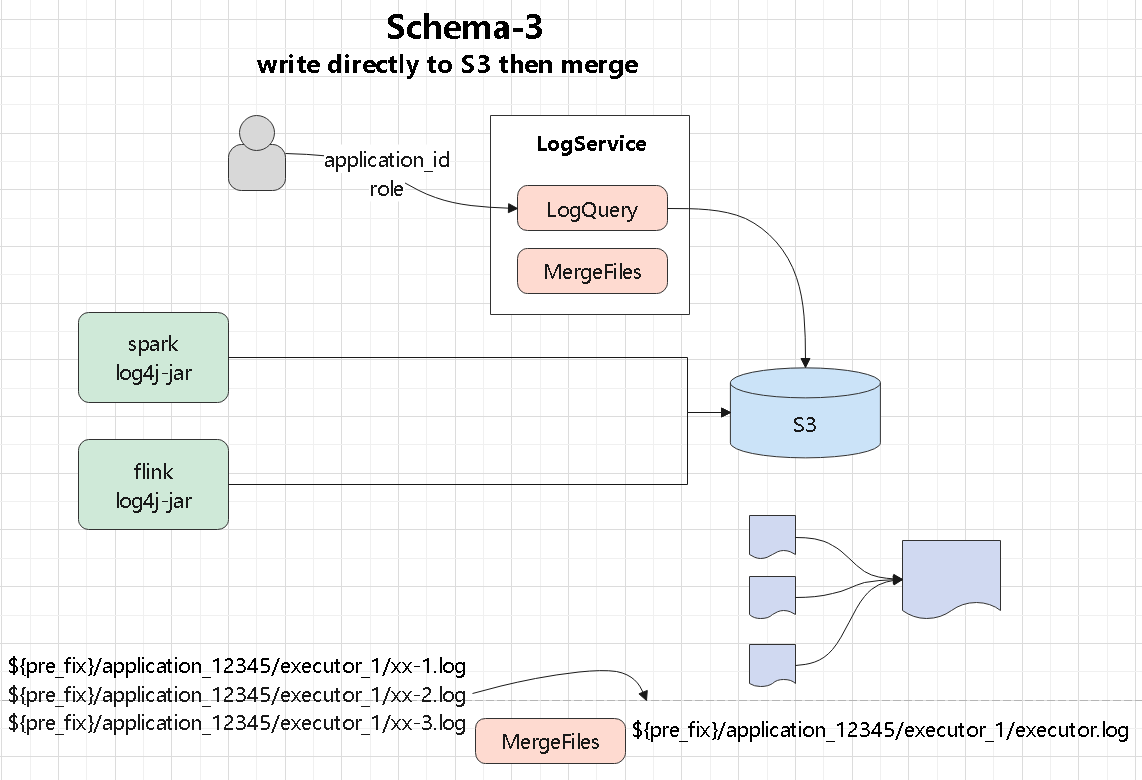
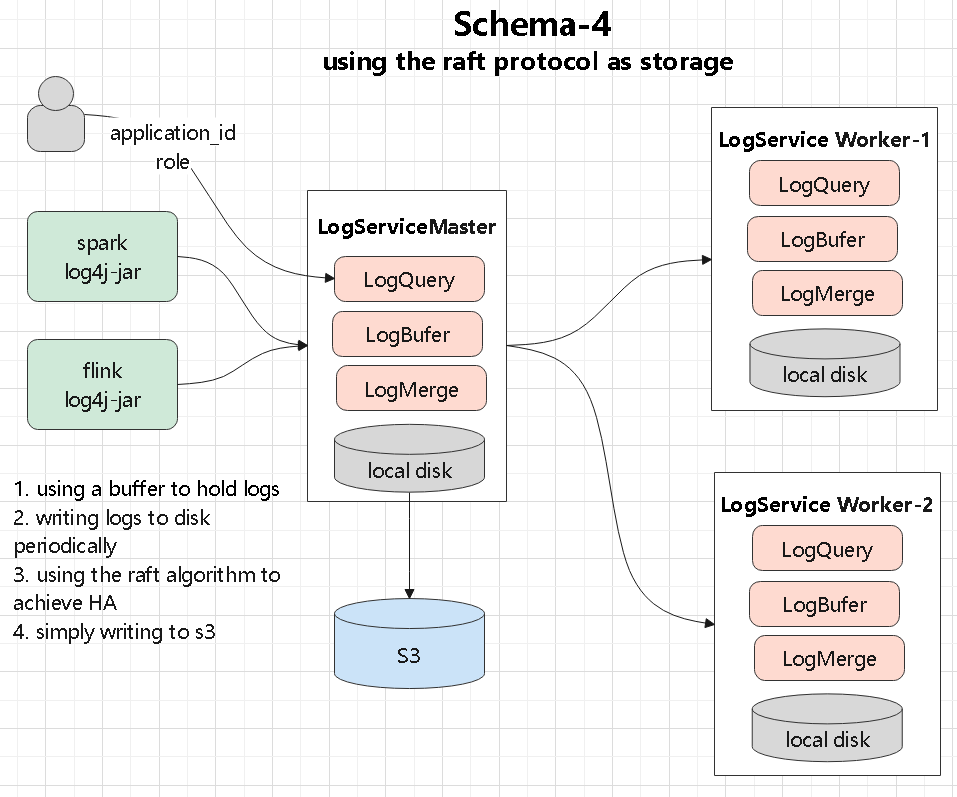
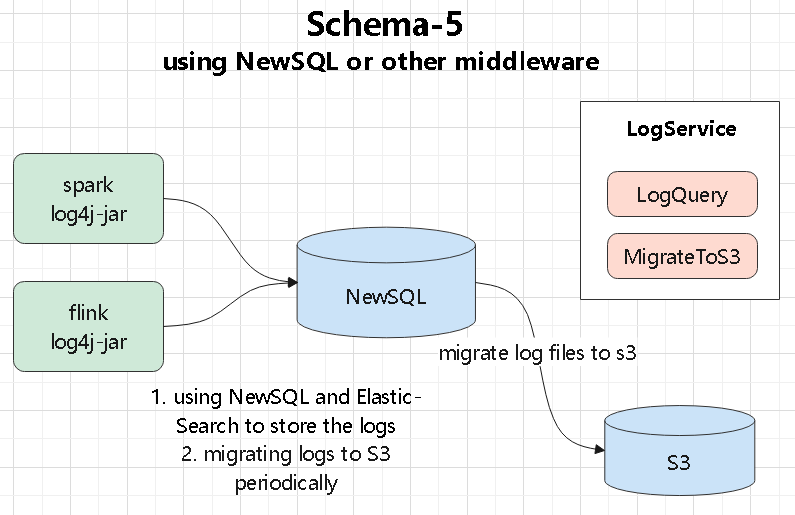
numpy、tensor、索引切片、张量和数组转换这些最基础的操作开始Torchvision、MNIST、训练评估、模型保存加载,以及常见图像预处理在公有云和 Kubernetes 环境里,日志怎么从 pod 里拿出来、再怎么落到后端存储:
log4j appender 直接发送,或者由辅助程序读取日志文件再转发Kafka、共享存储、S3,或者交给 Raft 集群、NewSQL 系统做聚合和索引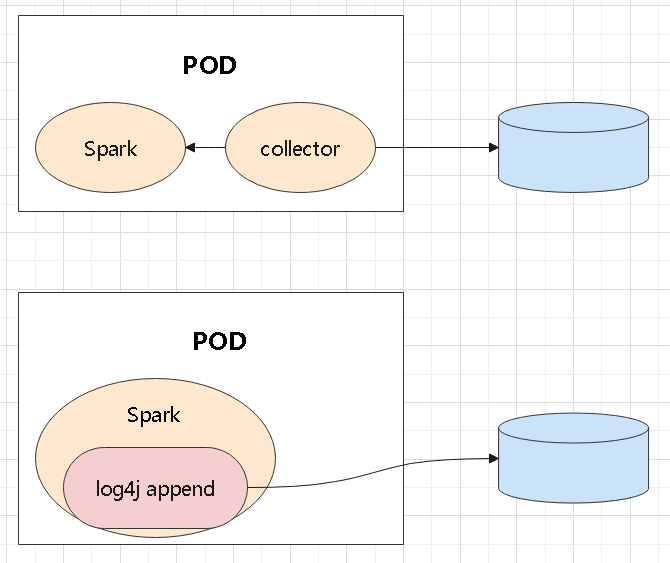

记录一个 BTrace 脚本,再顺带把几类 Java 线上诊断工具放到一起看:
Arthas retransform、jdb 这种更常见的调试方式做对照JFR、VisualVM、JProfiler、MAT、火焰图这些工具,方便按问题类型选手段