What Goes Around Comes Around
原文 https://15721.courses.cs.cmu.edu/spring2023/papers/01-intro/whatgoesaround-stonebraker.pdf
背景
论文介绍了 35年的数据模型演化过程,这些模型被分成9个不同的时代
不同时代提出的方案并非没有交集,后面的提案可能之前就出现过,所以学习历史对我们也很有帮助
这九个时代的数据模型包括
- Hierarchical (IMS): late 1960’s and 1970’s
- Network (CODASYL): 1970’s
- Relational: 1970’s and early 1980’s
- Entity-Relationship: 1970’s
- Extended Relational: 1980’s
- Semantic: late 1970’s and 1980’s
- Object-oriented: late 1980’s and early 1990’s
- Object-relational: late 1980’s and early 1990’s
- Semi-structured (XML): late 1990’s to the present
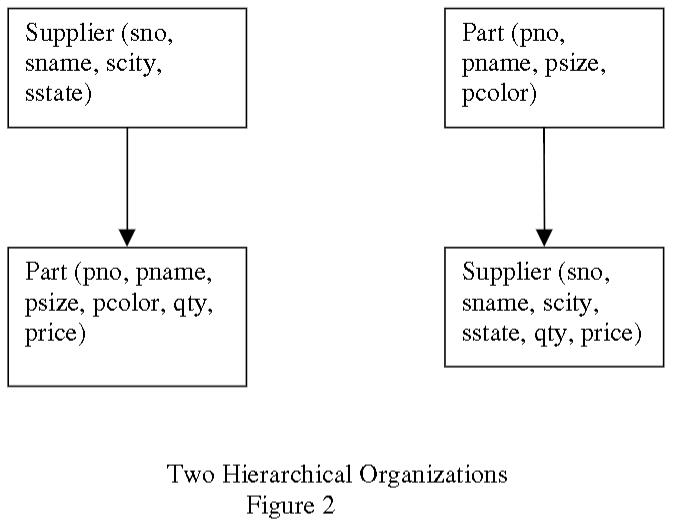
这里使用一个 供应商、零件、供应量的例子来作为模型
|
|
IMS Era
IMS (Information Management System) 是 IBM 开发的数据库管理系统
最初是为了处理大型事务性应用程序而设计的
这个系统非常适合处理 明确关系定义,如父子结构的数据集合
按照树状结构组织
比如有 Employee、Department
Employee 记录类型可能包含以下字段:
- Employee ID
- First Name
- Last Name
- Hire Date
Department 记录类型可能包含以下字段:
- Department ID
- Department Name
每个员工都必须由唯一 ID、每个部门也必须有唯一 ID
每个员工都必须属于一个部门
层次结构的问题
- 因为必须要有父子关系,如果一个零件是由一个供应商提供的,那么多个零件都需要指向这个供应商
- 同理,下图右边又需要重复零件的信息
- 重复数据的更新会导致可能出现不一致
- 对于边界条件,比如一个零件没有供应商,这种情况是不允许存在的
IMS 使用 DL/1 来操作数据,使用层次结构因为操作简单,有点类似于树的遍历
比如想获取 16号供应商下的 红色零件,可以这么写
首先获取 供应商,然后遍历其子节点
|
|
也可以用另一种方式:
|
|
这个相当于每个节点都有一个 key,然后子节点的key是:父节点key + 子节点key 这么拼接出来的
因为每个节点都key都是唯一,这样拼接出来的key 也是唯一的
IMS 支持多种不同的存储模型
对于 root
- 顺序存储
- B树 存储
- hash 存储
通过 root 找到依赖的记录其存储模式
- 物理顺序
- 各种各样的指针
ISM实际是把执行逻辑,存储模型给混合在一起了,这样就导致耦合性很高
应用层逻辑不能完全独立存储模型
这里有个关键词:physical data independence
物理数据的更改对上层应用是独立的,不管底层怎么改动,上层都可以照常运行,但 IMS 做不到
不过 IMS 也支持一定程度的逻辑数据独立,它定义的是逻辑数据集,可以跟物理数据集一样
当新插入物理数据后,可以重新定义逻辑数据集,将新加入的排除即可,这样逻辑数据 就是 物理数据的子集
上述定义的供应商、零件、供货信息 可能不适合 IMS 表示,但 IMS 也有应对策略
假设物理存储结构如下:
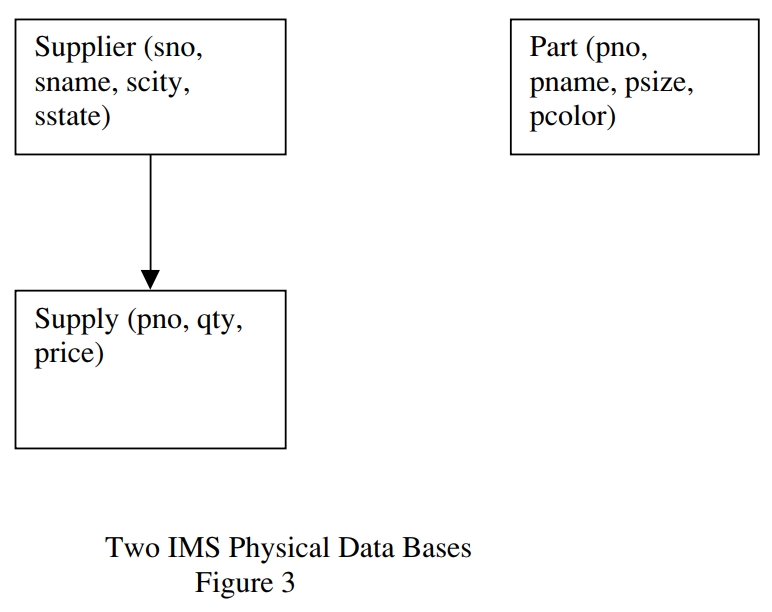
之后再定义一个 逻辑结构,将 供货信息、零件两个物理结构 连接起来,就可以解决上述问题了
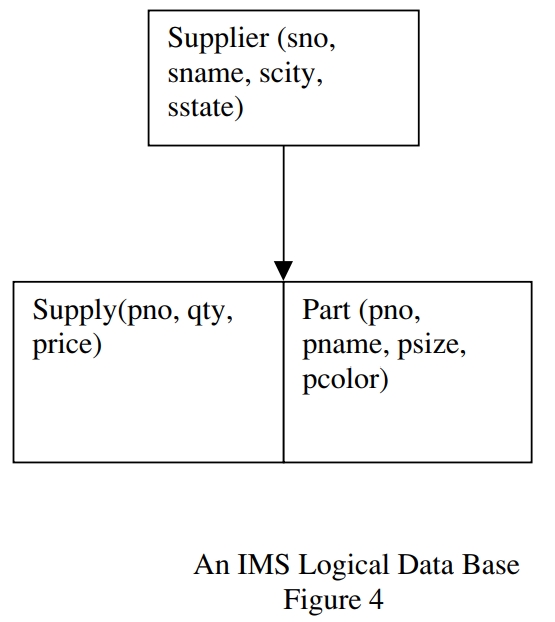
这就是 层次结构用来解决 非层次结构数据的方式,不过也有很多限制
比如对于删除、很复杂的场景也不好处理,这就是 IBM 未来决定支持关系数据库的原因
基于 IMS 的经验总结
- 物理数据、逻辑数据独立是非常重要的
- 树结构的数据模型使用起来很严格
- 为树状结构提供复制的逻辑重组是很有挑战的
- 一条记录一次查询,每个查询都需要手动优化,使用起来很麻烦
CODASYL Era
CODASYL 委员会于 1969 - 1973年,提出了一种基于 网络的数据模型,以及一种以记录为单元的数据操作语言
这种模型,将记录类型组织成一个 图结构,而不是树结构,比如 以供应商、零售商、供货记录为例
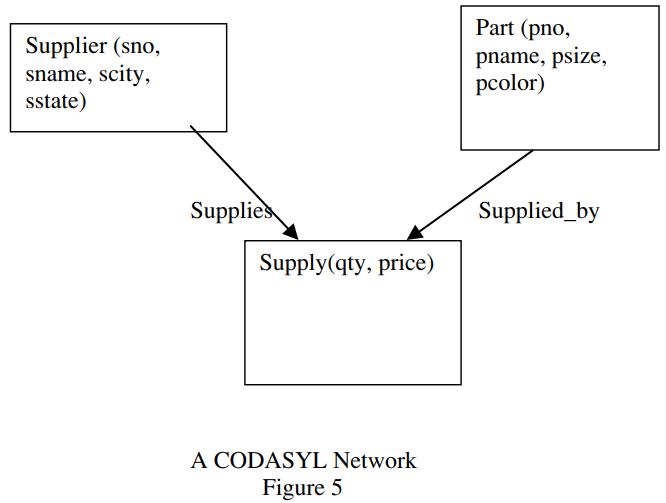
上图中包含了三种记录类型
- Supplier
- Part
- Supply
在 CODASYL 中,用 命名弧线 来表示两个记录之间关系,实际就是 多对多的关系
也可以用 关系数据库中的一个中间表,来模拟两个表的多对多关系
- Supplies,表示 Supplier 和 Supply 之间的关系,1 对多
- Supplied_by,表示 Part 和 Supply 之间的关系,1 对多
CODASYL 建立的是两个类型之间的多对多关系,是二元实体关系,如果有多个类型之间有关联
则必须要拆分开来表示,比如有 新郎、新娘、牧师 之间的关系,需要用下图来表示
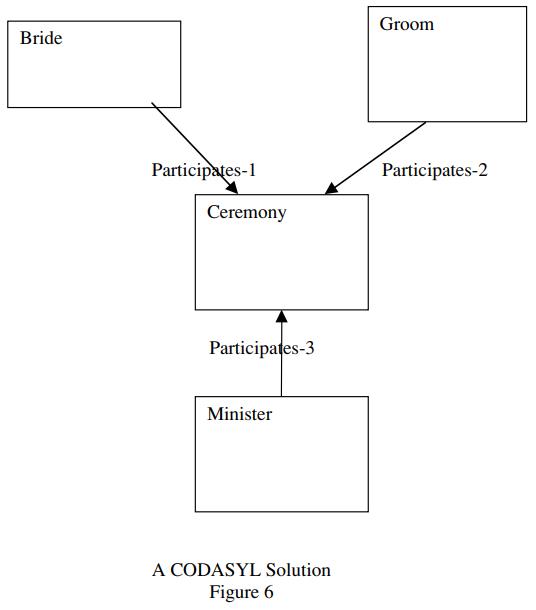 所以是用 三个二元关系,来表示三元关系的,这就增加了复杂性,不过它比 IMS 更灵活
所以是用 三个二元关系,来表示三元关系的,这就增加了复杂性,不过它比 IMS 更灵活
下面是一段遍历算法
|
|
先定位到 Supplier 16
- 然后,在Supplies类型子集合中查找所有与该供应商相关联的Supply类型记录,并依次处理每个Supply record
- 对于每个 Supply record,需要在 Supplied_by 类型子集合中查找其所属Part实体并获取当前record
- 最后检查该Part是否为红色零件即可完成查询过程
CODASYL 需要将每个记录的入口点做 hash
但这种方式是逻辑数据、物理数据紧耦合的,以你为记录之间的关系是定义在 set 集合中的
set 又是存储到物理存储上的,记录了指向关系的指针
所以任何结构的变更,都会改变底层的物理存储,从而影响上层的访问
每次遍历都需要程序员手动维护游标
- 最后一条被应用程序访问过的记录
- 每种实体类型最后一条被访问过的记录
- 每种集合类型最后一条被访问过的记录
程序员在用游标不断遍历获取数据,对于大型的项目,甚至需要一张地图来标记当前位置和游标指针
Charlie Bachman曾在1973年图灵奖颁奖典礼上提出了“导航超空间”(navigating in hyperspace)的概念
另一个问题是 IMS 由于是简单的父子关系,遍历时会有多次导入
而 CODASYL 的多对多关系,需要一次性导入,增加导入时间
而且数据损坏则需要重新加载所有数据库,与将数据划分为独立数据库的集合相比,崩溃恢复往往更复杂。
基于 CODASYL 的经验总结
- 网络比层次更灵活,但更复杂
- 加载和恢复网络模型比层次模型更复杂
Relational Era
Codd发现 IMS 开发人员在物理、逻辑数据变更时都要花很长时间来调整数据,这使得他决定做一些修改
于是就出现了关系模型,Codd 的提案有三点
- 数据存储到一个简单的数据结构中
- 访问数据通过一种高级别的操作 DML
- 不需要对物理存储有什么建议
因为逻辑、物理数据独立,并提供了高级别操作,使得 IMS,CODASYL 的那些问题就不存在了
此外,关系模型还提供了更灵活的表示,对于 供应商-零件-供应信息,以及新郎-新娘-牧师 这些类型可以很好的表示
|
|
之后 Codd 在 SIGMOD,以及 SIGFIDET 跟 CODASYL 的支持者做了很长时间的辩论
Codd的观点是
- CODASYL模型很复杂,而且对于像婚姻这种常见的场景都表示不好
- 逻辑数据、物理数据耦合,导致编程很复杂
之后的很多年里双方都认识到了自身的问题,也做了修改
再看商业市场,IBM 最开始卖的是基于大型机的 IMS,后来小型机,个人电脑出现
层次模型和 CODASYL失败了
IBM 当时想采用 SQL作为前端,后端继续对接 IMS,但是发现这两种模型并不匹配,强加在一起其实是很困难的
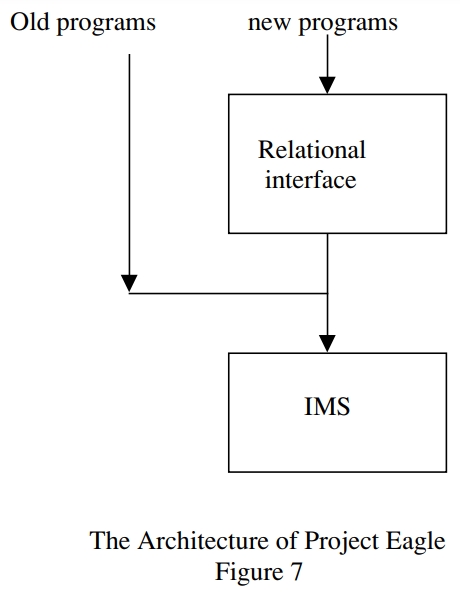
到 1984年推出了 DB2,IBMS 开始采用双数据库策略,同时搞两个产品
但是 DB/2 明显更简单,更有未来前景
当时 IBM 在数据库市场有巨大的份额,他宣布的结果基本上就判定了 关系数据库赢得了胜利
从这场争论到市场化,我们可以学到
- 不管数据模型怎么变,使用 Set-a-time(基于时间戳变更的方式而不是覆盖),提供了更好的物理数据独立性
- 简单模型比复杂模型更容易实现数据独立
- 技术的争论通常由市场的实际需求和其他因素决定胜负,这与技术本身无关,所以技术发展受到商业和社会的影响
- 查询优化器的效果,比人工优化的效果更好
The Entity-Relationship Era
这是在 1970年代中期被提出来的,作为 关系模型、层次模型、CODASYL 的替代
在实体关系模型中,数据集就是 实体实例的集合,实体之间彼此是独立的
比如
- Supplier 就是实体
- Parts 也是实体
实体可以有属性,比如 Parts包含:pno、pname、psize、pcolor
还有一个或者多个唯一的属性,如 key
实体之间可以有关系,这个关系是 1-1、1-N、N-1、或者是 M-N 的
比如 Supplier 和 Parts 之间的关系,就是 M-N 的
关系也有属性,比如qty、price等
不过 E-R模型并没有做到 数据库底层的数据模型
- 可能是当时没有支持它的查询语言
- 或者是当时被关系模型的出现所掩盖了
- 或者某些地方看起来太像 CODASYL 模型了
E-R 模型中用方框和尖头来表示
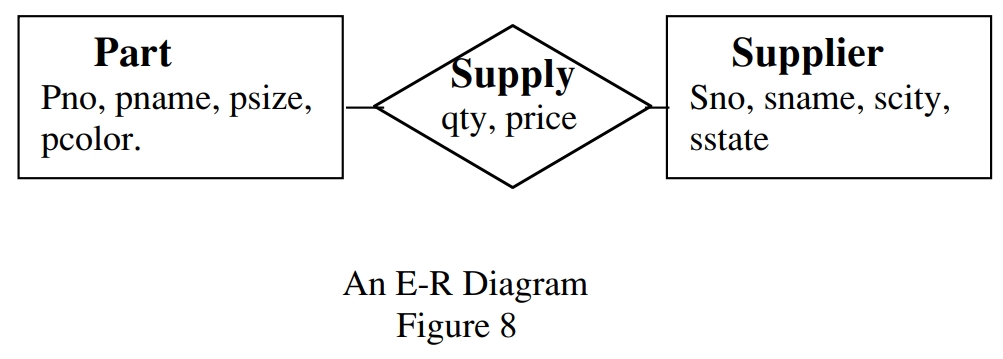
E-R模型在数据库模型设计上取得了巨大的成功
当时关系模型的倡导者建提出了各种理论,比如 第二、第三、第四范式
但这些理论 对于 DBA 帮助不大
而使用 E-R模型,用来构建表的结构,转换为 第三范式就狠简单
总结
- 功能依赖对于普通人来说难以理解,KISS 保持简单是很重要的
R++ Era
1970年代除了一些 parper,他们的主要目的是对关系模型的一些改进
这些研究包括
- CAD
- VLSI CAD
- 文本管理
- 时间
- 电脑绘图
这里有一些比较好的扩展属性
- set-valued 属性,比如一个零件可以由多种颜色,这些颜色表示这个属性的集合值,或者是用户的爱好标签也是类似的
- aggregation,类似SQL语法中的聚合
- generalization,允许有继承关系
比如 Supply (PT, SR, qty, price),PT来自 part表,SR来自Supplier表
可以使用如下SQL
|
|
这种查询方式于 网络语言中的 路径表示方式
“Supply.SR.sno”指代 Supply 表格和 Supplier 表格之间存在外键关系,并且通过 SR 属性引用了 Supplier 表格中与当前记录相关联的供应商信息
“Supply.PT.pcolor” 指代 Supply 和 Part 两张表之间存在外键关系,并且通过 PT 属性引用了 Part 表格中与当前记录相关联零件信息
WHERE 子句中使用 “pcolor = ‘red’” 条件过滤出所有颜色为红色(即 pcolor 列等于 “red”) 的零件所对应供应商编号 sno
泛化的继承关系如下,电器零件、管道零件都有相似的属性
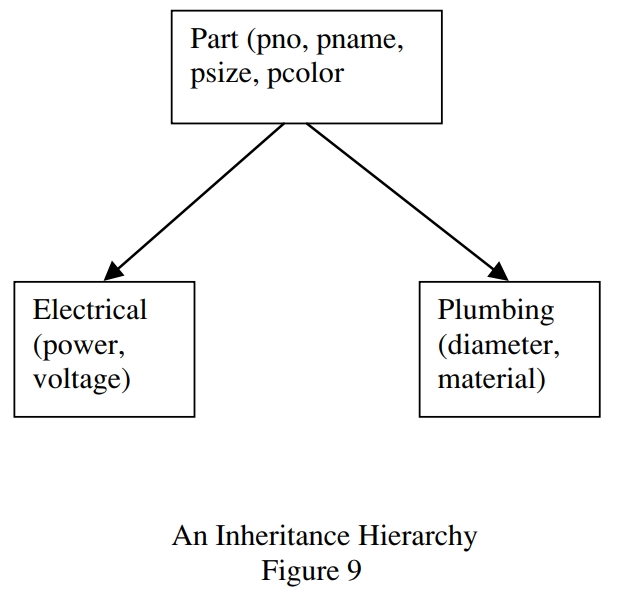
总结的经验
- 除非有很大的性能或功能优势,否则新的构造将无处可去
The Semantic Data Model Era
这种观点是,关系模型对于某些类型不好表示,于是出现了一种新的方案,叫做 post relational 数据模型
也叫做 语义模型
语义模型关注的是类别,跟R++模型类似,提出了 聚合、泛化、集合的概念
通过允许类具有作为其他类中的记录的属性来支持聚合
多重继承是SDM中的常见构造。类还可以是其他类之间的并集、交集或差集。
类还可以是另一个类的子类,由谓词确定成员资格
一个类也可以是由于某种原因而被分组在一起的记录集合
类可以有类变量,例如Ships类可以有一个类变量,它是类成员的数量
 上图展示了一个 多重继承
上图展示了一个 多重继承
在这个例子中,有三个类
- Oil_tankers
- American_ships
- American_oil_tankers
其中,Oil_tankers是所有油轮船只的父类(即最一般化)
而 American_ships 是所有美国船只 的父类
A merican_oil_ tank ers 继承了 Oil _tank ers 和 A merican_s hips 这两个类
因此它拥有这两者的属性
一个子类可以同时拥有多个父类,并且从每一个父级那里都可以获得属性和方法等信息
这个模型太复杂,后续几乎没有什么影响力
OO Era
出现在 1980年代,用来解决程序语言如C++ 和 关系数据库之间的阻抗不匹配问题
编程语言有他们自己的命名系统,数据类型,这和关系数据库之间并不匹配
比如用 C++定义的零件
|
|
之后用关系数据库做查询,然后将结果绑定到 结构体的变量中
|
|
有些语言,允许将 变量持久化,这变成了这样:
For P in Part where P.pno = 16{
Code_to_manipulate_part
}
允许以 程序语言的方式 做loop,但是需要做编译器扩展
而且每种语言的每个编译器都需要做一次扩展
而编程语言设计者一般不关注 I/O 方面的问题,所以也没有内置的库函数
到 1980年代开始为 C++做相关 OODB的扩展
比如一个 CAD程序,需要先打开,然后执行一些操作,关闭后会自动保存写入
对于这种情况,需要 C++将内存地址映射,以及磁盘地址映射关联起来
对于事务,查询语言的关注度就没那么高了,而且需要跟传统的C++ 编译器做竞争
失败的原因如下
- 仅仅只是自定义的加载和卸载,这种功能不算多强,用户未必买单
- 各种 OODB 不兼容,没有标准化
- 一旦做了修改,调用的逻辑还需要重新链接
- 非 C++ 生态不能使用
- 和用户逻辑在同一地址空间,安全和认证不好做,有隐患
O2 公司还做了一个 OQL的高级声明性语言嵌入到编程语言中
但他们的商业策略有问题,他们是法国公司,但主打美国市场,没有获得风投支持,失去市场
经验总结
- 除非用户真正出现了很大问题(比如编程语言和DB的严重阻抗不匹配),他们非常想解决这些问题,软件才有市场
- 没有编程语言社区的支持,想在语言上做出什么大突破不太可能
The Object-Relational Era
这是在 1982 年出现的,来自于一个简单的需求
假设有一个 GIS系统在表中这么记录的
|
|
如果要在一个边界内找到 (X0, Y0, X1, Y1) 的所有交点,则
|
|
POSTGRE 是用 B树存储的,是一维的,而这里是多维度的,很难表示,也很难高效的查询
另一种情况是要查询 土地拥有者
Parcel (P-id, Xmin, Xmax, Ymin, Ymax)
找到所有跟这个 矩形有相交的,然后通知他们
|
|
这种查询在 SQL 上很难表示,而且性能非常差
一个 OR提案可能会增加
|
|
对于上述问题,修改后的SQL是
|
|
!! “X0, X1, Y0, Y1” 表示 点范围
## “X0, X1, Y0, Y1” 表示矩形范围
为支持这些操作,需要增加自定义的类型,自定义的操作
需要增加 Quad-trees,以及 R-trees
这些就是 POSTGRE 的贡献
此外还有 Sybase 支持了 存储过程
- Postgres数据库管理系统的实现和商业成功,它是Object-Relational(OR)时代的一部分。
- Postgres实现了用户定义数据类型(UDT)、用户定义函数(UDF)和用户定义访问方法,
- 以允许定制DBMS以满足特定市场需求,例如在地理信息系统中
- 此外,它还实现了继承、指针、集合和数组等较不复杂的概念构造器来使其成为“面向对象”的数据库。
- 后来进行基准测试表明,在Postgres中UDT和UDF是主要优势所在
- 而内置聚合与泛化支持对性能提升帮助有限
- OR模型已经取得一些商业上的成功案例, 其中Illustra就是一个例子
这个时代 Informix 也比较成功
OR 模型的问题是,很多厂商之间不兼容,有他们独自的 UDF 功能
经验总结
- OR模型的主要好处,将代码放入数据集,模糊了数据和代码的不同;UDF 功能
- 新技术的推广,需要标准化,或者大力度的推广
Semi Structured Data
DB 的数据需要提前定义好模式,然后才能写入
而有些数据可以不用事先定义模式,这些数据往往有自解释的模式
一般叫做:schema last 的系统,如果没有自描述,则变成了一堆bit
需要在属性上定义一些元数据来描述这些数据,比如
Person:
Name: Joe Jones
Wages: 14.75
Employer: My_accounting
Hobbies: skiing, bicycling
Works for: ref (Fred Smith)
Favorite joke: Why did the chicken cross the road? To get to the other side
Office number: 247
Major skill: accountant
End Person
Person:
Name: Smith, Vanessa
Wages: 2000
Favorite coffee: Arabian
Passtimes: sewing, swimming
Works_for: Between jobs
Favorite restaurant: Panera
Number of children: 3
End Person
上面定了两个 person,但是他们的属性并不相同
这就给查询和使用带来了困难和挑战,他们叫做: semantic heterogeneity
schema last主要适用于以自由文本为数据输入机制的应用程序
为有效利用 schema-last,将应用分类四类
- 有严格结构化的数据
- 有严格结构化数据,以及一些文本字段数据
- 半结构化数据
- 文本数据
比如工资单,这种不允许错误,不允许出现格式问题,就必须要严格的格式,需要schema-first
另一种比如员工信息,大部分需要严格格式,有些字段如上一家的主管评价可以是自由文本,这就是第二种分类
广告、简历则需要半结构化,因为没有公用的部分,这时候可以自解释,然后提取出需要的信息即可
第四类是文本信息检索,他们没有模式
除了广告、简历之外,很少有符合第三类的数据模式,也就是说第三类的应用很少,相反第二类的则会很多
另外这类的应用,似乎只适合处理少量的数据
XML模型则是目前最复杂的模型,包含了之前出现过的所有特性
- 类似 IMS的层次结构
- 包含link 到其他记录,类似CODASYL
- 包含一个属性数据集,类似SDM
- 带有继承特点,类似SDM
此外它还有联合类型,如果一个联合类型包含了 N、M中类型,那么如果做 join的话
其查询计划就需要只要有 max(N, M) 种,大大增加了复杂度,所以union 类型从来没有在 DB 中被考虑过
经验总结
- schema-last 可能只合适小部分场景
- XQuery相当于是 SQL的扩展
- XML不能解决企业内部、跨企业的语义异构问题,即使是薪资,可能是法国税后包含午餐津贴、另一个是美国税前,没有比较性
Full Circle
历史就是一个轮回,30多年的数据模型发展历史,先是从复杂的模型开始
然后是 复杂模型 vs 简单模型 的大辩论,简单模型易于使用最后获胜
随后就是一系列的功能增强,但这些没能吸引市场,因为增加了很多复杂度,但却没能带来更多的好处
只有 UDF,以及自定义访问方式 能吸引人注意
而当前的功能是之前的超集,所以我们相当于是绕了一圈
XML 的倡导者 vs 关系模型,跟 第一场大辩论,关系模型 vs CODASYL 很类似
有点像 关系模型 vs CODASYL-2,但 CODASYL-2比之前的更复杂,想做到数据独立就更困难
从历史来看,如果原生的 XML 数据库获得关注,那么逻辑数据独立、复杂性方面的问题依然会出现
大多数新发明则是对过去的模型的重新发明而已,唯一值得注意的概念是
- Code in the data base (from the OR camp)
- Schema last (from the semi-structured data camp)
不过 schema-last 只是用于小众领域
而 code in DB 的想法不错,让数据和代码变得平等了