eBPF 内核跟踪
查找内核
内核函数是一个非稳定 API,在新版本中可能会发生变化
挂载的内核函数在/proc/kallsyms
|
|
系统调试文件DebugFS
- 提供内核调试所需的基本信息
- 如内核符号列表、跟踪点、函数跟踪(ftrace)状态以及参数格式等
查询 execve 系统调用的参数格式
|
|
eBPF 程序的执行也依赖于调试文件系统
挂载调试文件
|
|
也可以通过 perf 来查询,不过返回的结果非常非常多
|
|
更好的查找方式: bpftrace
用perf记录
|
|
结果
|
|
生成火焰图
|
|
perf 调用(用户和内核的交互)
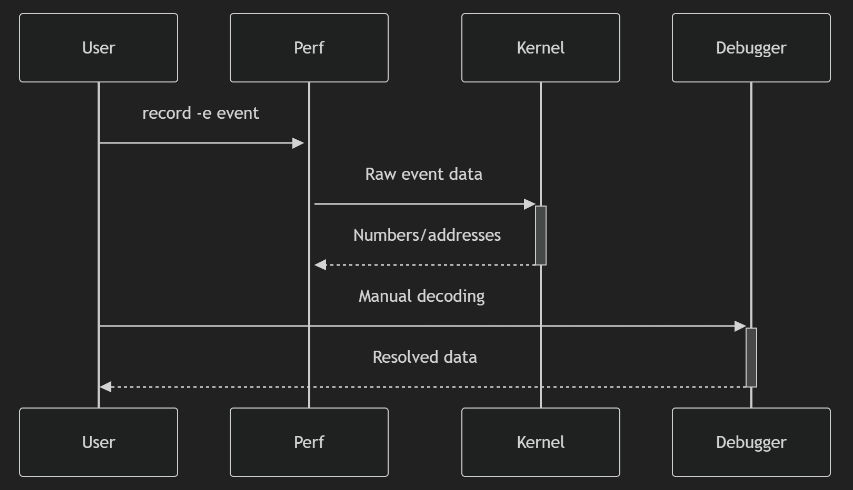
对比 bpf 调用(用户和内核的交互)
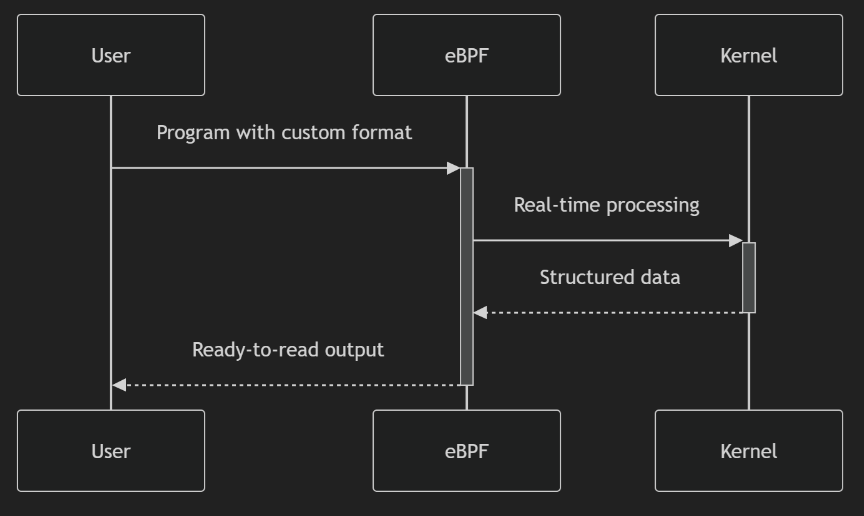
perf 的问题
- 基于 /sys/kernel/debug/tracing/events,不在这个内核暴露的目录中,就无法跟踪了
- 返回的内容是固定格式的,比如 进程名、地址之类的,而 bpf 是自定义的格式
- 用户 <–> 内核有频繁交互,性能比如 BPF
- 像文件系统、网络、调度,perf 就跟踪不了
bpftrace
bpftrace 是构建在 bcc 之上的,简化了很多
工作原理如下:
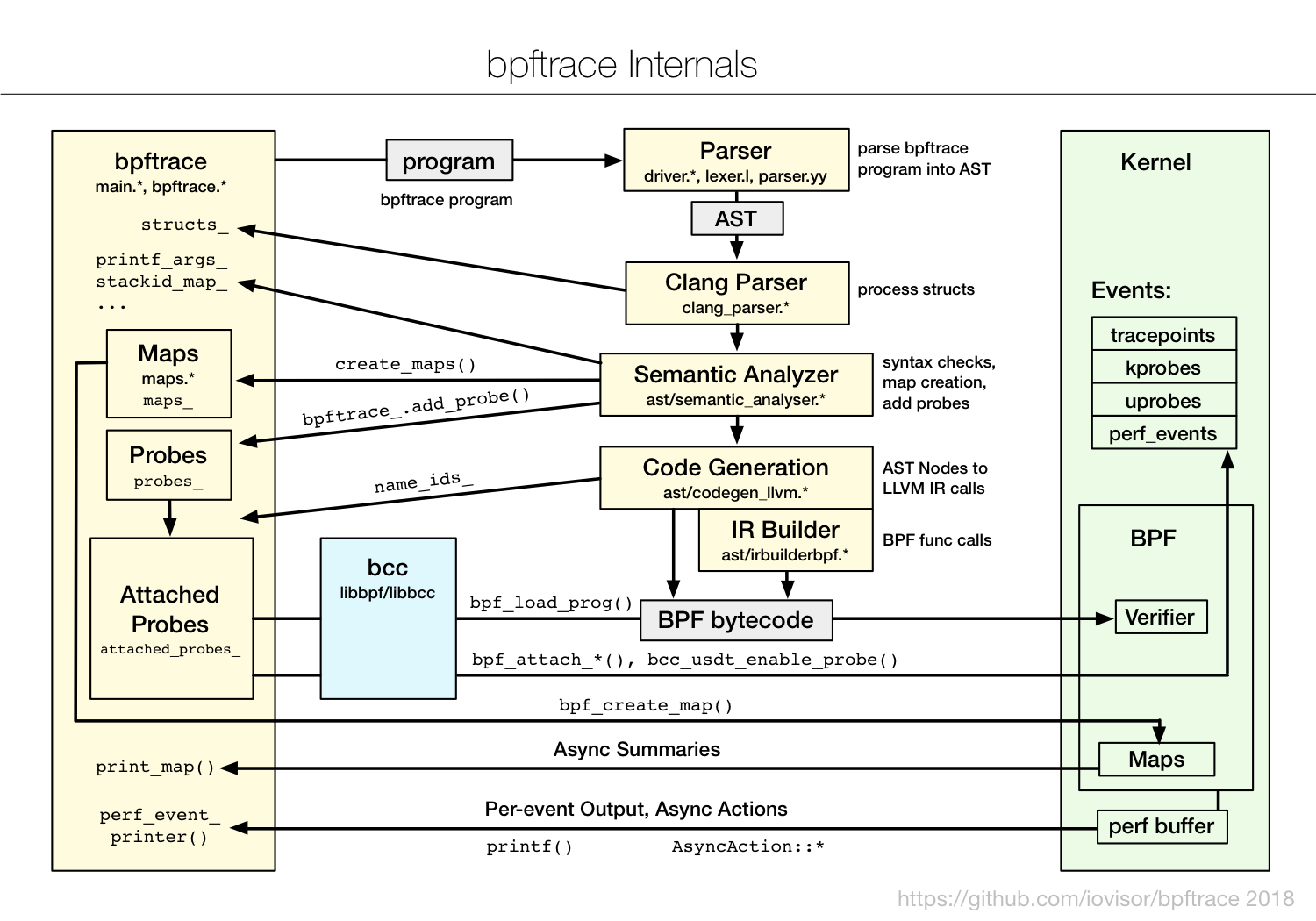
bpftrace Internals
|
|
主要包括
- 内核插桩(kprobe)
- 跟踪点(tracepoint)
kprobe 通过 int3 中断,保存当前的系统调用信息,转而执行用户的函数,可以执行所有内核
跟踪点(tracepoint),open.c 内核函数大致如下
|
|
如果 trace_sys_enter_open 被注册,则会转而执行自定义的函数
如果没有注册,则执行 nop 指令不占用时间
查询 execve 的参数
|
|
| Feature/Category | bpftrace | BCC | libbpf |
|---|---|---|---|
| Primary Use Case | Quick system troubleshooting and diagnostics | Complex eBPF program development | Production deployment and distribution |
| Development Style | Single-line scripts | Full C/Python programs with helpers | Complete BPF application development |
| Execution Pattern | Interactive one-liners | Compiled at runtime on target machine | Compile-once, run-anywhere |
| Complexity Level | Simple programs only | Supports complex implementations | Supports complex implementations |
| Dependencies | Requires BCC and LLVM on target | Requires LLVM and kernel headers on target | No LLVM/kernel headers on target |
| Kernel Requirements | Any kernel (BPF support only) | Any kernel (BPF support) | BTF required (CONFIG_DEBUG_INFO_BTF=y) |
| Deployment | Tool must run on target | Tool+compiler must run on target | Single binary distribution |
| Portability | Manual re-run on different kernels | Recompiles automatically on target | Works across distros (kernels ≥5.8) |
| Example Distros | All Linux with kernel 4.1+ | All Linux with kernel 4.1+ | RHEL 8.2+, Ubuntu 20.10+, Fedora 34+ |
| Strengths | Ad-hoc debugging, rapid prototyping | Comprehensive tracing tools, rich libraries | Production stability, minimal overhead |
| Limitations | Limited program complexity | Heavy runtime dependencies, memory overhead | Requires modern kernel (BTF support) |
| Performance Impact | Medium (runtime compilation) | High (JIT compilation at runtime) | Low (pre-compiled) |
| Main Users | Sysadmins, quick diagnostics | Developers, complex tracing | Production systems, embedded environments |
命令
|
|
bpf 内置的
打印出 AST 和 LLVM 字节码
|
|
bcc
c 代码
|
|
上面 c 代码的调用关系如下:
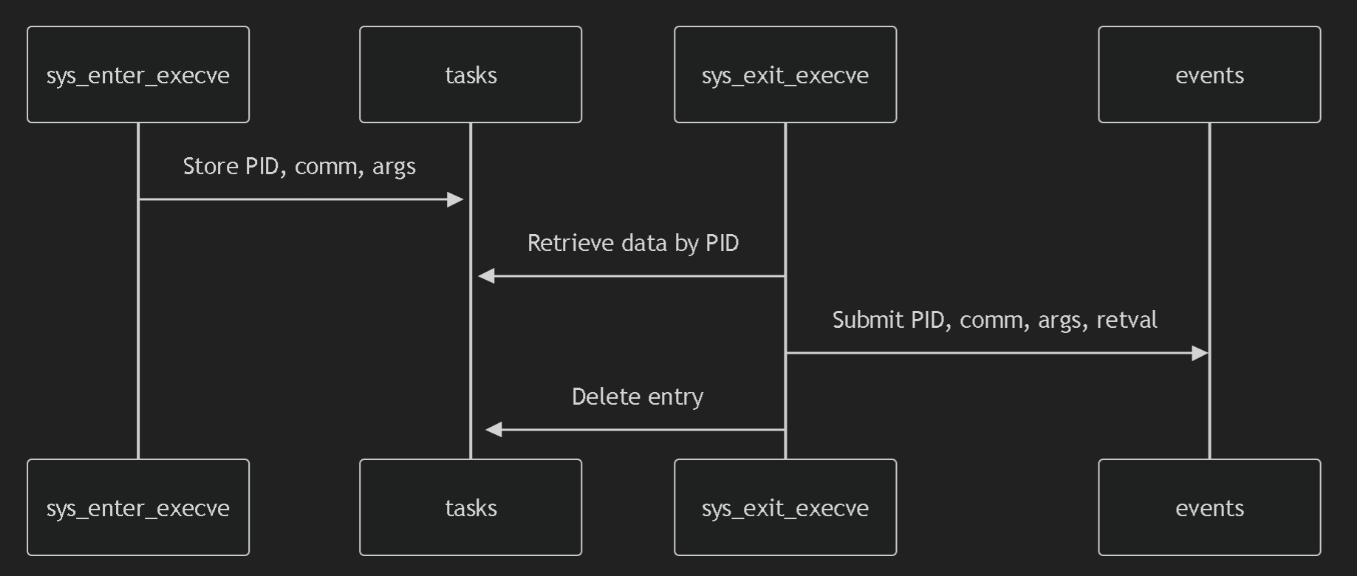
python 代码
|
|
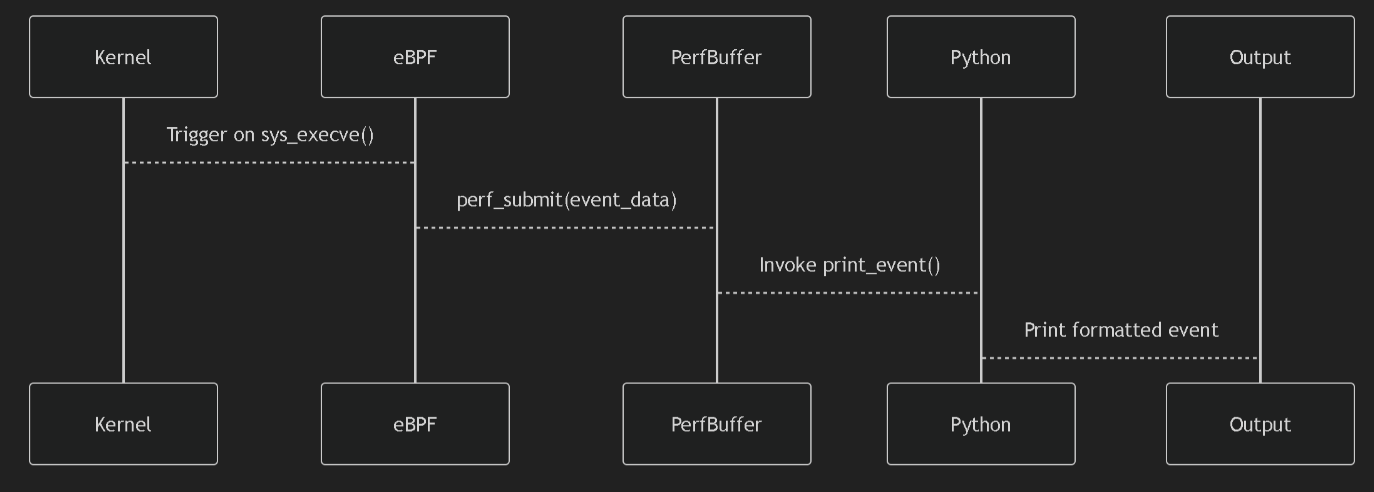
python 代码 和 c 代码交互的过程:
libbpf
使用 libbpf 开发 eBPF 程序就可以通过以下四个步骤完成
- 使用 bpftool 生成内核数据结构定义头文件
- 开发 eBPF 程序部分,也就是内核态的代码,eBPF 程序的源码文件一般命名为 <程序名>.bpf.c
- 编译 eBPF 程序为字节码,再用 bpftool 生成 脚手架头文件(Skeleton Header);这个头文件包含了 eBPF 字节码以及相关的加载、挂载和卸载函数,可在用户态程序中直接调用
- 开发用户态代码,并完整最终编译,生成可执行文件
生成内核头文件
|
|
execsnoop.h 头文件
|
|
execsnoop.bpf.c 代码
|
|
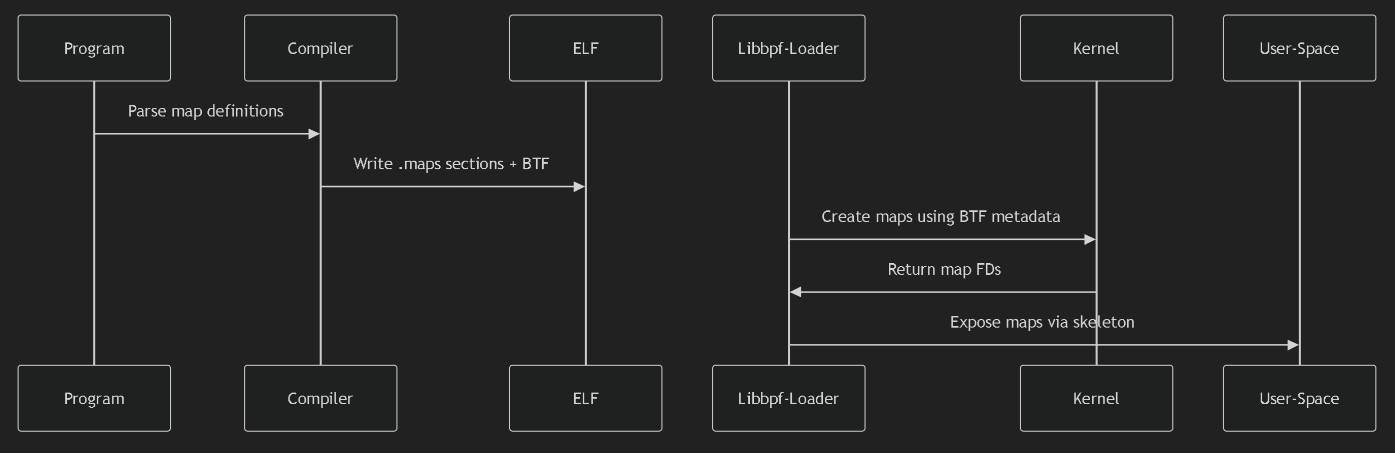
程序,编译器,ELF文件格式,内核的交互过程
编译
|
|
生成 骨架文件
|
|
用户态代码 execsnoop.c
|
|
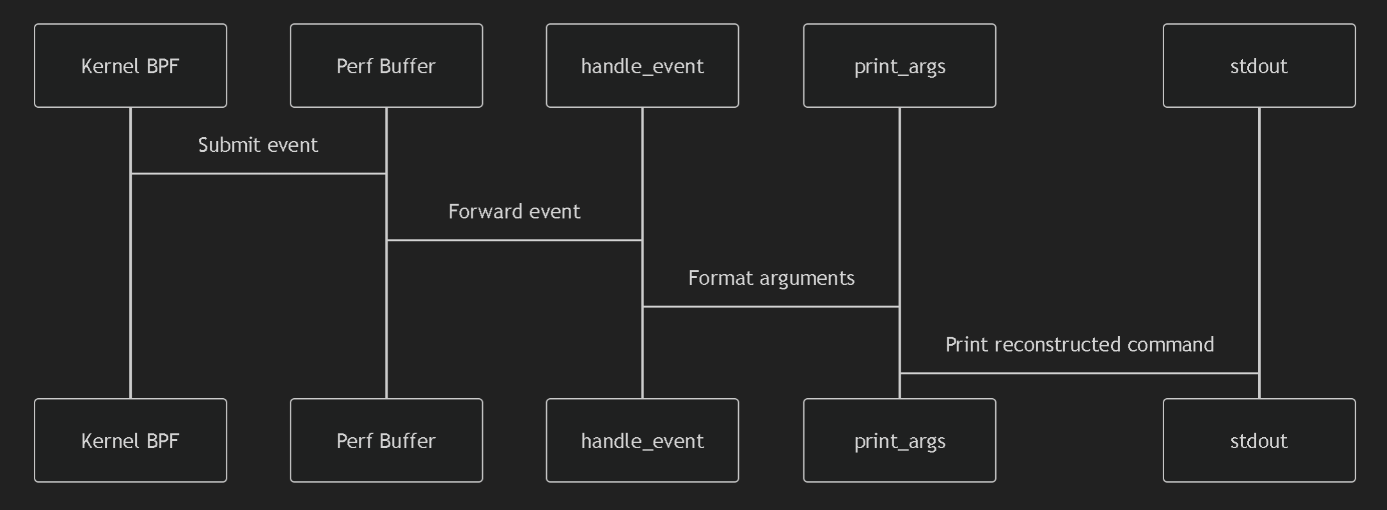
用户态、内核态的交互过程
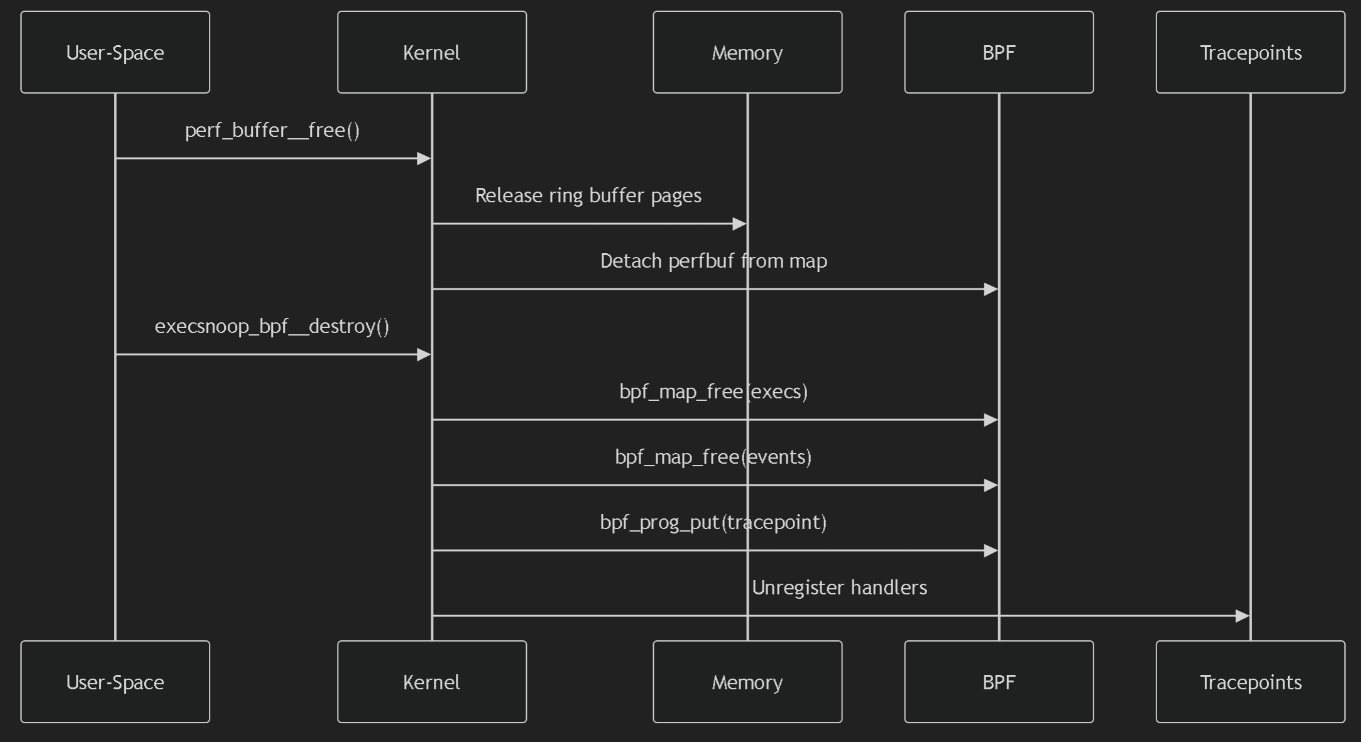
程序释放的过程
编译用户态代码
|
|
生成最终可执行文件
|
|
执行这个二进制程序
|
|