概述
业务负载画像
- 负载是谁产生的(如:进程ID、用户ID、进程名、IP地址)?
- 负载为什么会产生(代码路径、调用栈、火焰图)?
- 负载的组成层是什么(IOPS、吞吐量、负载类型)?
- 负载怎样随着时间发生变化(比较每个周期的摘要信息)?
可以测量的指标:
- 延迟: 多久可以完整一次请求或者操作,毫秒为单位
- 速率: 每秒操作或请求的速率
- 利用率:以百分比形式表示的某资源在一段时间内的繁忙程度
- 成本: 开销/性能的 比例
下钻分析
- 从业务最高层就开始分析
- 检查下一个层级的细节
- 挑出最感兴趣的部分或者线索
- 如果问题还没有解决,跳转至第(2)步
USE 方法
60 秒系统检查清单
- uptime
- dmesg | tail
- vmstat 1
- mpstat -P ALL 1
- pidstat 1
- iostat -xz 1
- free -m
- sar -n DEV 1
- sar -n TCP, ETCP 1
- top
BCC 工具检查清单
- execsnoop
- opensnoop
- ext4slower(或 brtfs*, xfs*, zfs*
- biolatency
- biosnoop
- cachestat
- tcpconnect
- tcpaccept
- tcpretrans
- runqlat
- profile
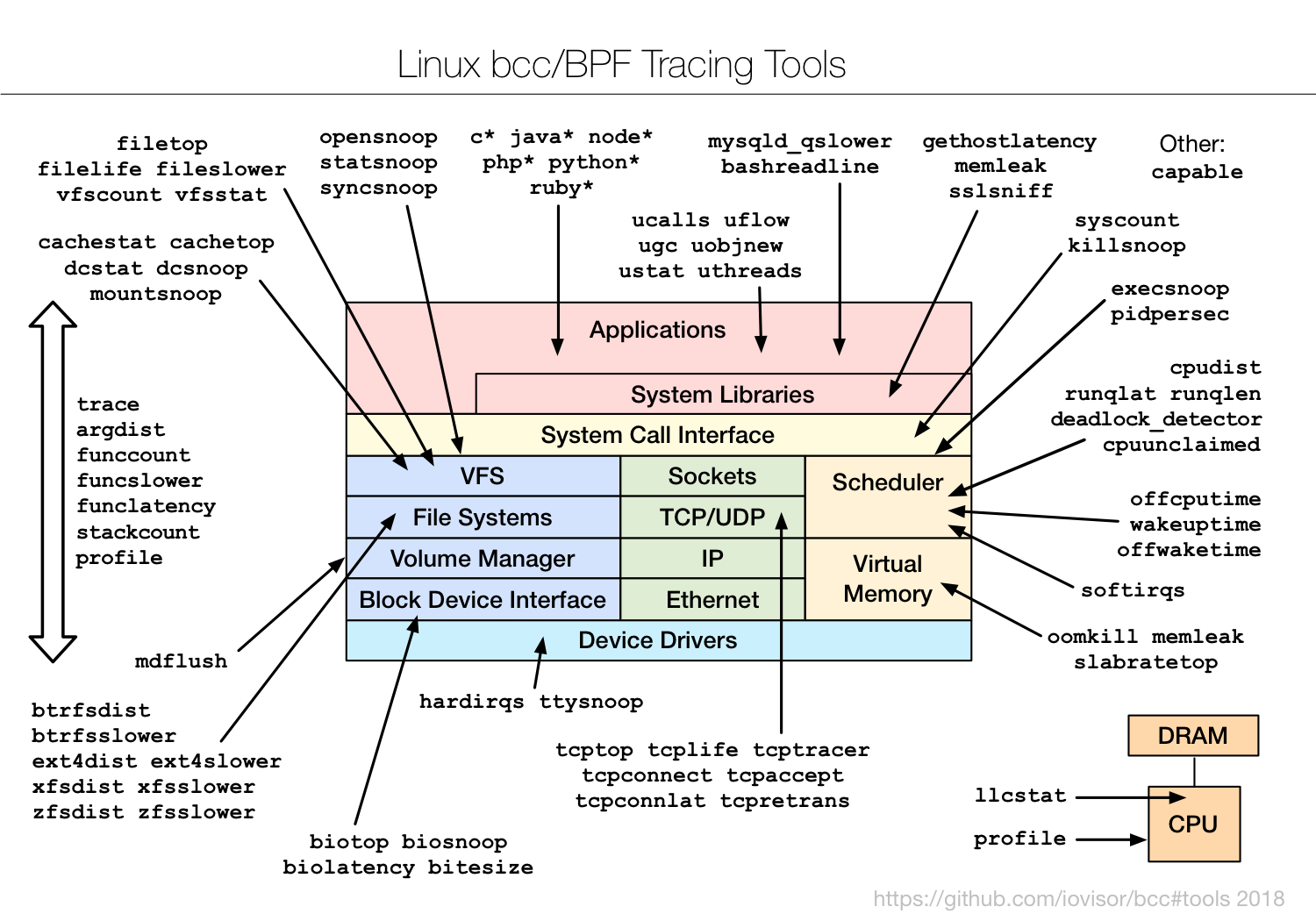
BCC 工具
常用 BCC 工具在内核中的位置
| 工具 |
来源 |
目标 |
描述 |
| funccount |
BCC |
软件 |
对事件进行计数,包括函数调用 |
| stackcount |
BCC |
软件 |
对引发某事件的函数调用栈进行计数 |
| trace |
BCC |
软件 |
定制化打印每个事件的细节信息 |
| argdist |
BCC |
软件 |
对事件的参数分布进行统计 |
funccount 的例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
# 内核函数 tcp_drop() 是否被调用
funccount-bpfcc tcp_drop
# 内核中最频繁的 VFS 是哪个
funccount-bpfcc 'vfs*'
# 用户态函数 pthread_mutext_lock 每秒被调用的次数
funccount-bpfcc -i 1 'c:pthread_mutex_lock'
# 全系统内, libc ku 中调用最频繁的与字符串相关的函数是哪个
funccount-bpfcc 'c:str*'
# 执行最频繁的系统调用是哪个
funccount-bpfcc 't:syscalls:sys_enter_*'
# 对某个进程 统计 VFS 执行次数
funccount-bpfcc -p 46649 'vfs_*'
# 对全局统计 VFS内核进行计数
funccount-bpfcc 'vfs_*'
# 对 TCP 内核进行计数
funccount-bpfcc 'tcp_*'
# 统计每秒 TCP 发送函数的调用次数
funccount-bpfcc -i 1 'tcp_send*'
# 每秒 I/O 事件的数量
funccount-bpfcc -i 1 't:block:*'
# 每秒新创建的进程数量
funccount-bpfcc -i 1 't:sched:sched_process_fork'
# 每秒 libc 中 getaddrinfo() 域名解析 函数的调用次数
funccount-bpfcc -i 1 'c:getaddrinfo'
# 对 libgo 中全部的 os.* 调用进行计数
funccount-bpfcc -i 1 'go:os.*'
|
stackcount 例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# 统计 ktime_get() 调用的代码路径
stackcount-bpfcc ktime_get
# 对创建块 I/O 的函数调用栈进行计数:
stackcount-bpfcc t:block:block_rq_insert
# 对发送 IP 数据包的调用栈进行计数:
stackcount-bpfcc ip_output
# 对发送 IP 数据包的调用栈进行计数,同时显示对应的 PID:
stackcount-bpfcc -P ip_output
# 对导致线程阻塞并且导致脱离 CPU 的调用栈进行计数:
stackcount-bpfcc t:sched:sched_switch
# 对导致系统调用 read () 的调用栈进行计数:
stackcount-bpfcc t:syscalls:sys_enter_read
|
stackcount 生成火焰图
1
2
3
4
5
6
|
stackcount-bpfcc -f -P -D 10 ktime_get > out.stackcount01.txt
git clone https://github.com/brendangregg/FlameGraph.git
cd FlameGraph
./flamegraph.pl --hash --bgcolors=grey < /data/out.stackcount01.txt > \
out.stackcount01.svg
|
trace 例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
# 跟踪 open 系统调用,并打印 打开的 filename
trace-bpfcc 'do_sys_open "%s", arg2'
# 跟踪内核函数 do_sys_open (),并打印文件名:
trace-bpfcc 'do_sys_open "% s", arg2'
# 跟踪内核函数 do_sys_open (),并打印返回值:
trace-bpfcc 'r::do_sys_open "ret: % d", retval'
# 跟踪 do_nanosleep (),并且打印用户态的调用栈:
trace-bpfcc -U 'do_nanosleep "mode: % d", arg2'
# 跟踪通过 pam 库进行身份鉴别的请求:
trace-bpfcc 'pam:pam_start "% s: % s", arg1, arg2'
# 跟踪 udpv6 系统调用,这里需要结构体,所以有一个 -I 'net/sock.h'
# 需要系统有完整的内核源码才能工作,未来会通过 BPF类型格式解决此问题
# 即将结构体信息嵌入到 二进制文件中,这样就不需要结构体的头文件了
trace -I 'net/sock.h' \
'udpv6_sendmsg(struct sock *sk) (sk->sk_dport == 13568)'
# 打印时间戳,并打印内核堆栈、用户态堆栈,跟踪 tcp_send_fin 函数
trace-bpfcc -tKU 'tcp_send_fin'
|
argdist
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
# 打印 kmalloc 分配的柱状图size
argdist-bpfcc -H 'p::__kmalloc(u64 size):u64:size'
# 从 kmalloc 分配中打印每字节纳秒的直方图
argdist-bpfcc -H 'r::__kmalloc(size_t size):u64:$latency/$entry(size)#ns per byte'
# 打印读取 size 满足条件,延迟 > 1秒的
argdist-bpfcc -H 'r::__vfs_read(void *file, void *buf, size_t count):size_t:
$entry(count):$latency > 1000000'
# 打印完整的 block I/O 请求的 sector 数量柱状图
argdist-bpfcc -H 't:block:block_rq_complete():u32:args->nr_sector'
# IRQ 中断请求的统计聚合
argdist-bpfcc -C 't:irq:irq_handler_entry():int:args->irq'
# usdt 用户态静态跟踪,1337 进程 的 pthread_start 频率
argdist-bpfcc -C 'u:pthread:pthread_start():u64:arg2' -p 1337
# 跟踪 1234 进程,打印 libc 的 malloc 调用的频繁(分配的内存 >1024字节)
argdist-bpfcc -p 1234 -C 'p:c:malloc(size_t size):size_t:size:size>1024'
# 这里需要一个结构体,统计 cfs scheduling 队列剩余的运行时间
argdist-bpfcc -I 'kernel/sched/sched.h' \
-C 'p::__account_cfs_rq_runtime(struct cfs_rq *cfs_rq):s64:cfs_rq->runtime_remaining'
# 统计 tcp 零窗口问题,看其返回的窗口大小
argdist-bpfcc -H 'r::__tcp_select_window():int:$retval'
# 对 vfs_read() 返回值统计,用直方图打印
argdist-bpfcc -H 'r::vfs_read()'
根据调用号(syscall ID)对系统调用进行计数,这里使用了 raw_syscalls:sysenter 这个跟踪点:
argdist-bpfcc -C 't:raw_syscalls:sys_enter():int:args->id'
# 对 tcp_sendmsg () 的参数 size 进行统计:
argdist-bpfcc -C 'p::tcp_sendmsg(struct sock *sk, struct msghdr *msg, size_t size):u32:size'
#将 tcp_sendmsg () 的 size 作为以 2 的幂为区间的直方图打印出来:
argdist-bpfcc -H 'p::tcp_sendmsg(struct sock *sk, struct msghdr *msg, size_t size):u32:size'
#将 PID 为 181 的进程按照文件描述符对 write () 调用进行计数:
argdist-bpfcc -p 181 -C 'p:c:write(int fd):int:fd'
# 打印出延迟大于 0.1 毫秒的进程读操
argdist-bpfcc -C 'r::vfs_read():u32:$PID:$latency > 100000'
|
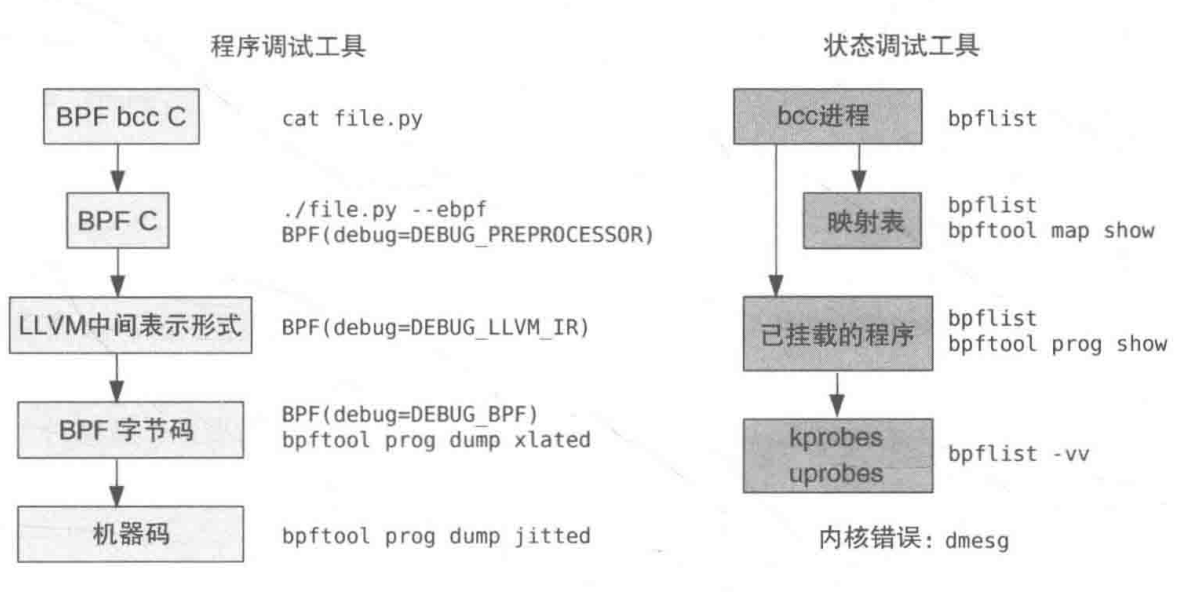
调试
BCC 装载一个 BPF 程序并开始对某个事件进行插桩的步骤如下:
- 创建 Python BPF 对象,将 BPF C 程序传递给该 BPF 对象。
- 使用 BCC 改写器对 BPF C 程序进行预处理,将内存访问替换为 bpf_probe_read () 调用。
- 使用 Clang 将 BPF C 程序编译为 LLVM IR。
- 使用 BCC codegen 根据需要增加额外的 LLVM IR。
- LLVM 将 IR 编译为 BPF 字节码。
- 如果用到了映射表,就创建这些映射表。
- 字节码被传送到内核,并经过 BPF 验证器的检查。
- 事件被启用,BPF 程序被挂载到事件上。
- BCC 程序通过映射表或者 perf_event 缓冲区读取数据。
用bpf_trace_printfk做调试
之后对
1
2
3
4
5
6
|
# 读取调试信息
# 会阻塞更多的消息,当读取后消息会被清除
cat /sys/kernel/debug/tracing/trace_pipe
# 打印头文件,不会阻塞
cat /sys/kernel/debug/tracing/trace
|
ebpf 参数,可以把这个程序的源码打印出来
调试标志位
1
|
b = BPF(tex = bpf_text, debug = 0x2)
|
| 标志位 |
名称 |
调试 |
| 0x1 |
DEBUG_LLVM_IR |
打印编译好的 LLVM 中间表示形式 |
| 0x2 |
DEBUG_BPF |
在分支处打印 BPF 字节码和寄存器状态 |
| 0x4 |
DEBUG_PREPROCESSOR |
打印预处理结果(与 –ebpf 类似) |
| 0x8 |
DEBUG_SOURCE |
打印出源代码中内嵌的汇编指令 |
| 0x10 |
DEBUG_BPF_REGISTER_STATE |
打印所有指令中的寄存器状态 |
| 0x20 |
DEBUG_BTF |
打印出 BTF 调试信息(否则 BTF 错误会被忽略) |
其他
1
2
|
bpflist-bpfcc
bpflist-bpfcc -vv
|
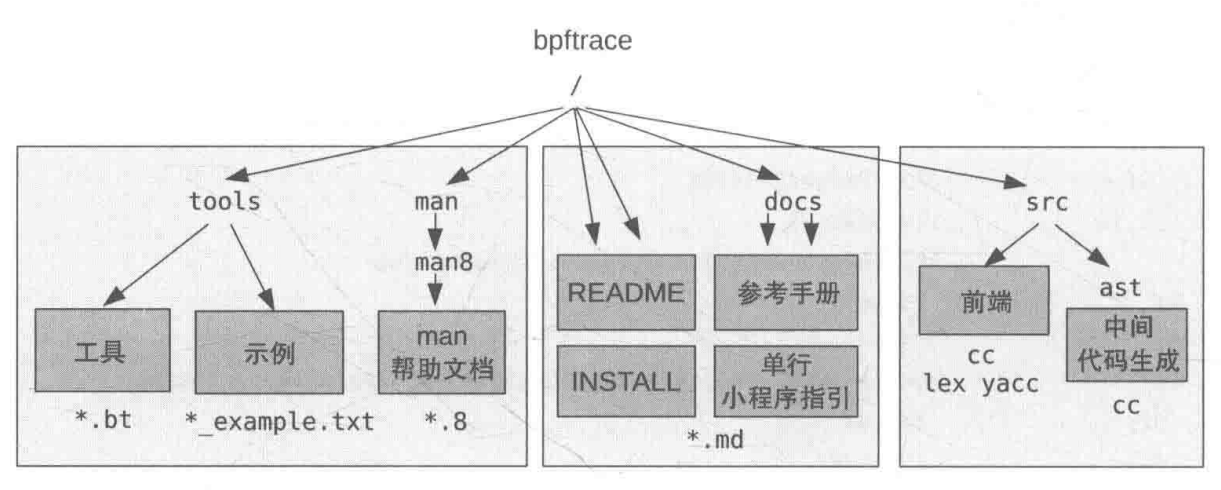
bpftrace
bpftrace 程序结构
- 前端使用了 lex、yacc 做词法、语法分析
- clang 解析 结构体
- 后端将 bpftrace 程序编译成 LLVM 中间表示形式
- 再通过 LLVM 库将其编译为 BPF 代码
bpftrace 内置的工具
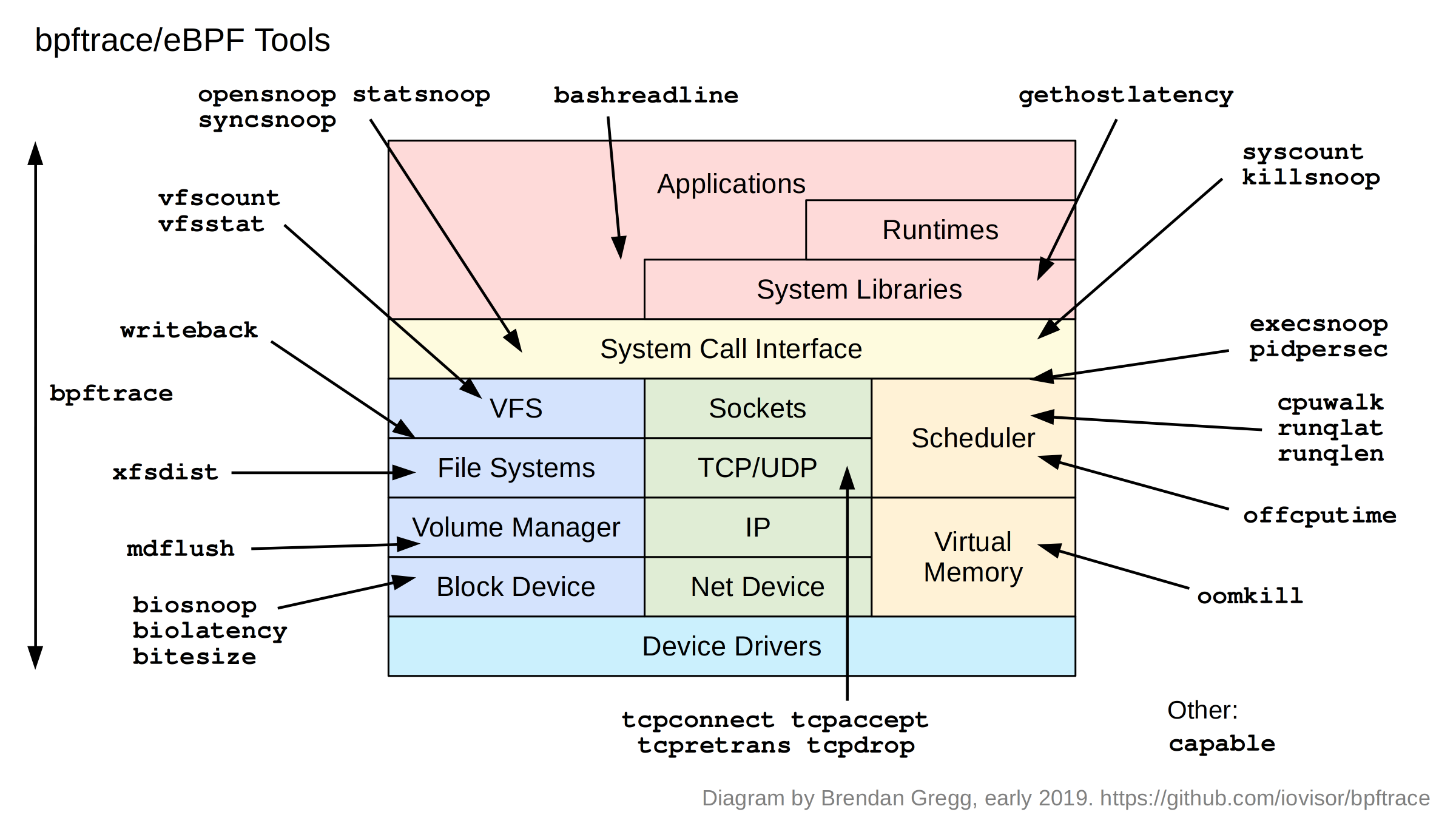
bpf官方手册
| 主题 |
特色工具 |
| CPU 相关 |
execsnoop.bt、runqlat.bt、runqlen.bt、cpuwalk.bt、offcputime.bt |
| 内存相关 |
oomkill.bt、faults.bt、vmscan.bt、swapin.bt |
| 文件系统相关 |
vfsstat.bt、filelife.bt、xfsdist.bt |
| 存储 I/O 相关 |
biosnoop.bt、biolatency.bt、bitesize.bt、biostacks.bt、scsilatency.bt、nvmelatency.bt |
| 网络相关 |
tcpaccept.bt、tcpconnect.bt、tcpdrop.bt、tcpretrans.bt、gethostlatency.bt |
| 安全相关 |
ttysnoop.bt、elfsnoop.bt、setuids.bt |
| 编程语言相关 |
jnistacks.bt、javacalls.bt |
| 应用程序相关 |
threadsnoop.bt、pmheld.bt、naptime.bt、mysqld_qslower.bt |
| 内核相关 |
mlock.bt、mheld.bt、kmem.bt、kpages.bt、workq.bt |
| 容器相关 |
pidnss.bt、blkthrot.bt |
| 虚拟机管理器相关 |
xenhyper.bt、cpustolen.bt、kvmexits.bt |
| 调试器/多用途工具相关 |
execsnoop.bt、threadsnoop.bt、opensnoop.bt、killsnoop.bt、signals.bt |
以直方图行驶统计 vfs_read() 返回值
1
|
bpftrace -e 'kretprobe:vfs_read { @bytes = hist(retval); } '
|
bpftrace 的单行程序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
# 展示系统中谁在执行什么命令:
bpftrace -e 'tracepoint:syscalls:sys_enter_execve { printf("%s -> %s\n", comm, str(args->filename)); }'
# 展示新进程的创建,以及参数信息
bpftrace -e 'tracepoint:syscalls:sys_enter_execve { join(args->argv); }'
# 通过 openat () 查看打开文件动作,按进程统计
bpftrace -e 'tracepoint:syscalls:sys_enter_openat { printf("%s %s\n", comm, str(args->filename)); }'
# 按照不同程序统计系统调用
bpftrace -e 'tracepoint:raw_syscalls:sys_enter { @[comm] = count(); }'
# 按系统调用探针的名字对系统调用进行计数
bpftrace -e 'tracepoint:syscalls:sys_enter_* { @[probe] = count(); }'
# 按进程统计系统调用数量
bpftrace -e 'tracepoint:raw_syscalls:sys_enter { @[pid, comm] = count(); }'
# 按进程展示总的读取字节数
bpftrace -e 'tracepoint:syscalls:sys_exit_read /args->ret/ { @[comm] = sum(args->ret); }'
# 按进程展示 read 返回结果大小的分布
bpftrace -e 'tracepoint:syscalls:sys_exit_read { @[comm] = hist(args->ret); }'
# 展示进程的磁盘 I/O 尺寸
bpftrace -e 'tracepoint:block:block_rq_issue { printf("%d %s %d\n", pid, comm, args->bytes); }'
# 按进程展示页换入的数量
bpftrace -e 'software:major-faults:1 { @[comm] = count(); }'
# 按进程展示缺页中断的数量
bpftrace -e 'software:faults:1 { @[comm] = count(); }'
# 对 PID 为 189 的进程,以 49Hz 的频率抓取其用户态的调用栈信息:
bpftrace -e 'profile:hz:49 /pid == 189/ {@[ustack] = count (); }'
|
bpftrace 的探针格式
1
2
3
4
5
6
|
# 内核需要一个参数
kprobe:vfs_read
# 用户态需要路径和函数名
uprobe:/bin/bash:readline
|
查询可用的探针
1
|
bpftrace -l 'kprobe:vfs_*'
|
查看内核函数参数
1
2
3
4
5
6
7
8
|
bpftrace -lv 'tracepoint:syscalls:sys_enter_clone'
int __syscall_nr
unsigned long clone_flags
unsigned long newsp
int * parent_tidptr
int * child_tidptr
unsigned long tls
|
其他语法
1
2
3
4
5
|
# 条件判断
/pid > 100 & pid < 1000/
# 执行
{ action one; action two; action three }
|
变量
- 内置变量
- 临时变量: $x = 1; $y = “hello”; $z = (struct task_struct *)curtask;
- 映射哈希表,可以在不同 action 之间传递(全局变量) @a = 1;
对内核函数 vfs_read() 进行计时,并用直方图打印
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
#!/usr/bin/bpftrace
// this program times vfs_read()
kprobe:vfs_read
{
@start[tid] = nsecs;
}
kretprobe:vfs_read
/@start[tid]/
{
$duration_us = (nsecs - @start[tid]) / 1000;
@us = hist($duration_us);
delete(@start[tid]);
}
|
一个例子
1
2
3
4
|
# bpftrace -e 'tracepoint:syscalls:sys_enter_clone {
printf("-> clone() by %s PID %d\n", comm, pid); }
tracepoint:syscalls:sys_exit_clone {
printf("<- clone() return %d, %s PID %d\n", args->ret, comm, pid); }'
|
bpftrace 探针类型
| 类型 |
缩写 |
描述 |
| tracepoint |
t |
内核静态插桩点 |
| usdt |
U |
用户态静态定义插桩点 |
| kprobe |
k |
内核动态函数插桩 |
| kretprobe |
kr |
内核动态函数返回值插桩 |
| uprobe |
u |
用户态动态函数插桩 |
| uretprobe |
ur |
用户态动态函数返回值插桩 |
| software |
s |
内核软件事件 |
| hardware |
h |
硬件基于计数器的插桩 |
| profile |
p |
对全部 CPU 进行时间采样 |
| interval |
i |
周期性报告(从一个 CPU 上) |
| BEGIN |
|
bpftrace 启动 |
| END |
|
bpftrace 退出 |
硬件探针,预先定义好的硬件事件
1
2
3
4
5
6
7
8
9
10
11
|
bpftrace -l 'hardware:*:*'
hardware:backend-stalls:
hardware:branch-instructions:
hardware:branch-misses:
hardware:bus-cycles:
hardware:cache-misses:
hardware:cache-references:
hardware:cpu-cycles:
hardware:frontend-stalls:
hardware:instructions:
hardware:ref-cycles:
|
| 硬件事件名称 |
缩写 |
默认采样间隔 |
描述 |
| cpu-cycles |
cycles |
1000000 |
CPU 运行时钟周期 |
| instructions |
|
1000000 |
CPU 运行指令数 |
| cache-references |
|
1000000 |
CPU 末级缓存引用 |
| cache-misses |
|
1000000 |
CPU 末级缓存未命中 |
| branch-instructions |
branches |
100000 |
跳转指令 |
| bus-cycles |
|
100000 |
总线周期 |
| frontend-stalls |
|
1000000 |
处理器前端阻塞(例如,取指令) |
| backend-stalls |
|
1000000 |
处理器后端阻塞(例如,数据加载/存储) |
| ref-cycles |
|
1000000 |
CPU 参考时钟周期(未使用 turbo) |
软件探针,预先定义好的软件事件
1
2
3
4
5
6
7
8
9
10
11
12
|
bpftrace -l 'software:*:*'
software:alignment-faults:
software:bpf-output:
software:context-switches:
software:cpu-clock:
software:cpu-migrations:
software:dummy:
software:emulation-faults:
software:major-faults:
software:minor-faults:
software:page-faults:
software:task-clock:
|
| 软件事件名称 |
缩写 |
默认采样间隔 |
描述 |
| cpu-clock |
cpu |
1000000 |
CPU 真实时间 |
| task-clock |
|
1000000 |
CPU 任务时间(只在任务运行在 CPU 上时增长) |
| page-faults |
faults |
100 |
缺页中断 |
| context-switches |
cs |
1000 |
上下文切换 |
| cpu-migrations |
|
1 |
CPU 线程迁移 |
| minor-faults |
|
100 |
次要缺页中断:由内存满足 |
| major-faults |
|
1 |
主要缺页中断:由存储 I/O 满足 |
| alignment-faults |
|
1 |
对齐中断 |
| emulation-faults |
|
1 |
当指令模拟执行时触发中断 |
| dummy |
|
1 |
用于测试的假事件 |
| bpf-output |
|
1 |
BPF 输出通道 |
其他探针
- profile,会在全部 cpu 上激活
- interval,会在单个 cpu 上激活
bpftrace 内置的变量
官方文档
内置变量
内置函数
内置的map 函数
更多的例子
1
2
3
4
5
6
7
8
|
bpftrace -e 't:syscalls:sys_enter_setuid { printf("setuid by PID %d (%s), UID %d\n", pid, comm, uid); }'
bpftrace -e 'tracepoint:syscalls:sys_exit_setuid { printf("setuid by %s returned %d\n", comm, args->ret); }'
bpftrace -e 't:block:block_rq_insert { printf("Block I/O by %s\n", kstack); }'
bpftrace -e 't:block:block_rq_insert { @[kstack] = count(); }'
|
映射表变量
1
2
3
4
5
6
7
|
@start = nsecs; // 整数类型
@last[tid] = nsecs;
@bytes = hist(retval);
@who[pid, comm] = count(); // 包含两个键
|
函数
1
2
3
|
bpftrace -e 'tracepoint:syscalls:sys_enter_execve {join(args->argv); }'
bpftrace -e 'ur:/bin/bash:readline {printf("%s\n", str(retval)); }'
|
打印 堆栈信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
bpftrace -e 't:block:block_rq_insert {@[kstack(3), comm] = count(); }'
# 结果
@[
blk_mq_insert_requests+115
blk_mq_insert_requests+115
blk_mq_sched_insert_requests+187
, kworker/u64:5]: 20
@[
blk_mq_insert_requests+115
blk_mq_insert_requests+115
blk_mq_sched_insert_requests+187
, kworker/u64:1]: 84
@[
blk_mq_insert_requests+115
blk_mq_insert_requests+115
blk_mq_sched_insert_requests+187
, kworker/u64:4]: 144
bpftrace -e 'k:do_nanosleep {printf("%s", ustack(perf)); }'
# 结果
503f4bd runtime.usleep.abi0+61 (/usr/share/grafana/bin/grafana)
50145c5 runtime.sysmon+165 (/usr/share/grafana/bin/grafana)
500bd33 runtime.mstart1+147 (/usr/share/grafana/bin/grafana)
500bc7a runtime.mstart0+122 (/usr/share/grafana/bin/grafana)
503b8e5 runtime.mstart.abi0+5 (/usr/share/grafana/bin/grafana)
990ac68 start+114 (/usr/share/grafana/bin/grafana)
|
将地址解析为对应的函数名
1
2
3
4
5
6
7
8
|
bpftrace -e 'tracepoint:timer:hrtimer_start {@[ksym(args->function)] = count();}'
@[it_real_fn]: 2
@[sched_rt_period_timer]: 5
@[timerfd_tmrproc]: 5
@[watchdog_timer_fn]: 96
@[hrtimer_wakeup]: 4524
@[tick_sched_timer]: 10603
|
映射表函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
# 对出现次数计数
bpftrace -e 'tracepoint:block:* { @[probe] = count(); }'
@[tracepoint:block:block_bio_frontmerge]: 2
@[tracepoint:block:block_rq_insert]: 15
@[tracepoint:block:block_plug]: 30
@[tracepoint:block:block_unplug]: 34
@[tracepoint:block:block_getrq]: 148
@[tracepoint:block:block_rq_issue]: 163
@[tracepoint:block:block_bio_backmerge]: 169
@[tracepoint:block:block_rq_complete]: 185
@[tracepoint:block:block_dirty_buffer]: 249
@[tracepoint:block:block_bio_complete]: 309
@[tracepoint:block:block_touch_buffer]: 463
@[tracepoint:block:block_bio_remap]: 624
@[tracepoint:block:block_bio_queue]: 628
# 聚合函数
# sum()、avg()、min()、max()
bpftrace -e 'tracepoint:syscalls:sys_exit_read /args->ret > 0/ { @bytes = sum(args->ret); }'
# 打印柱状图(二次幂为区间)
bpftrace -e 'tracepoint:syscalls:sys_exit_read { @ret = hist(args->ret); }'
# 打印线性直方图
bpftrace -e 'tracepoint:syscalls:sys_exit_read { @ret = lhist(args->ret, 0, 1000, 100); }'
|
一个综合性的例子
1
2
3
4
|
bpftrace -e 'kprobe:vfs_read { @start[tid] = nsecs; }
kretprobe:vfs_read /@start[tid]/ {
@ms[comm] = sum(nsecs - @start[tid]); delete(@start[tid]); }
END { print(@ms, 0, 1000000); clear(@ms); clear(@start); }'
|
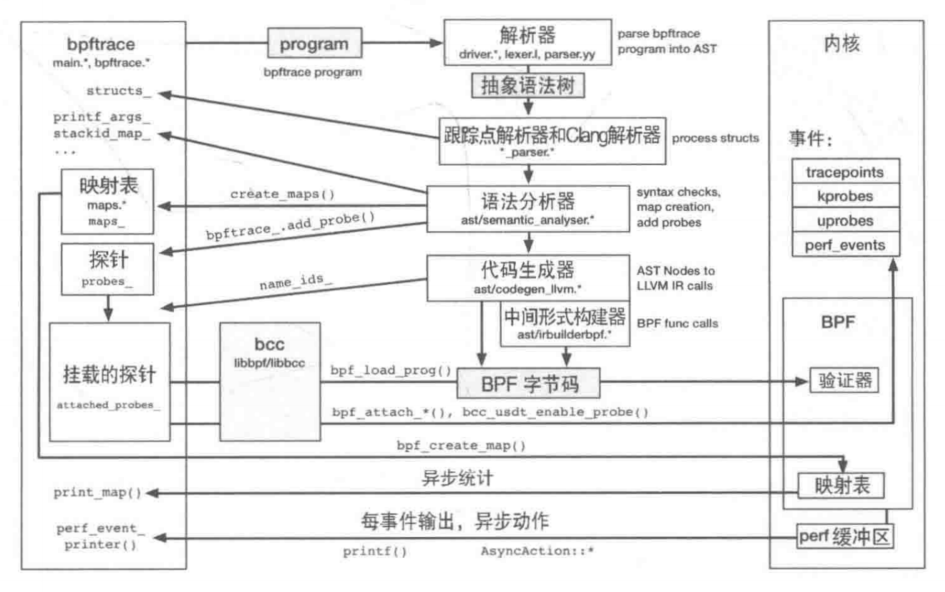
执行原理
- bpftrace 使用 libbcc 和 libbpf 完成对探针的插桩、程序的加载,以及使用 USDT。它也使用 LLVM 将程序编译为 BPF 字节码。
- bpftrace 语言是使用 lex 和 yacc 文件定义的,会分别经过 flex 和 bison 程序处理
- 输出是一个作为抽象语法树存在的程序。跟踪点解析器和 Clang 解析器会对这个结构进行语法分析
- 一个语法分析器会检查语言元素的使用,在出错时会抛出错误
- 下一步是代码生成 —— 将 AST 节点转为 LLVM IR,最后再由 LLVM 编译为 BPF 字节码。
编程语言
使用 BPF 对一种语言进行跟踪所需要的能力,包括可回答以下问题:
- 什么函数被调用?
- 函数的参数是什么?
- 函数的返回值是什么?有错误吗?
- 引发了某个事件的什么代码路径(调用栈)?
- 函数运行的时长是多久?可以用直方图表示吗?
C相关工具
| 工具 |
来源 |
目标 |
描述 |
| funccount |
BCC |
函数 |
对函数调用计数 |
| stackcount |
BCC |
调用栈 |
对导致某个事件发生的本地调用栈进行计数 |
| trace |
BCC |
函数 |
打印详细的函数调用和返回值 |
| argdist |
BCC |
函数 |
摘要统计函数参数和返回值 |
| bpftrace |
BT |
All |
自定义函数和调用栈插桩 |
bpftrace
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
# 对以 “attach” 开头的内核函数调用进行计数:
bpftrace -e 'kprobe:attach* { @[probe] = count(); }'
# 对某个二进制(如 /bin/bash)文件中以 a 开头的函数调用计数:
bpftrace -e 'uprobe:/bin/bash:a* { @[probe] = count(); }'
# 对某个库(如 libc.6.so)文件中以 a 开头的函数调用计数:
bpftrace -e 'u:/lib/x86_64-linux-gnu/libc.so.6:a* { @[probe] = count(); }'
# 跟踪某个函数和它的参数(比如,bash 的 readline ()):
bpftrace -e 'u:/bin/bash:readline { printf("prompt: %s\n", str(arg0)); }'
# 跟踪某个函数和它的返回值(比如,bash 的 readline ()):
bpftrace -e 'ur:/bin/bash:readline { printf("read: %s\n", str(retval)); }'
# 跟踪某个库函数和它的参数(比如,libc 的 fopen ()):
bpftrace -e 'u:/lib/x86_64-linux-gnu/libc.so.6:fopen { printf("opening: %s\n",str(arg0)); }'
# 对某个库函数的返回值进行统计(比如,libc 的 fopen ()):
bpftrace -e 'ur:/lib/x86_64-linux-gnu/libc.so.6:fopen { @[retval] = count(); }'
# 对某个用户态函数调用栈进行计数(比如,bash 的 readline ()):
bpftrace -e 'u:/bin/bash:readline { @[ustack] = count(); }'
# 以 49Hz 的频率对用户态调用栈进行采样:
bpftrace -e 'profile:hz:49 { @[ustack] = count(); }'
|
Java相关工具
| 工具 |
来源 |
跟踪目标 |
描述 |
| jnistacks |
本书 |
libjvm |
使用对象调用栈来展示JNI消费者 |
| profile |
BCC |
CPU |
基于时间的调用栈采样,包括Java方法 |
| offcputime |
BCC |
Sched |
未在CPU上运行的栈采样,包括Java方法 |
| stackcount |
BCC |
Event |
对任何事件获取其调用栈 |
| javastat |
BCC |
USDT |
高级语言操作统计 |
| javathreads |
本书 |
USDT |
跟踪线程的开始和结束事件 |
| javacalls |
BCC/本书 |
USDT |
对Java方法调用进行计数 |
| javaflow |
BCC |
USDT |
展示Java方法的代码流 |
| javagc |
BCC |
USDT |
跟踪Java的垃圾回收 |
| javaobjnew |
BCC |
USDT |
对Java新对象的分配进行计数 |
Java 的 USDT 探针
- 虚拟机生命周期
- 线程生命周期
- 类加载
- 垃圾回收
- 方法编译
- 监控器
- 应用跟踪
- 方法调用
- 对象分配
- 监控器事件
上述探针只在 JDK 使用了 –enable-dtrace 编译选项后才能使用
应用程序
应用程序相关的工具
| 工具 |
来源 |
目标 |
工具介绍 |
| execsnoop |
BCC/BT |
调度器 |
列出新创建的进程 |
| threadsnoop |
本书 |
pthread |
列出新创建的线程 |
| profile |
BCC |
CPU |
on-CPU 调用栈采样 |
| threaded |
本书 |
CPU |
on-CPU 线程采样 |
| offcputime |
BCC |
Sched |
展示带调用栈的 off-CPU 执行时间 |
| offcpuist |
本书 |
Sched |
展示带时间直方图的 off-CPU 调用栈 |
| syscount |
BCC |
系统调用 |
按类型计数的系统调用 |
| ioprofile |
本书 |
I/O |
I/O 调用栈计数 |
| mysqld_qslower |
BCC/本书 |
MySQL服务器 |
展示慢于阈值的 MySQL 查询 |
| mysqld_clat |
本书 |
MySQL服务器 |
以直方图的形式展示 MySQL 命令延迟 |
| signals |
本书 |
信号 |
汇总目标进程发出的信号 |
| killsnoop |
BCC/BT |
系统调用 |
展示带发送进程信息的 kill(2) 系统调用 |
| pmlock |
本书 |
锁 |
展示 pthread 互斥锁次数和用户调用栈 |
| pmheld |
本书 |
锁 |
展示 pthread 互斥锁被持有次数和用户调用栈 |
| naptime |
本书 |
系统调用 |
展示被动睡眠调用 |
bpftrace
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
# 带参数的新创建进程:
bpftrace -e 'tracepoint:syscalls:sys_enter_execve { join(args->argv); }'
# 按进程对系统调用计数:
bpftrace -e 'tracepoint:raw_syscalls:sys_enter { @[pid, comm] = count(); }'
# 按系统调用名称对系统调用计数:
bpftrace -e 'tracepoint:syscalls:sys_enter_* { @[probe] = count(); }'
# 对 PID 为 189 的进程,以 49Hz 进行用户态调用栈采样:
bpftrace -e 'profile:hz:49 /pid == 189/ { @[ustack] = count(); }'
# 对 mysqld 进程,以 49Hz 进行用户态调用栈采样:
bpftrace -e 'profile:hz:49 /comm == "mysqld"/ { @[ustack] = count(); }'
# 对 off-CPU 用户态调用栈计数:
bpftrace -e 'tracepoint:sched:sched_switch { @[ustack] = count(); }'
# 对所有调用栈和进程名采样:
bpftrace -e 'profile:hz:49 { @[ustack, stack, comm] = count(); }'
# 按用户态调用栈计算 malloc () 请求的字节总数(高开销):
bpftrace -e 'u:/lib/x86_64-linux-gnu/libc-2.27.so:malloc { @[ustack(5)] = sum(arg0); }'
# 跟踪 kill () 信号,显示发送进程名称、目标 PID 和信号号码:
bpftrace -e 't:syscalls:sys_enter_kill { printf("%s -> PID %d SIG %d\n", comm, args->pid, args->sig); }'
# 对 libpthread 互斥锁方法计数 1 秒:
bpftrace -e 'u:/lib/x86_64-linux-gnu/libpthread.so.0:pthread_mutex_*lock { @[probe] = count(); } interval:s:1 { exit(); }'
# 对 libpthread 条件变量相关函数计数 1 秒:
bpftrace -e 'u:/lib/x86_64-linux-gnu/libpthread.so.0:pthread_cond_* { @[probe] = count(); } interval:s:1 { exit(); }'
# 按进程对 LLC 缓存未命中计数:
bpftrace -e 'hardware:cache-misses: { @[comm] = count(); }'
|
内核
BPF 跟踪工具可以提供内核指标外的其他信息,包括回答以下问题:
- 线程为什么离开 CPU,以及它们离开 CPU 多久了?
- off-CPU 的线程在等待什么事件?
- 谁正在使用内核的 slab 分配器?
- 内核是否正在移动页面来平衡 NUMA?
- 正在发生什么工作队列事件?延迟是多少?
- 对于内核开发者:哪些函数被调用了?传入和返回的参数是什么?延迟是多少?
内核事件类型和插桩源
| 事件类型 |
事件源 |
| 内核函数执行 |
kprobes |
| 调度器事件 |
sched 跟踪点 |
| 系统调用 |
syscalls 跟踪点和 raw_syscalls 跟踪点 |
| 内核内存分配 |
kmem 跟踪点 |
| 页面换出守护进程扫描 |
vmscan 跟踪点 |
| 中断 |
irq 跟踪点和 irq_vectors 跟踪点 |
| 工作队列执行 |
workqueue 跟踪点 |
| 计时器 |
timer 跟踪点 |
| IRQ 和抢占禁用 |
preemptirq 跟踪点1 |
内核相关工具
| 工具 |
来源 |
目标 |
描述 |
| loads |
BT |
CPU |
显示平均负载 |
| offcputime |
BCC/本书 |
调度器 |
总结off-CPU调用栈和时间 |
| wakeuptime |
BCC |
调度器 |
总结唤醒调用栈和阻塞时间 |
| offwaketime |
BCC |
调度器 |
总结带off-CPU调用栈的唤醒 |
| mlock |
本书 |
互斥锁 |
显示互斥锁时间和内核堆栈 |
| mheld |
本书 |
互斥锁 |
显示互斥保持时间和内核堆栈 |
| kmem |
本书 |
内存 |
总结内核内存分配 |
| kpages |
本书 |
内存页面 |
总结内核内存页面分配 |
| memleak |
本书 |
内存 |
显示可能的内存泄漏代码路径 |
| slabratetop |
BCC/本书 |
slab |
按缓存显示内核slab分配率 |
| numamove |
本书 |
NUMA |
显示NUMA页面迁移统计信息 |
| workq |
本书 |
工作队列 |
显示工作队列函数的执行时间 |
bpftrace
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
# 按进程对系统调用进行计数:
bpftrace -e 'tracepoint:raw_syscalls:sys_enter { @[pid, comm] = count(); }'
# 按系统调用探针名称对系统调用进行计数:
bpftrace -e 'tracepoint:syscalls:sys_enter_* { @[probe] = count(); }'
#按系统调用函数对系统调用进行计数:
bpftrace -e 'tracepoint:raw_syscalls:sys_enter {
@[ksym(*(kaddr("sys_call_table") + args->id * 8))] = count(); }'
# 对以 “attach” 开始的内核函数调用进行计数:
bpftrace -e 'kprobe:attach* { @[probe] = count(); }'
# 为内核函数 vfs_read () 计时并将其总结为直方图:
bpftrace -e 'k:vfs_read { @ts[tid] = nsecs; } kr:vfs_read /@ts[tid]/ {
@ = hist(nsecs - @ts[tid]); delete(@ts[tid]); }'
# 对内核函数 “func1” 的第一个整数参数出现的频率进行计数:
bpftrace -e 'kprobe:func1 { @[arg0] = count(); }'
# 对内核函数 “func1” 的返回值出现的频率进行计数:
bpftrace -e 'kretprobe:func1 { @[retval] = count(); }'
# 以 99Hz 对内核态调用栈采样,不包含 idle:
bpftrace -e 'profile:hz:99 /pid/ { @[kstack] = count(); }'
# 以 99Hz 对 on-CPU 内核函数采样:
bpftrace -e 'profile:hz:99 { @[kstack(1)] = count(); }'
# 对上下文切换调用栈计数:
bpftrace -e 't:sched:sched_switch { @[kstack, ustack, comm] = count(); }'
# 按内核函数对工作队列请求进行计数:
bpftrace -e 't:workqueue:workqueue_execute_start { @[ksym(args->function)] = count() }'
# 对内核函数开始的 hrtimer 进行计数:
bpftrace -e 't:timer:hrtimer_start { @[ksym(args->function)] = count(); }'
|
容器
主要有两种实现容器的方法。
- 操作系统级别的虚拟化:在 Linux 中这涉及使用命名空间(namespace)对系统进行分区,通常与 cgroup 结合使用进行资源控制。所有容器共享同一个运行着的内核。这是 Docker、Kubernetes 以及其他容器环境所使用的方法。
- 硬件级别的虚拟化:这涉及运行轻量级虚拟机,每个虚拟机都有自己的内核。Intel 的 Clear Containers(即现在的 Kata Containers[165])和 AWS 的 Firecracker[166]使用这种方式。
容器专用工具
| 工具 |
来源 |
目标 |
工具描述 |
| runqlat |
BCC |
Sched |
按 PID 命名空间总结 CPU 运行队列延迟 |
| pidnss |
本书 |
Sched |
对 PID 命名空间切换进行计数:容器共享一个 CPU |
| blkthrot |
本书 |
块I/O |
对被 blk cgroup 限制的块I/O进行计数 |
| overlayfs |
本书 |
Overlay文件系统 |
显示Overlay文件系统的读写延迟 |
bpftrace
1
2
3
4
5
6
7
|
# 以 99Hz 的频率对 cgroup ID 进行计数:
bpftrace -e 'profile:hz:99 { @[cgroup] = count(); }'
# 跟踪名为 “container1” 的容器(cgroup v2)中打开的文件名:
bpftrace -e 't:syscalls:sys_enter_openat
/cgroup == cgroupid("/sys/fs/cgroup/unified/container1")/ {
printf("%s\n", str(args->filename)); }'
|
虚拟机
类型
- 配置 A:此配置被称为本机管理器或裸机管理器。虚拟机管理器直接运行在处理器上,它负责创建为运行访客虚拟机的域并将虚拟的访客系统 CPU 调度到真实 CPU 上,这种配置的一个流行的例子是 Xen 虚拟机管理器。
- 配置 B: 虚拟机管理器由宿主机内核运行,可能由内核态模块和用户态进程组成。宿主机操作系统有管理虚拟机管理器的特权,其内核负责将虚拟机 CPU 以及宿主机上的其他进程一同调度。这种配置的一个流行的例子是 KVM 虚拟机管理器。
改进
- 处理器虚拟化支持:在2005—2006年引入的AMD-V和Intel VT-x处理器扩展为虚拟机操作提供了更快的硬件支持。
- 半虚拟化(paravirt或PV):通过半虚拟化运行一个修改过的操作系统,可以使操作系统知道它正在硬件虚拟机上运行,并对虚拟机管理器发起超级调用,以更高效地处理某些操作。为了提高效率,Xen将这些超级调用批处理为一个多重调用。
- 硬件设备支持:为了进一步优化虚拟机性能,处理器之外的硬件设备已经添加了虚拟机支持。这包括用于网络和存储设备的SR-IOV,以及使用它们的特殊驱动程序:ixgbe、ena和nvme。
监控
GUI 和工具包括如下一些。
- Vector 和 Performance Co-Pilot(PCP):用于远程 BPF 监控
- Grafana 配合 PCP:用于远程 BPF 监控
- eBPF Exporter:用于 BPF 同 Prometheus 和 Grafana 的集成
- kubectl-trace:用于跟踪 Kubernetes 的 pods 和 nodes
参考