Spark和Flink的对比总结(包含Operator)
Saprk
Spark处理流的问题
这个是比较明显的
- MicroBatchExecution,实现精确一次,100ms 延迟
- ContinuousExecution,没有精确保障,1ms 延迟
本质上,还是通过:
- micro batch 来模拟的
- 时效性会略差一些
IncrementalExecution
- 继承自 QueryExecution,重用了spark的整个逻辑,包括分析,优化,执行逻辑计划等等
- 他内部维护了两个批之间的状态,用来实现增量的查询
参考
Spark Operator
Spark 任务提交方式
Spark Thrift
Spark Thrift Server/JDBC Server
Purpose:
- Provides JDBC/ODBC interface for SQL queries
Usage:
|
|
Clients:
- Beeline, JDBC applications, BI tools (Tableau, Power BI)
spark-submit (Primary CLI)
例子
|
|
Spark Operator (Kubernetes Native)
例子
|
|
Apply with:
- kubectl apply -f spark-application.yaml
Apache Livy (REST Interface)
例子
|
|
Programmatic Submission
例子
|
|
Spark-sql CLI
例子
|
|
Another
Workflow Orchestrators
- Apache Airflow with Spark operators
- AWS Step Functions with EMR steps
- Azure Data Factory Spark activities
- Google Cloud Composer
Notebook Environments
- Jupyter Notebooks with Spark kernels
- Zeppelin Notebooks with native Spark integration - Databricks Notebooks (commercial) - AWS EMR Notebooks
Apache Livy 过时的问题
1、Performance Overhead
|
|
- Additional network hops increase latency
- HTTP serialization/deserialization overhead
- Session management complexity
2、Resource Inefficiency
- Maintains persistent Spark contexts even when idle
- Less granular resource control compared to K8s operators
- Scaling challenges in containerized environments
3、Ecosystem Evolution
- Kubernetes operators provide more native cloud integration
- Serverless offerings (AWS Glue, Databricks SQL) reduced need for self-managed Livy
- Improved JDBC/ODBC drivers made Thrift Server more accessible
4、Operational Complexity
- Separate component to maintain and monitor
- Security challenges (additional authentication layer)
- Less integration with modern infrastructure tools
Flink
Flink处理批的问题
假设有一条SQL
|
|
执行过程
- spark 的 worker 会并行读取这个表
- 然后做本地排序(部分聚合),再通过 shuffle 做final 聚合
- 每个节点只会产生一个 shuffle 数据文件 + 索引文件
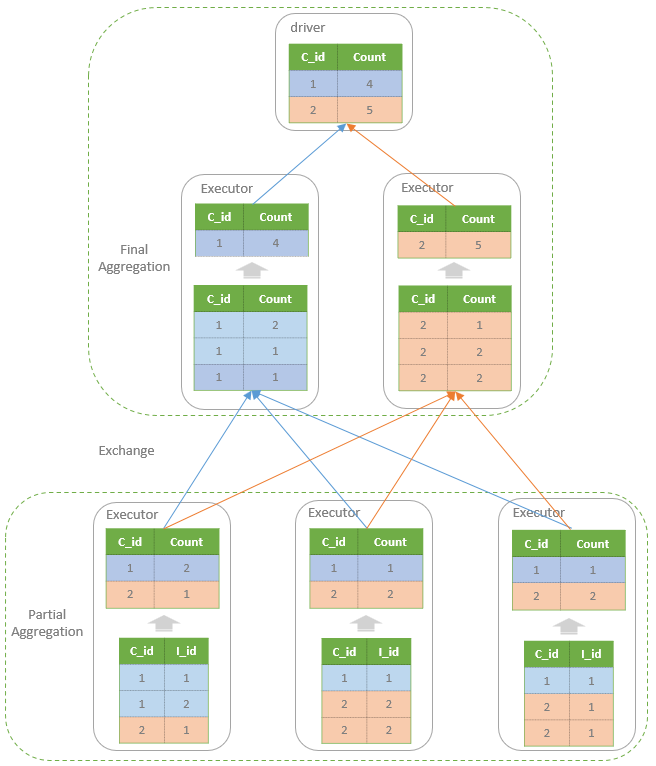
Flink 的执行过程
flowchart TD
subgraph FlinkDataflow[Flink Pipelined Execution]
direction LR
subgraph TaskManager1[TaskManager JVM 1]
S[Source<br/>Read Data] --> |Forward records| L[LocalKeyBy<br/>C_Id]
L --> |Forward grouped<br/>stream| PA[PartialAggregate<br/>Count*]
end
subgraph Shuffle[Network Shuffle]
direction TB
PA --> |Ship by key<br/>C_id| NS[Network Shuffle]
end
subgraph TaskManager2[TaskManager JVM 2]
NS --> FA[FinalAggregate<br/>Sum partial counts]
end
FA --> Si[Sink<br/>Send to Client]
end
Flink 的问题
- 读取一个 buffer数据后,就立刻发给下游
- 当数据不断积累就需要写磁盘,由于是不断发过来的数据,所以会产生很多小文件
- 之后又会有合并的情况(多个文件读做归并)
- 这就导致它的 I/O 读写要比spark 多很多
Shuffle Mechanism Face-Off
| Aspect | Spark | Flink | Performance Impact |
|---|---|---|---|
| Shuffle Write | Single consolidated writeEach task writes 1 file per reducer (e.g., 10 tasks × 10 reducers = 100 files) | Incremental spill writesEach task writes multiple small spill files (e.g., 10 tasks × 20 spills = 200+ files) | 🚫 Flink: 2-5x more file creations → Higher metadata overhead |
| File Size | Large partition filesFull partition output written as single file (e.g., 512MB file) | Small spill filesBuffer-sized writes (e.g., 128MB buffer → 128MB files) | 🚫 Flink: More random I/O during read phase → Slower merge |
| Sorting | Single full sortSort entire partition once before writing | Multi-pass merge sortSort in-memory chunks → spill → merge sorted runs | 🚫 Flink: 30-50% more CPU cycles for same data volume |
| Network Transfer | Pull-basedReducers fetch entire partitions when ready | Push-basedMappers push data immediately via backpressure | ✅ Flink: Lower latency but ⚠️ causes more small network packets |
| Disk I/O Pattern | Sequential writesLarge contiguous writes to disk | Random writesSmall buffer flushes scattered on disk | 🚫 Flink: 2-3x slower on HDDs, 30% slower on SSDs |
Spark Execution:
|
|
Flink Execution:
|
|
总的来说
- Flink 会产生更多的小文件,导致更多的 I/O 读写
- 会有更多的合并,造成写放大
其他影响点
- Flink 的 checkpoint
- 反压机制
- 没有 Spark 那样的 AQE 运行时优化
- 没有 Spark 那样的 Whole-Stage Code Generation
checkpoint
- I/O Pauses: The pipeline experiences mini-pauses as operators align with the barrier and persist state.
- Network & Disk I/O: Even for a simple SELECT * FROM table, Flink might checkpoint source offsets and operator states, writing small files to remote storage.
- Coordination Overhead: The Job Manager coordinates this global snapshot, creating communication overhead.
Flink (Push-based with Backpressure):
- Operators push data to the next operator as soon as it’s ready.
- If the downstream operator is slow, backpressure is signaled upstream, eventually slowing down the source.
- Batch Impact: This model is designed for continuous flow. In batch, it can lead to poor locality. A fast mapper might push data to a remote reducer that isn’t ready, causing the data to be buffered in memory or spilled to disk on the reducer’s node instead of being efficiently read later from the mapper’s local disk.
Core Difference: Philosophy of Memory Management
| Apache Spark (Tungsten) | Apache Flink | |
|---|---|---|
| Primary Goal | Maximize throughput for batch/micro-batch processing. | Enable low-latency, stateful, record-by-record streaming processing. |
| Memory Model | Operator-Centric. An operator (e.g., a sorter) claims a large, contiguous chunk of off-heap memory and manages it itself for its specific purpose. | Network-Centric. MemorySegment is the universal currency of data exchange between operators, networks, and disks. |
| Data Format | Custom, internal, columnar layout. Data is formatted for computational efficiency (e.g., columnar for aggregation). | Serialized byte arrays. Data is stored in its serialized form (e.g., as it would be sent over the network or to disk). |
| Analogy | A specialized factory workshop that rearranges raw materials (data) into a custom layout for a single, efficient assembly line. | A universal shipping container system. Goods are packed in standardized containers (MemorySegments) for easy transport, regardless of their content. |
简单来说
- Flink 的内存管理,可以用于算子处理、网络发送、checkpoint、存储到 rocksDB
- 但是他不是专门为计算而设计的
- Spark Tungsten 专门设计了自定义的存储格式,对于CPU和缓存友好,适合计算场景
向量化
- Spark 有 gluten + velox
- 目前阿里有类似的实现,但不开源
- velox 做的都是无状态算子,需要大量改造,目前不支持
- 还有状态存储,回撤这些支持
Flink Operator
Flink 任务提交方式
Flink run (CLI Submission)
例子
|
|
Flink Kubernetes Operator
例子
|
|
Apply with:
- kubectl apply -f flink-deployment.yaml
Flink REST API
例子
|
|
SQL Client & Table API
例子
|
|
PyFlink (Python API)
例子
|
|
Flink Application Mode
例子
|
|
Flink Web UI
操作
- Upload and submit jobs through the Flink dashboard
- Monitor and manage running jobs
- Access via http://jobmanager:8081
总结
Spark
Spark Submission Methods Comparison
| Method | Advantages | Disadvantages | Best For |
|---|---|---|---|
| spark-submit CLI | • Simple and universal• Full control over parameters• Works with all cluster managers | • Manual operation• Limited automation• No built-in session management | • Batch jobs• Scripting• Testing |
| Spark Thrift Server | • JDBC/ODBC compatibility• BI tool integration• Connection pooling | • Resource-intensive• Single point of failure• Complex to scale | • Business intelligence• Ad-hoc queries• Tableau/Power BI |
| Spark Operator (K8s) | • Kubernetes-native• Declarative API• GitOps compatible | • K8s expertise required• Limited to Kubernetes• Newer ecosystem | • Cloud-native deployments• CI/CD pipelines• Multi-tenant environments |
| Apache Livy | • REST API interface• Session management• Multi-user support | • Performance overhead• Additional component• Declining adoption | • REST-based automation• Web applications• Legacy systems |
| Notebooks (Jupyter/Zeppelin) | • Interactive development• Visualization• Collaboration friendly | • Resource inefficient• Versioning challenges• Production concerns | • Exploration• Prototyping• Data science |
| Kyuubi | • Multi-engine support• Better isolation• Cloud-native | • Newer project• Less documentation• Smaller community | • Multi-engine environments• Replacement for Livy/Thrift |
Flink
Flink Submission Methods Comparison
| Method | Advantages | Disadvantages | Best For |
|---|---|---|---|
| flink run CLI | • Direct control• Simple debugging• All Flink features | • Manual operation• No automation• Cluster-specific | • Development• Testing• Simple deployments |
| Flink Kubernetes Operator | • Native K8s integration• Declarative API• Auto-scaling | • Kubernetes dependency• Complex setup• Newer feature set | • Production deployments• Cloud-native environments• Auto-scaling workloads |
| Flink REST API | • Programmatic control• Integration friendly• Cluster management | • Security concerns• Network dependencies• Additional complexity | • CI/CD automation• Custom tooling• Monitoring systems |
| SQL Client | • SQL-only interface• Easy to use• No coding required | • Limited functionality• No complex logic• Debugging challenges | • SQL-centric workloads• Quick prototyping• Business analyst use |
| PyFlink API | • Python ecosystem• Data science integration• Library support | • Performance overhead• JVM/Python bridge• Limited debugging | • ML integration• Python shops• Data science workflows |
| Application Mode | • Isolation guarantees• Dedicated resources• Consistent performance | • Resource intensive• Slower startup• Complex management | • Performance-critical apps• Multi-tenant environments• Production workloads |
Recommendation Summary
| Use Case | Recommended Spark Method | Recommended Flink Method |
|---|---|---|
| Production Batch Processing | Spark Operator | Application Mode |
| Ad-hoc SQL Queries | Thrift Server/Kyuubi | SQL Client |
| CI/CD Automation | spark-submit via scripts | Flink REST API |
| Data Science | Notebooks | PyFlink |
| Stream Processing | Structured Streaming | Flink Operator |
| Multi-tenant Environment | Kyuubi | Application Mode |