2024年11月1日
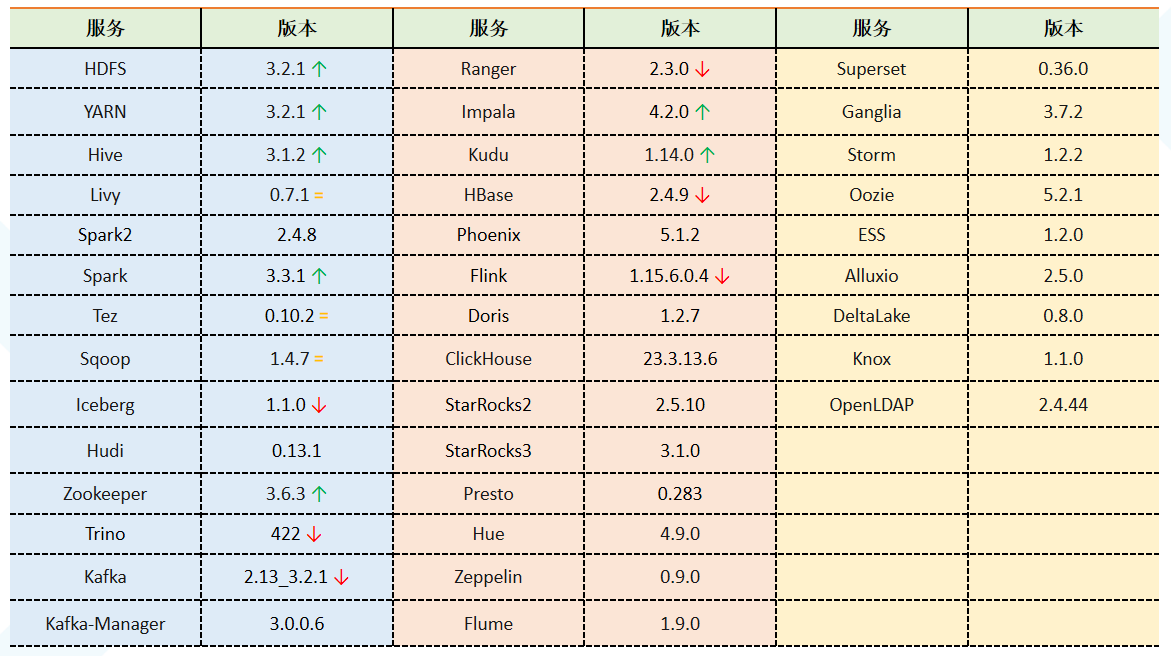
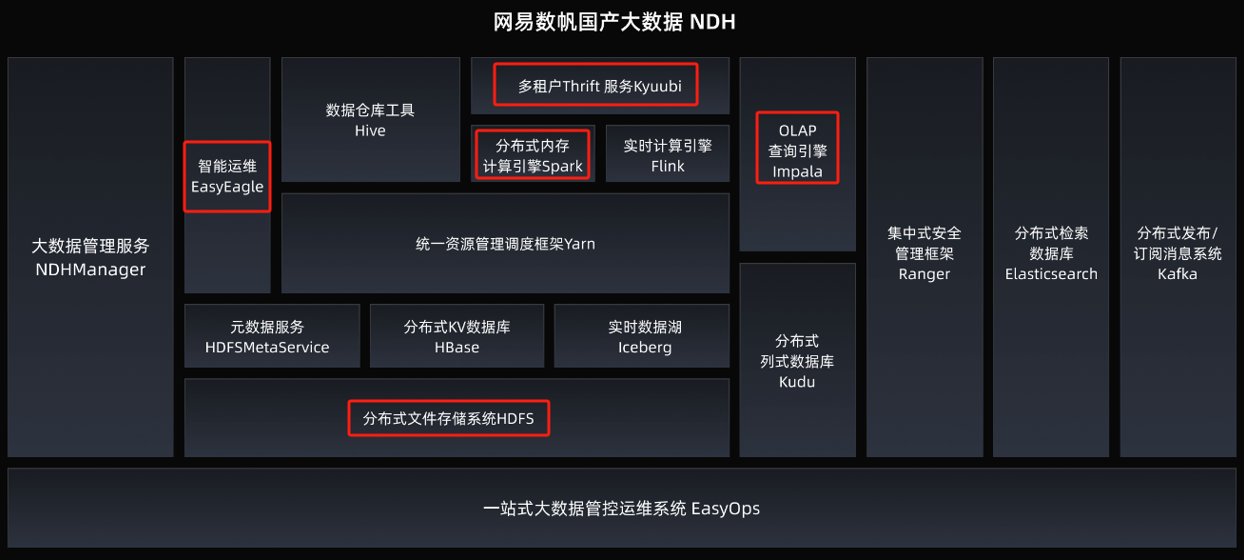
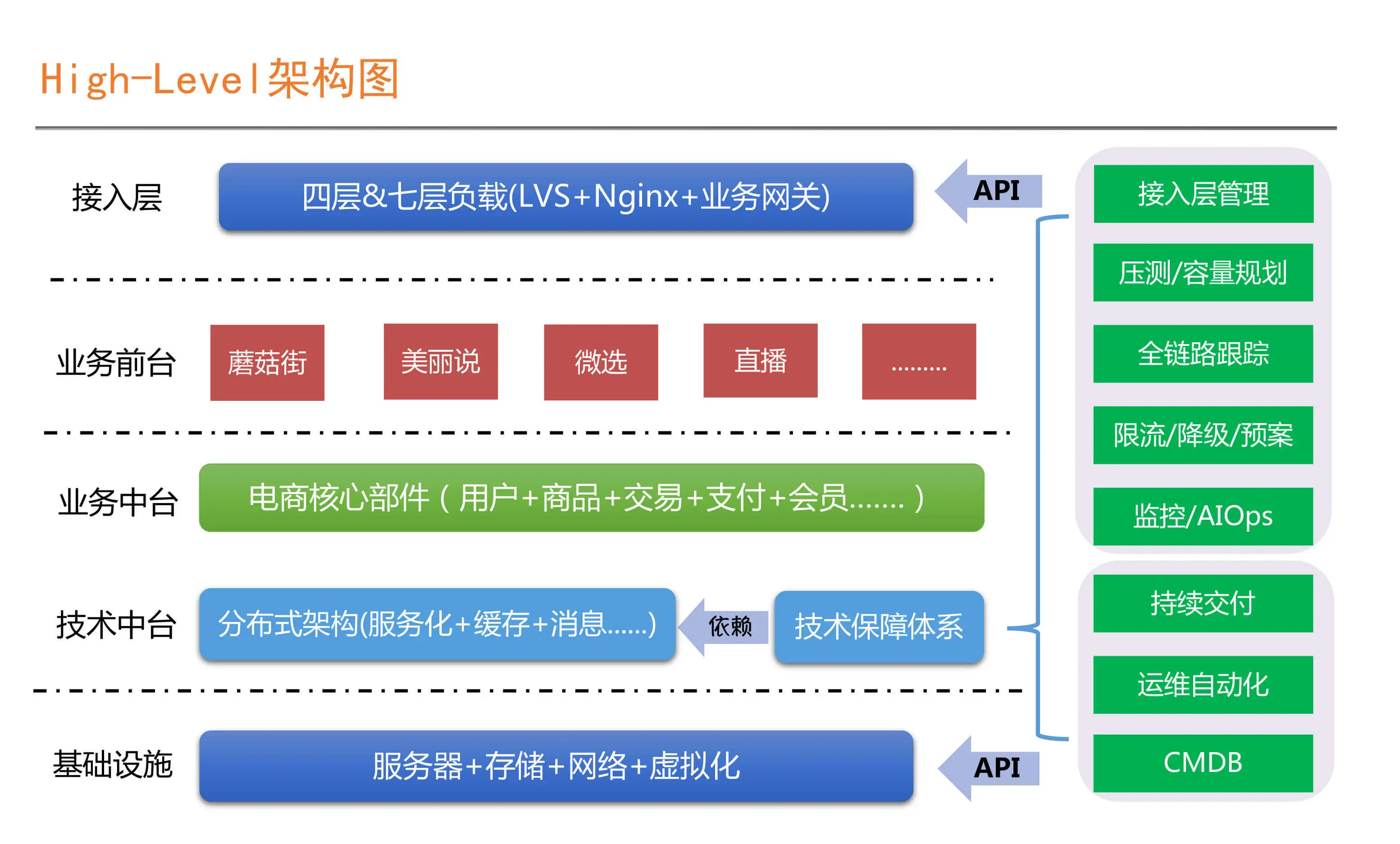
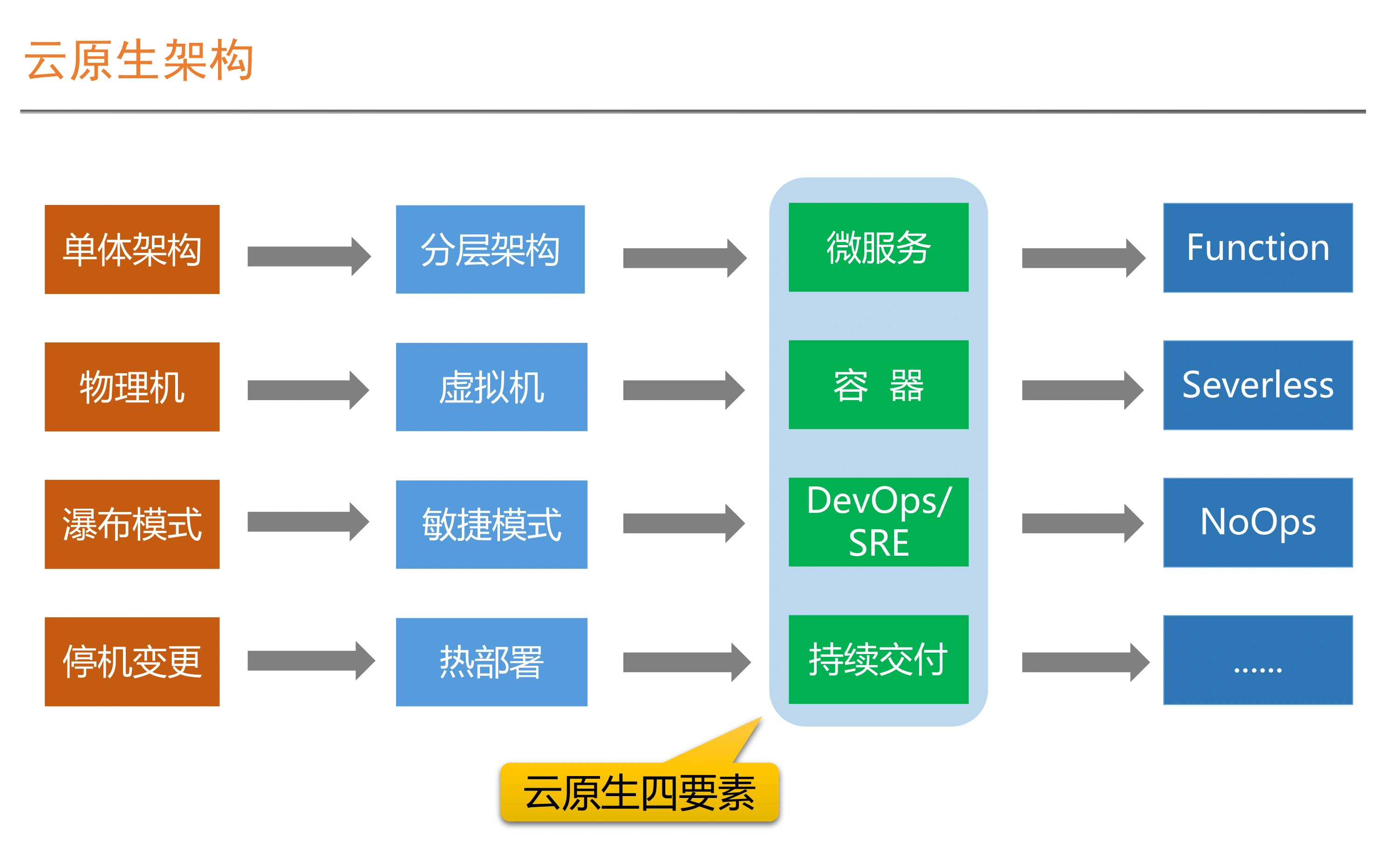
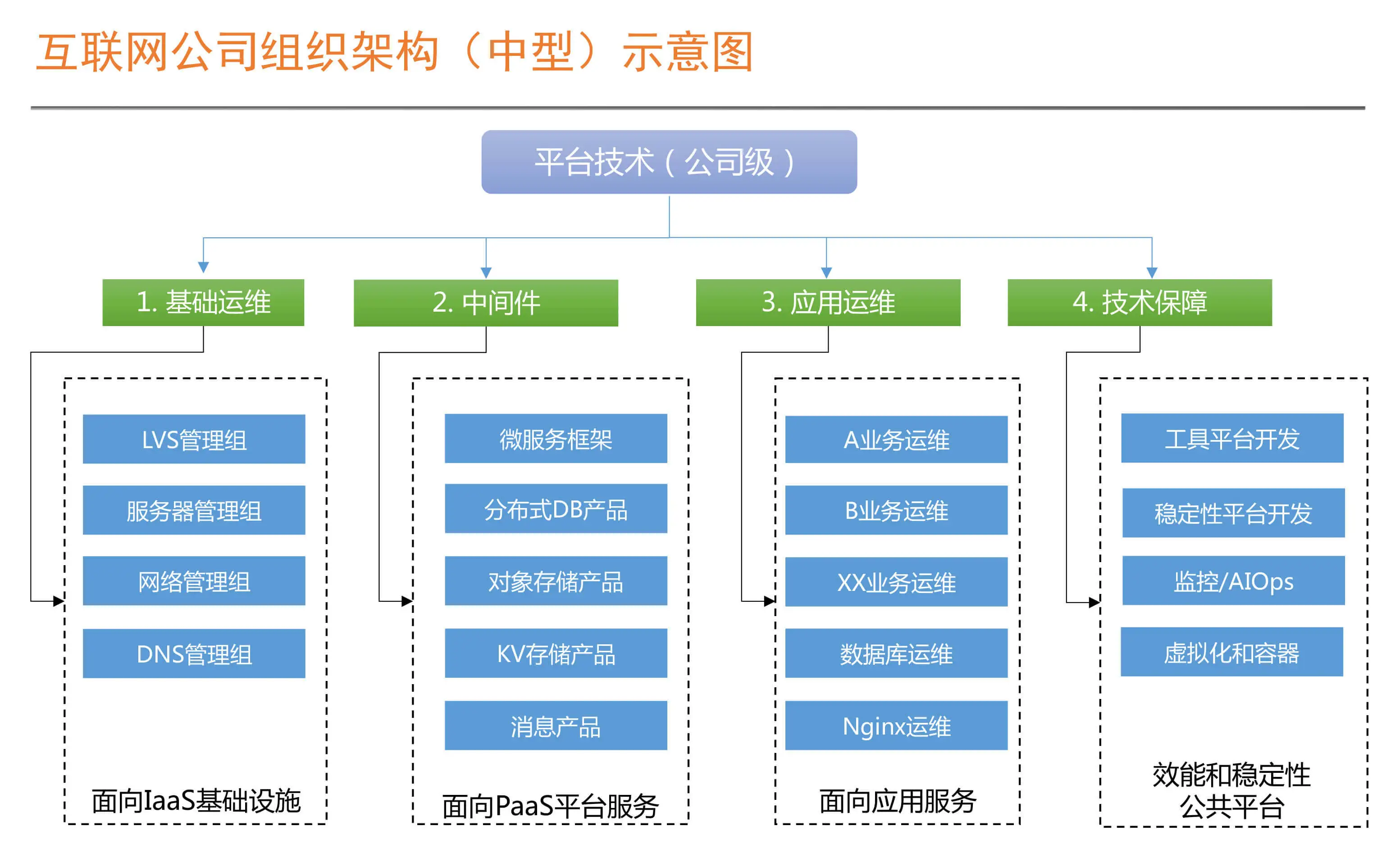
国内几个厂商,阿里、华为、腾讯、网易的大数据平台产品粗略调研;共同点:去Ambari 自己的管控平台,报警 监控 自动化运维,智能诊断,数据治理,集成各开源组件,离线、实时、OLAP,数据服务。 阿里云:有 celeborn向量化, EMR on ECS、on ACK,Serverless, 网易:自动化诊断做的不错,Kyuubi、Impala两个增强点; 华为云:基于OpenStack还有 API,鲲鹏硬件整合、CarbonData,Superiro Scheduler;腾讯:TDBS 比较中规中矩 各种都有
阅读全文
2024年10月30日
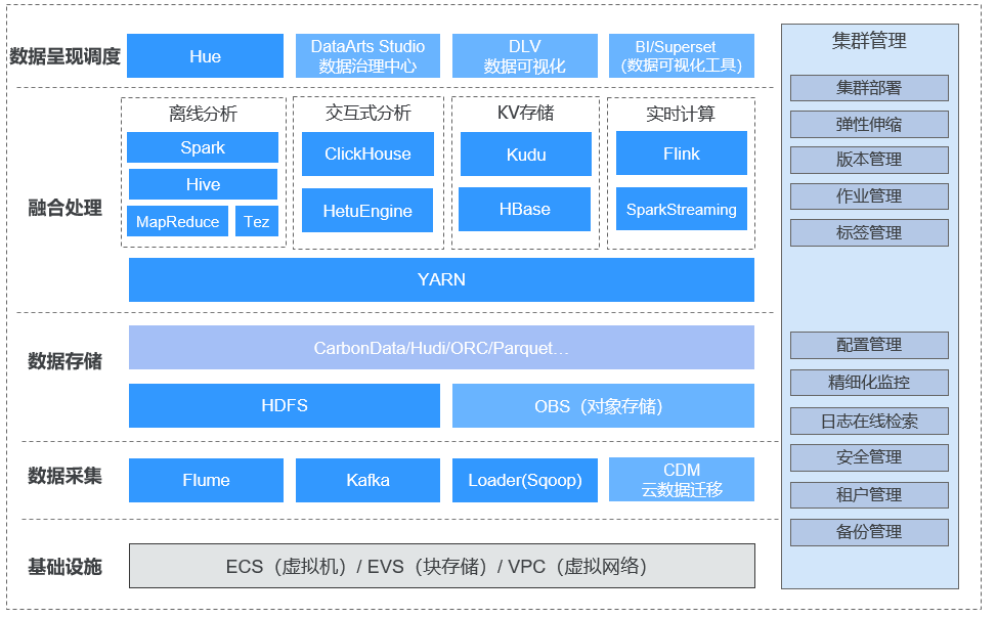
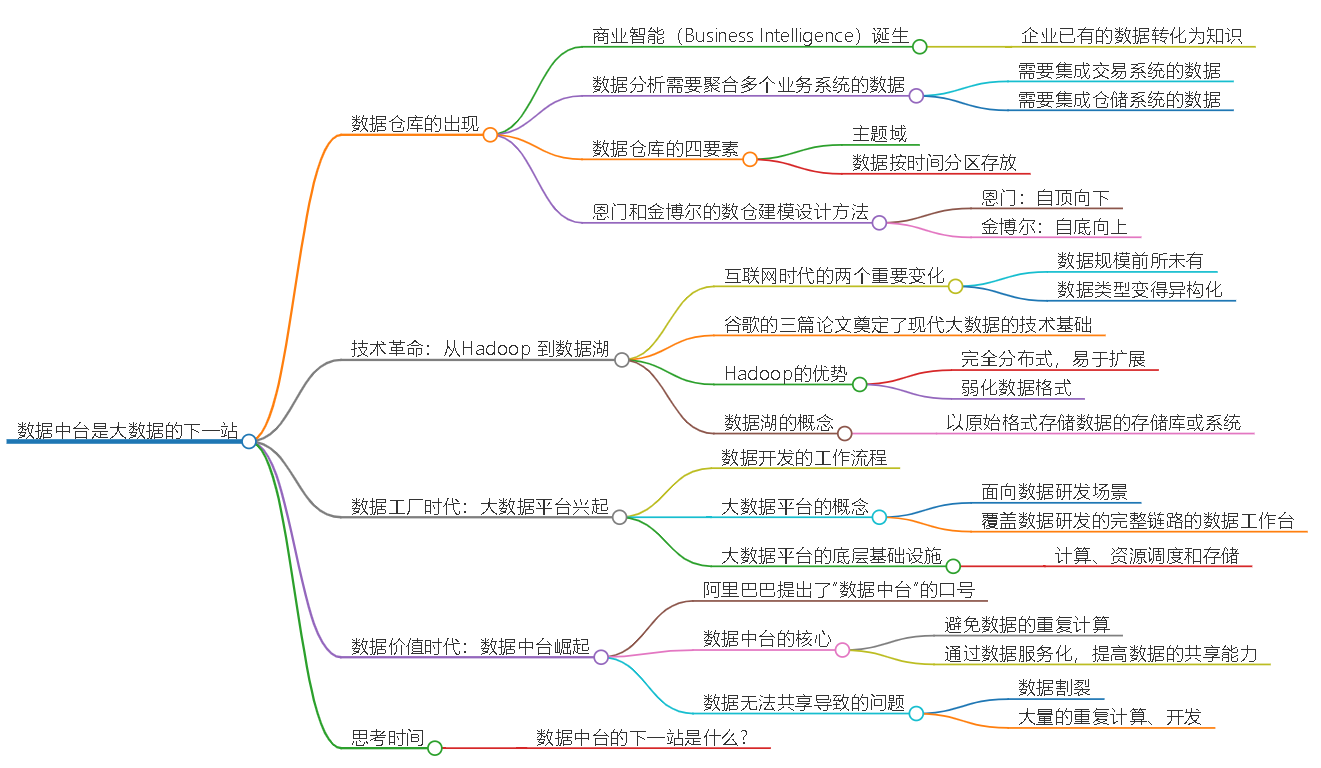
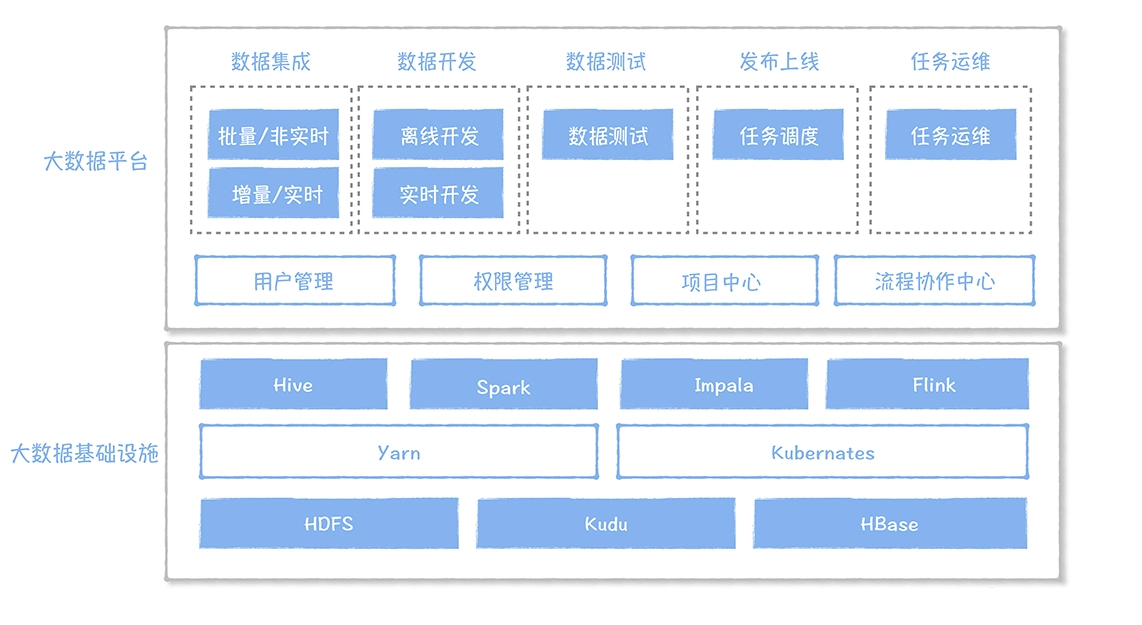
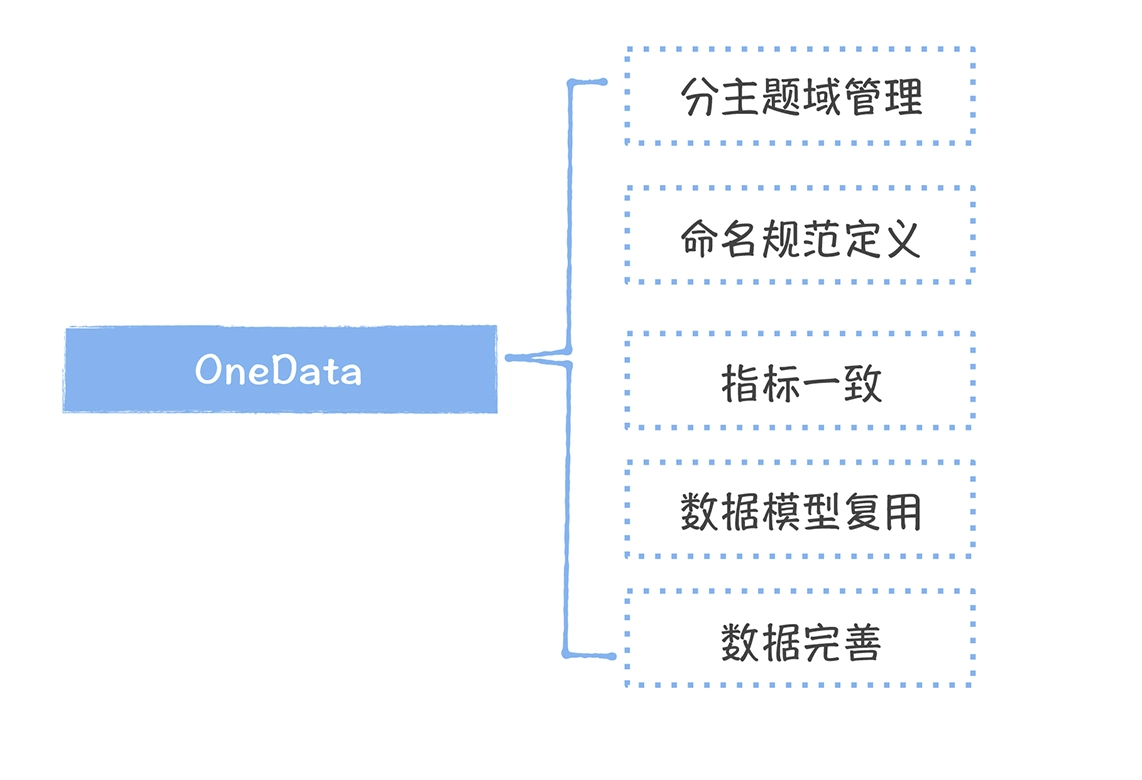
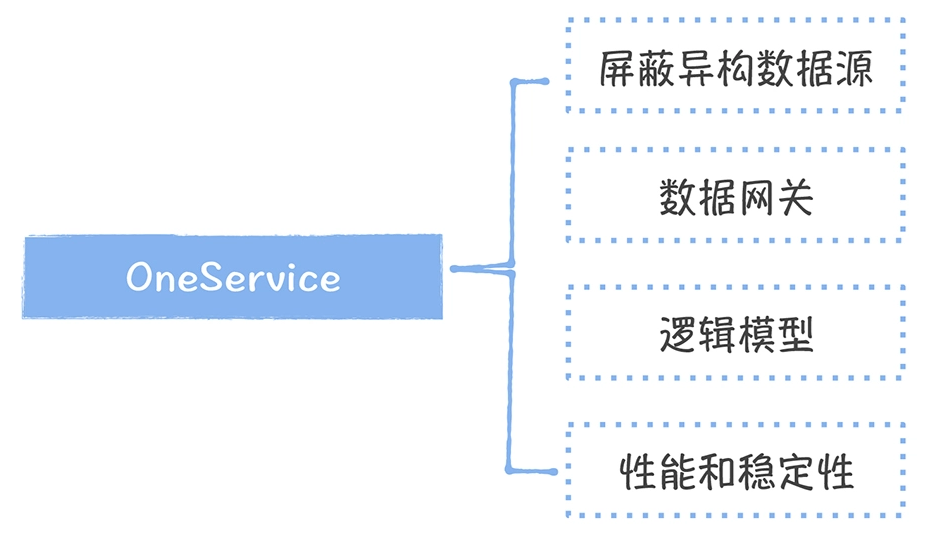
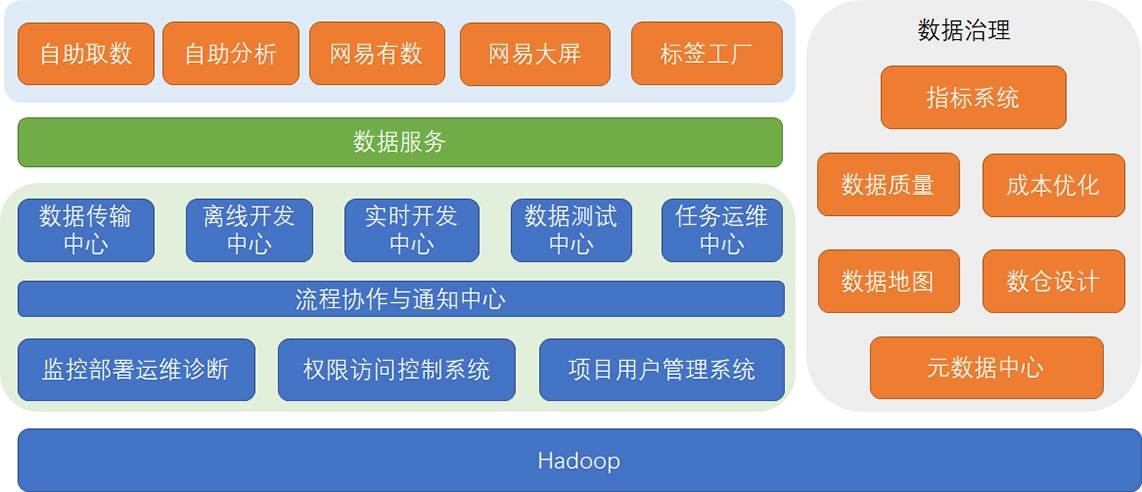
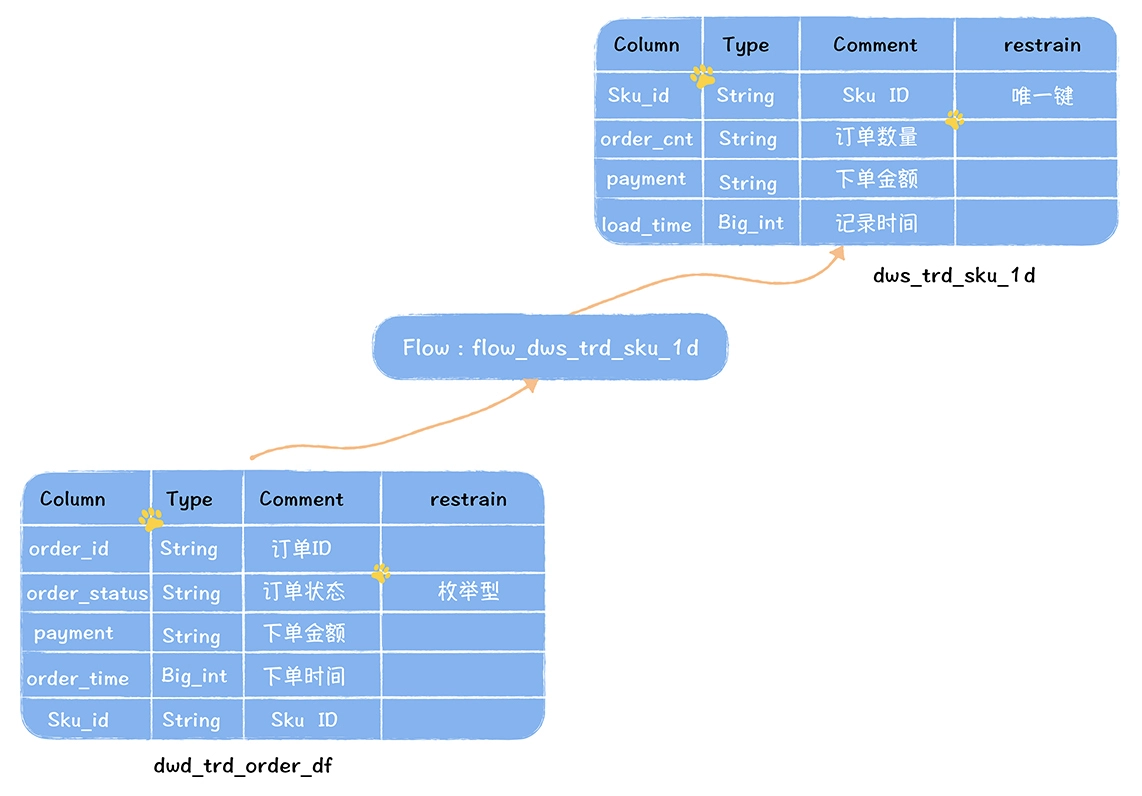
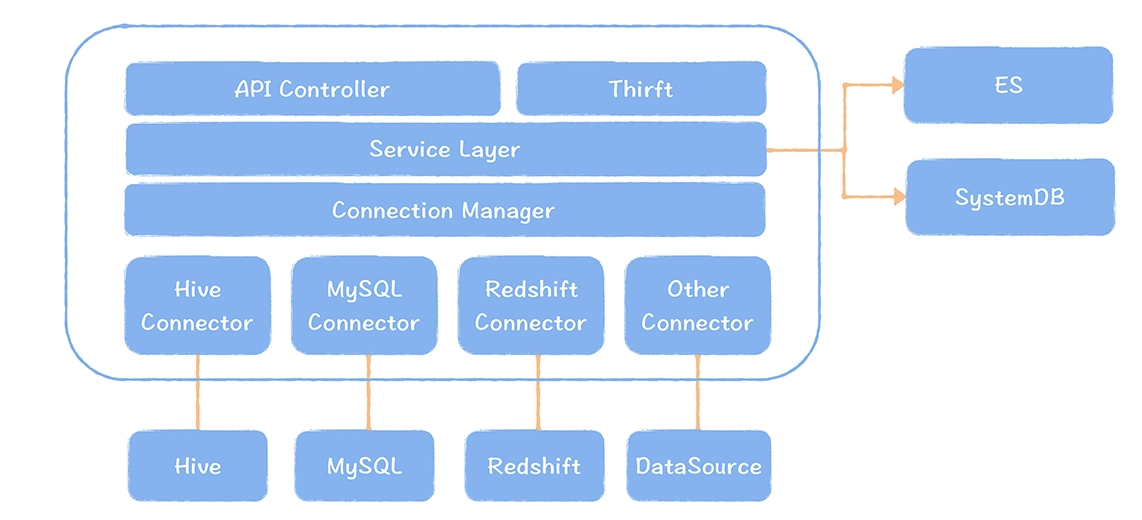
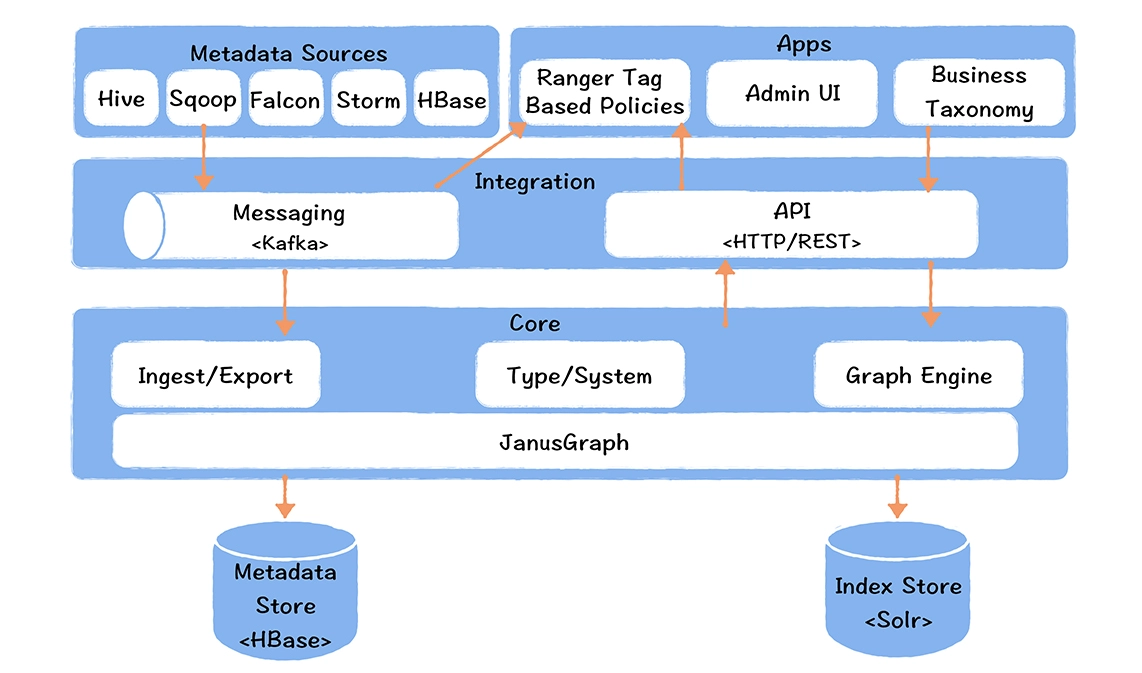
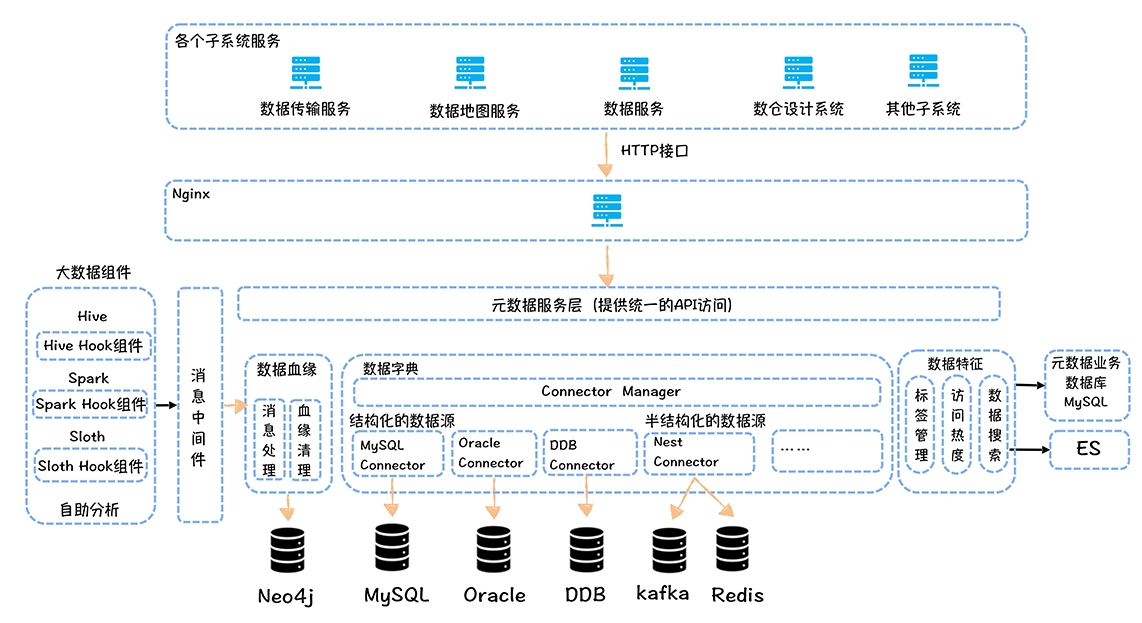
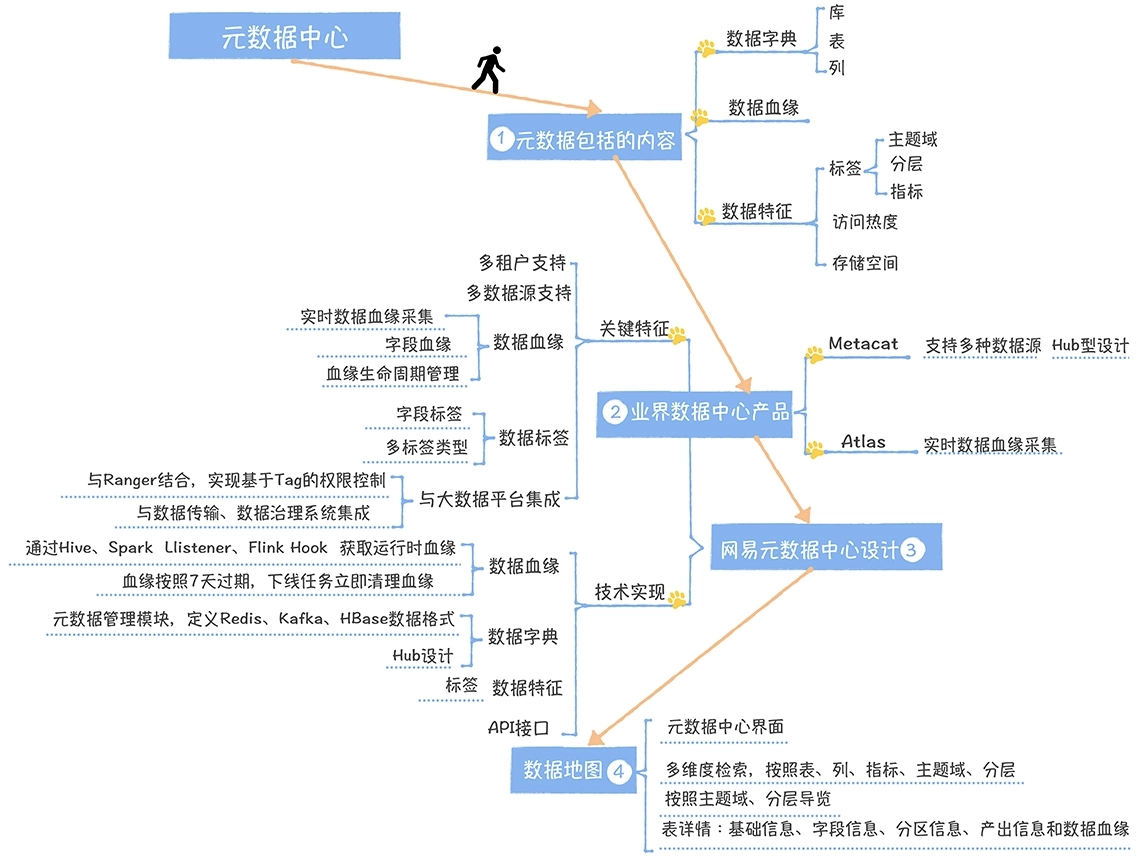
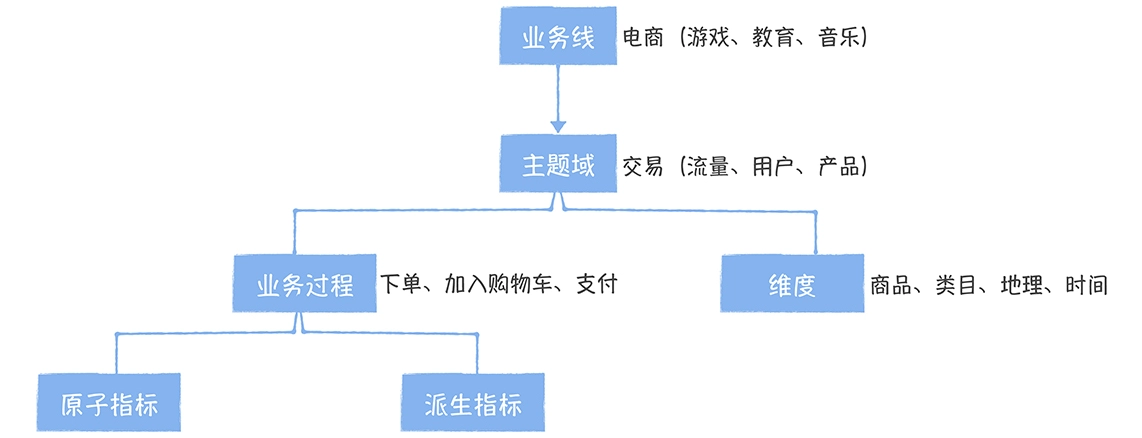
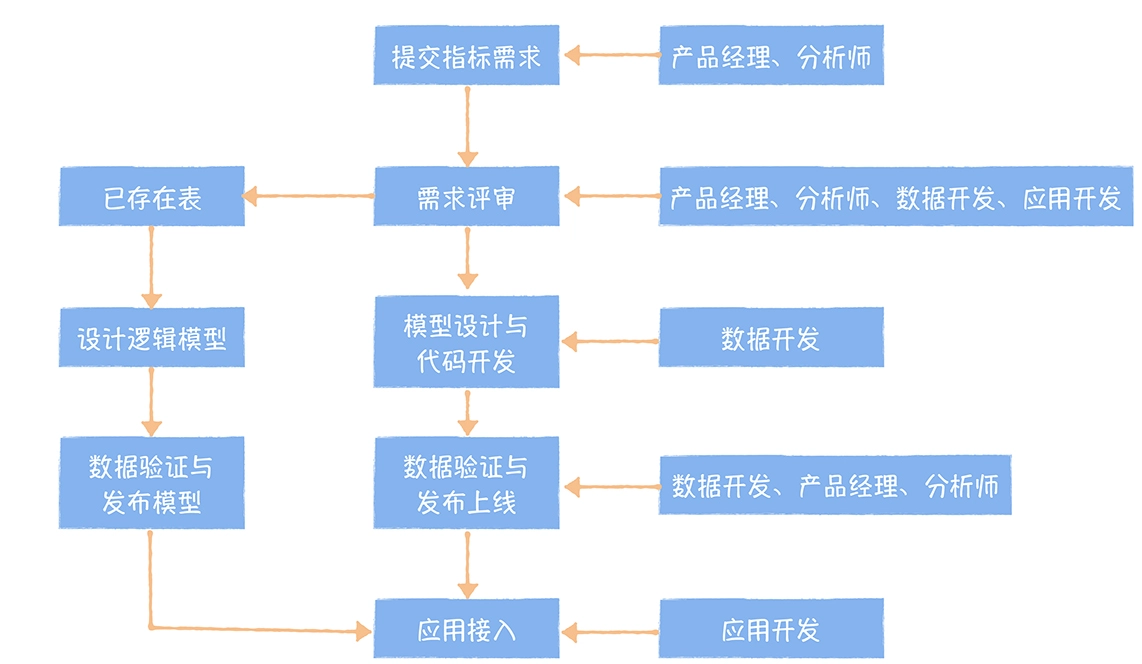
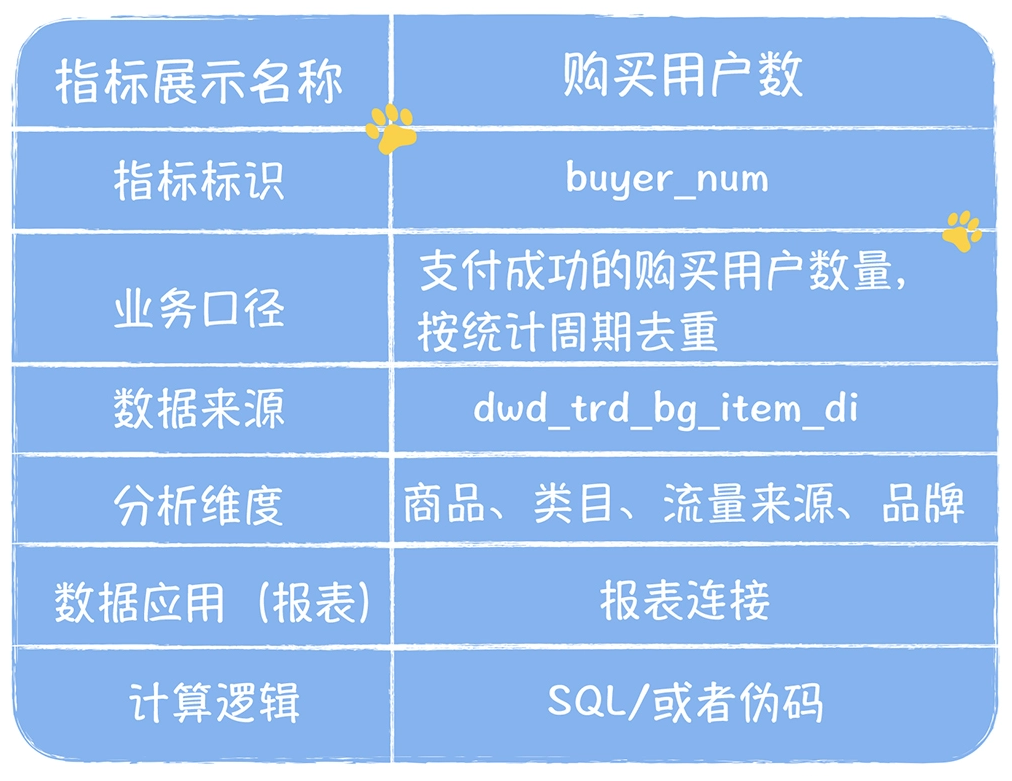
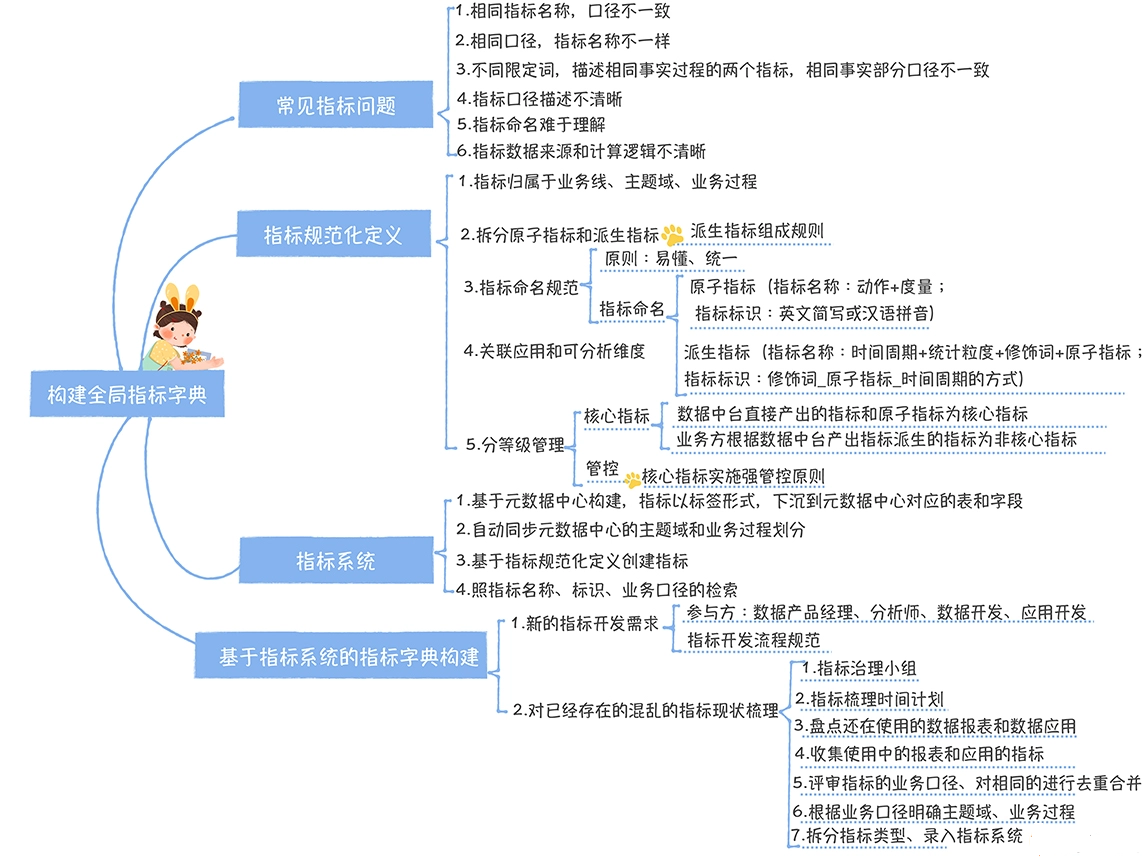
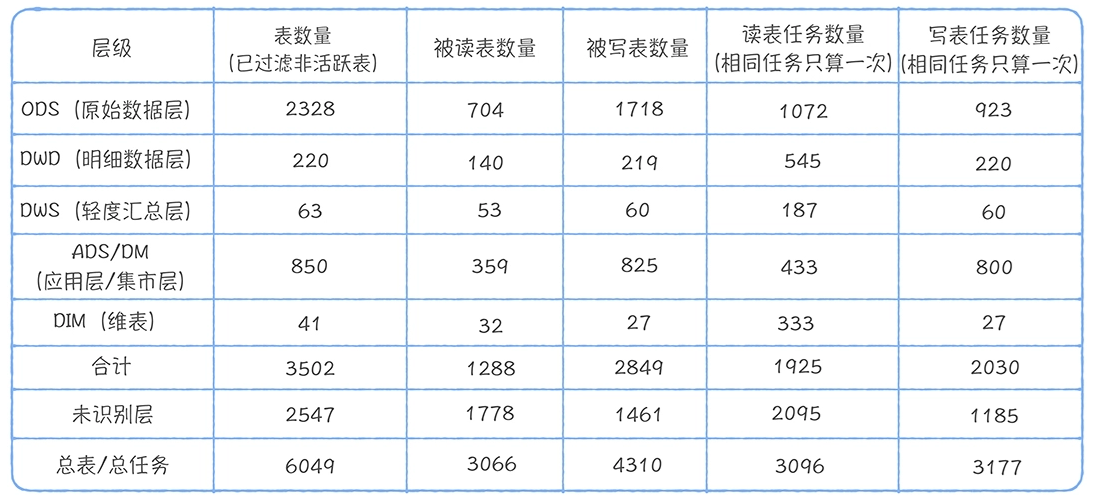
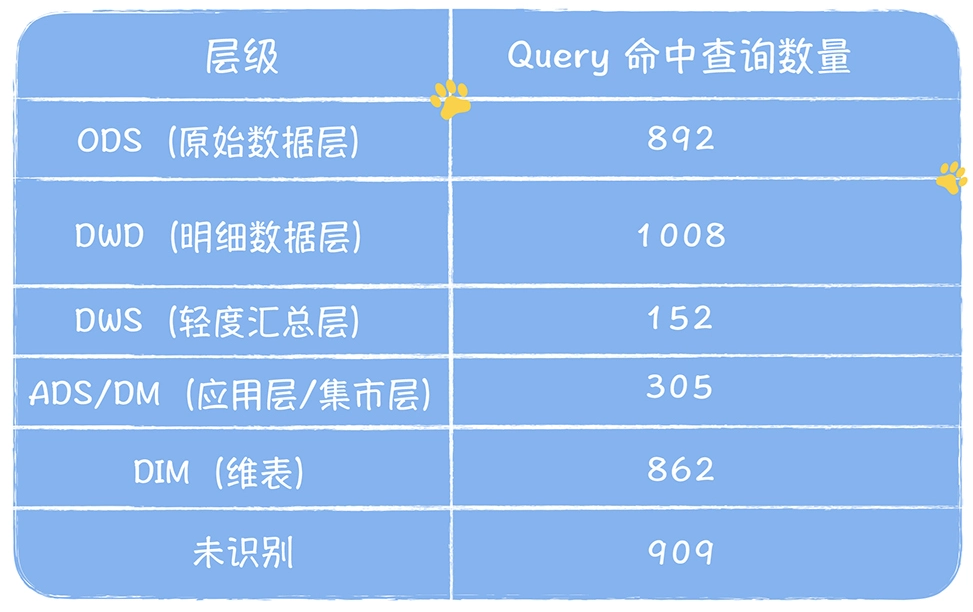
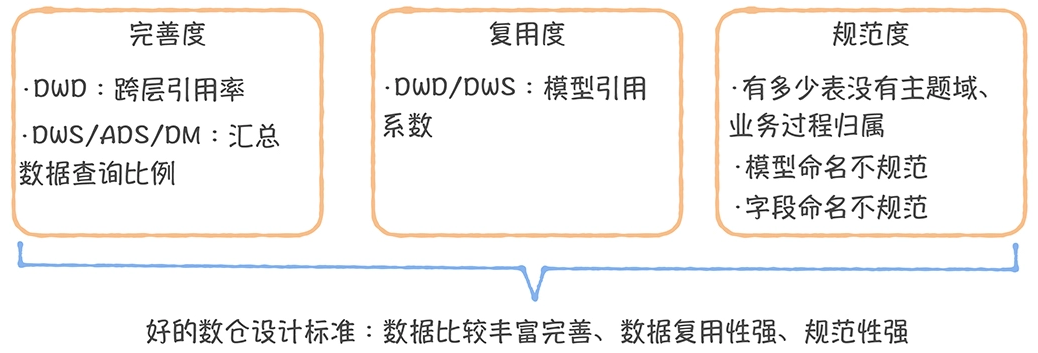
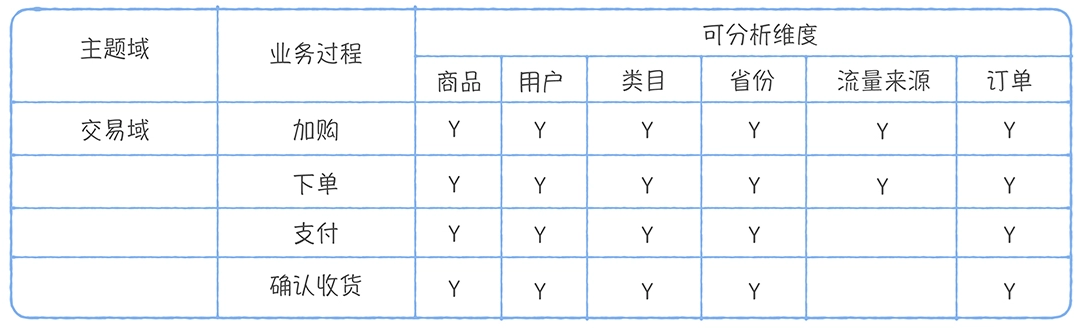
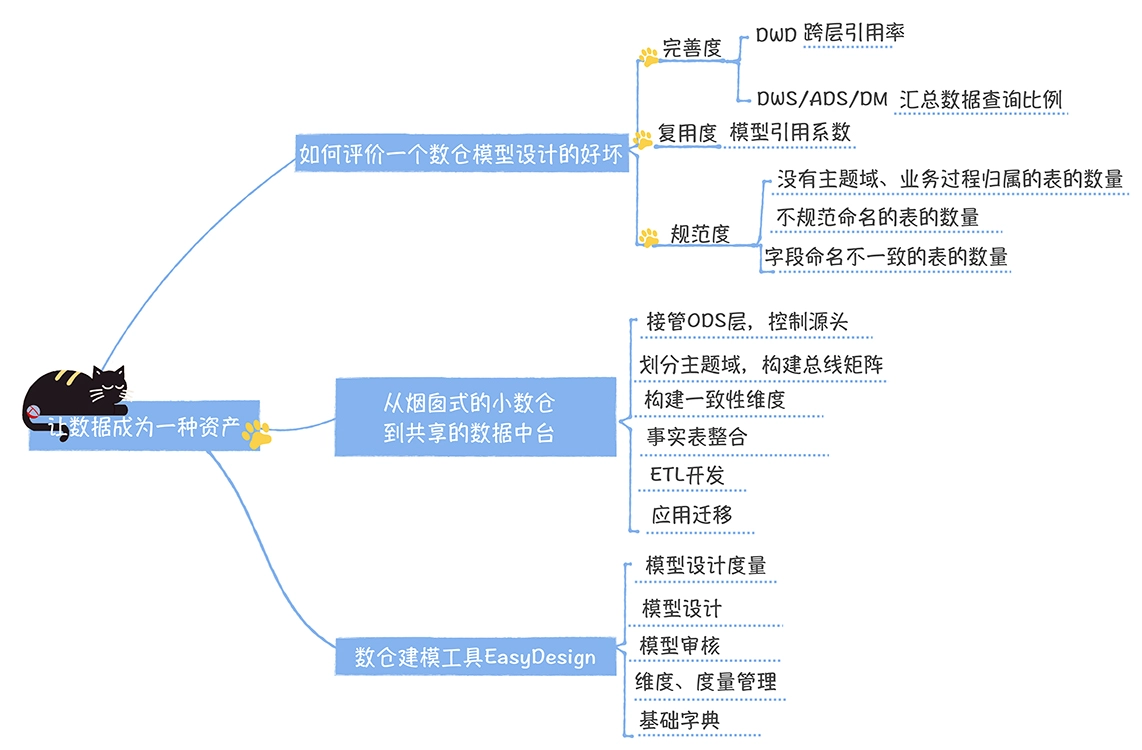
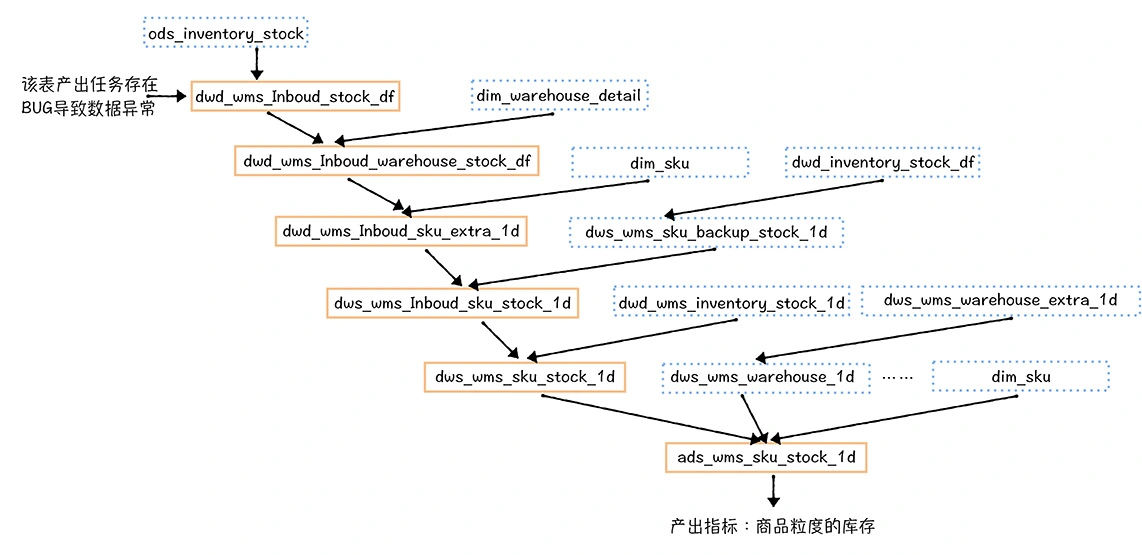
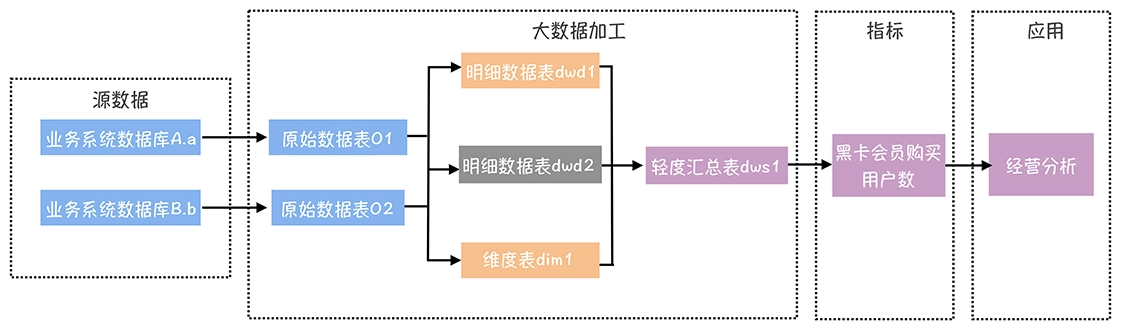
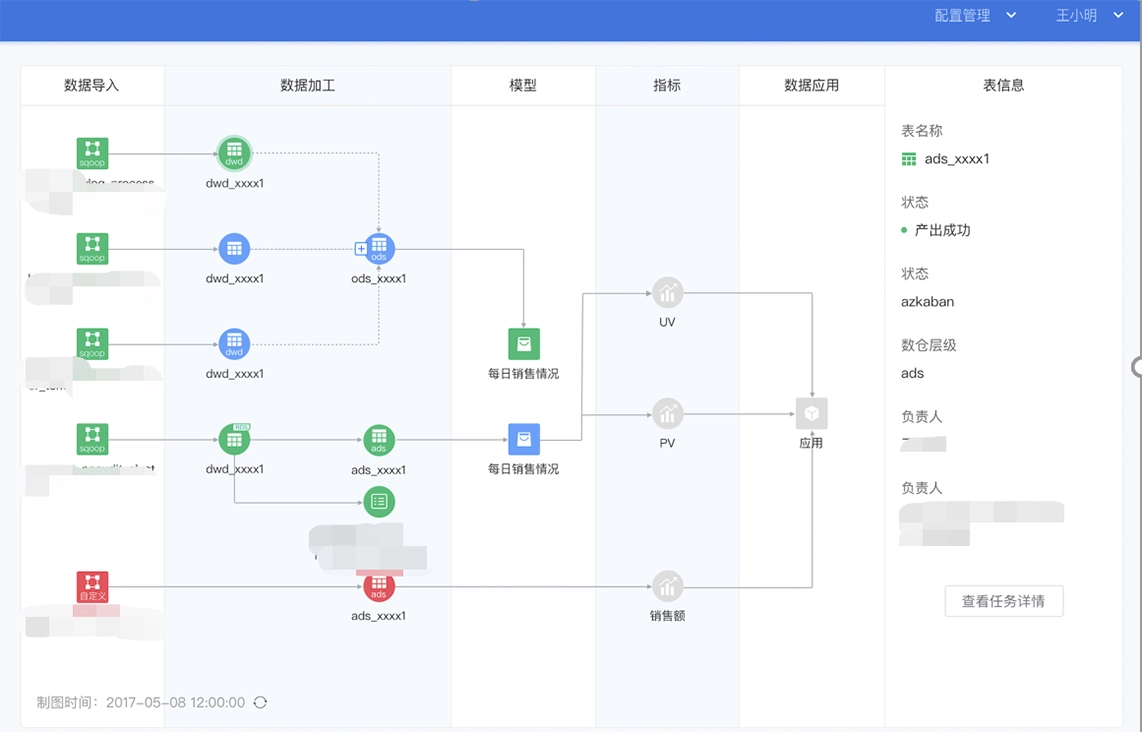
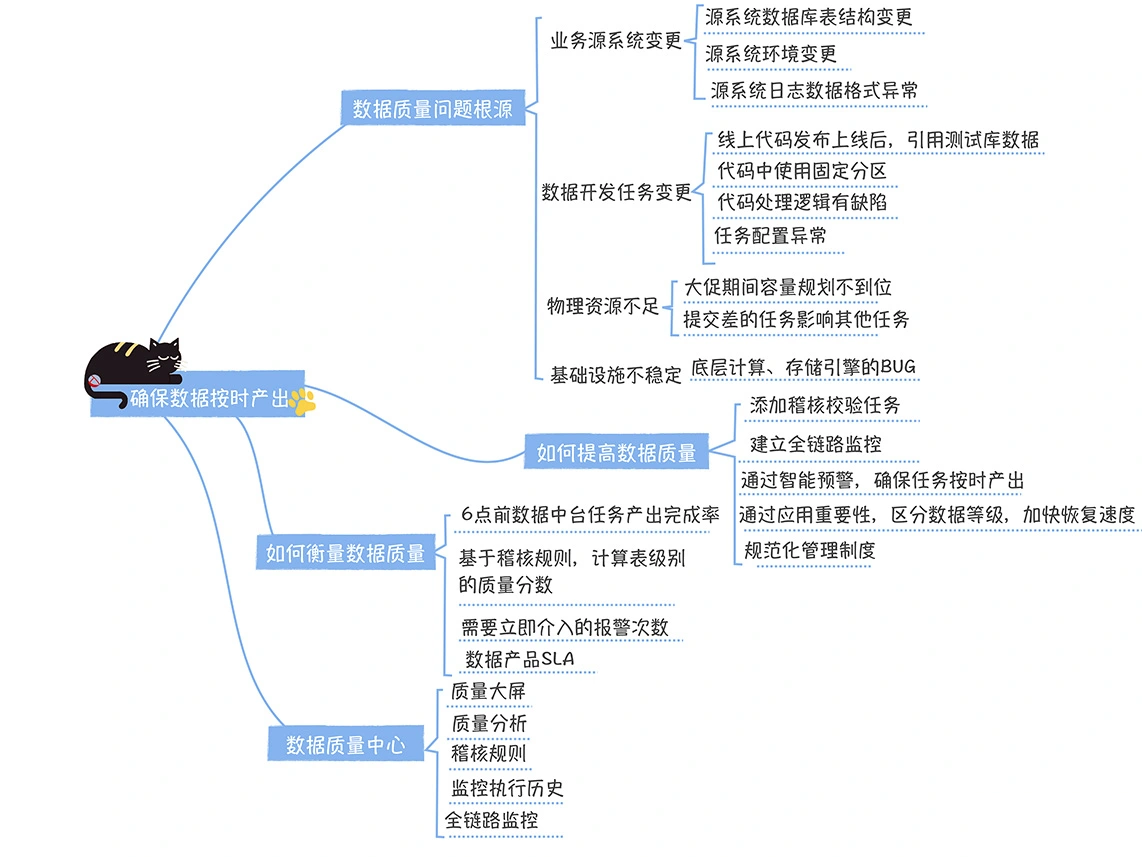
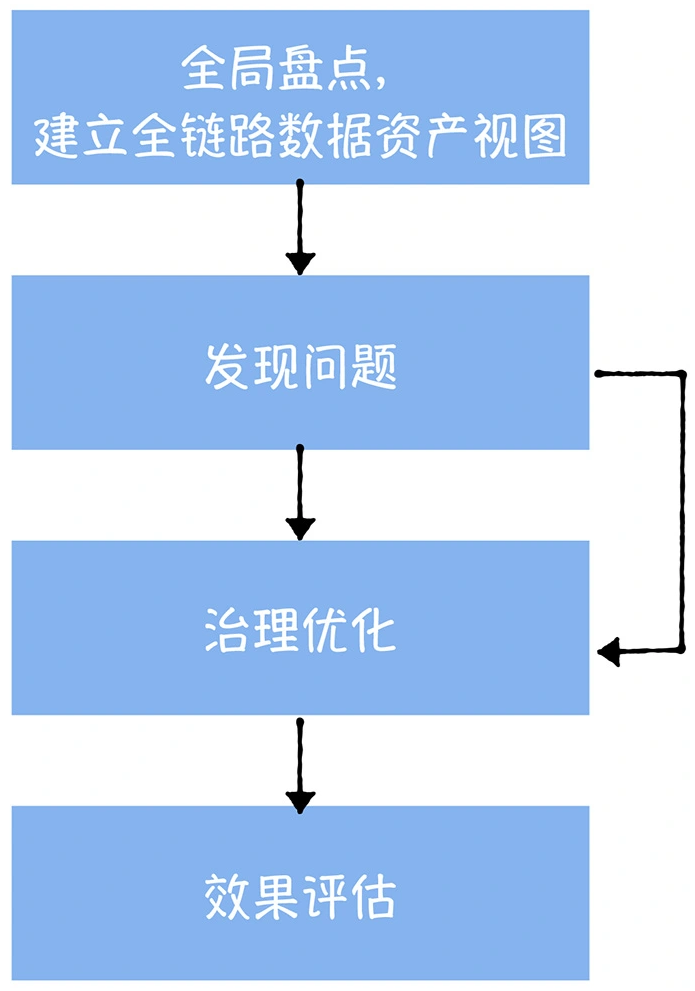
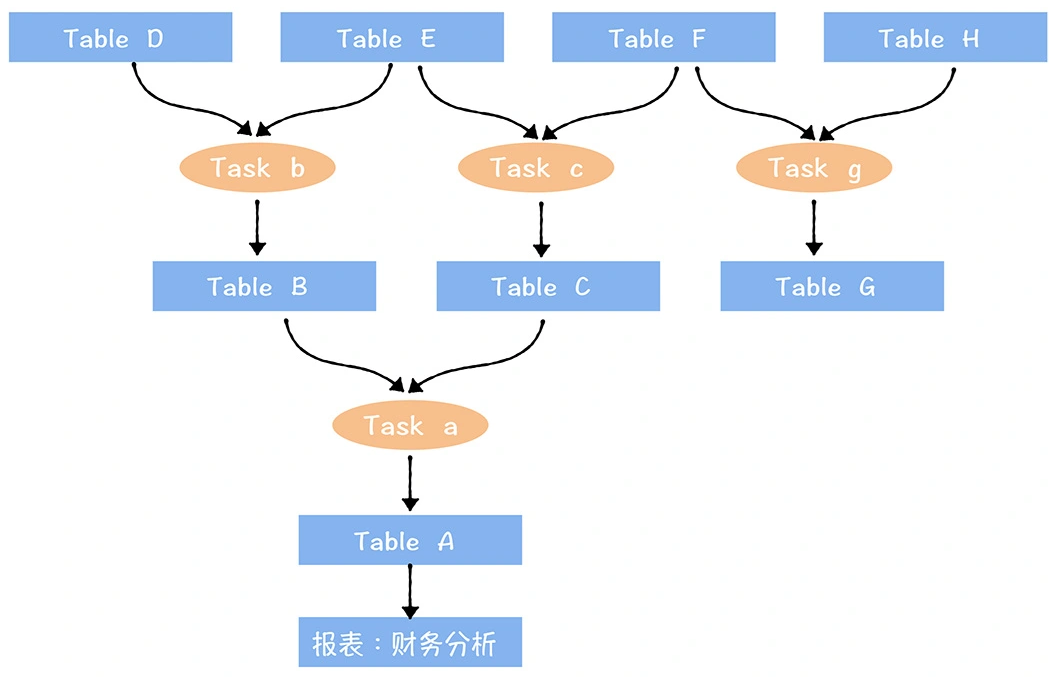
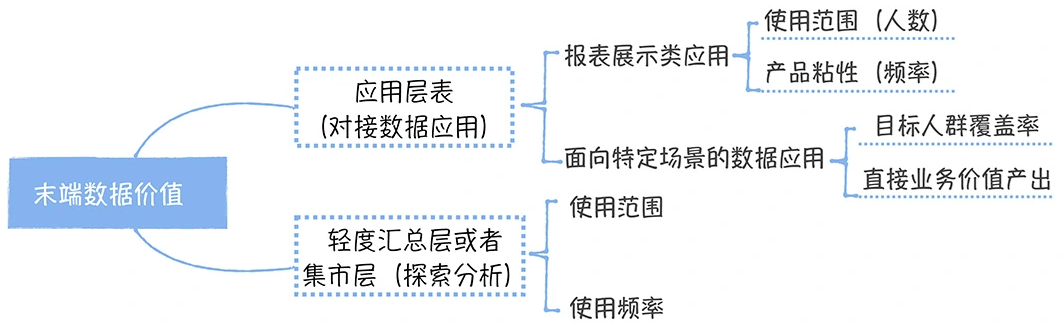
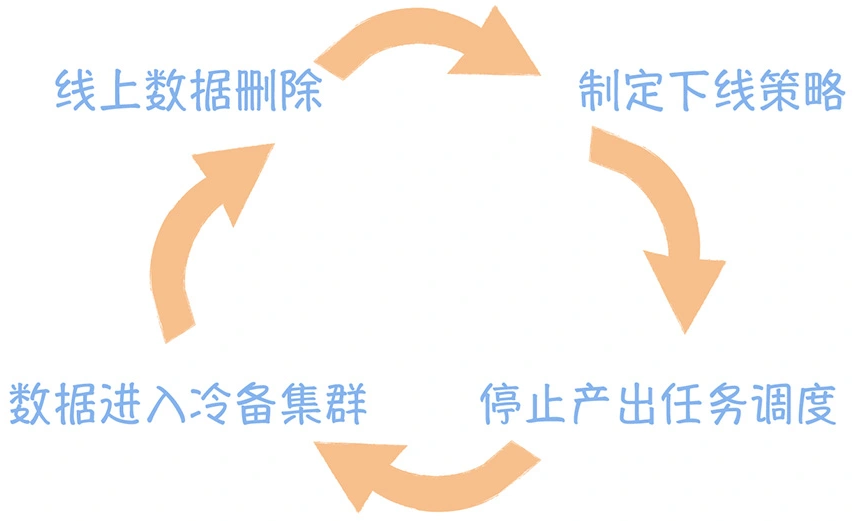
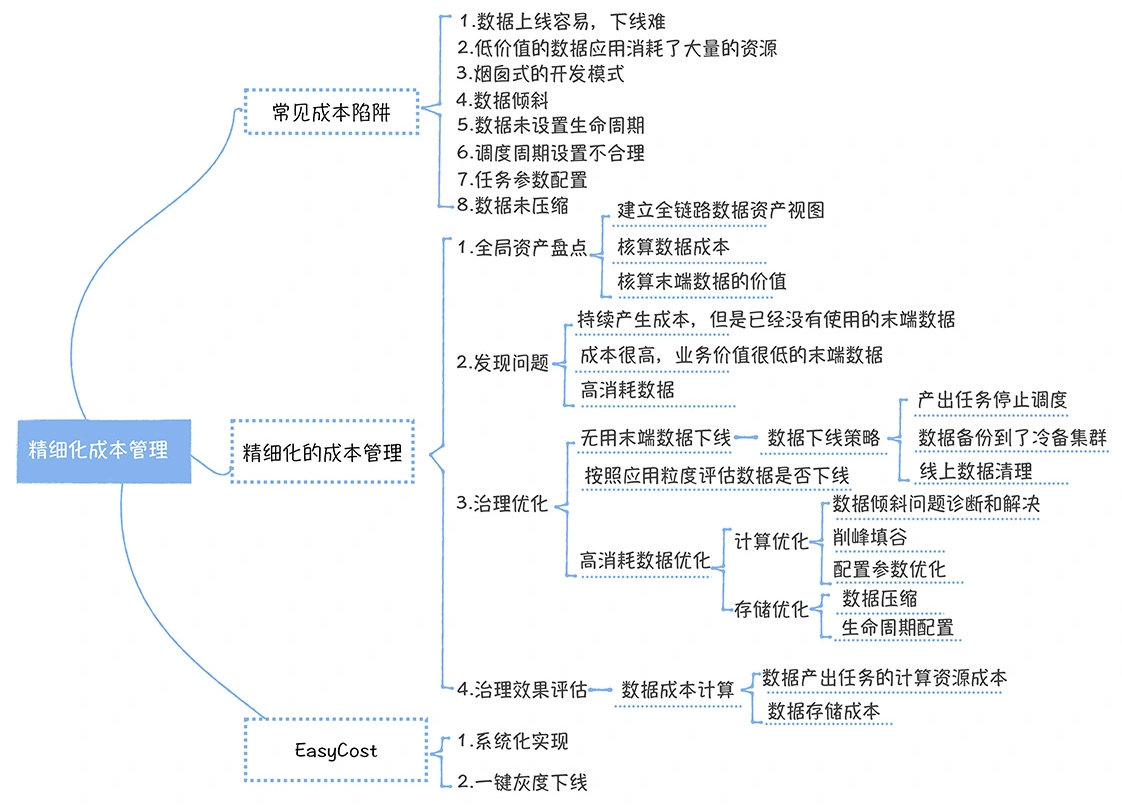
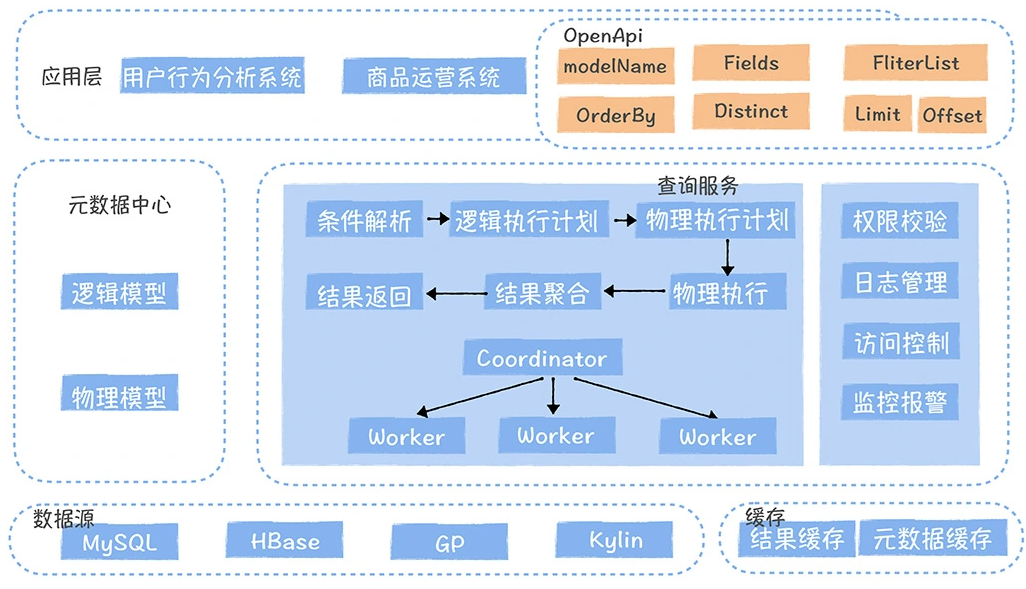
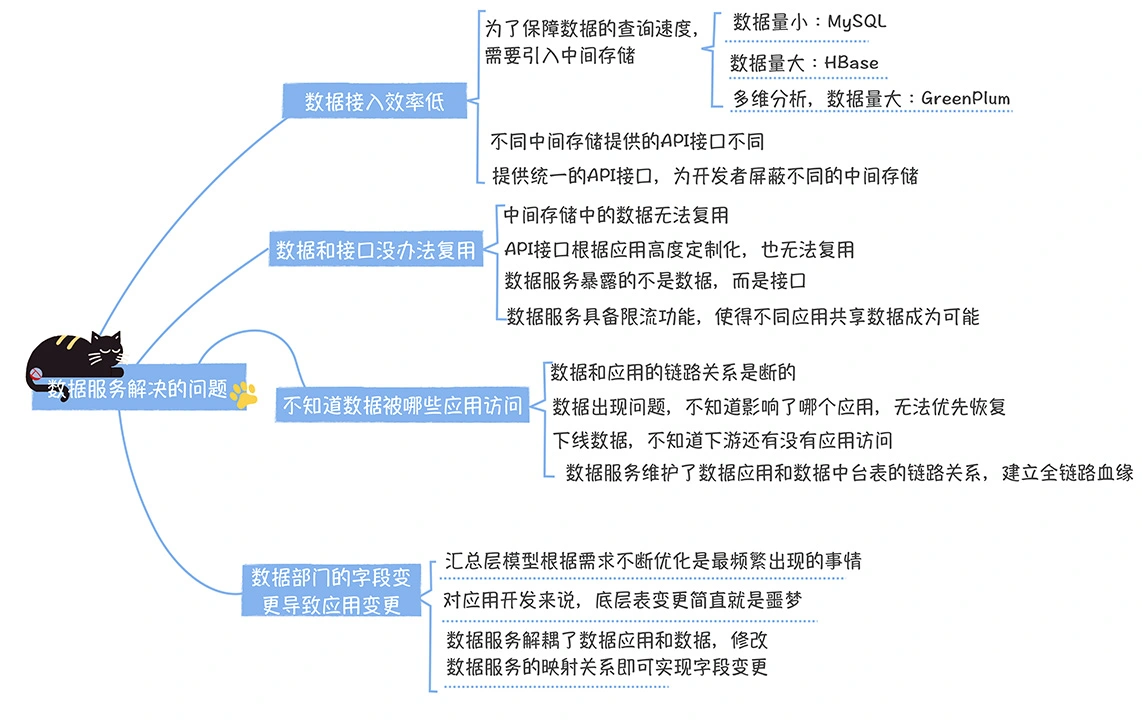
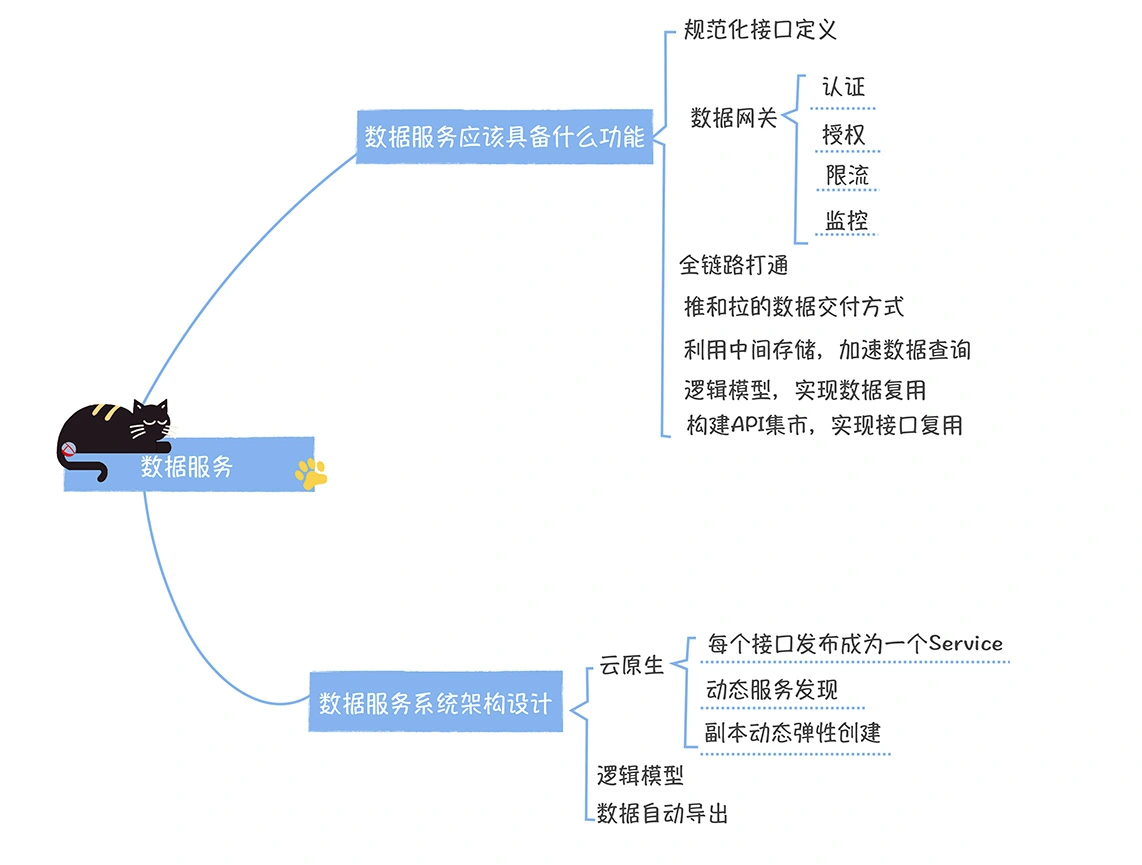
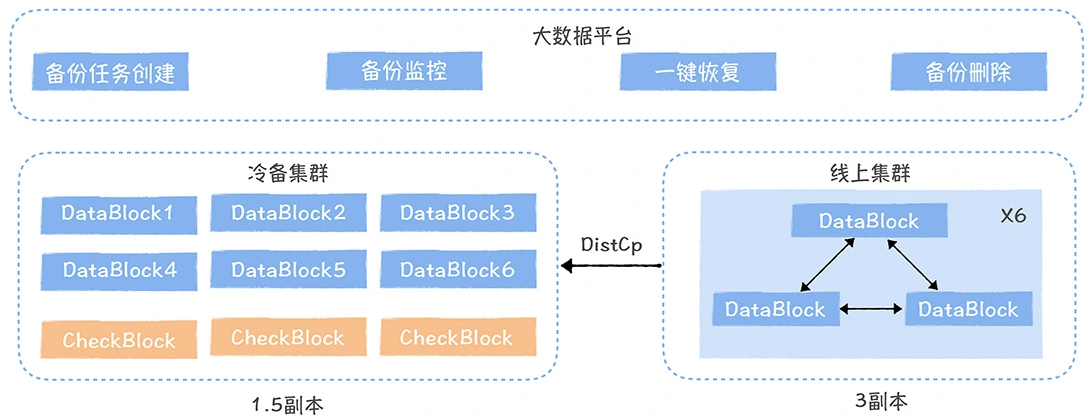
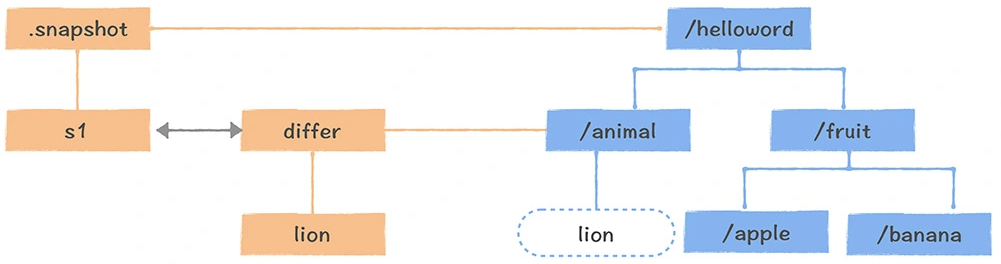
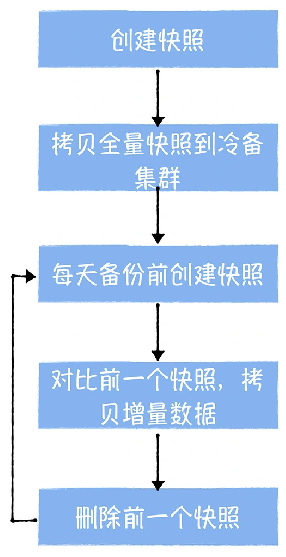
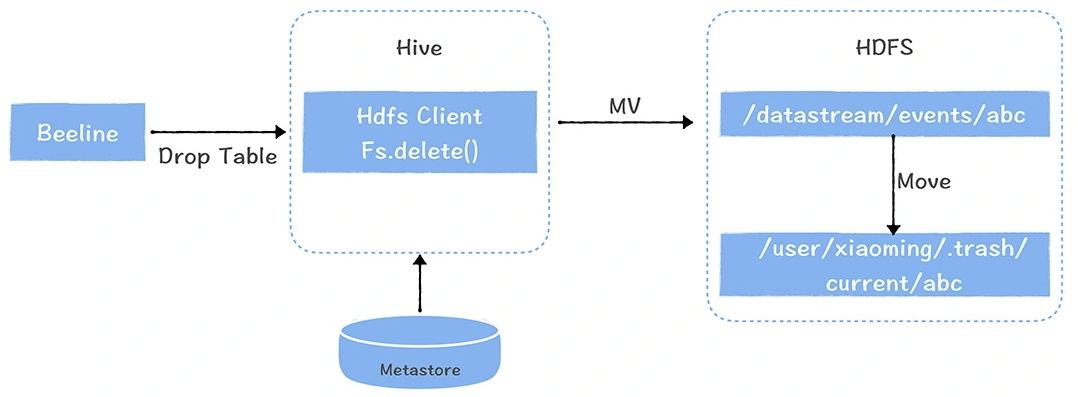
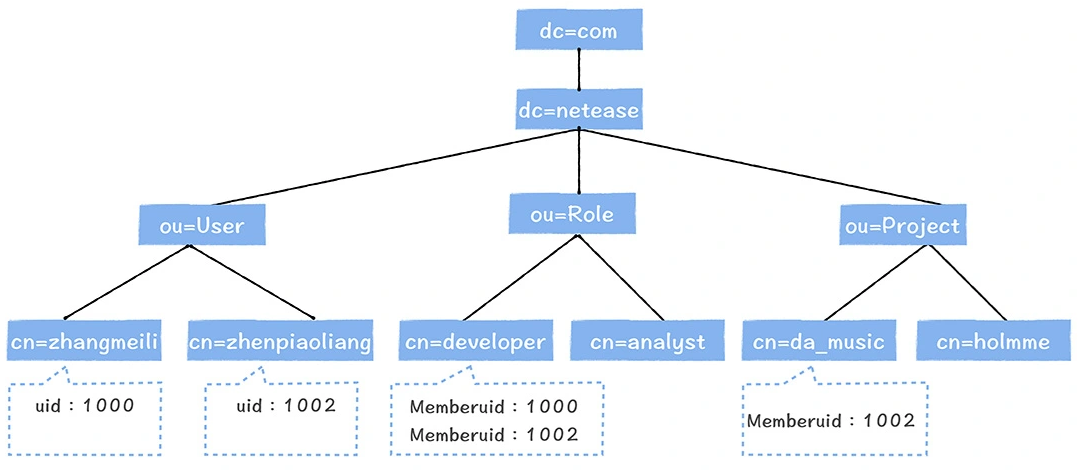
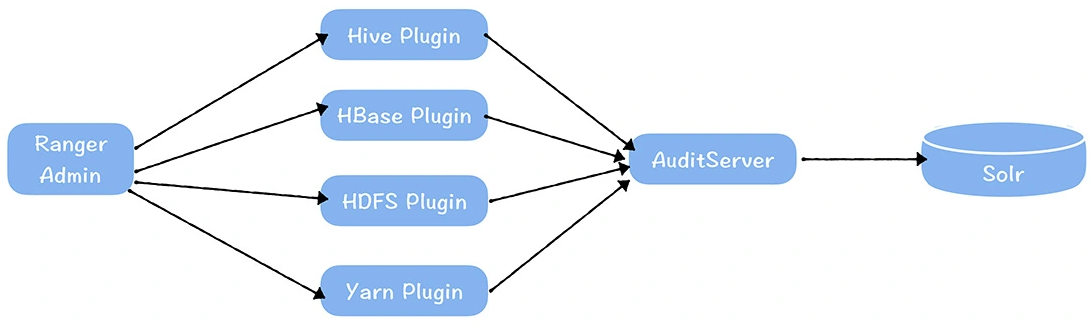
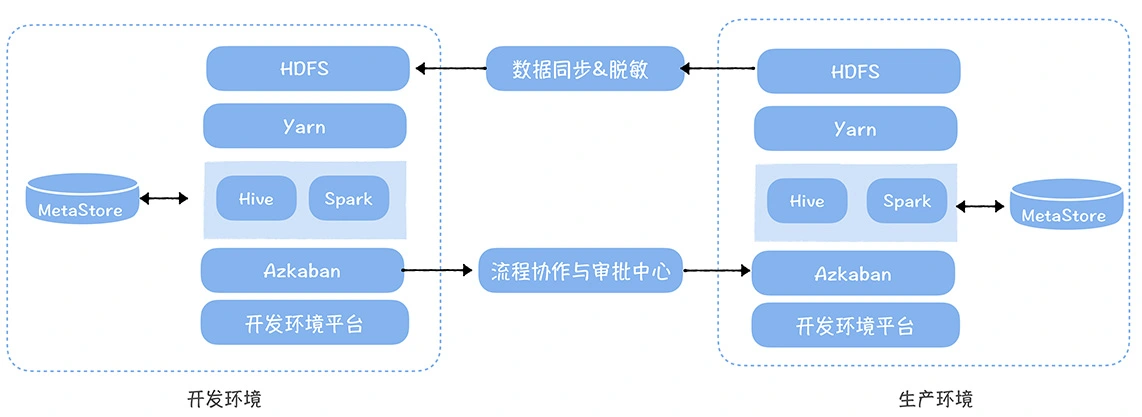
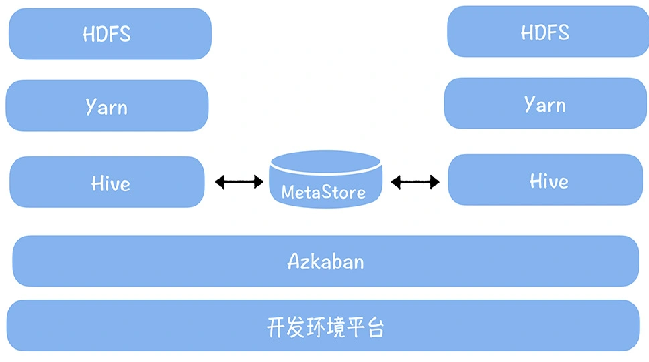
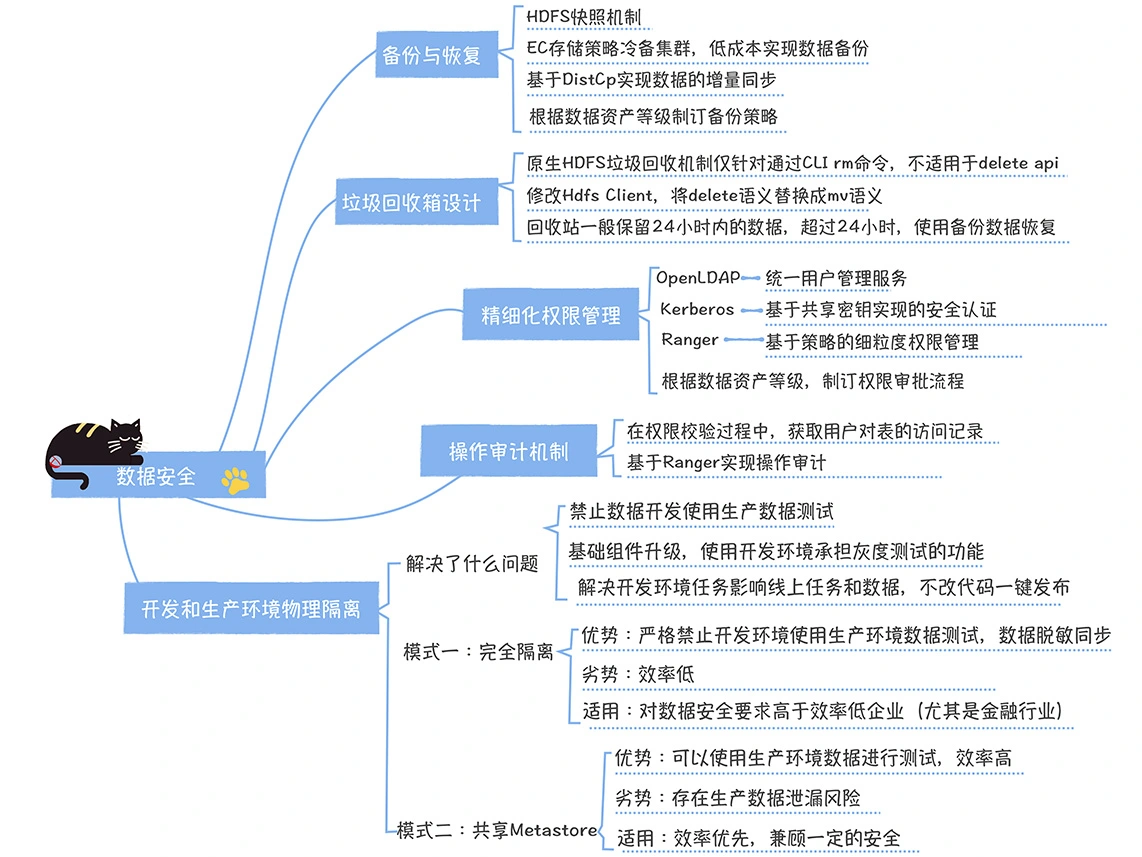
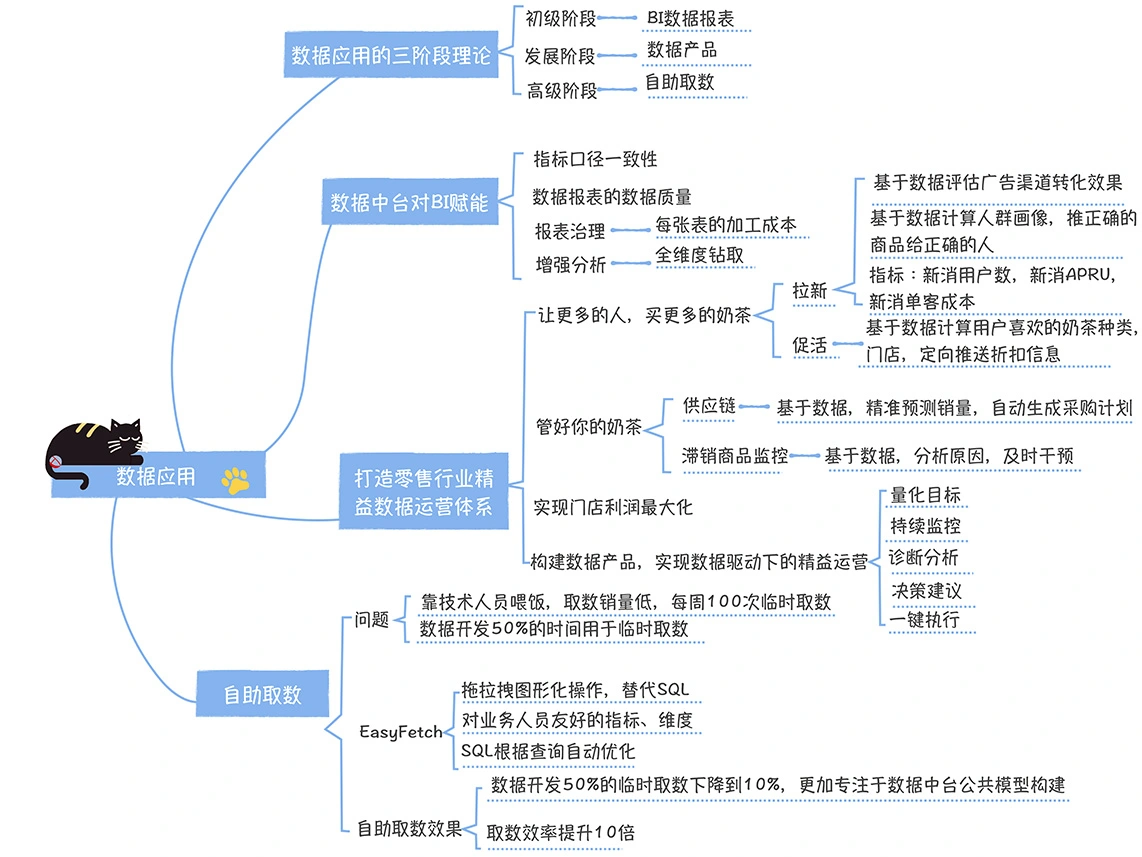
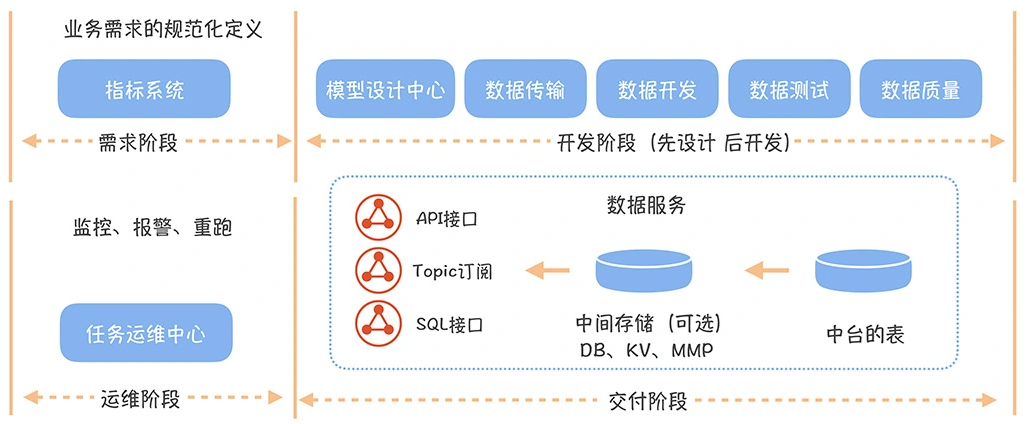
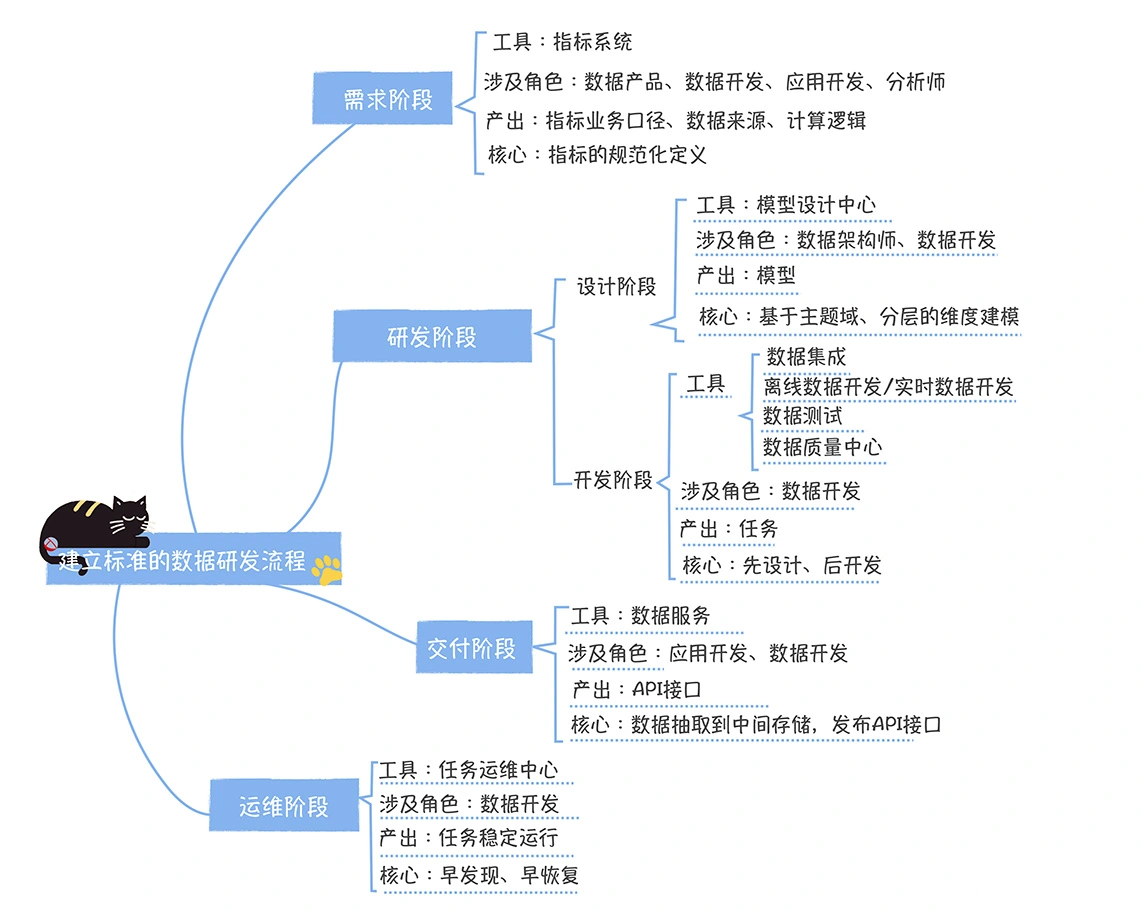
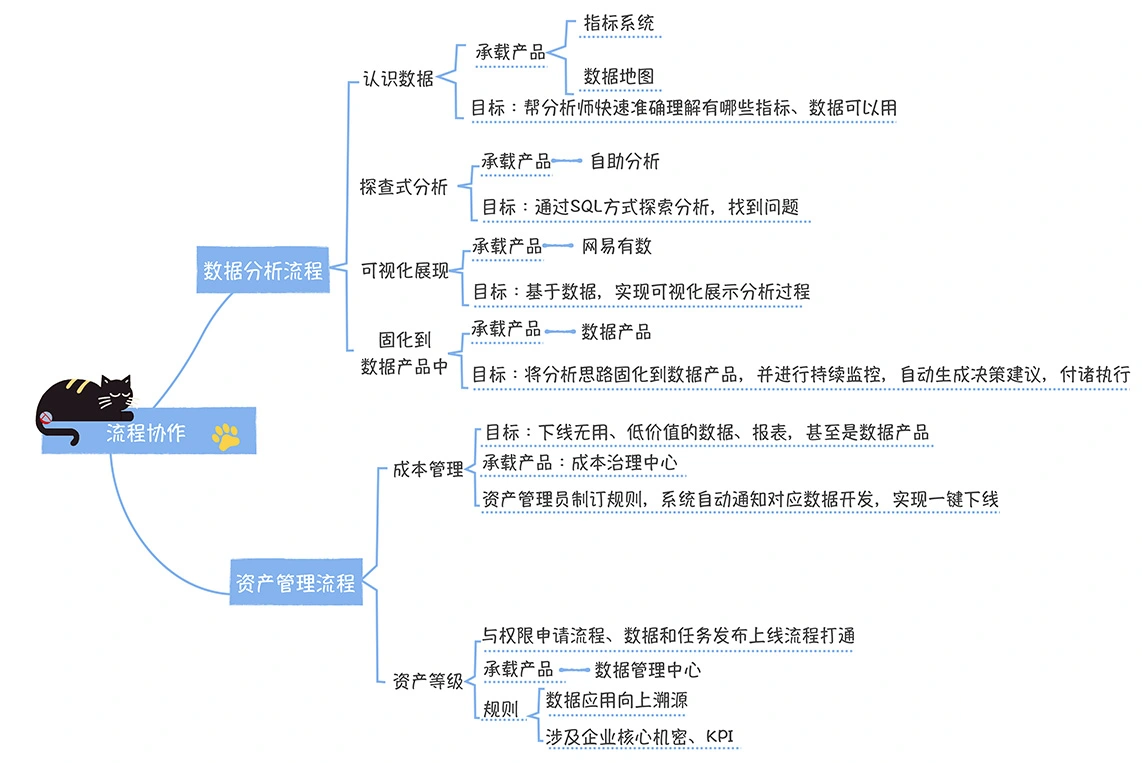
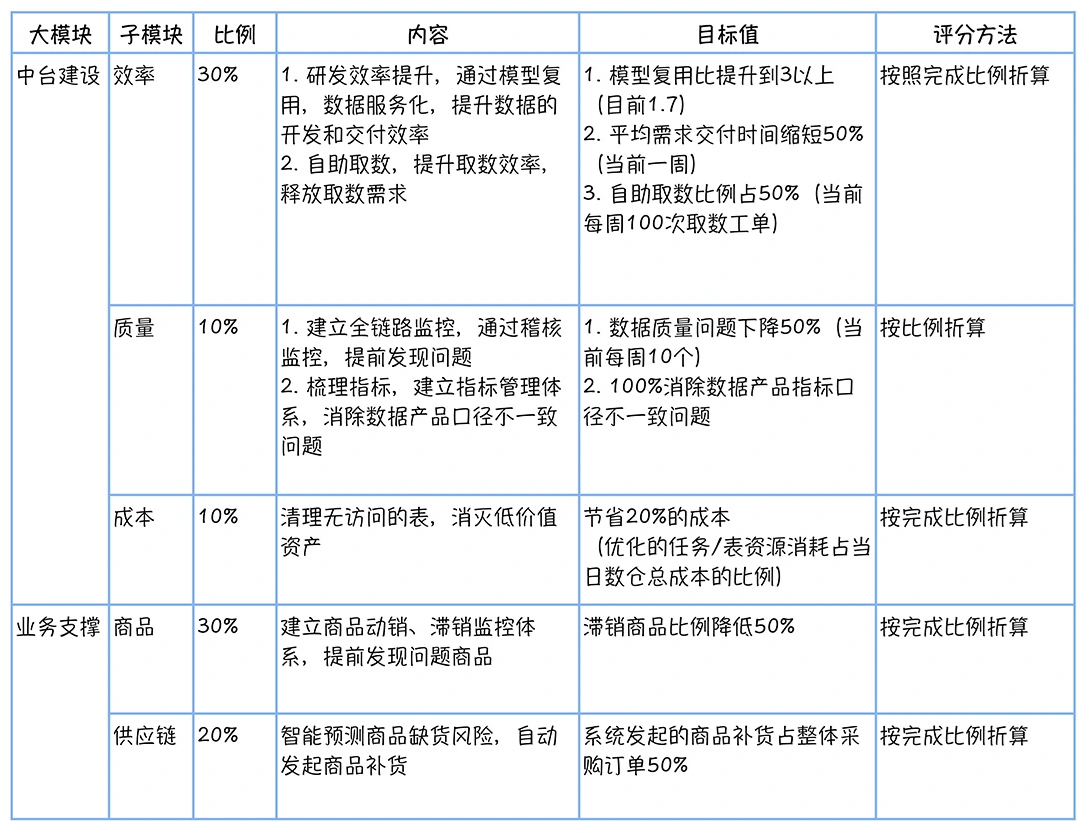
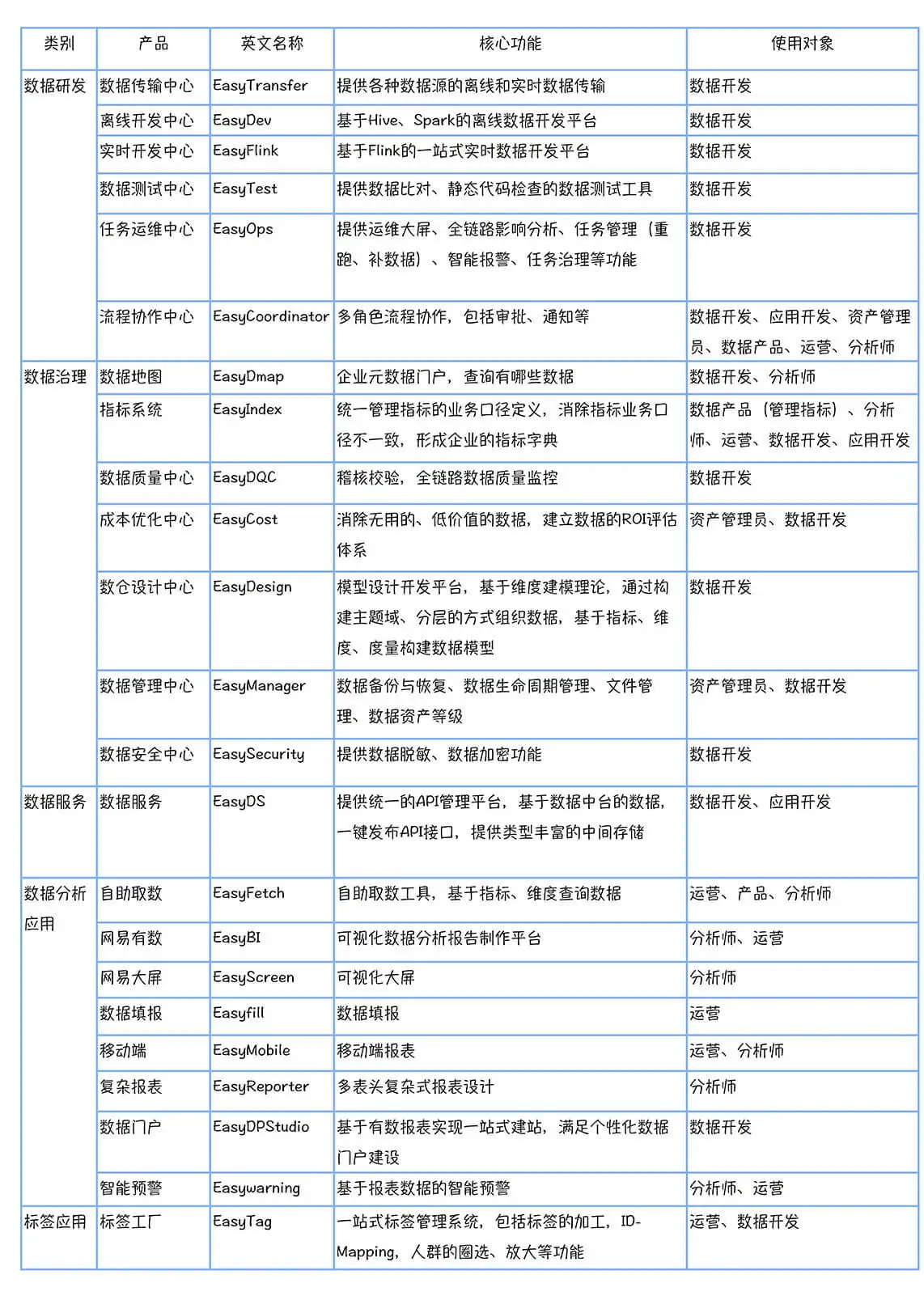
数仓时代、大数据出现、大数据平台、数据中台。自顶向下建模、自底向上建模。大数据平台问题:1、指标口径不一致;2、数据重复建设;3、取数难;4、数据质量差;5、成本高;数据中台:OneData、OneService,基于大数据平台,增加数据治理能。其中元数据中心是关键(数据字典、数据血缘、数据特征)。 数据指标:口径不一致,描述错误/不清晰/难以理解/计算逻辑不清晰;面向主题域管理、原子和派生指标、规范命名。数据模型复用:DWD跨层引用,DWS/ADS/DM 汇总查询比列,接管ODS,划分主题域,构建一致性维度、事实表整合、ETL开发。数据质量:添加稽核任务、全链路监控、智能预警、质量打分、SLA。成本治理:全局资产盘点、发现问题、治理优化(无用的下线、高消耗查询、存储成本)、治理效果评估。 数据服务:提供统一接口、解决数据接入效率低、数据和接口无法复用、不知道数据被哪些应用访问;具备网关能力,全链路打通,利用中间存储加速查询,逻辑模型嵌套底层多个物理数据源。 数据安全:HDFS快照+备份;垃圾箱、权限管理:OpenLDAP + Kerberos + Ranger,两套环境物理隔离 or 复用底层设施 + 共享 meta-store。 实践: BI 赋能、打通行业的运营体系、自助取数; 研发流程:需求阶段、开发阶段、交付阶段、运维阶段。 中台建设:数据中台和业务的关系,就是鱼和水的关系,谁也离不开谁;业务想要获得更大的增长,就必须依赖数据中台,数据中台想要存活下去,就必须依赖业务的口碑和认可
阅读全文
2024年10月26日
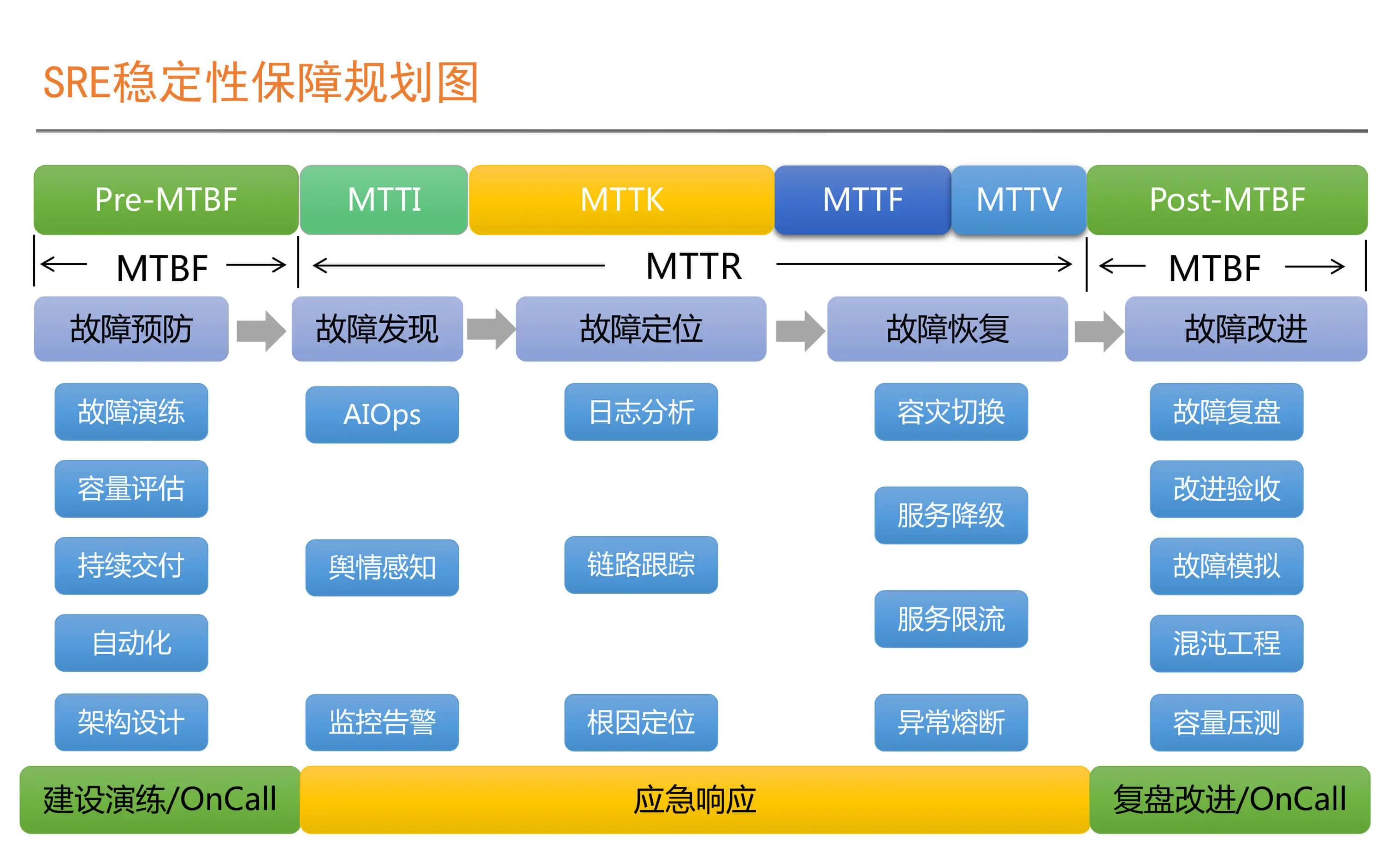
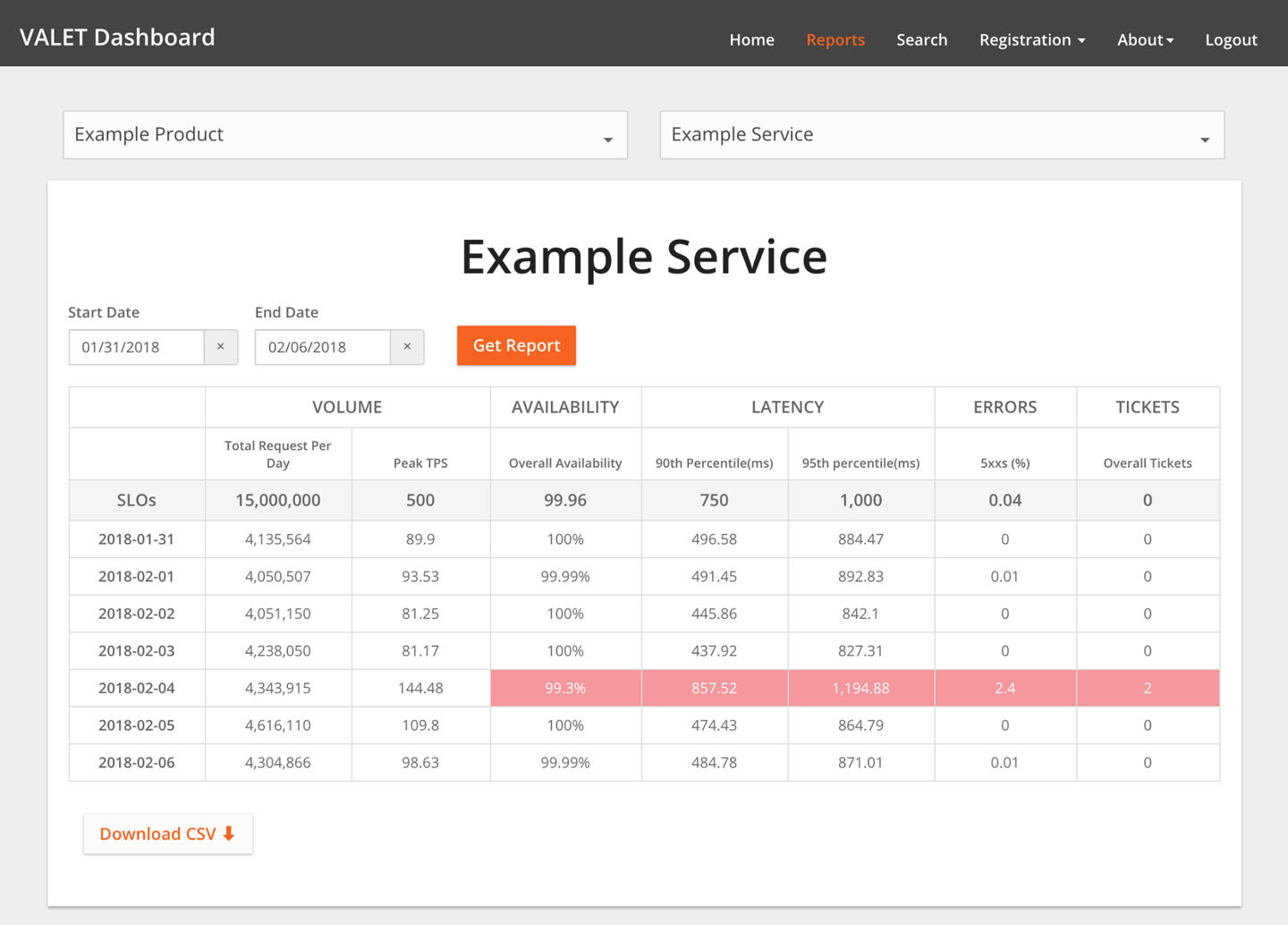
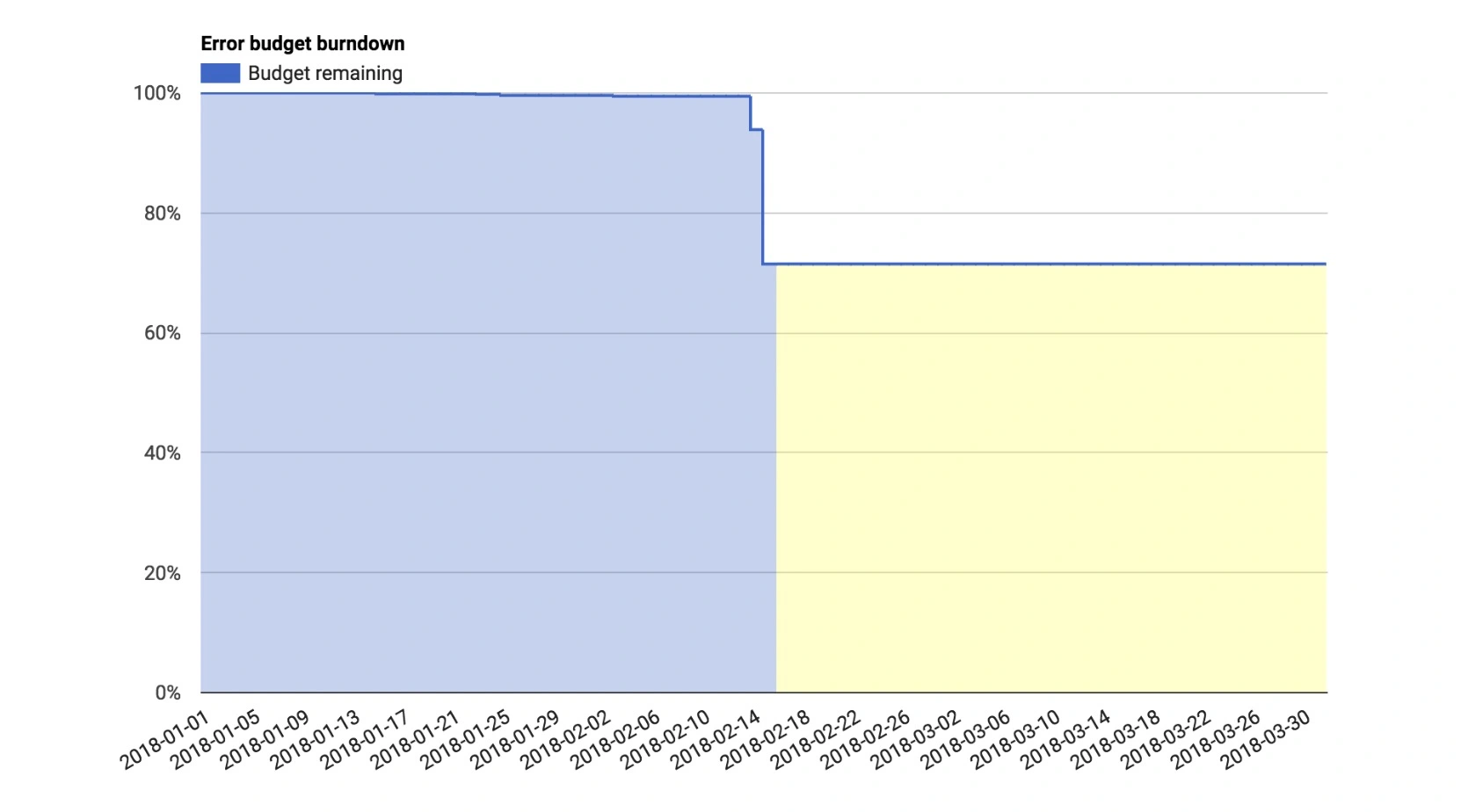
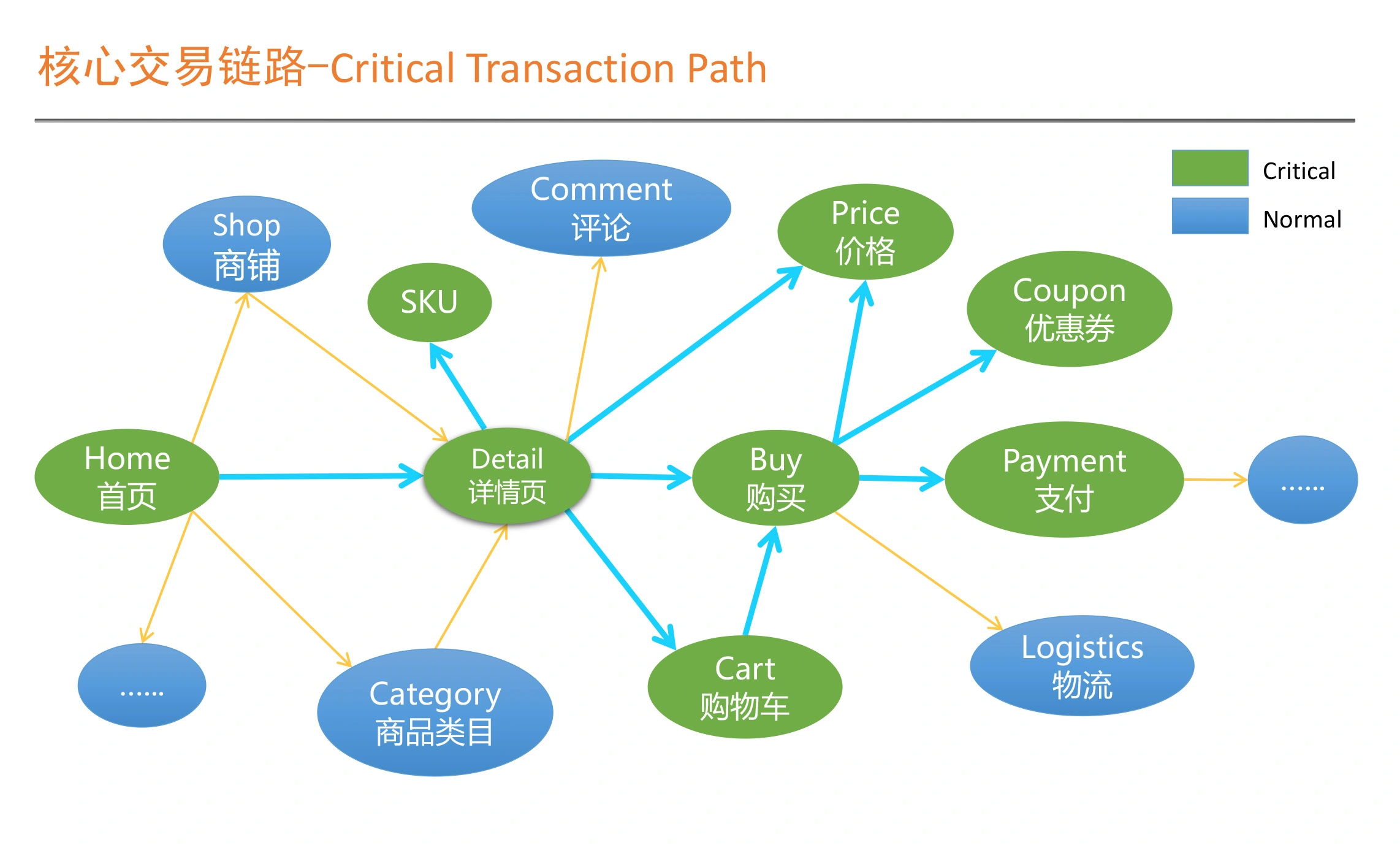
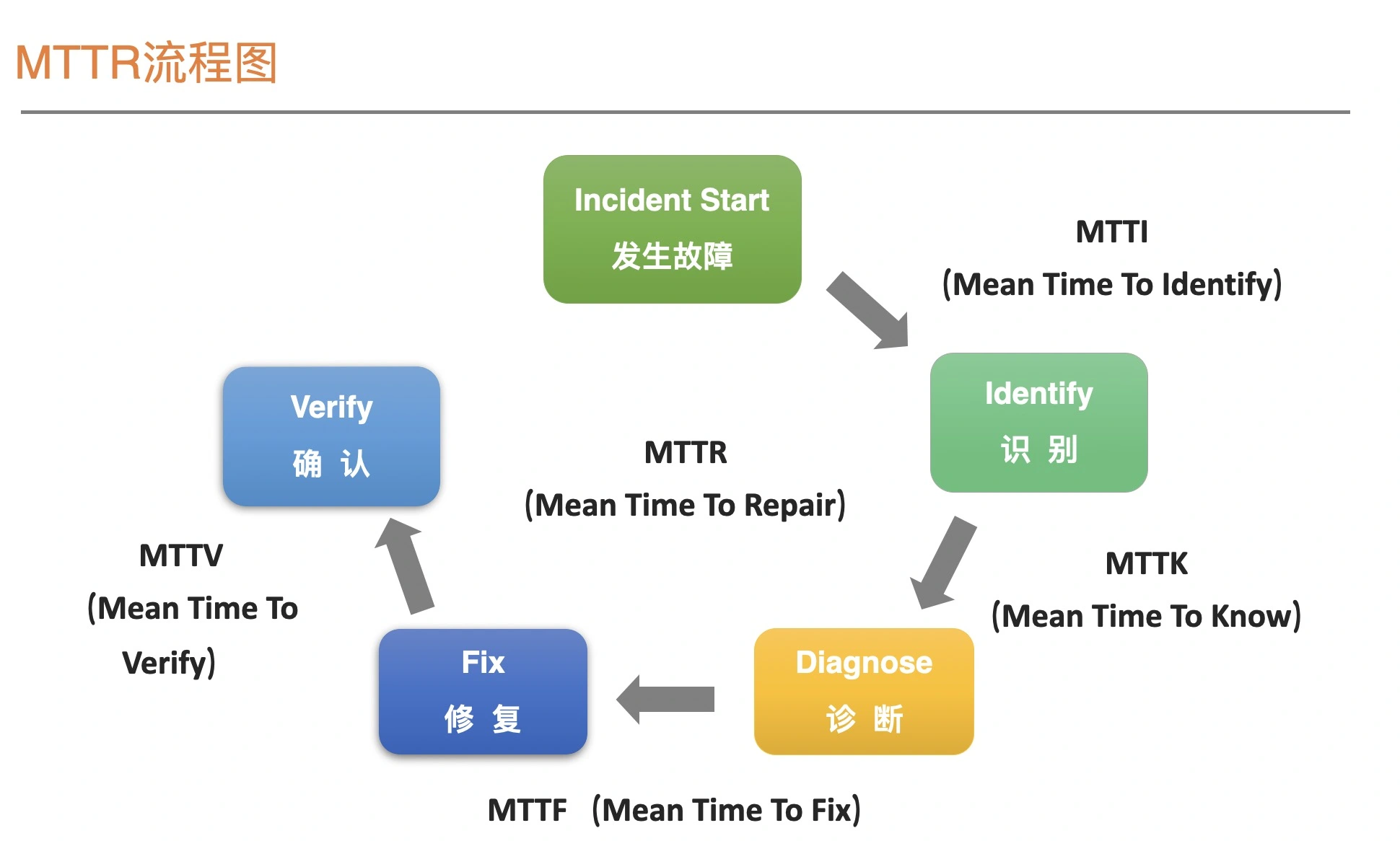
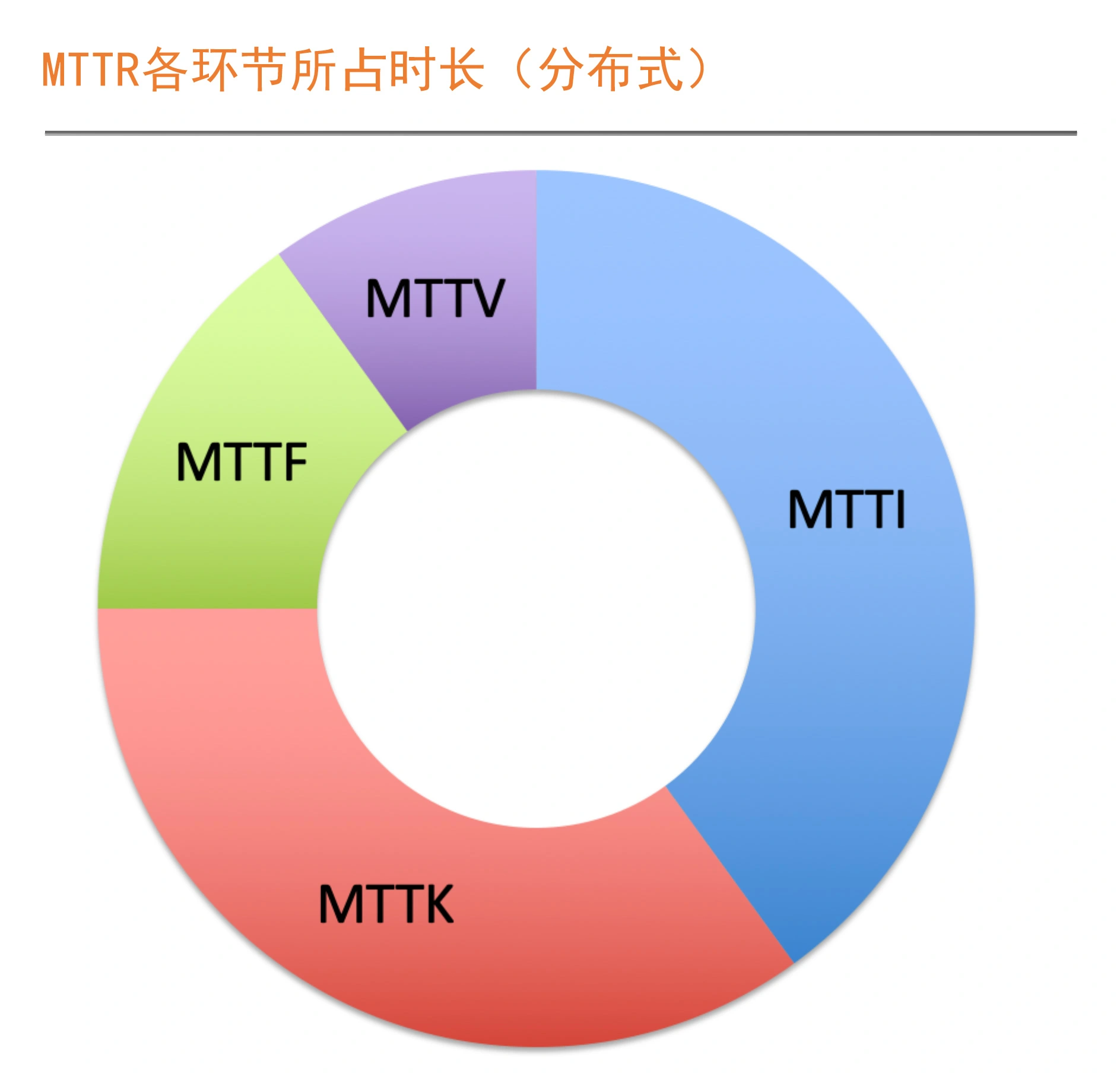
SRE是一个体系化工程,包括Pre-MTBF,MTTR(MTTI,MTTK,MTTF,MTTV),Post-MTBF;衡量标准包括:故障时间维度,请求维度,SLI 监控的指标、SLO 指标对应的目标;包括系统层面、应用服务器层面、应用运行层面、PaaS层面、数据层面、业务层面;SLI指标方法 VALET volume、Availablity、Latency、Errors、Tickets;错误预算,燃尽图,故障定级;衡量SLO有效性三组指标:达成情况、人肉投入程度、用户满意度。落地SLO 包括确认核心交易链路、确认强弱依赖关系,核心链路要求更严格、弱依赖需要降级,核心依赖共享Error Budget,验证 核心链路 SLO包括:容量压测、混沌工程。 实践,on-call机制,也就是确认 MTTI部分;故障处理,角色分工,故障排查中定期汇报,问题扩大需要运营侧公开反馈。故障复盘:故障原因?怎样保证不出现类似问题?怎样短时间恢复业务?互联网的SRE组织架构,根据分布式架构慢慢推动演化了组织架构。以赛带练
阅读全文
2024年10月23日
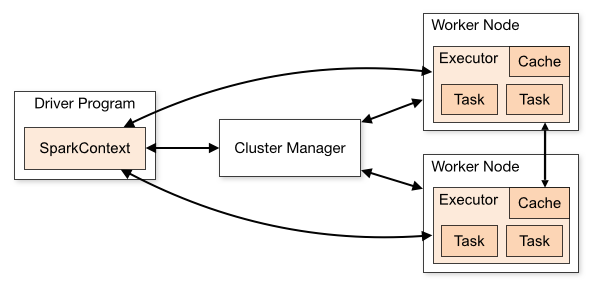
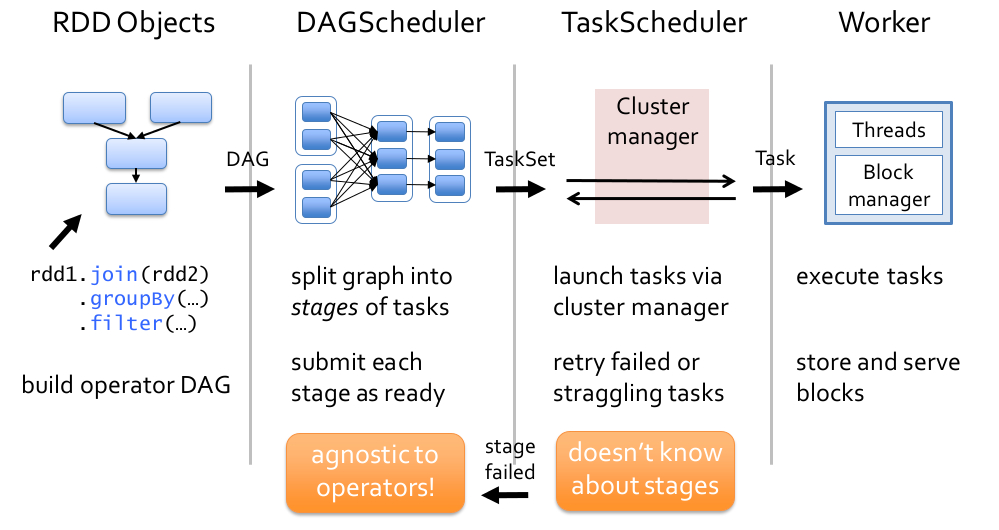
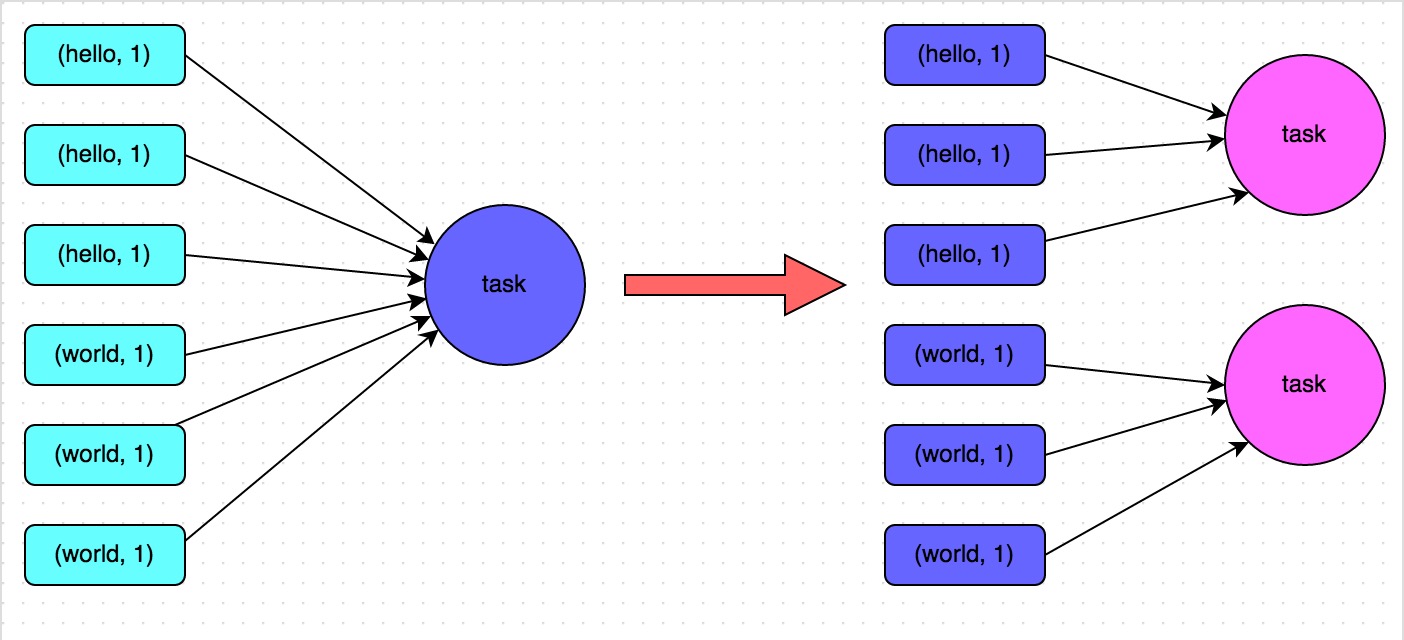
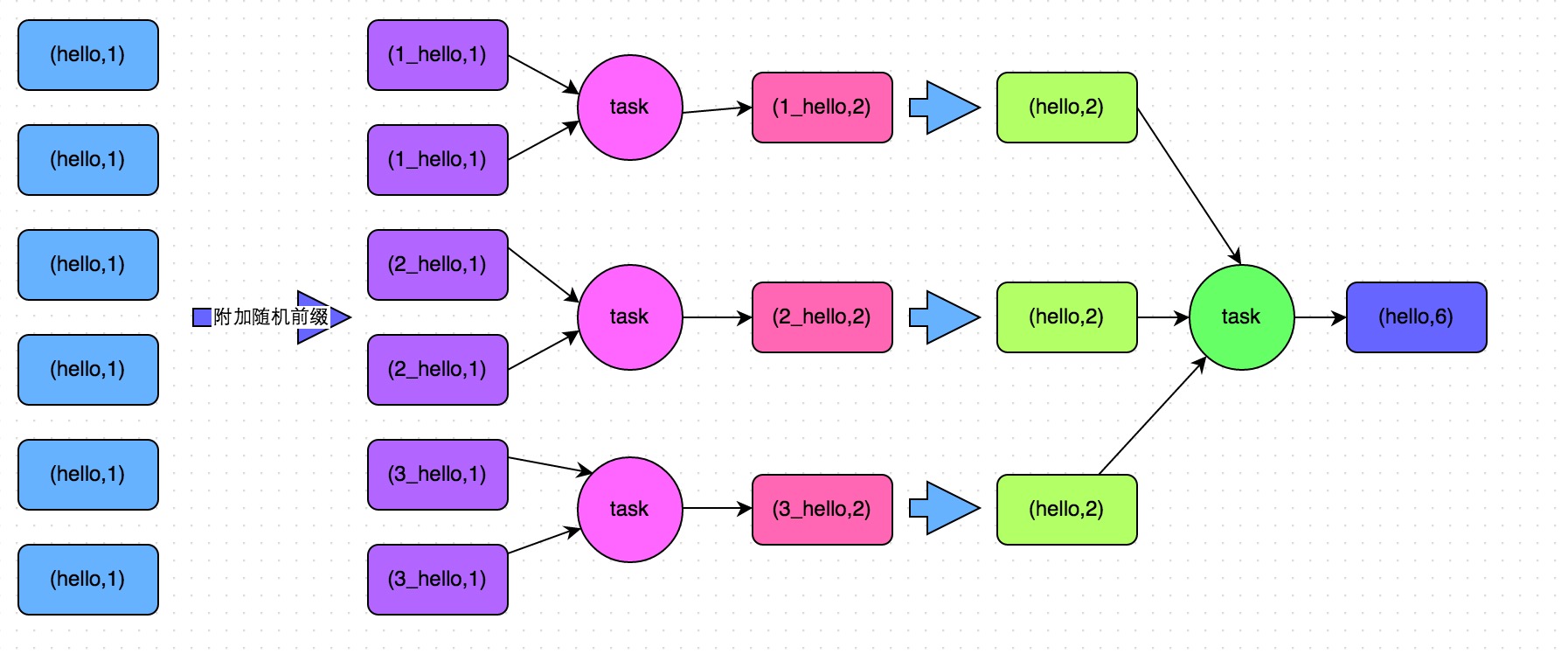
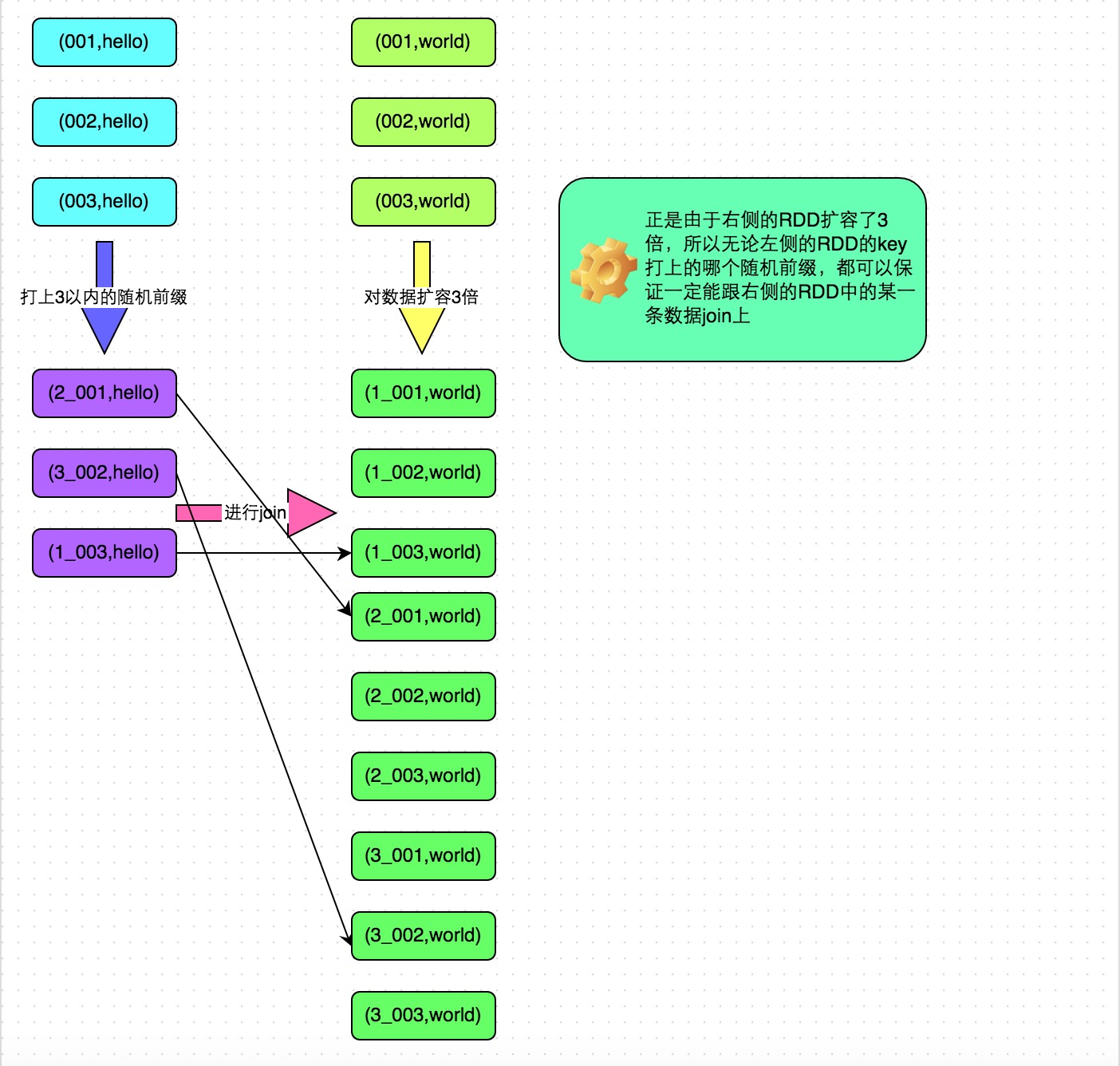
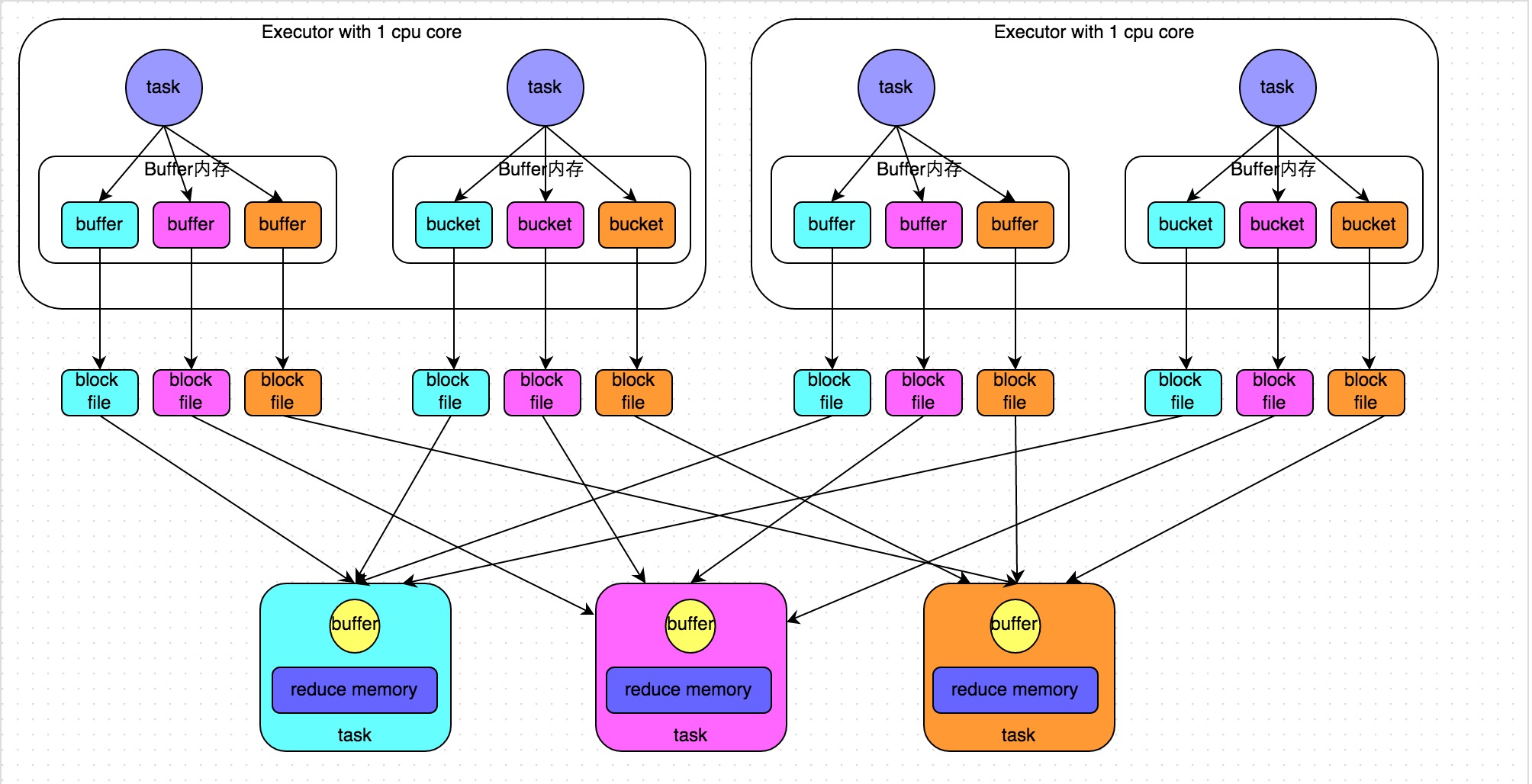
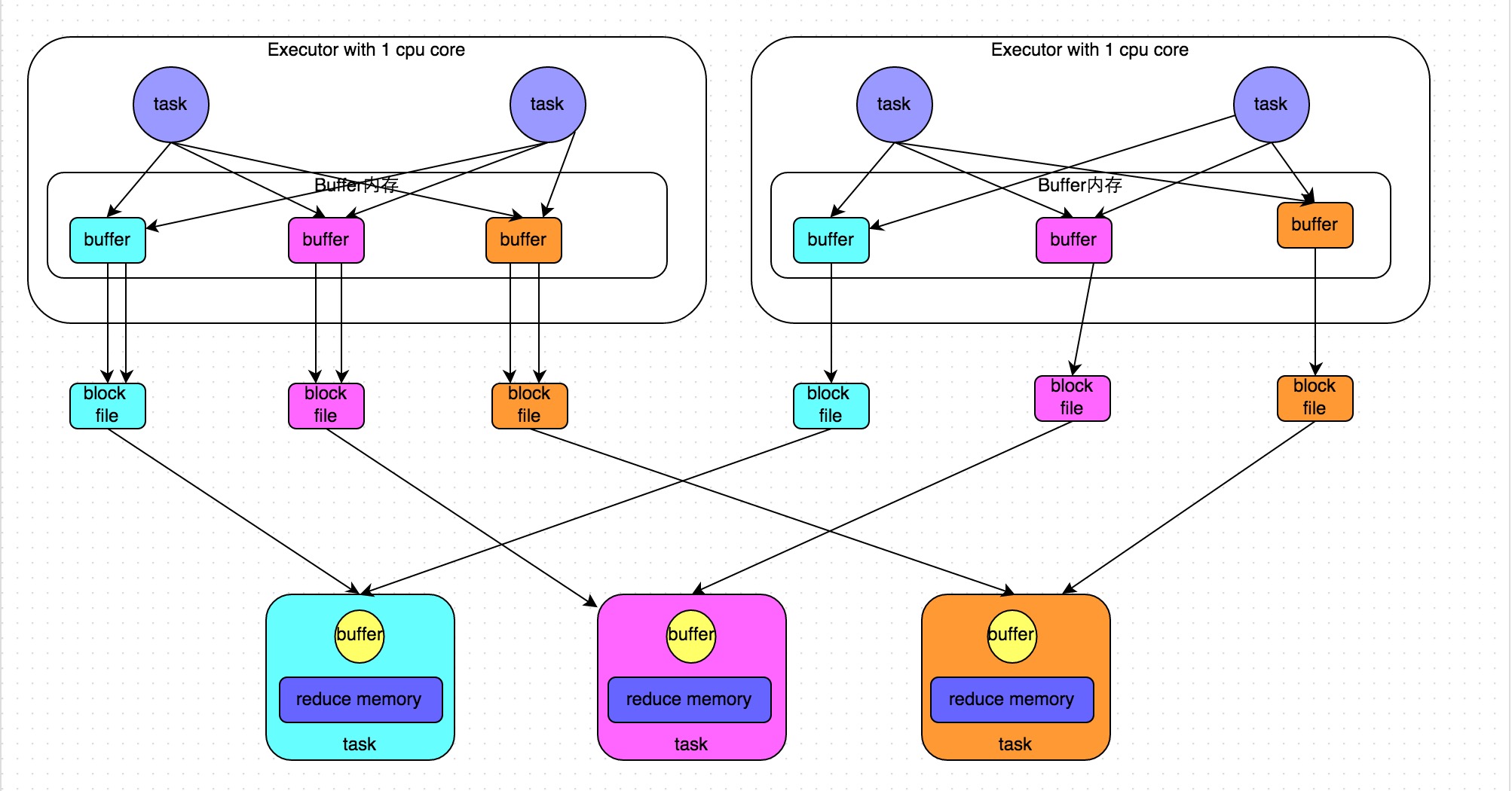
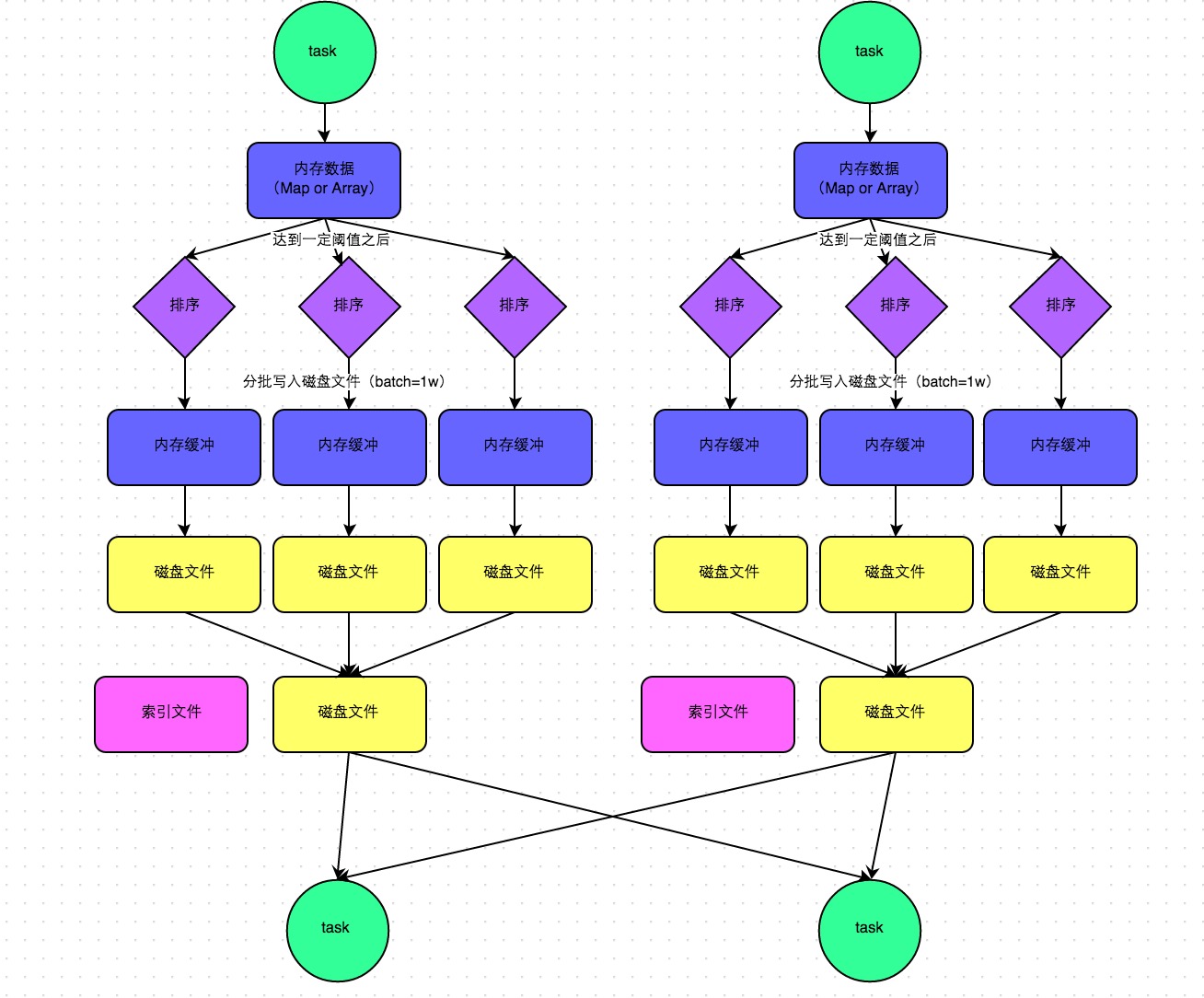
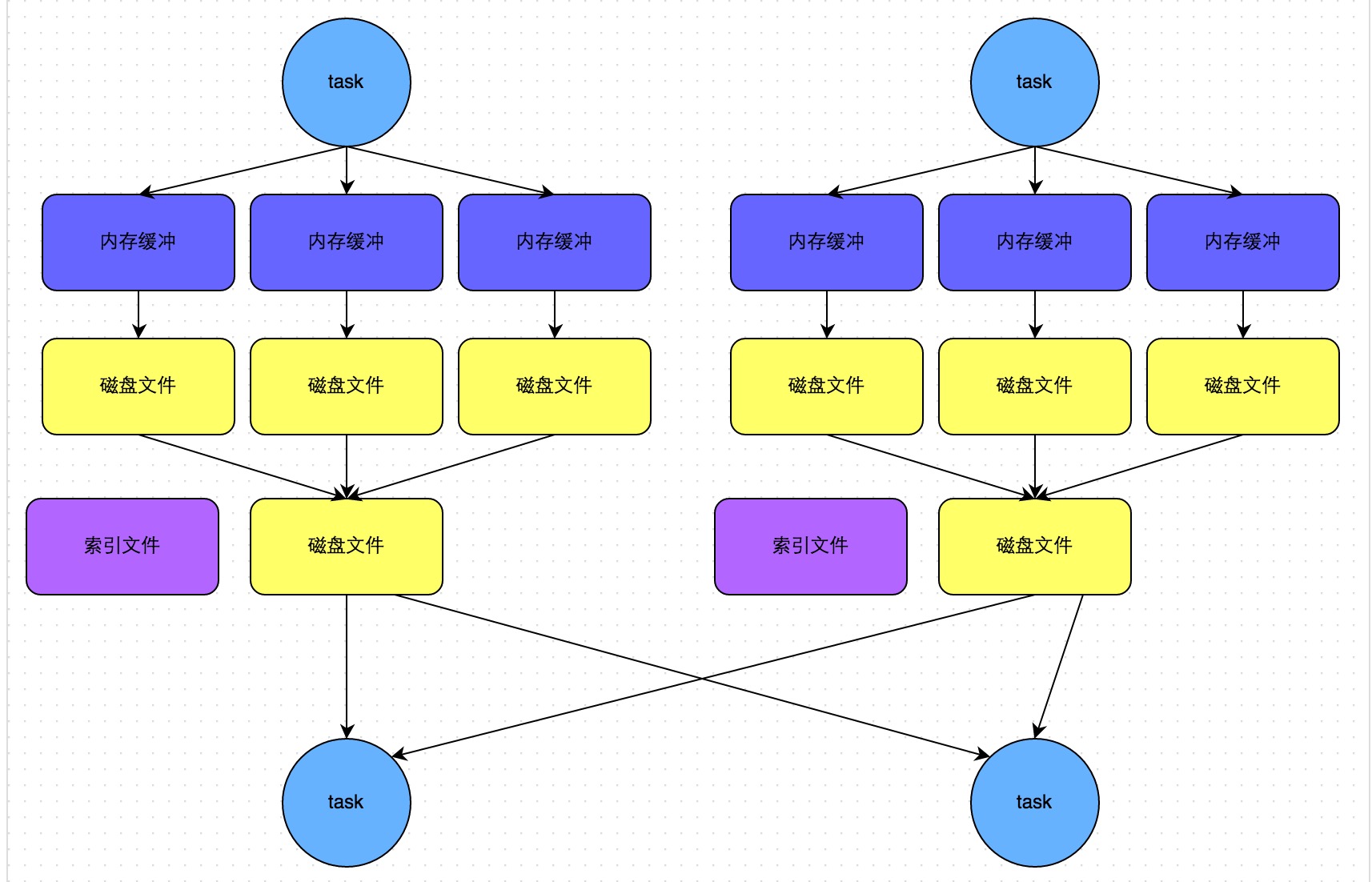
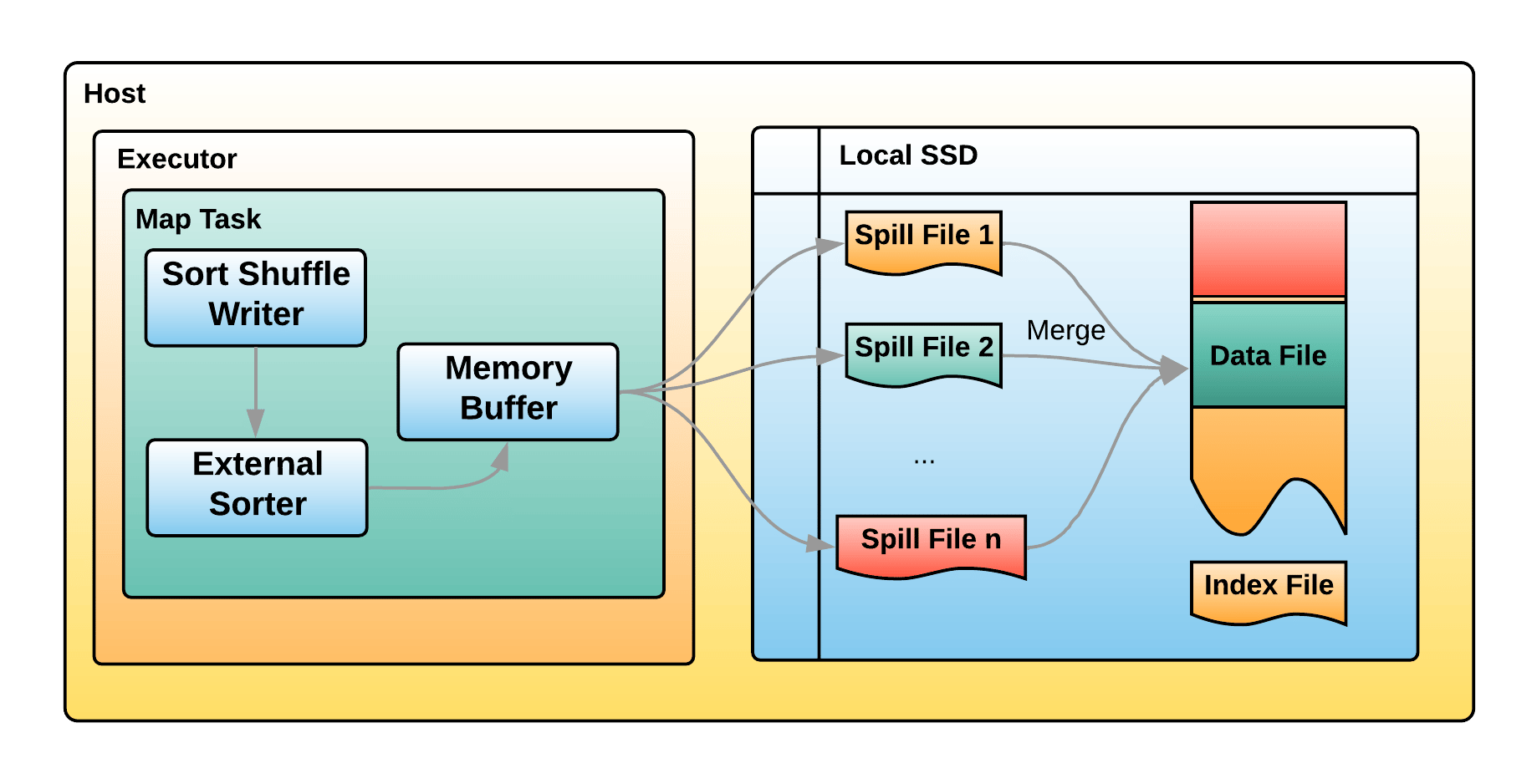
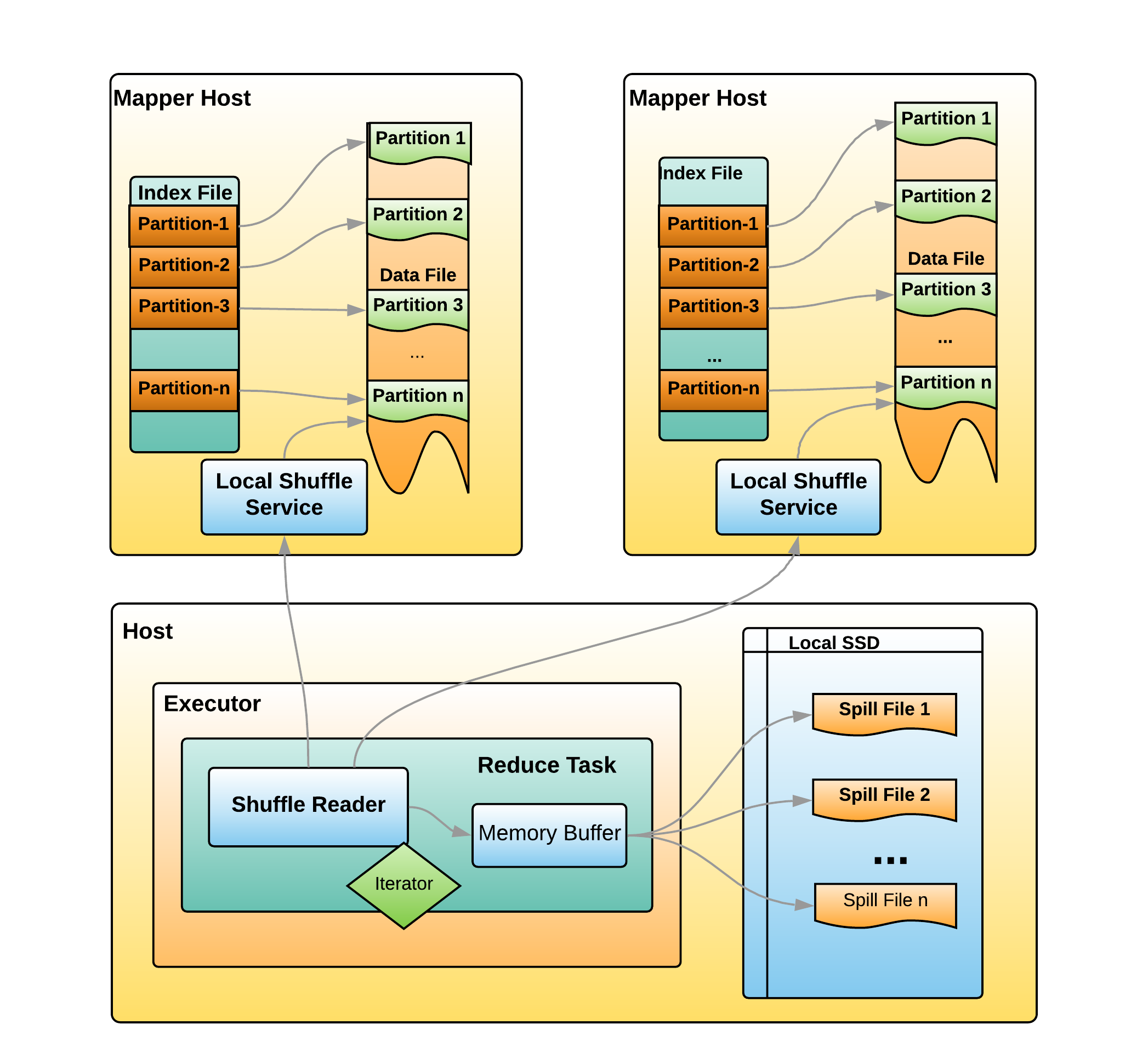
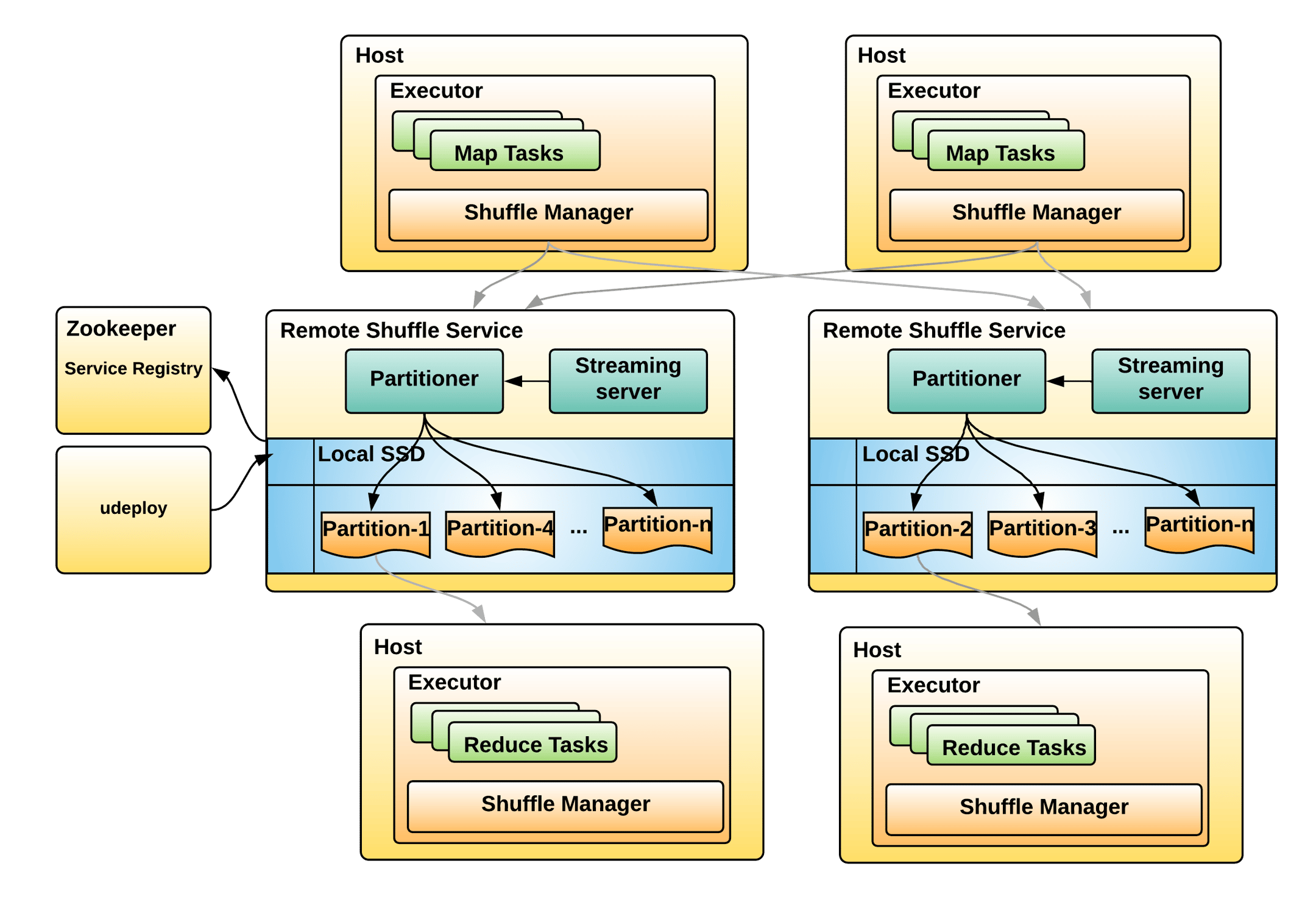
web-ui观察 executor指标:失败,shuffle,cache,CPU,内存,RDD数量,GC;stage关注 DAG,也是shuffle等数据,还有 Event Timeline。shuffle优化方式:增加并行度,group by变成局部聚合+全局聚合;转为 BHJ,大表 join 大表的 外表加盐,内表复制N份,再去盐gourp原始id,最后聚合;shuffle原理,HashShuffleManager(废除),SortShuffleManager。 with 缓存优化,查询下推,自动倾斜join优化,LIMIT大数量优化,bucked join,4表join转为2个2个join增加并行度。RSS,向量化, AQE
阅读全文
2024年10月22日
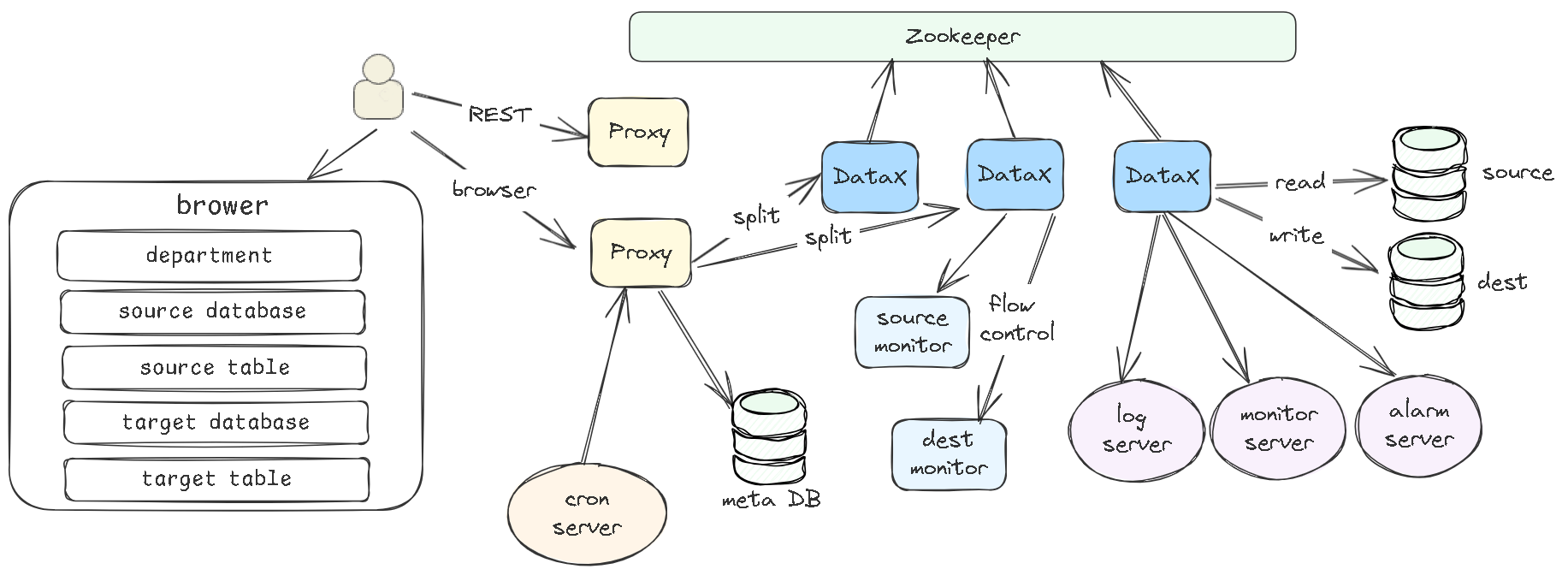
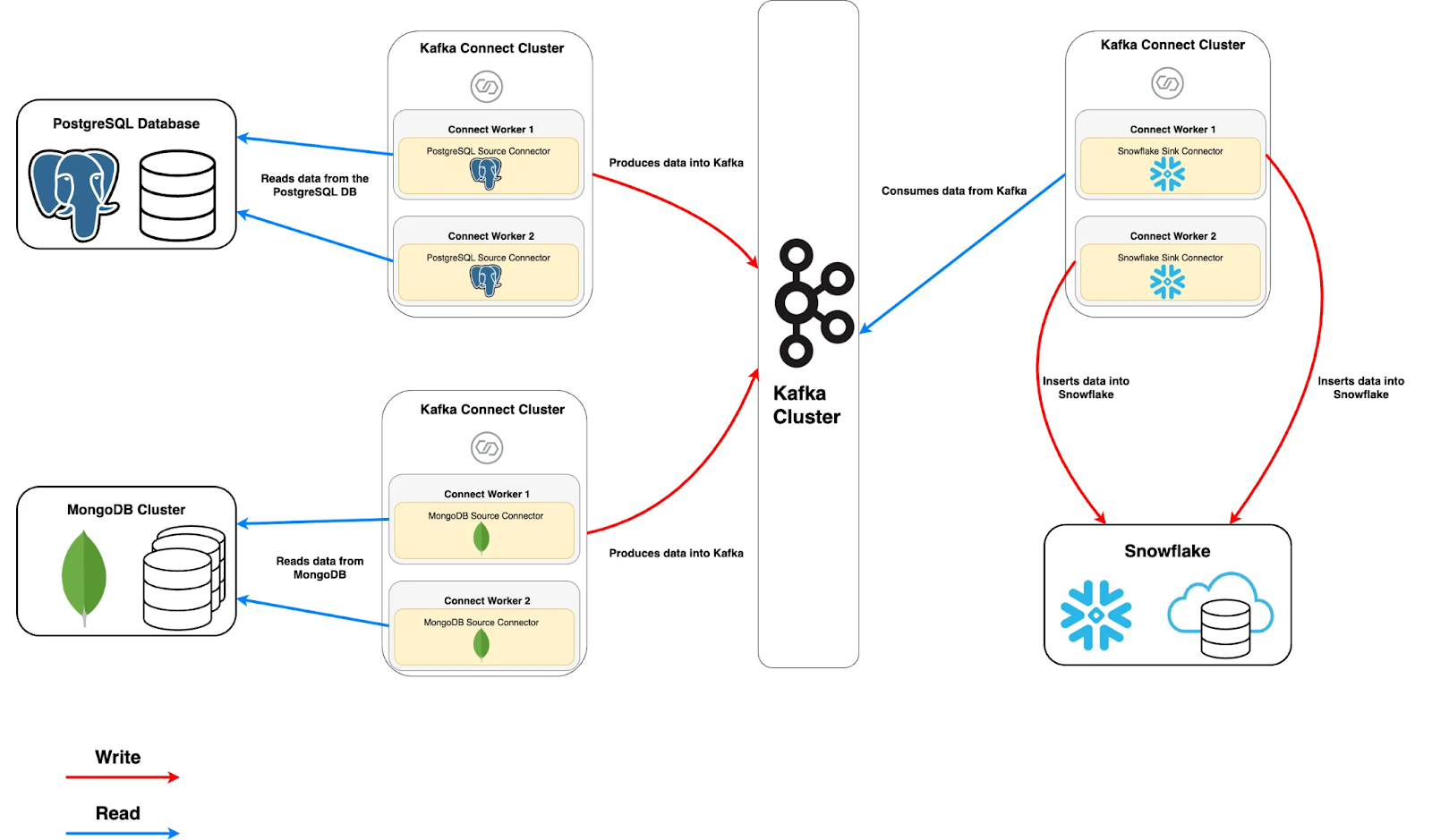
DataX:读写插件,Job任务拆分,Task和Task Group,transform(filter,substr,replace,可自定义),流控,脏数据,数据库冥等写入,ETL架构。Canal:Server(服务端-客户端模式,嵌入式模式),多个instance,包括:eventParser (数据源接入,模拟slave协议和master进行交互,协议解析)、eventSink (Parser和Store链接器,进行数据过滤,加工,分发的工作)、eventStore (数据存储)、metaManager (增量订阅&消费信息管理器)
阅读全文
2024年10月19日
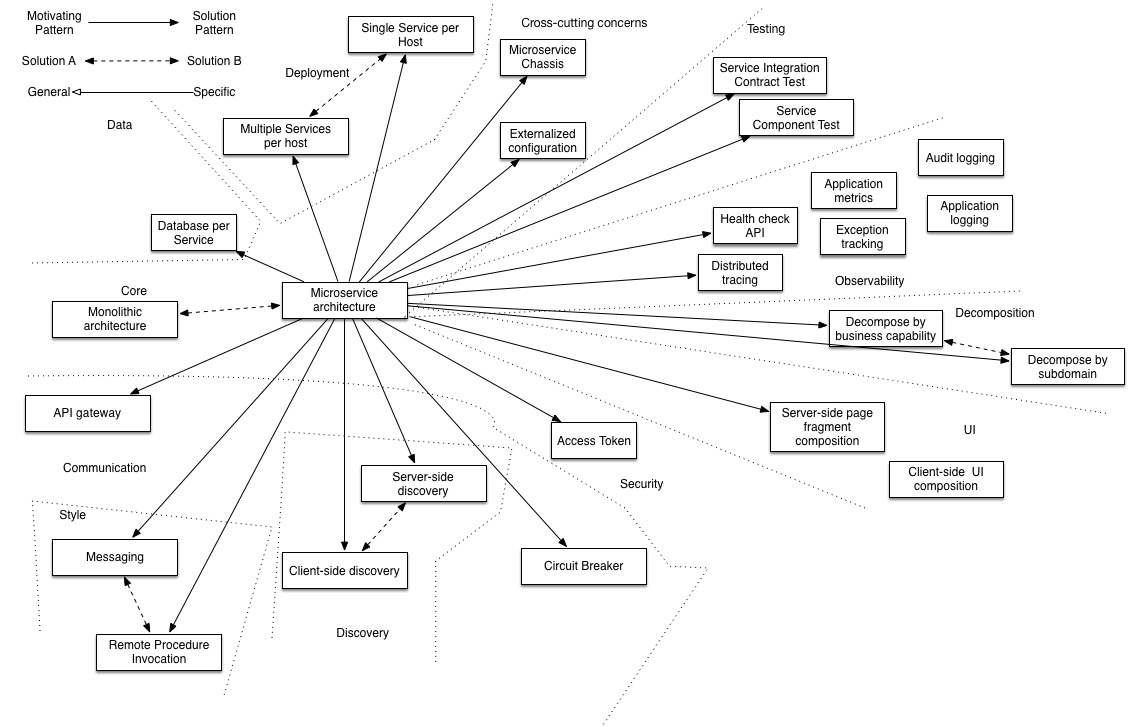
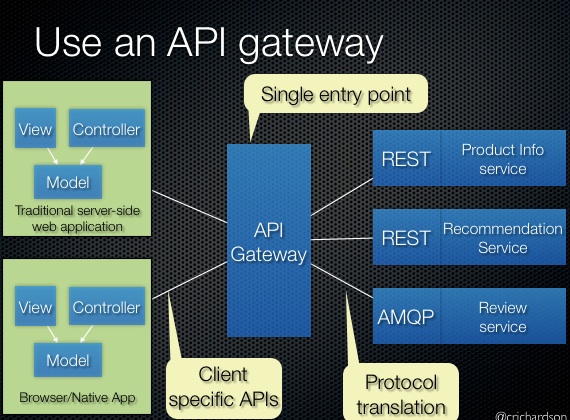
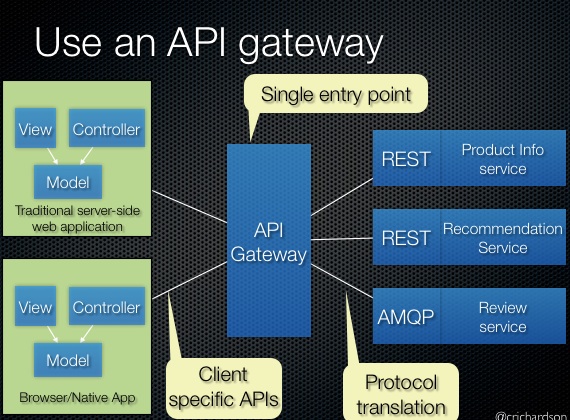
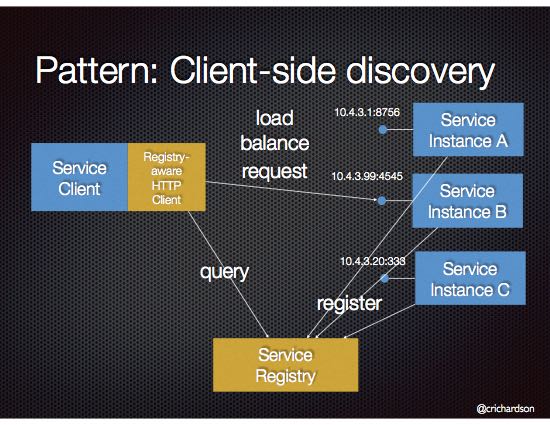
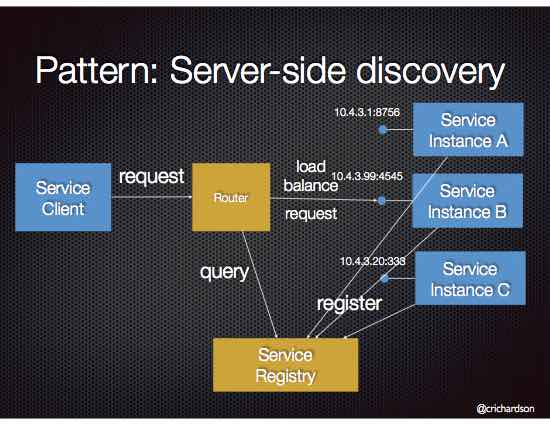
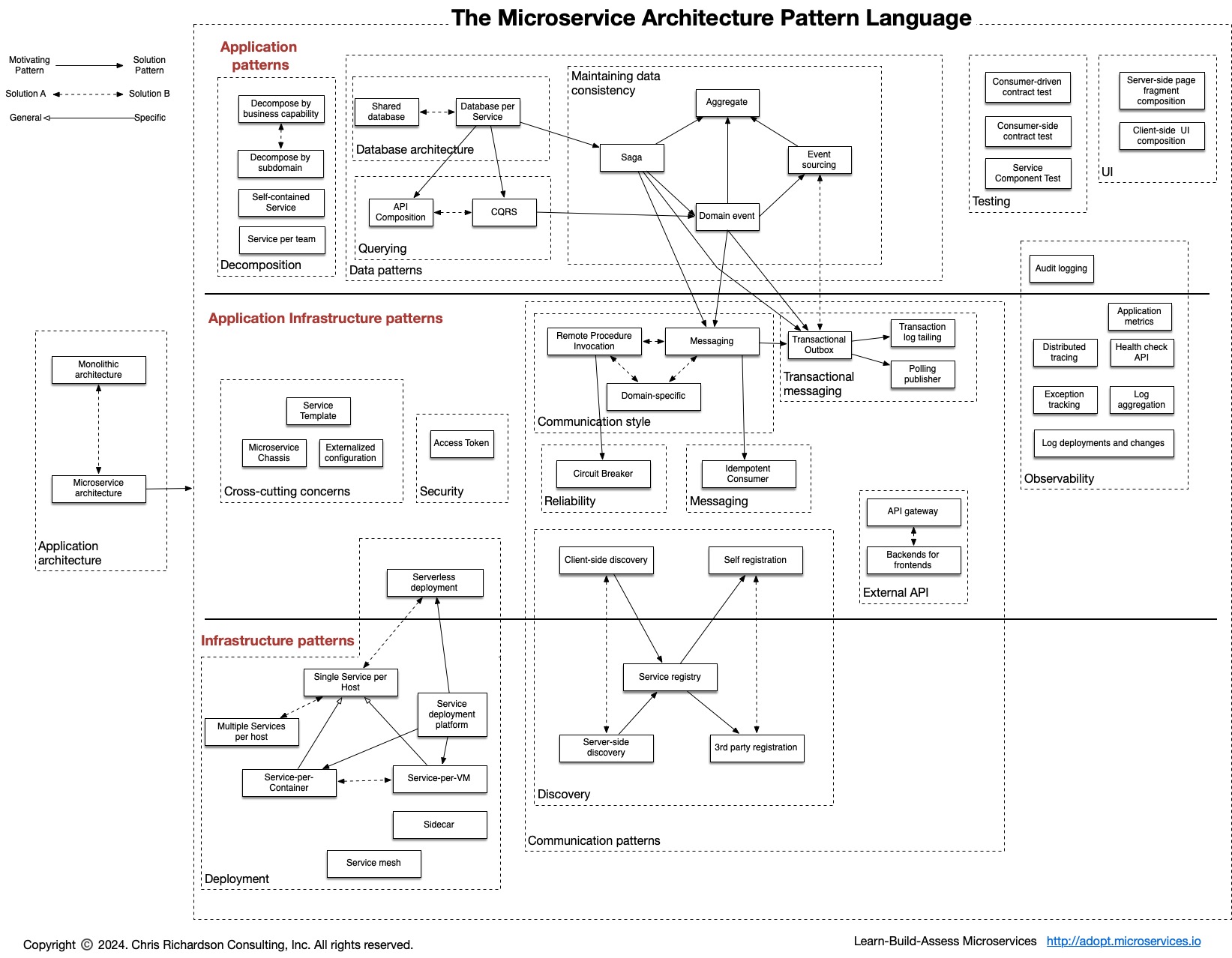
五种暗能量:Simple components、Team autonomy、Fast deployment pipeline、Multiple technology stacks、Segregate by characteristics、;Service collaboration patterns:Saga 模式、CQRS 模式、;Communicate、MessagingAPI composition;一些重要的设计:、Database per Service pattern、API Gateway pattern、Circuit Breaker、Access token。可观测性模式:Log aggregation、Application metrics、Audit logging、Distributed tracing、Exception tracking、Health check API、Log deployments and changes。Testing patterns:Service Component Test、Service Integration Contract Test。UI 模式:Server-side page fragment composition、Client-side UI composition
阅读全文
2024年10月18日
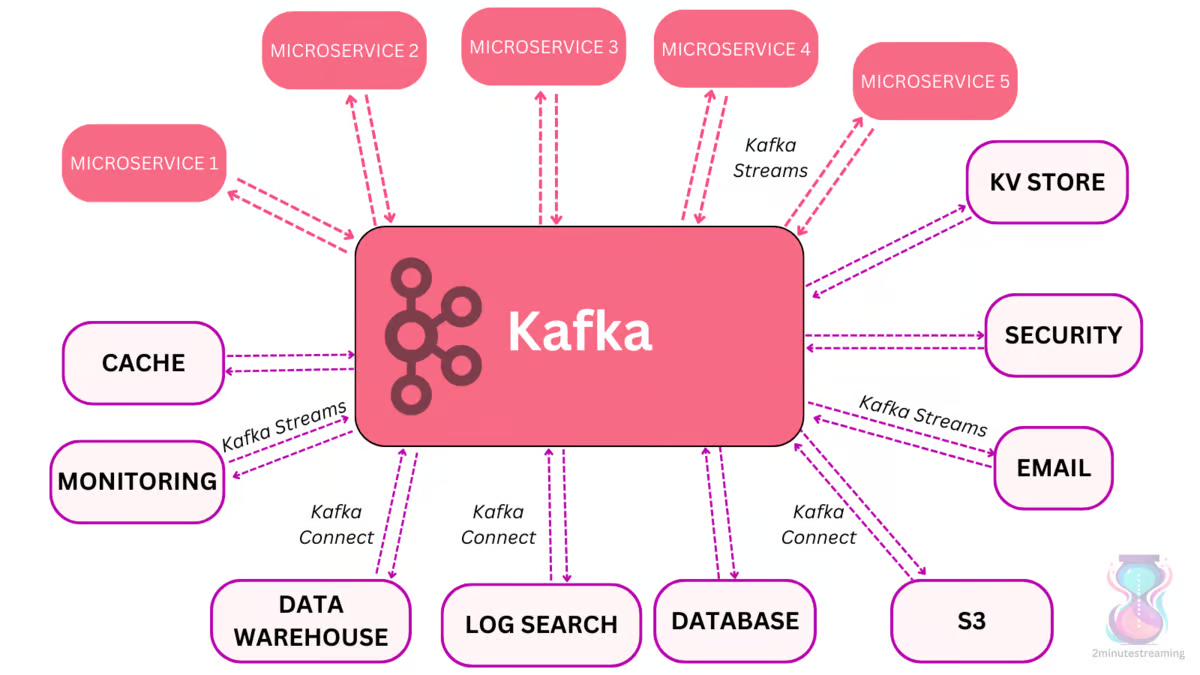
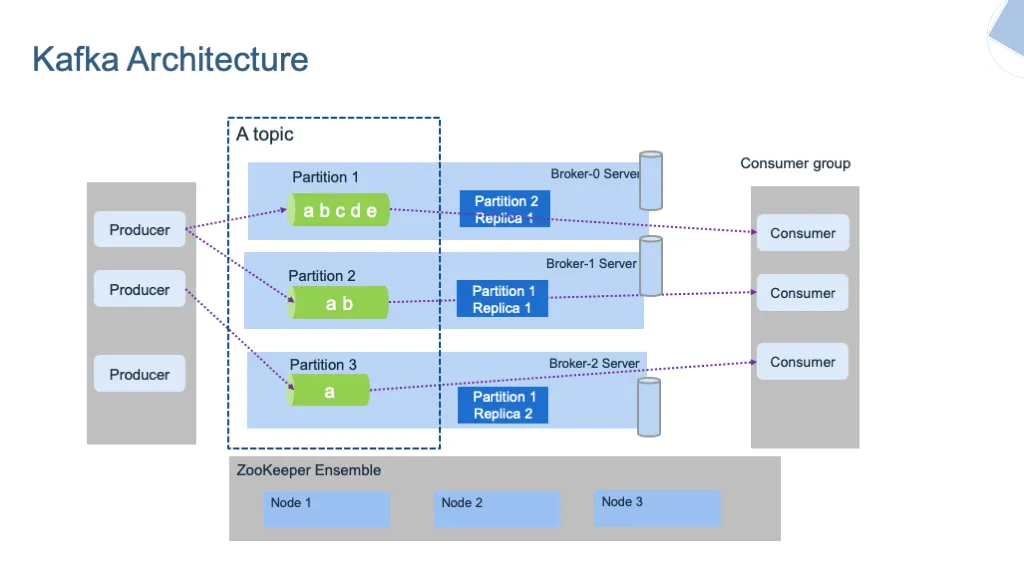
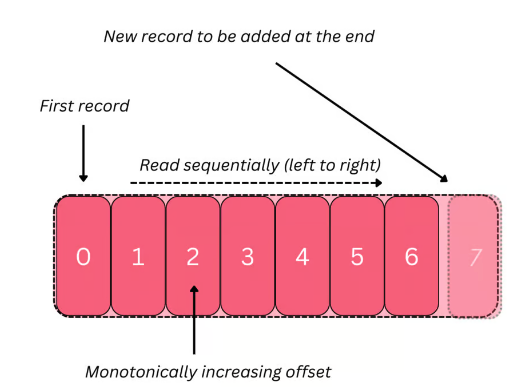
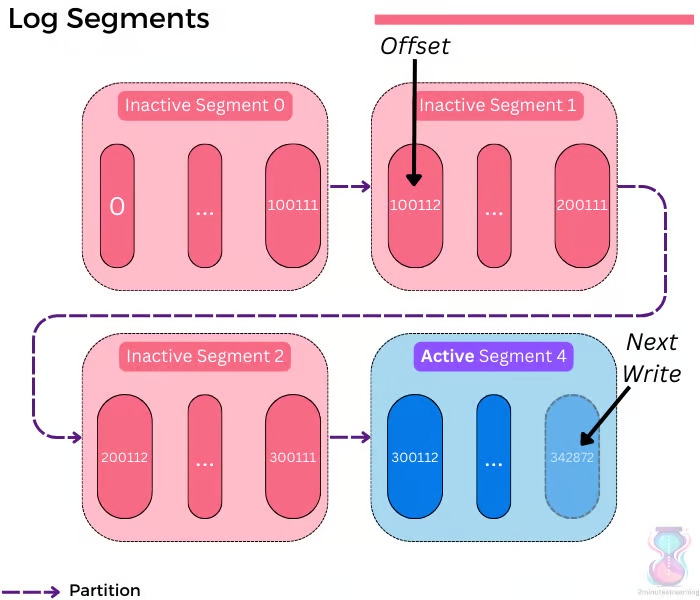
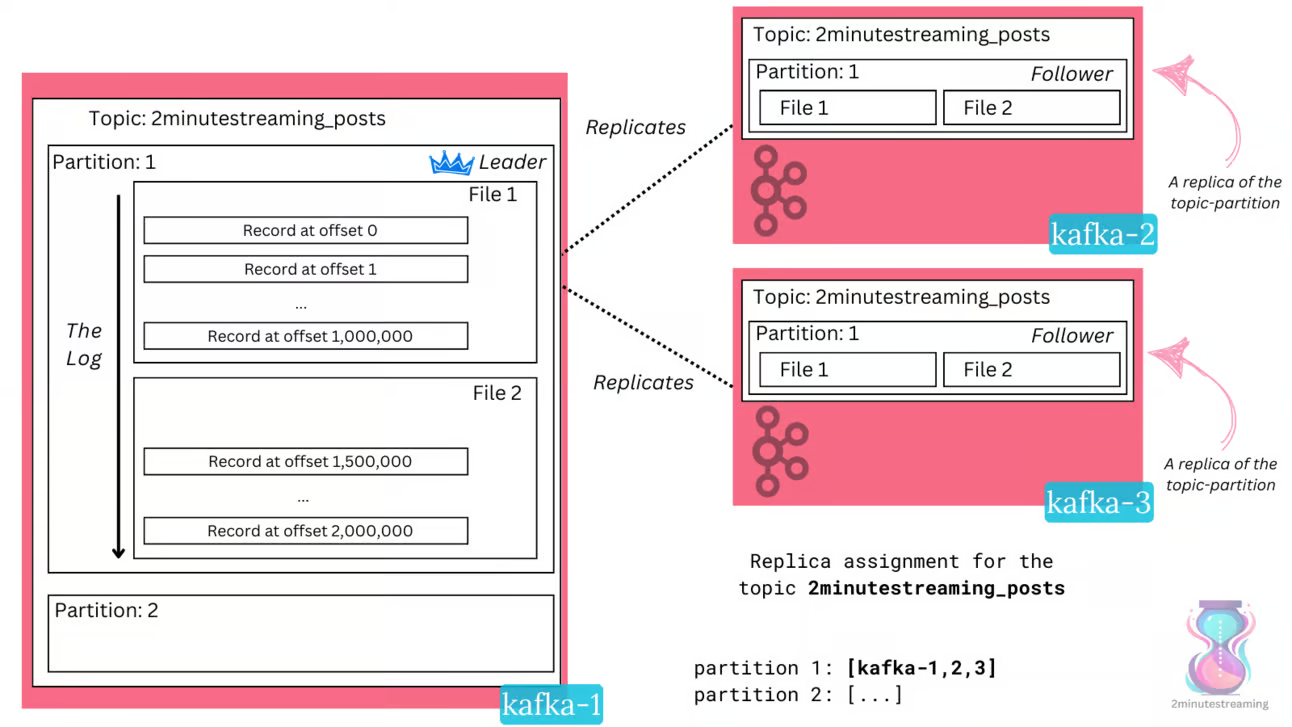
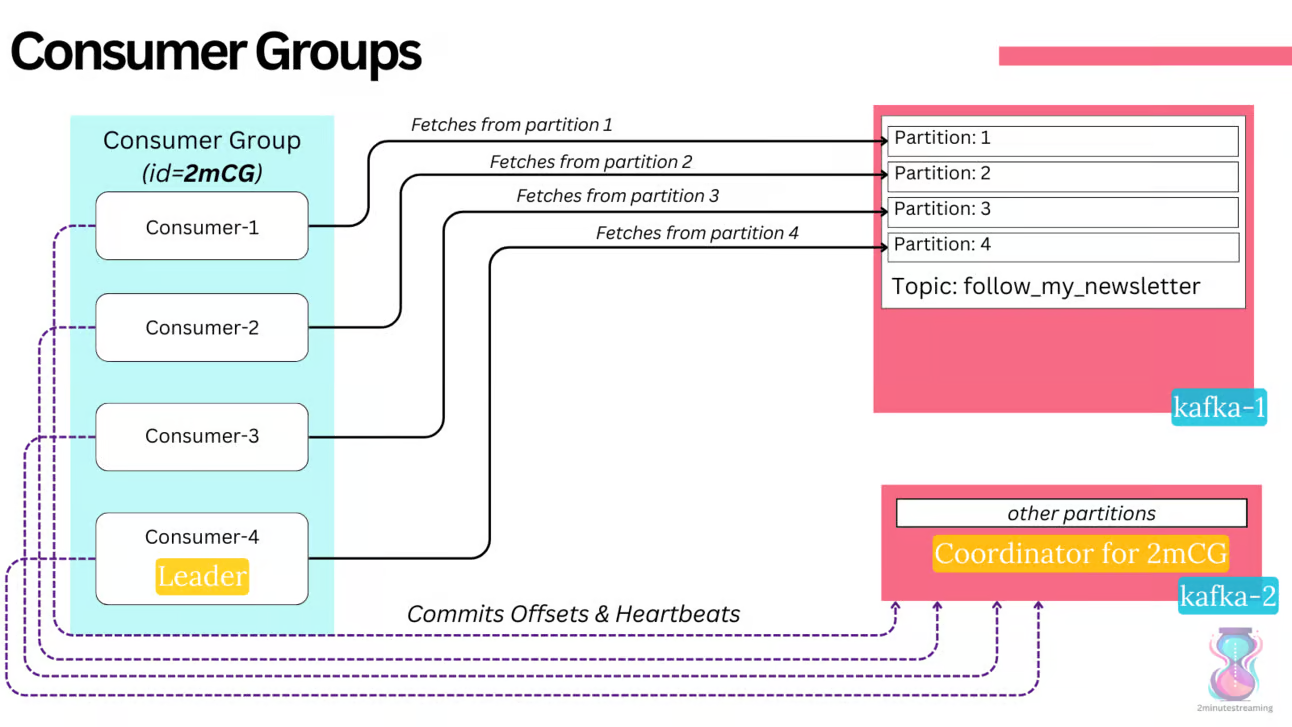
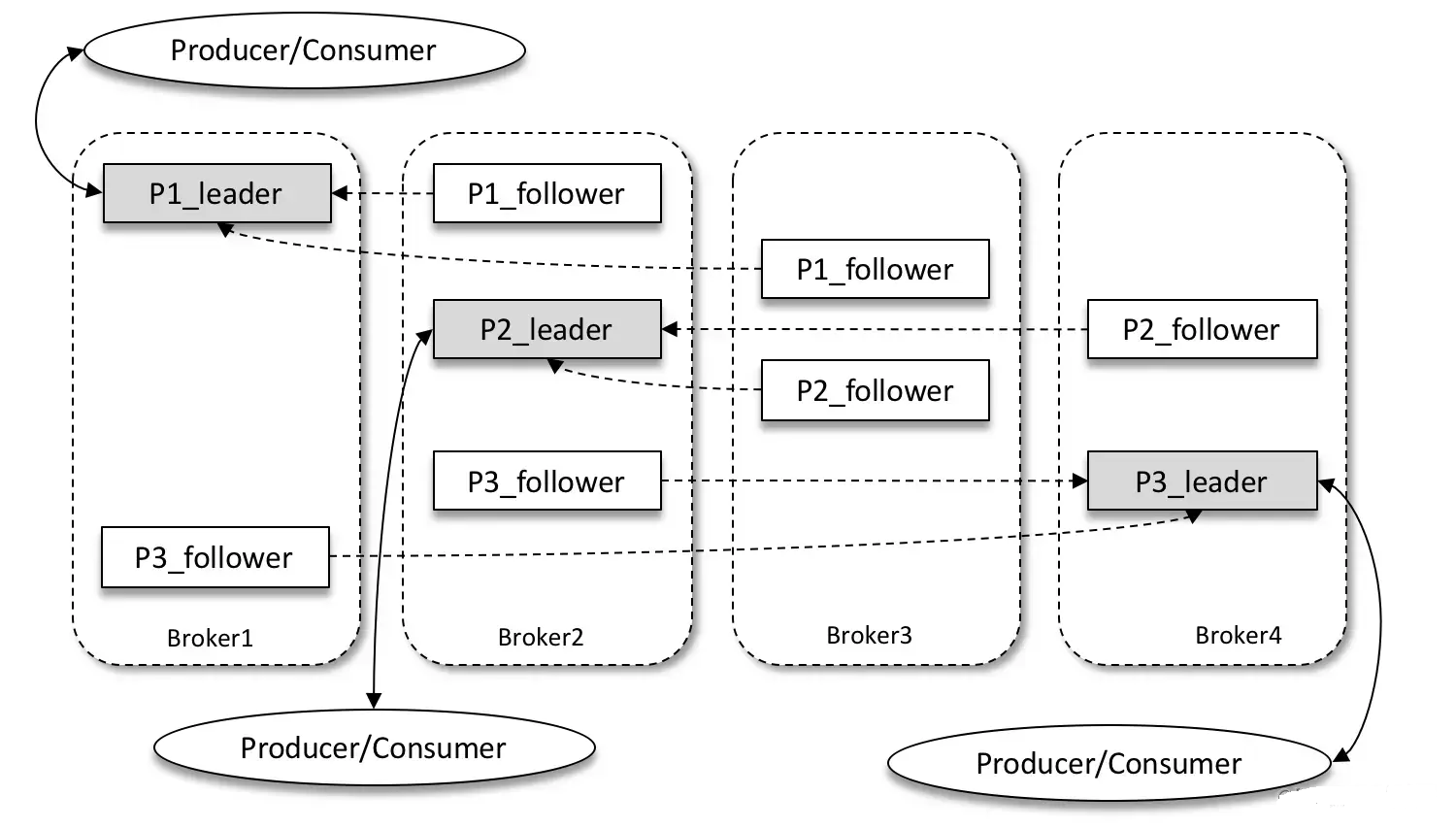
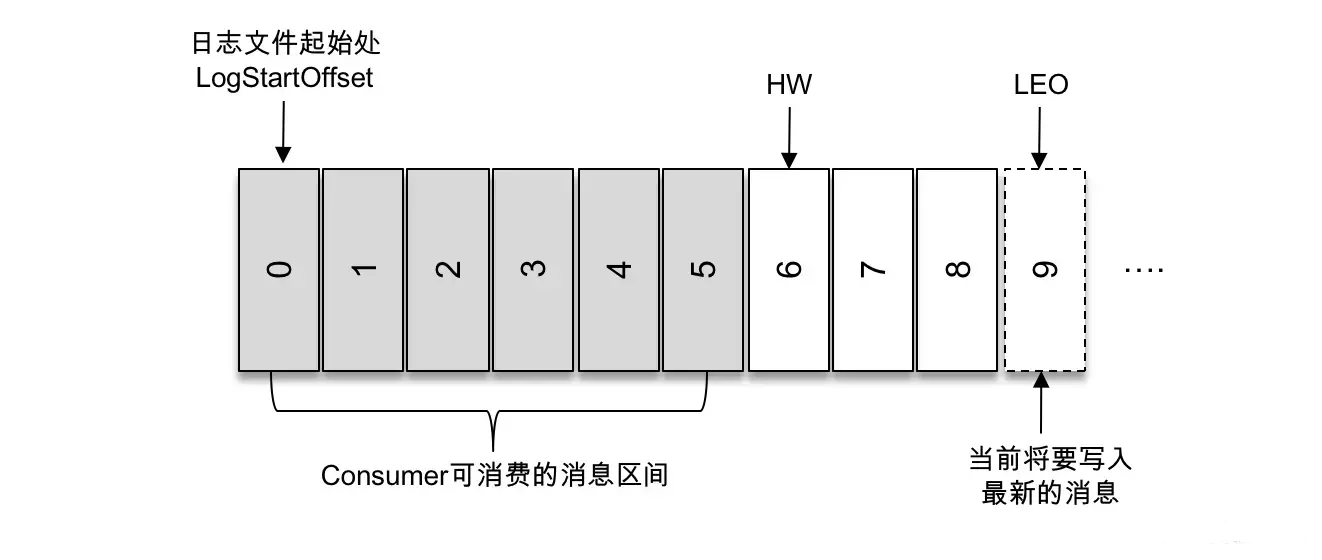
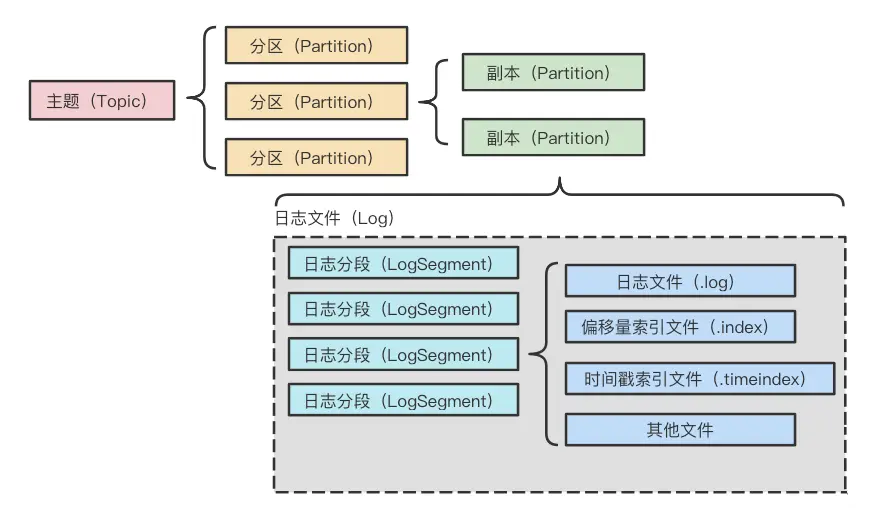
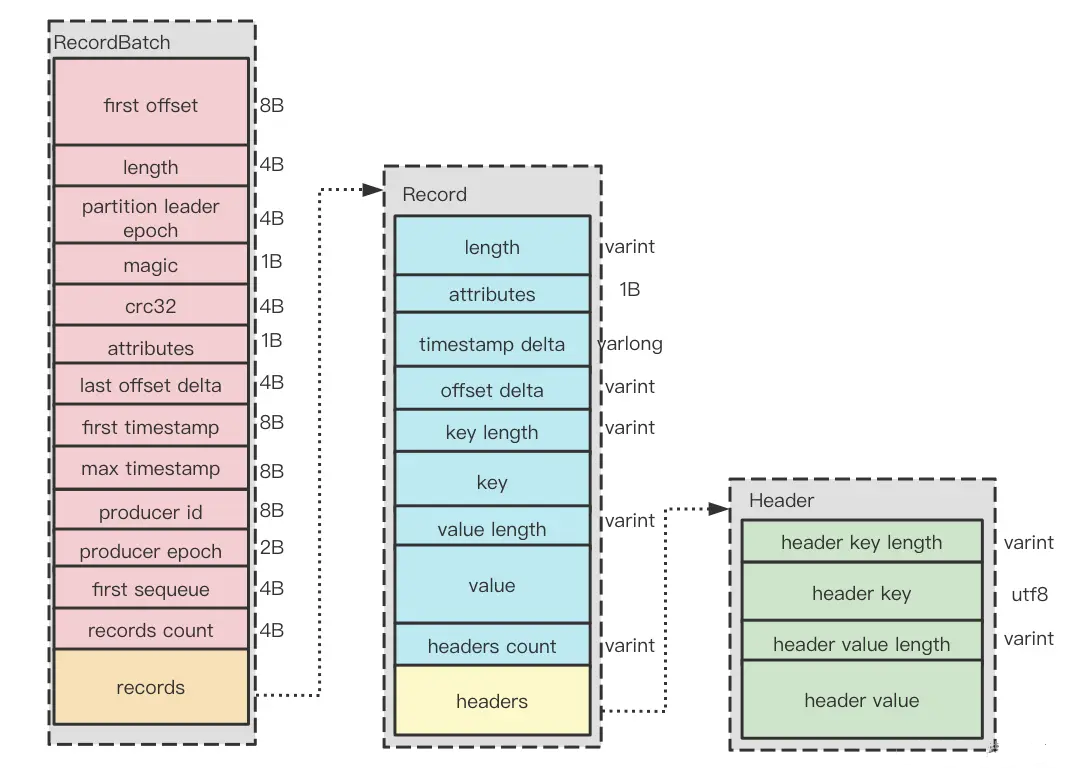
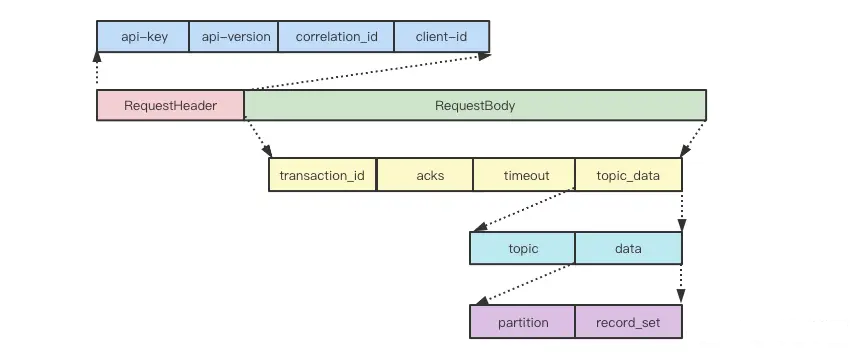
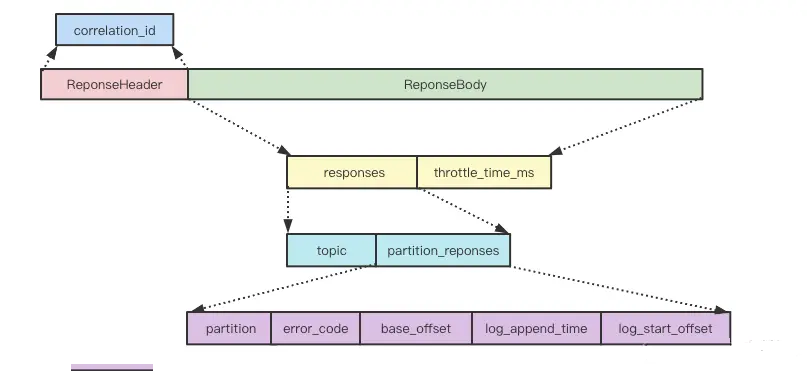
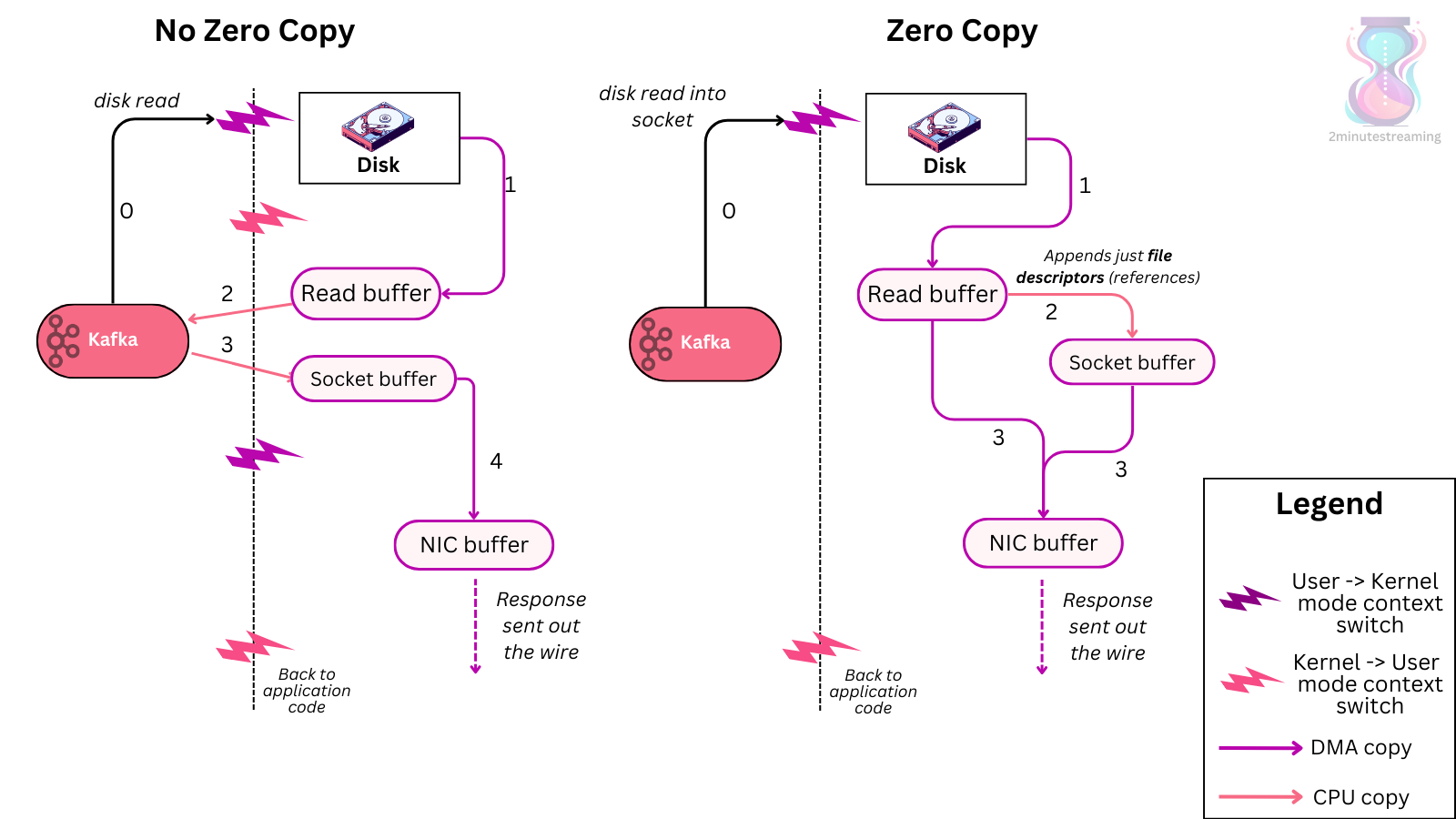
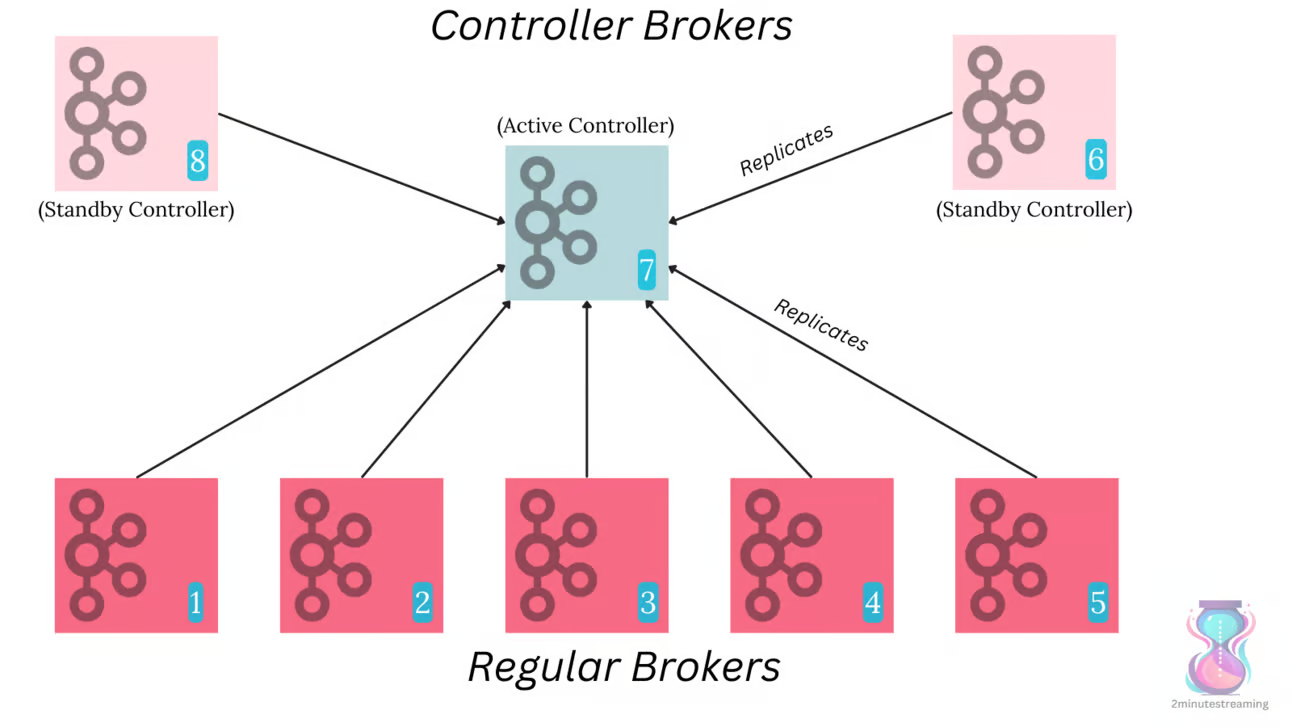
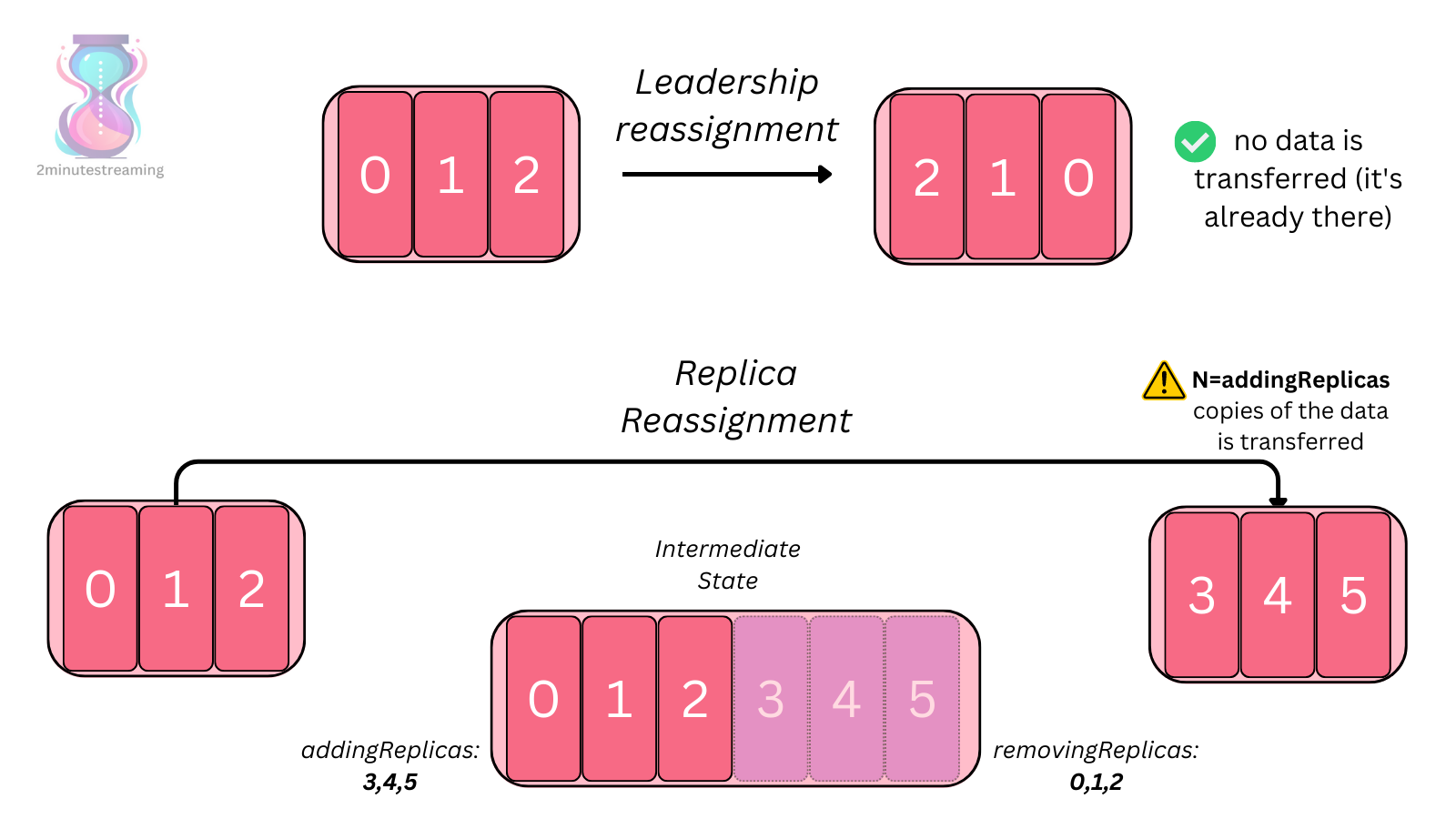
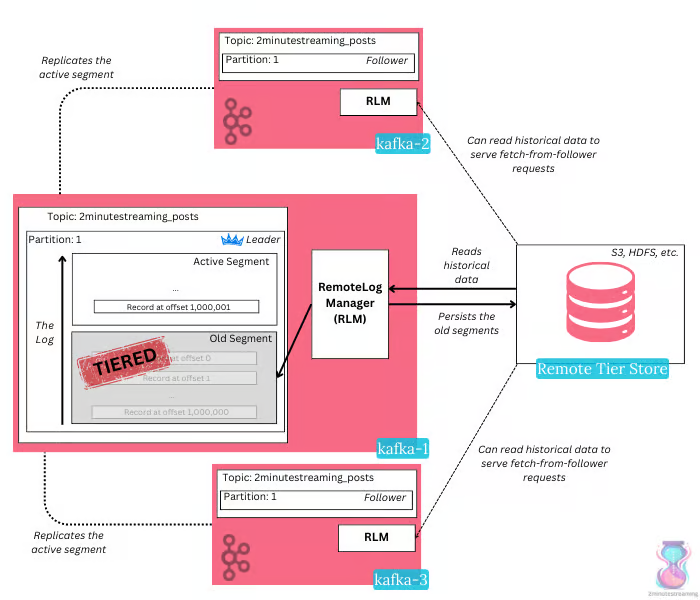
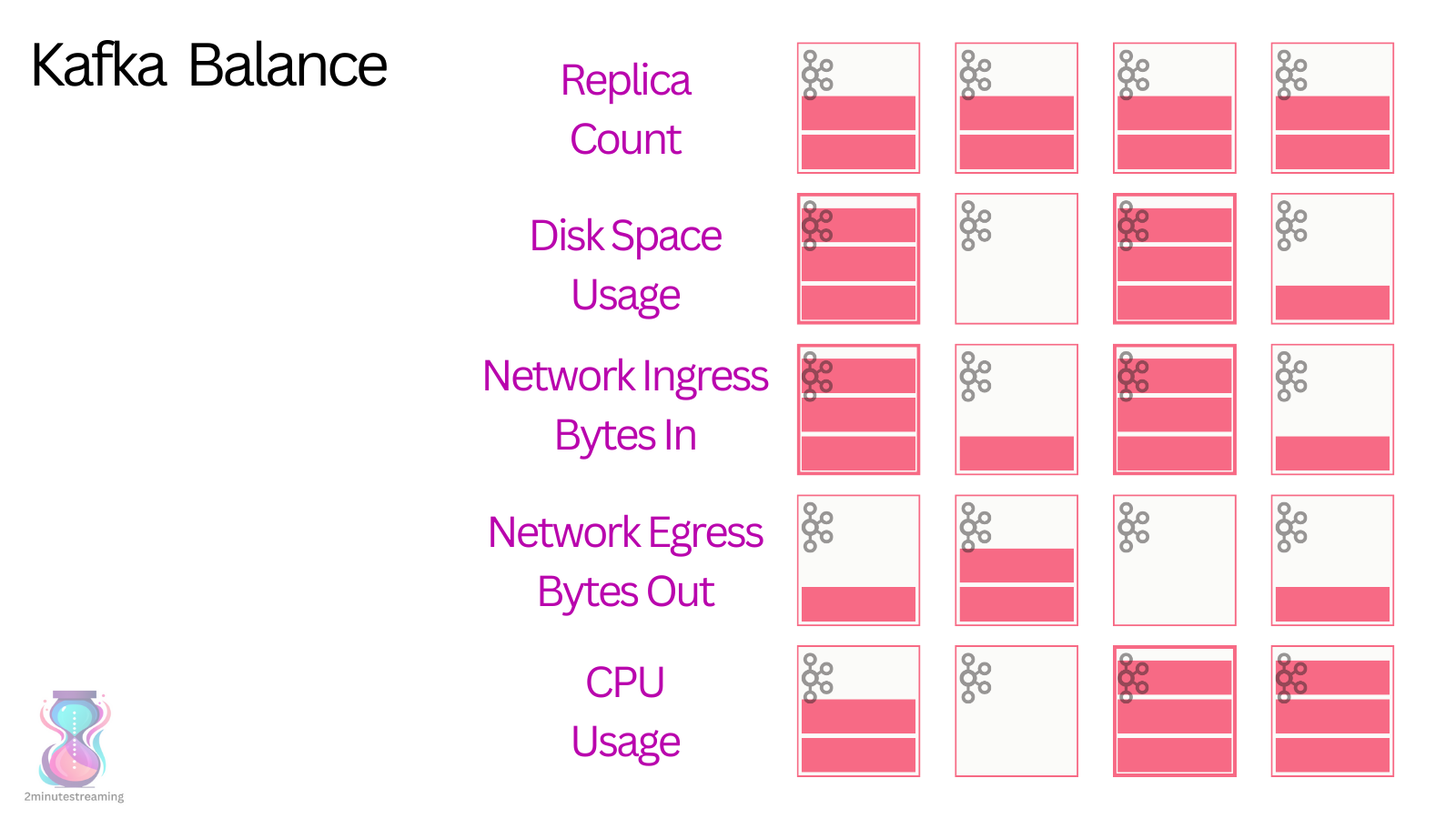
producer, broker, consumer,consumer group消费对应的partition数据,partition 包括多个 log segment,当一个达到阈值后,变成read only,再生成一个新的;每次都是head或者tail读,以及append写,速度很快,另外用了page cache会将数据写先到缓存再刷新;每个分区都有一个leader,副本只用于备份不做读写处理;副本如果能跟上leader就会放到 ISR集合中,ISR集合中最小的读确认offset 就是高水位,低水位是下次写的offset;producer 用 ack=0、1、all来表示副本节点是否接受了消息;ZK 后面迁移到了 Z-Raft 了,还有分层存储;kafka balance 是 NP问题,kafka connect,kafka streams;未来发展:完全基于云的kafka,用C++重写的kafka,数据存储在S3上的 statefulness 的kafka
阅读全文
2024年10月15日
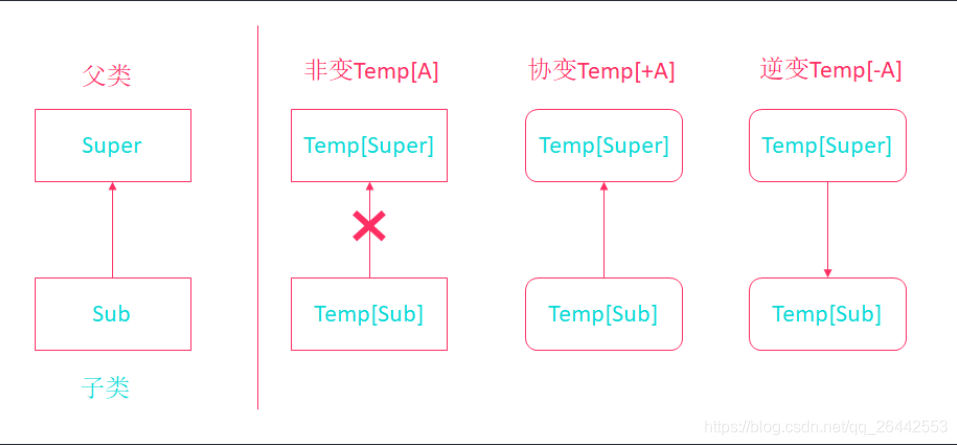
高阶函数、函数柯里化、隐式转换(类型,对象),lazy延迟计算、最后一行默认返回return。内置的可变 不可变集合、自动类型推导、操作符重载、模式匹配、内部函数、对象的apply和unapply、None和Some以及Option。foldLeft ,增强的for 循环,协变、逆变,上界 和 下界
阅读全文
2024年10月3日
大数据平台上云的问题:集群管控方式变了,YARN调度系统变了;安全性问题、DDos、数据治理问题;成本问题,计费策略;存储迁移,HDFS -> S3 语义的变化;多云高可用方案;混合云方案;适配其他业务线
阅读全文