2024年10月2日
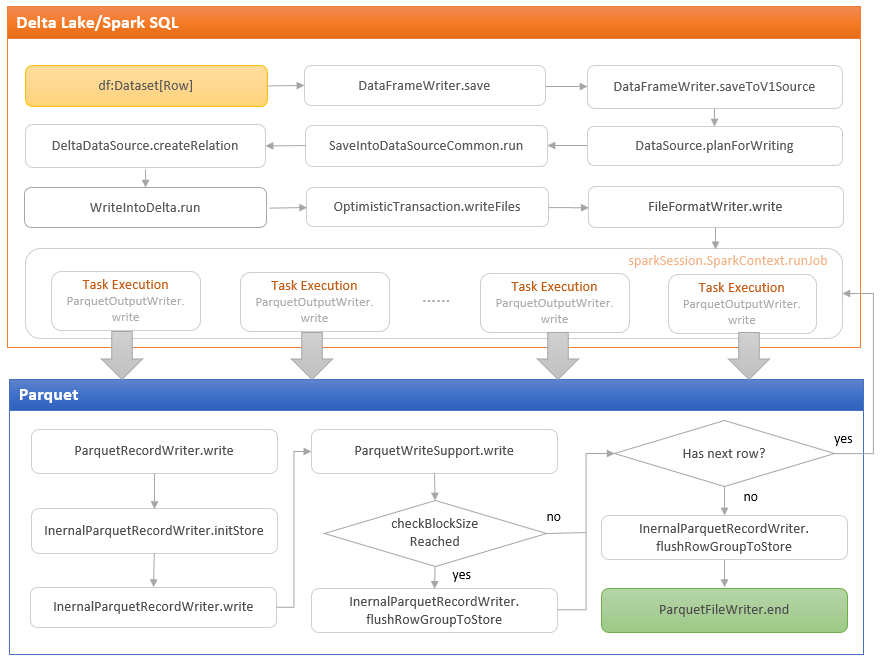
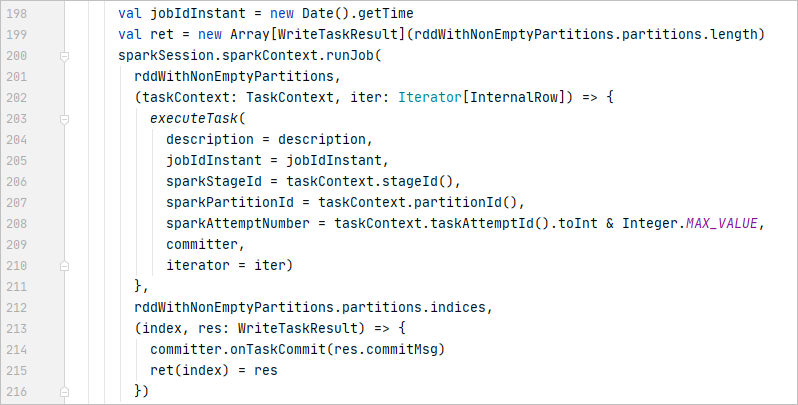
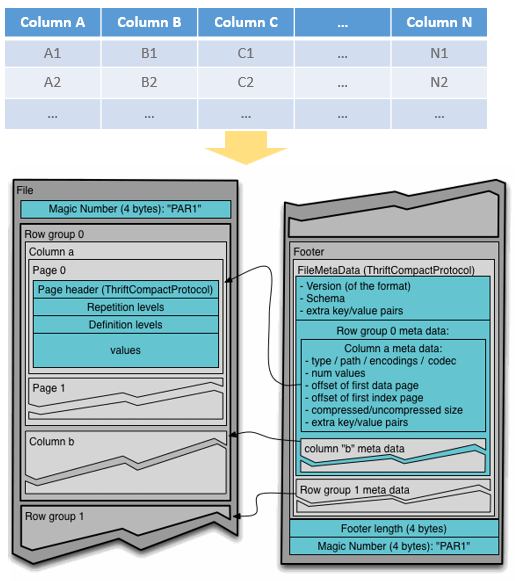
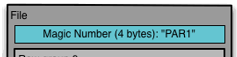
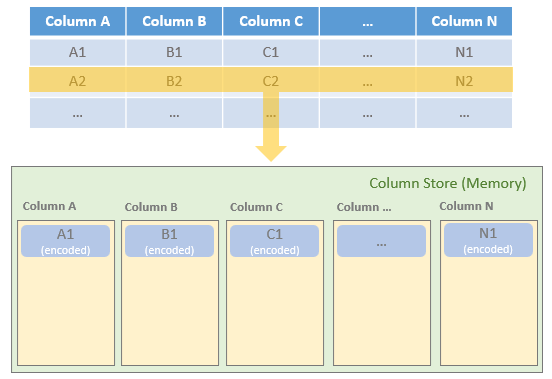
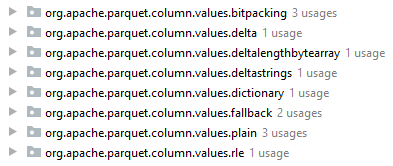
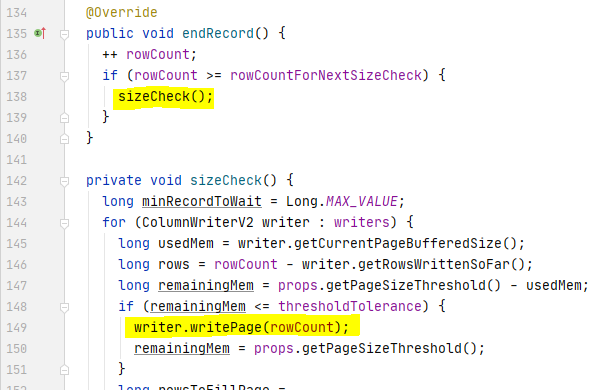
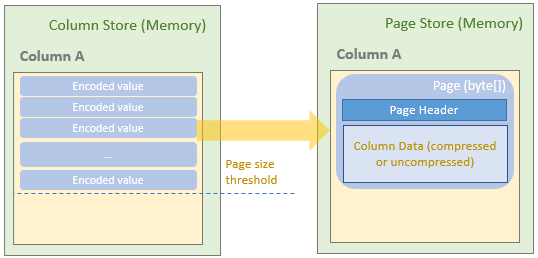
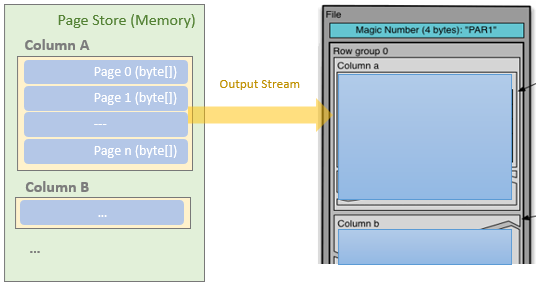
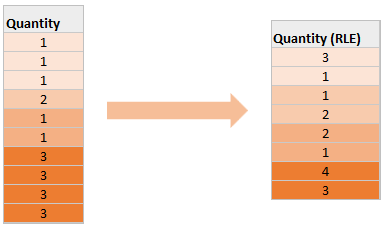
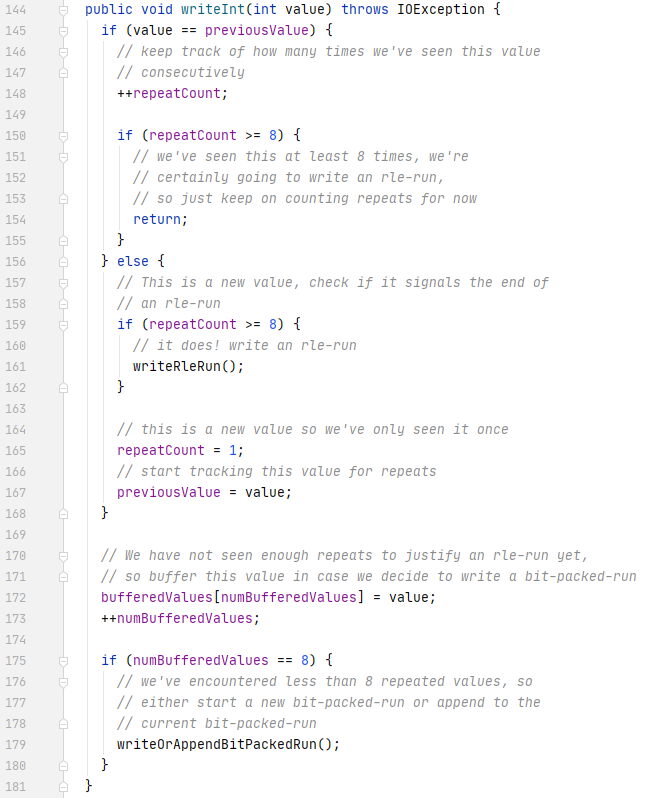
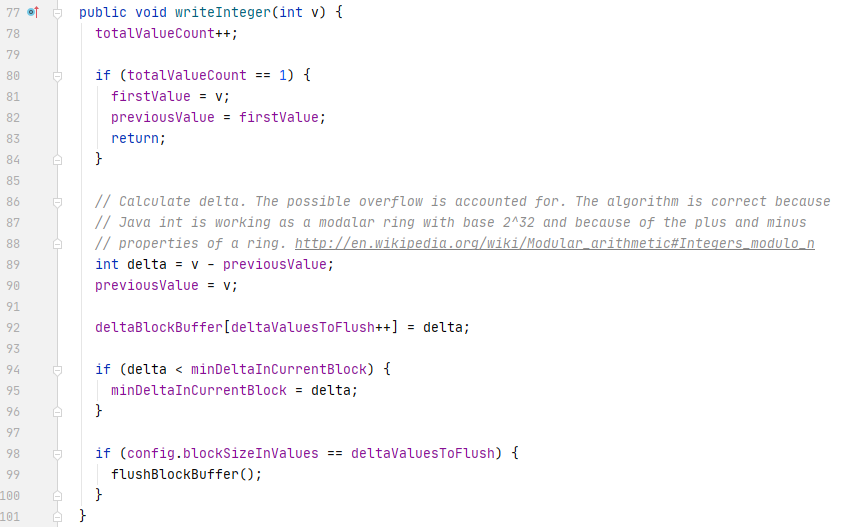
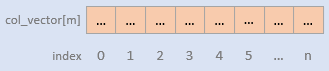
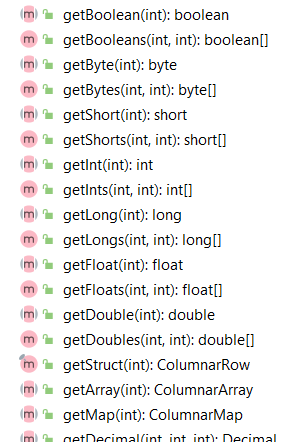
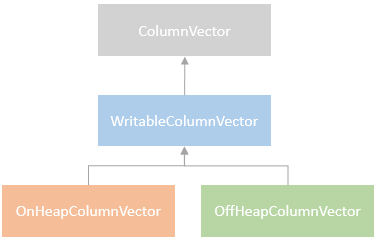
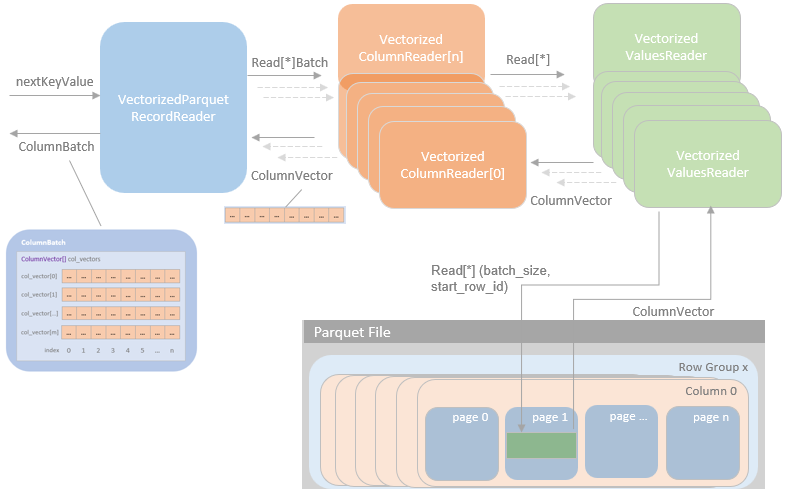
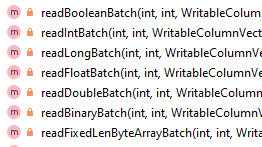
Spark执行Delta的过程,通过自定义的format格式,到DataFrameWriter.saveToV1Source,在是到DeltaDataSource#createRealation,写入做优化事务处理,再用FileFormatWriter创建多个Task并行写入,之后就是到Parquet内部执行阶段。Parquet包含Row Groups,往下是Column Chunk,再往下是Page,文件尾部包含Footer和一些元数据信息。Spark是按行写入的,一次写一行,每行写对应的 column。Parquet编码包括Dictionary Encoding、Run Length Encoding (RLE)、Delta Encoding。读取的主要类是VectorizedParquetRecordReader执行一批读取,调用VectorizedColumnReaders(对应每个column),再调用VectorizedValuesReader(读取一个column中的一段数据),返回由上层应用消费 。
阅读全文
2024年9月9日
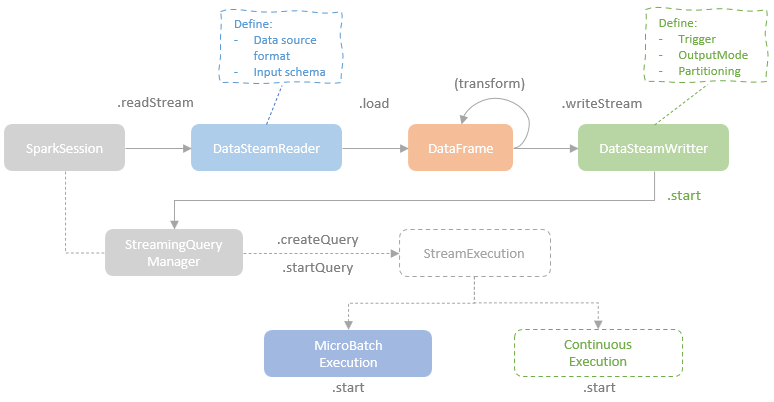
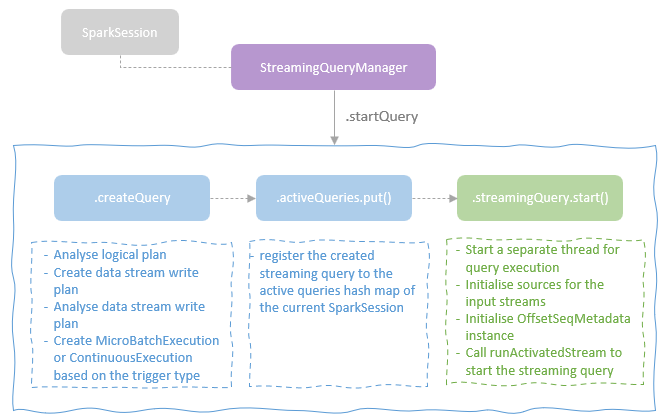
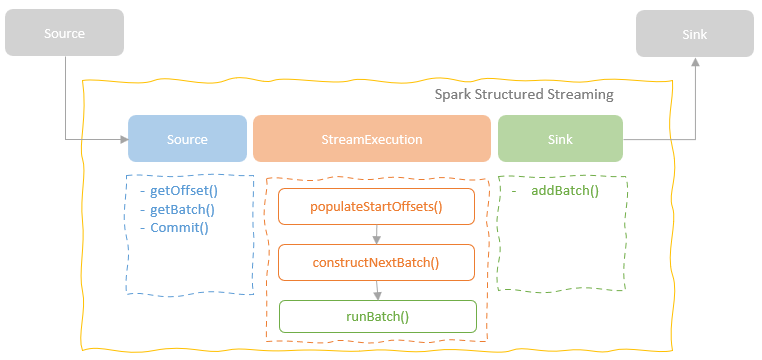
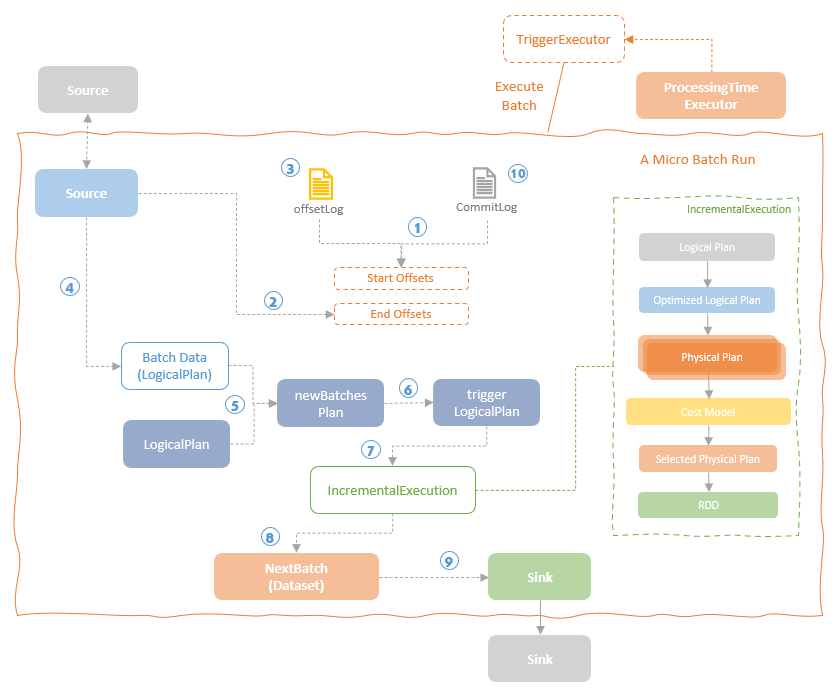
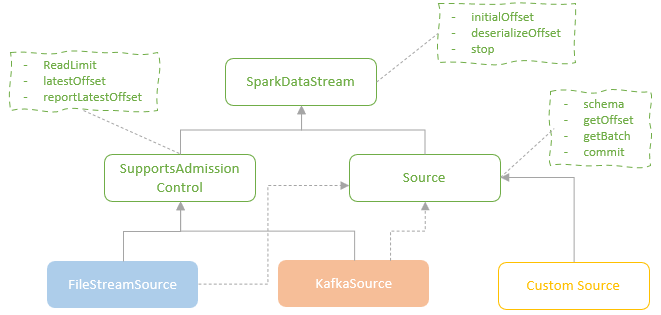
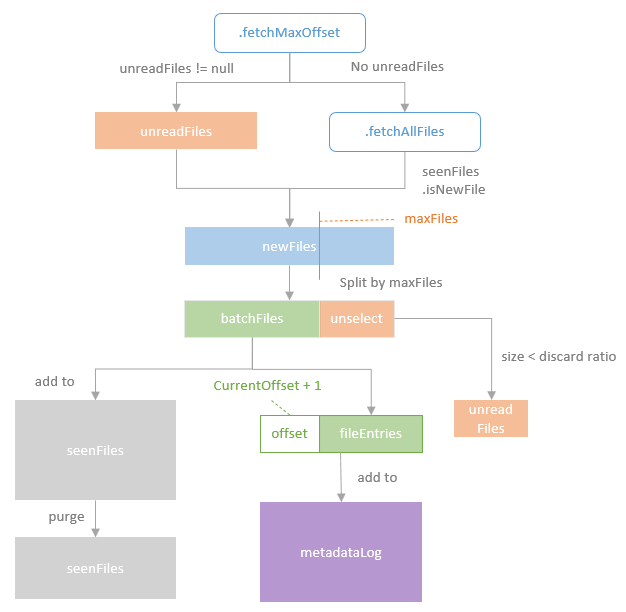
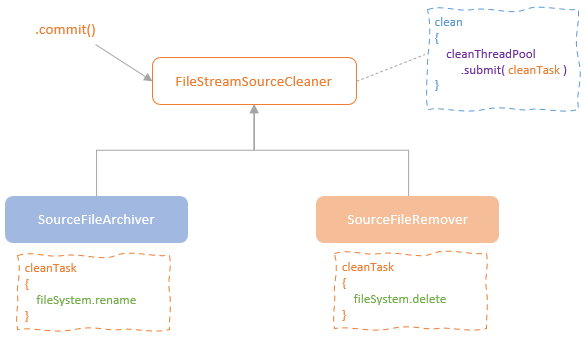
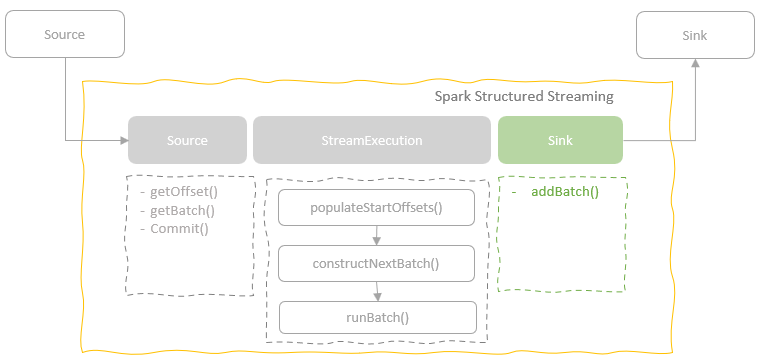
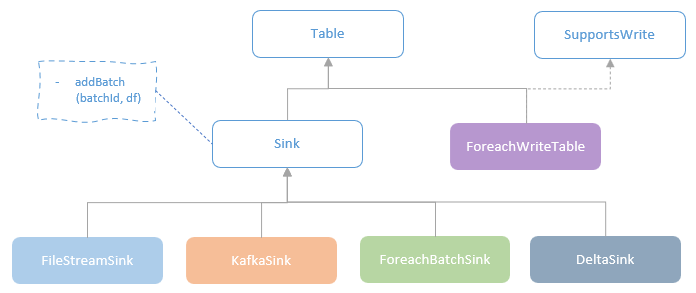
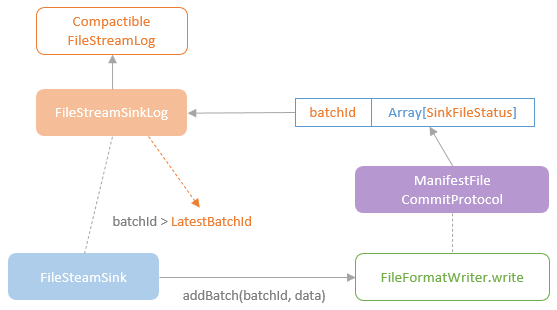
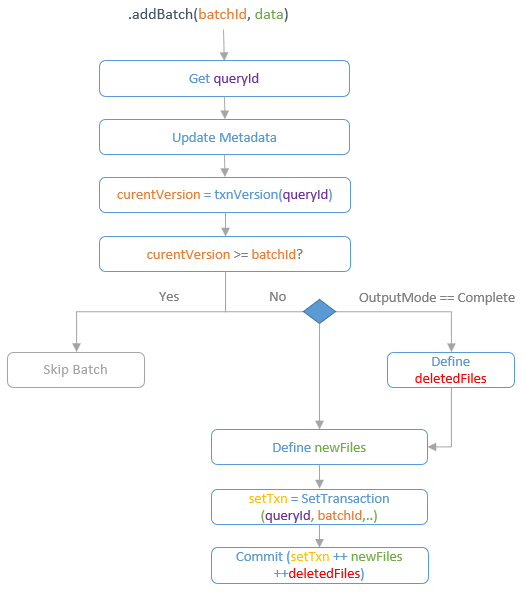
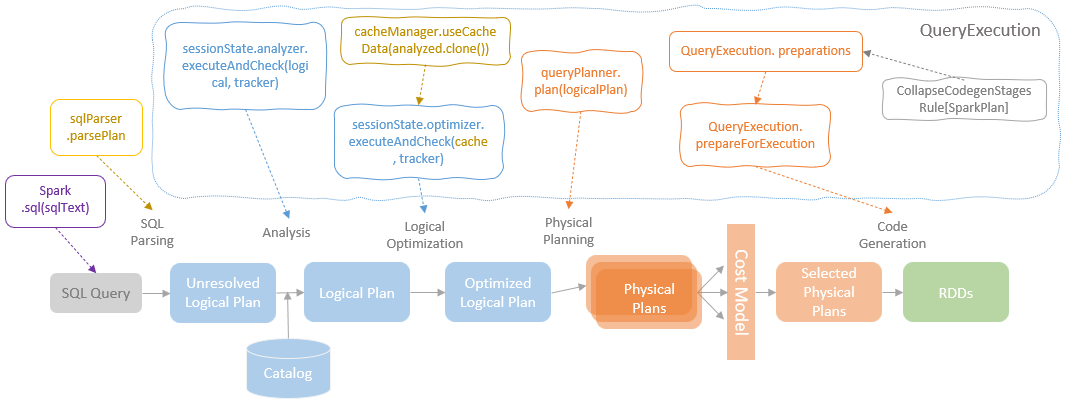
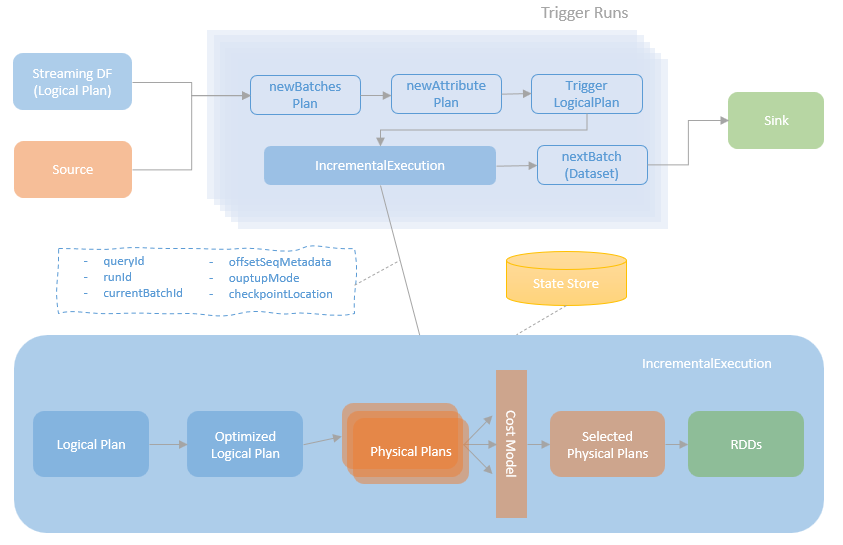
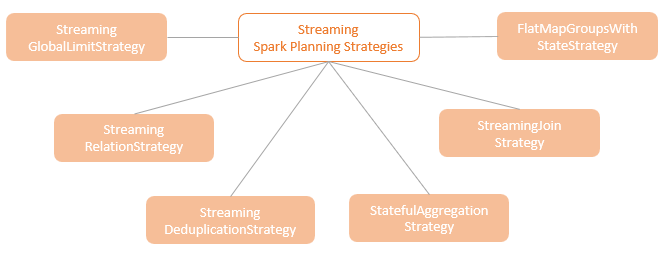
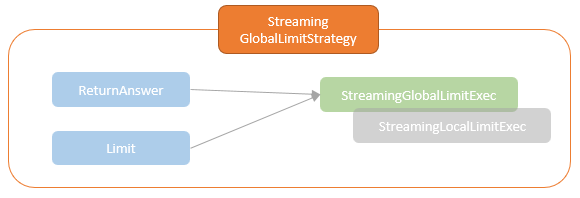
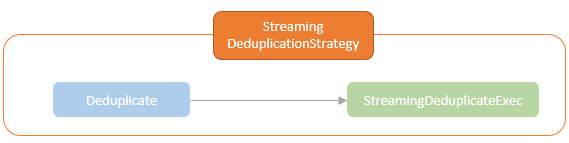
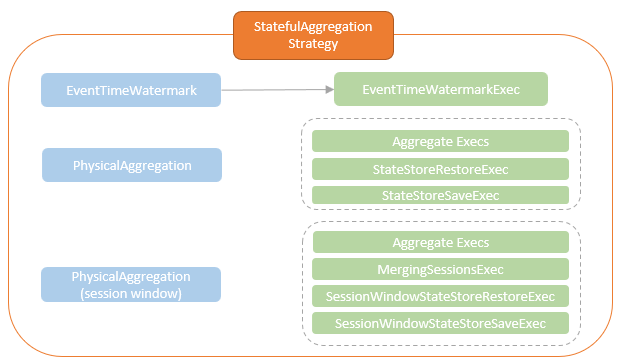
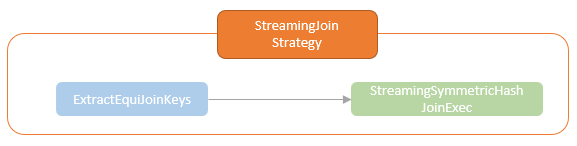
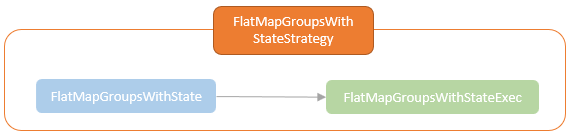
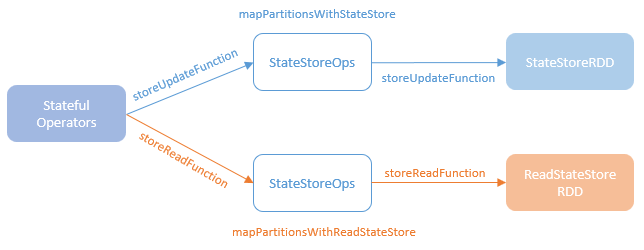
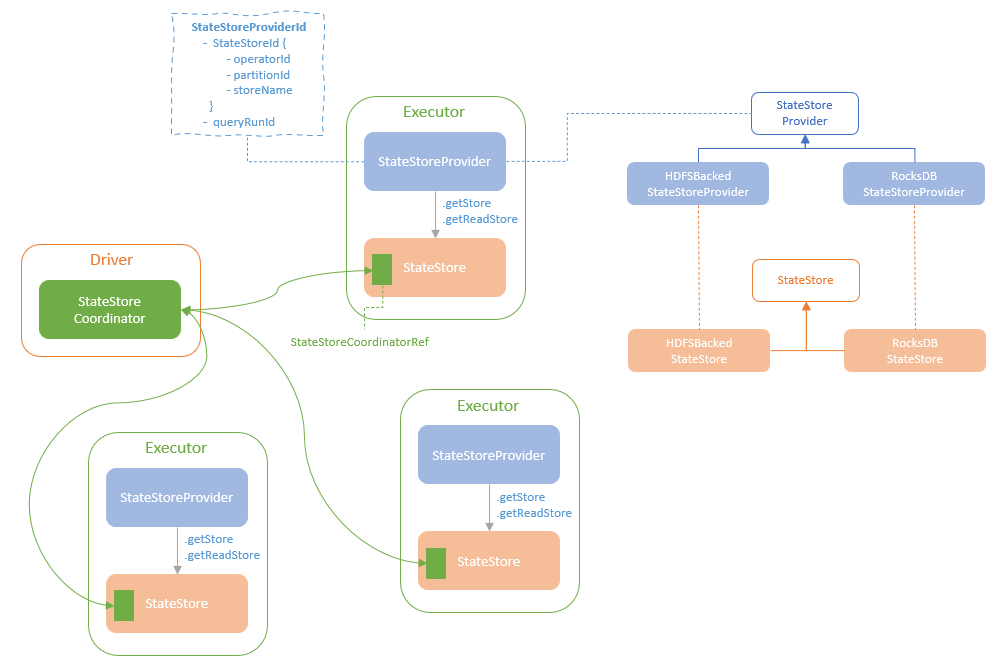
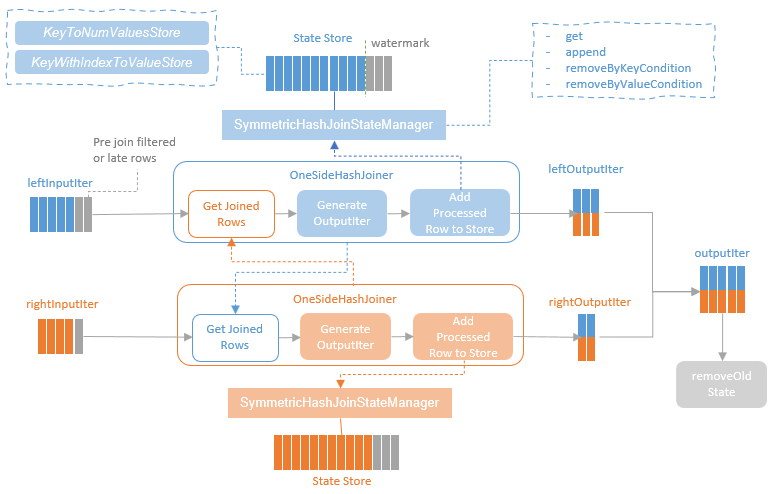
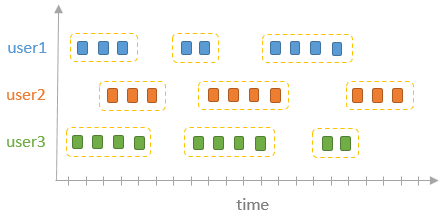
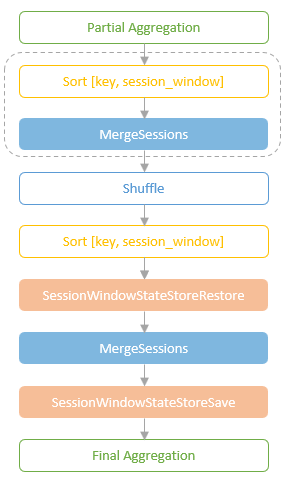
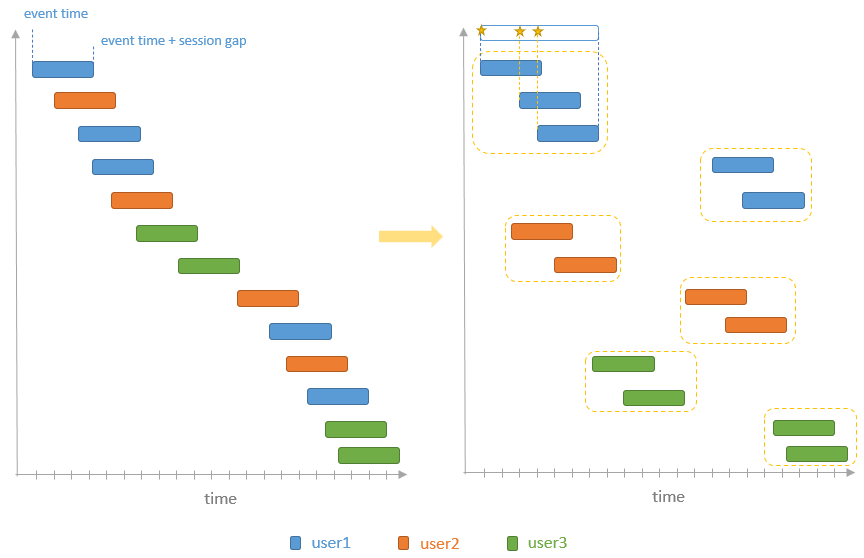
spark streaming的基本原理,包括MicroBatchExecution,ContinuousExecution,通过IncrementalExecution + 状态实现micro-batch 并复用了spark 的所有查询逻辑;Source接口支持 getOffset,commit,可以自定义各种扩展实现;Sink包括:FileStreamSink、KafkaSink、DeltaSink、、ForeachBatchSink,ForeachWriteTable;Stateful将信息存如StateStoreRDD,保存到 HDFSBackedStateStoreProvider、RocksDBStateStoreProvider 中;Stream-Stream Join使用了StreamingSymmetricHashJoin,需要保证状态;Session Window同样也是通过插入一些流相关的算子 + 状态保存实现的
阅读全文
2024年9月1日
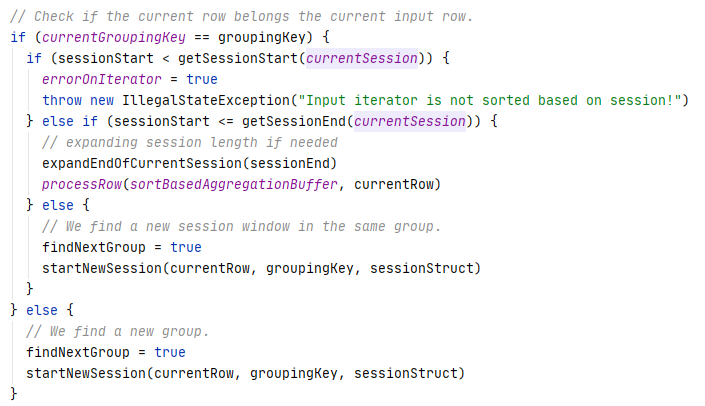
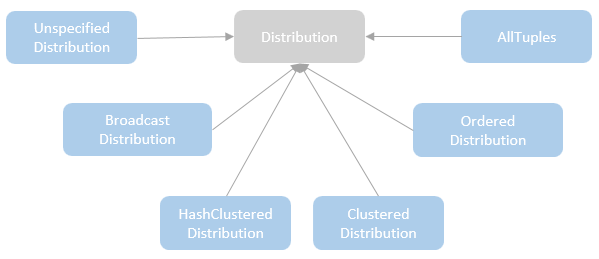
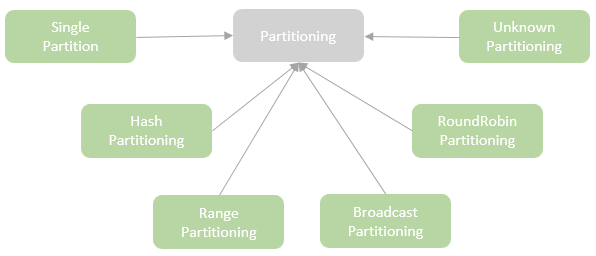
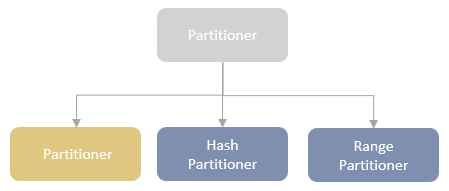
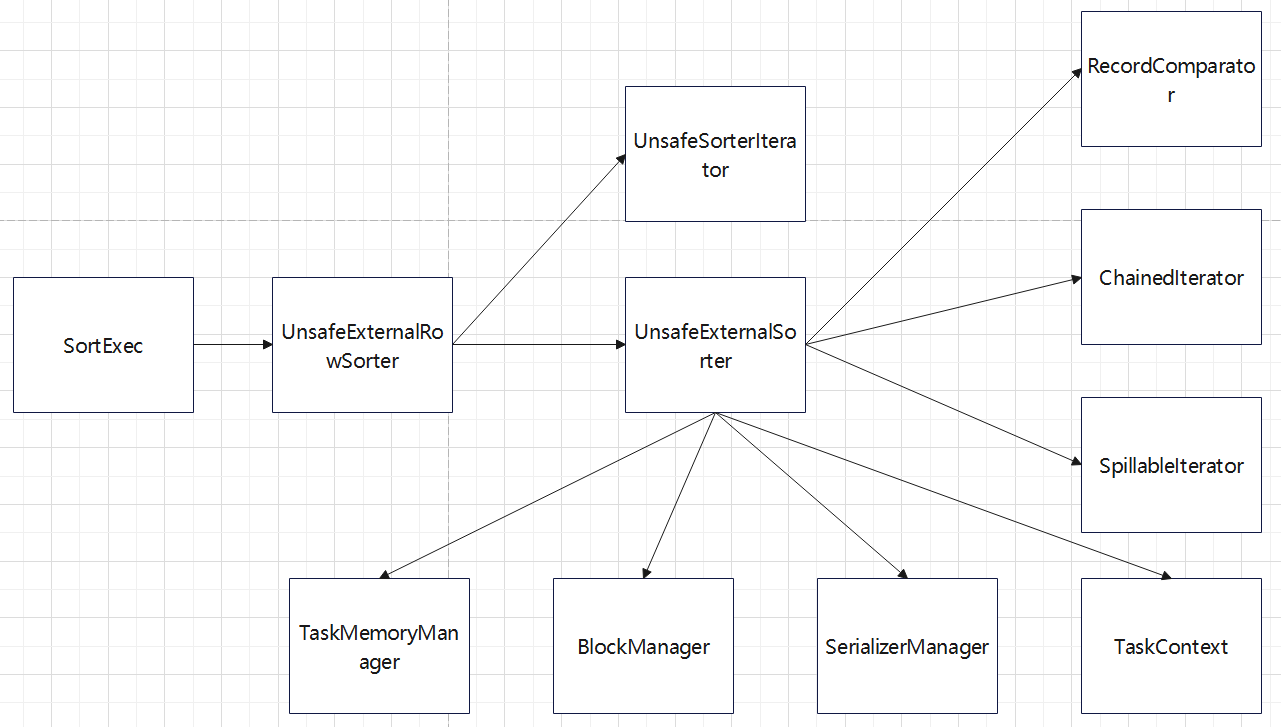
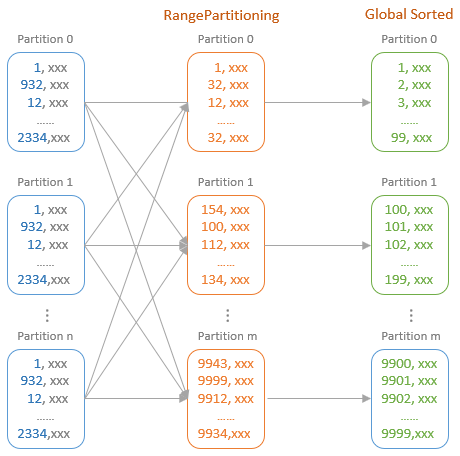
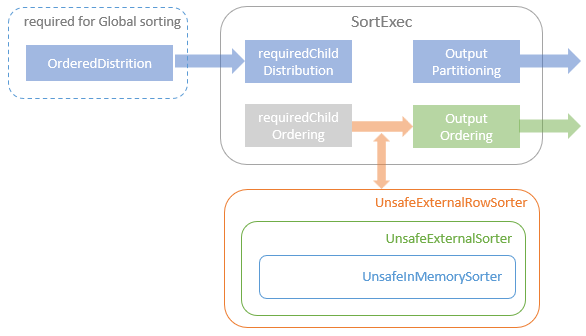
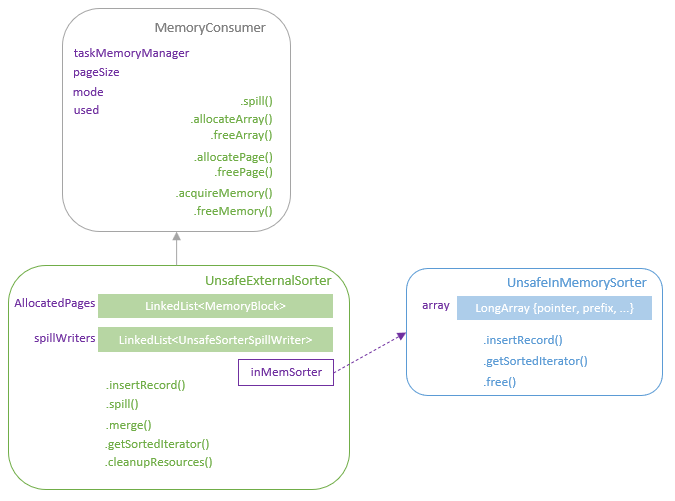
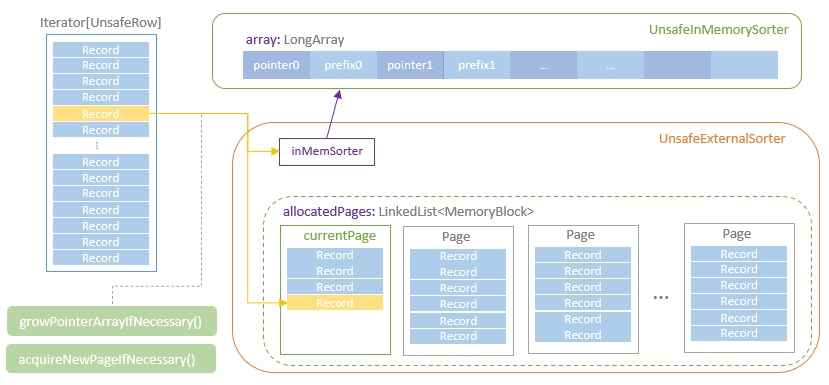
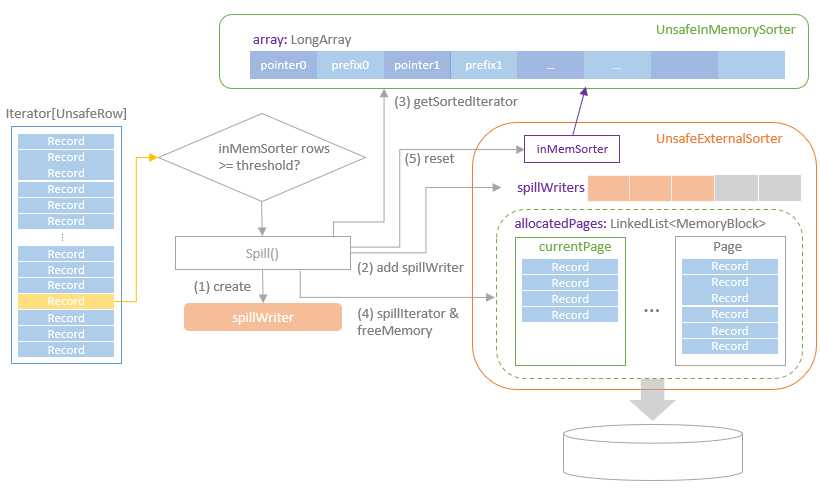
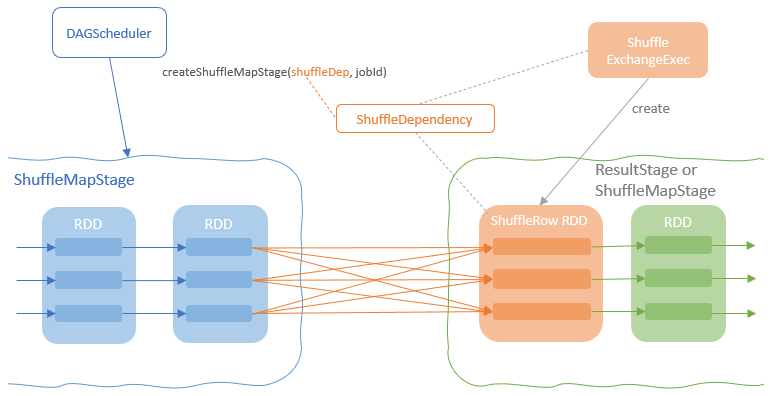
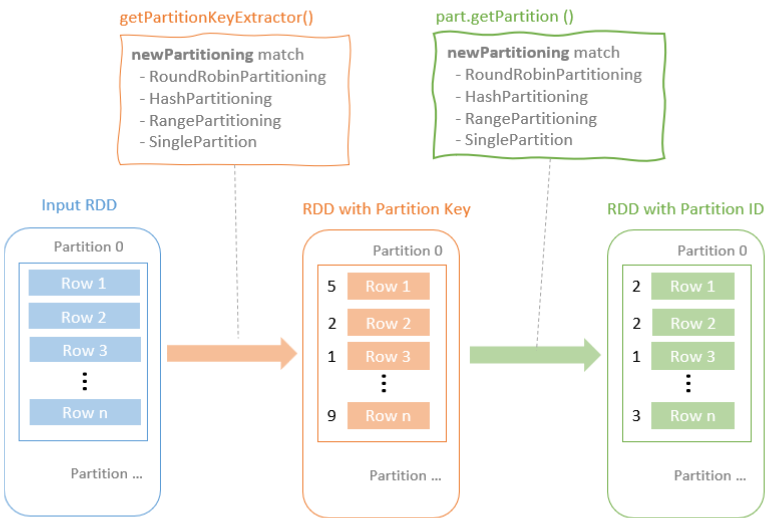
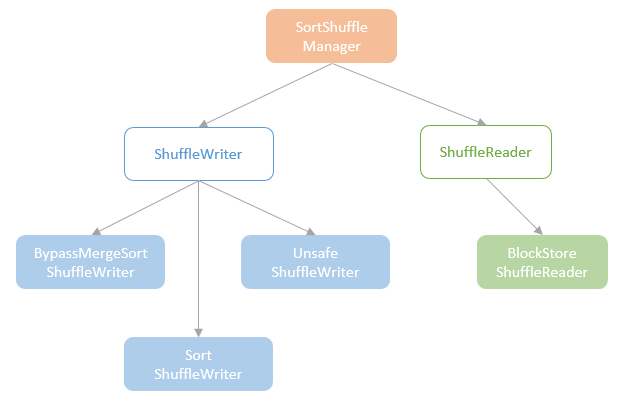
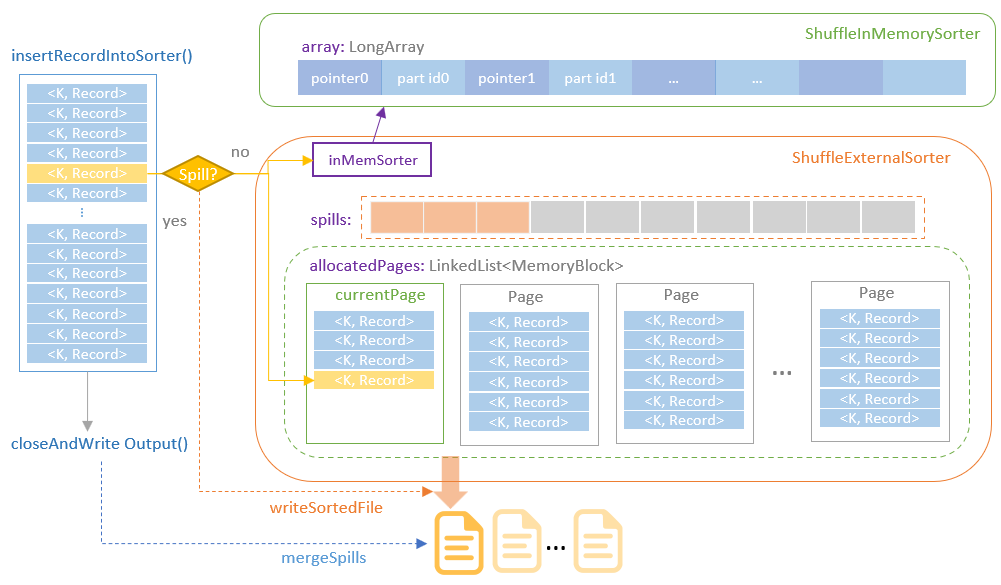
Distribution及相关类,Partitioning类,Partitioner类,排序的物理算子,UnsafeExternalSorter 和UnsafeInMemorySorter,spill和归并排序;shuffle操作,ShuffleDependency,ShuffleRowRDD,map端的ShuffleMapTasks,reduce端 ShuffleDependency 从shuffle manager 那里读取数据,拿到MapStauts 状态;ShuffleManager 包含了ShuffleWriter,ShuffleReader;BypassMergeSortShuffleWriter 、UnsafeShuffleWriter、SortShuffleWriter、、BlockStoreShuffleReader
阅读全文
2024年8月25日
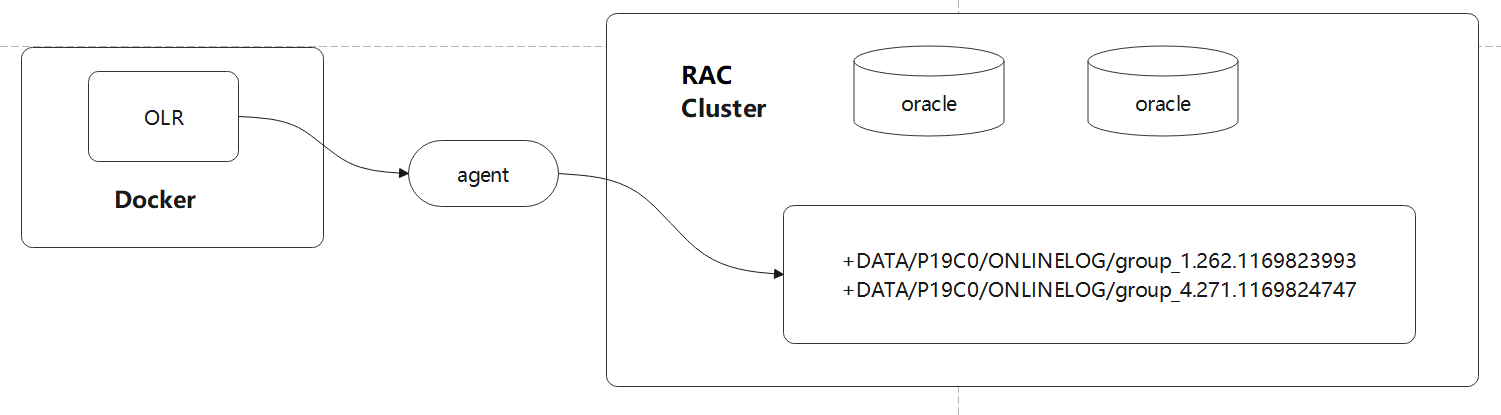
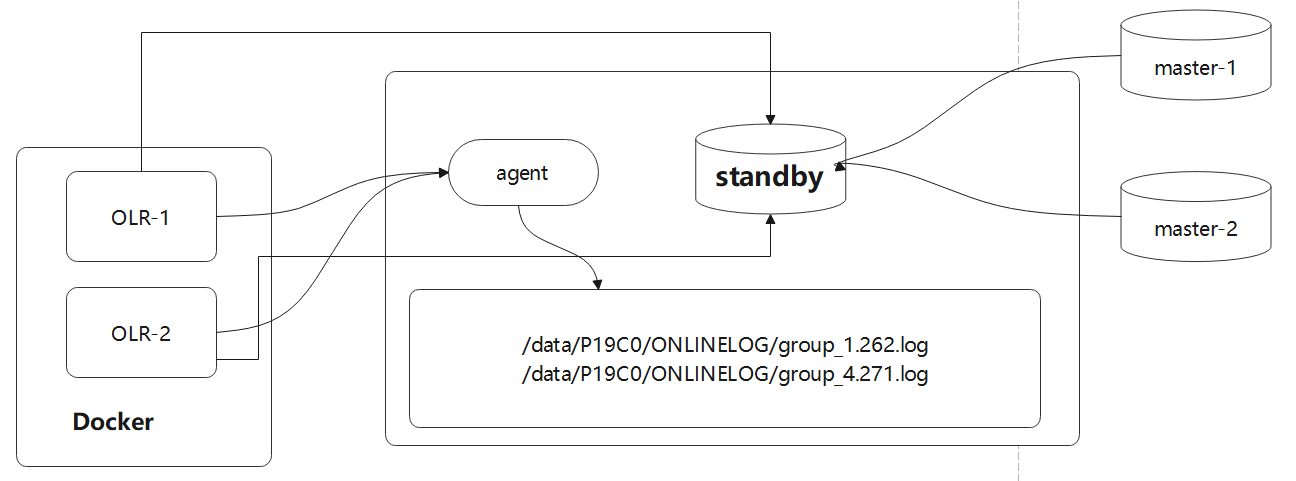
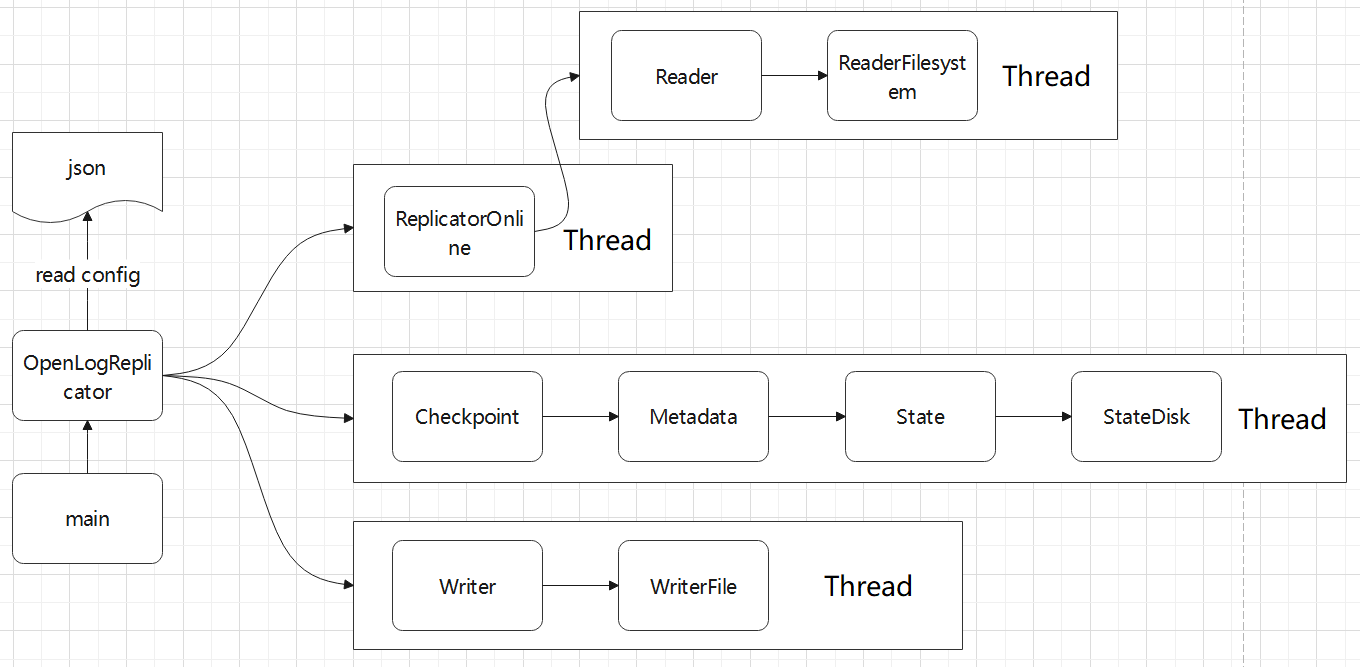
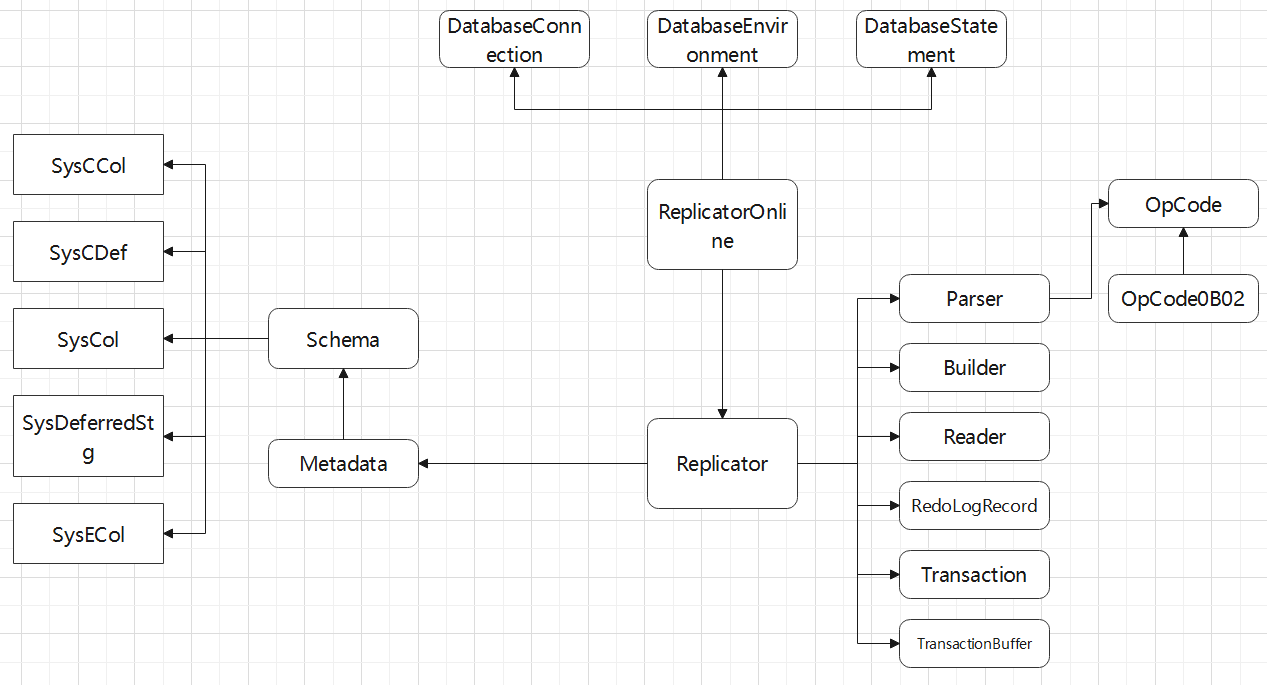
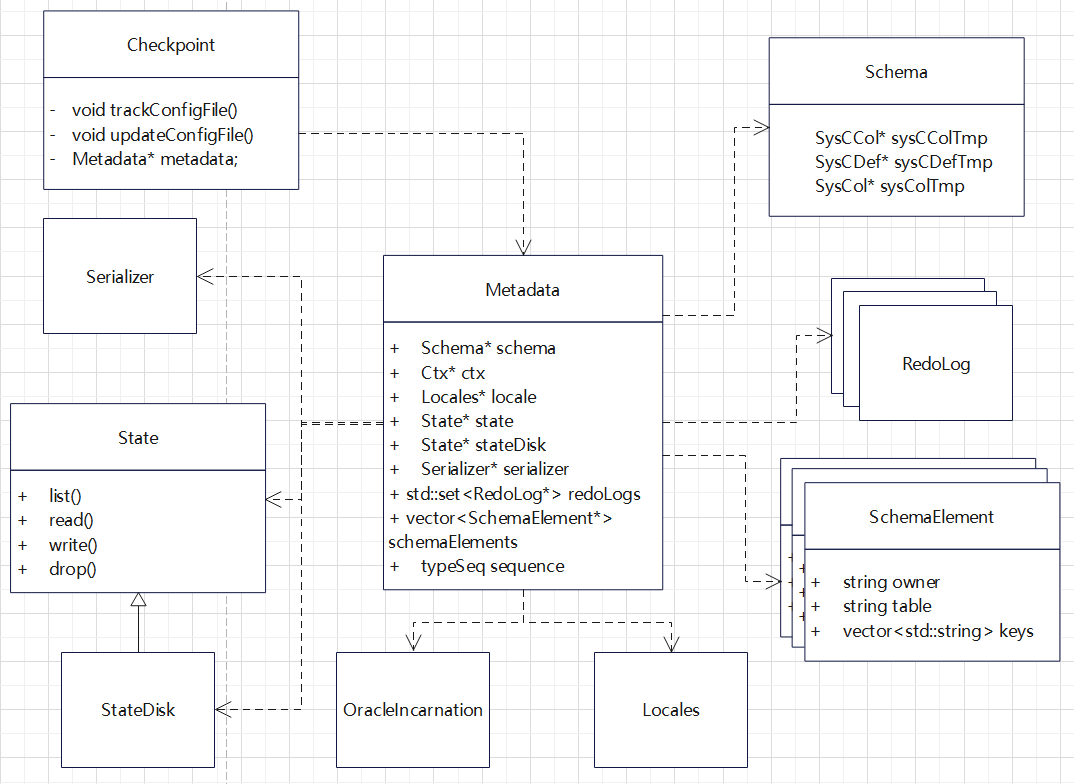
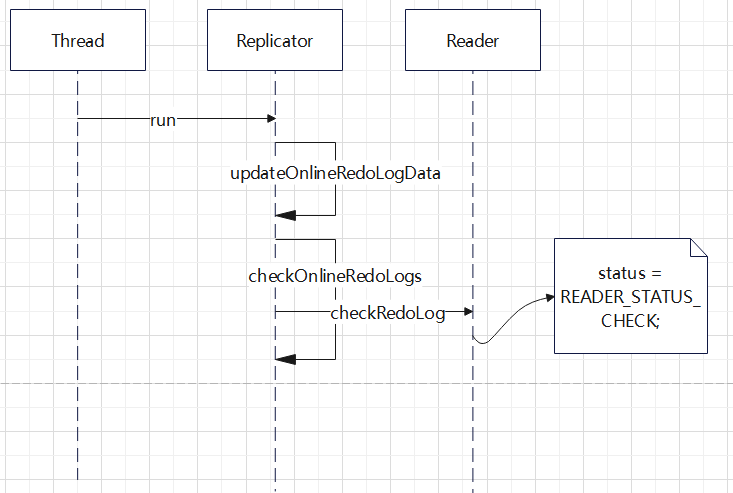
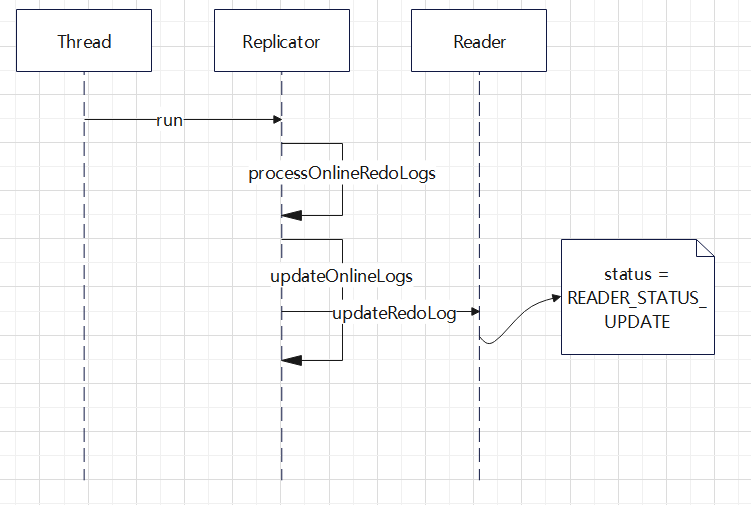
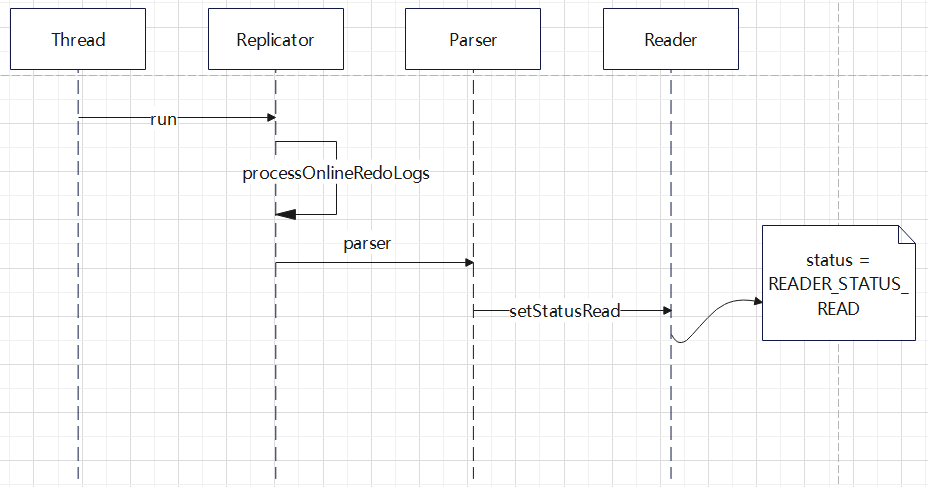
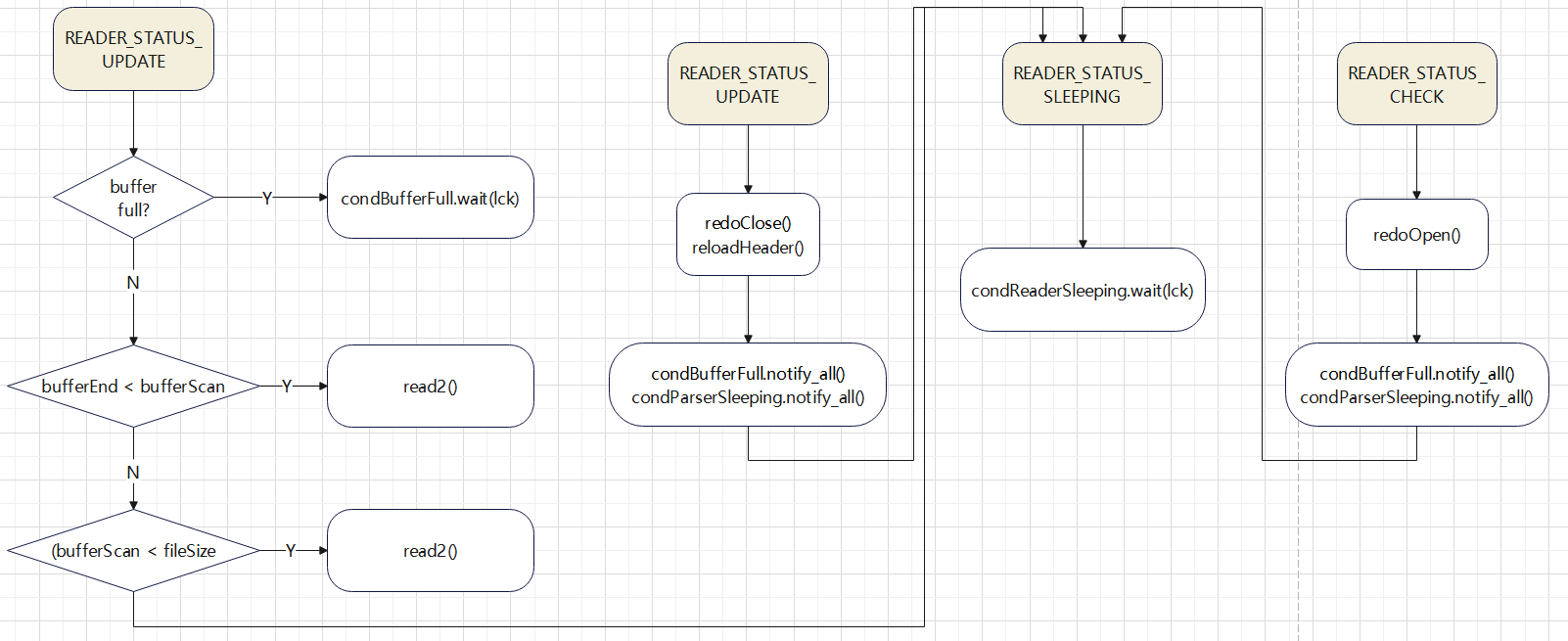
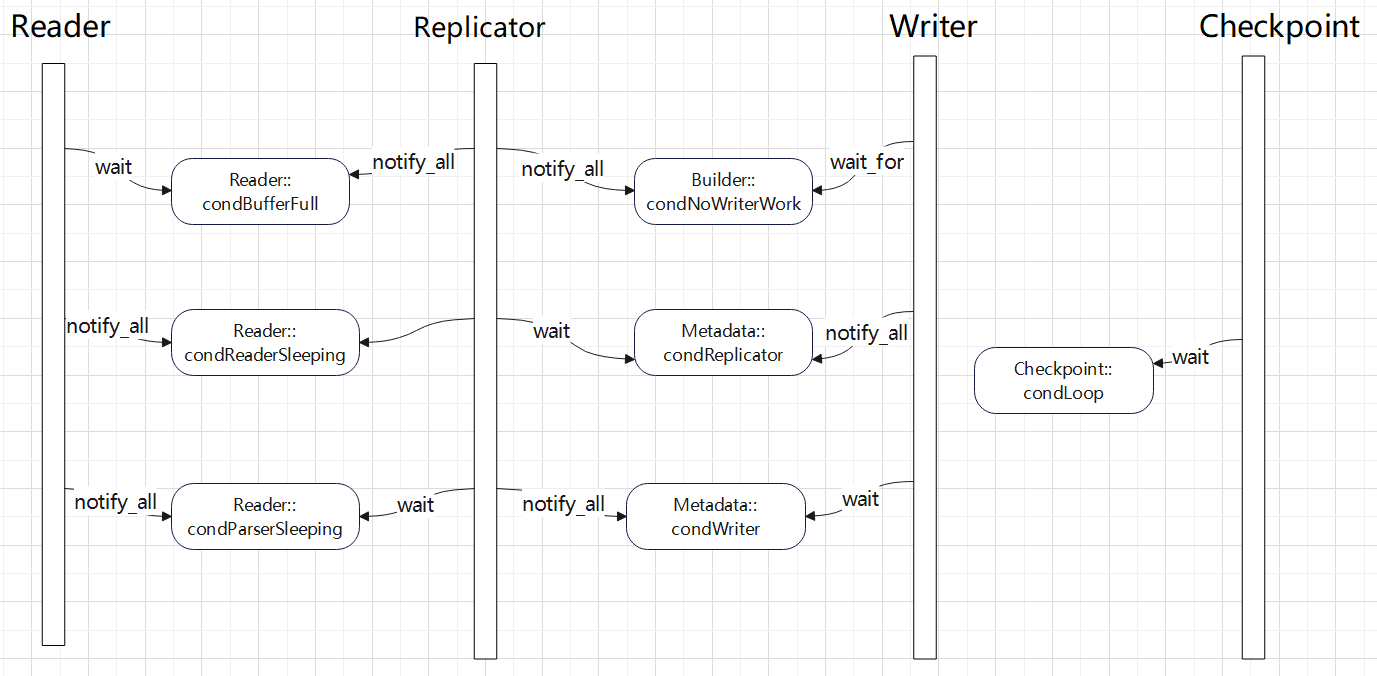
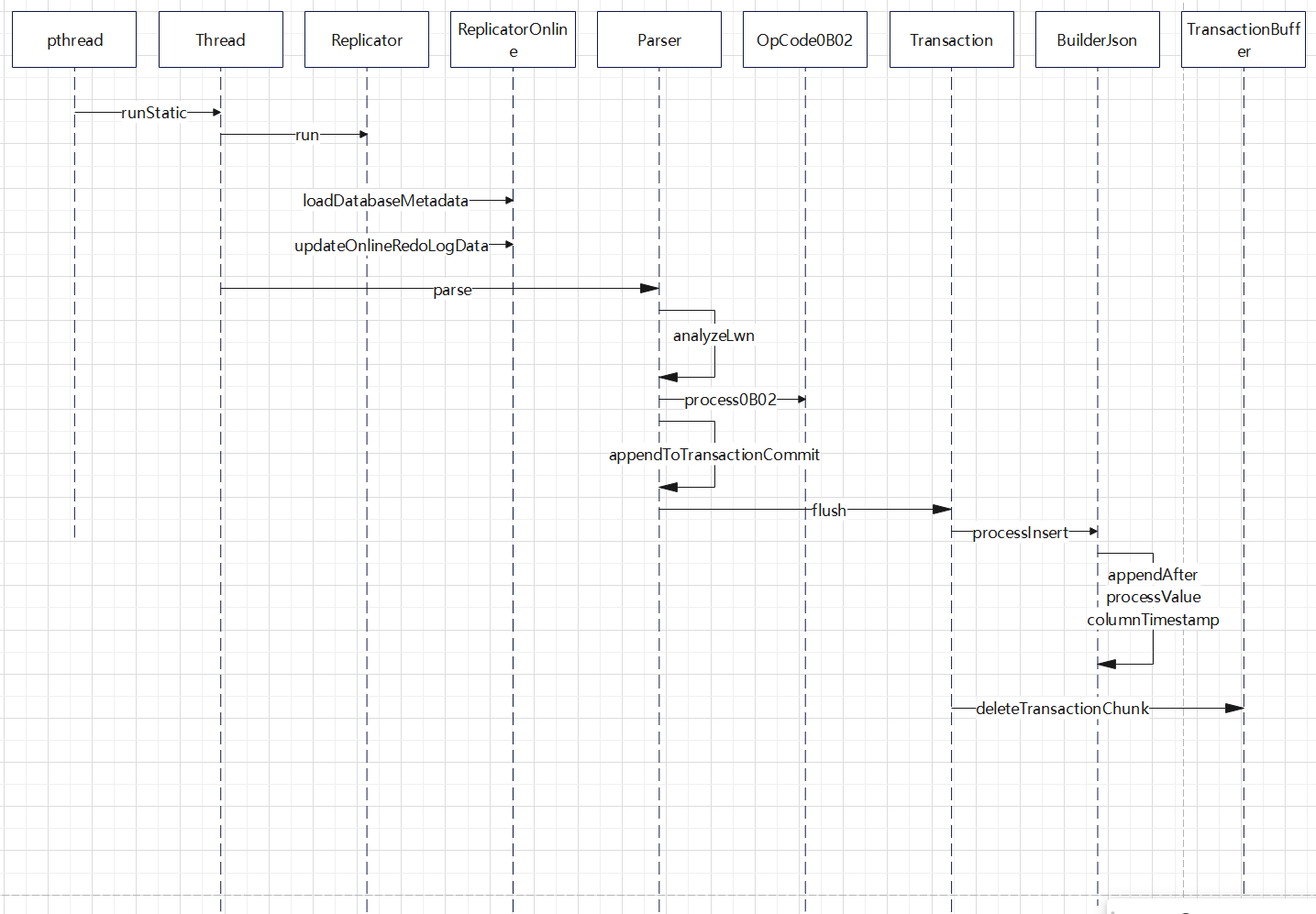
对 CDC 工具的一些改动,支持ASM 文件读取,支持 RAC 多个活跃节点,高可用等
阅读全文
2024年5月6日
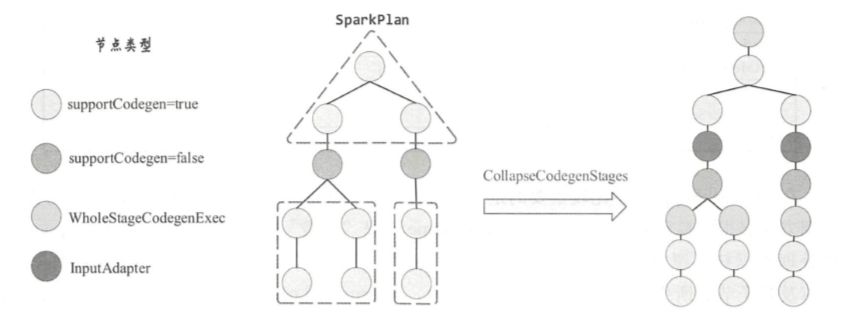
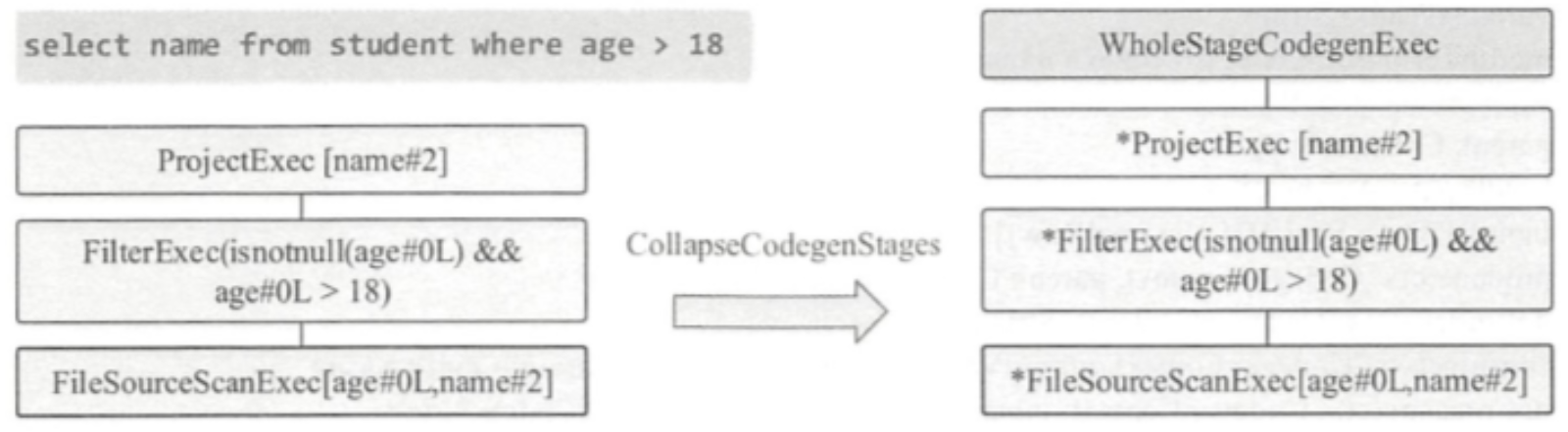
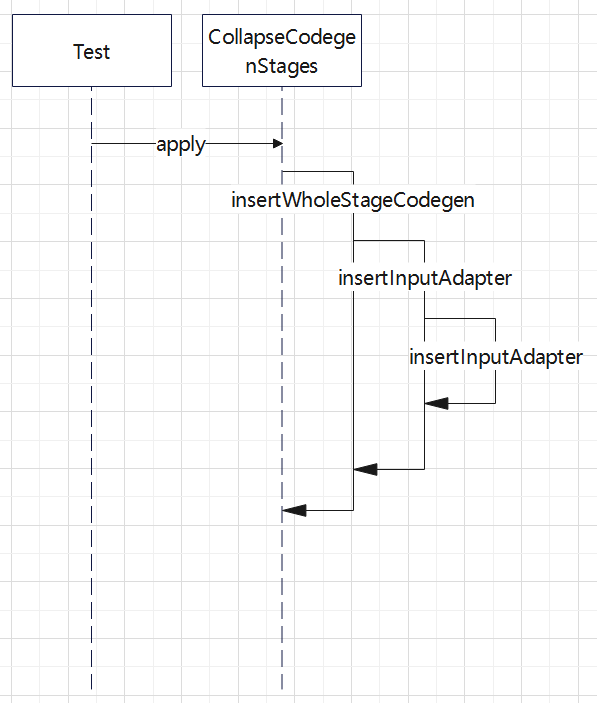
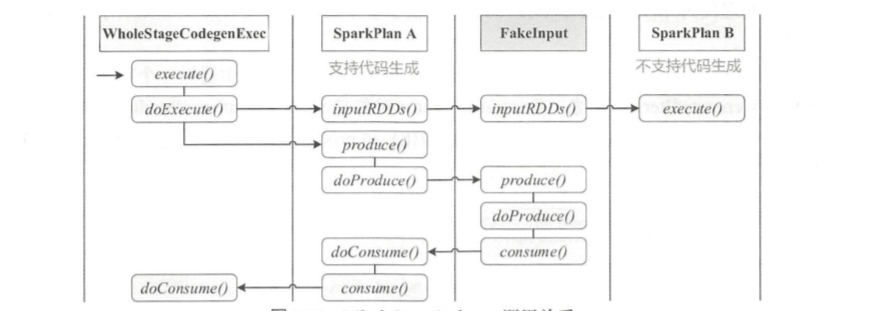
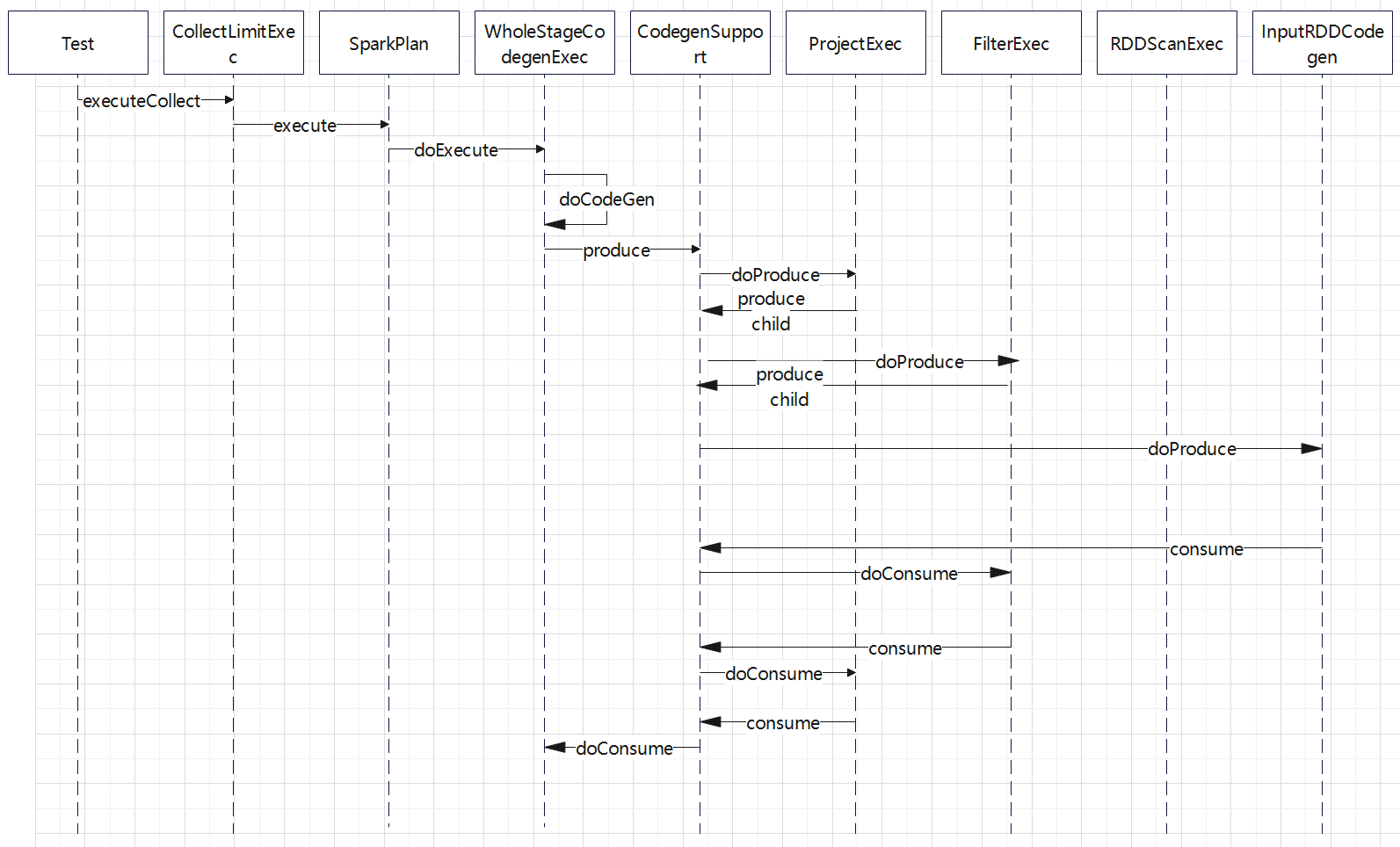
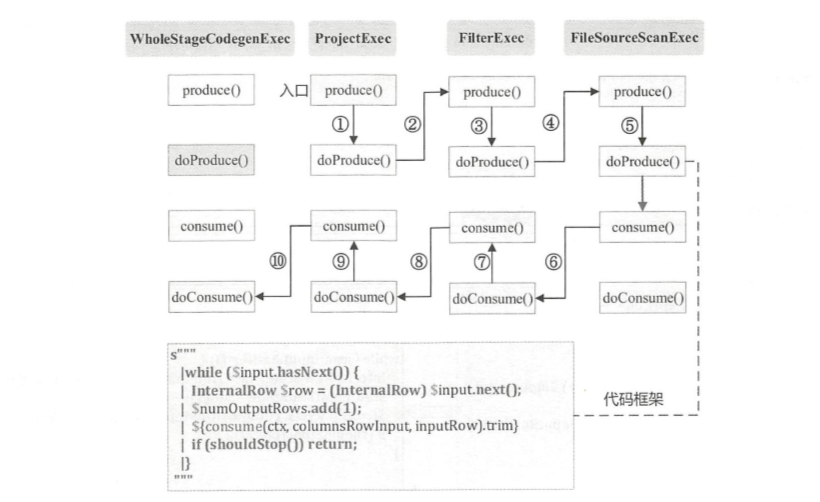
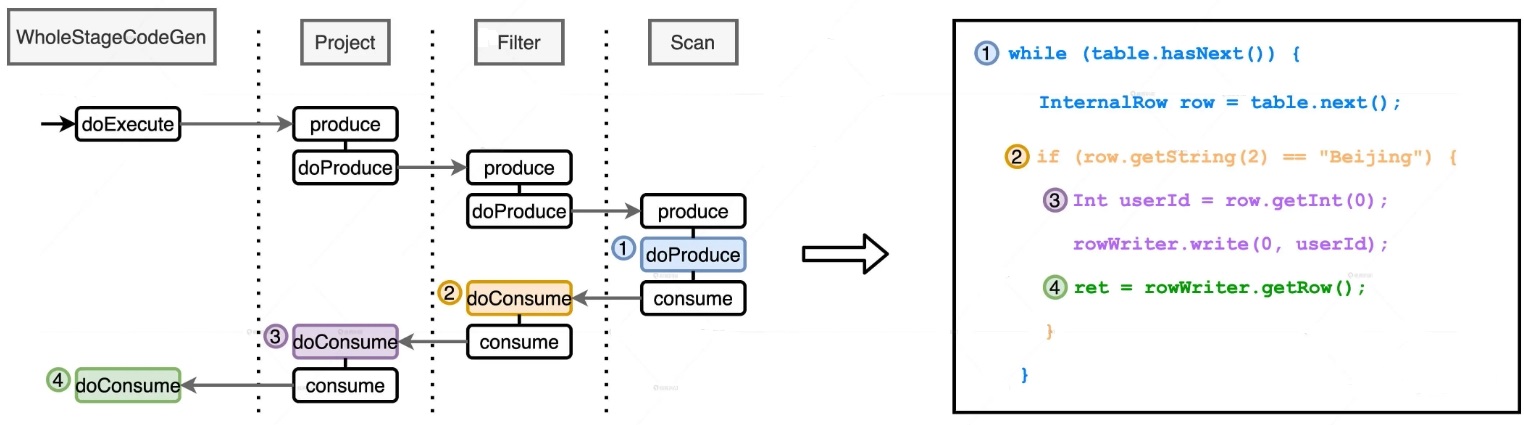
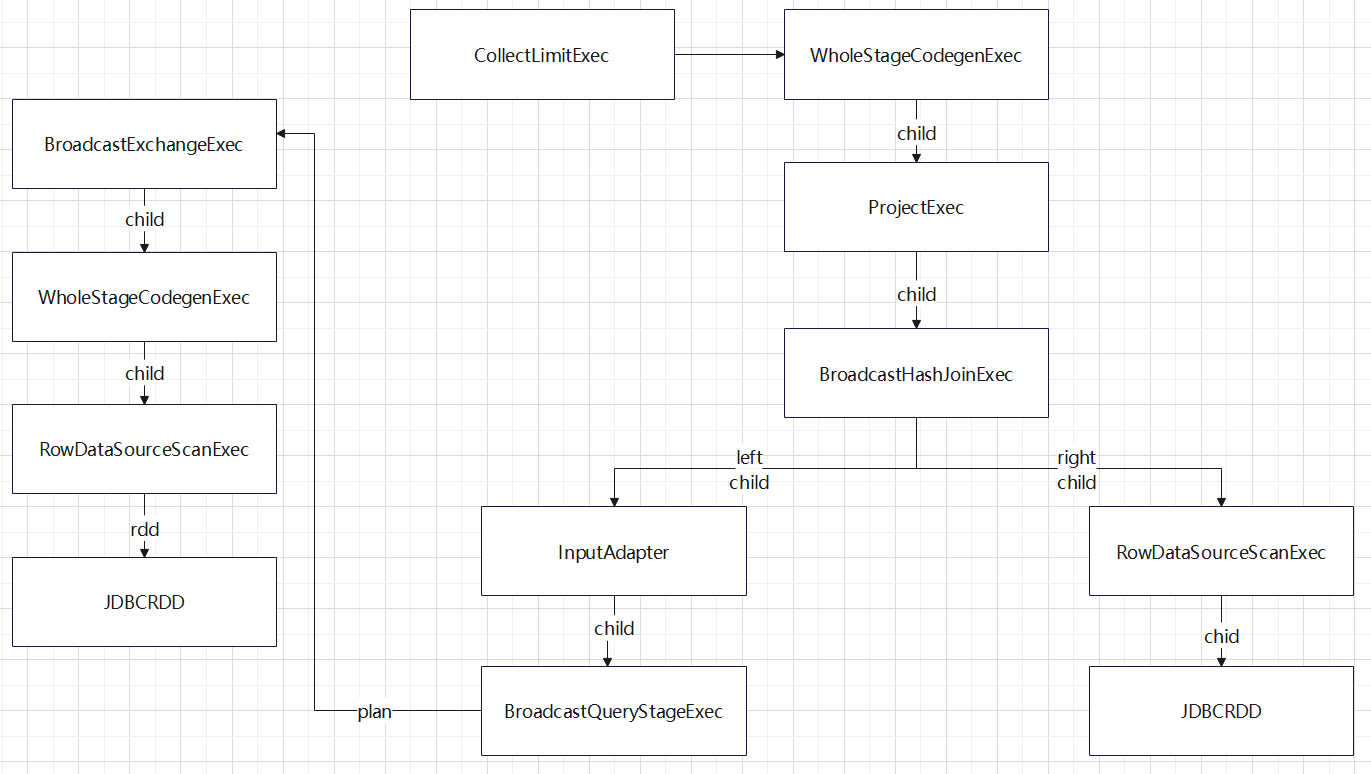
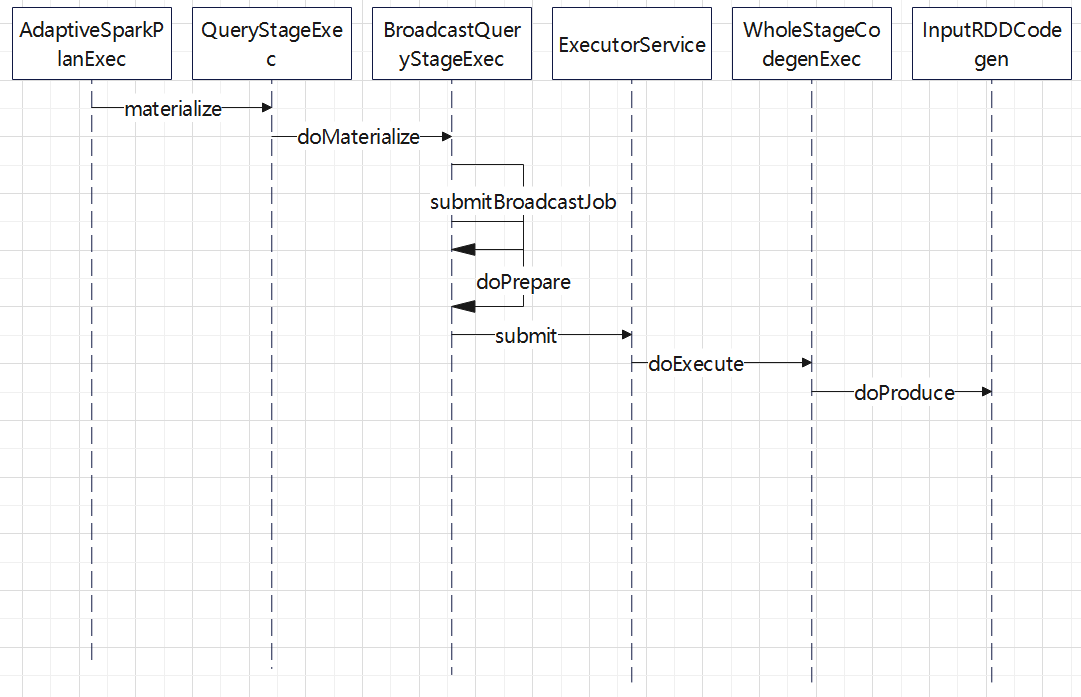
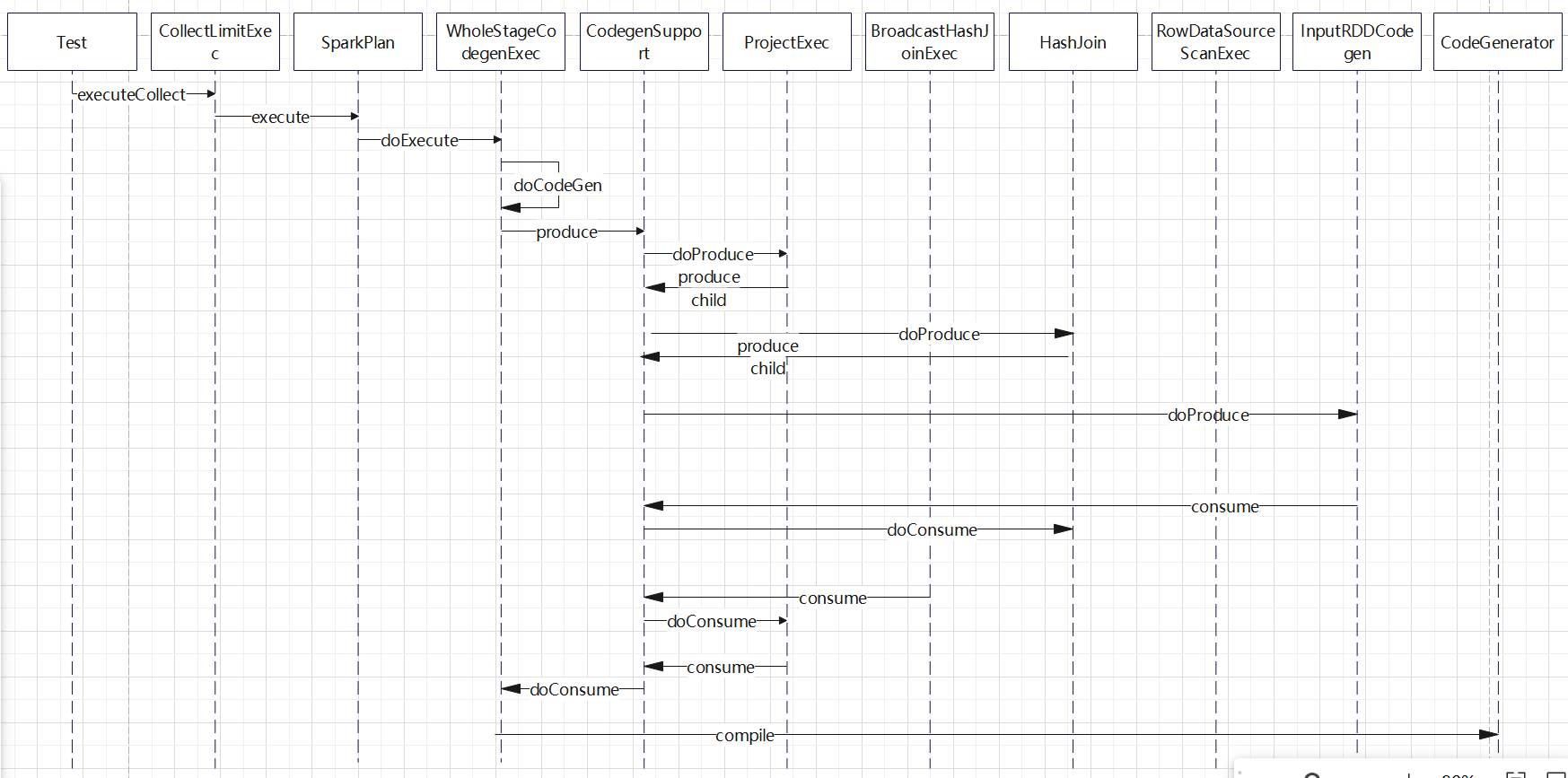
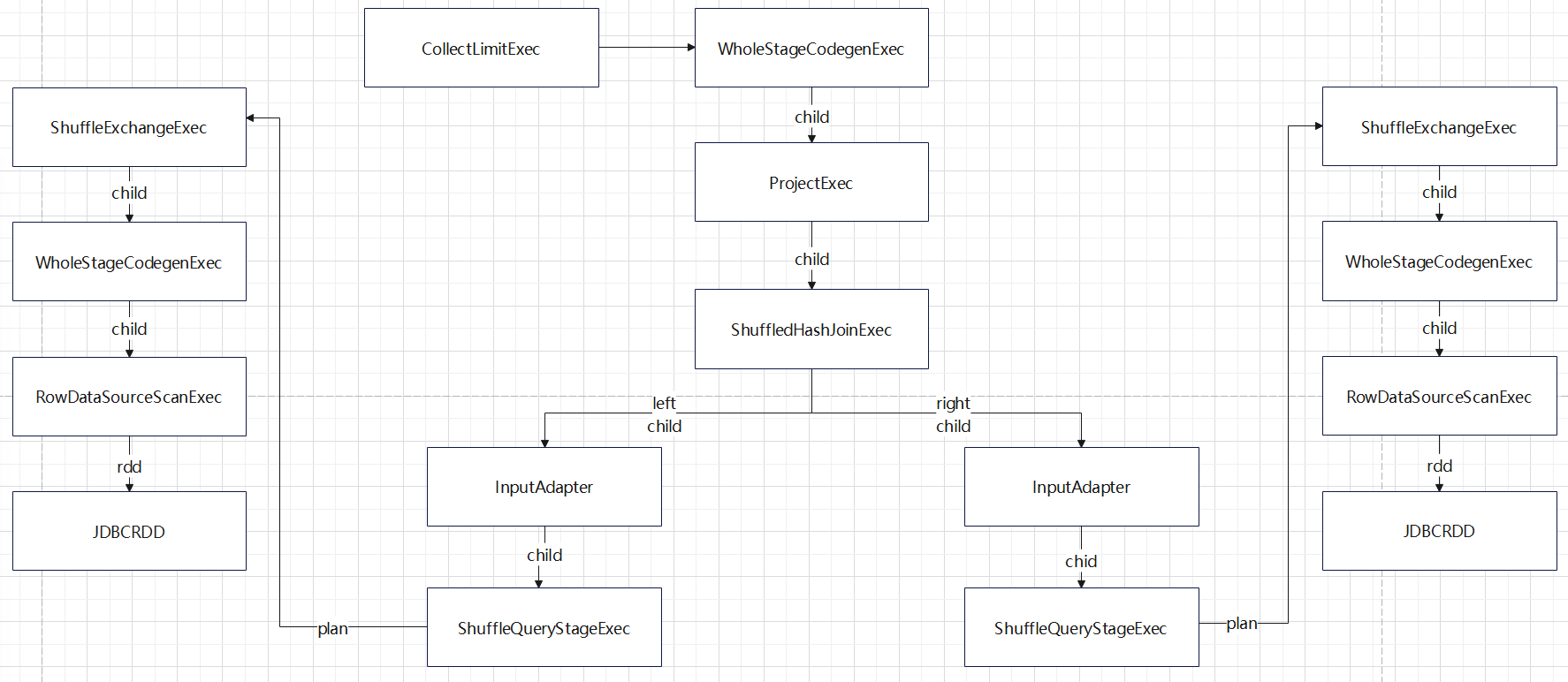
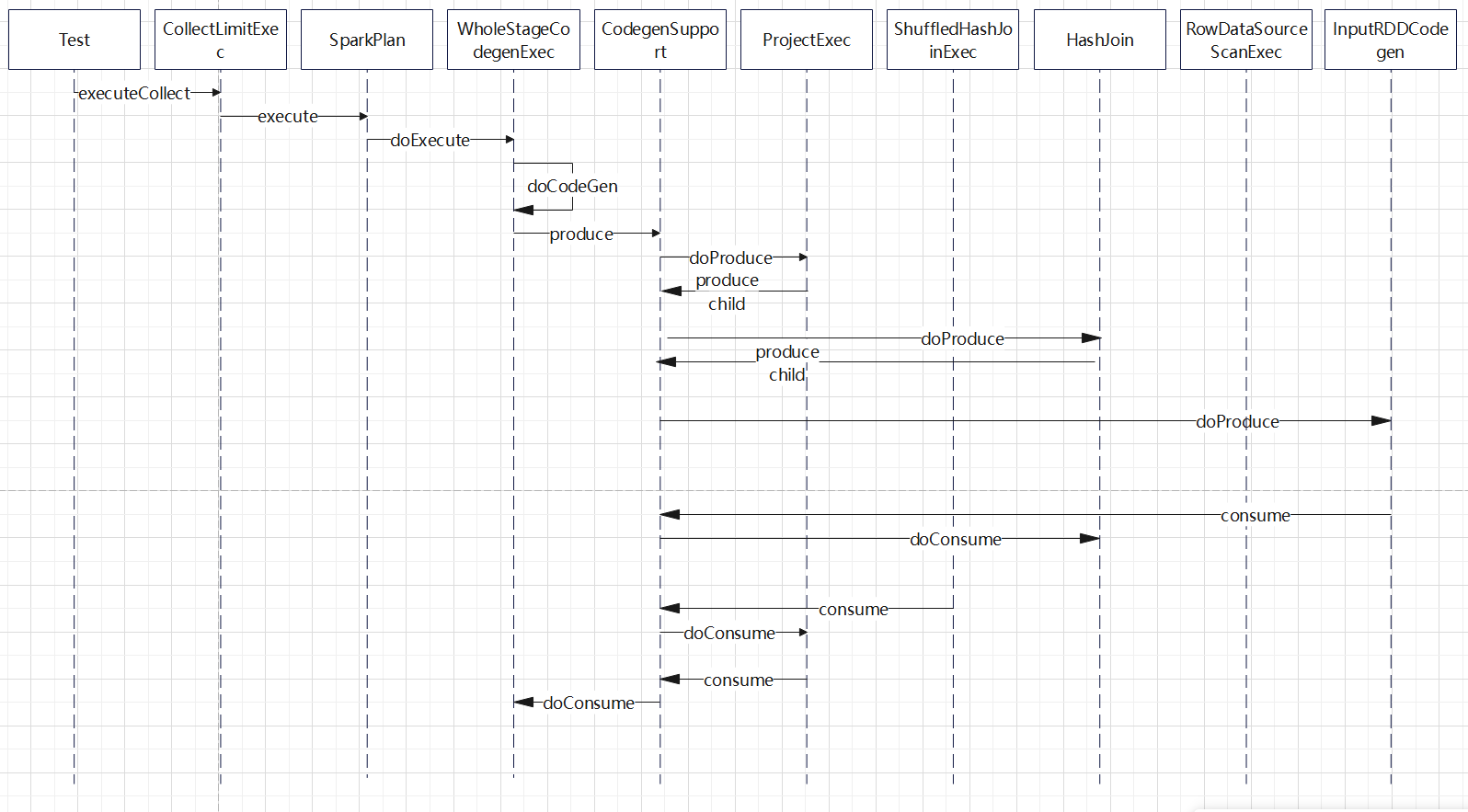
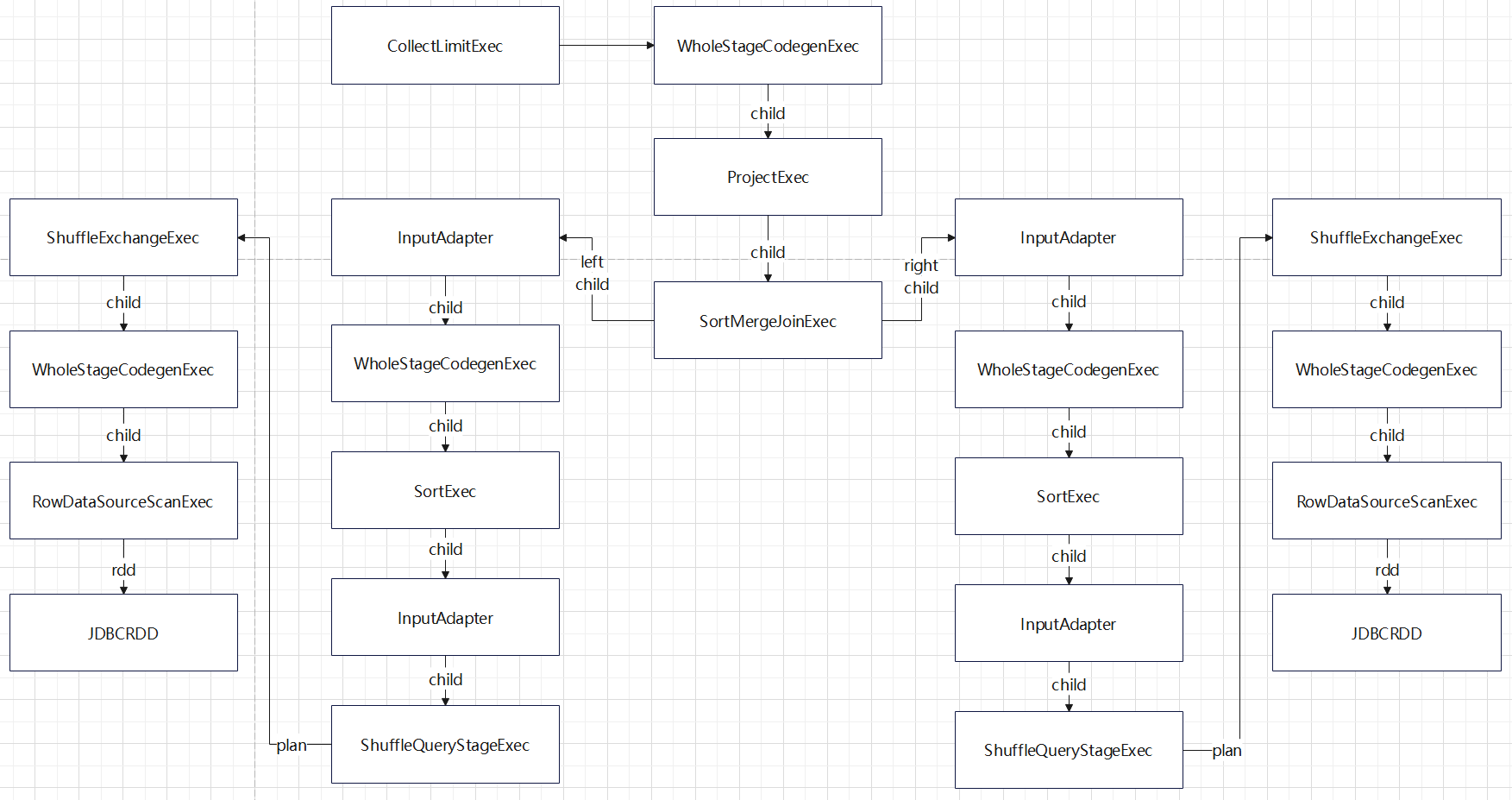
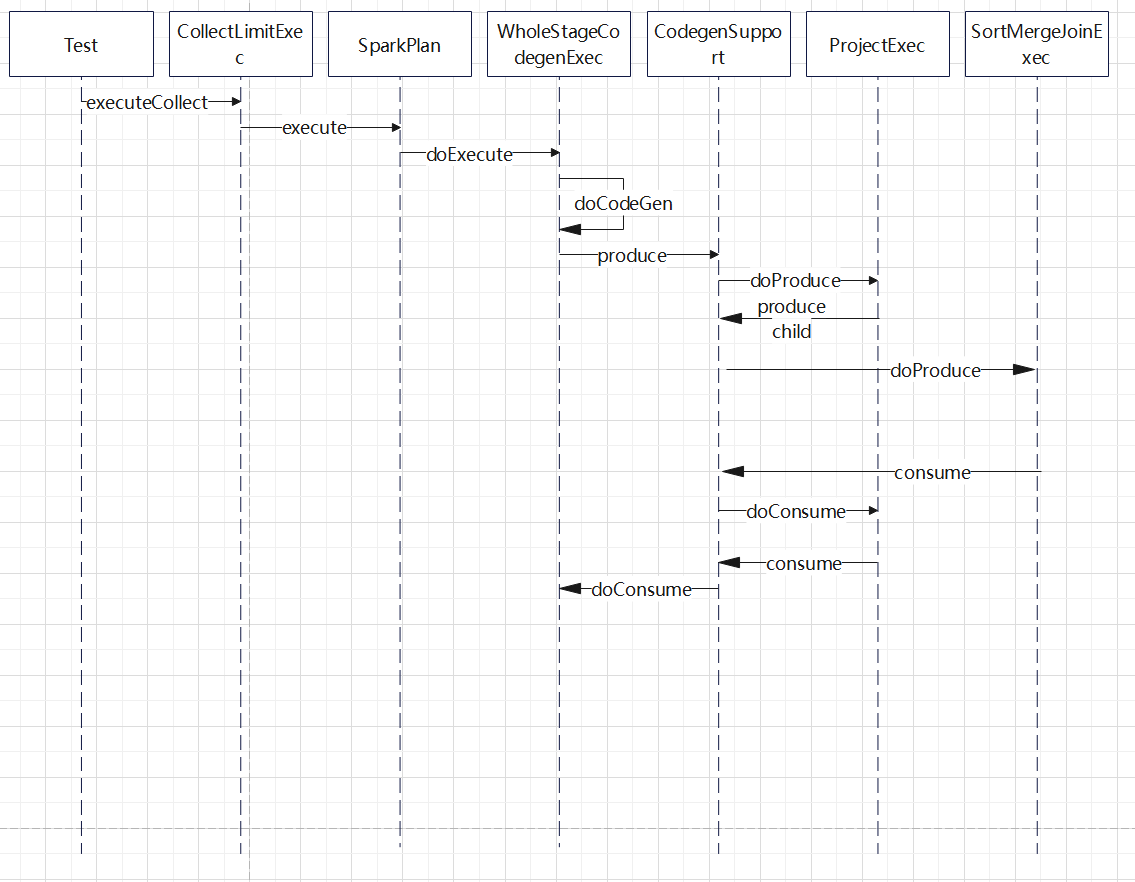
入口点:CollapseCodegenStages,插入WholeStageCodegenExec;对于不支持的,或者 SortMergeJoinExec、ShuffledHashJoinExec 会插入 InputAdapter;代码生成可以看作是两个方向相反的递归过程:代码的整体框架由 produce/doProduce 方法负责,父节点调用子节点。代码具体处理逻辑由 consume/doConsume 方法负责,由子节点调用父节点。整个物理算子树的执行过程被InputAdapter分隔开。boradcast-hash-join跟普通的bhj类似,分割部分插入了InputAdapter。shuffle-hash-join,跟 bhj 类似,只是左右两个子节点都增加了 InputAdapter,作为code-gen 的分割。sort-merge-join 左右两边都是 InputAdapter,对code-gen做了分割,之后调用SortExec 再次增加 InputAdapter,然后是shuffle逻辑,会生成5个代码片段。BroadcastNestedLoopJoin:广播+nested loop实现。CartesianProduct 没有 code-gen
阅读全文
2024年5月5日
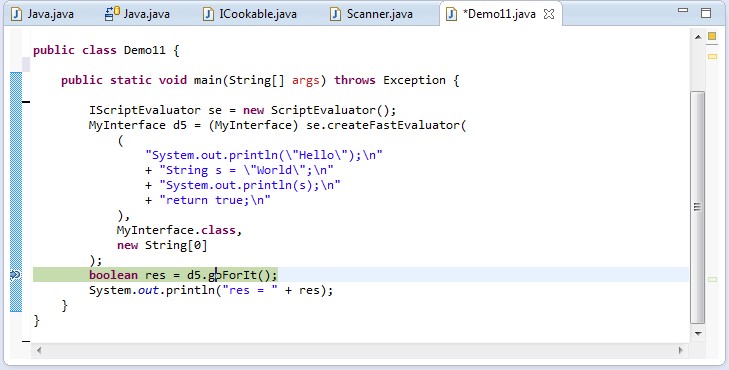
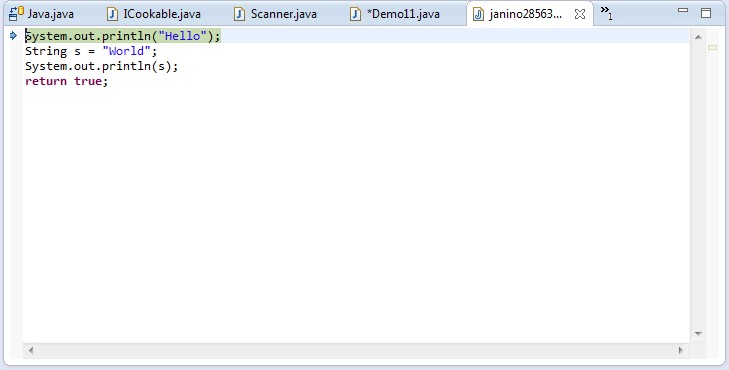
Janino的一些例子,Expression Evaluator,Script Evaluator,Class Body Evaluator,Simple Compiler,as a Source Code Class Loader,jsh - the Java shell,Compiler Plugin for Tomcat,code analysisi,debug
阅读全文