2024年1月5日
Introduce Doris,include: Data Model(Aggregate Model,Unique Model,Duplicate Model), Data Partition(Rollup),Index(Inverted Index,BloomFilter Index,NGram BloomFilter Index,Bitmap Index). Import Scenes,Import Way(Broker Load,Routine Load,Spark Load,Stream Load,MySql Load,S3 Load,Insert Into,Importing Data in JSON Format,Min Load Replica Num),Export,Update and Delete
阅读全文
2023年12月9日
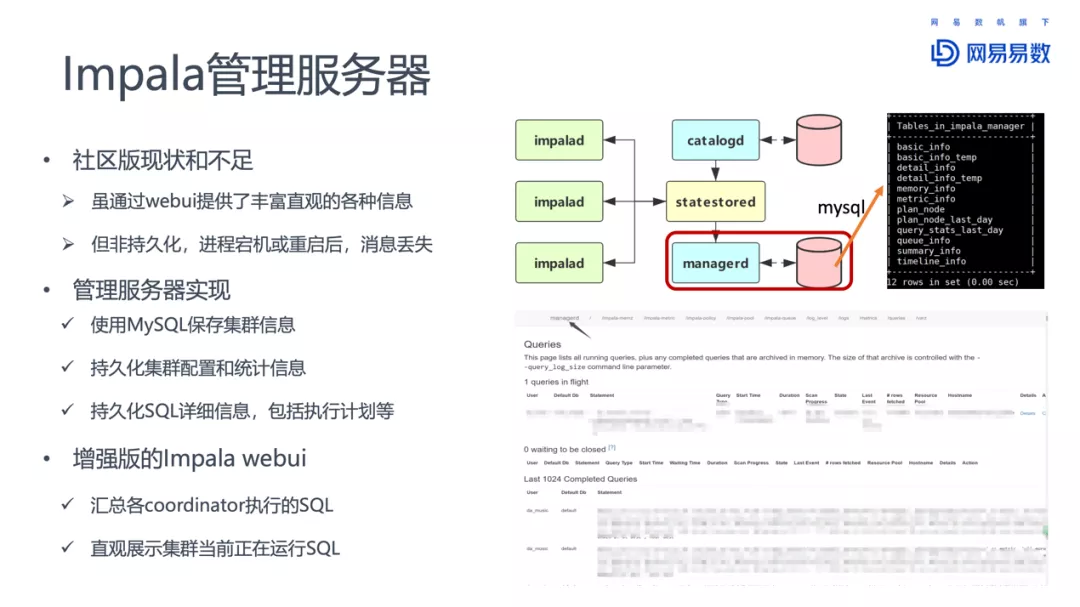
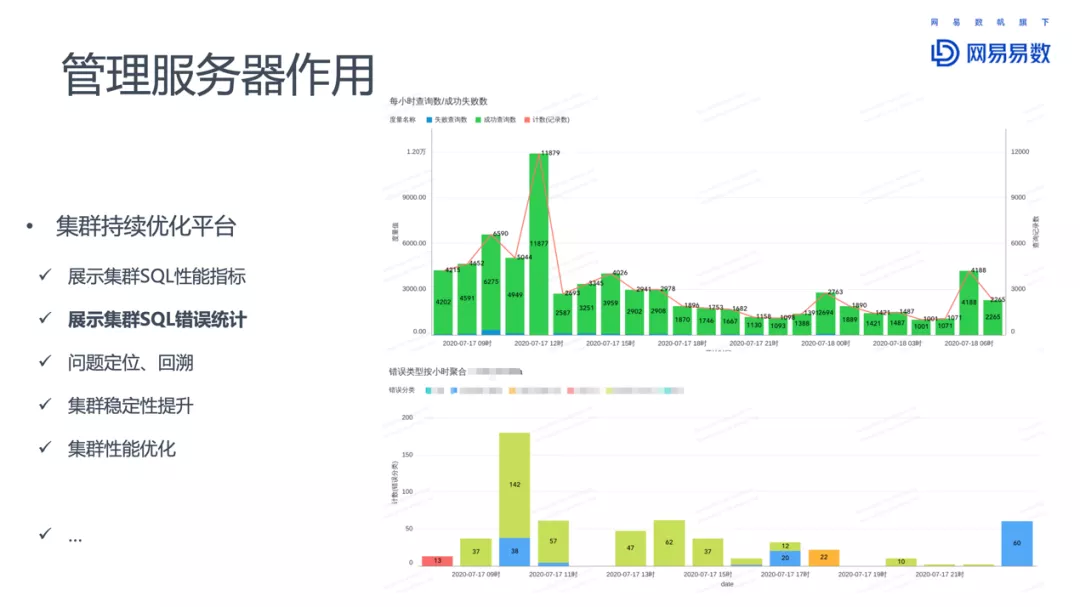
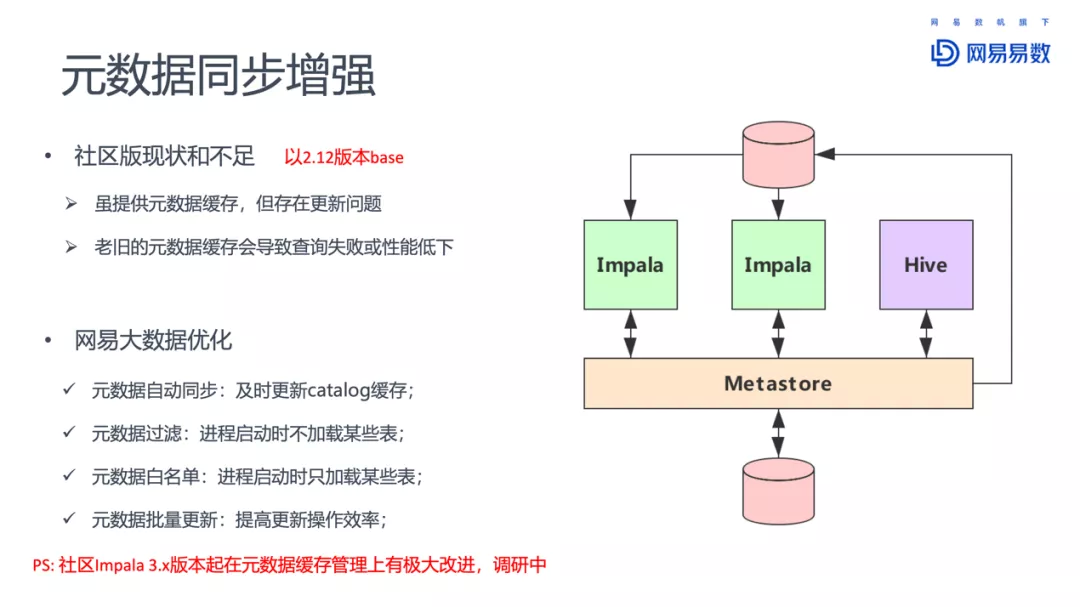
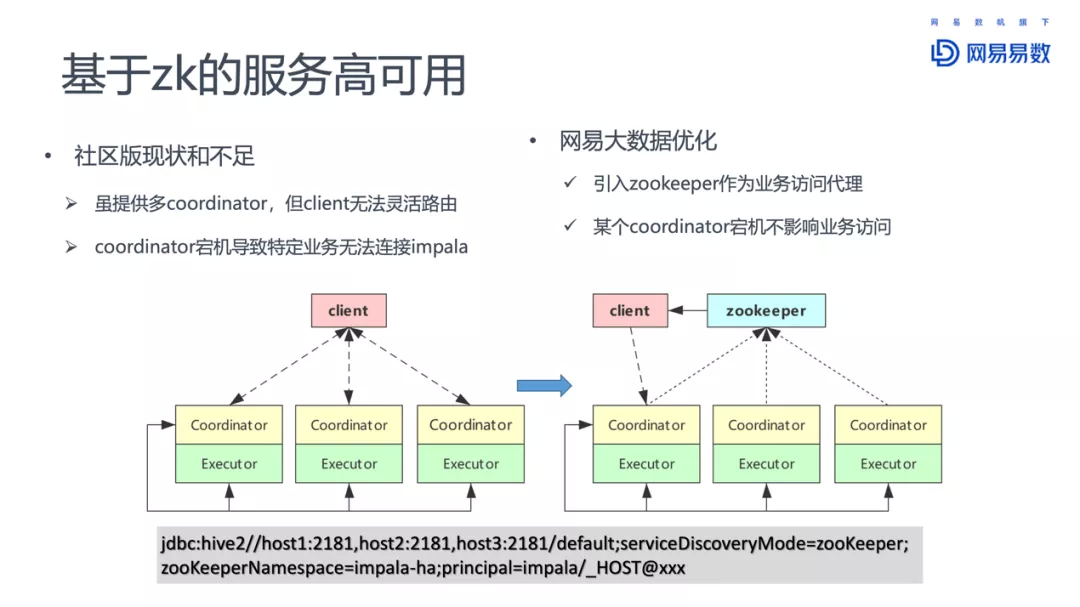
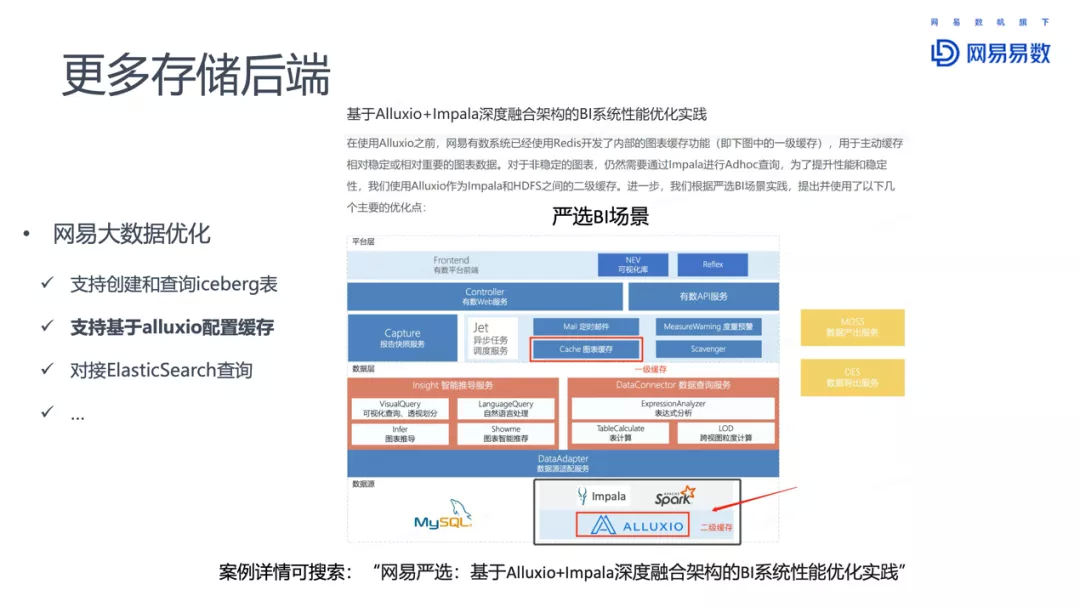
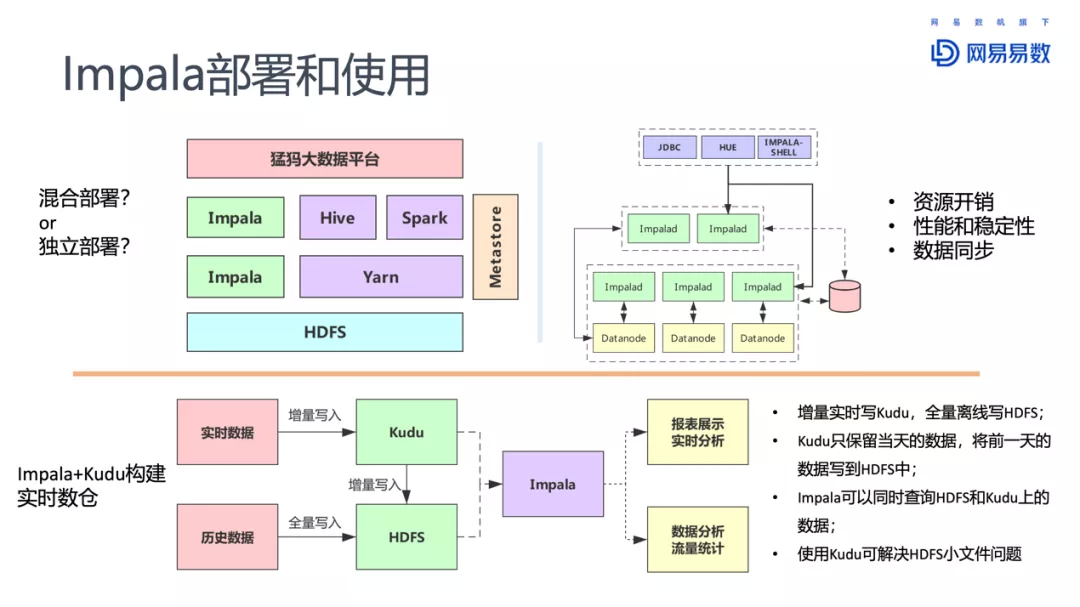
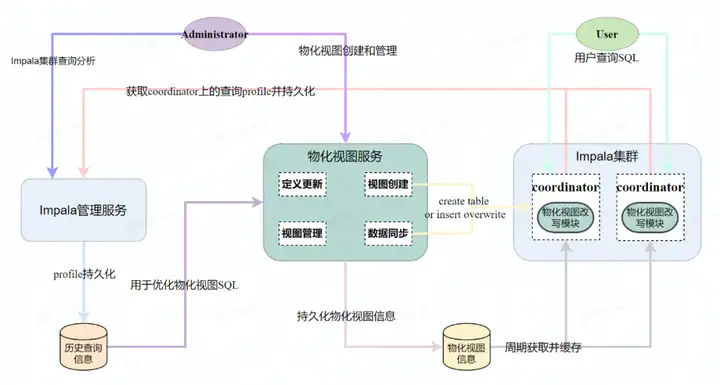
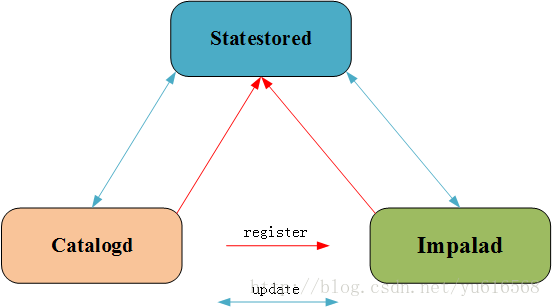
Impala在网易的一些使用,包括元数据同步增强、基于ZK的高可用、支持更多的后端、HBO和查询持久化、K8S部署、物化视图、虚拟数仓、完善的监控和报警系统
阅读全文
2023年12月1日
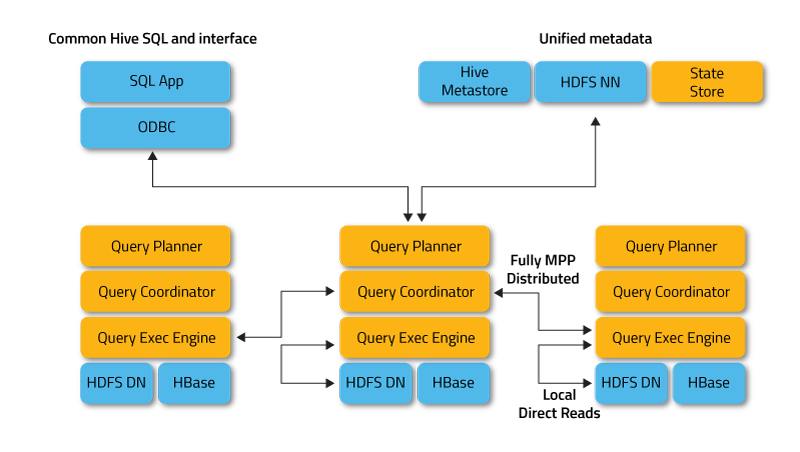
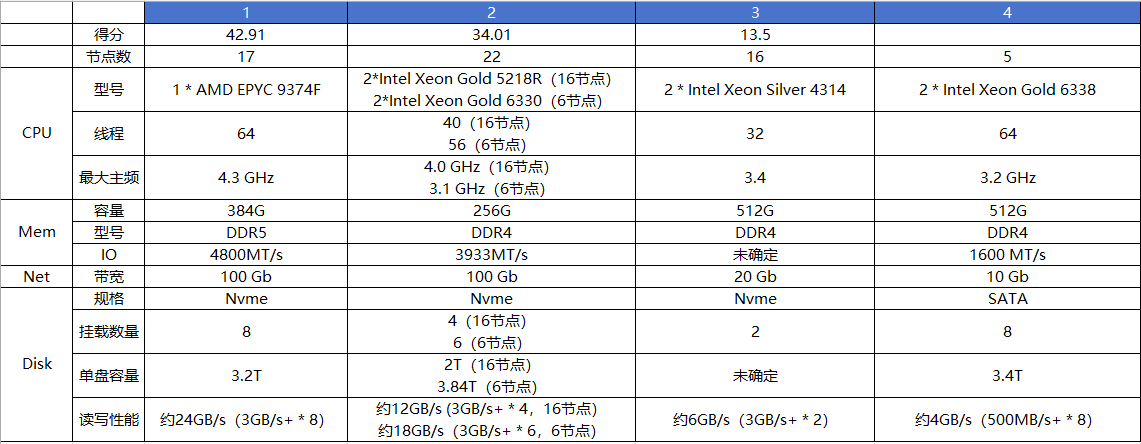
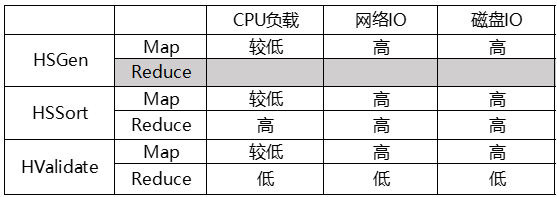
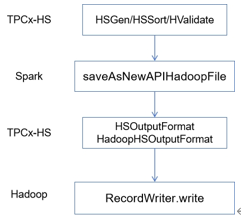
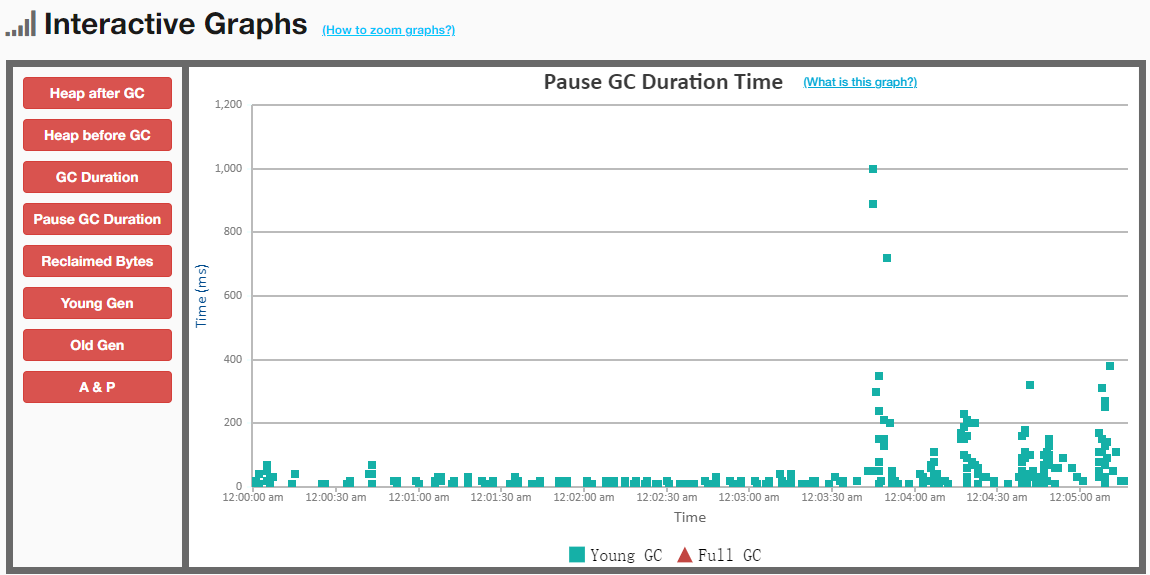
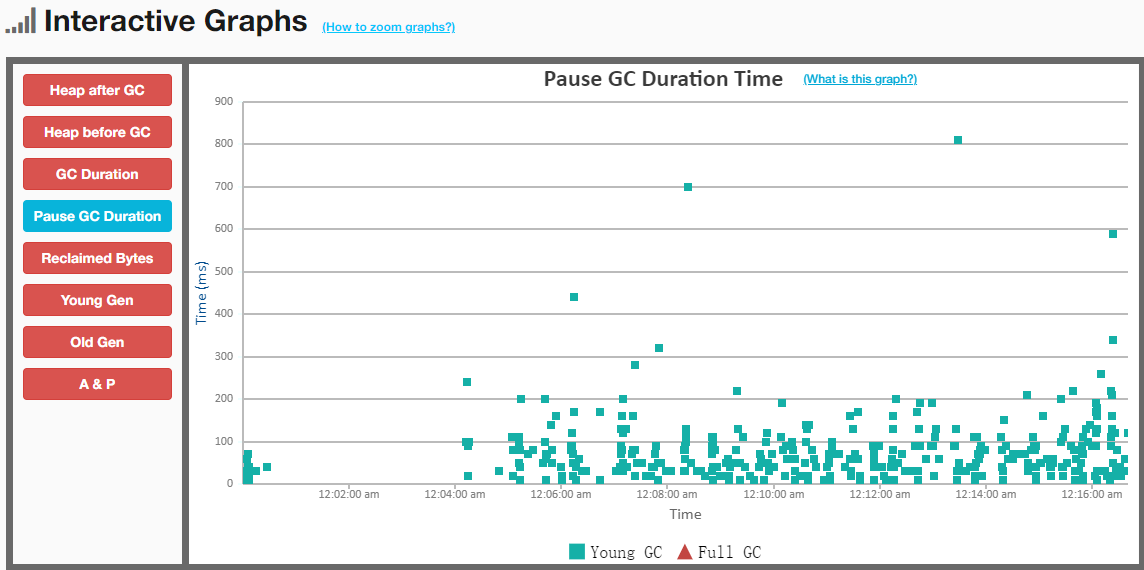
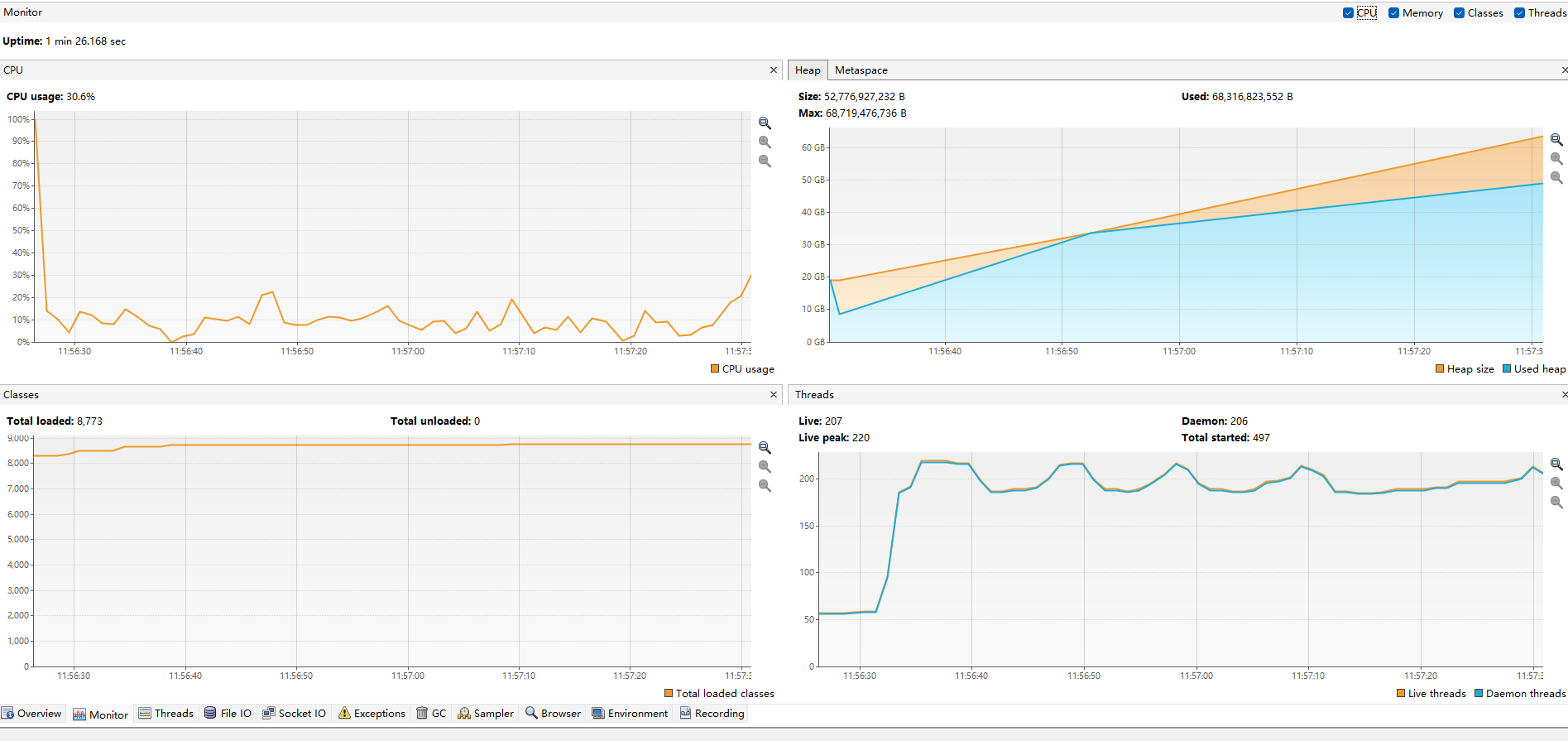
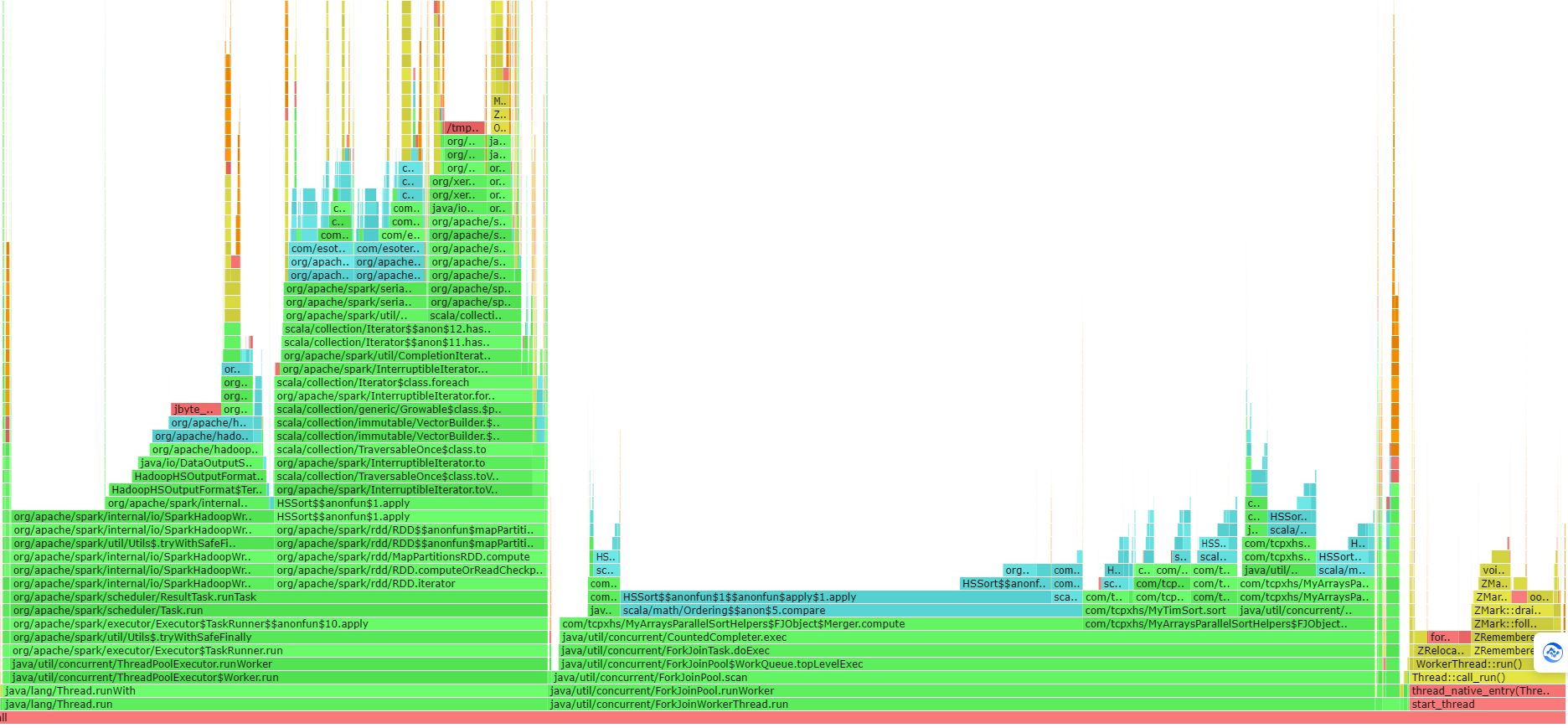
Impala Tuning, Architecture. tunning: join,statistics,cache,coordinators,web ui. admission control,administration configuration,security. SQL Statements and Data Type, built-in functions,udf, explain commands, file formats, Supported table and storage
阅读全文
2023年11月19日
从谷歌的三篇论文到Hadoop的诞生,再是各种开源产品依次出现,Hive对MapReduce的易用性改进,三大Hadoop 供应商,谷歌新三篇论文诞生了交互式查询(三大供应商推出)以及各种开源存储格式,Spark的出现和各种流处理系统,Netflix也证明了云的强大,流批一体以及各种分布式调度系统,基于云的数仓产品出现,HDFS替换上云、容器化出现、全托管数仓Modern Data Stack、深度学习对Hadoop的影响,三大供应商被收购,三大开放表格存储的出现,几个元数据管理产品,几个新的调度框架,LakeHouse的出现以及相关类似云产品
阅读全文
2023年10月7日
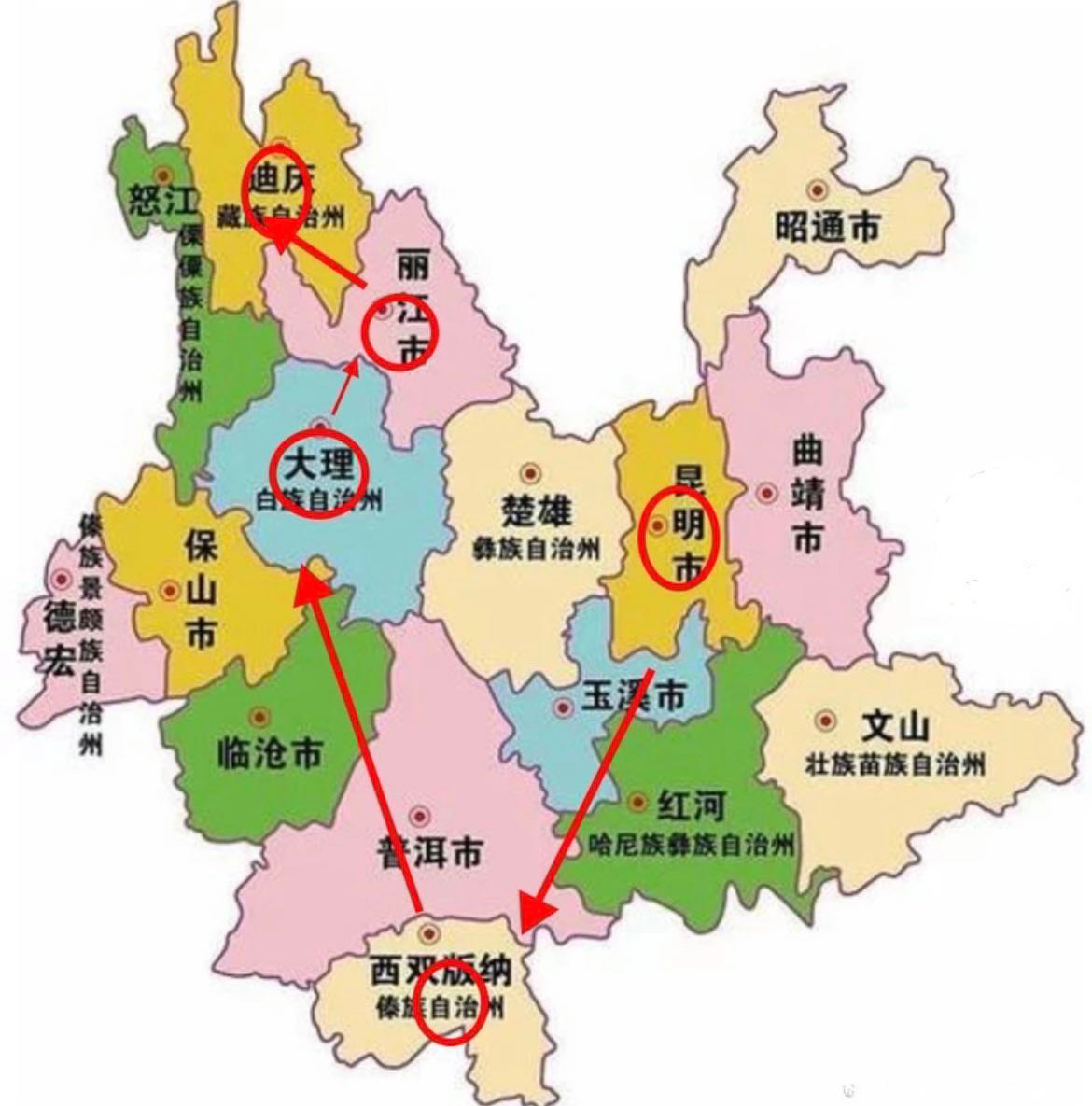
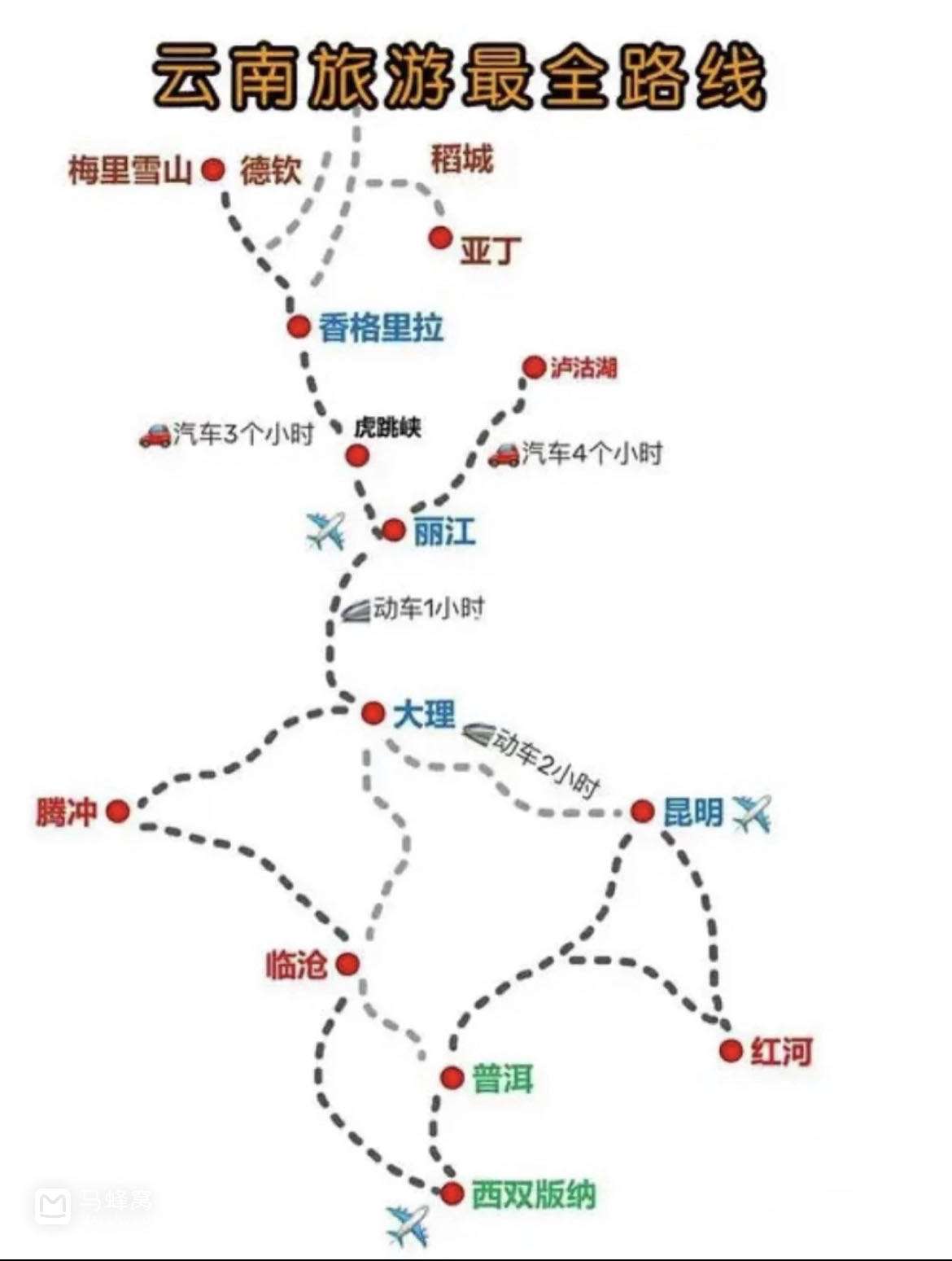
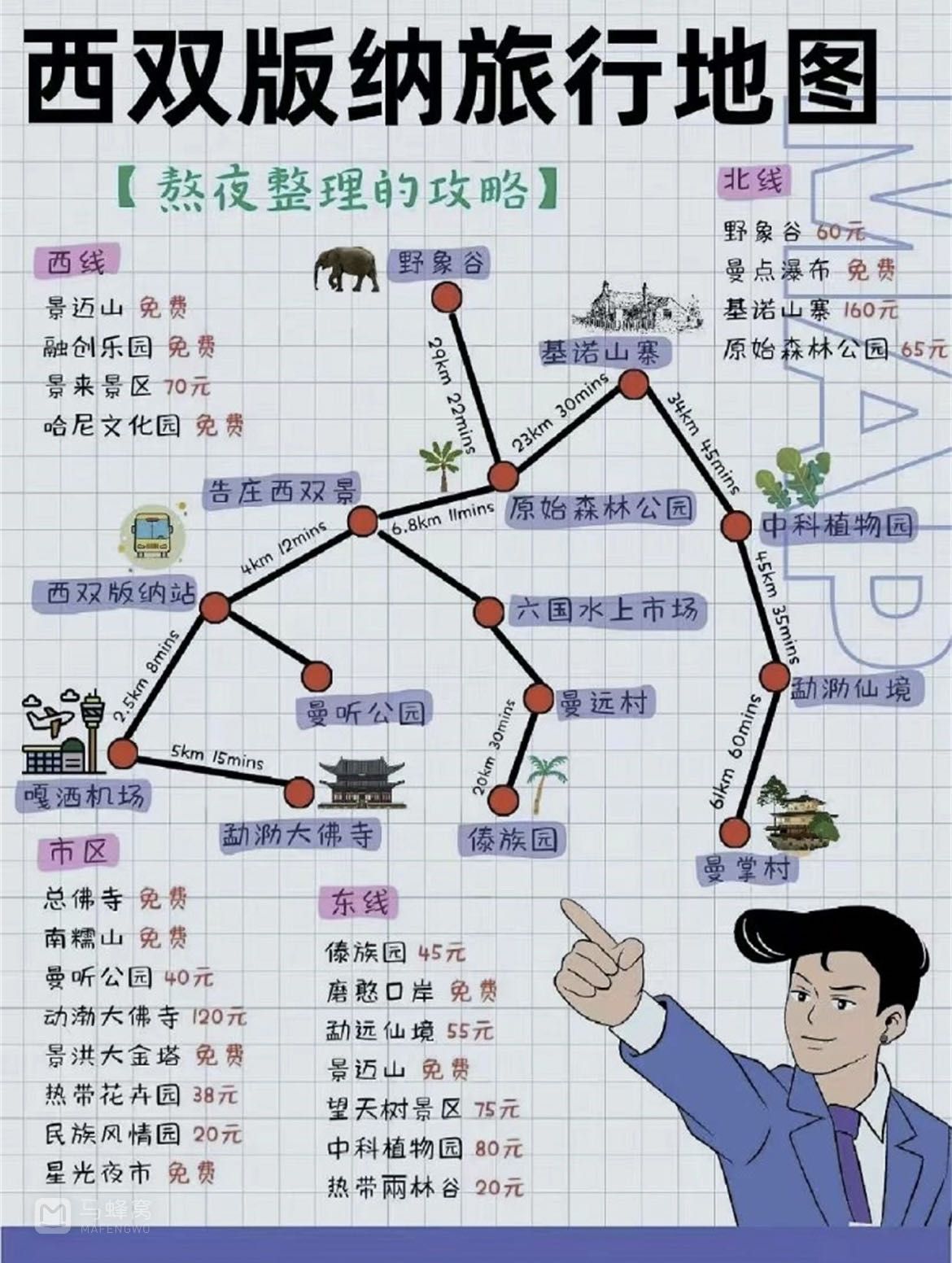
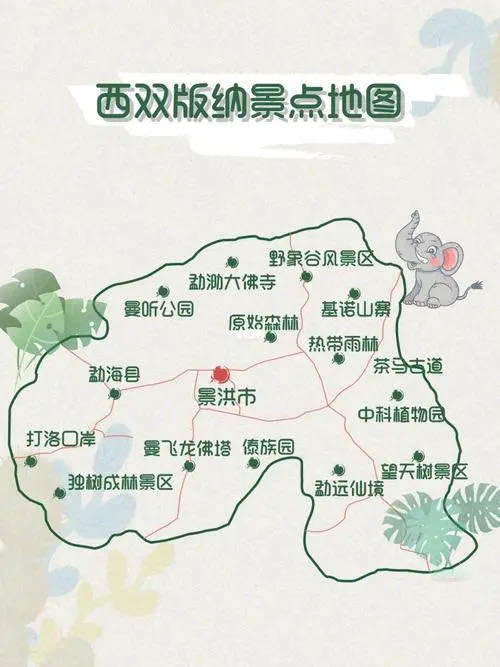
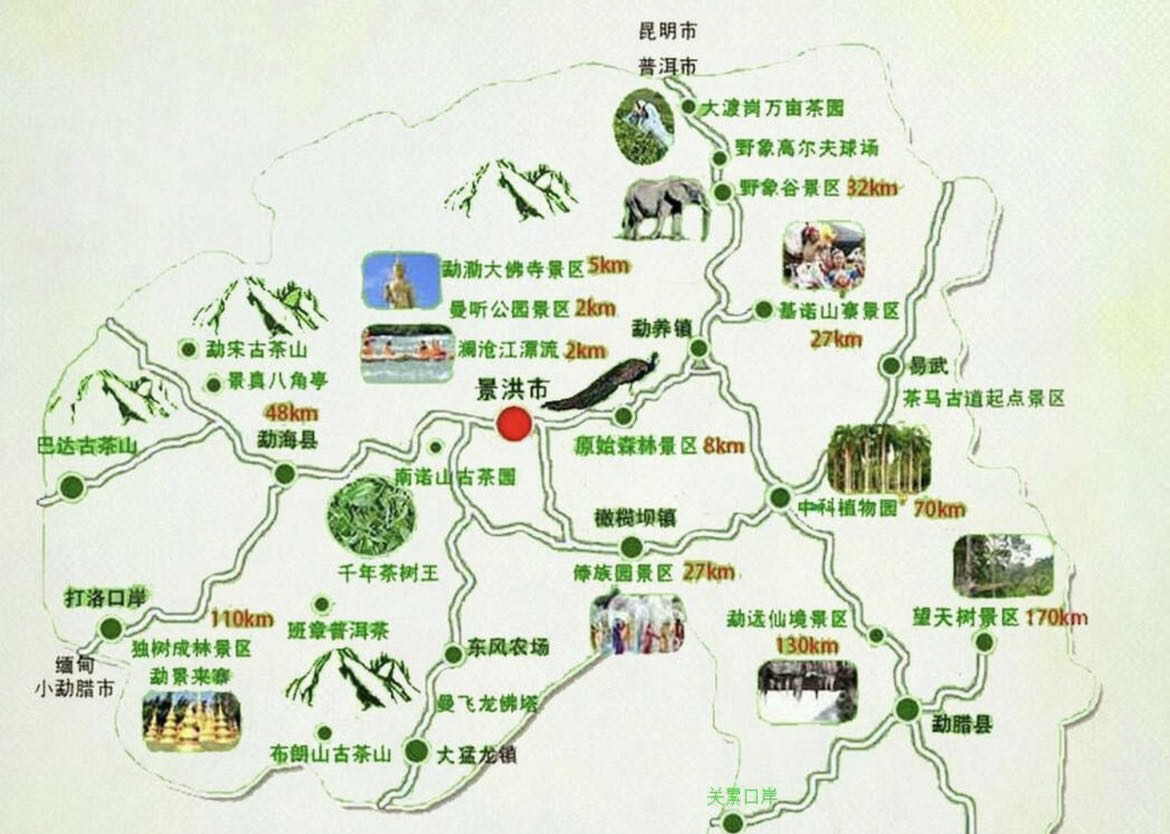
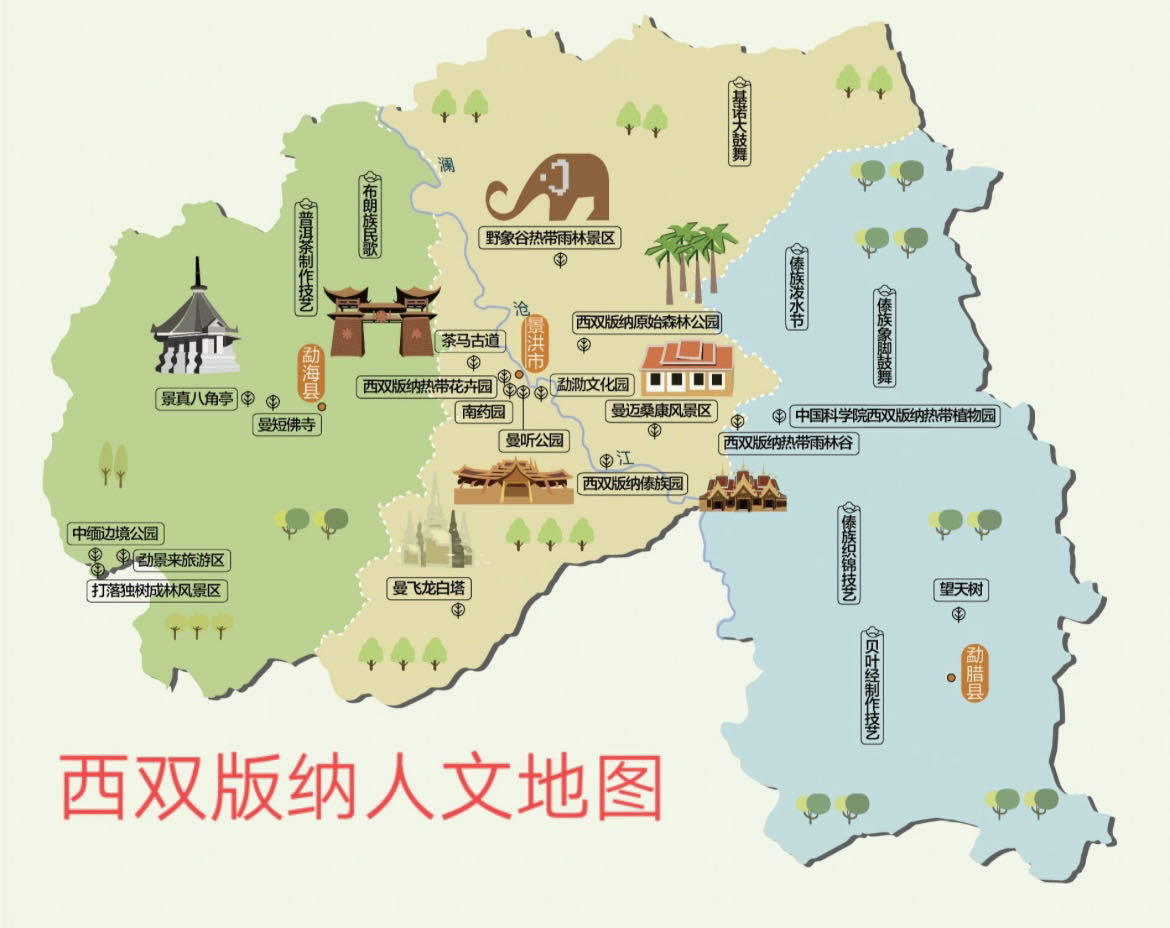
西双版纳游记,去了北线:曼掌村、原始森林公园、野象谷;东线:曼远村、中科院植物园、傣族园;市内的:江边夜市、星光夜市、曼听公园、总佛寺、勐腊旅游文化区、般若寺、六国水上市场
阅读全文
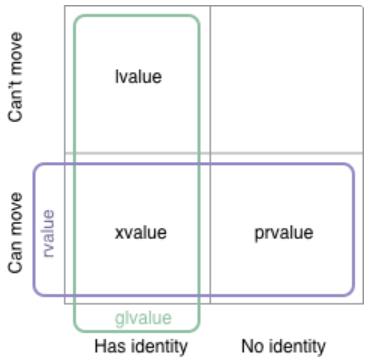
2023年9月17日
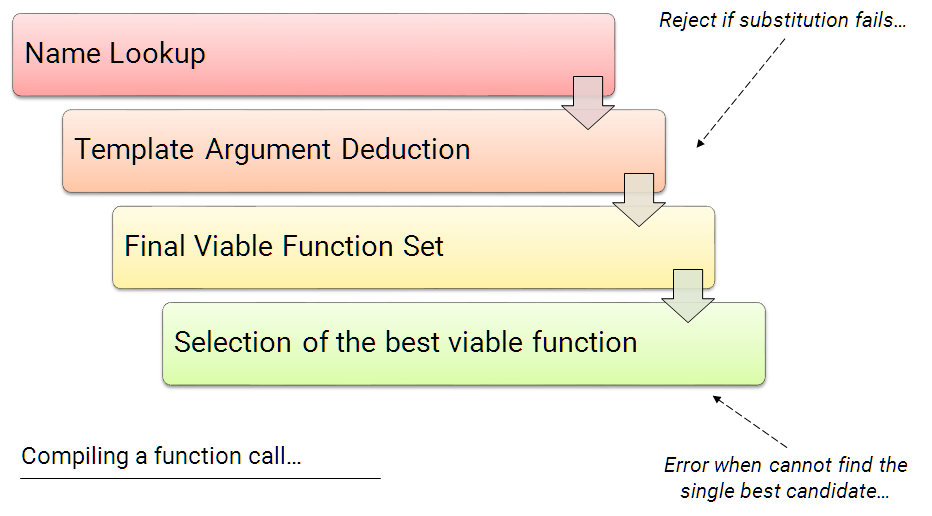
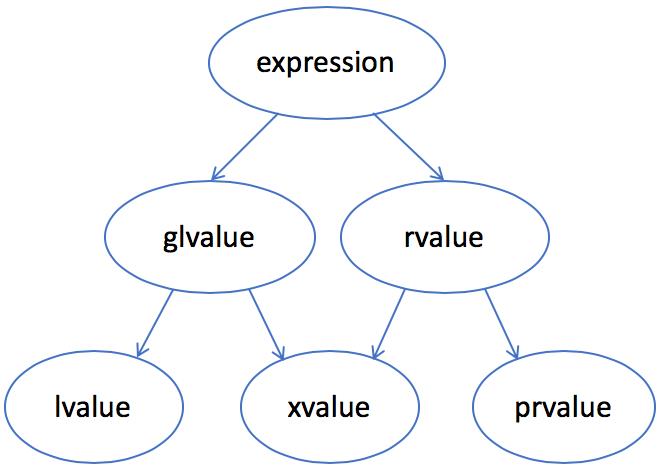
左值、右值、移动语义,std::move, std::forward 等一些基本概念
阅读全文