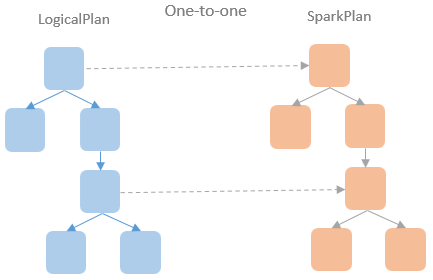
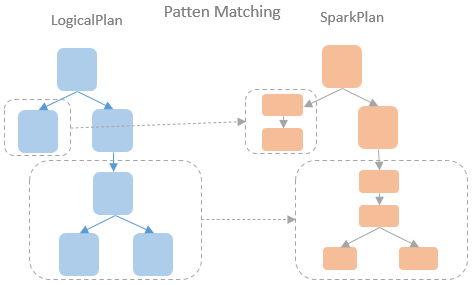
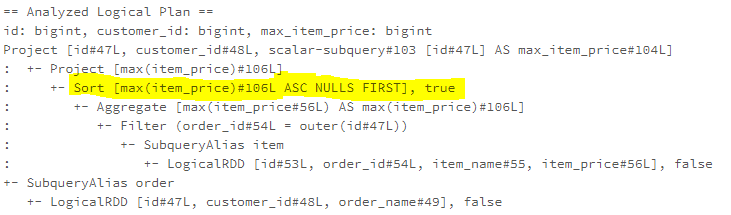
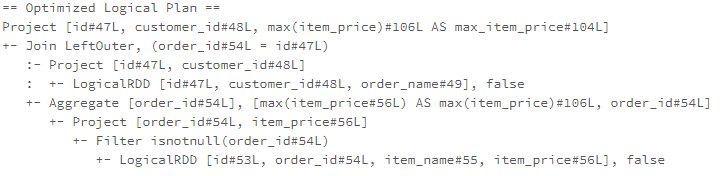
2024年4月27日
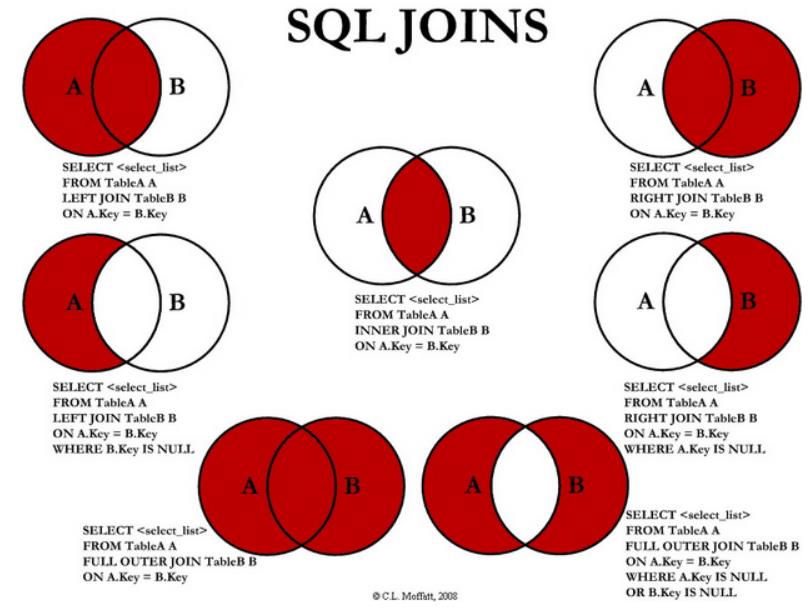
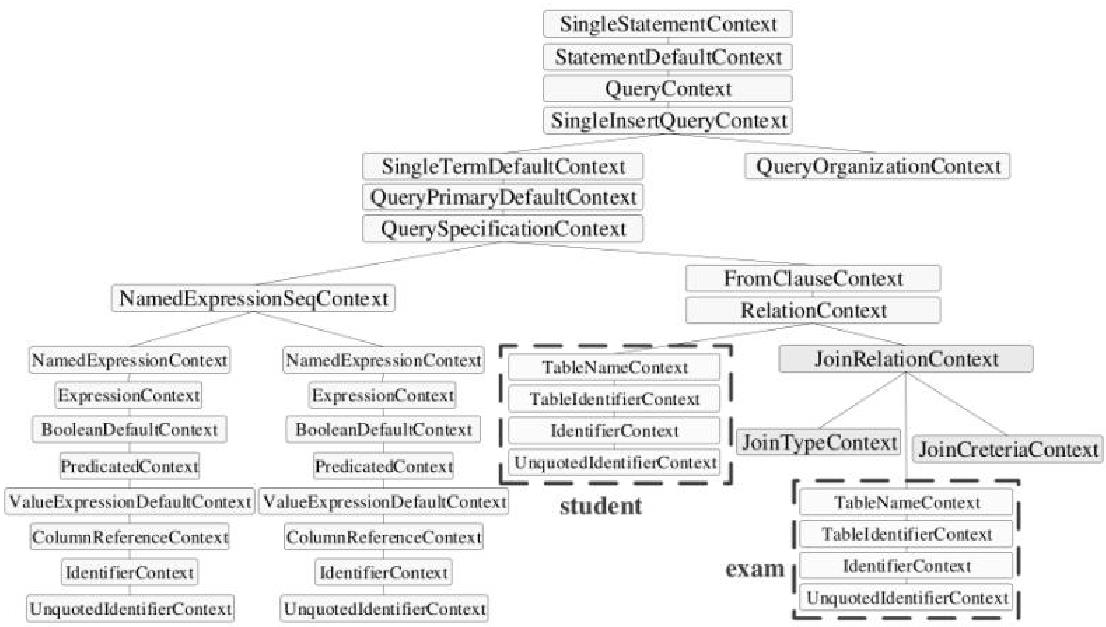
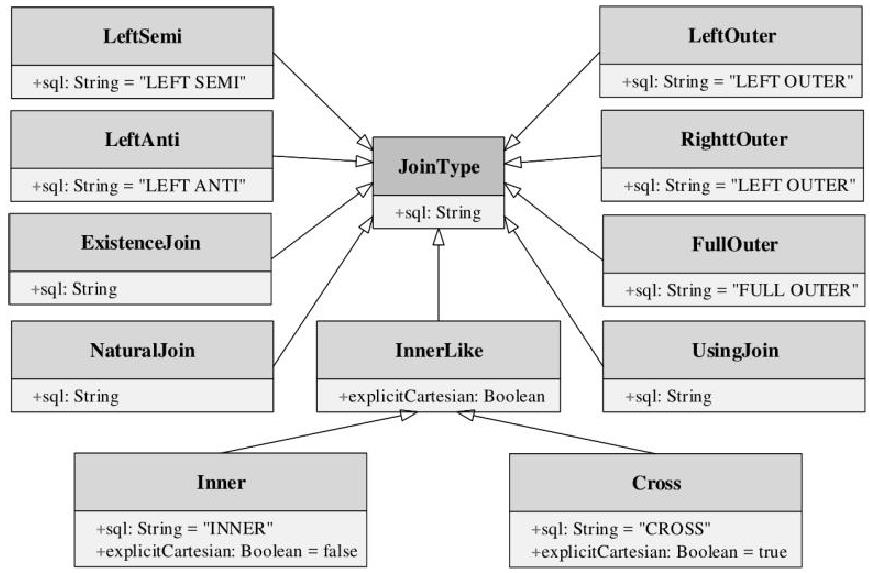
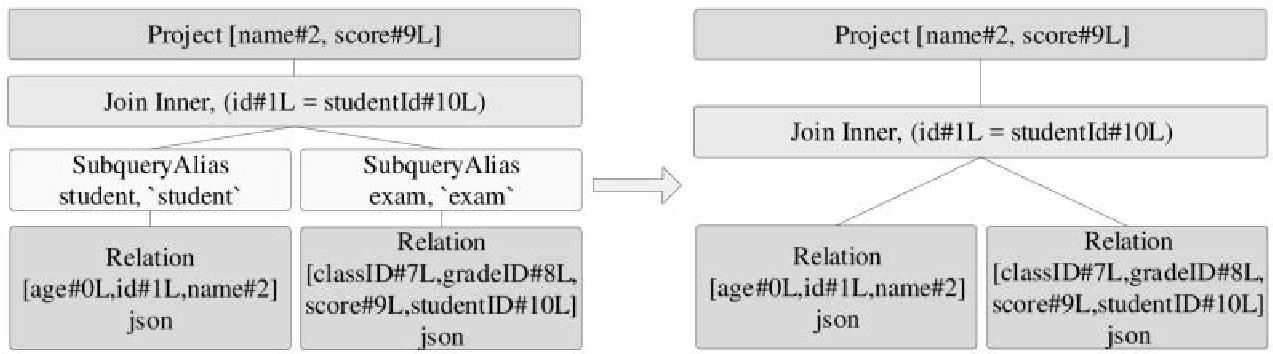
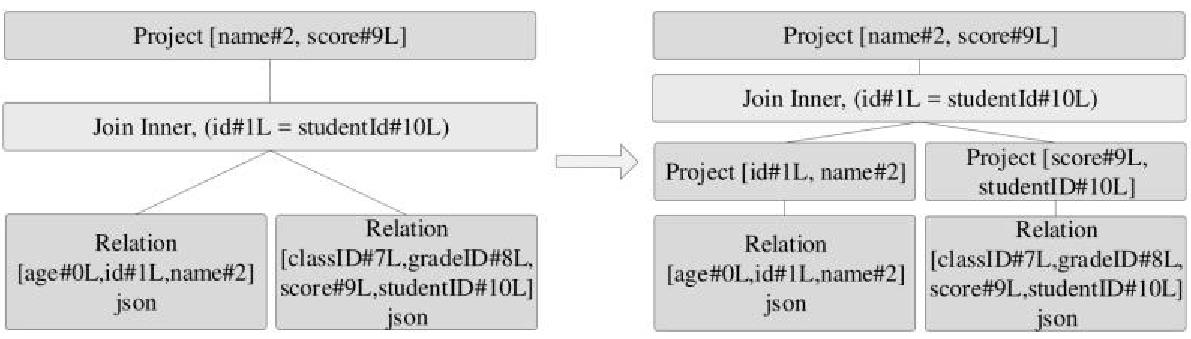
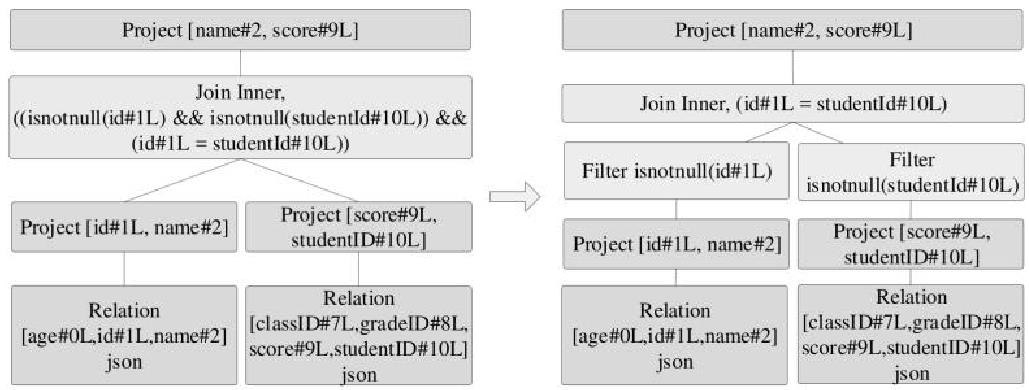
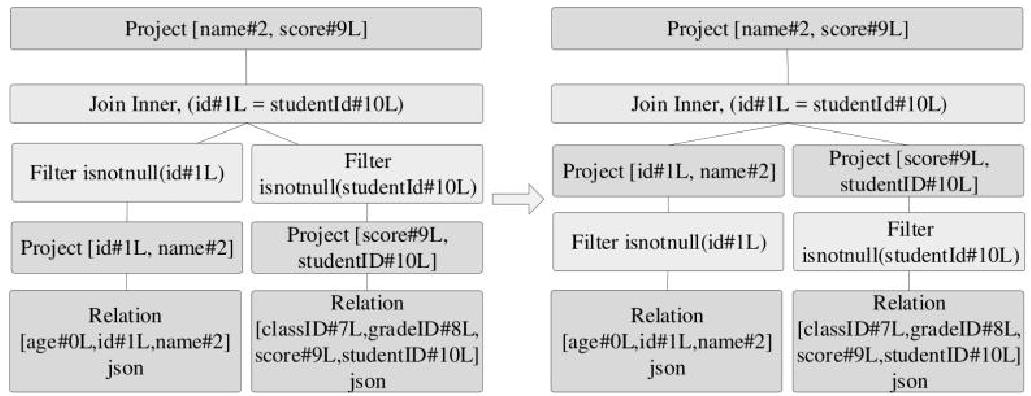
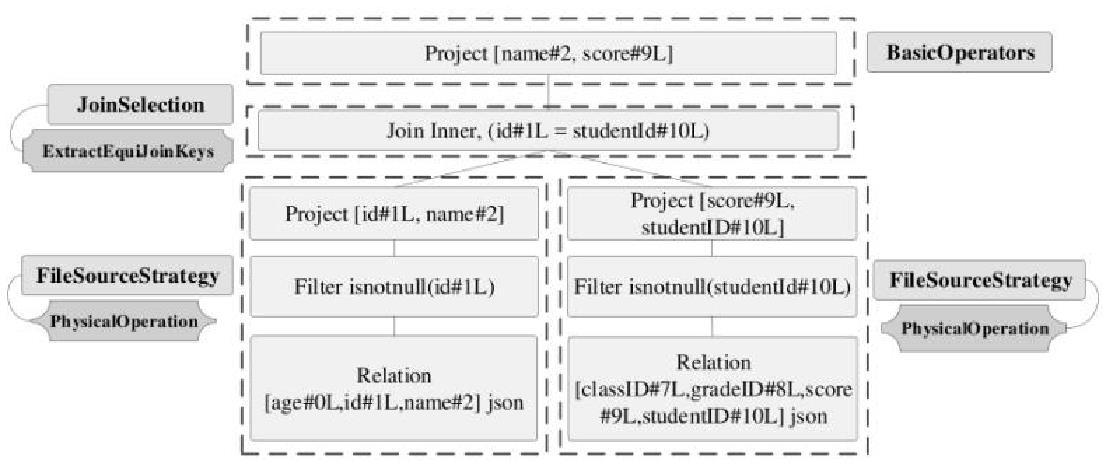
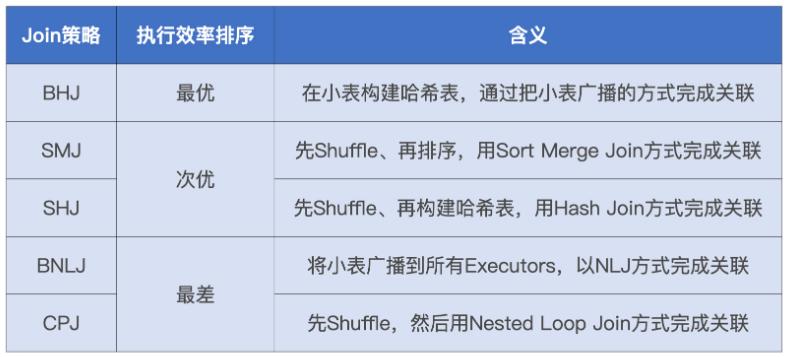
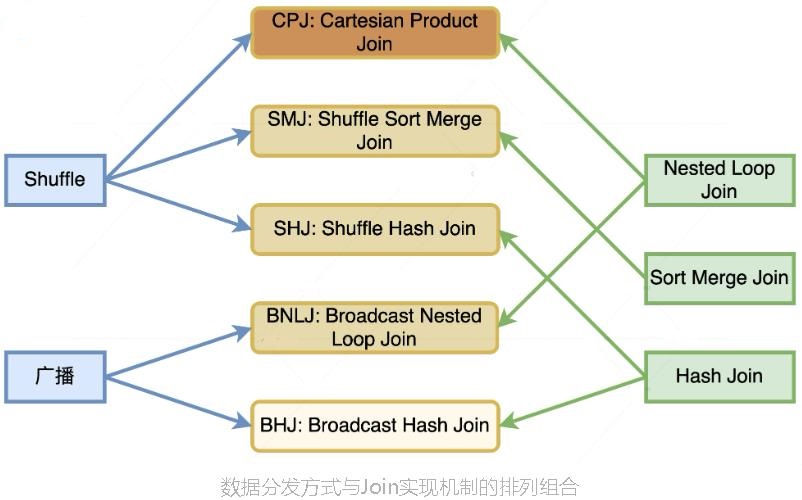
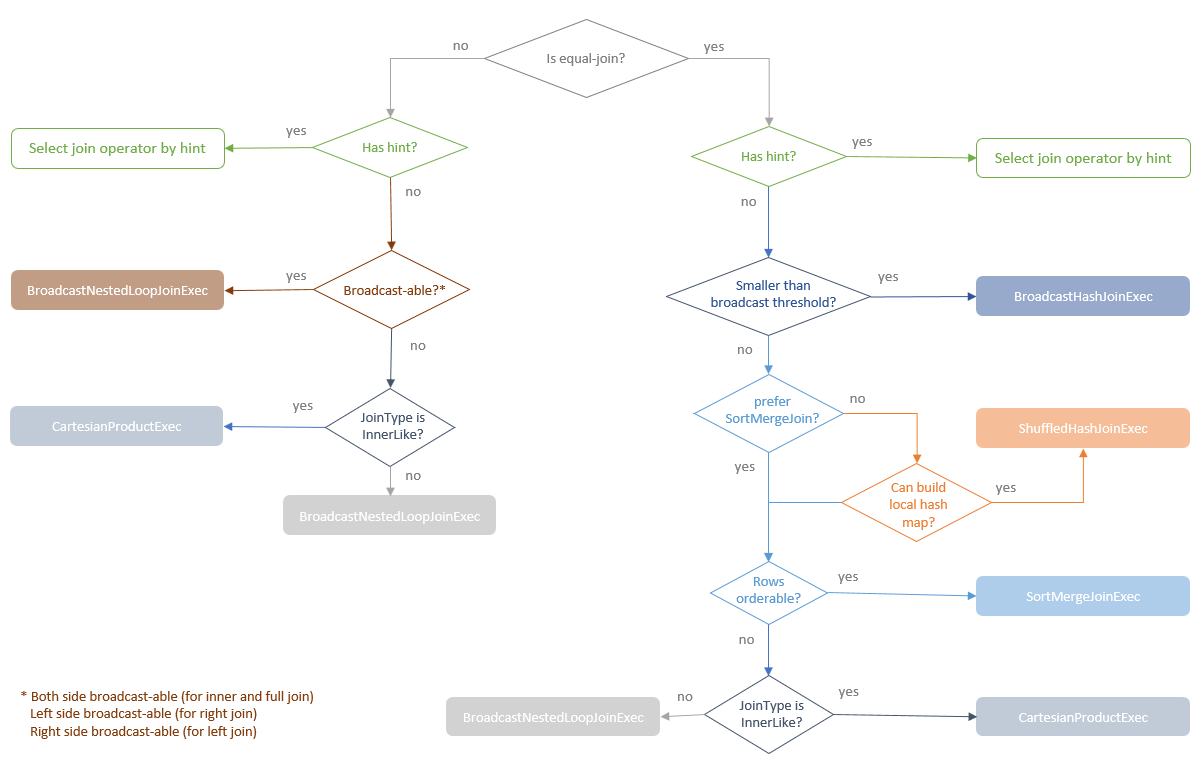
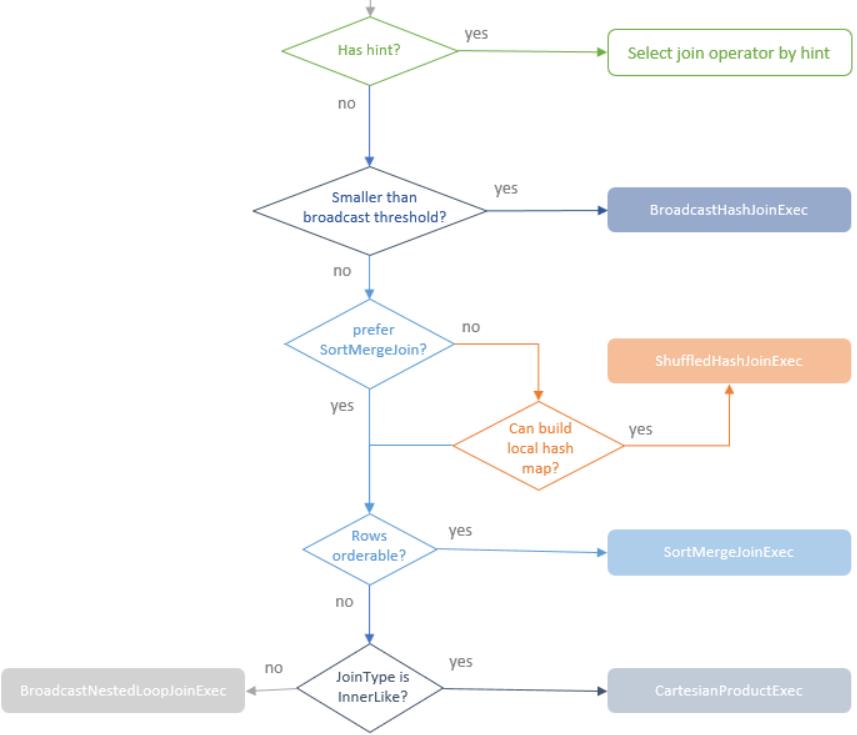
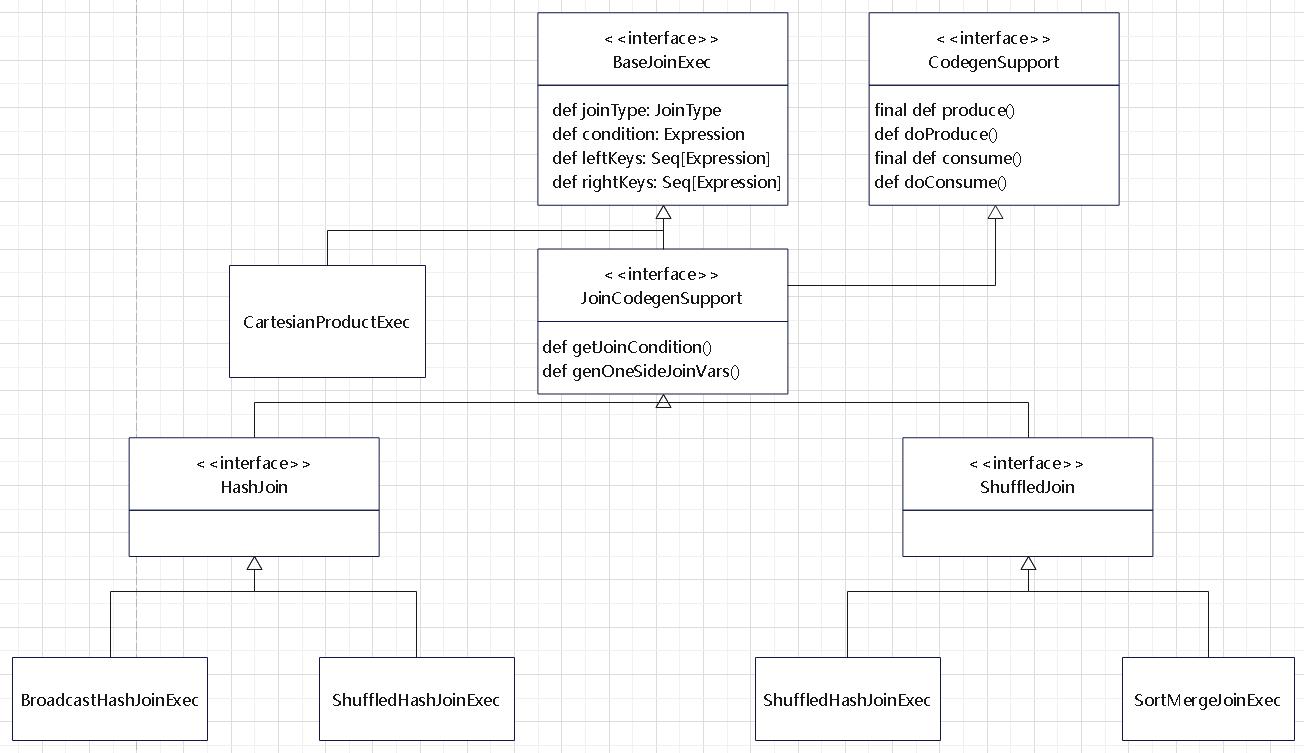
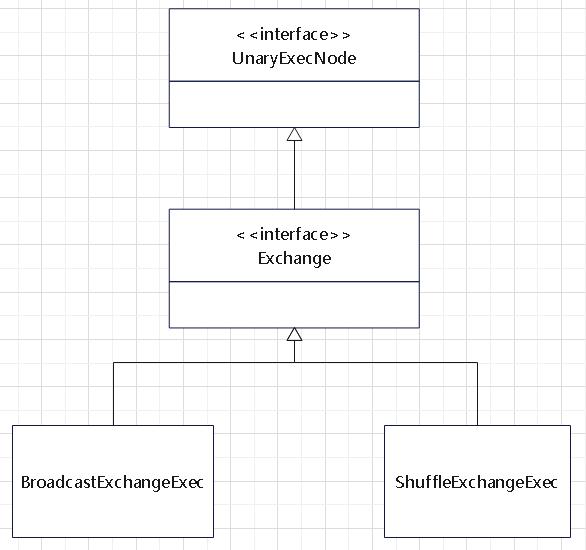
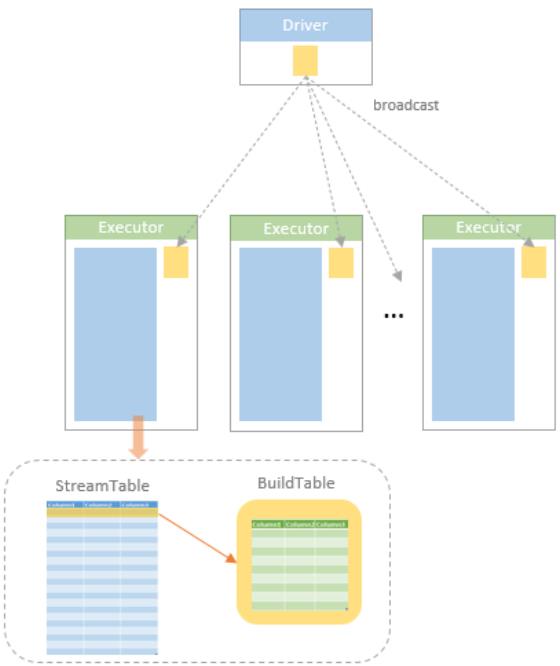
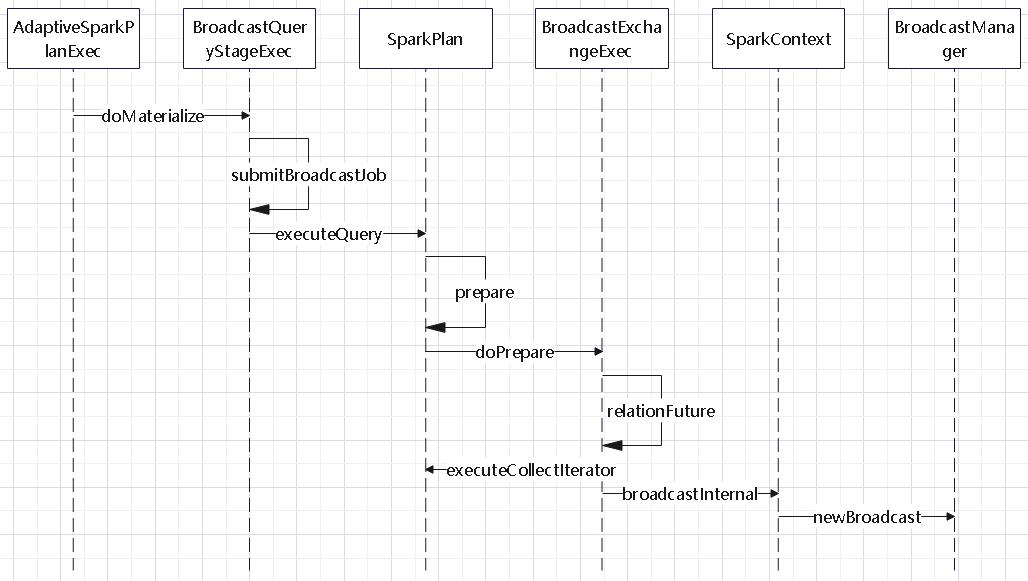
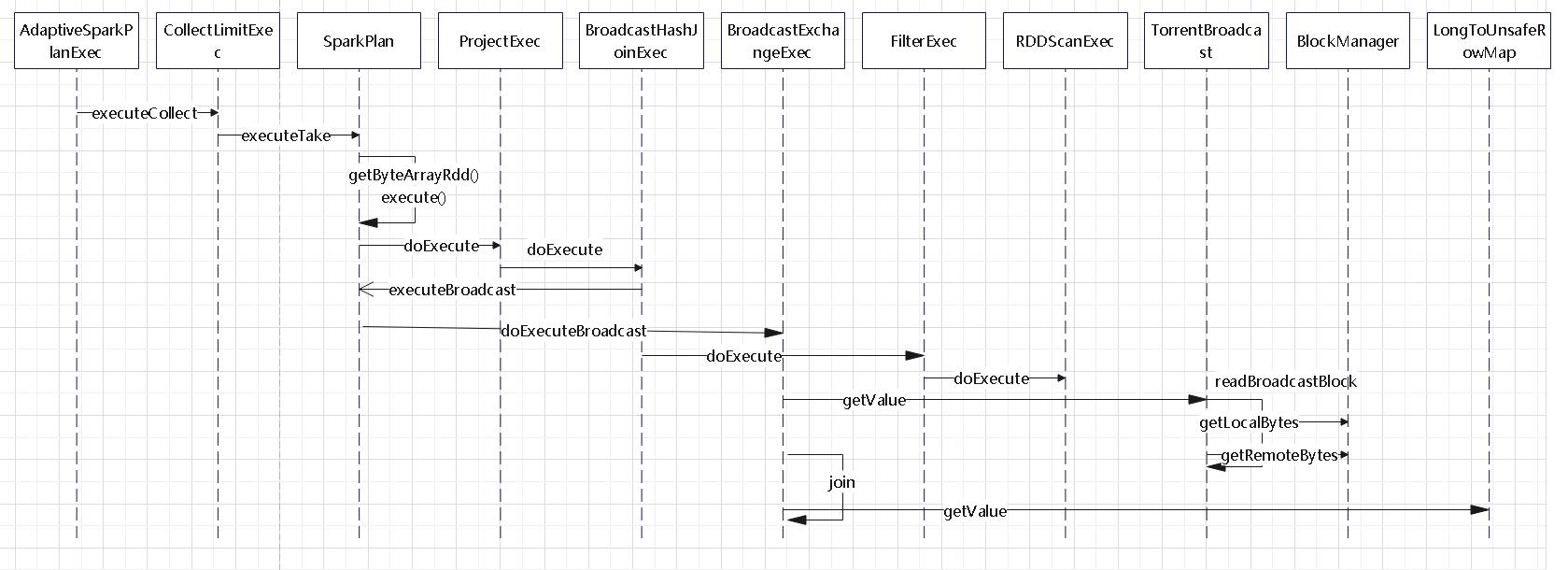
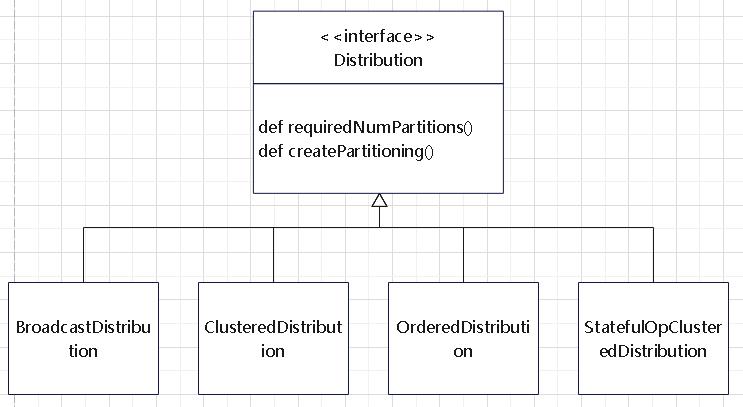
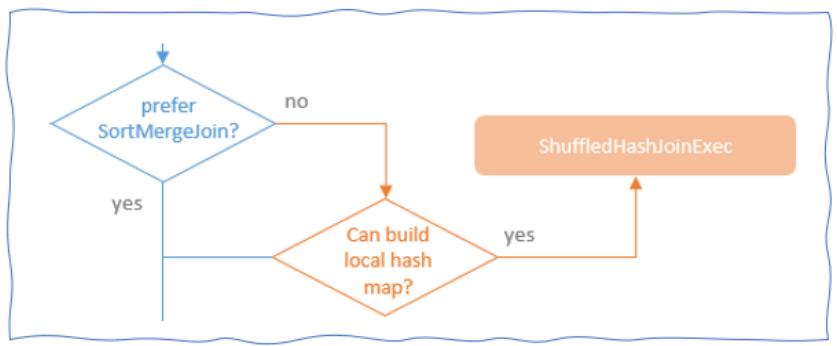
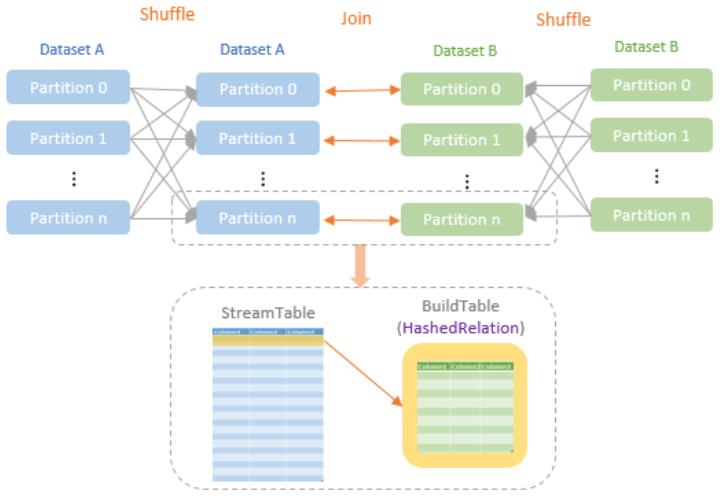
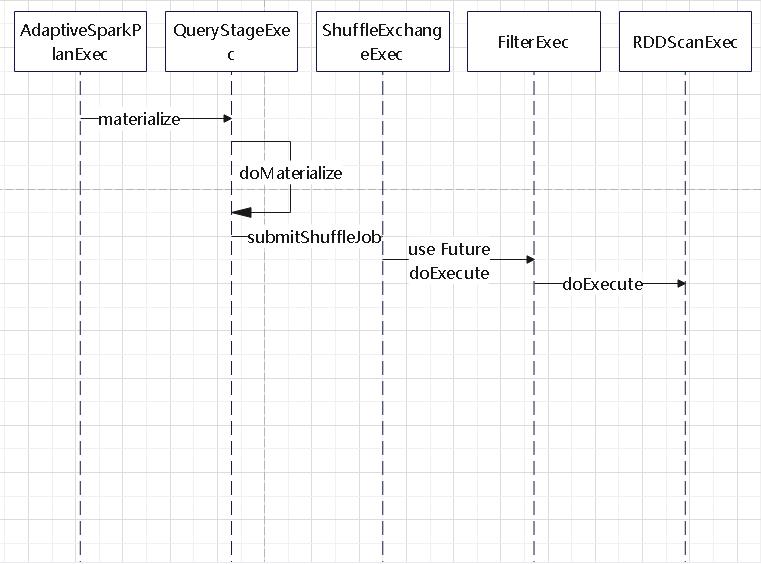
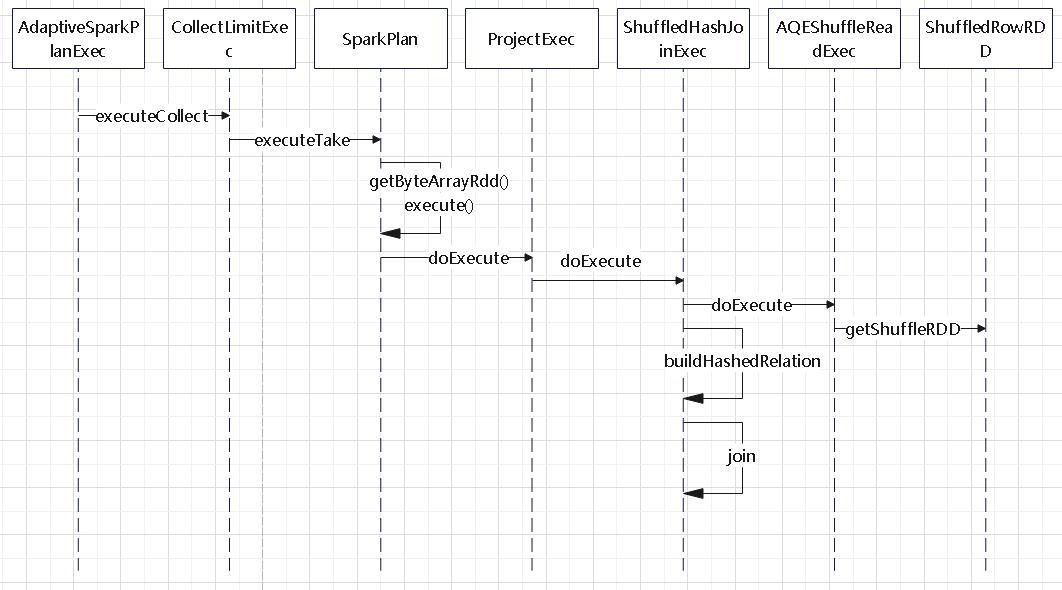
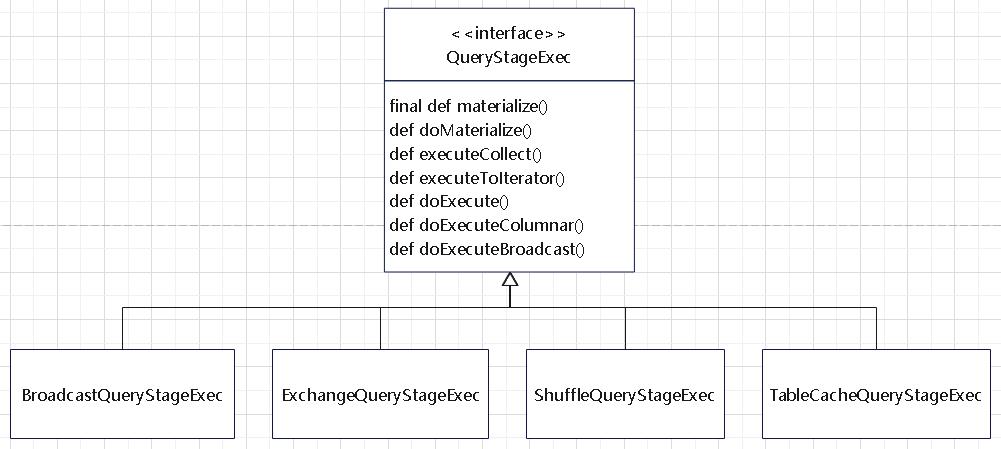
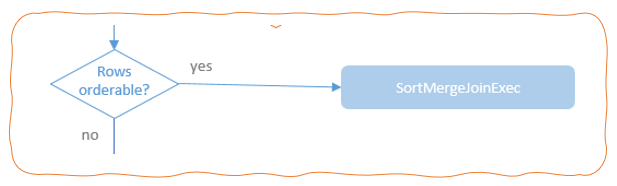
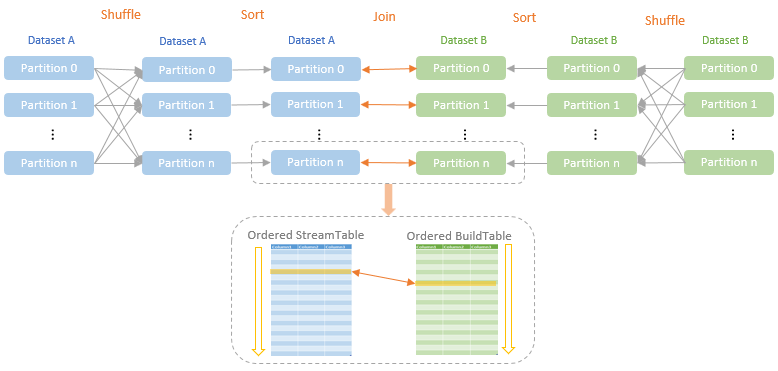
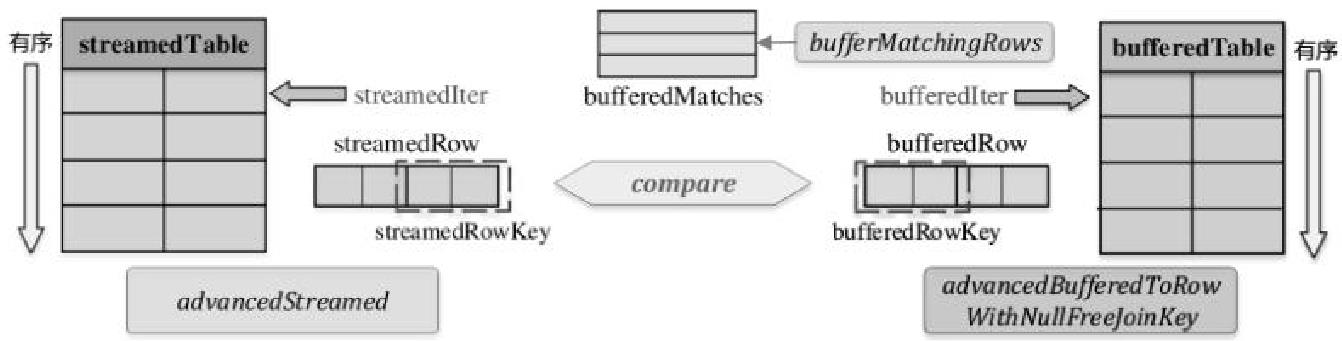
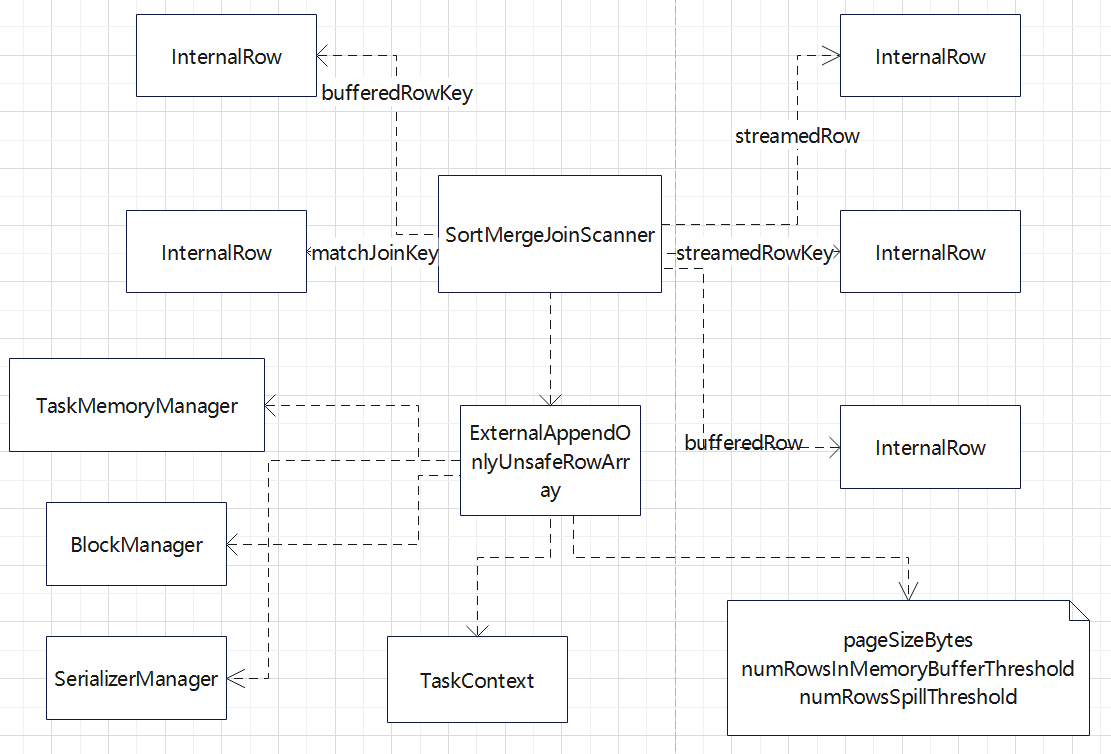
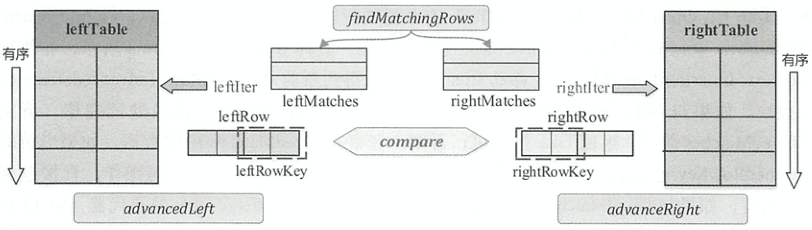
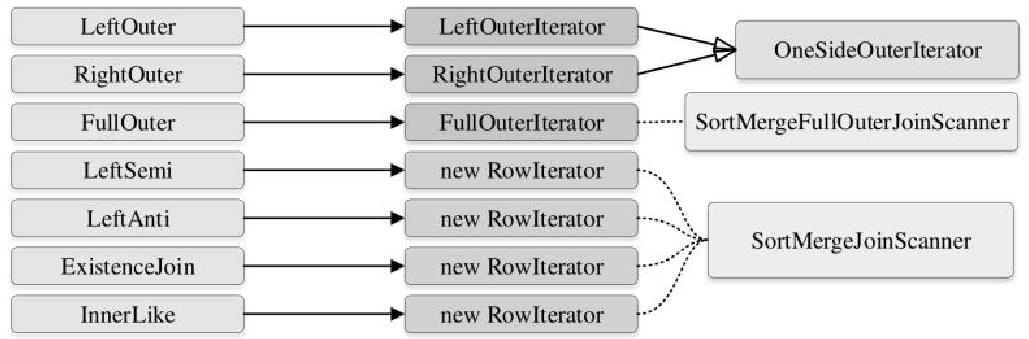
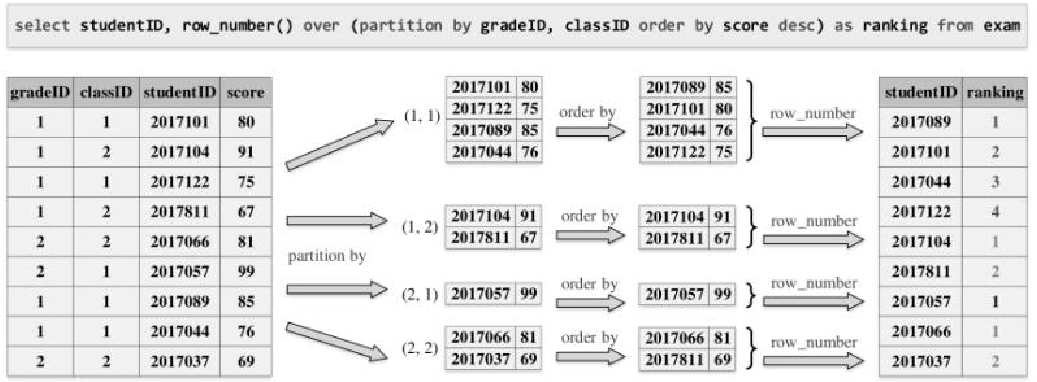
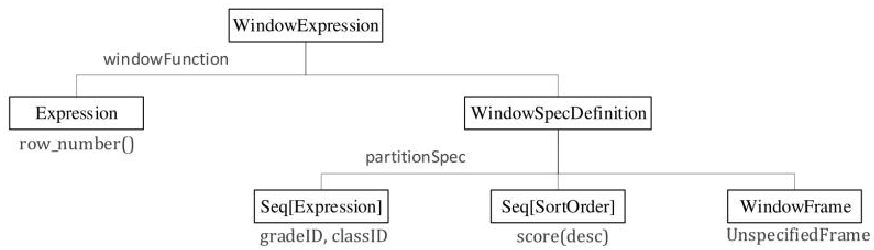
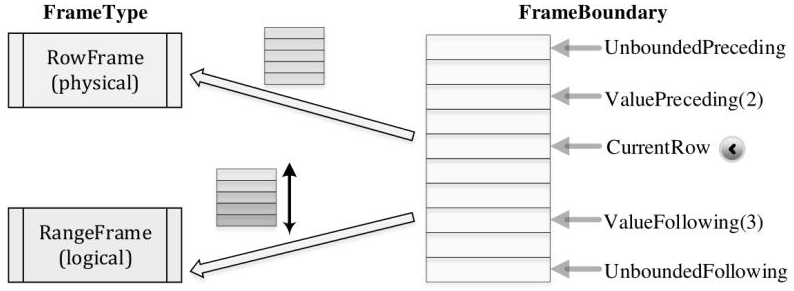
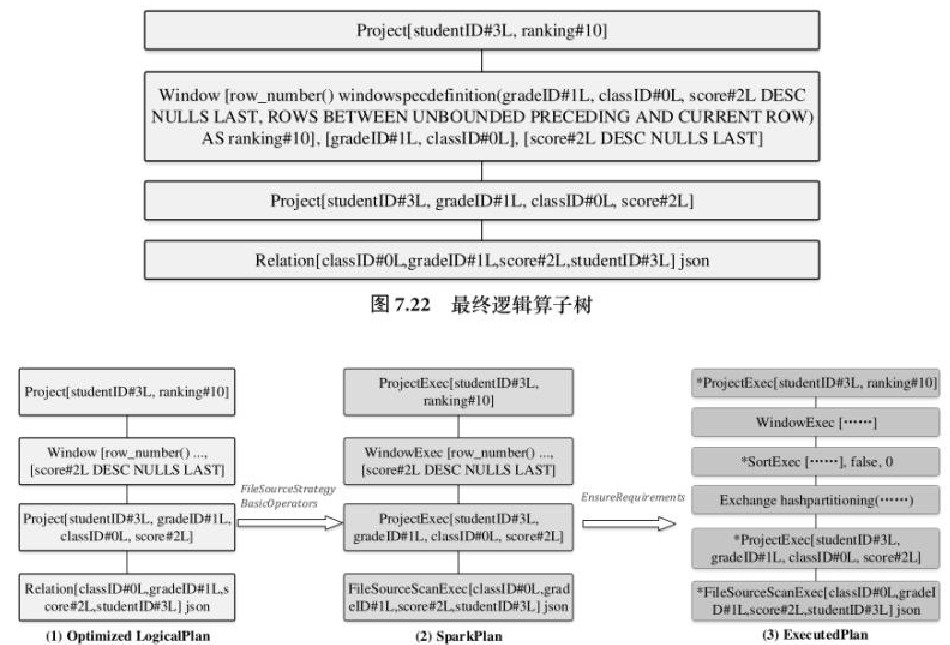
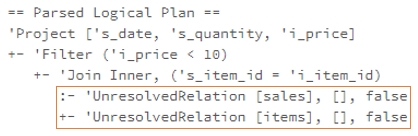
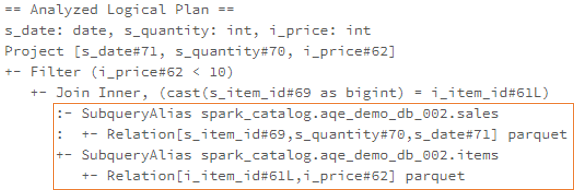
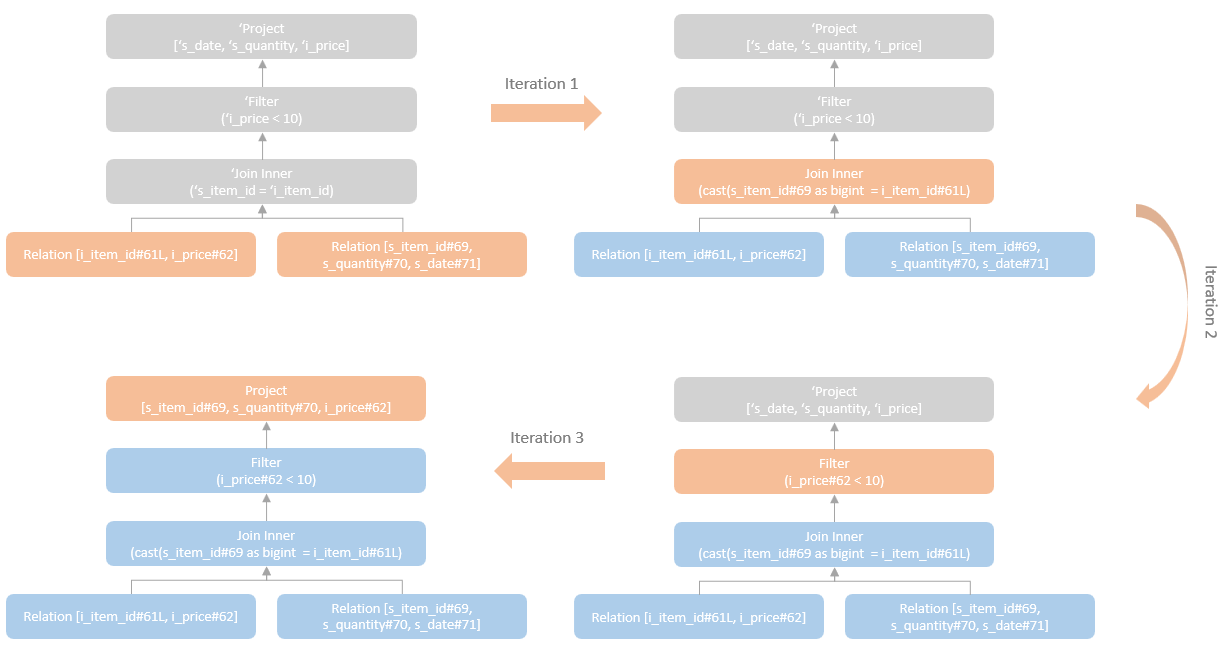
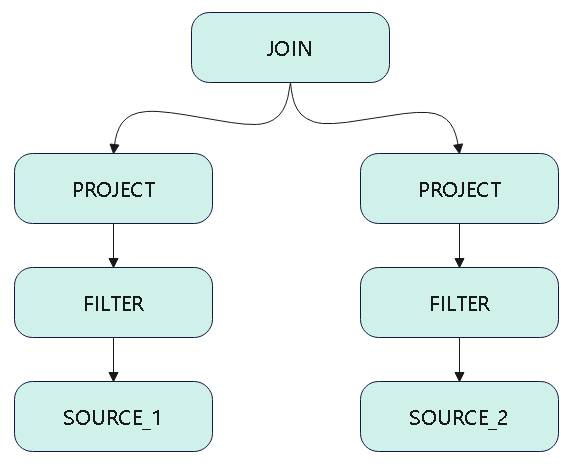
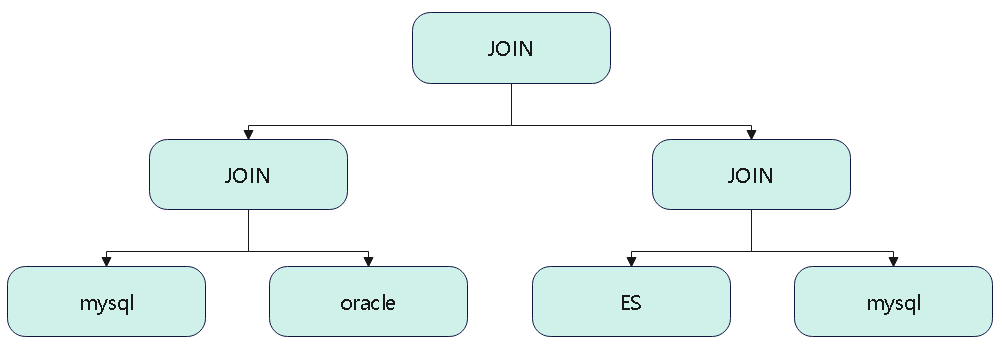
join的语法定义,join类型,解析、优化过程,join选择策略:hint、等值、数据size,父hash join: streamedlter 和 buildlter,数据的节点分布,对子节点的要求,JoinedRow 类型;BroadcastHashJoin 和 BroadcastExchange; ShuffleHashJoin 和 ClusteredDistribution,先将数据物化再通过AQEShuffleRead 读取; Shuffle Sort Merge Join,Sort ,Exchange,SortMergeJoinScanner(ExternalAppendOnlyUnsafeRowArray);BroadcastNestedLoopJoinExec ,BroadcastDistribution 等价两个for循环; CartesianProduct 对子节点无要求也是两个for循环; 排序算子执行过程
阅读全文
2024年4月27日
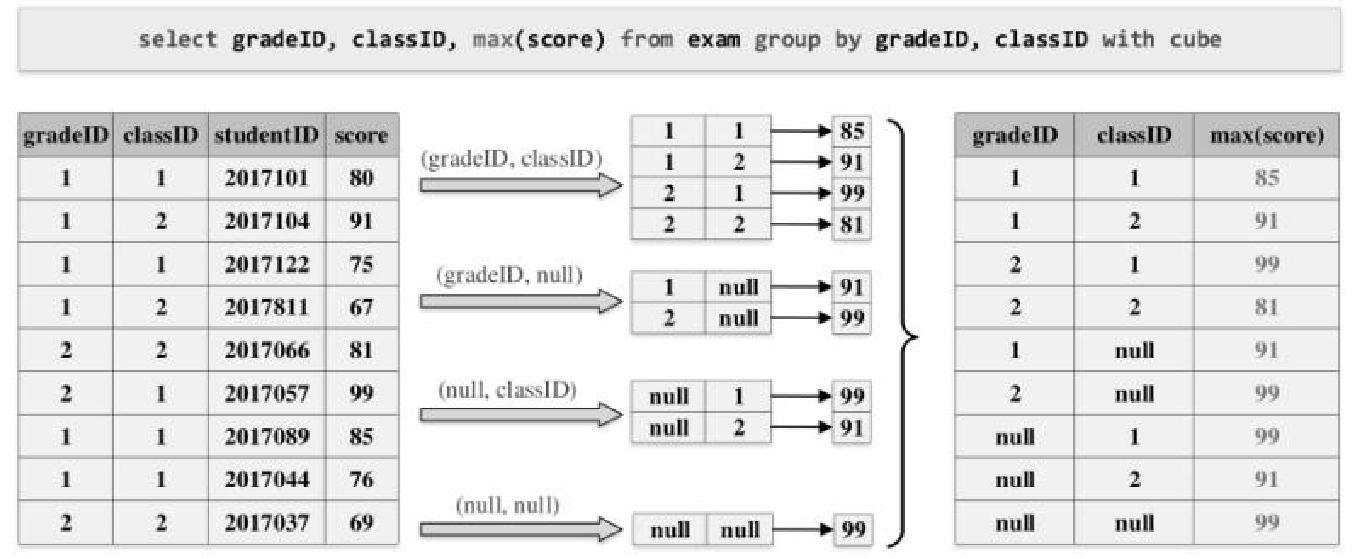
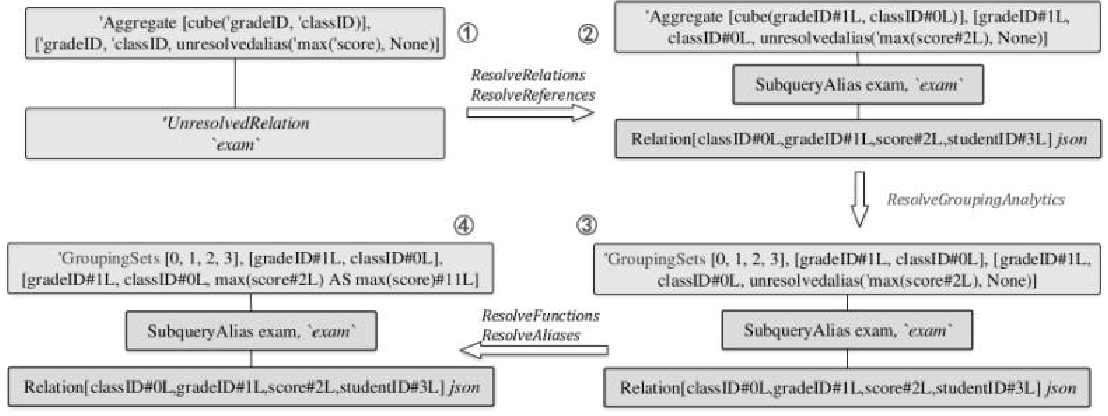
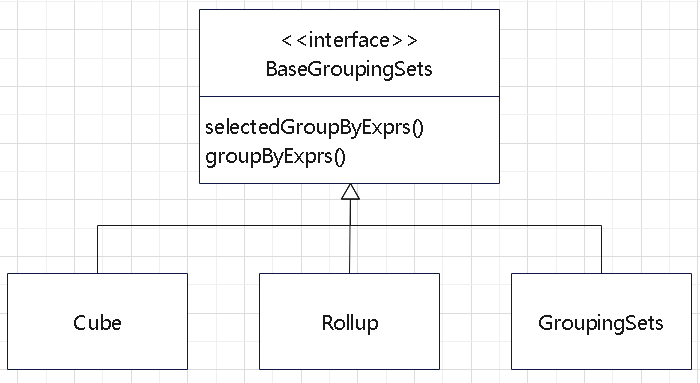
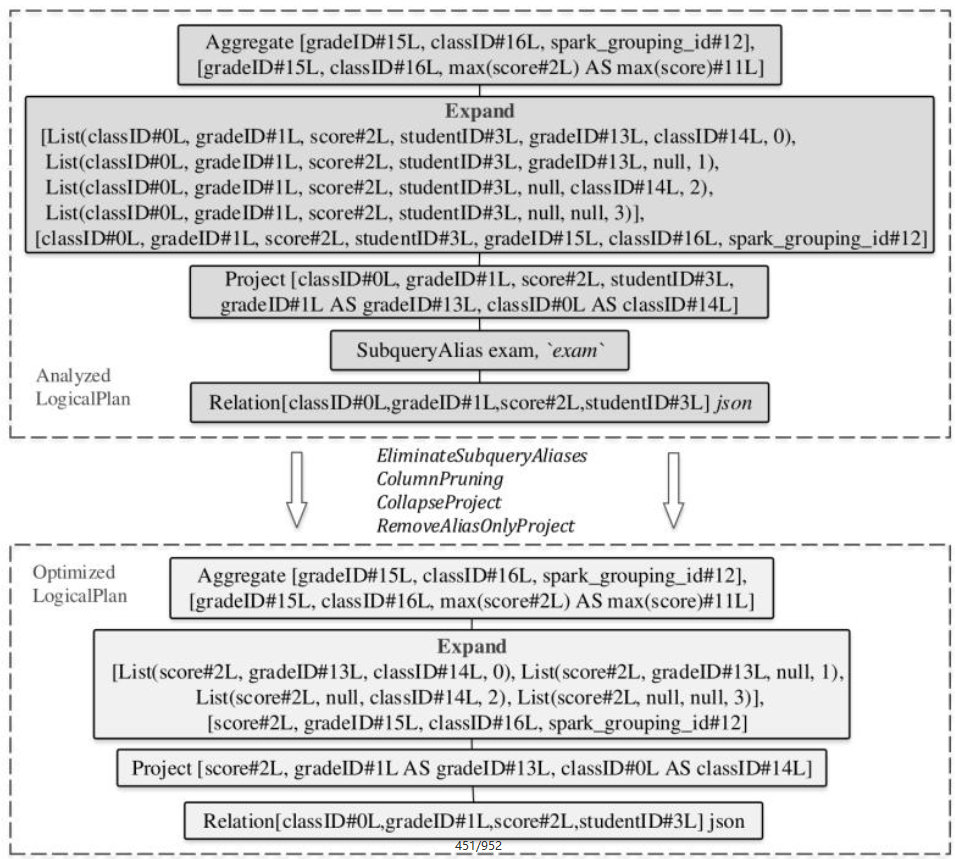
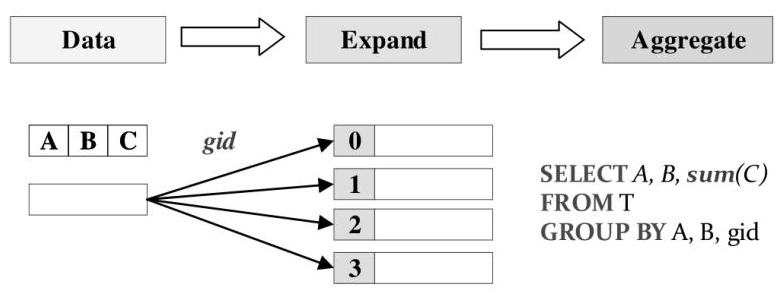
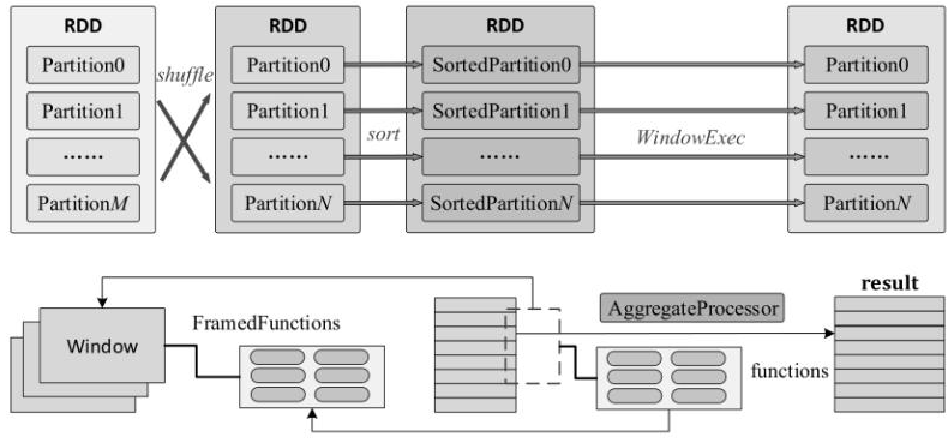
cube,rollup,grouping set,窗口函数执行过程,lateral,pivot,unpivot,with cube 的代码生成
阅读全文
2024年4月19日
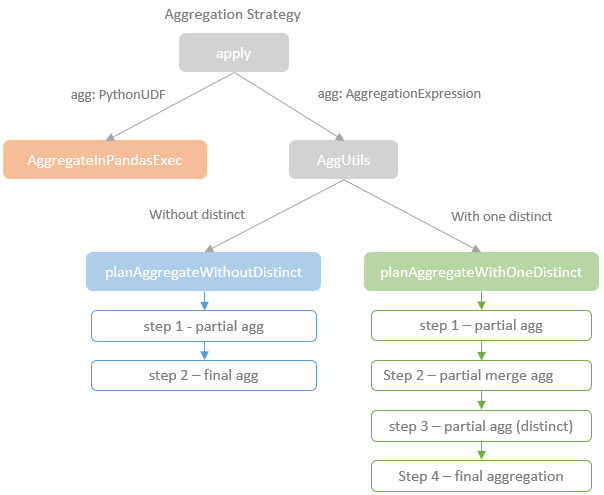
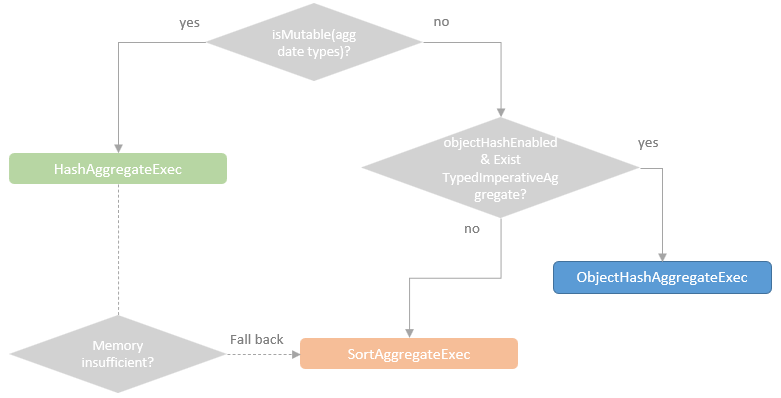
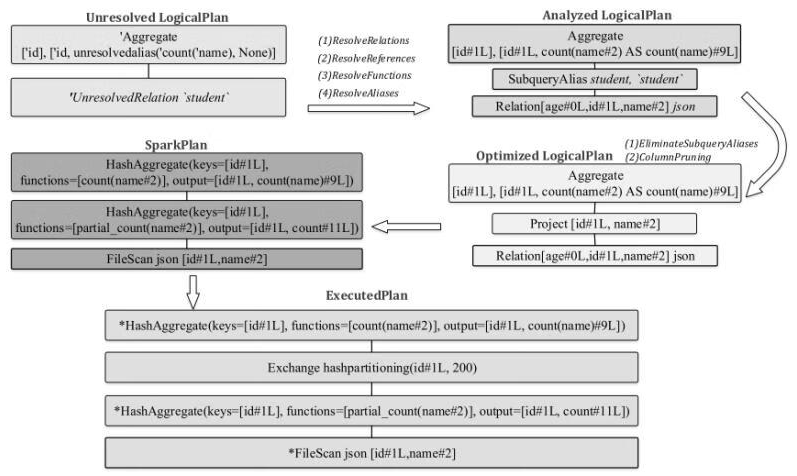
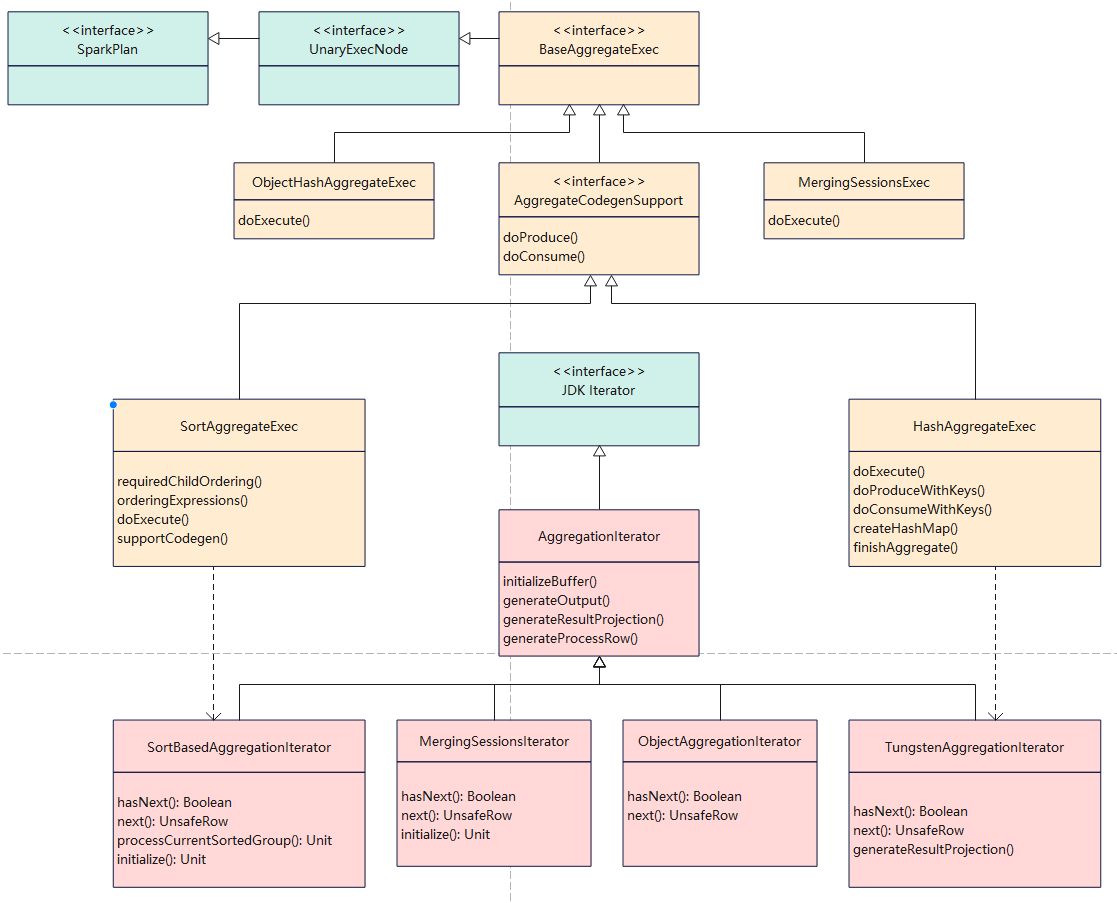
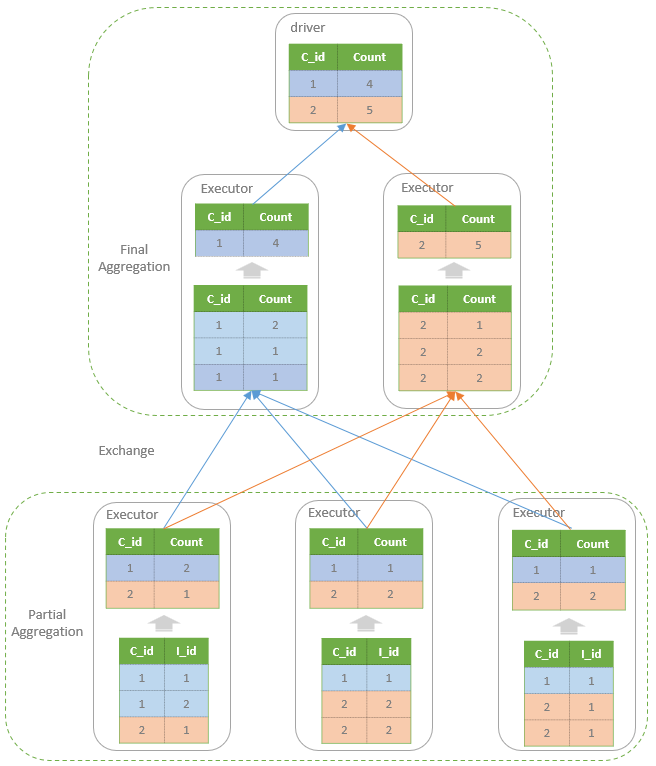
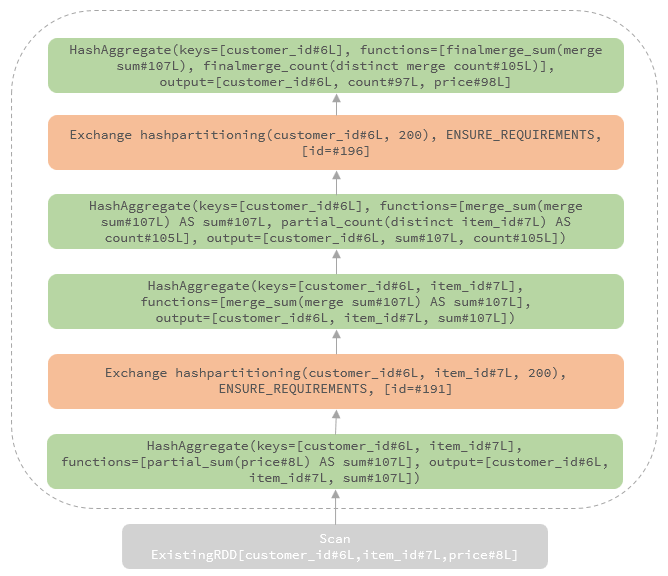
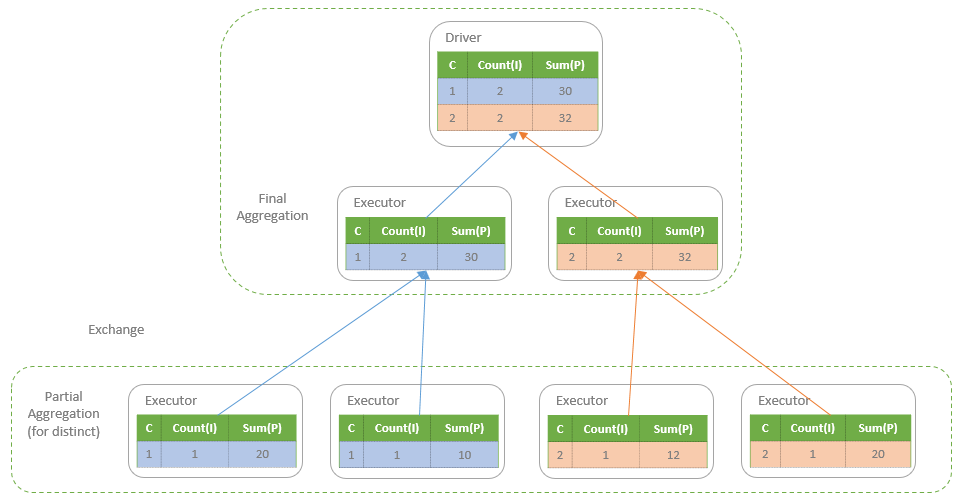
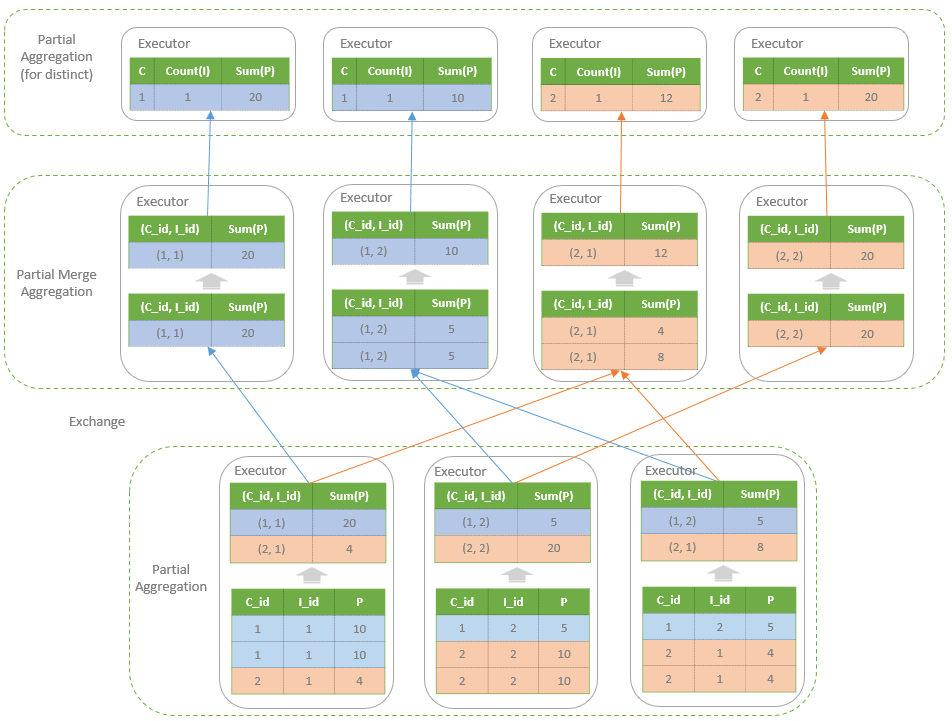
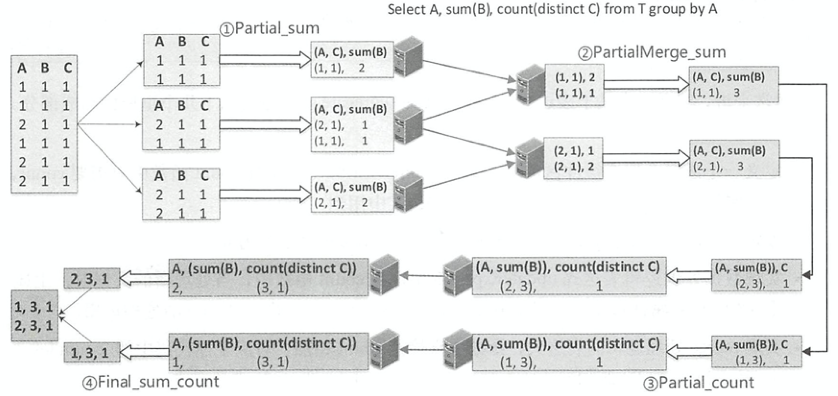
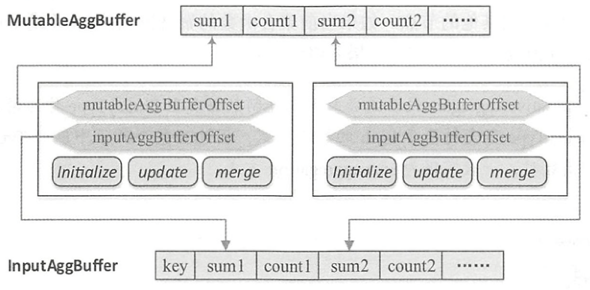
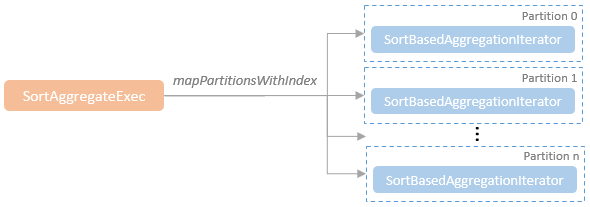
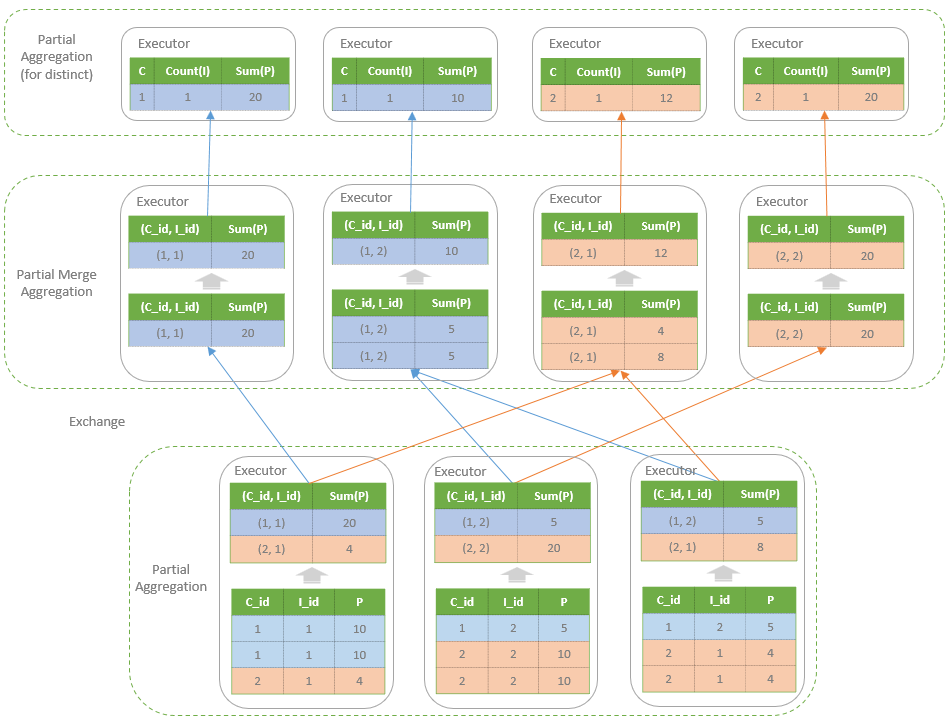
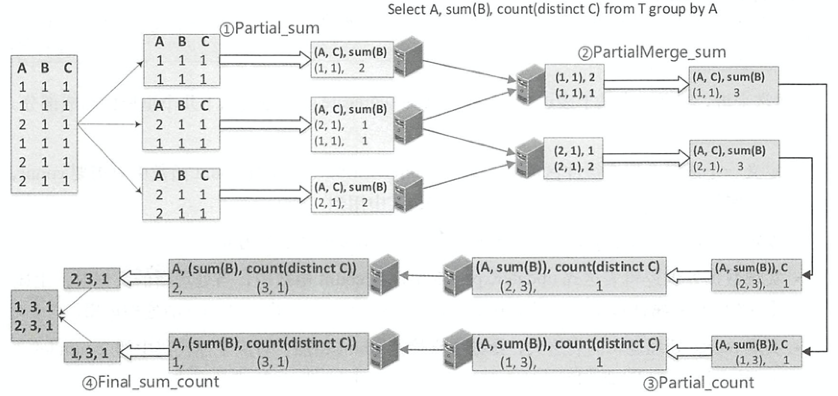
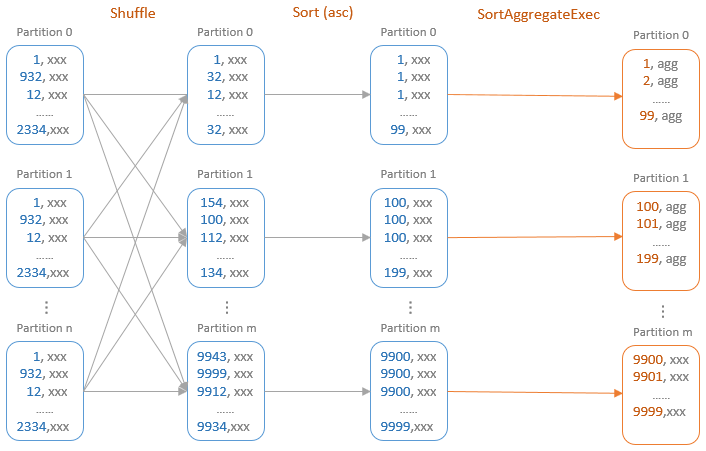
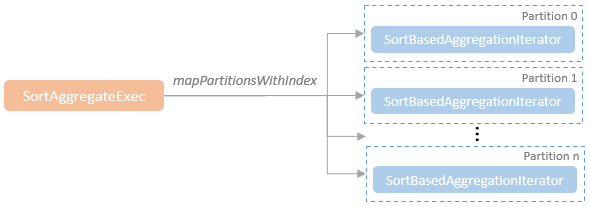
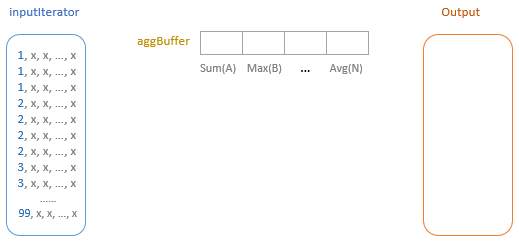
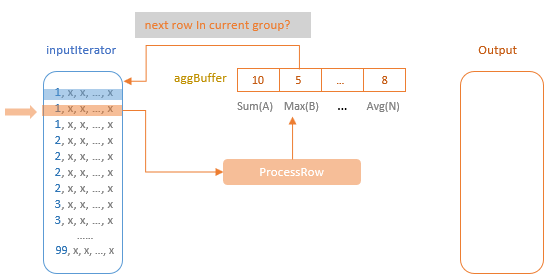
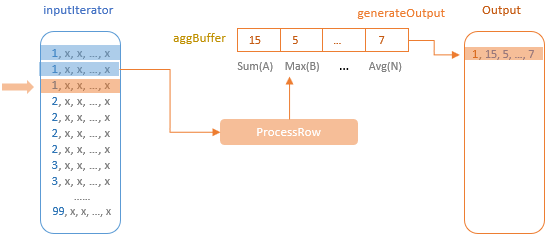
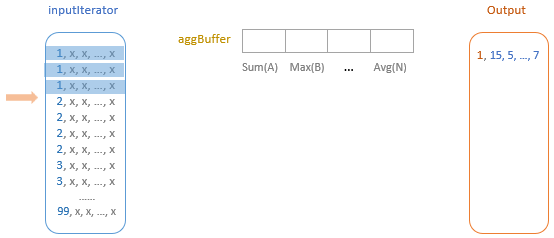
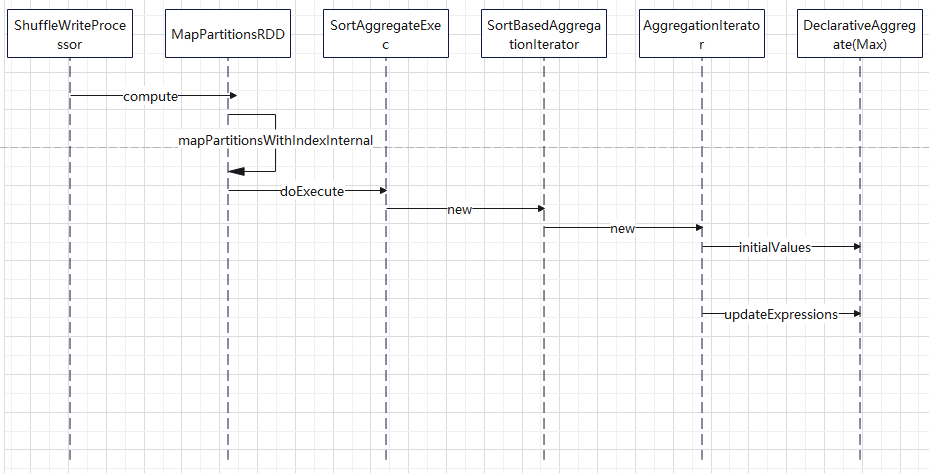
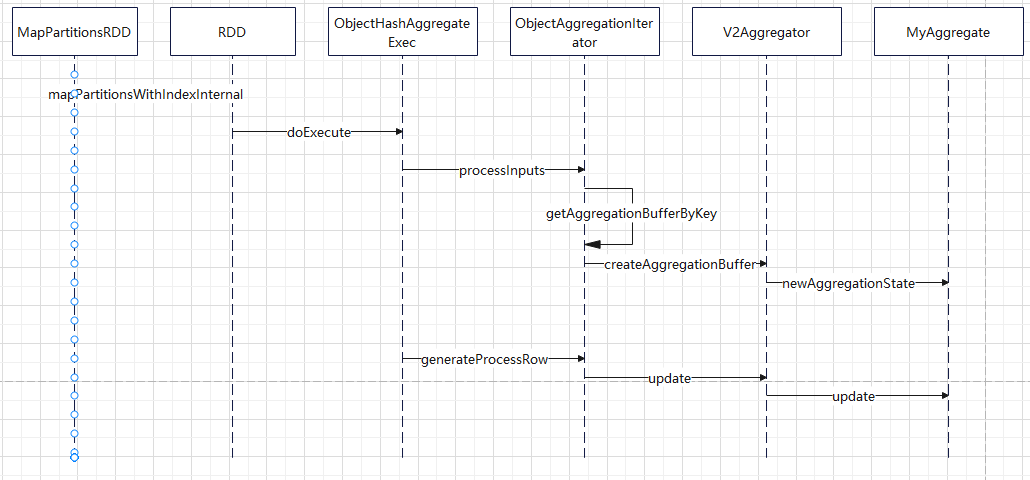
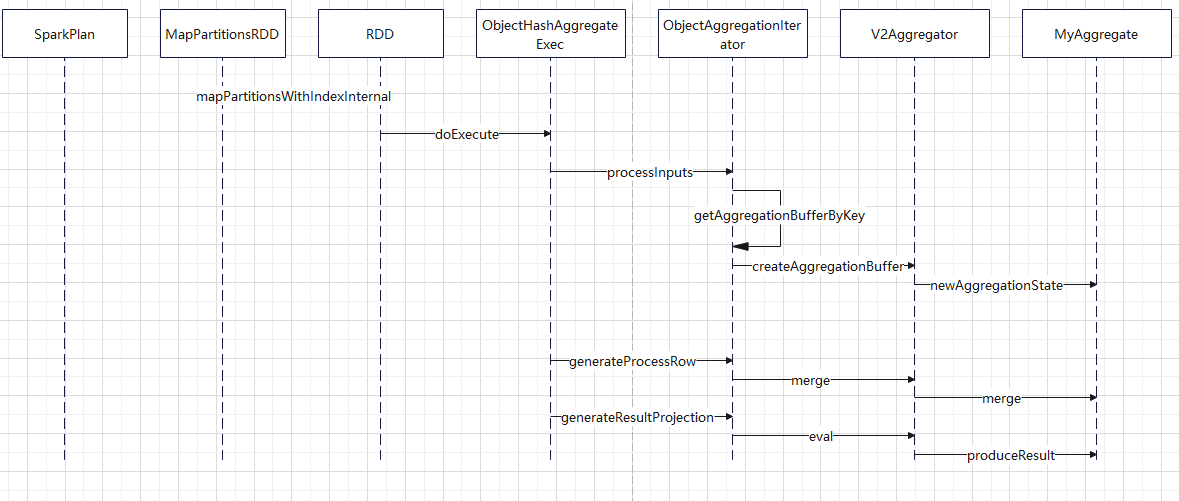
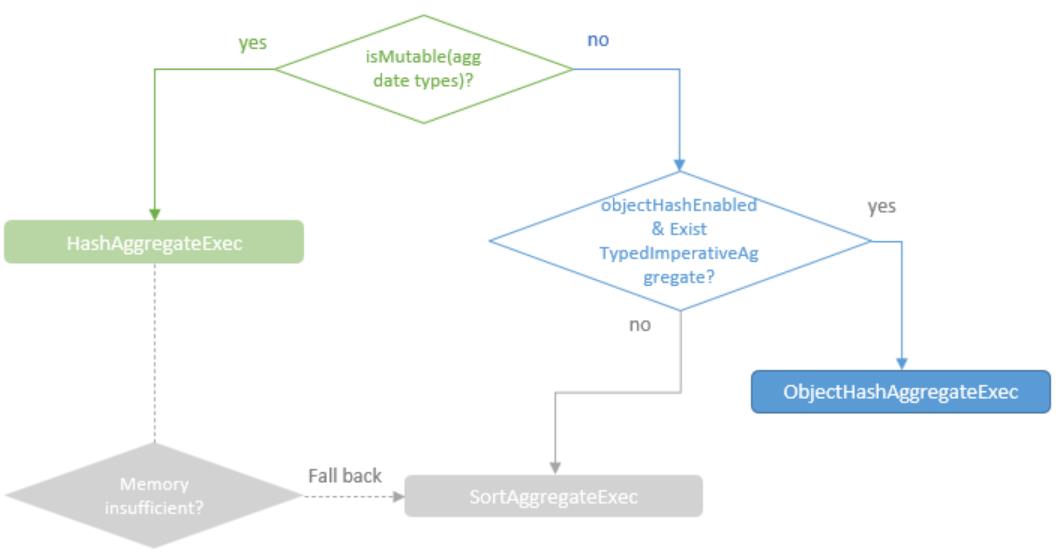
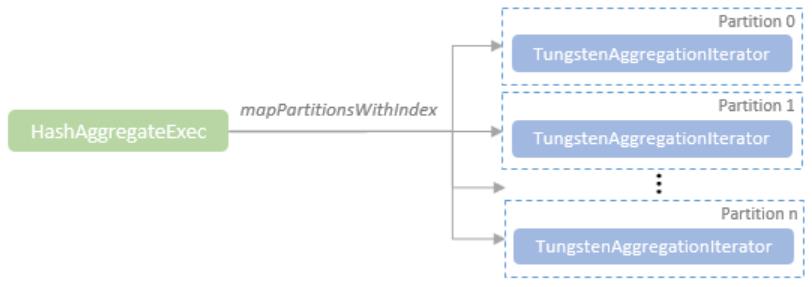
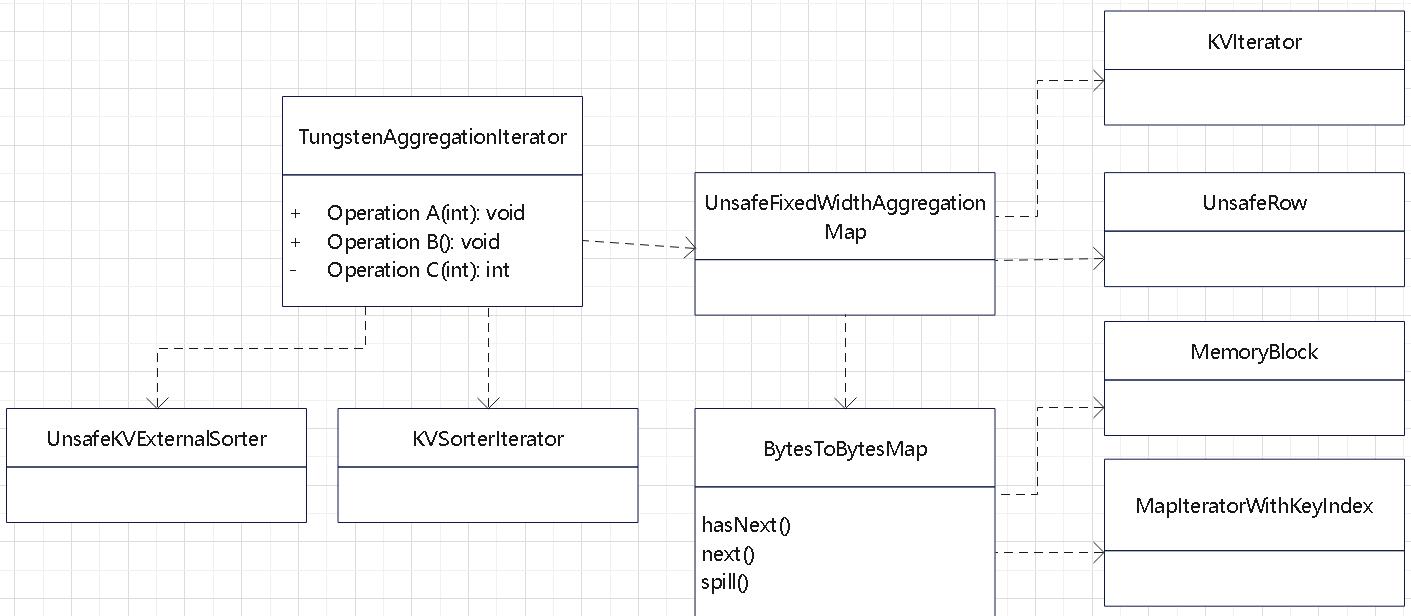
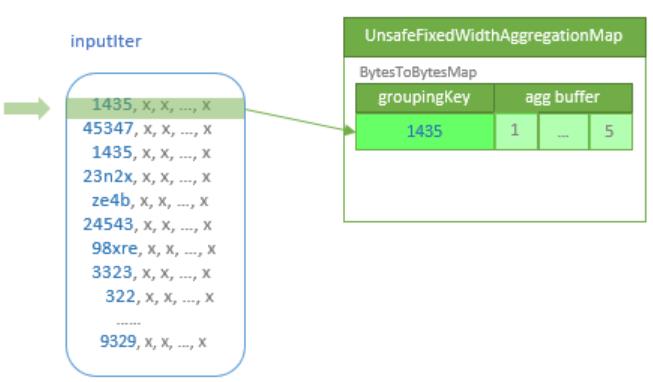
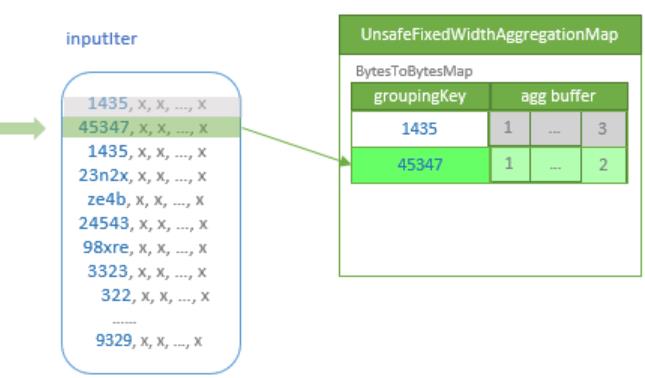
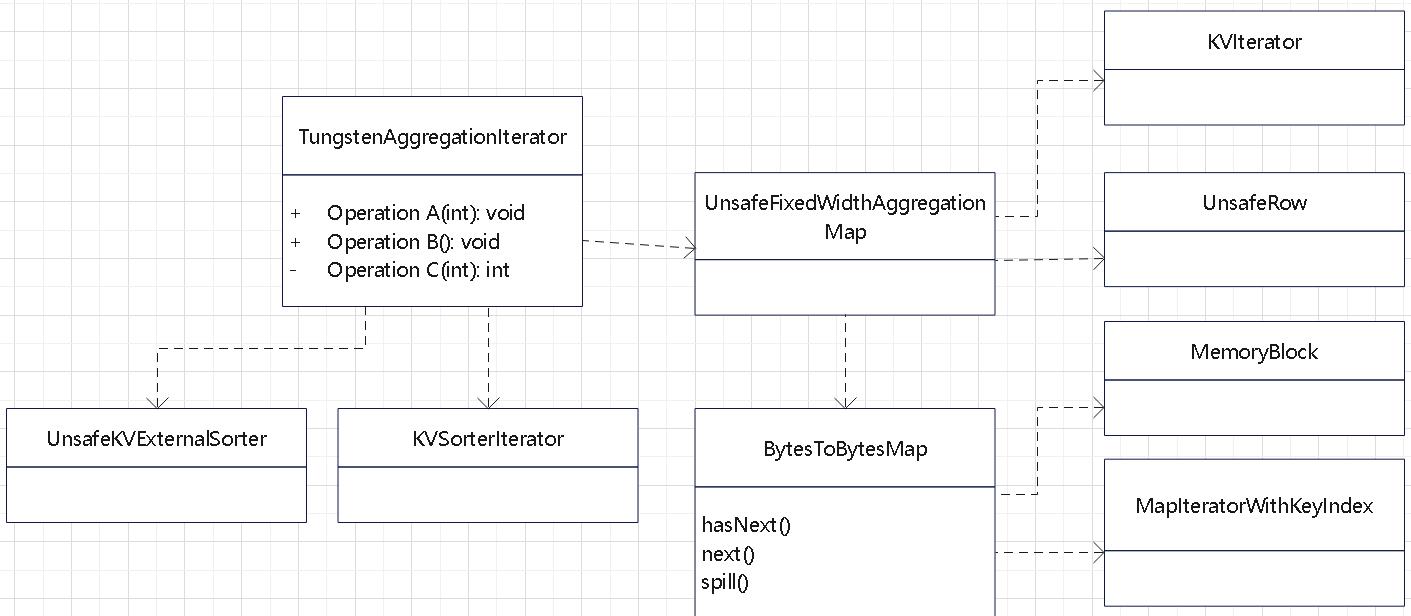
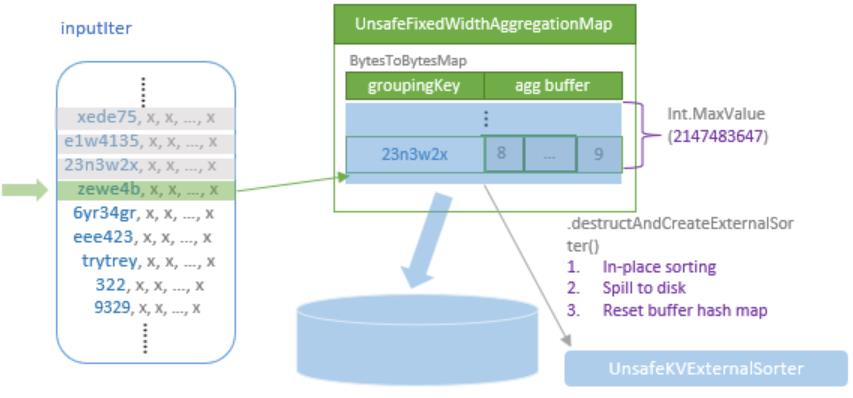
聚合的基本原理,聚合方式的分类:Partial、ParitialMerge、Final、Complete;distinct 和 非 distinct聚合;DeclarativeAggregate、ImperativeAggregate,聚合迭代器;基于排序的聚合,自定义函数 V1 和 V2 实现,自定义的 classloader,V2方式的自定义聚合函数,ObjectHashAggregate,基于hash 的聚合;自定义函数下推:标量函数下推、聚合函数下推;基于Hash 的聚会
阅读全文
2024年4月7日
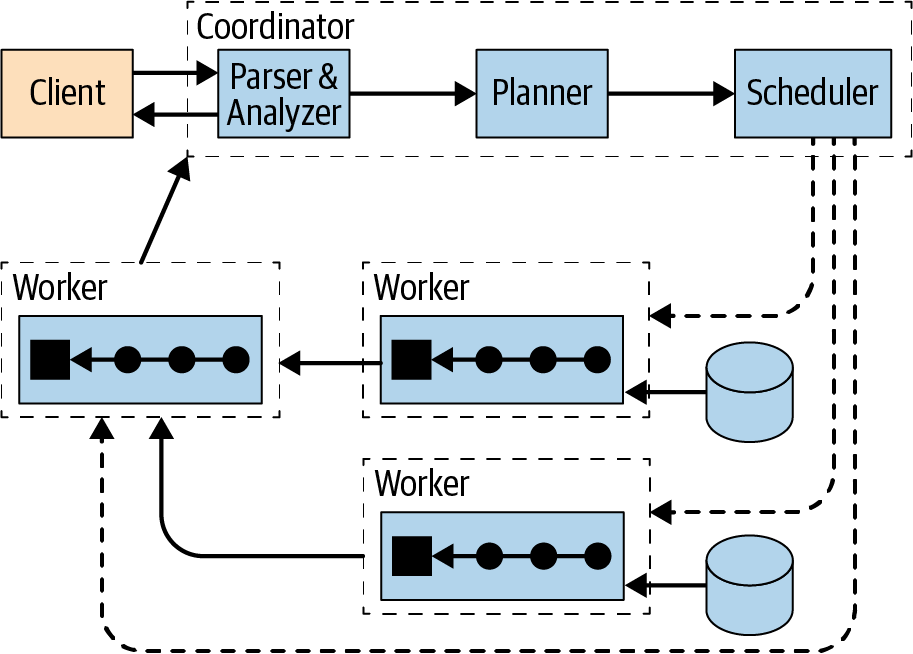
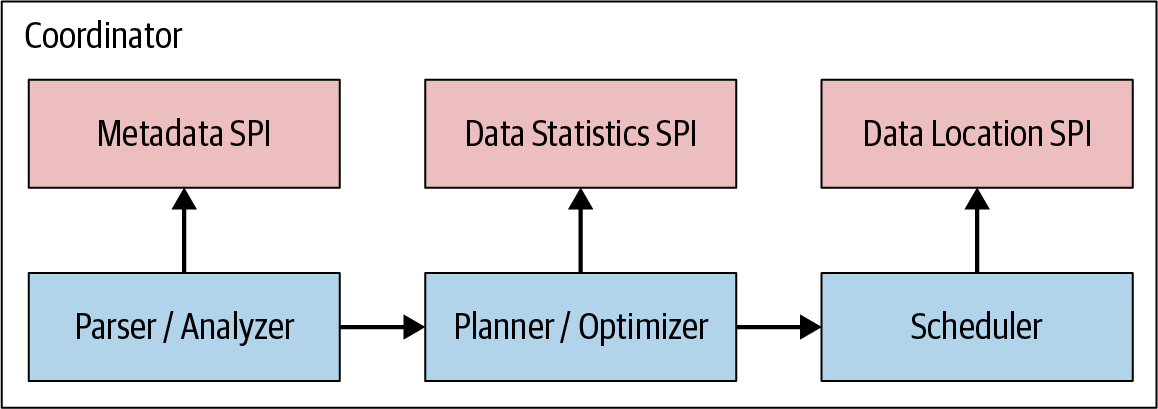
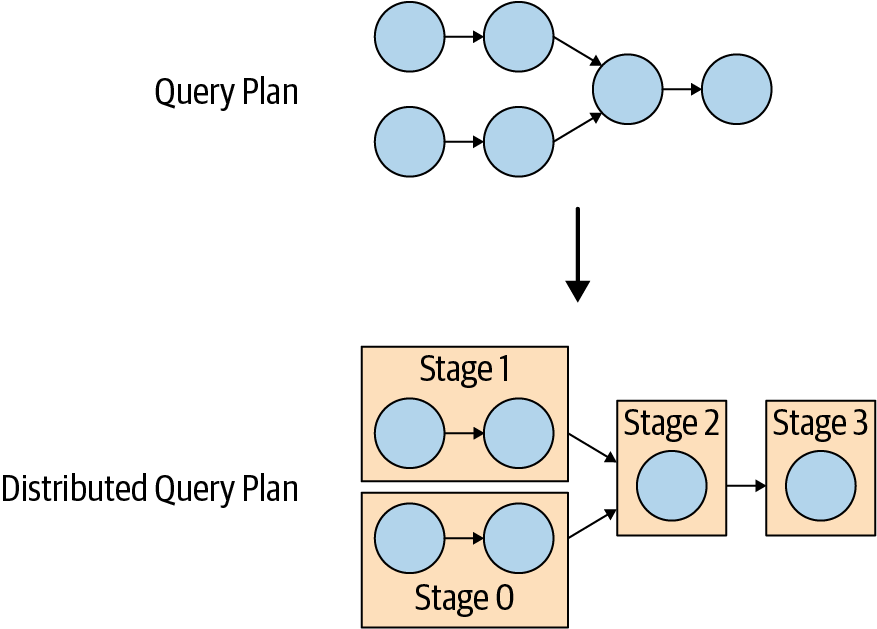
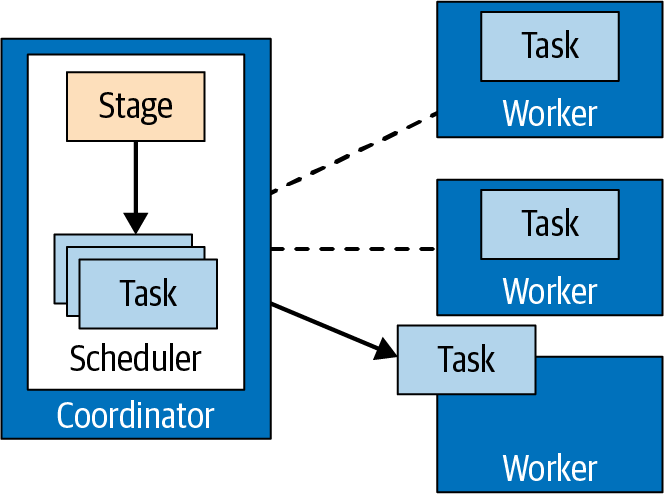
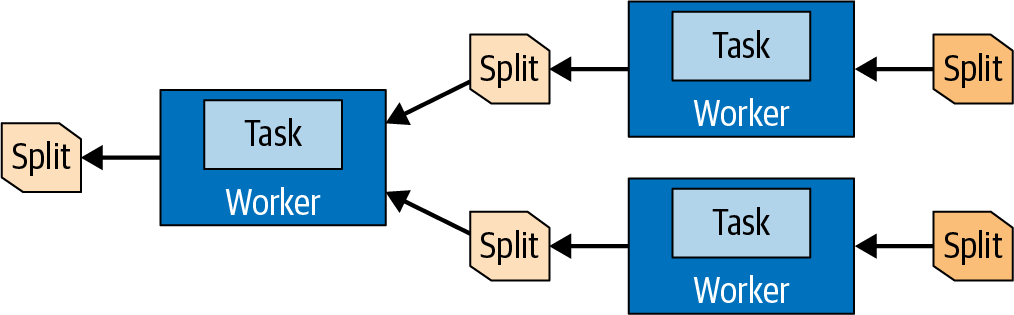
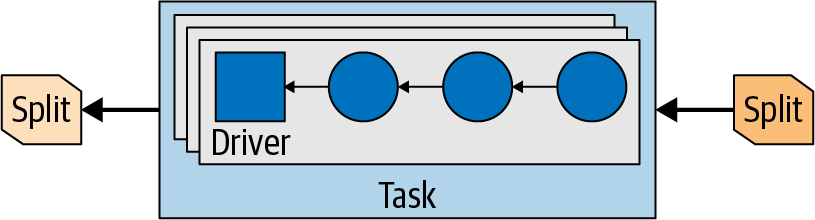
三种角色:discovery、coordinate、worker;连接器的设计:Metadata SPI、Data Statistics SPI、Data Location SPI、Data Stream SPI;查询计划,物理计划和调度,Stage,split,page,driver;Dynamic filtering,Spill to disk,Table statistics,JOIN 策略,CBO,join order,Join pushdown
阅读全文
2024年3月4日
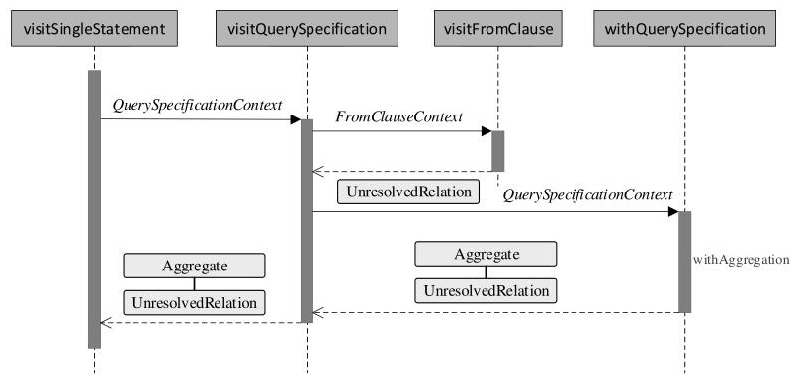
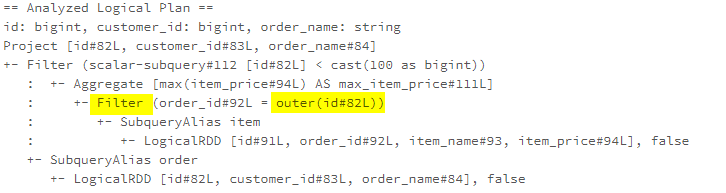
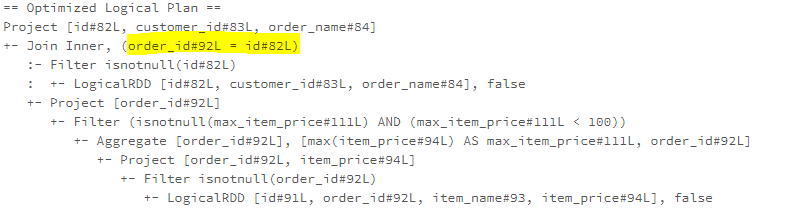
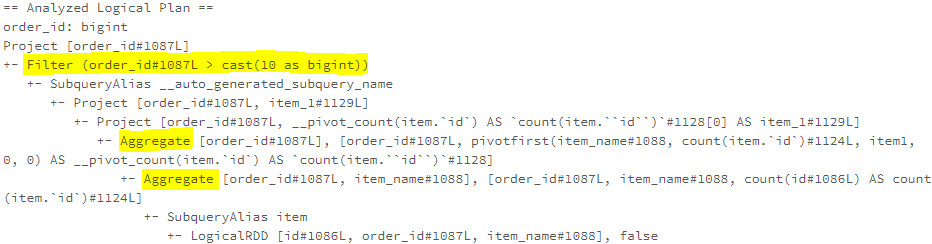
子查询优化:查询合并、展开,一行一列,单行多列,多行单列,多行多列,转换为 exist,子查询上提转join,子查询重写(转为semi/anti join);算子合并:CollapseRepartition、CollapseProject、CombineFilters、CombineUnions;常量折叠和强度消减:NullPropagation
、ConstantPropagation、OptimizeIn、ConstantFolding、ReplaceNullWithFalseInPredicate、CombineConcats;算子简化:
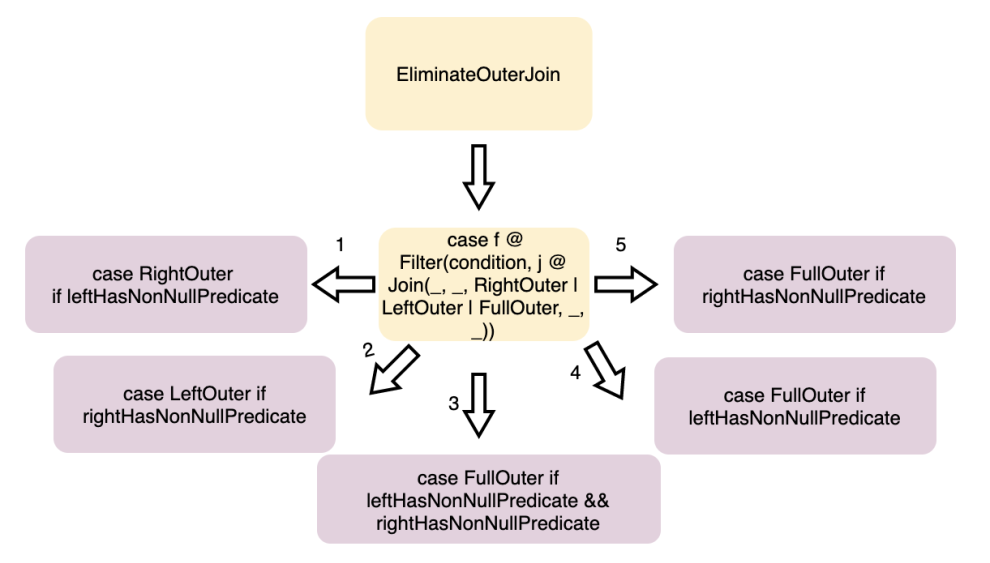
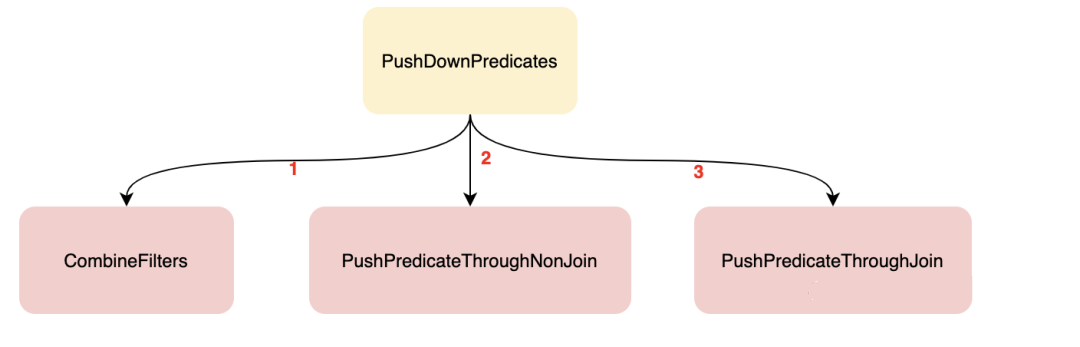
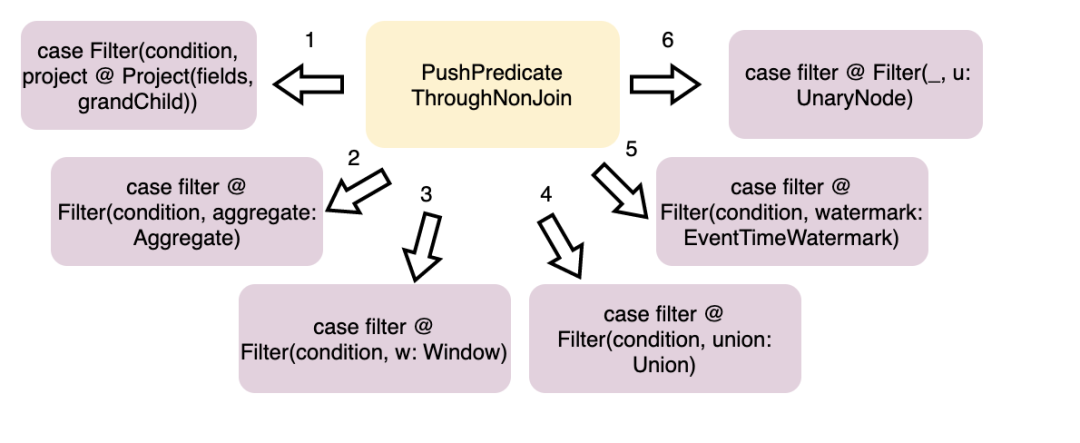
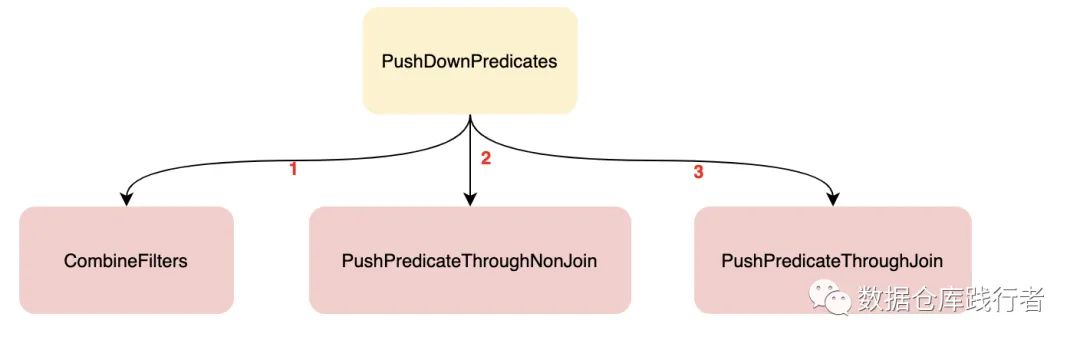
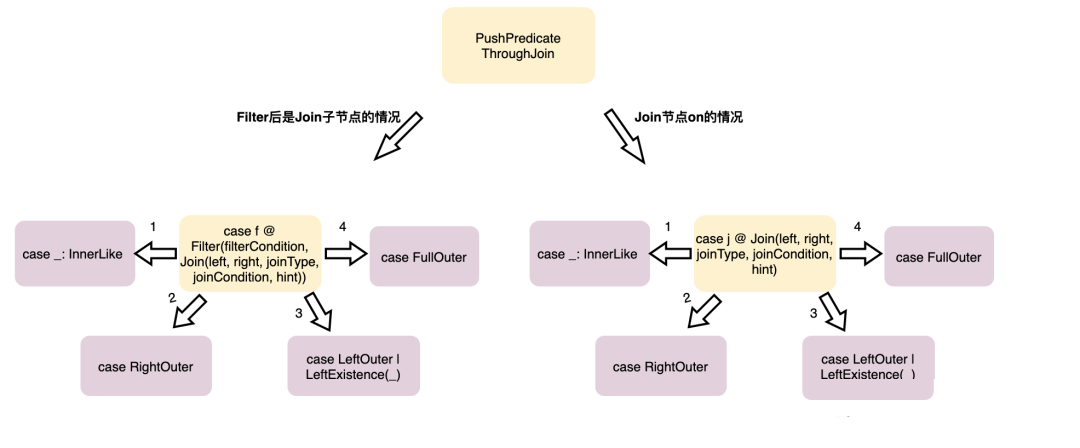
LikeSimplification、BooleanSimplification、SimplifyBinaryComparison、PruneFilters、EliminateSerialization、SimplifyExtractValueOps; Rewrite/Replace/Eliminate规则:EliminateOuterJoin、EliminateDistinct、EliminateLimits; 下推规则:PushDownPredicates、PushPredicateThroughNonJoin、PushPredicateThroughJoin、LimitPushDown、ColumnPruning
阅读全文
2024年3月2日
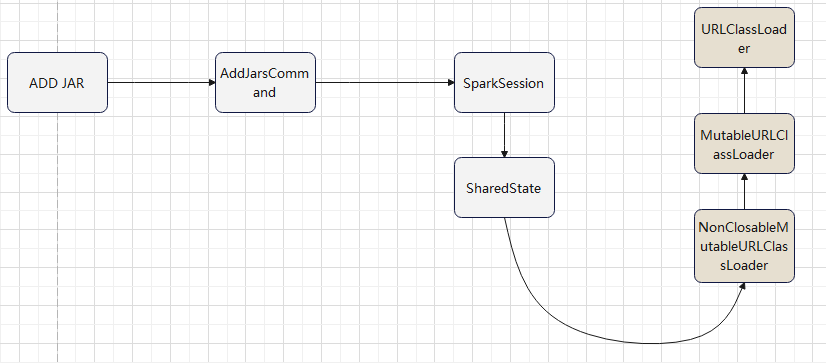
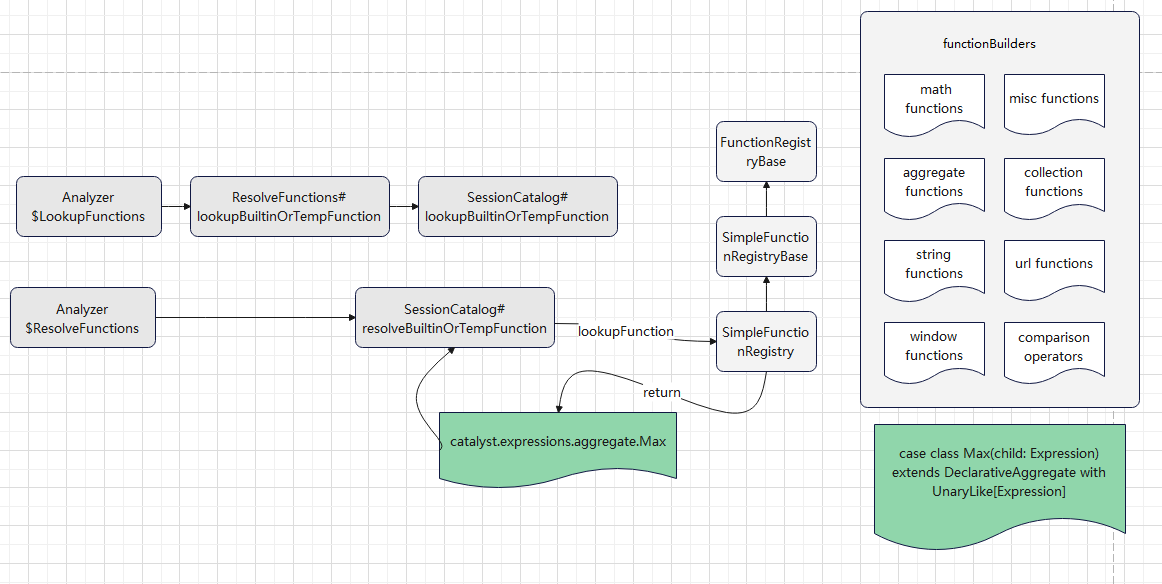
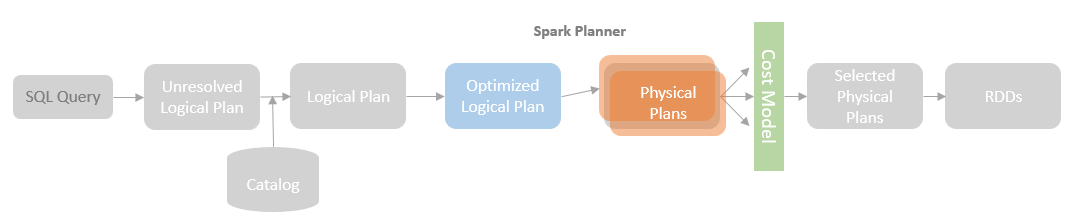
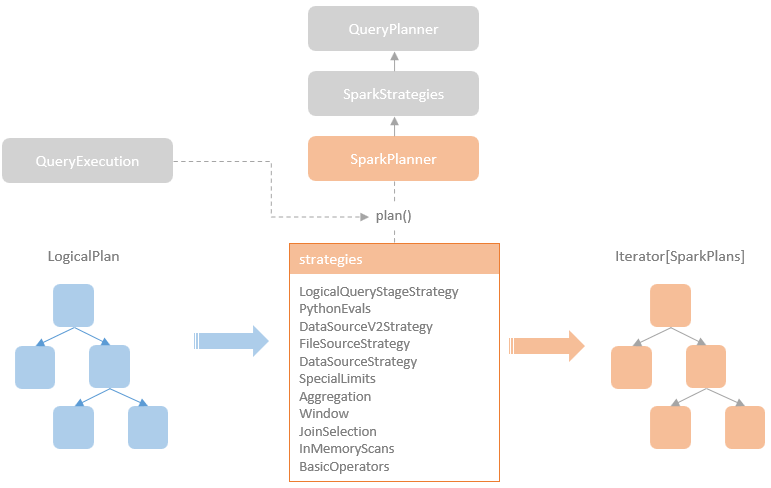
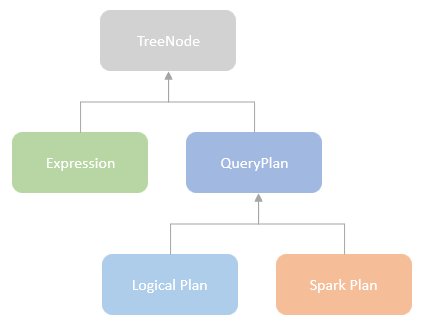
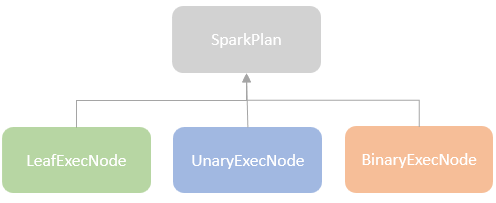
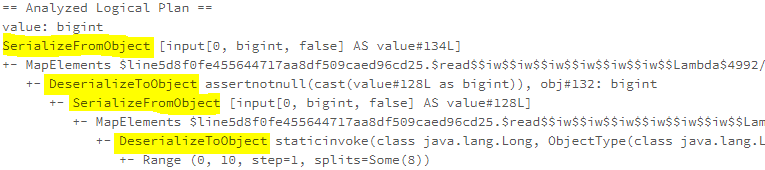
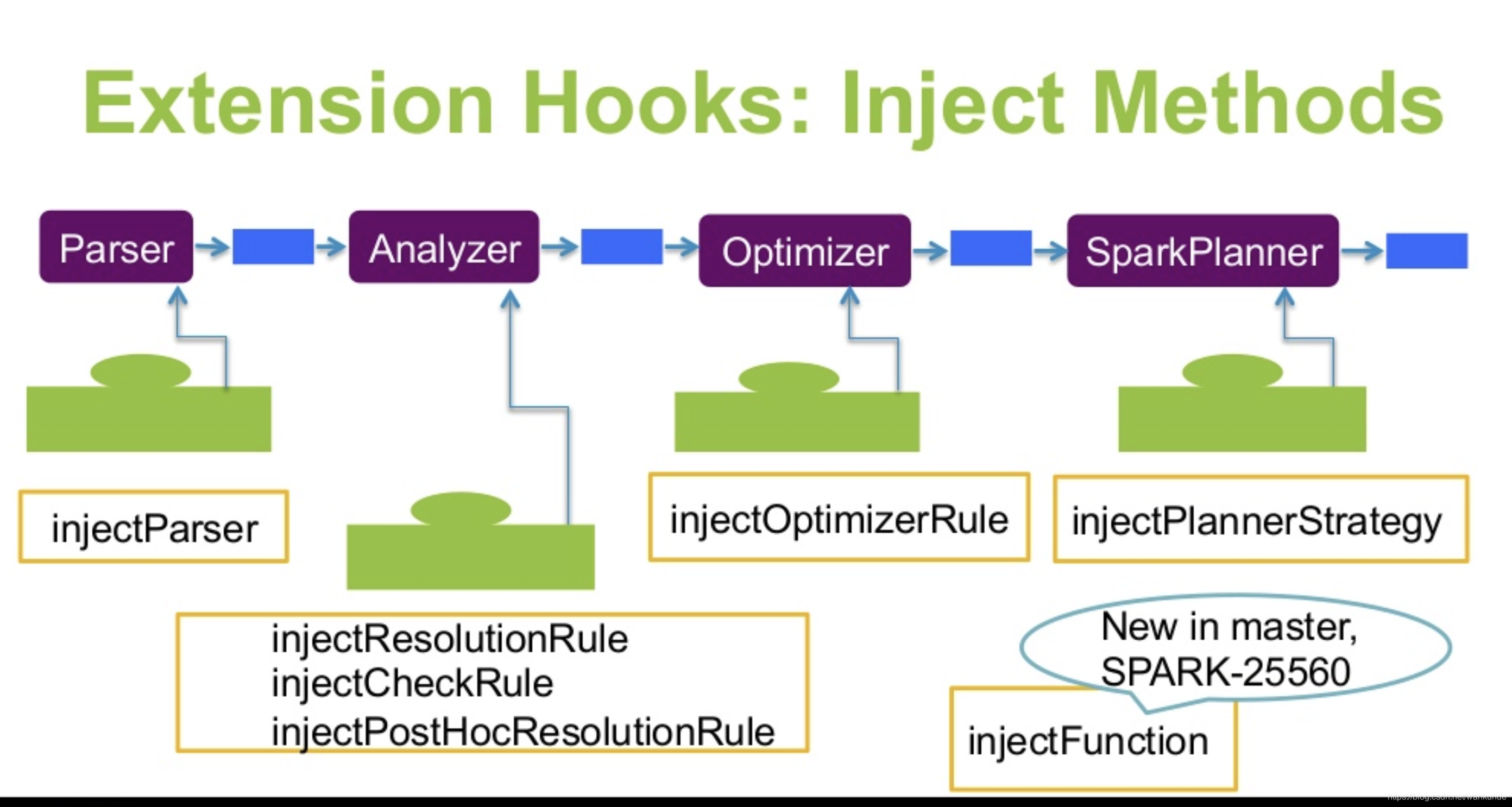
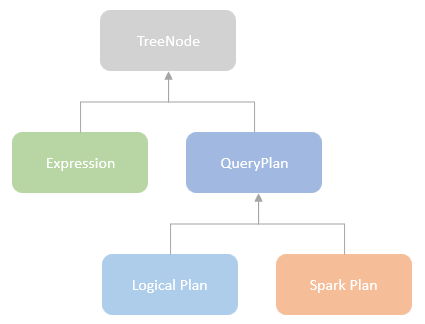
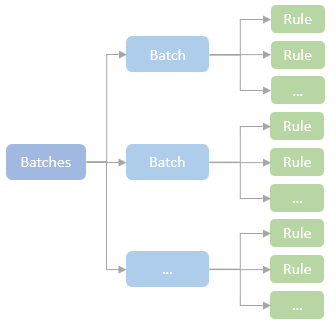
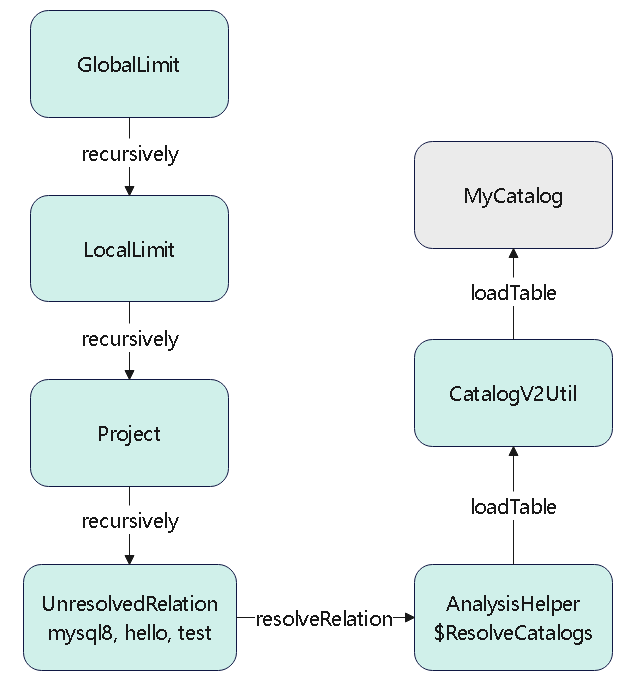
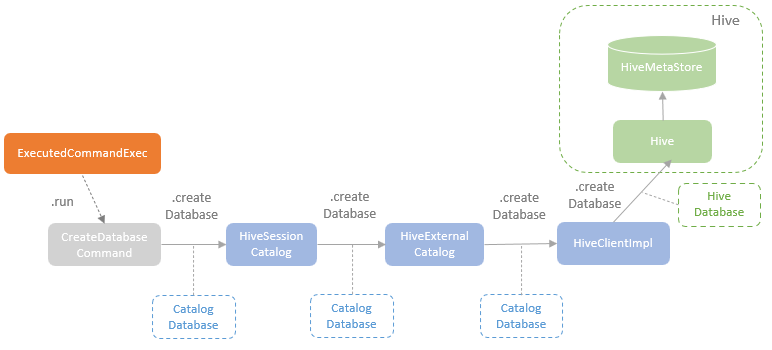
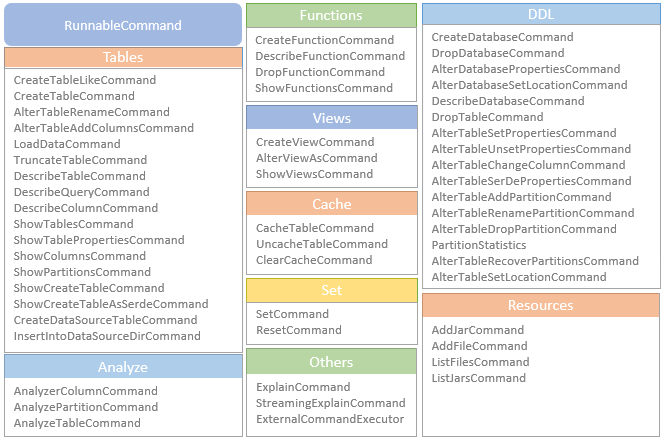
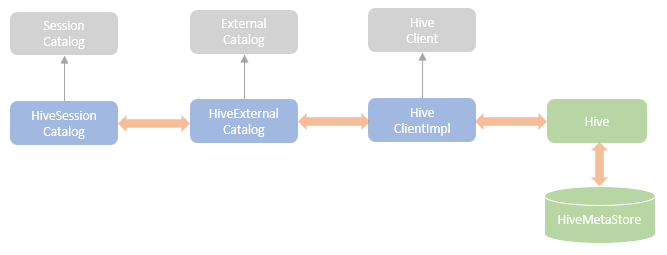
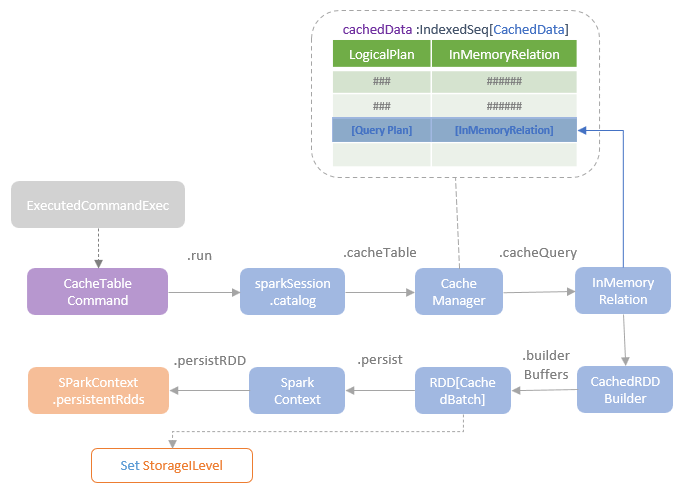
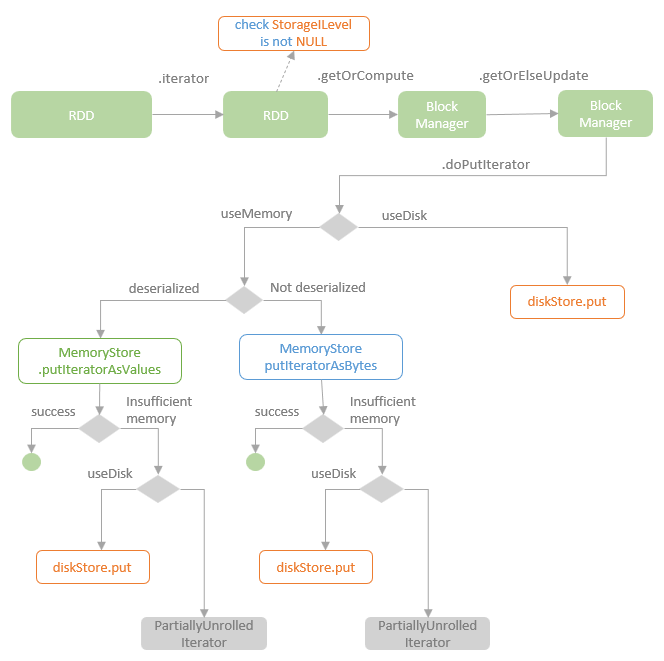
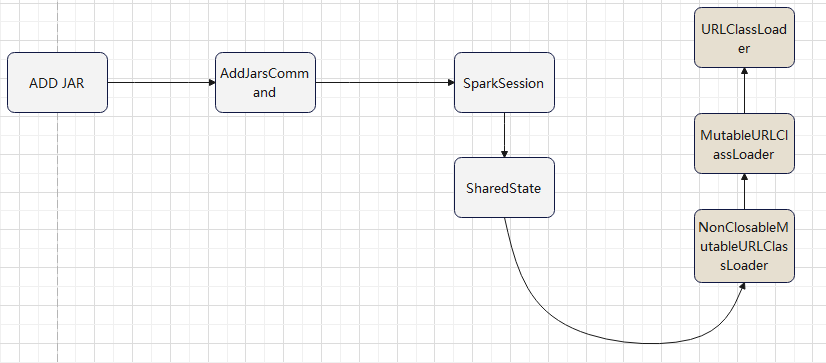
逻辑计划扩展,注入点。TreeNode的两个子类:Expression,QueryPlan。而 QueryPlan。而QueryPlan的子类是:LogicalPlan、SparkPlan。并将规则分为Batch。 CatalogV2Util#loadTable会解析:库、表、列信息,ResolveReferences。内置的一堆优化规则。查询下推、join下推。SPark的catalog体系,主要拷贝各种SupportRead、Wirte、Dialect,各种数据源的Catalog扩展如HiveCatalog。SessionCatalog 会使用hive 的meta-store走老的catalog路线。自定义函数下推,继承UnboundFunction、ScalarFunction、AggregateFunction,使用Spark的线程上下文classloader 机制加载类,也是用 新Catalog扩展如MyCatalog去执行loadFunction、functionExists
阅读全文
2024年2月29日
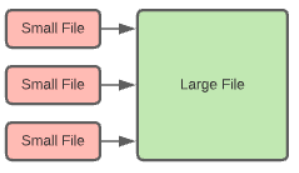
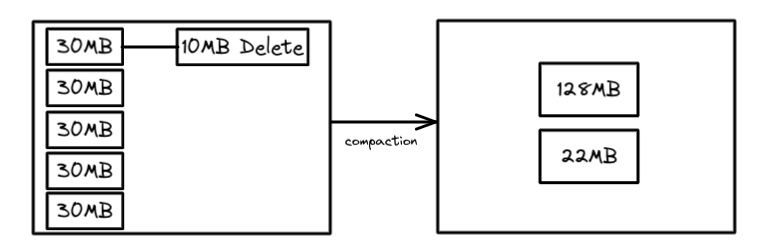
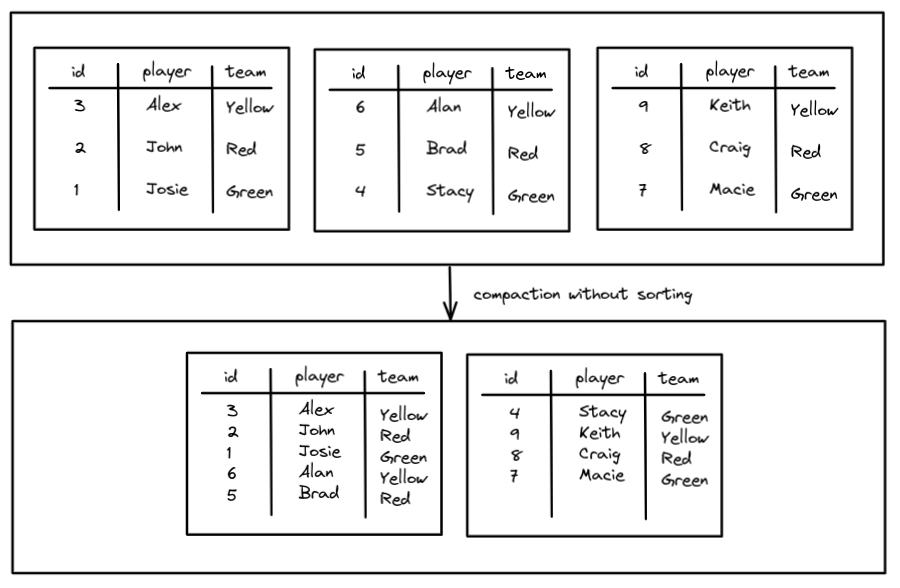
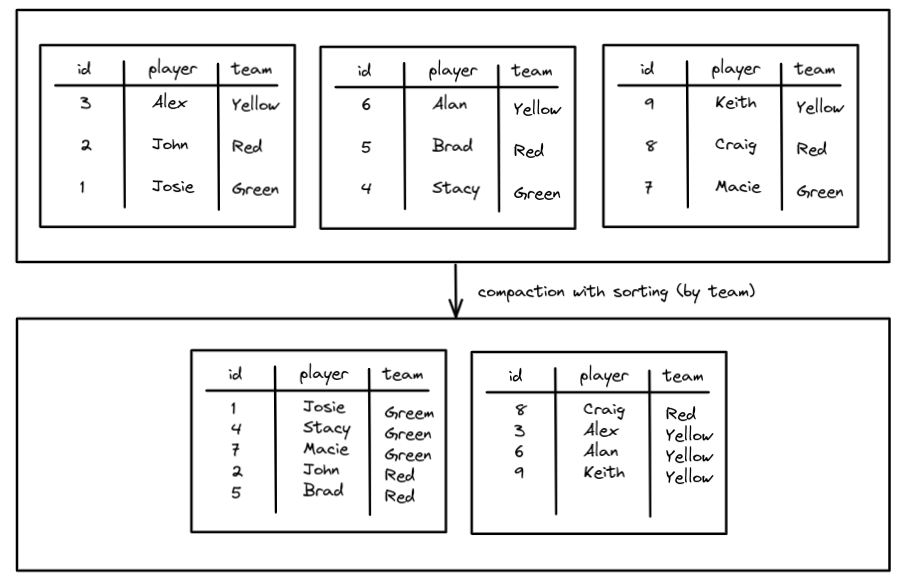
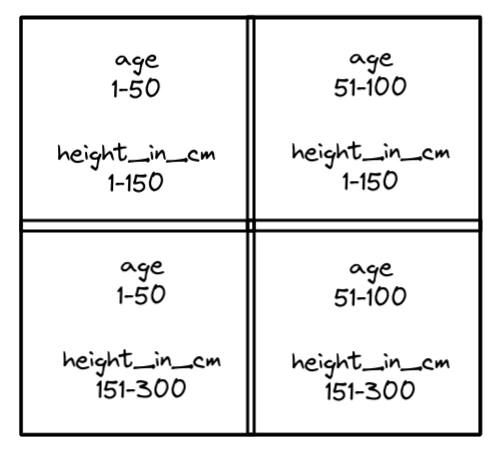
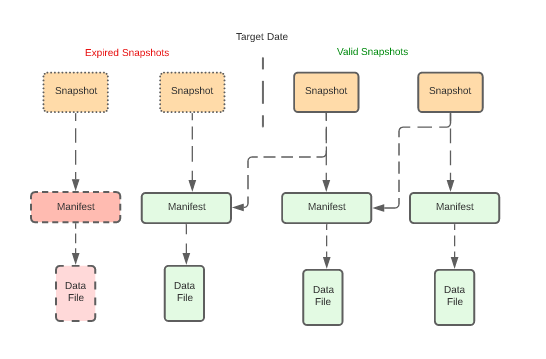
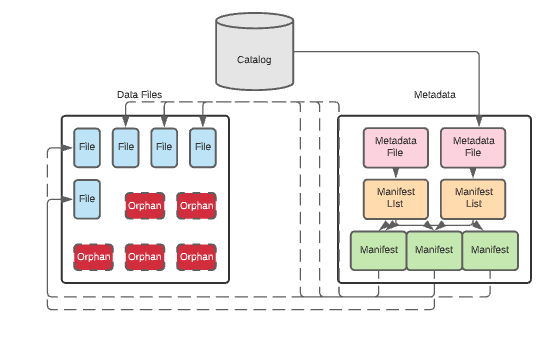
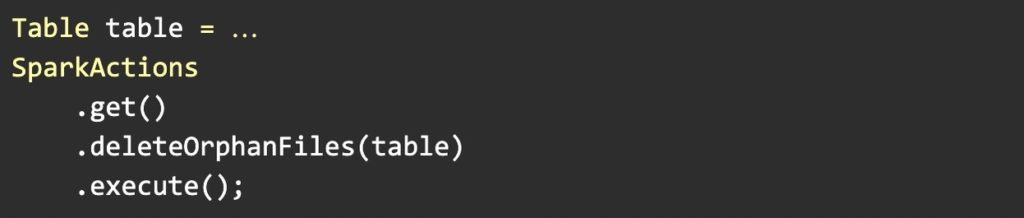
压缩,可以将多个小文件合并为大文件提高读性能,几种压缩策略:binpack(简单合并)、sort、z-order(适合多列查询),Expire Snapshots 可以删除过期的数据文件,还提供了参数可以自动删除manifest 文件、保留多少manifest文件,以及清除orphan 文件
阅读全文
2024年2月28日
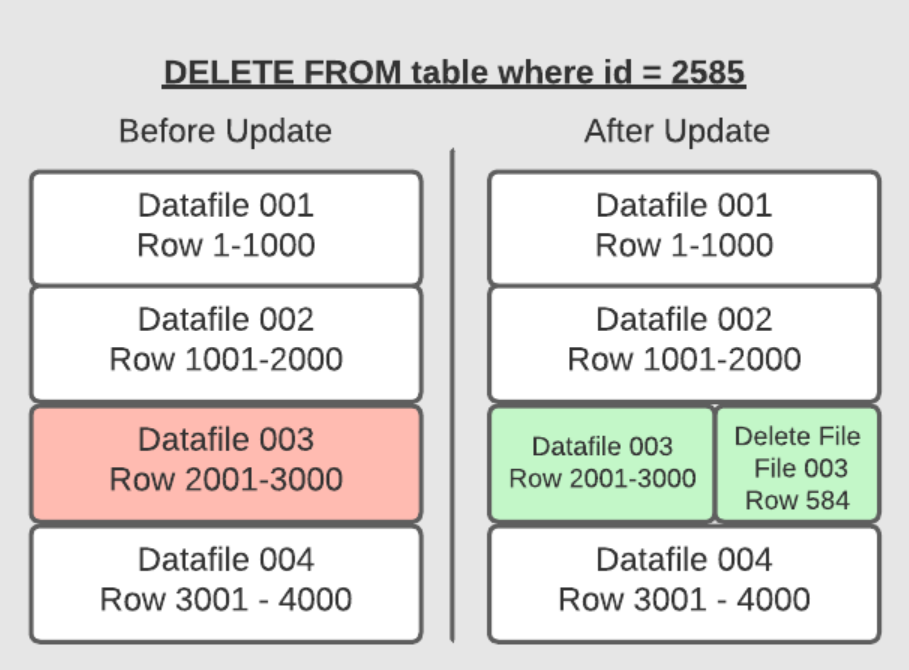
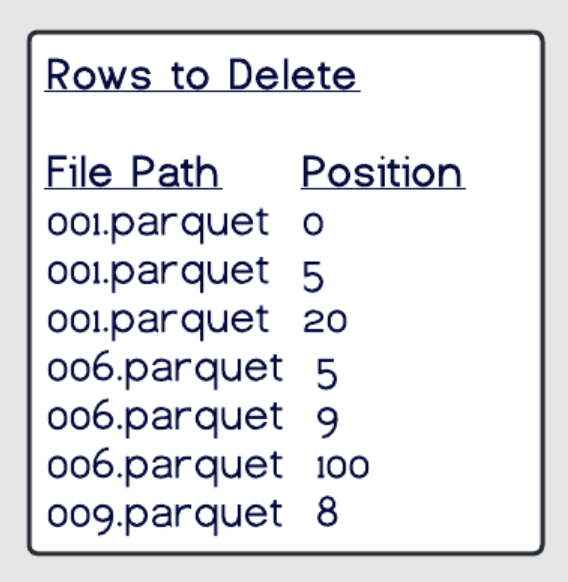
Copy-On-Write适用的场景和优缺点,Merge-On-Read的 position deletes、equality deletes 原理,以及适用的场景,优缺点,如何选择COW和MOR,以及如何配置他们
阅读全文