The leveldb library provides a persistent key value store. Keys and values are arbitrary byte arrays. The keys are ordered within the key value store according to a user-specified comparator function.
架构
LevelDB的底层存储使用的是 LSM树,这是一种为了写优化的磁盘存储结构
相比于 传统的 B+树,其写性能会好很多,但是读性能会差不少
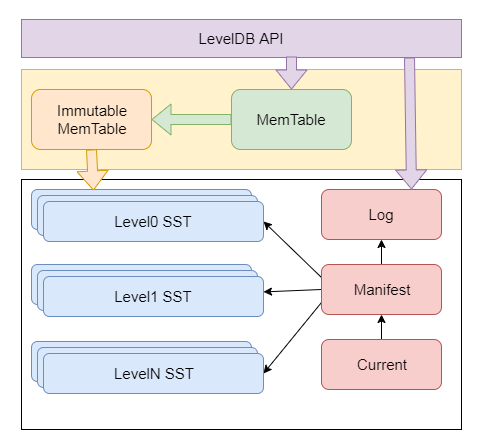
整体架构如下
图片来源,这里
主要组件介绍
- LevelDB对外提供了一套API,应用层可以调用API,包括各种读、写、自定义比较器,各种优化参数等
- MemTable,新的数据会放到这里,skip-list实现
- Log,写MemTable之前会先写Log文件,通过append方式追加,完全顺序写入,跟 DB的 WAL 类似
- Immutable Memtable,当MemTable容量达到上限后,会变成不可变的,后台线程会将其写入成 SST
- SST,磁盘存储结构,分为 Level0 到 LevelN多层,其中 Level0是由 immutable生成的,其他层是由上一层和本层归并产生的
- Manifest,记录 SST文件在不同Level的分布,单个SST文件的min、max key等元信息
- Current,Manifest可能有多个,而LevelDB启动时会找到Current文件,它记录了当前Manifest文件名
读写交互过程
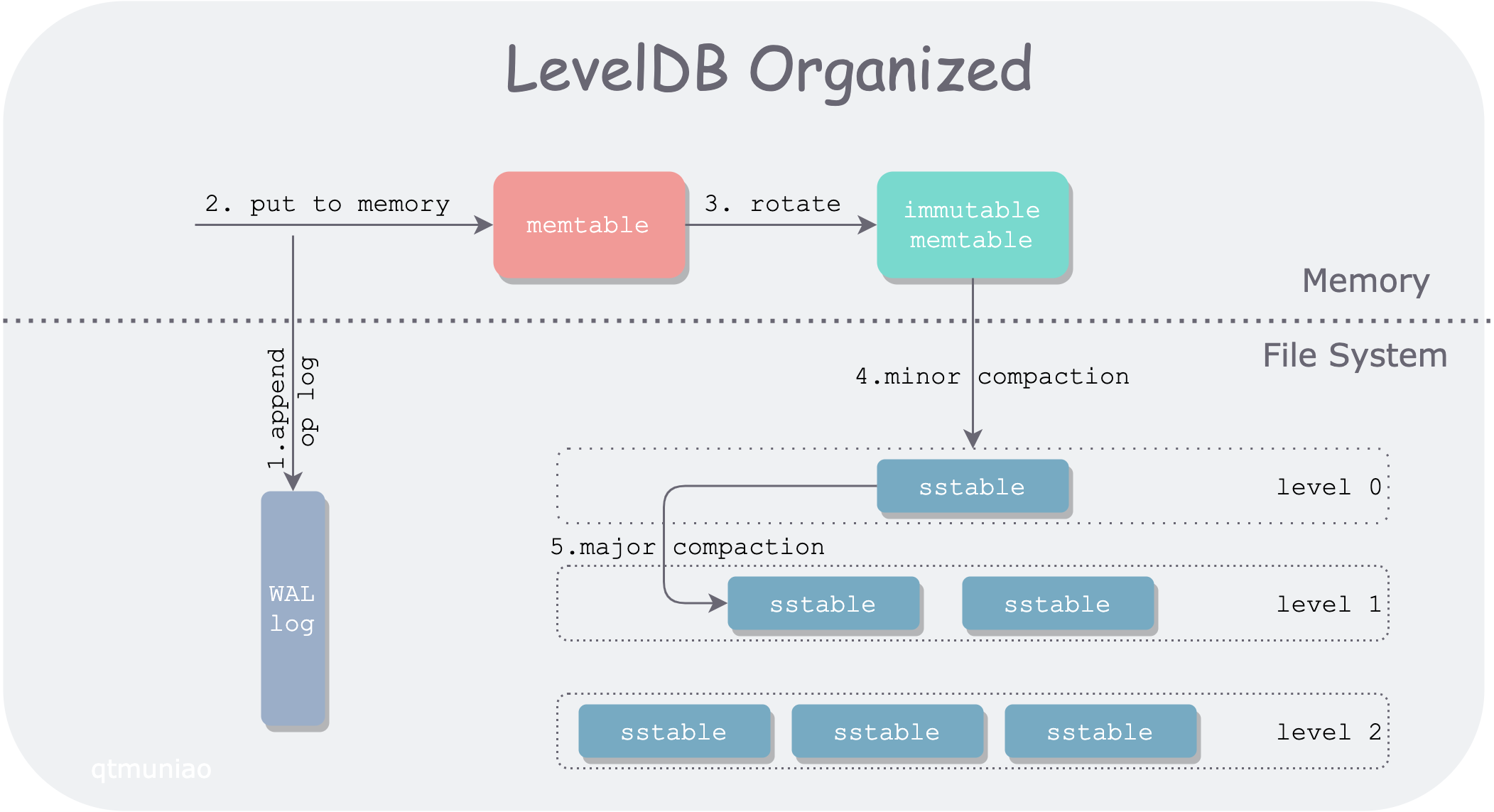
- 当 LevelDB 收到一个写入请求 put(k, v) ,会首先将其操作日志追加到日志文件(WAL)中,以备节点意外宕机恢复
- 写完 WAL 后,LevelDB 将该条 kv 插入内存中的查找结构:memtable
- 在 memtable 积累到一定程度后,会 rotate 为一个只读 memtable,即 immutable memtable;同时生成一个新的 memtable 以供写入
- 当内存有压力后,会将 immutable memtable 顺序写入文件系统,生成一个 level0 层的 sstable(sorted strings table) 文件。该过程称为一次 minor compaction
- 由于查询操作需要按层次遍历 memtable、immutable 和 sstable。当 sstable 文件生成的越来越多之后,查询性能必然越来越差,因此需要将不同的 sstable 进行归并,称为 major compaction
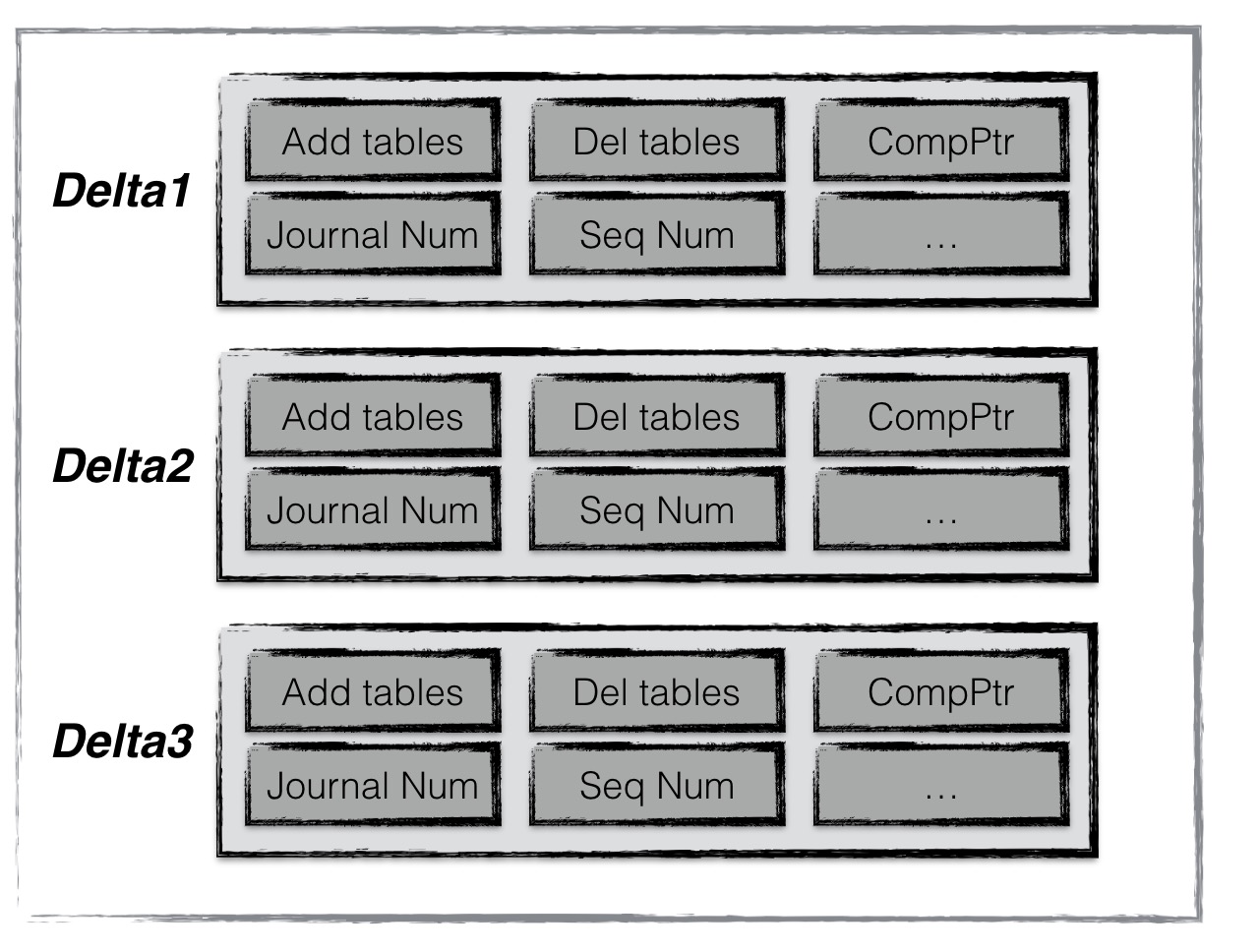
manifest 版本
- 每个版本都会记录当前层中所有文件的元数据,如文件大小,min、max key等,还有一些 compaction信息
- 每次压缩完,都会创建一个新版本,其规则为:versionNew = versionOld + versionEdit
- versoinEdit 就是基于旧版本基础上,变化的内容
- manifest 用来记录这些变化信息
图片来源,这里
如上是一个 manifest文件,包含了 3条 versionEdit记录,每条包括
- 新增哪些 SST
- 删除哪些 SST
- 当前 compaction下标
- 操作 seqNumber信息等
启动时,通过不断apply这些记录,能就得到上一次运行结束后的版本
一个数据库目录中会有多个 manifest 文件,而 current 就指定当前的 manifest文件
主要功能点介绍
基本操作
打开一个数据库
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
#include <cassert>
#include "leveldb/db.h"
leveldb::DB* db;
leveldb::Options options;
options.create_if_missing = true;
leveldb::Status status = leveldb::DB::Open(options, "/tmp/testdb", &db);
assert(status.ok());
...
// 不存在则报错
options.error_if_exists = true;
// 状态检查
leveldb::Status s = ...;
if (!s.ok()) cerr << s.ToString() << endl;
// 关闭
delete db;
|
读写
1
2
3
4
|
std::string value;
leveldb::Status s = db->Get(leveldb::ReadOptions(), key1, &value);
if (s.ok()) s = db->Put(leveldb::WriteOptions(), key2, value);
if (s.ok()) s = db->Delete(leveldb::WriteOptions(), key1);
|
原子更新
1
2
3
4
5
6
7
8
9
10
|
#include "leveldb/write_batch.h"
...
std::string value;
leveldb::Status s = db->Get(leveldb::ReadOptions(), key1, &value);
if (s.ok()) {
leveldb::WriteBatch batch;
batch.Delete(key1);
batch.Put(key2, value);
s = db->Write(leveldb::WriteOptions(), &batch);
}
|
默认是异步写,也可以转为同步写
调用的是fsync、fdatasync、msync
即使进程挂了,数据如果写入操作系统缓存了,数据也不会丢
1
2
3
|
leveldb::WriteOptions write_options;
write_options.sync = true;
db->Put(write_options, ...);
|
leveldb::DB 保证了原子性,被多个线程读写也是安全的
迭代
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
leveldb::Iterator* it = db->NewIterator(leveldb::ReadOptions());
for (it->SeekToFirst(); it->Valid(); it->Next()) {
cout << it->key().ToString() << ": " << it->value().ToString() << endl;
}
assert(it->status().ok()); // Check for any errors found during the scan
delete it;
// 范围迭代
for (it->Seek(start);
it->Valid() && it->key().ToString() < limit;
it->Next()) {
...
}
// 反向迭代
for (it->SeekToLast(); it->Valid(); it->Prev()) {
...
}
|
高级特性
快照
1
2
3
4
5
6
7
|
leveldb::ReadOptions options;
options.snapshot = db->GetSnapshot();
... apply some updates to db ...
leveldb::Iterator* iter = db->NewIterator(options);
... read using iter to view the state when the snapshot was created ...
delete iter;
db->ReleaseSnapshot(options.snapshot);
|
Slice,只是对 std::string 的包装,包含 length 和指向外部字节数组的指针,所以Slice操作很轻量
1
2
3
4
|
leveldb::Slice s1 = "hello";
std::string str("world");
leveldb::Slice s2 = str;
|
自定义比较器,默认是按照字典排序的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
class TwoPartComparator : public leveldb::Comparator {
public:
// Three-way comparison function:
// if a < b: negative result
// if a > b: positive result
// else: zero result
int Compare(const leveldb::Slice& a, const leveldb::Slice& b) const {
int a1, a2, b1, b2;
ParseKey(a, &a1, &a2);
ParseKey(b, &b1, &b2);
if (a1 < b1) return -1;
if (a1 > b1) return +1;
if (a2 < b2) return -1;
if (a2 > b2) return +1;
return 0;
}
// Ignore the following methods for now:
const char* Name() const { return "TwoPartComparator"; }
void FindShortestSeparator(std::string*, const leveldb::Slice&) const {}
void FindShortSuccessor(std::string*) const {}
};
|
使用新的比较器创建数据库
1
2
3
4
5
6
7
|
TwoPartComparator cmp;
leveldb::DB* db;
leveldb::Options options;
options.create_if_missing = true;
options.comparator = &cmp;
leveldb::Status status = leveldb::DB::Open(options, "/tmp/testdb", &db);
...
|
性能
相关配置参数在include/options.h.
BlockSize,默认为 4K,如果是大量 scan可以调大,甚至到 1M,如果都是小的点查,可以调小,比如 1K
压缩,默认是开启的,也可以关闭
1
2
3
|
leveldb::Options options;
options.compression = leveldb::kNoCompression;
... leveldb::DB::Open(options, name, ...) ....
|
缓存,内置了一个 LRU
1
2
3
4
5
6
7
8
9
|
#include "leveldb/cache.h"
leveldb::Options options;
options.block_cache = leveldb::NewLRUCache(100 * 1048576); // 100MB cache
leveldb::DB* db;
leveldb::DB::Open(options, name, &db);
... use the db ...
delete db
delete options.block_cache;
|
scan的时候也可以关闭
1
2
3
4
5
6
7
|
leveldb::ReadOptions options;
options.fill_cache = false;
leveldb::Iterator* it = db->NewIterator(options);
for (it->SeekToFirst(); it->Valid(); it->Next()) {
...
}
delete it;
|
Filter,内置了一个 bloom filter,用于减少读放大
1
2
3
4
5
6
7
|
leveldb::Options options;
options.filter_policy = NewBloomFilterPolicy(10);
leveldb::DB* db;
leveldb::DB::Open(options, "/tmp/testdb", &db);
... use the database ...
delete db;
delete options.filter_policy;
|
上面使用了 每个key 10个 bit
如果要自定义比较器,比如去掉后缀,并关联 bloom filter,可以这么写
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
class CustomFilterPolicy : public leveldb::FilterPolicy {
private:
leveldb::FilterPolicy* builtin_policy_;
public:
CustomFilterPolicy() : builtin_policy_(leveldb::NewBloomFilterPolicy(10)) {}
~CustomFilterPolicy() { delete builtin_policy_; }
const char* Name() const { return "IgnoreTrailingSpacesFilter"; }
void CreateFilter(const leveldb::Slice* keys, int n, std::string* dst) const {
// Use builtin bloom filter code after removing trailing spaces
std::vector<leveldb::Slice> trimmed(n);
for (int i = 0; i < n; i++) {
trimmed[i] = RemoveTrailingSpaces(keys[i]);
}
builtin_policy_->CreateFilter(trimmed.data(), n, dst);
}
};
|
check sum,默认是关闭的,也可以打开
1
|
ReadOptions::verify_checksums
|
大致的 size
统计出[a, c)的数量,以及 [x, z) 的数量
1
2
3
4
5
|
leveldb::Range ranges[2];
ranges[0] = leveldb::Range("a", "c");
ranges[1] = leveldb::Range("x", "z");
uint64_t sizes[2];
db->GetApproximateSizes(ranges, 2, sizes);
|
兼容性
LevelDB提供了Env,可以兼容不同的环境
比如在一个受限的环境中,需要限制LevelDB,不能让其影响其他活跃应用
1
2
3
4
5
6
7
8
|
class SlowEnv : public leveldb::Env {
... implementation of the Env interface ...
};
SlowEnv env;
leveldb::Options options;
options.env = &env;
Status s = leveldb::DB::Open(options, ...);
|
移植,可以兼容不同的平台
参考