Flink架构
架构
任务提交
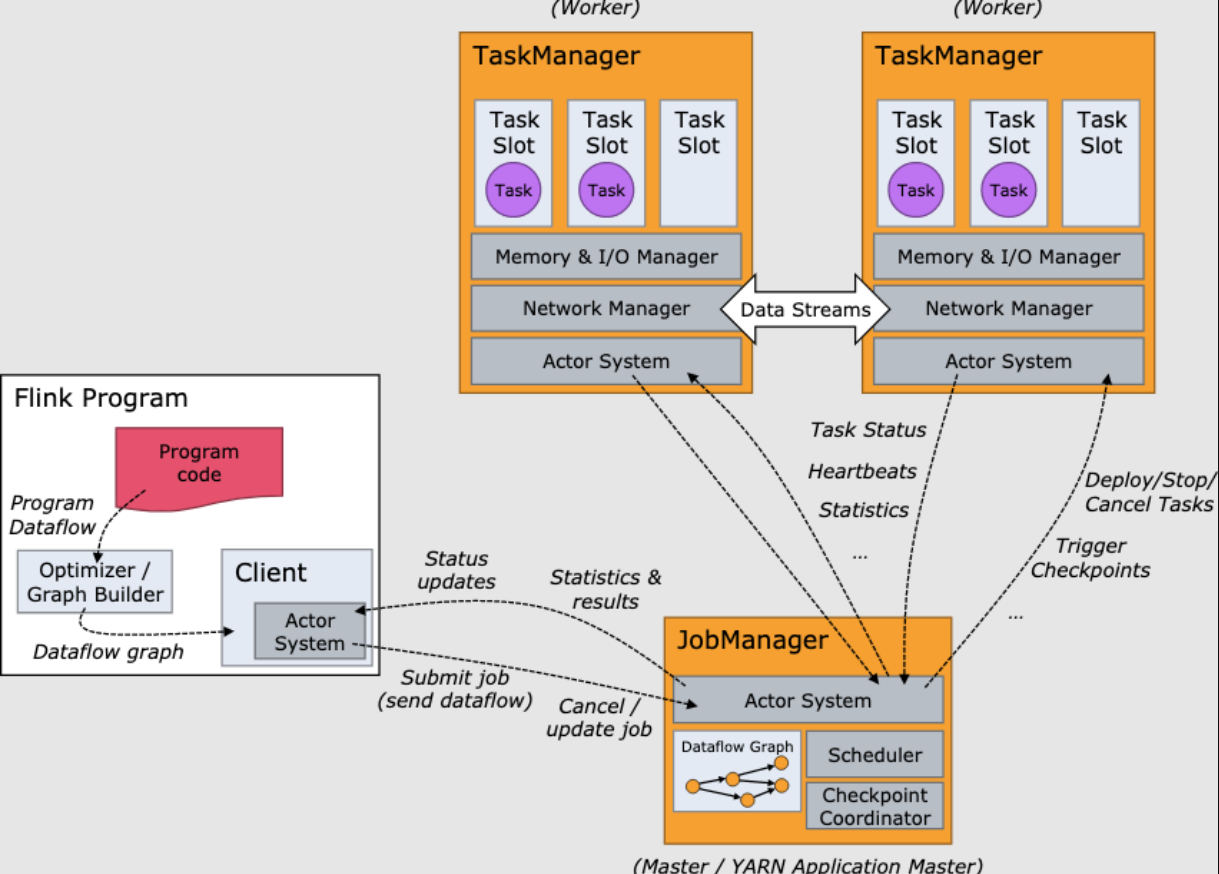
Flink Session集群的启动流程主要包含如下步骤
- 用户通过客户端命令启动Session Cluster,此时会触发整个集群服务的启动过程,客户端会向集群资源管理器申请Container计算资源以启动运行时中的管理节点
- ClusterManagement会为运行时集群分配Application主节点需要的资源并启动主节点服务,例如在Hadoop Yarn资源管理器中会分配并启动Flink管理节点对应的Container
- 客户端将用户提交的应用程序代码经过本地运行生成JobGraph结构,然后通过ClusterClient将JobGraph提交到集群运行时中运行
- 此时集群运行时中的Dispatcher服务会接收到ClusterClient提交的JobGraph对象,然后根据JobGraph启动JobManager RPC服务。JobManager是每个提交的作业都会单独创建的作业管理服务,生命周期和整个作业的生命周期一致
- 当JobManager RPC服务启动后,下一步就是根据JobGraph配置的计算资源向ResourceManager服务申请运行Task实例需要的Slot计算资源
- 此时ResourceManager接收到JobManager提交的资源申请后,先判断集群中是否有足够的Slot资源满足作业的资源申请,如果有则直接向JobManager分配计算资源,如果没有则动态地向外部集群资源管理器申请启动额外的Container以提供Slot计算资源
- 如果在集群资源管理器(例如Hadoop Yarn)中有足够的Container计算资源,就会根据ResourceManager的命令启动指定的TaskManager实例
- TaskManager启动后会主动向ResourceManager注册Slot信息,即其自身能提供的全部Slot资源。ReResourceManager接收到TaskManager中的Slot计算资源时,就会立即向该TaskManager发送Slot资源申请,为JobManager服务分配提交任务所需的Slot计算资源
- 当TaskManager接收到ResourceManager的资源分配请求后,TaskManager会对符合申请条件的SlotRequest进行处理,然后立即向JobManager提供Slot资源
- 此时JobManager会接收到来自TaskManager的offerslots消息,接下来会向Slot所在的TaskManager申请提交Task实例。TaskManager接收到来自JobManager的Task启动申请后,会在已经分配的Slot卡槽中启动Task线程
- TaskManager中启动的Task线程会周期性地向JobManager汇报任务运行状态,直到完成整个任务运行
客户端提交
|
|
Key Responsibilities of JobClient:
- Submitting Jobs: The JobClient allows users to submit jobs to a Flink cluster. It interacts with the Dispatcher to send a job request (along with job configurations) to the cluster. The Dispatcher then forwards the job to the JobMaster for execution.
- Monitoring Jobs: Once a job is submitted, the JobClient can be used to track the status and progress of the job. It can provide information such as:
- Job state (running, finished, failed, etc.)
- Progress of the tasks
- Job result, if applicable
- Handling Job Completion: The JobClient can handle the completion of a job, whether the job has finished successfully, failed, or was canceled. It provides mechanisms to retrieve the final job result and perform any necessary cleanup.
- Job Cancellation: If required, the JobClient can also cancel a running job, which informs the JobMaster to stop the job and release resources.
- Accessing Job Results: After a job completes, the JobClient can be used to retrieve the results, especially when using operations like collect(), or to query metrics and diagnostics about the job.
集群启动
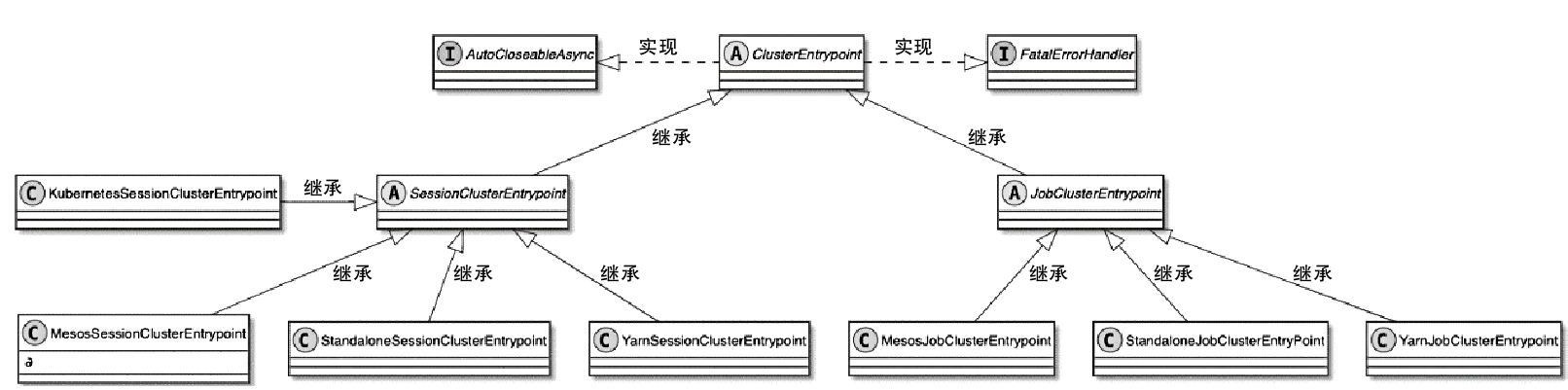
ClusterEntrypoint 是入口点
- 可以创建出 pre 集群,就是每个提交一个集群
- 以及 session 集群
- 注意,新版本 pre 集群入口main 类是:ApplicationClusterEntryPoint
- session 集群入口 main 类是:StandaloneSessionClusterEntrypoint
- 如果是单机版的入口是:MiniCluster
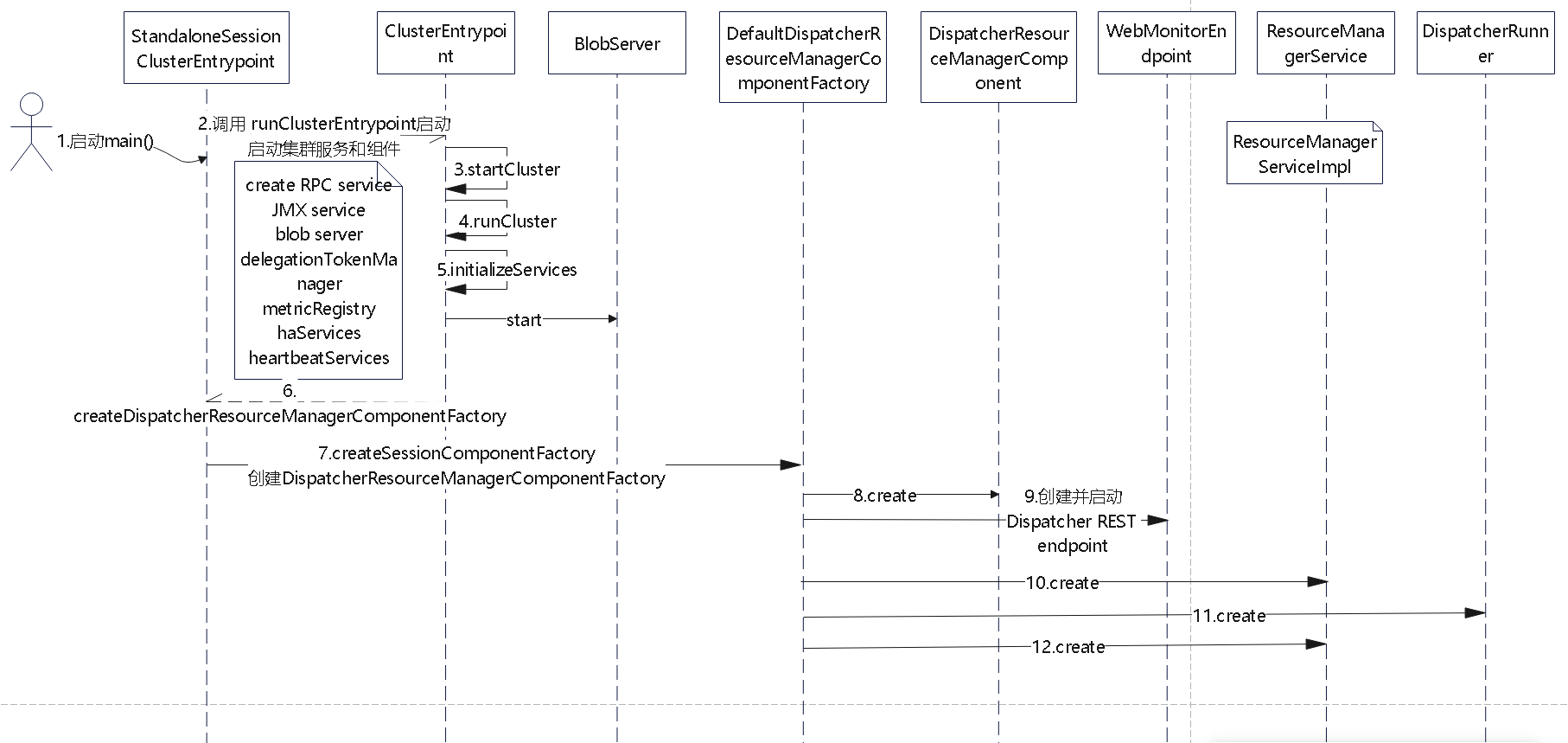
StandaloneSession集群启动流程
- 还会创建其他一些组件
- create RPC service
- JMX service
- blob server
- delegationTokenManager
- metricRegistry
- haServices
- heartbeatServices
DispatcherResourceManagerComponent的 create函数包含了一堆必要组件
|
|
DispatcherResourceManagerComponentFactory 类图
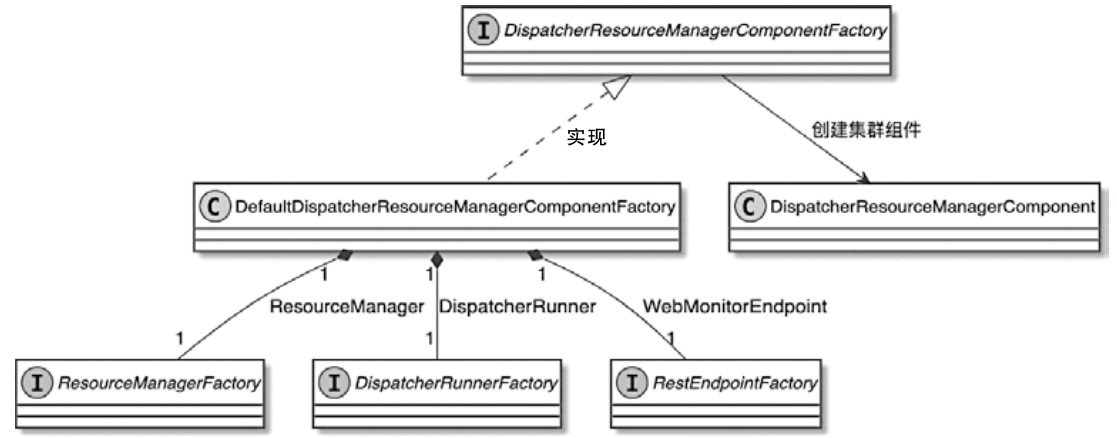
几个重要组件
WebMonitorEndpoint
创建 DispatcherRunner
- 创建HistoryServerArchivist,用于在HistoryServer上对指定的AccessExecutionGraph进行历史归档
- 创建PartialDispatcherServices,用于提供Dispatcher组件使用的一部分服务,包括高可用、blobServer等
- 调用dispatcherRunnerFactory.createDispatcherRunner()方法创建DispatcherRunner对象
- 创建参数,包括前面创建的所有参数信息,而DispatcherRunner会在后面被leaderElectionService服务启动和执行
WebMonitorEndpoint
- 基于Netty通信框架实现了Restful的服务后端,提供Restful接口支持Flink Web页面在内的所有Rest请求
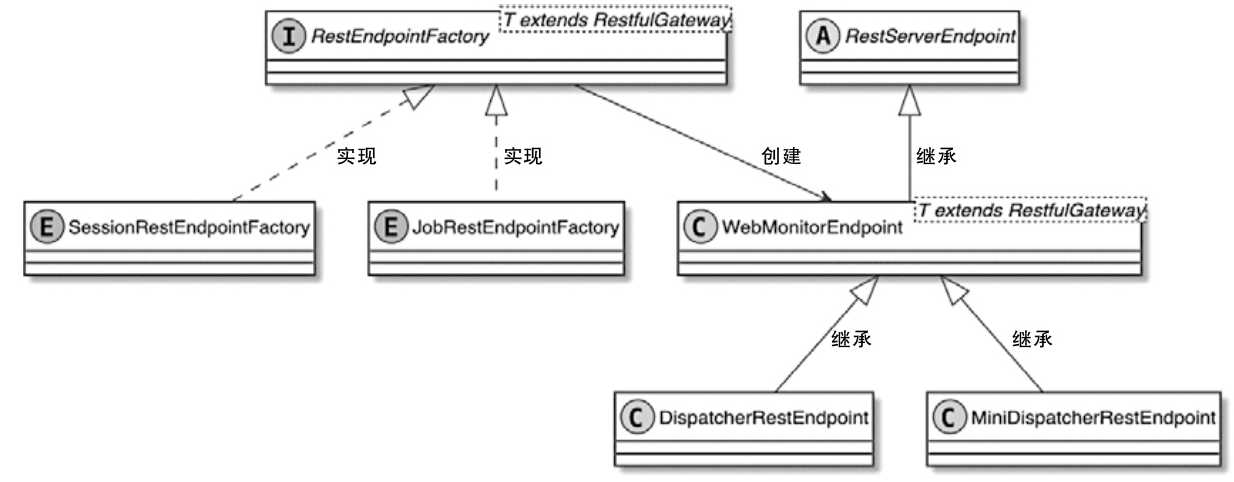
DispatcherRestEndpoint
- dispatcherGatewayRetriever:DispatcherGateway服务地址获取器,用于获取当前活跃的dispatcherGateway地址。基于dispatcherGateway可以实现与Dispatcher的RPC通信,最终提交的JobGraph通过dispatcherGateway发送给Dispatcher组件
- resourceManagerGatewayRetriever:ResourceManagerGateway服务地址获取器,用于获取当前活跃的ResourceManagerGateway地址,通过Re
- ResourceManagerGateway实现ResourceManager组件之间的RPC通信,例如在TaskManagersHandler中通过调用ResourceManagerGateway获取集群中的TaskManagers监控信息
- transientBlobService:临时二进制对象数据存储服务,BlobServer接收数据后,会及时清理Cache中的对象数据
- executor:用于处理WebMonitorEndpoint请求的线程池服务
- metricFetcher:用于拉取JobManager和TaskManager上的Metric监控指标
- leaderElectionService:用于在高可用集群中启动和选择服务的Leader节点,如通过leaderElectionService启动WebMonitorEndpoint RPC服务,然后将Leader节点注册至ZooKeeper,以此实现WebMonitorEndpoint服务的高可用
- fatalErrorHandler:异常处理器,当WebMonitorEndpoint出现异常时调用fatalError-Handler的中处理接口
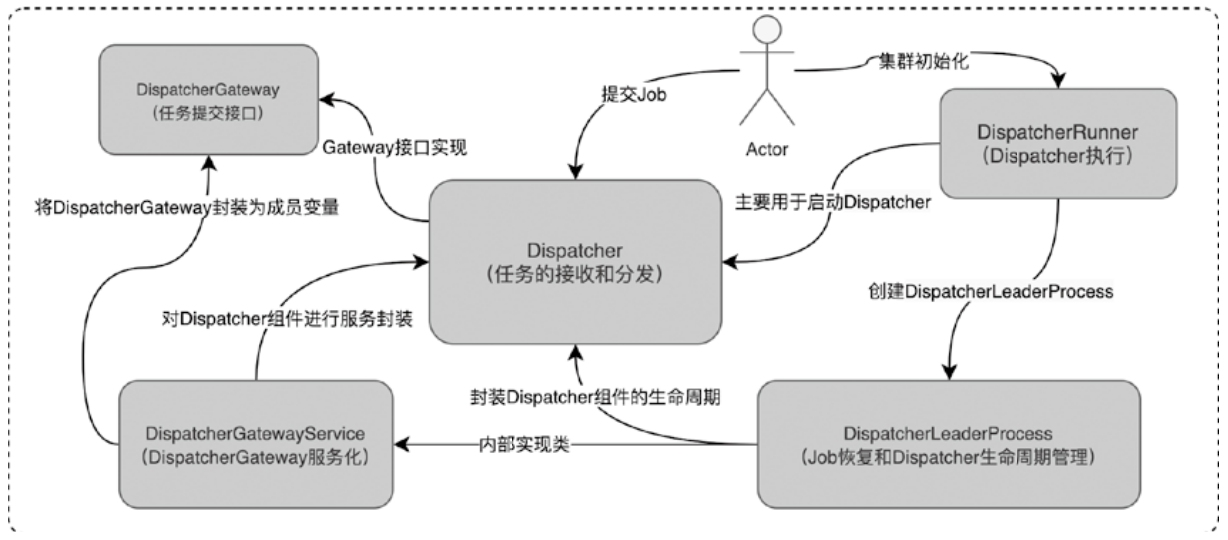
Dispatcher
Dispatcher主要涉及模块示意图
- Dispatcher:负责对集群中的作业进行接收和分发处理操作,客户端可以通过与Dispatcher建立RPC连接,将作业过ClusterClient提交到集群Dispatcher服务中。Dispatcher通过JobGraph对象启动JobManager服务
- DispatcherRunner:负责启动和管理Dispatcher组件,并支持对Dispatcher组件的Leader选举。当Dispatcher集群组件出现异常并停止时,会通过DispatcherRunner重新选择和启动新的Dispatcher服务,从而保证Dispatcher组件的高可用
- DispatcherLeaderProcess:负责管理Dispatcher生命周期,同时提供了对JobGraph的任务恢复管理功能。
- DispatcherGatewayService:主要基于Dispatcher实现的GatewayService,用于获取DispatcherGateway
DispatcherRunner 类图
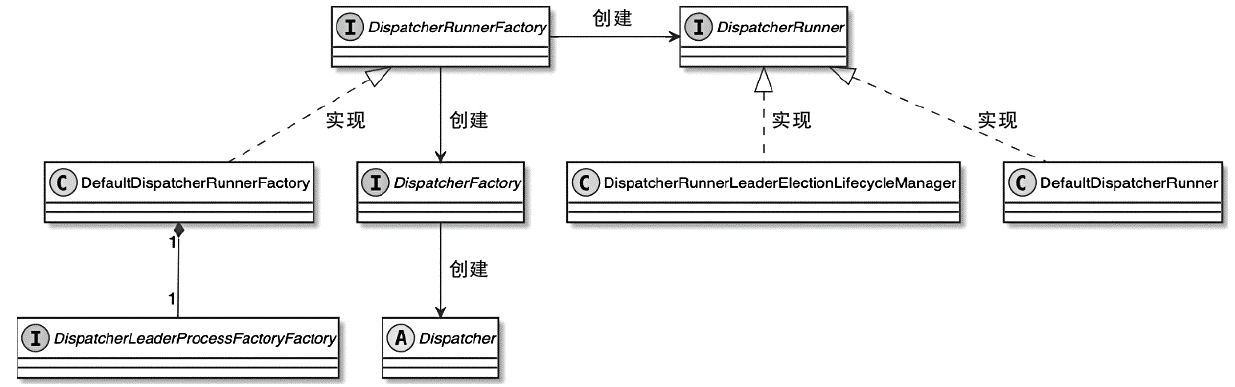
DispatcherLeaderProcess的创建关系
|
|
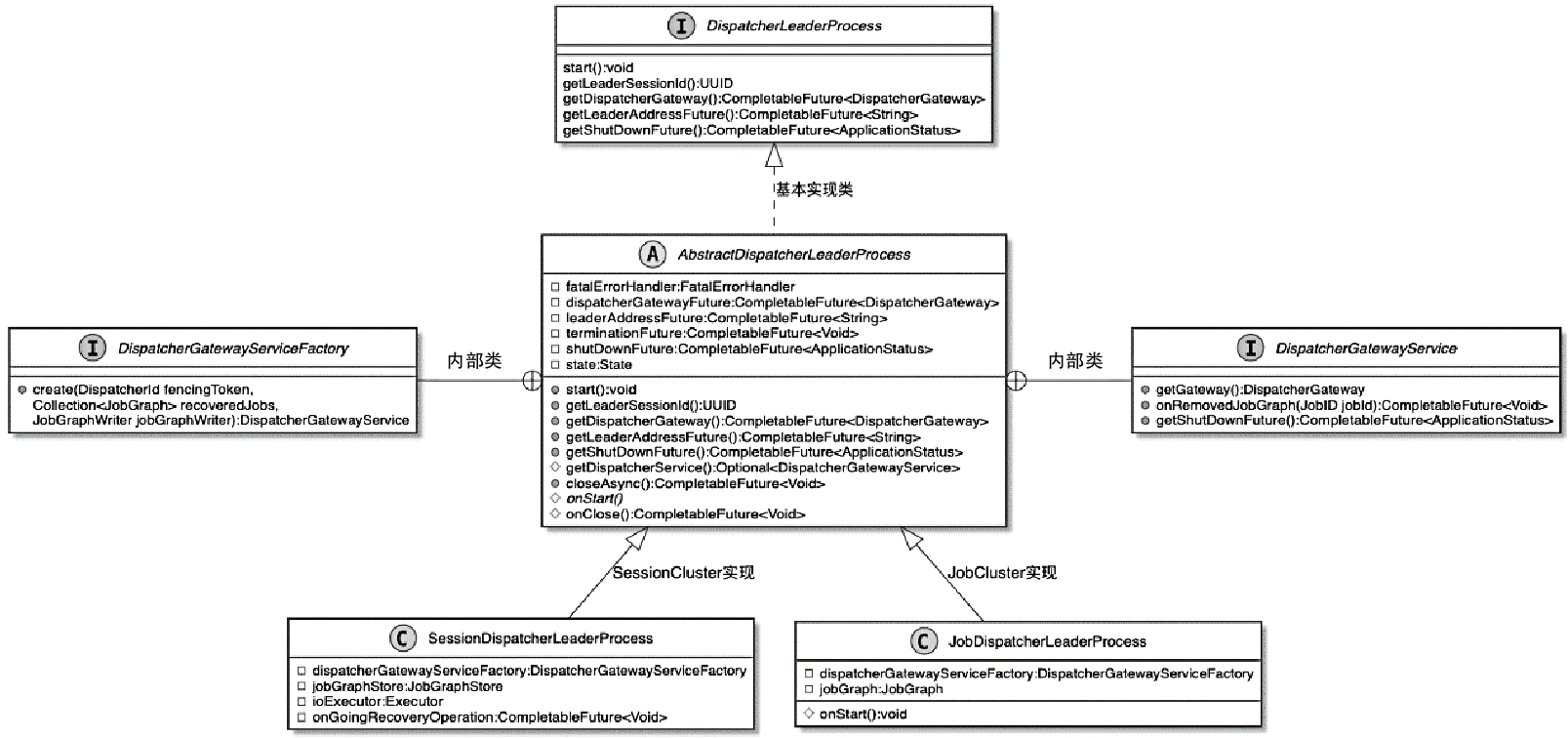
DispatcherLeaderProcess 类图
- SessionDispatcherLeaderProcess实现类中主要实现了与Session集群相关的Dispatcher处理逻辑,主要用于对JobGraphStore中存储的JobGraph进行恢复
- 在非高可用集群下,JobGraphStore的实现类为StandaloneJobGraphStore,也就是不对JobGraph进行存储和管理
- 在高可用集群中,JobGraphStore基于ZooKeeper存储集群中的JobGraph
- JobDispatcherLeaderProcess实现类中包含了对单个JobGraph进行创建和提交的方法
ResourceManager
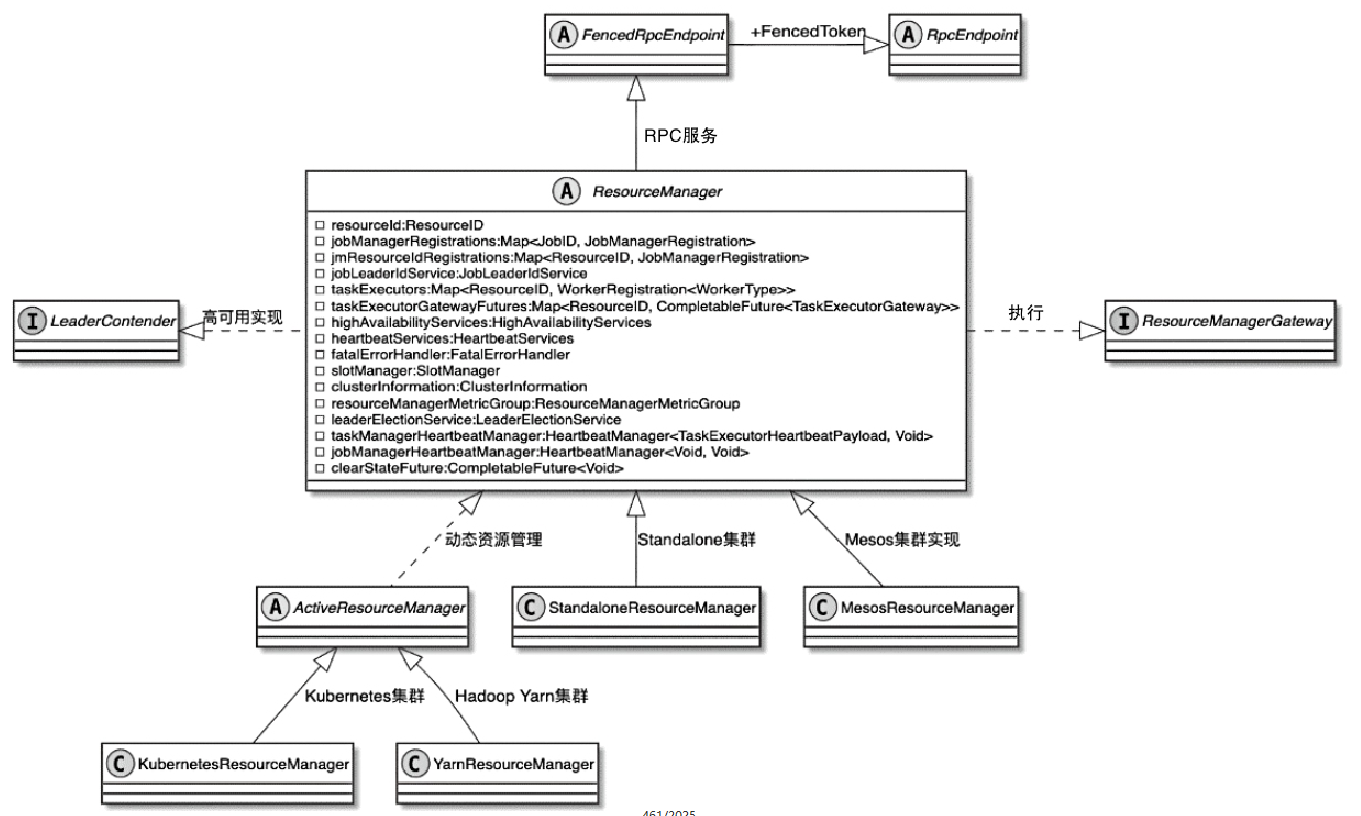
ResourceManager 实现类
- 实现类:ActiveResourceManager
- 实现类:StandaloneResourceManager
- 继承自 RpcEndpoint
- 本质上是一个 RPC 服务
其他一些要创建的组件
- RpcService
- HeartbeatServices
- HighAvailabilityServices
- SlotManager
- JobLeaderIdService
SlotMatchingStrategy
- LeastUtilizationSlotMatchingStrategy,即按照利用率最低原则匹配Slot资源
- AnyMatchingSlotMatchingStrategy,即直接返回第一个匹配的Slot资源策略
ResourceManager 类图
- ActiveResourceManager 表示动态资源申请的
- StandaloneResourceManager 是standalone 模式的
- 通过实现 RpcEndpoint 可以作为 RPC 对外提供服务
- 也实现了 高可用
ResourceManager 内部的其他一些信息
- jobManagerRegistrations:专门存储JobManager注册信息
- jobLeaderIdService
- taskExecutors:注册在ResourceManager的TaskExecutor列表中,其中Key为TaskExecutor对应的ResourceID,Value为WorkRegistration,即TaskExecutor向ResourceManager注册过程中所提供的信息
- highAvailabilityServices
- heartbeatServices
- fatalErrorHandler:系统异常错误处理
- slotManager:ResourceManager的内部组件,用于管理集群的可用Slot资源,同时接收并处理TaskExecutor的SlotReport
- taskManagerHeartbeatManager
- jobManagerHeartbeatManager
- clearStateFuture:用于停止ResourceManager后进行数据异步清理
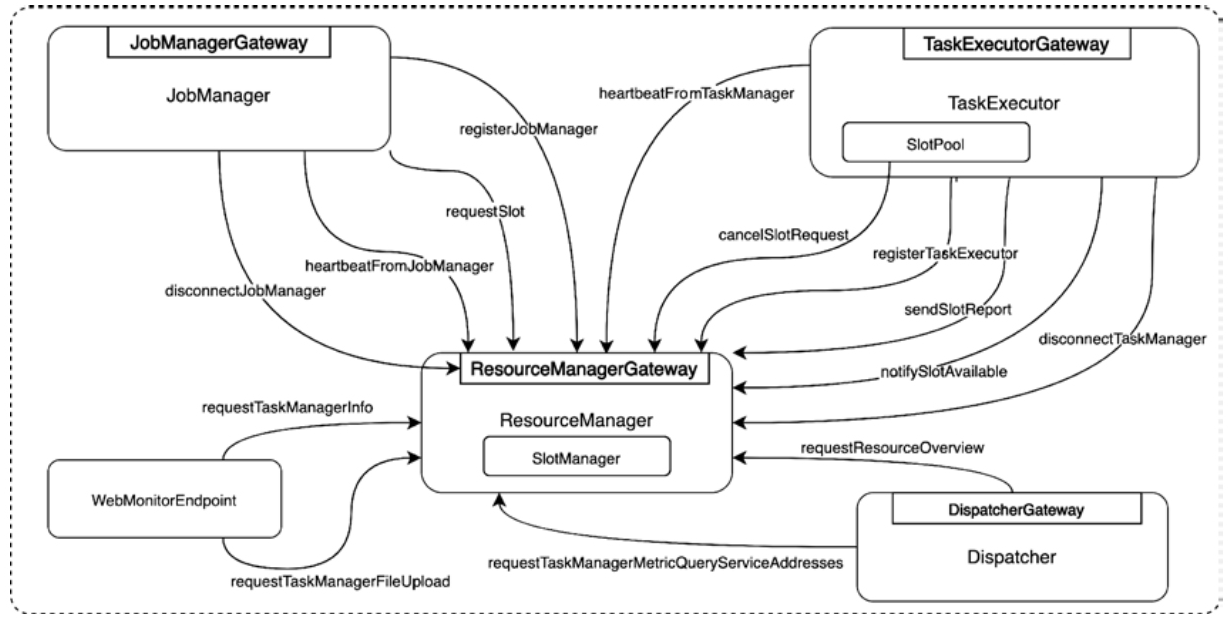
ResourceManager调用关系图
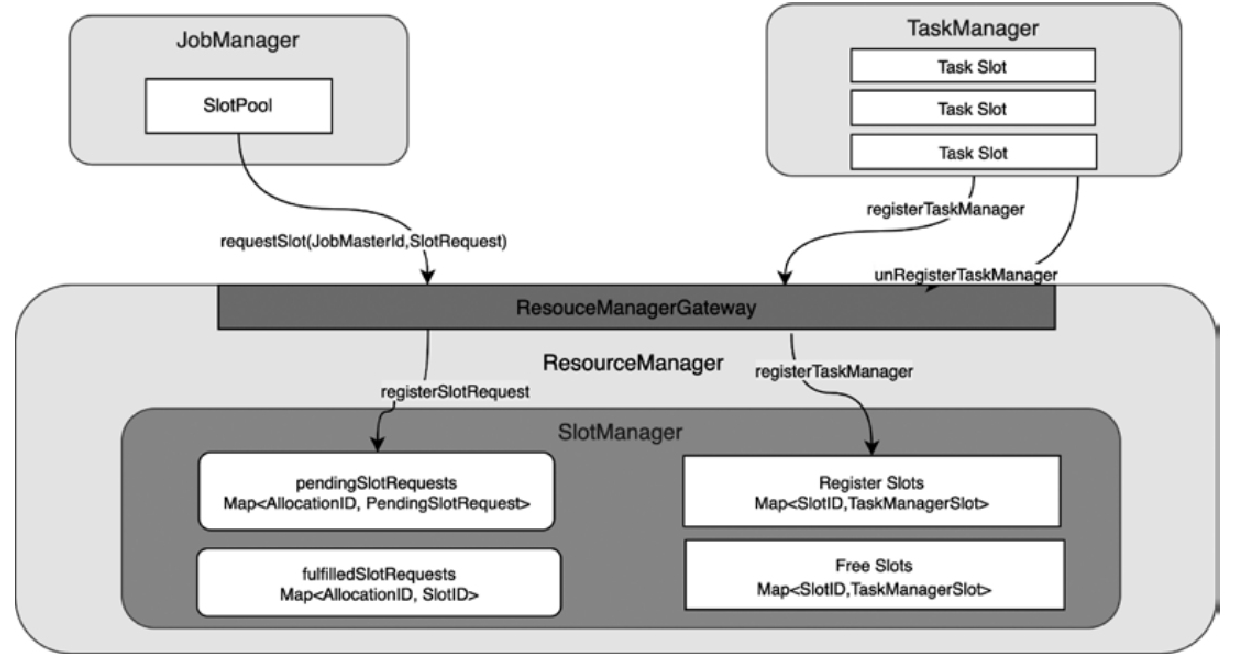
Slot计算资源管理
- 包含了SlotID、ResourceProfile以及TaskExecutorConnection等信息
- 如果Slot被分配使用,在TaskManagerSlot中还会存储AllocationID和JobID等分配信息
- SlotManager还包含了pendingSlotRequests和fulfilledSlotRequests两个键值对集合
- pendingSlotRequests存储了所有处于pending和unfulfilled状态的Slot请求
- fulfilledSlotRequests存储了所有已经分配完成的Slot请求
SlotManager接口的主要函数
- start
- processResourceRequirements
- registerTaskManager
- unregisterTaskManager
- reportSlotStatus
- freeSlot
- setFailUnfulfillableRequest
- triggerResourceRequirementsCheck
TaskManager
TaskManager 的启动过程
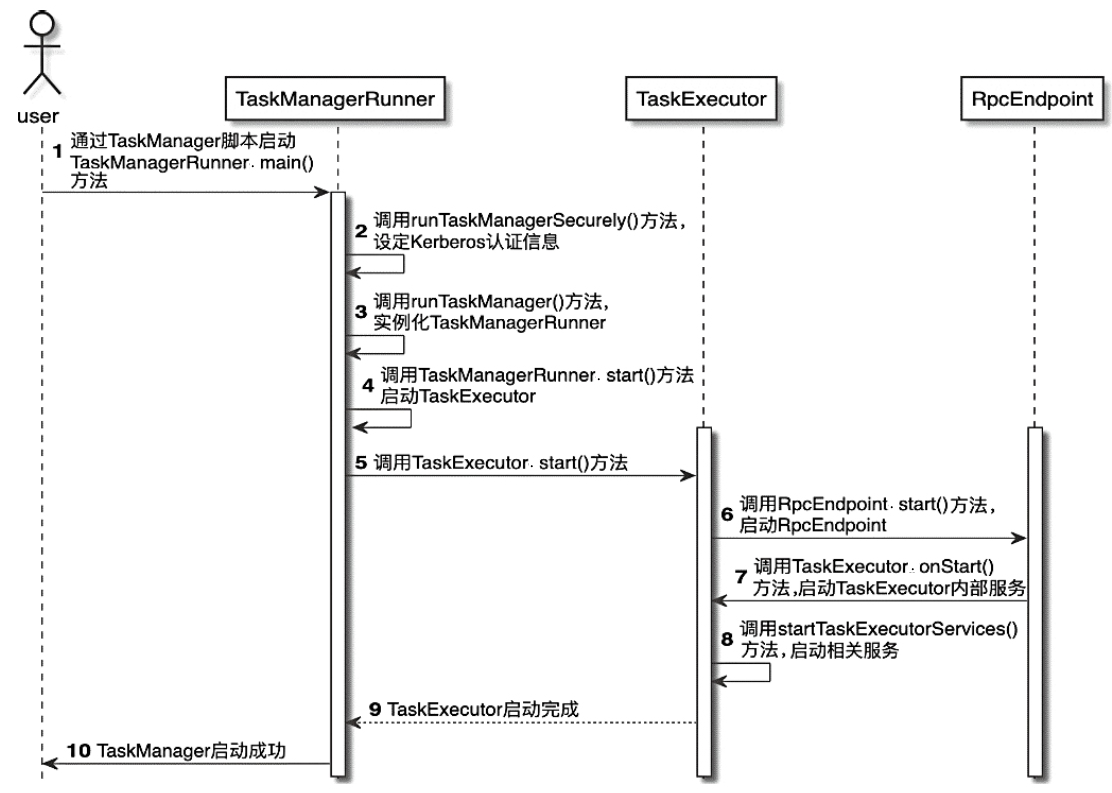
TaskExecutor
- 调用resourceManagerLeaderRetriever.start()方法,用于创建ResourceManager之间的RPC连接,此时会将TaskManager的资源信息汇报给ResourceManager
- 调用taskSlotTable.start()方法启动TaskSlotTable,用于管理当前TaskManager中的Slot计算资源
- 启动JobLeaderService服务,用于和JobManager进行RPC通信,监听和获取JobManager当前活跃的Leader节点
- 创建FileCache对象,用于存储Task在执行过程中从PermanentBlobService拉取的文件,并将文件展开在/tmp_/路径中,如果Task处于非注册状态超过5秒,将清理临时文件
高可用
HighAvailabilityServices 类图
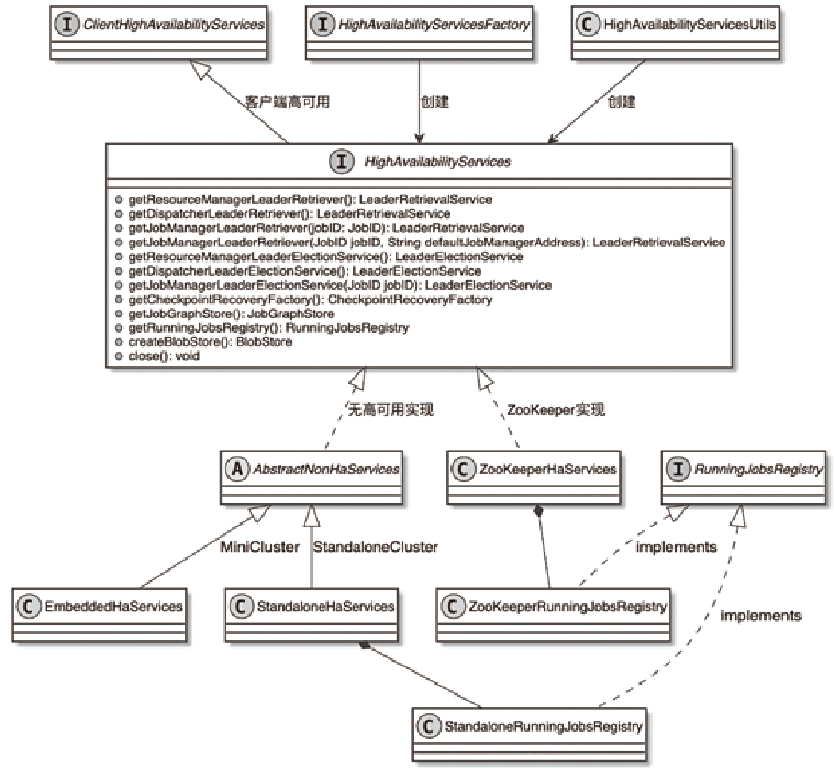
HighAvailabilityMode 主要有
- NONE,创建 EmbeddedHaServices
- ZOOKEEPER,创建 ZooKeeperMultipleComponentLeaderElectionHaServices 实例
- FACTORY_CLASS,自定义高可用服务
- KUBERNETES,作为自定义类型,创建:KubernetesHaServicesFactory
HighAvailabilityServices 和客户端的关系
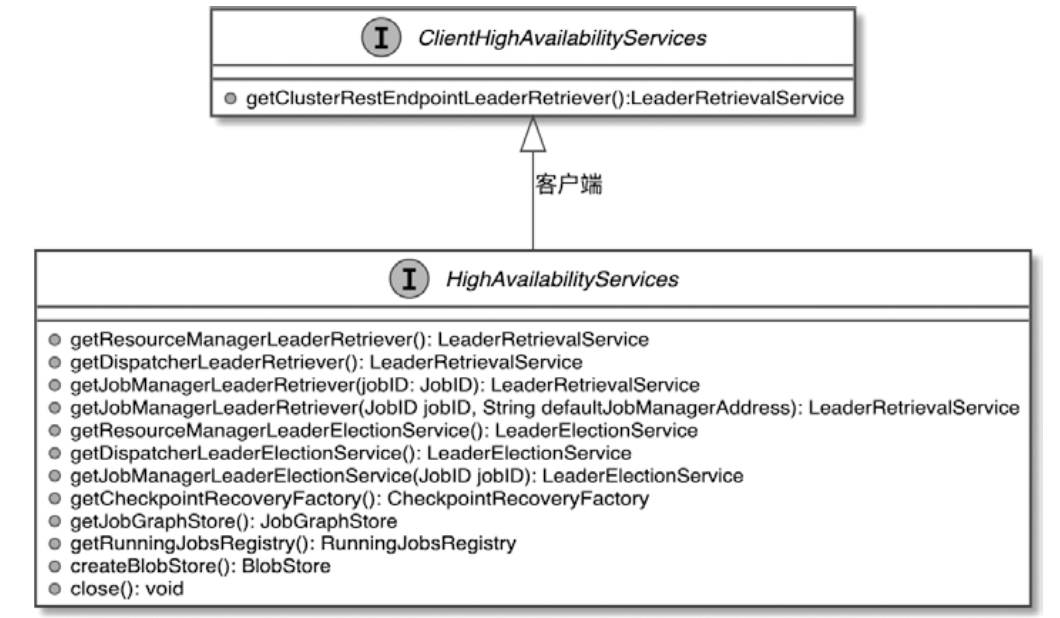
相关组件需要使用的高可用
- ResourceManager
- Dispatcher
- JobManager
- WebMonitorEndpoint
- CheckpointRecoveryFactory
- JobGraphStore
- RunningJobsRegistry
- BlobStore
ZooKeeperHaServices 类图
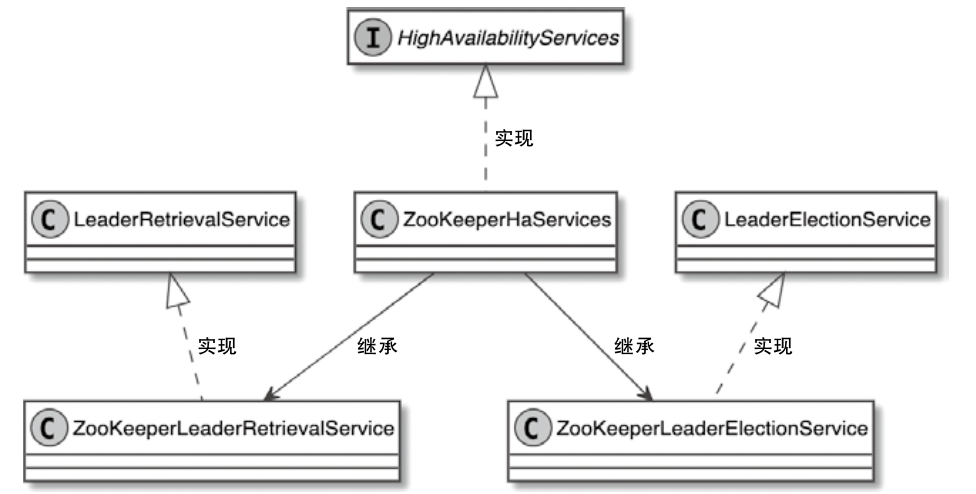
高可用的 ZK 路径
|
|
LeaderContender 类图
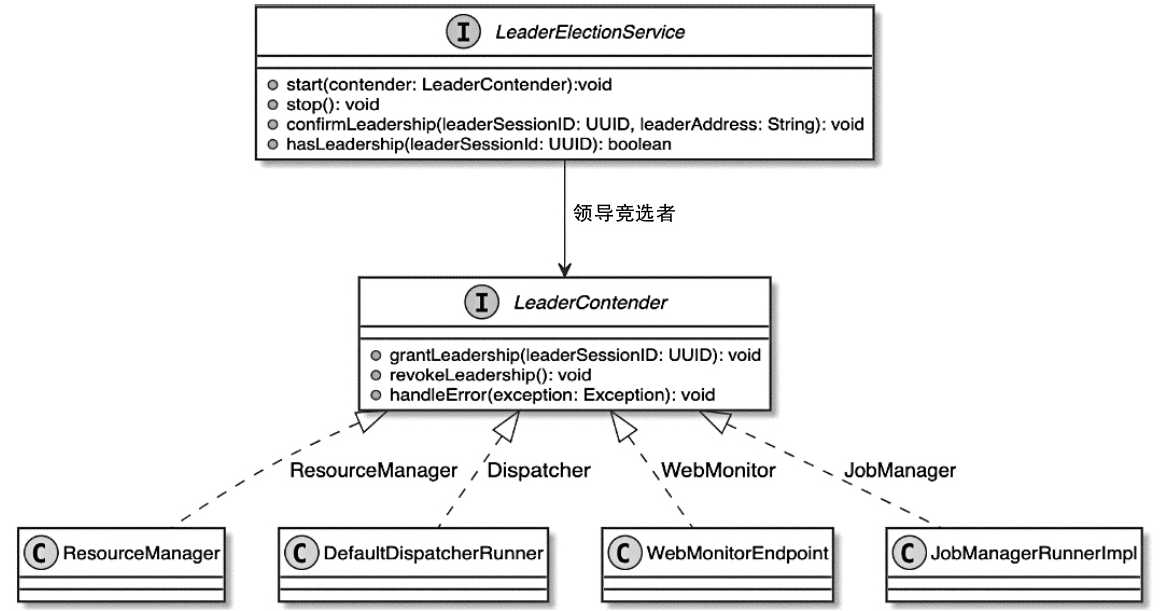
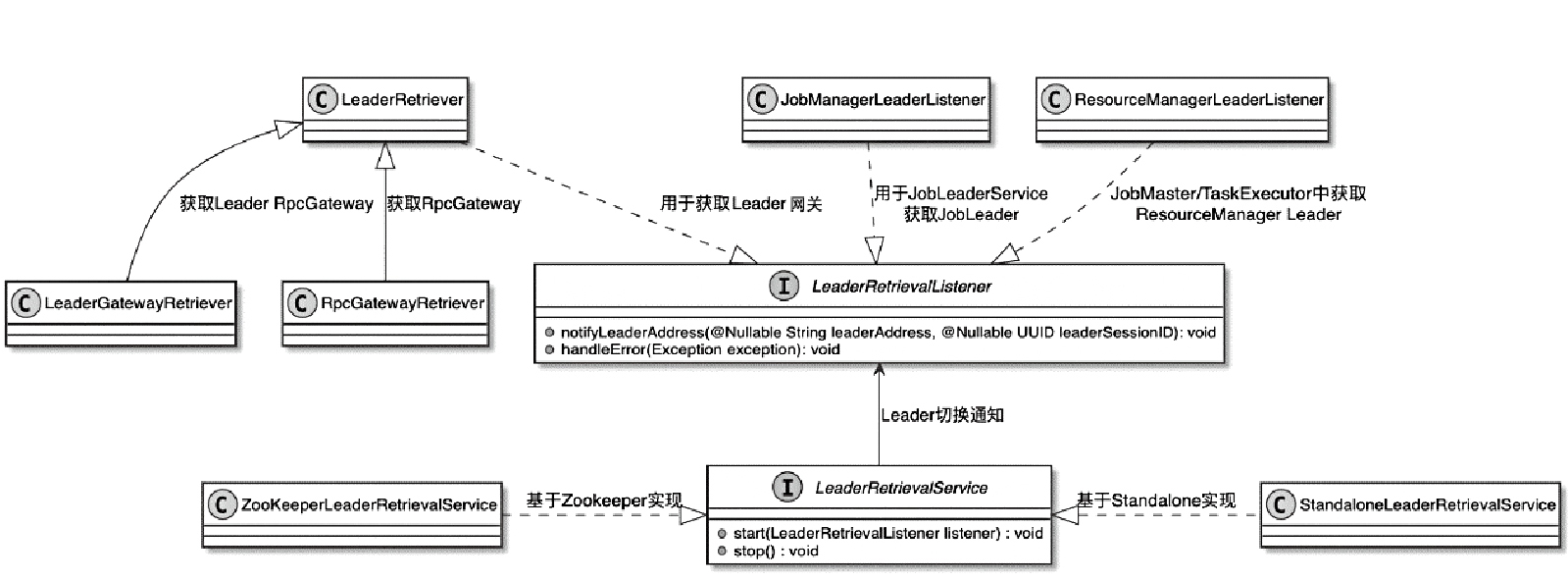
ZooKeeperLeaderRetrievalService 和 ZooKeeperLeaderElectionService
- 启动方式一致
- LeaderRetrievalService
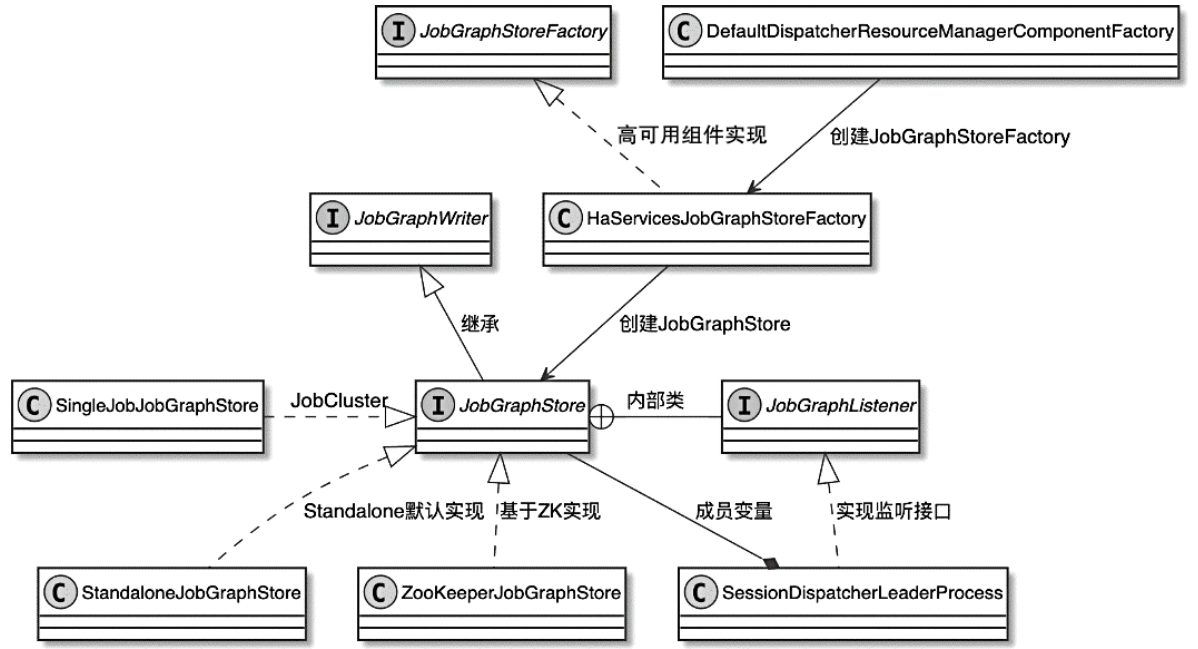
JobGraphStore
- session 模式下, 会通过 HighAvailabilityServices 创建 JobGraphStore
- 可以从 JobGraphStore 中恢复之前提交的 JobGraph
整体架构
其中高可用是依赖 Zookeeper 实现
Dispatcher 是一个抽象类
- MiniDispatcher
- StandaloneDispatcher
Dispatcher 的主要字段
|
|
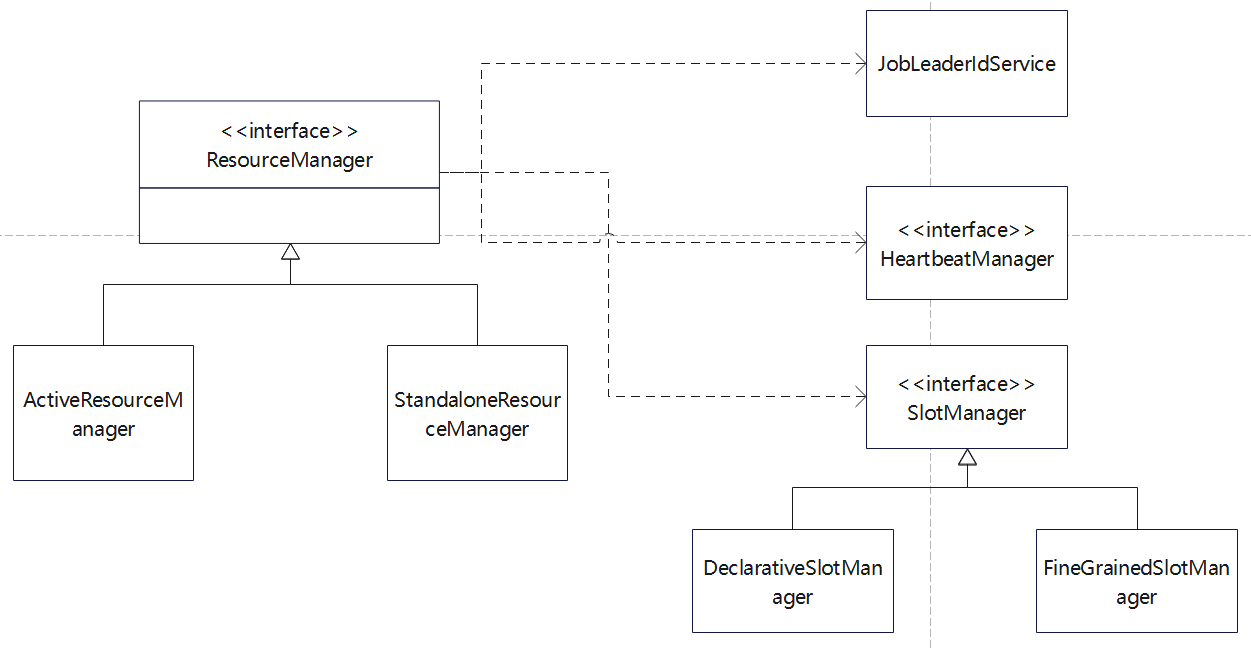
ResourceManager相关类图
- 整个过程与 Dispatcher 构造、选举、启动的过程类似
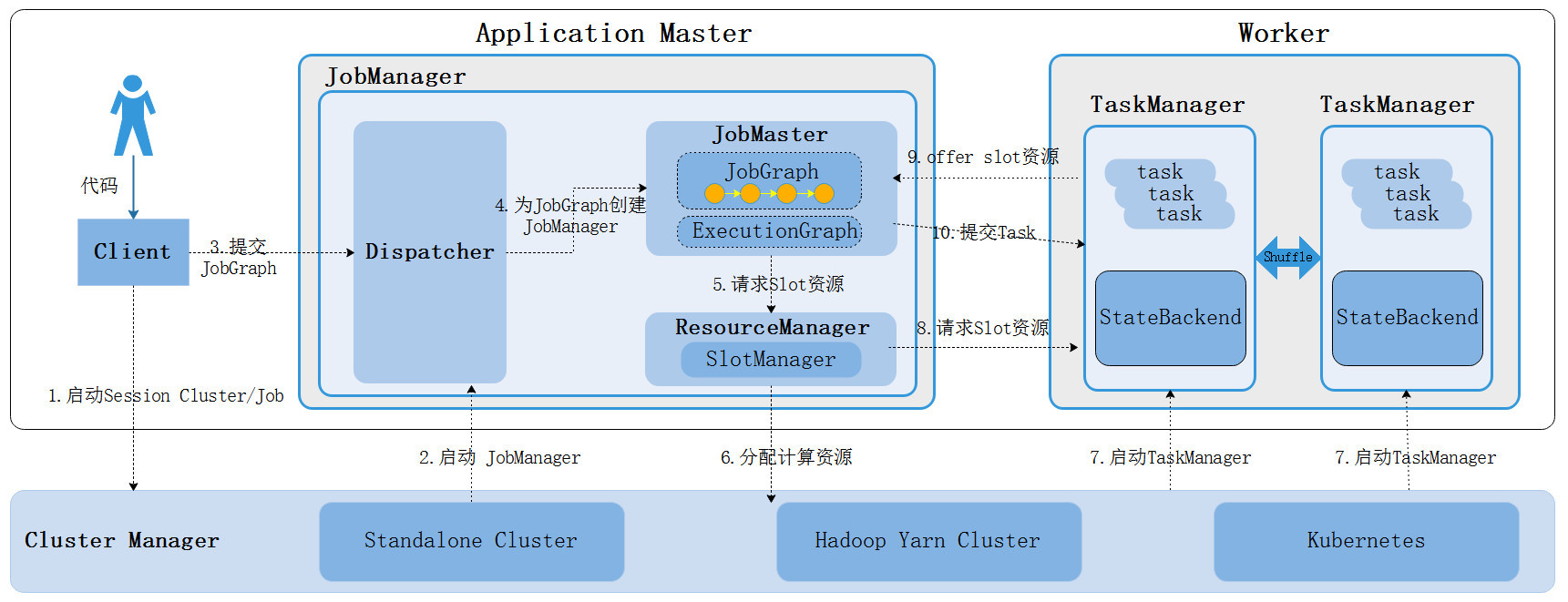
几个角色的分工
- client 创建 JobGraph并提交给 Dispatcher
- Dispatcher 在获取 JobGraph 后创建 JobMaster
- ResourceManager 主要负责管理资源
- JobMaster 负责任务调度 和 checkpoint 等
- TaskExecutor 负责任务的执行、任务的数据传输
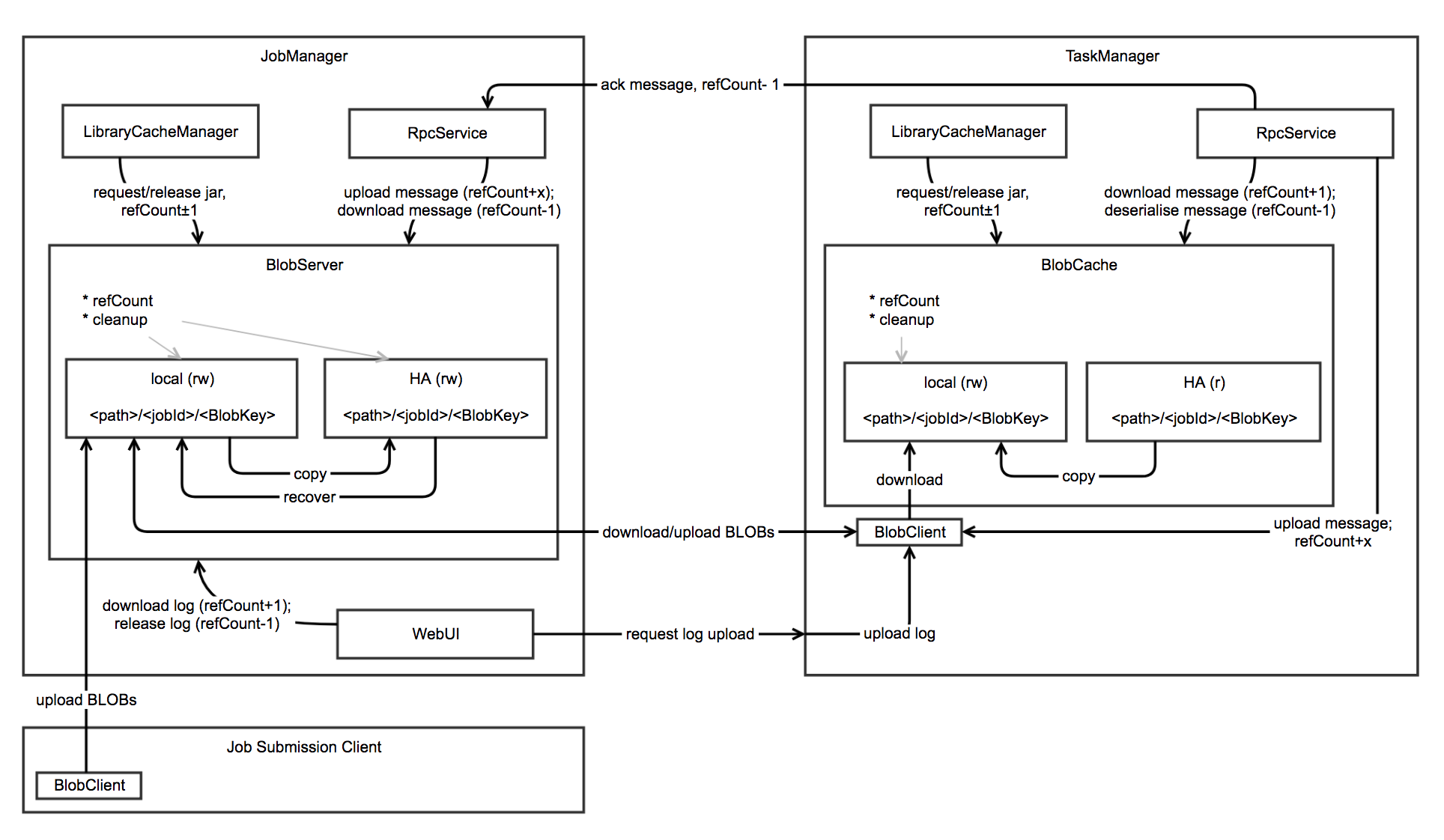
- BlobServer 负责处理 jar、等二进制文件分发
JobManager
- 主要用于协调分布式任务的执行,包括调度任务、协调容错机制等
- 又包含了 JobMaster、Dispatcher、ResourceManager
- 新版本的还有 BlobServer
TaskManager
- 主要用于负责任务的具体执行和任务间数据的传输
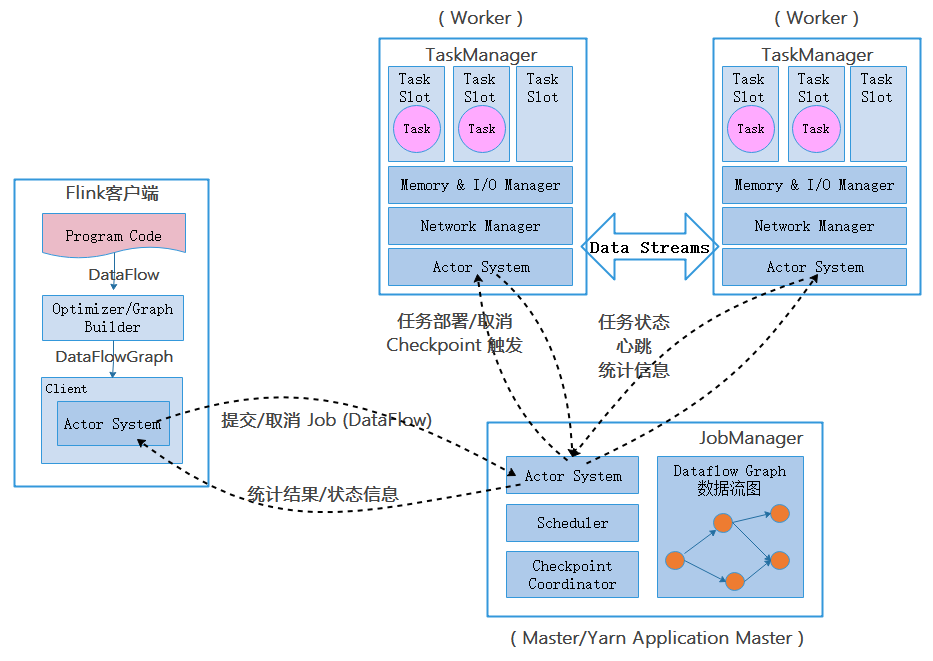
任务提交过程
BolbServer