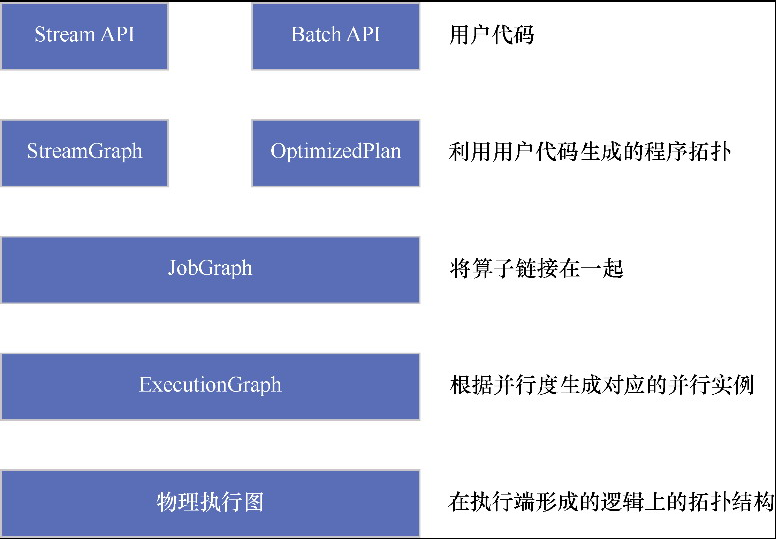
Flink的执行图
StreamGraph
一个例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
// nc -lk 8888
public void go() throws Exception {
// 1.准备环境-env
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
env.setRuntimeMode(RuntimeExecutionMode.STREAMING);
// env.setRuntimeMode(RuntimeExecutionMode.BATCH);
//默认是RuntimeExecutionMode.STREAMING
env.setParallelism(1);
// 2.准备数据-source
DataStream<String> linesDS =
env.fromElements("flink,hadoop,hive", "flink,hadoop,hive", "flink,hadoop", "flink");
// 3.处理数据-transformation
DataStream<String> wordsDS = linesDS.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
// value就是一行行的数据
String[] words = value.split(",");
for (String word : words) {
out.collect(word);// 将切割处理的一个个的单词收集起来并返回
}
}
});
DataStream<Tuple2<String, Integer>> wordAndOnesDS = wordsDS.map(new MapFunction<String,
Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
// value就是进来一个个的单词
return Tuple2.of(value, 1);
}
});
//DataSet中分组是groupBy,DataStream分组是keyBy
KeyedStream<Tuple2<String, Integer>, String> groupedDS = wordAndOnesDS.keyBy(
new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> value) throws Exception {
return value.f0;
}
});
DataStream<Tuple2<String, Integer>> result = groupedDS.sum(1);
// 4.输出结果-sink
// result.print();
result.addSink(new PrintSinkFunction<>());
// 5.触发执行-execute
// env.execute();// DataStream需要调用execute
env.execute("word count stream");
}
|
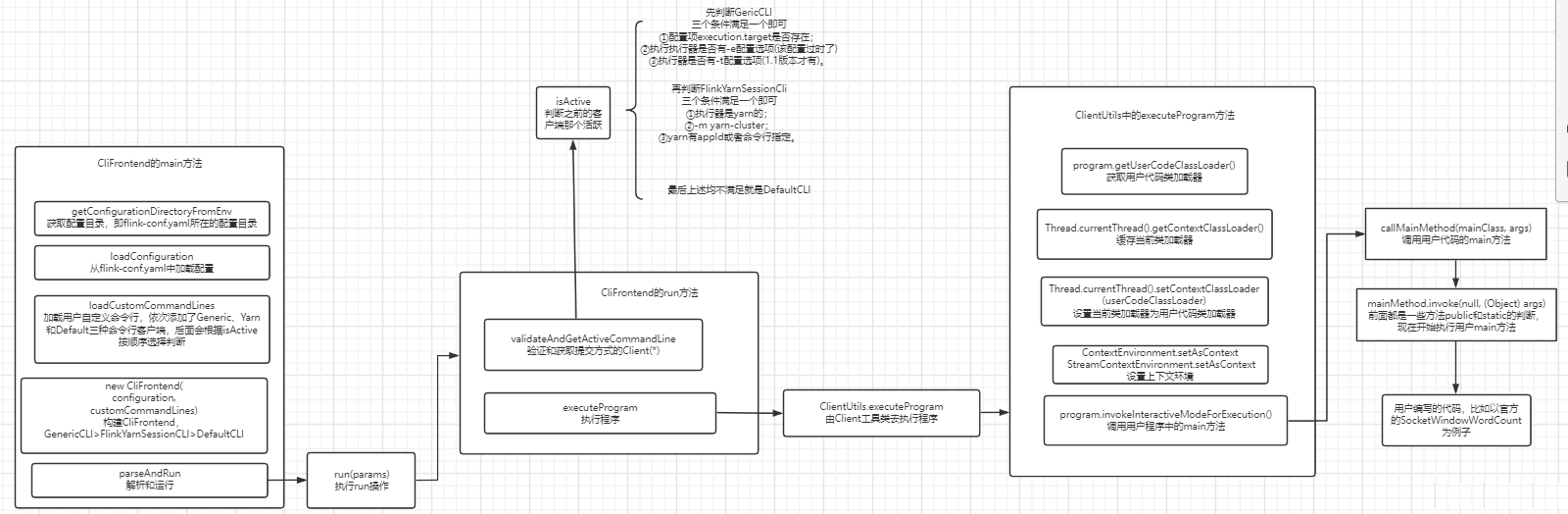
算子的转换
执行到:env.execute 时
- 会根据 stream、batch 做转换
接口 Pipeline 的实现类:
- StreamGraph,流的拓扑
- Plan ,批的拓扑
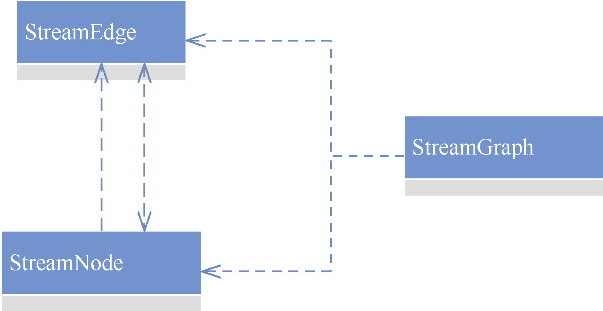
StreamGraph 会生成一个 DAT图,其内部有一个很重要的streamNodes,用来表示 有向图之间节点的关系
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
streamNodes = {HashMap@2283} size = 5
{Integer@2309} 1 -> {StreamNode@2310} "Source: Collection Source-1"
key = {Integer@2309} 1
value = {StreamNode@2310} "Source: Collection Source-1"
{Integer@2311} 2 -> {StreamNode@2312} "Flat Map-2"
key = {Integer@2311} 2
value = {StreamNode@2312} "Flat Map-2"
{Integer@2313} 3 -> {StreamNode@2314} "Map-3"
key = {Integer@2313} 3
value = {StreamNode@2314} "Map-3"
{Integer@2315} 5 -> {StreamNode@2316} "Keyed Aggregation-5"
key = {Integer@2315} 5
value = {StreamNode@2316} "Keyed Aggregation-5"
{Integer@2317} 6 -> {StreamNode@2318} "Sink: Unnamed-6"
key = {Integer@2317} 6
value = {StreamNode@2318} "Sink: Unnamed-6"
|
和 spark 的对比
| Feature |
Spark (DAG Scheduler) |
Flink (StreamGraph) |
| Job Splitting |
Split into Stages based on Shuffle Boundaries |
Single DAG (StreamGraph) for the entire job |
| Shuffle Handling |
Happens before execution (defining stages) |
Happens during execution (JobGraph phase) |
| Execution Plan |
Spark materializes RDDs and pipelines stages |
Flink creates one DAG and chains operators dynamically |
| Network Shuffle |
Happens at stage boundaries (causes slowdowns) |
Happens at keyBy or repartitioning but optimizes via chaining |
StreamGraph
- chaining:用于设置是否开启链接。如果开启,则可能实现把多个算子链接在一起,这样就可以把它们部署到一个任务中执行
- scheduleMode:ScheduleMode类型,表示调度策略
- allVerticesInSameSlotSharingGroupByDefault:用于设置是否把所有节点放入同一个SlotSharingGroup。默认值为true
- streamNodes:Map<Integer, StreamNode>类型,表示一个会被执行的任务节点
- virtualSelectNodes:Map<Integer, Tuple2<Integer, »类型,表示虚拟的select节点
- virtualSideOutputNodes:Map<Integer, Tuple2<Integer, OutputTag»类型,表示虚拟的side output节点
- virtualPartitionNodes:Map<Integer, Tuple3<Integer, StreamPartitioner, Shufflemode»类型,表示虚拟的partition节点
解释
- StreamNode 包含了List<> 出边,以及List 入边
- 以及包含的 jobVertexClass,如:OneInputStreamTask
一些常见的算子的类图,这里省略了很多子类
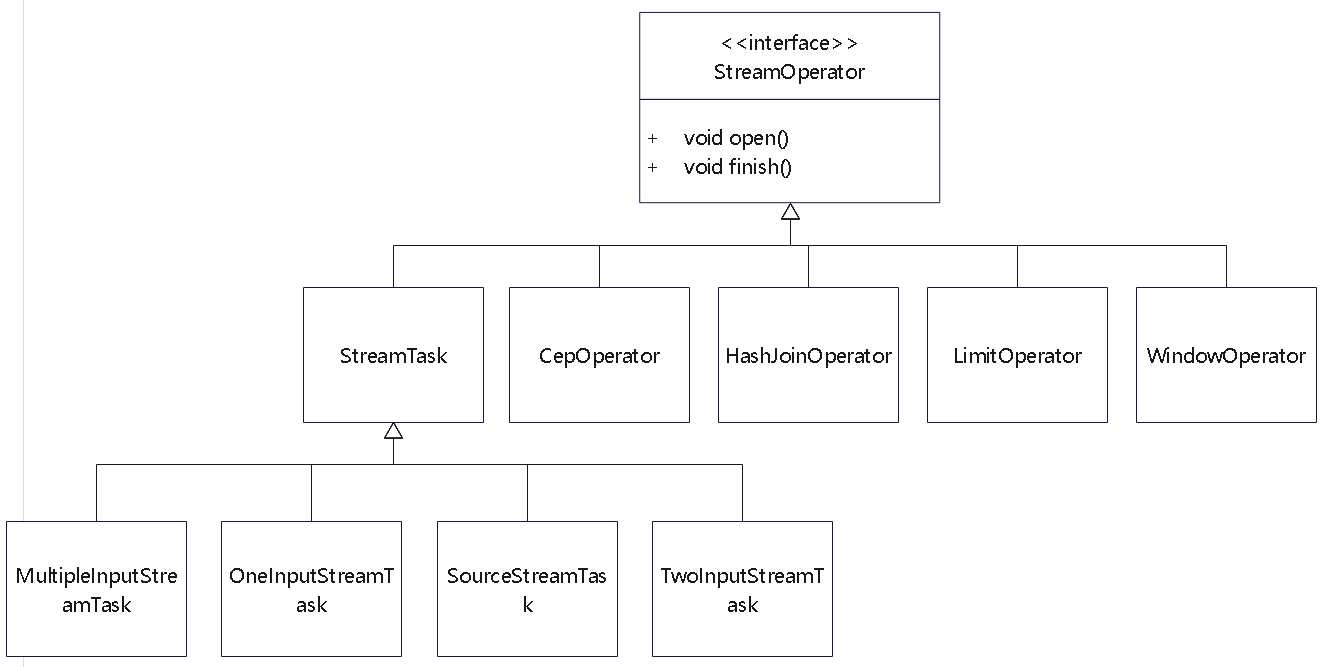
Plan
例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
public void go() throws Exception {
// 1. Create Flink batch execution environment
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 2. Prepare data source
DataSet<String> ds = env.fromElements(
"flink hadoop hive",
"flink hadoop hive",
"flink hadoop flink"
);
ds.flatMap((FlatMapFunction<String, Tuple2<String, Integer>>) (value, out) -> {
// Split input line into words
String[] words = value.split(" ");
for (String word : words) {
out.collect(new Tuple2<>(word, 1));
}
})
.returns(TypeInformation.of(new TypeHint<Tuple2<String, Integer>>() {}))
.map((MapFunction<Tuple2<String, Integer>, Tuple2<String, Integer>>)
value -> Tuple2.of(value.f0, value.f1))
.returns(TypeInformation.of(new TypeHint<Tuple2<String, Integer>>() {}))
.groupBy(0) // Group by word (Tuple2<String, Integer> is now recognized)
.sum(1) // Sum the second field (integer count)
.print();
env.execute("word count stream");
}
|
这里构建过程也是递归的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
public class OperatorTranslation {
private <T> Operator<T> translate(DataSet<T> dataSet) {
Operator<T> dataFlowOp;
if (dataSet instanceof DataSource) {
} else if (dataSet instanceof SingleInputOperator) {
dataFlowOp = translateSingleInputOperator(singleInputOperator);
} else if (dataSet instanceof TwoInputOperator) {
dataFlowOp = translateTwoInputOperator(twoInputOperator);
} else if (dataSet instanceof BulkIterationResultSet) {
} else if (dataSet instanceof DeltaIterationResultSet) {
} else {
}
}
private <I, O> Operator<O> translateSingleInputOperator(SingleInputOperator<?, ?, ?> op) {
// 递归调用
Operator<I> input = translate(typedInput);
dataFlowOp =
typedOp.translateToDataFlow(input);
// ...
// ...
return dataFlowOp;
}
private <I, O> Operator<O> translateTwoInputOperator(SingleInputOperator<?, ?, ?> op) {
DataSet<I1> typedInput1 = (DataSet<I1>) op.getInput1();
DataSet<I2> typedInput2 = (DataSet<I2>) op.getInput2();
// 递归调用
Operator<I1> input1 = translate(typedInput1);
Operator<I2> input2 = translate(typedInput2);
dataFlowOp =
typedOp.translateToDataFlow(input1, input2);
// ...
// ...
return dataFlowOp;
}
}
|
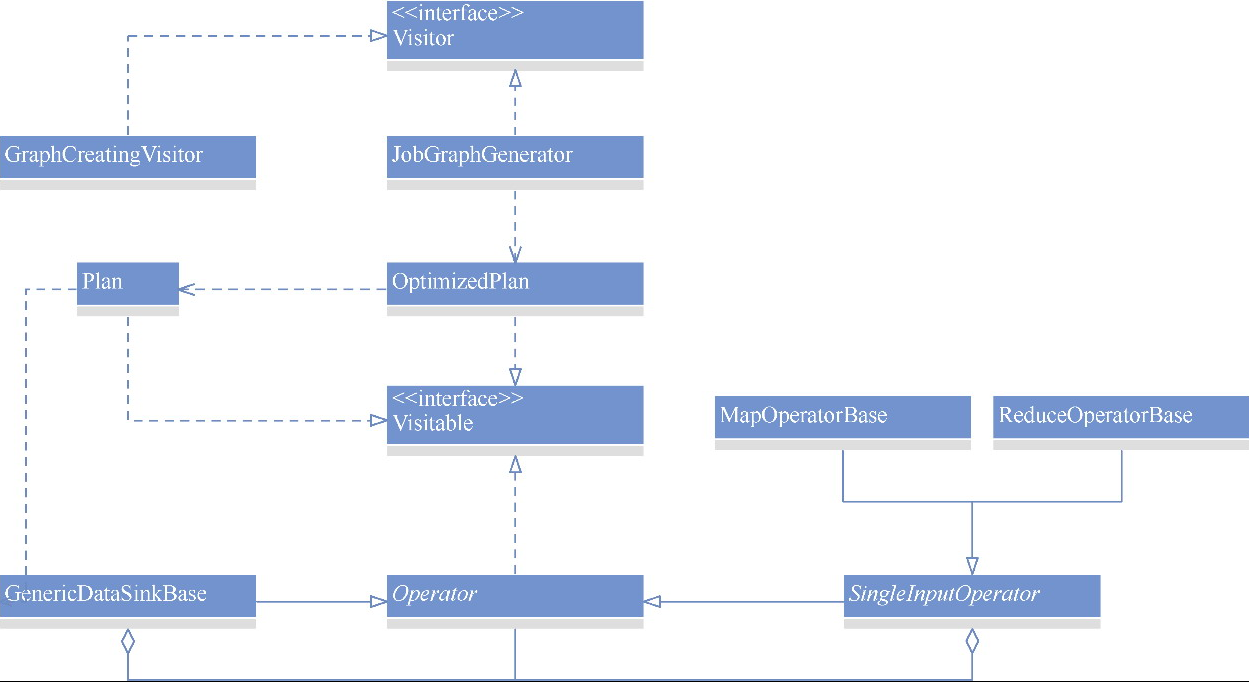
Visitable、Visitor
- Plan 继承 Visitor,后面对 Plan 做优化可以用访问者模式遍历
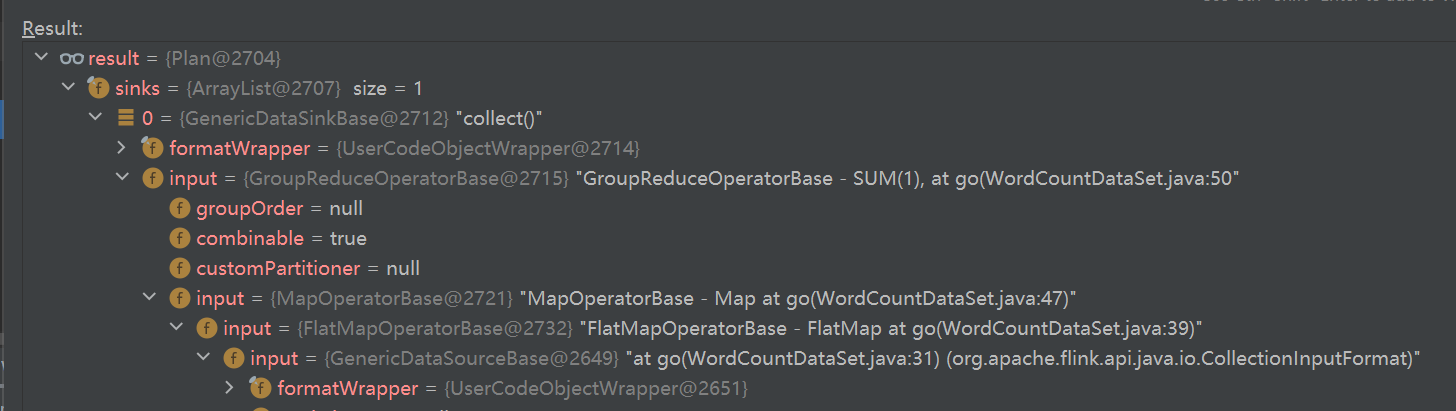
Plan debug内部过程
- sink不断展开,可以看到 input
- 最后的 input 就是 DataSource
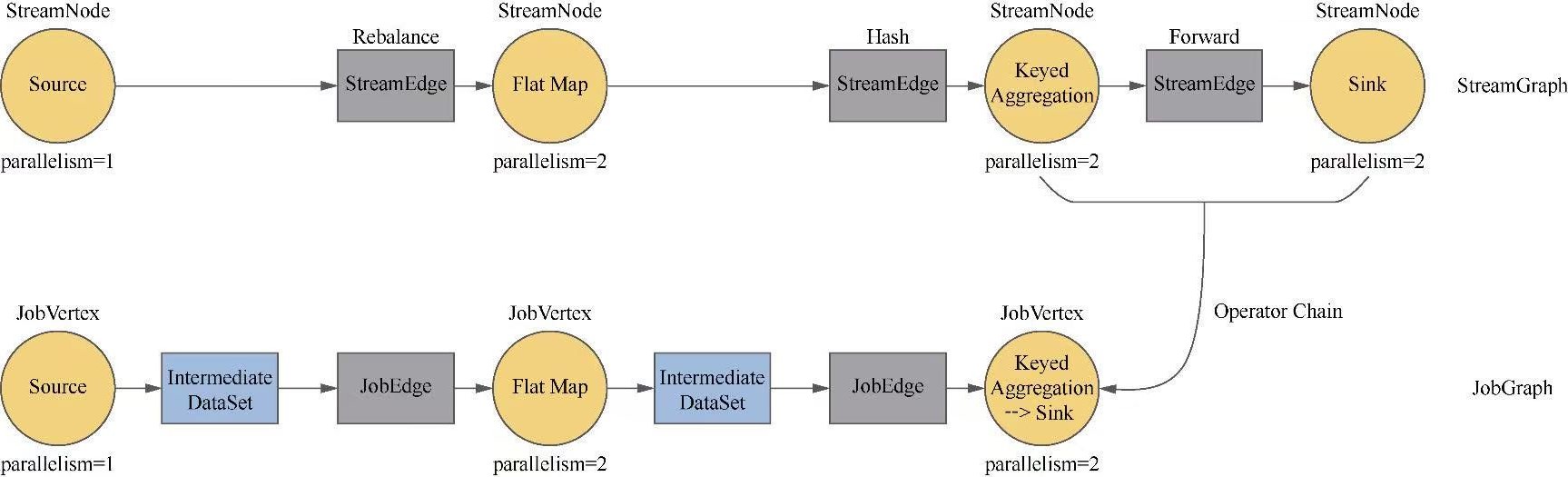
JobGraph
类图如下
- Flink的类图之间还是比较清晰的
- StreamGraph和Plan 都会委托 FlinkPipelineTranslator 生成 JobGraph
- 而JobGraph 会将任务根据 shuffle 做拆分,为后续真正调度做准备
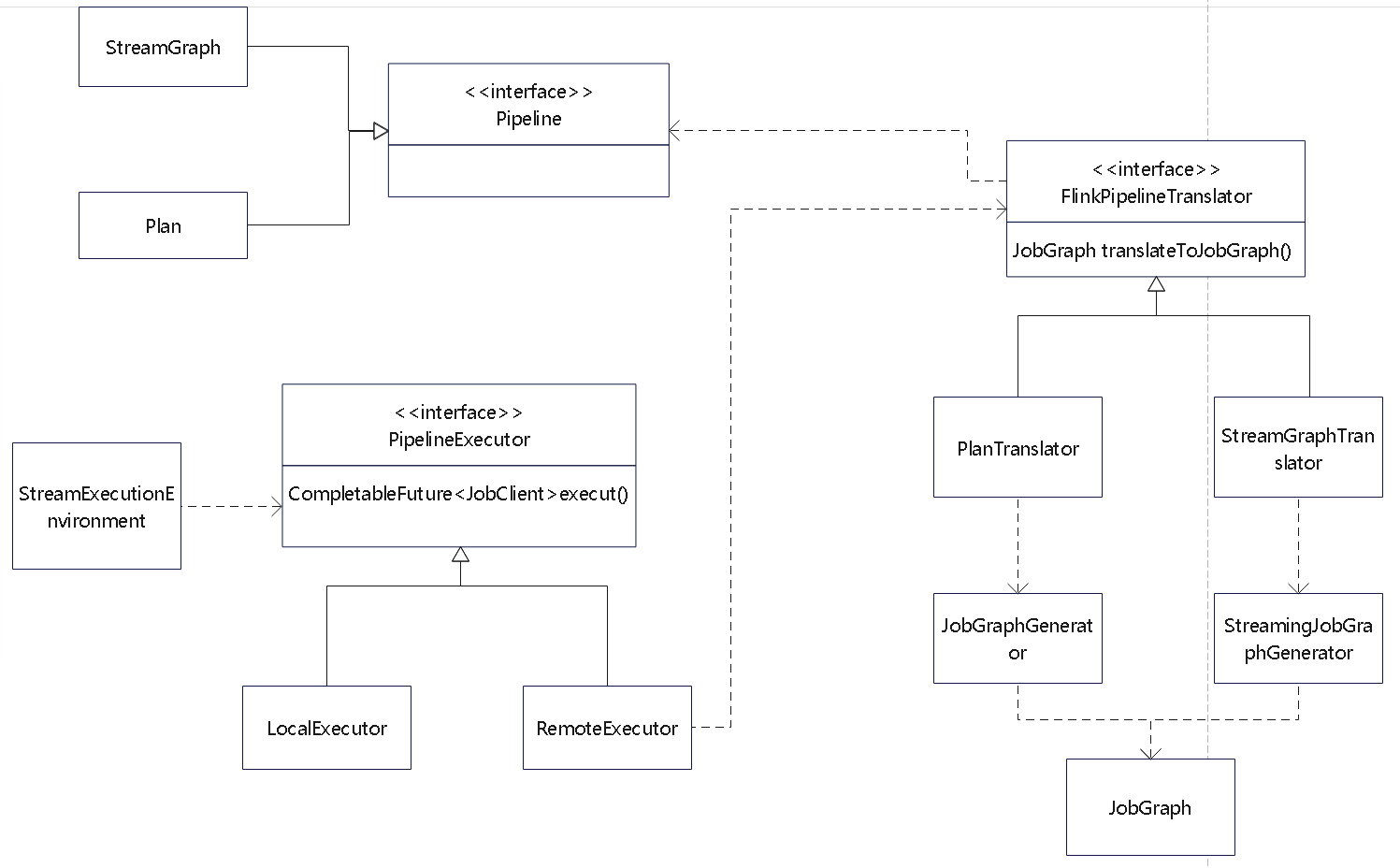
StreamGraphTranslator的translateToJobGraph()方法如下
StreamingJobGraphGenerator
- 是JobGraph的生成器,它的核心字段如下
- streamGraph:StreamGraph类型。
- jobVertices:Map<Integer, JobVertex>类型,用于维护JobGraph中的节点。
- jobGraph:JobGraph类型
- builtVertices:Collection类型,用于维护已经构建的StreamNode的id
- physicalEdgesInOrder:StreamEdge类型,表示物理边的集合,排除了链接内部的边
- chainedConfigs:Map<Integer, Map<Integer, StreamConfig» 类型,保存链接信息
- vertexConfigs:Map<Integer, StreamConfig>类型,保存节点信息
- chainedNames:Map<Integer, String>类型,表示链接的名称
createJobGraph的过程如下:
createJobGraph
- 进行一些转换前的验证,比如检验配置是否有冲突等
- 设置调度方式、计算哈希值等
- 将任务链接在一起,创建节点JobVertex和边JobEdge。这是整个过程中最重要的一步
- 设置物理边,用于给StreamConfig添加物理边
- 设置共享槽组
- 设置内存占比
- 配置检查点、保存点参数
- 设置分布式缓存文件
- 设置运行时的配置
- 返回完整的JobGraph对象
From a source code perspective, the setChaining() method in StreamingJobGraphGenerator:
- Iterates over the stream nodes in the topology,
- Determines chaining eligibility by comparing operator chaining modes and partitioning strategies,
- Propagates the “chainable” flag along eligible subgraphs,
- Ultimately groups operators into chains so that during execution they run in a single task (reducing serialization, network overhead, and context switching).
ASCII
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
STREAM 1 STREAM 2
--------- ---------
+---------+ +---------+
| Source1 | | Source2 |
+----+----+ +----+----+
| |
v v
+---------+ +---------+
| Map1 | | Map2 |
+----+----+ +----+----+
| |
v v
+---------+ +---------+
| Filter1 | | Filter2 |
+---------+ +---------+
| |
| (Both Chains A & B) |
|______________________________________|
| (Shuffle/Exchange)
v
+------------+
| Join |
| (Stage Break) |
+------------+
|
v
+------------+
| PostJoinMap|
+------------+
|
v
+------------+
| Sink |
+------------+
|
总结起来,isChainable()方法中的判断条件如下
- 该出边的上游算子是该出边的下游算子的唯一输入。
- 上下游的StreamOperatorFactory对象的值不能为null。
- 上下游处于同一个SlotSharingGroup。
- 下游的ChainingStrategy为ALWAYS。
- 上游的ChainingStrategy为ALWAYS或HEAD。
- 该出边的分区器为ForwardPartitioner,即没有进行重分区等。
- 该出边的ShuffleMode不为BATCH。
- 上下游的并行度相同。
- StreamGraph的chaining属性的值为true
JobGraph和相关的类
- JobVertex
- JobEdge
- IntermediateDataSet
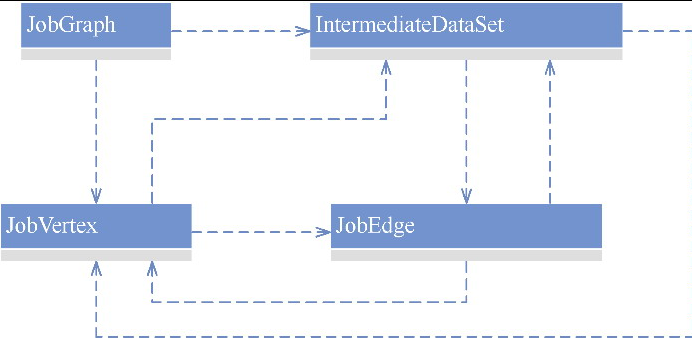
Plan 转换过程中会有一些优化步骤,类图如下
- PlanTranslator 是负责转换Plan 的
- 这会生成 JobVertex、JobEdge
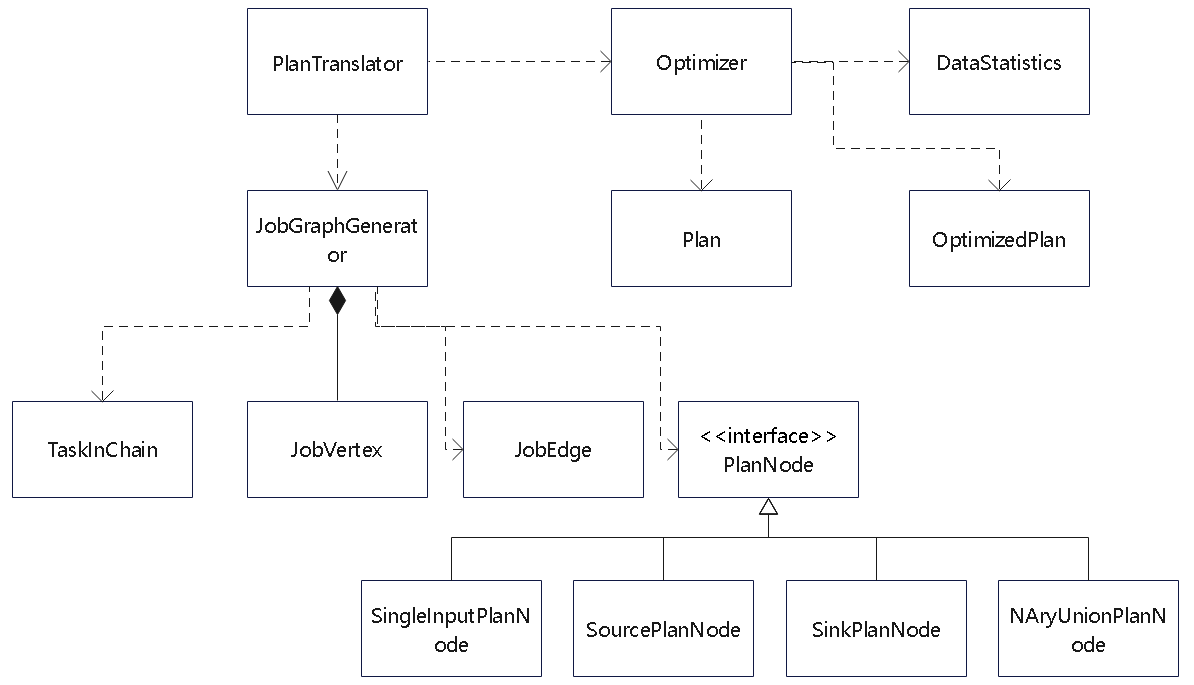
ExecutionGraph
类似于将 优化后的 执行计划 -> 转换为可以被调度的 物理计划
JobGraph和ExecutionGraph的关系如下:
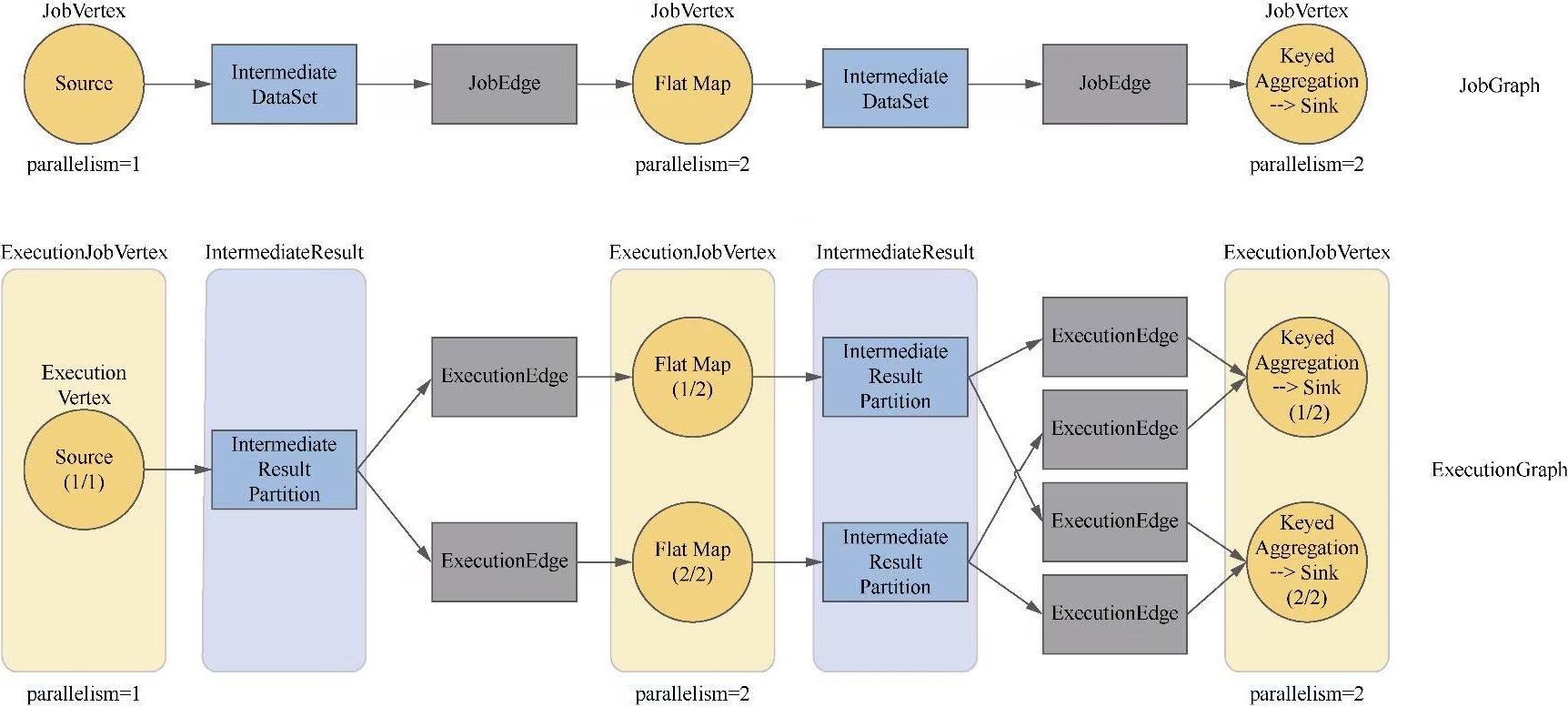
一个执行例子的 ascii 图
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
JobGraph:
[KafkaSource] ---> [HDFSSink]
DefaultExecutionGraphBuilder:
For each JobVertex:
+---------------------+ +---------------------+
| KafkaSource (Job) | | HDFSSink (Job) |
+---------------------+ +---------------------+
| |
v v
+---------------------+ +---------------------+
| ExecutionJobVertex | | ExecutionJobVertex |
| for KafkaSource | | for HDFSSink |
| (with 4 subtasks) | | (with 4 subtasks) |
+---------------------+ +---------------------+
| |
|--- Create Intermediate Result | <--- Wire input/output connections
| (data partitions) |
v v
[IntermediateResultPartitions connecting source and sink]
| |
v v
+-------------------------------------------------+
| Fully Constructed ExecutionGraph |
+-------------------------------------------------+
|
v
Scheduler uses this graph
|
From a source-code perspective, the DefaultExecutionGraphBuilder:
- Takes a high-level JobGraph,
- Instantiates ExecutionJobVertices for each job vertex,
- Wires them together via intermediate results,
- Sets scheduling, resource, and fault-tolerance parameters,
- And finally produces an ExecutionGraph that the Flink scheduler deploys on your cluster.
ExecutionGraph
- 是协调分布式任务执行的关键的数据结构
- 持有每一个任务的并行实例并维护它们的运行状态
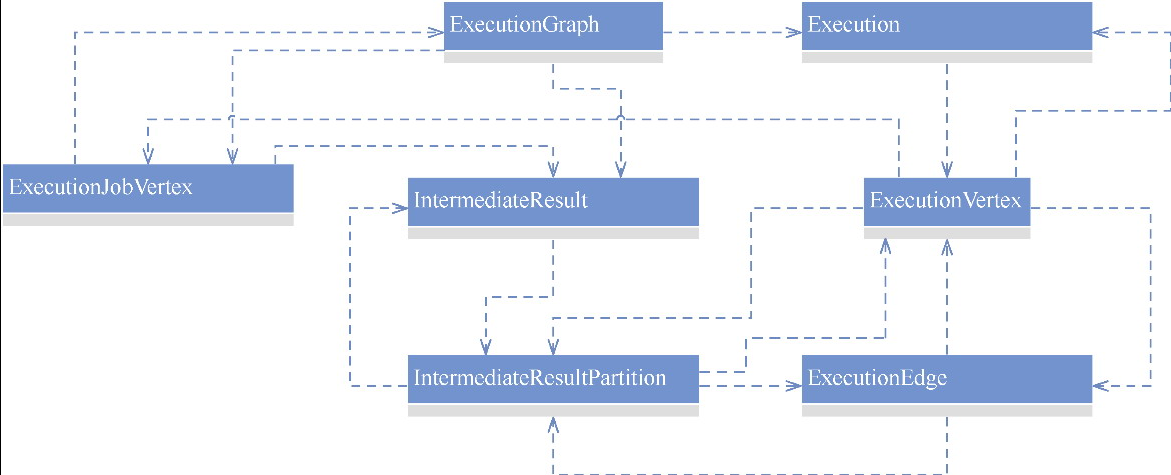
ExecutionGraph 的字段
- jobInformation:JobInformation类型,包含作业名称、作业id等信息。
- tasks:Map<JobVertexID, ExecutionJobVertex>类型,表示将 JobVertexID 与 ExecutionGraph 中的任务节点 ExecutionJobVertex 映射起来。
- verticesInCreationOrder:ExecutionJobVertex类型,表示按照创建顺序维护的ExecutionJobVertex列表。
- intermediateResults:Map<IntermediateDataSetID, IntermediateResult>类型,维护所有的IntermediateResult对象。
- currentExecutions:Map<ExecutionAttemptID, Execution>类型,表示当前执行的任务。
- jobStatusListeners:JobStatusListener类型,表示作业状态的监听器。
- failoverStrategy:FailoverStrategy类型,表示作业失败后的策略。
- restartStrategy:RestartStrategy类型,表示重启策略
- slotProviderStrategy:SlotProviderStrategy类型,用于给任务提供槽位的策略。
- scheduleMode:ScheduleMode类型,表示调度方式。
- verticesFinished:表示已完成的节点个数。
- state:JobStatus类型,表示作业的状态。
- checkpointCoordinator:CheckpointCoordinator类型,表示检查点的协调器
ExecutionJobVertex、ExecutionVertex和Execution
- ExecutionJobVertex (“Map”): Represents the overall Map operator.
- ExecutionVertex #i: Represents the i-th parallel instance of the Map operator.
- Execution: Each subtask’s current execution attempt (its state, timing, etc.).
执行关系图如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
JobGraph
[Map]
|
---------------------
| |
ExecutionJobVertex ("Map")
|
-----------------------------------------
| | | |
ExecutionVertex ExecutionVertex ExecutionVertex ExecutionVertex
#1 #2 #3 #4
| | | |
Execution Execution Execution Execution
(RUNNING) (RUNNING) (RUNNING) (RUNNING)
|
IntermediateResult
- 逻辑表示,由job vertex 产生
- 在 ExecutionGraph 中,为作业顶点的每个输出边创建一个IntermediateResult
- 通过 IntermediateDataSet 构建出 IntermediateResult
IntermediateResultPartition
- 物理表示,当 job vertex 完成后会产生IntermediateResult
- 拆分为多个物理的:IntermediateResultPartition
JobGraph –> ExecutionGraph
- In the JobGraph, the plan is static and just represents the logical operators and data flow.
- The JobGraph is a high-level, immutable representation of a submitted Flink job. It is constructed by the Flink client based on the user’s program and defines the logical dataflow as a directed acyclic graph (DAG).
- It contains job vertices (logical operators), the connections between them (edges), user-specified parallelism, and other metadata like checkpointing settings.
- The ExecutionGraph expands each logical operator into multiple execution tasks (ExecutionVertices) and adds runtime information necessary for scheduling and fault tolerance.
- The ExecutionGraph is the runtime representation of the job. It is derived from the JobGraph (typically by the DefaultExecutionGraphBuilder) and enriched with runtime details necessary for scheduling, execution, fault tolerance, and state management.
- It “expands” the logical job by breaking each job vertex into multiple execution vertices (subtasks) according to the defined parallelism. It also holds runtime state for each subtask and information such as execution attempt IDs and resource allocations.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
JobGraph (Logical Plan)
+----------------+ +----------------+ +----------------+
| Source | ---> | Map | ---> | Sink |
| parallelism=4 | | parallelism=4 | | parallelism=4 |
+----------------+ +----------------+ +----------------+
Transformation via DefaultExecutionGraphBuilder
|
V
ExecutionGraph (Runtime Plan)
+-----------------------+ +-----------------------+ +-----------------------+
| ExecutionJobVertex | | ExecutionJobVertex | | ExecutionJobVertex |
| for Source (4 tasks) | | for Map (4 tasks) | | for Sink (4 tasks) |
+-----------------------+ +-----------------------+ +-----------------------+
| | |
V V V
+---------+ +---------+ ... +---------+ +---------+ +---------+ ... +---------+ +---------+ +---------+ ... +---------+
| Task 1 | | Task 2 | ... | Task 4 | | Task 1 | | Task 2 | ... | Task 4 | | Task 1 | | Task 2 | ... | Task 4 |
+---------+ +---------+ ... +---------+ +---------+ +---------+ ... +---------+ +---------+ +---------+ ... +---------+
|
一个转换图
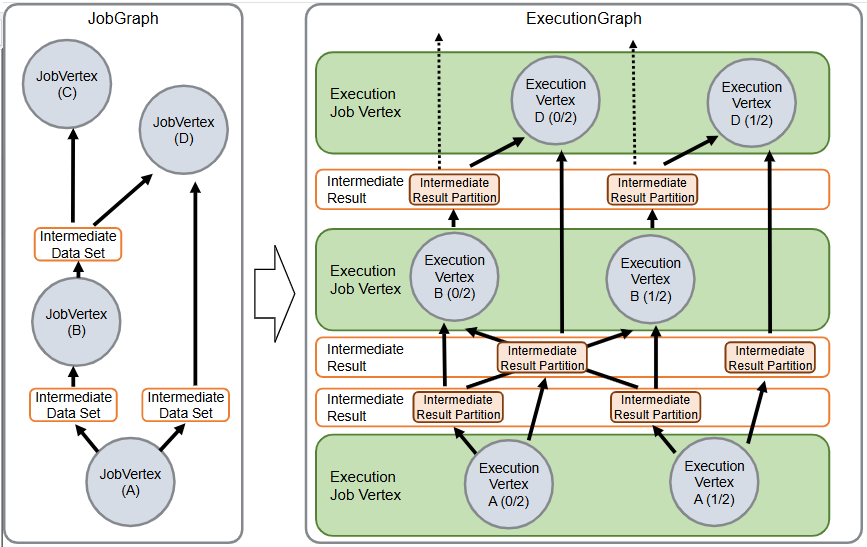
转换过程
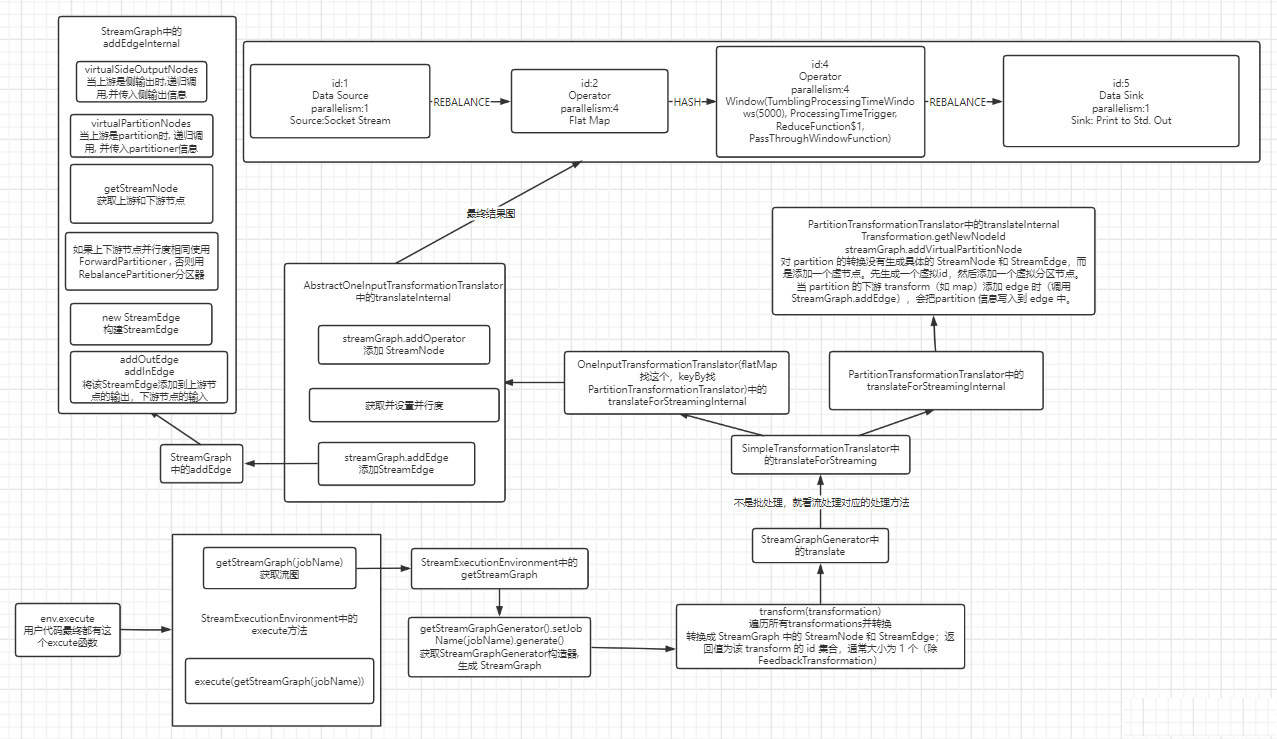
参考