Flink 集群管理
集群基本概念
集群创建流程图
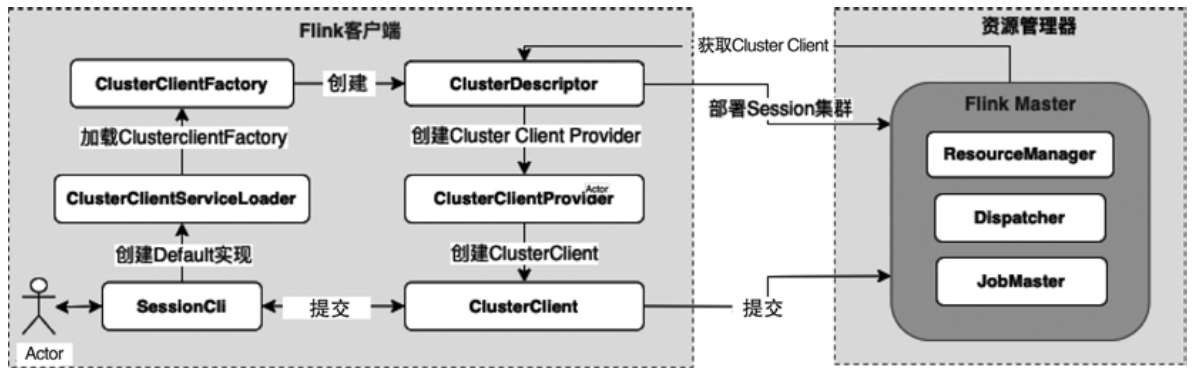
ClusterDescriptor
- 先由 ClusterClientFactory 创建 ClusterDescriptor
- 然后通过 ClusterDescriptor 创建 ClusterClientProvier
- 最终基于 ClusterClientProvier 实例获取 ClusterClient
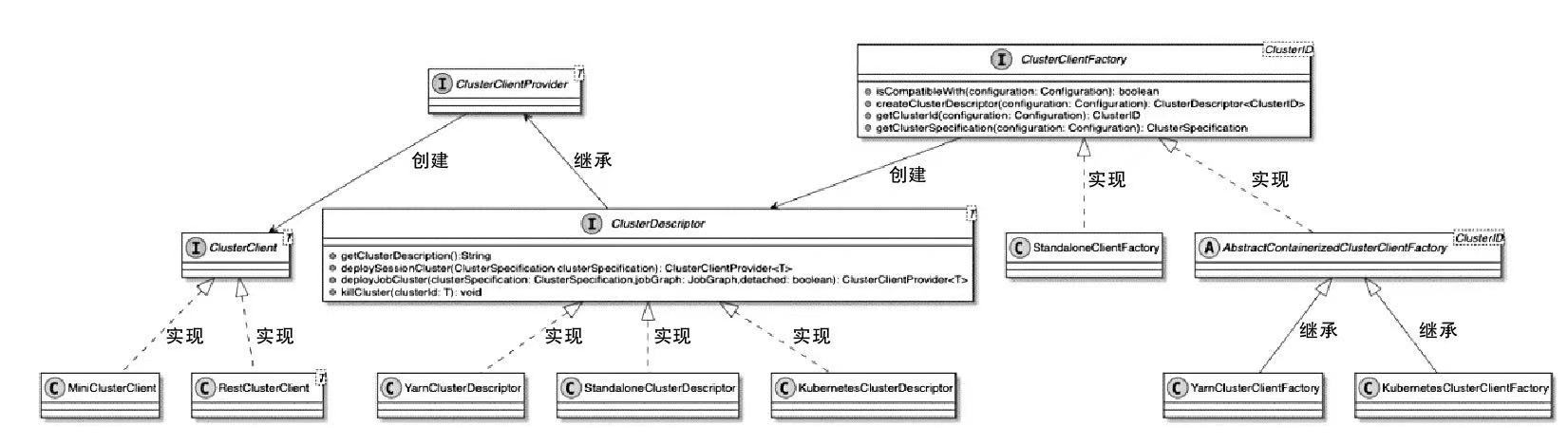
ClusterClientFactory 主要分为两种类型
- 支持容器化部署的 AbstractContainerizedClusterClientFactory
- 不支持容器化部署的 StandaloneClientFactory
ClusterDescriptor 相关类图
- ClusterDescriptor接口主要用于创建和停止指定的Flink集群
- 实现ClusterDescriptor接口的deploySessionCluster()和deployJobCluster()方法
- 可以远程部署SessionCluster或JobCluster到指定的集群资源管理器上
- KubernetesClusterDescriptor中借助fabric8IO客户端,实现与Kubernetes集群的网络交互
通过SPI加载不同类型的ClusterClientFactory
- 在DefaultClusterClientServiceLoader中通过Java SPI机制将不同类型的ClusterClientFactory实现子类加载到客户端进程中
- 扩展机制,需要将对应模块的JAR包复制到${FLINK_HOME}/lib路径
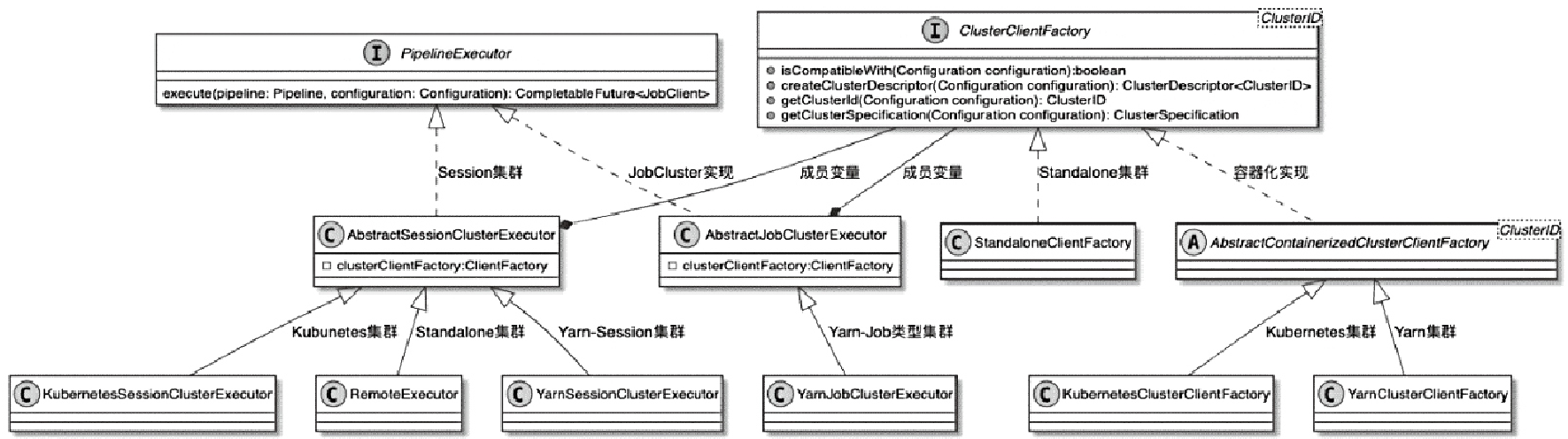
PipelineExecutor 相关类图
- 通过PipelineExecutor执行并生成JobGraph数据结构
- 然后通过ClusterClient将JobGraph对象提交到集群运行时
- 支持 提交单个Job的AbstractJobClusterExecutor
- 支持提交多个Job的AbstractSessionClusterExecutor
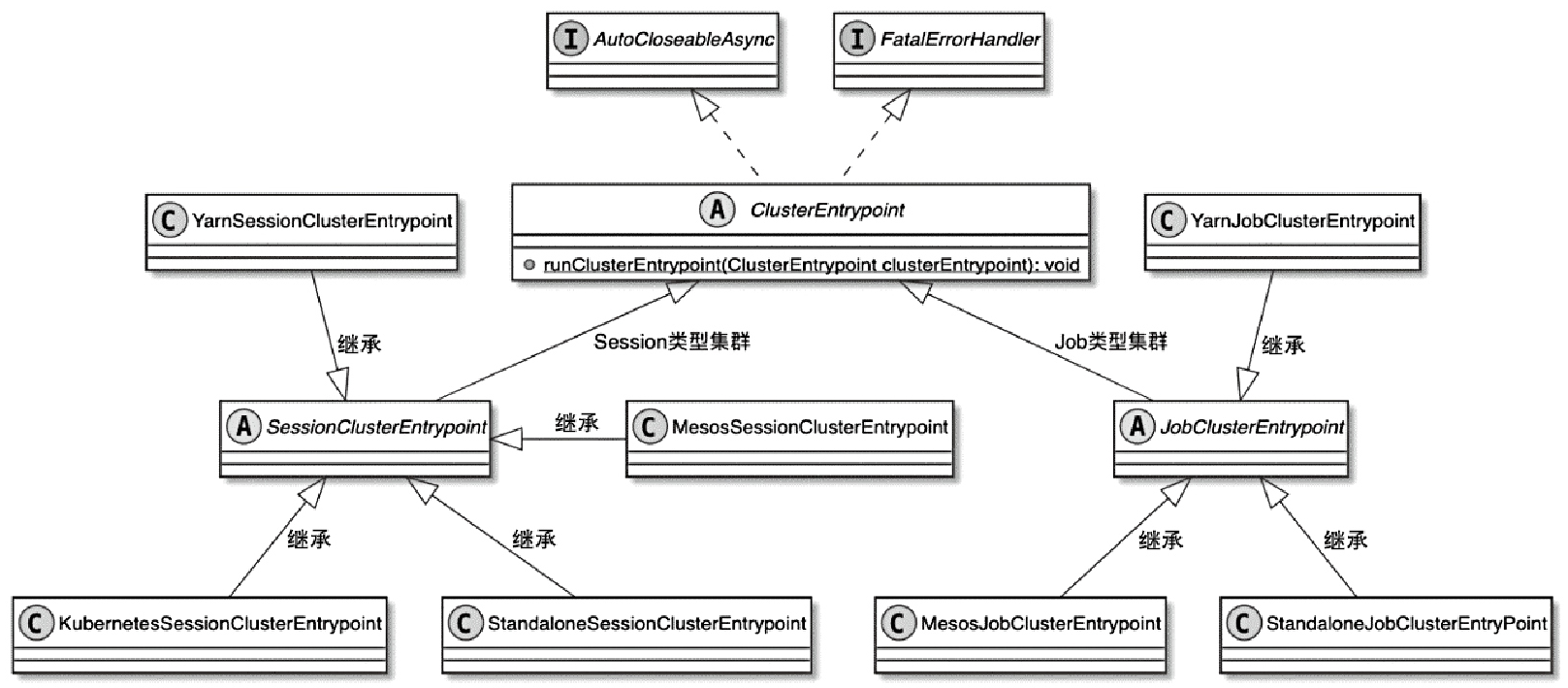
ClusterEntrypoint 相关类图
- 有基于 Job 的,有基于 Session 的
- yarn 模式同时支持 job、 session
- 而 k8s 只支持 session
FlinkYarnSessionCli
- 使用bin/yarn-session.sh脚本启动Session集群
- 在脚本执行过程中会调用FlinkYarnSessionCli的main()方法启动集群客户端
- 创建 YarnClusterClientFactory,
- 根据是否指定了 applicationId,获取已有集群,或者创建新集群
- 如果启动模式为attached,则直接打印集群信息,否则启动ScheduledExecutorService,周期性地调用YarnApplicationStatusMonitor获取Yarn集群上对应Application的状态信息
Flink On Yarn
YARN 架构
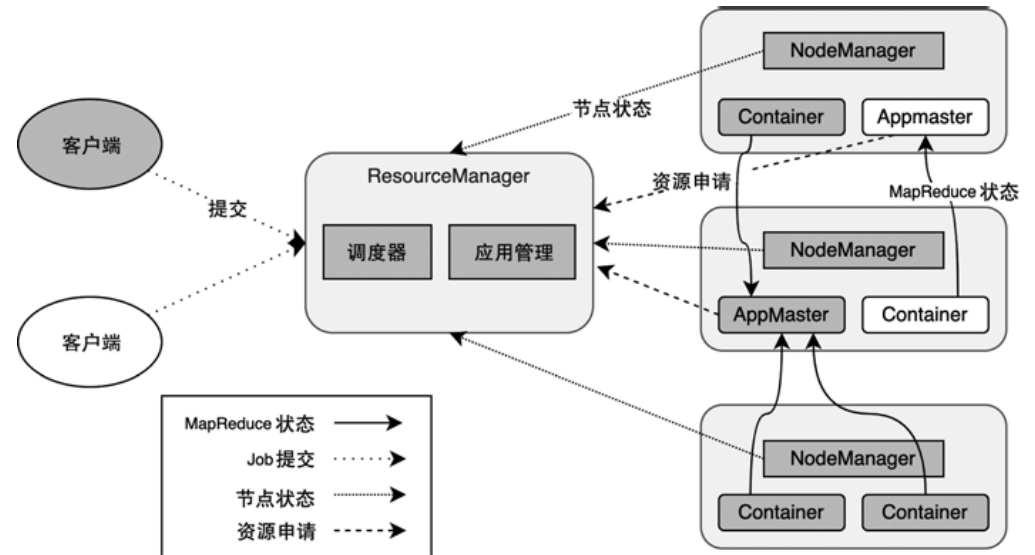
Flink On Yarn架构
- YarnClusterDescriptor 用来创建集群,并返回给客户端YarnClusterClient
- YarnClusterClient将JobGraph对象提交到运行时中运行
- FlinkYarnSessionCli中解析提交作业的参数信息,将解析后的JAR包上传至HDFS
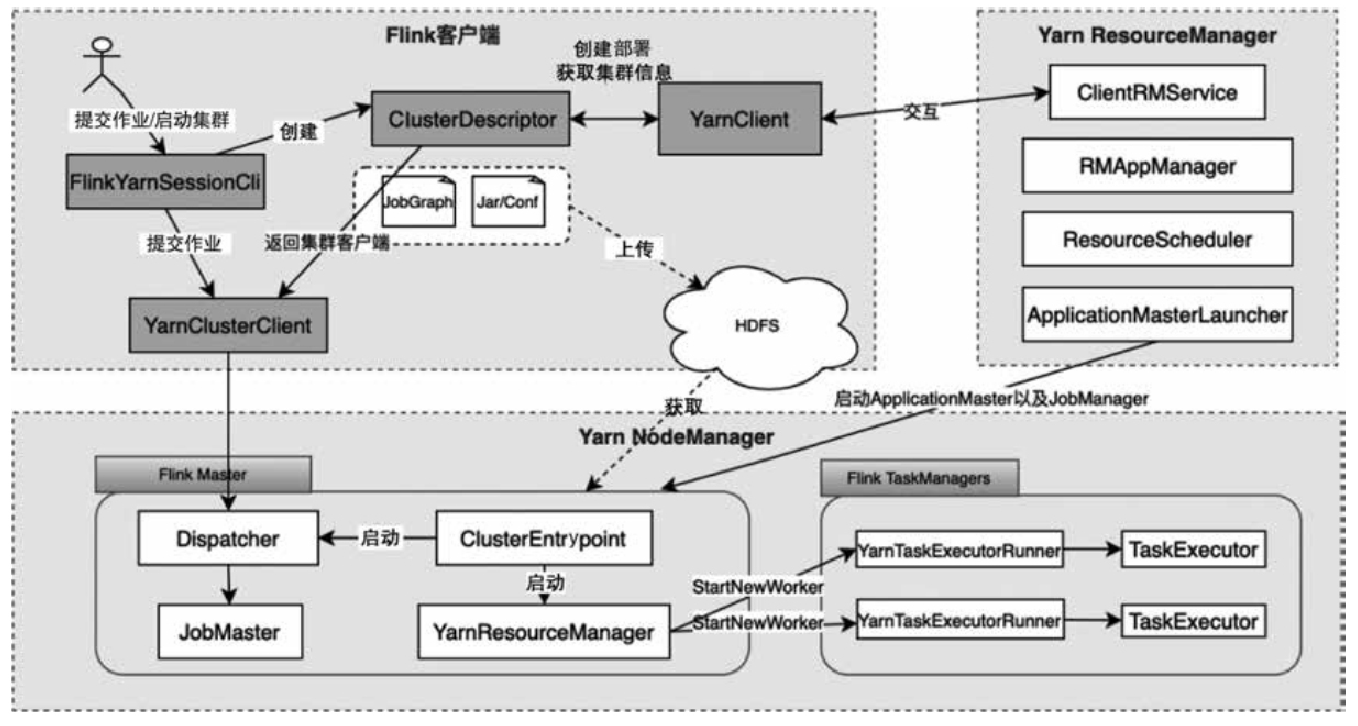
YarnClusterDescriptor
- 在这里启动 pre job、或者 sesion 集群
- 内部是调用 Apache Yarn client 去创建 yarn 资源的
创建 ApplicationMaster
|
|
主要逻辑
- 构建 hadoop FileSystem,设置准入控制
- 下载资源文件,如 jar 包等,使用:YarnApplicationFileUploader
- 以及 jobGraph 依赖的用户 jar等,然后缓存到 NodeManager 本地
- 设置 classpath 等
- 配置 job graph 相关参数,输出目录等
- 将传递的配置文件信息,write 到本地,保持为:flink-conf.yaml
- 设置 kerberos 信息,设置 UserGroupInformation
- 设置 ApplicationSubmissionContext 相关信息,类型,Resouce,优先级,Queue 等
- 提交:yarnClient.submitApplication(appContext)
- 提交成功后就可以监控这个 am
- 返回 ApplicationReport :yarnClient.getApplicationReport(appId)
- 在 while(true) 不断监控
YarnResourceManager 相关类图
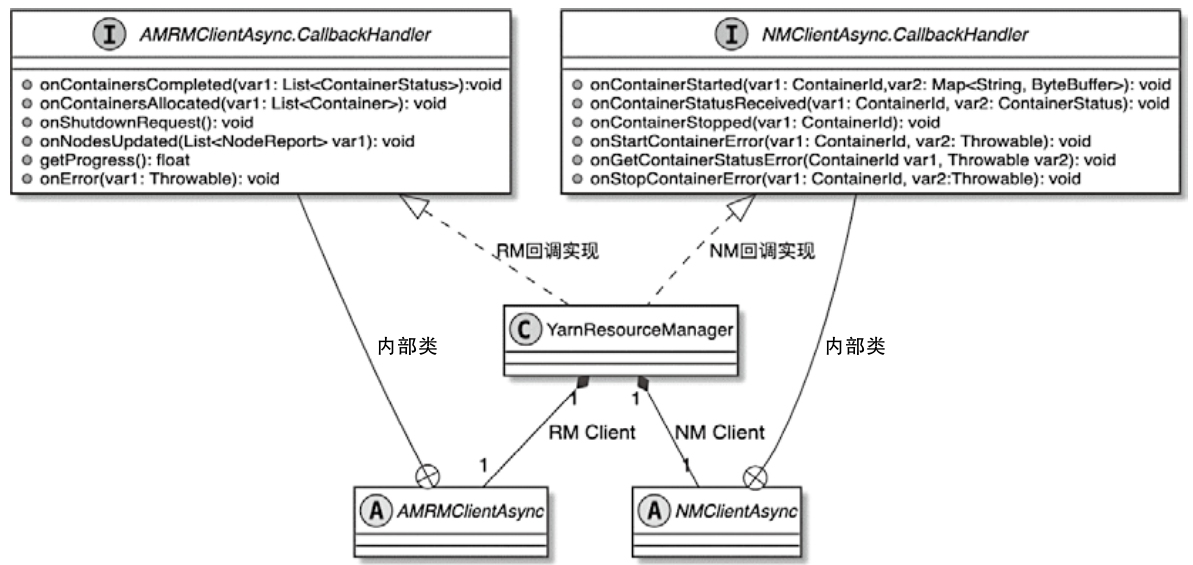
当创建 Flink 的 ResourceManager,会创建不同的子类
- ActiveResourceManager
- StandaloneResourceManager
而 yarn 的 YarnResourceManager 会创建
- resourceManagerClient
- nodeManagerClient
资源管理启动过程
- RM客户端创建与启动
- NM客户端创建与启动
- 动态启动TaskManager节点
创建 TaskExecutor
- 为每个TaskManager创建ResourceID信息,通过ResourceID标识TaskManager资源实例
- 创建启动TaskExecutor的Context上下文信息
- 启动TaskExecutor对应的Container资源容器
- 如果启动有异常则释放资源
TaskManager 和 TaskExecutor
- tm 是基于 jvm 的一个工作节点,包含多个 slots,以及跟 resoure manager 通讯
- TaskExecutor 是内部执行组件,负责真正的执行,以及 状态管理、checkpoint、slots 等
ON k8s
Kubernetes架构图
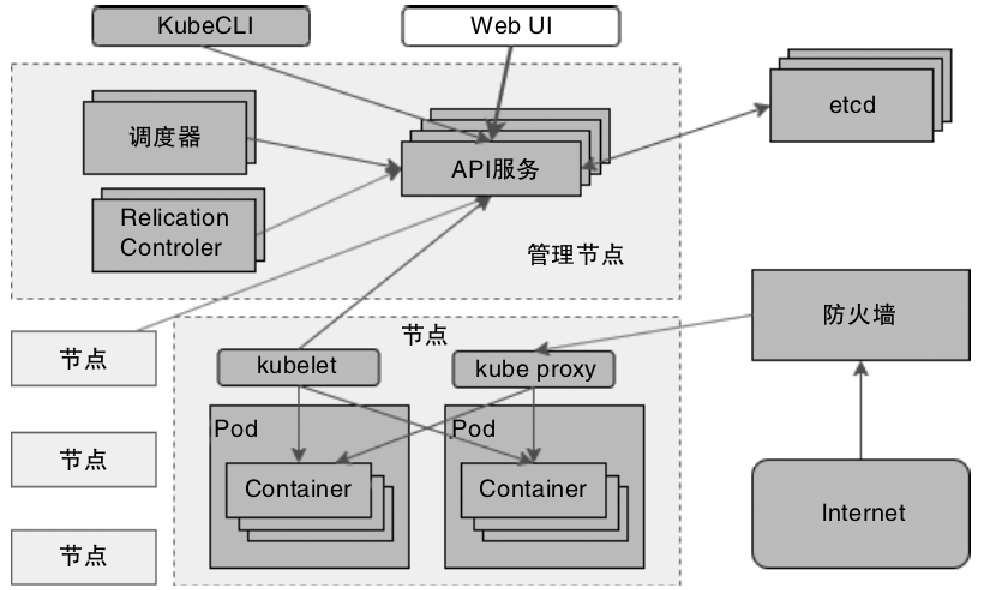
Flink On Kubernetes架构图
- 将Flink客户端连接到Kubernetes API Server,包括 config-map,job-manager service,deployment 等
- kubelet 会从镜像仓库下载镜像,然后挂载,并执行 job-manager命令
- 当JobManager的Pod启动后,Dispacher和KubernetesResourceManager等组件随之全部启动
- KubernetesResourceManager 会申请和启动 task-manager 所需要的容器资源
- k8s 为 task-manager 分配第一个新的 pod,
- TaskManager启动后会主动注册到ResourceManager的SlotManager中
- SlotManager向TaskManager请求Slot计算资源,并分配给JobMaster服务
- TaskManager提供Slot计算资源给JobMaster,JobMaster将任务分配到对应的Slot计算资源上运行
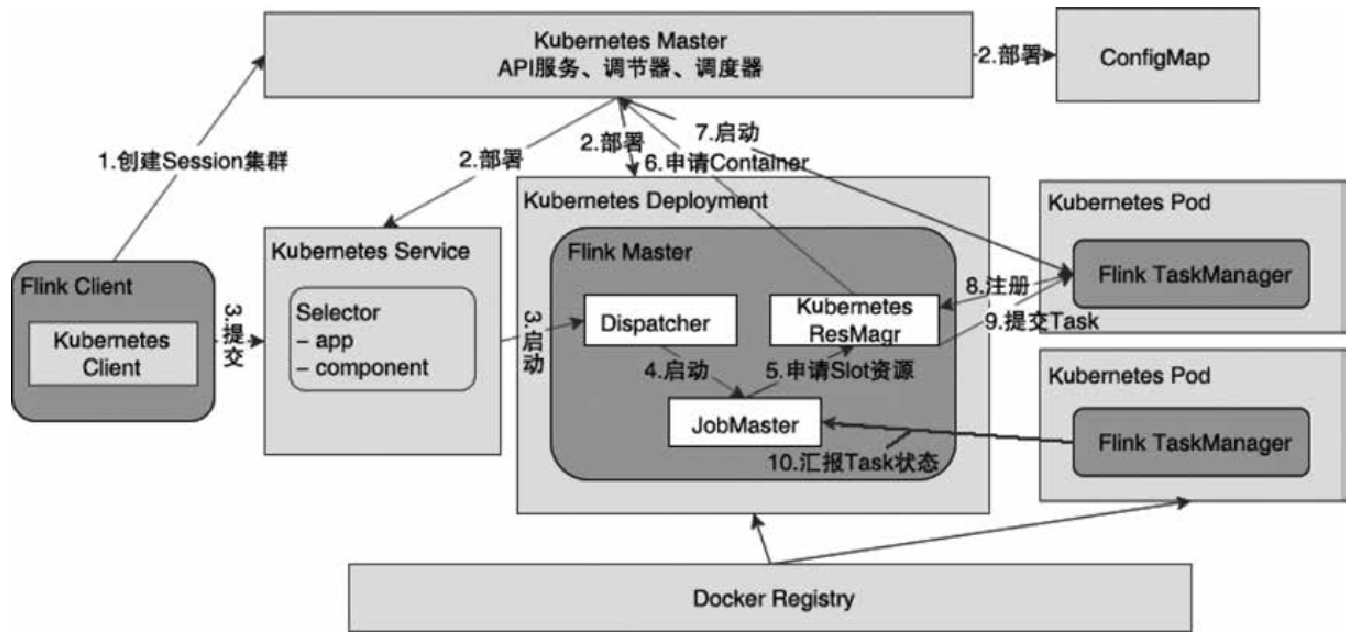
Session集群的部署与启动
- 通过 KubernetesSessionCli客户端部署 KubernetesSession 集群
- 创建 FlinkKubeClient,跟 k8s 交互,创建对应的 pod
- 根据传入的 clusterId,判断是获取已有集群,或者是新建集群
- 基于 KubernetesClusterDescriptor 部署集群
- 创建的入口点是:KubernetesSessionClusterEntrypoint
- 检查高可用配置
- 调用 FlinkKubeClient#createJobManagerComponent()
- 创建:internalClient.resourceList(accompanyingResources).createOrReplace()
- 最终是调用 fabric8 API 创建 pod
- 创建资源
- 通过FlinkKubeClient创建FlinkMasterDeployment
- 通过FlinkKubeClient创建Kubernetes Service
创建的资源包括:
- ConfigMap
- Service
- Deployment
- Pod
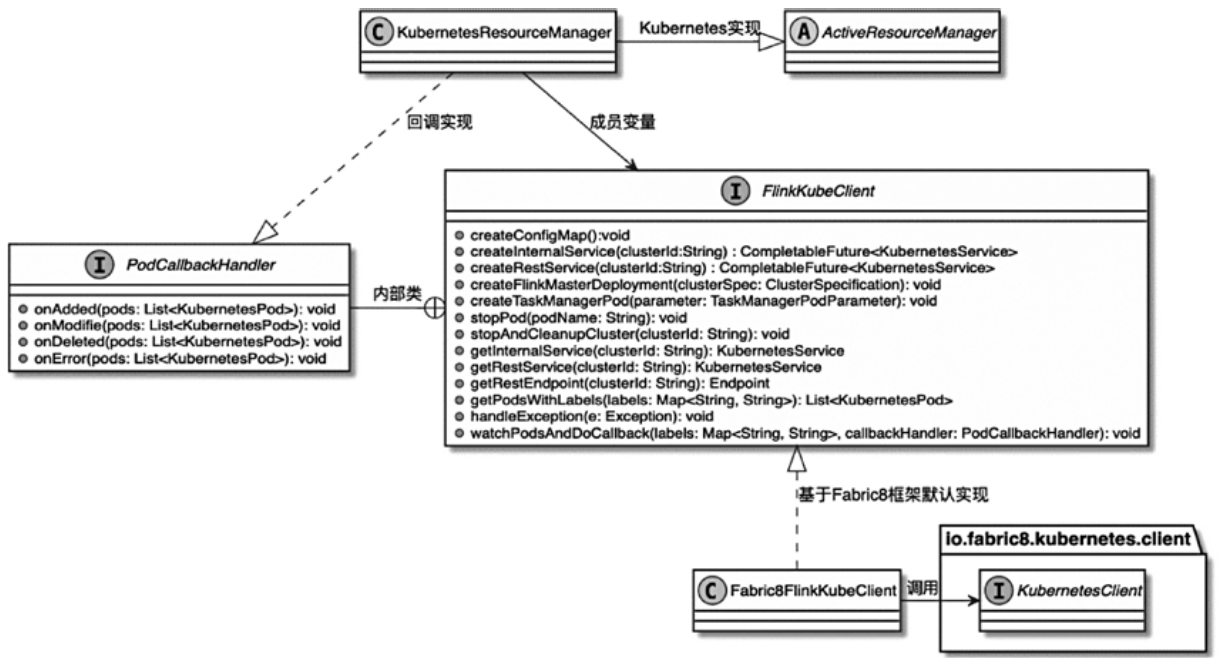
KubernetesResourceManager
- 如从Kubernetes集群申请和启动TaskManager Pod计算资源
- 内部主要使用FlinkKubeClient作为与Kubernetes交互的客户端
PodCallbackHandler接口
- onAdded()、onModifie()、onDeleted()、onError()等回调方法
- 用于 Kubernetes 资源发生变化后,KubernetesResourceManager 能够感知并进行后续的处理
KubernetesResourceManager 类图
动态启动TaskManager节点
- 当用户向Session集群提交任务后,会启动 tm
- 从 镜像仓库拉取镜像,启动 tm
- 调用的是: FlinkKubeClient#createTaskManagerPod
- 通过 KubernetesTaskExecutorRunner,启动 TaskExecutor
Fabric8FlinkKubeClient
- 用这个实现类,来创建 k8s 相关的各种资源
|
|
KubernetesSessionClusterEntrypoint.java
|
|
KubernetesTaskExecutorRunner.java
|
|
角色
Apache Flink Component Classes Overview
来自于 $FLINK_HOIME/bin/flink-console.sh 脚本
| Class Name | Functionality | Deployment Mode | Key Differences |
|---|---|---|---|
**TaskManagerRunner** |
Manages task execution, slot allocation, and data exchange between tasks. | All modes | Core component for task execution; runs in both standalone and Kubernetes modes. |
**HistoryServer** |
Provides a web UI to view historical job metrics and completed job details. | All modes | Post-execution monitoring tool; not part of the runtime cluster. |
**FlinkZooKeeperQuorumPeer** |
Integrates Flink with ZooKeeper for leader election and high availability. | Standalone HA setups | Used only in HA configurations relying on ZooKeeper (not Kubernetes HA). |
**StandaloneSessionClusterEntrypoint** |
Starts a session cluster in standalone mode (long-lived, multi-job). | Standalone | Session clusters accept multiple jobs; requires explicit job submissions. |
**StandaloneApplicationClusterEntryPoint** |
Starts an application cluster in standalone mode (single job). | Standalone | Dedicated to a single job; embeds the job JAR in the cluster. |
**KubernetesSessionClusterEntrypoint** |
Starts a session cluster on Kubernetes (long-lived, multi-job). | Kubernetes | Similar to standalone session mode but optimized for Kubernetes orchestration. |
**KubernetesApplicationClusterEntrypoint** |
Starts an application cluster on Kubernetes (single job). | Kubernetes | Embeds a single job; cluster lifecycle tied to the job execution. |
**KubernetesTaskExecutorRunner** |
Runs TaskManager pods in Kubernetes clusters. | Kubernetes | Kubernetes-specific TaskManager implementation for dynamic resource scaling. |
Key Differences Summary
-
Session vs. Application Clusters:
- Session clusters accept multiple jobs and persist until manually stopped.
- Application clusters run a single job and terminate when the job finishes.
-
Standalone vs. Kubernetes:
- Standalone classes (e.g.,
StandaloneSessionClusterEntrypoint) assume manual VM/container management. - Kubernetes classes (e.g.,
KubernetesSessionClusterEntrypoint) integrate with Kubernetes APIs for autoscaling and resource management.
- Standalone classes (e.g.,
-
ZooKeeper Dependency:
FlinkZooKeeperQuorumPeeris required only for standalone HA setups using ZooKeeper. Kubernetes HA uses native Kubernetes mechanisms (e.g., ConfigMaps).
-
TaskManager Execution:
TaskManagerRunneris generic for all modes, whileKubernetesTaskExecutorRunneradds Kubernetes-specific lifecycle hooks.