Flink 状态管理
状态数据管理
状态类型 类图
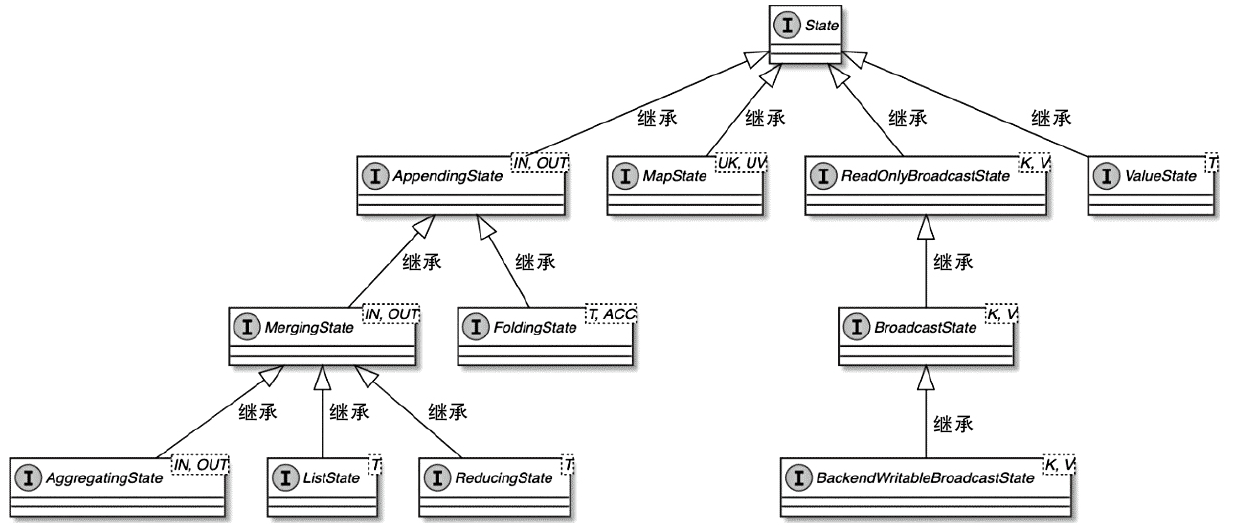
- 状态数据通过抽象出统一的状态接口来表示,并根据不同的状态数据类型和使用方式区分接口实现
Flink中的状态类型都是通过接口实现的
- MapState:用于存储分区的Key-Value类型状态数据
- ValueState:用于单值类型的状态数据,并提供获取和更新状态的方法
- ReadOnlyBroadcastState:提供只读操作的BroadcastState
- BroadcastState:用于存储BroadcastStream中的状态数据,BroadcastState中的数据会被发送到指定算子的所有实例中
- AppendingState:支持累积操作的状态数据
- MergingState:在AppendingState的基础上增加了合并功能,即支持合并状态的操作
- FoldingState:用于支持FoldFunction转换的状态数据
- AggregatingState:用于支持基于AggregateFunction转换的状态数据
- ListState:以数组结构类型存储状态数据
- ReducingState:用于支持ReduceFunction操作状态
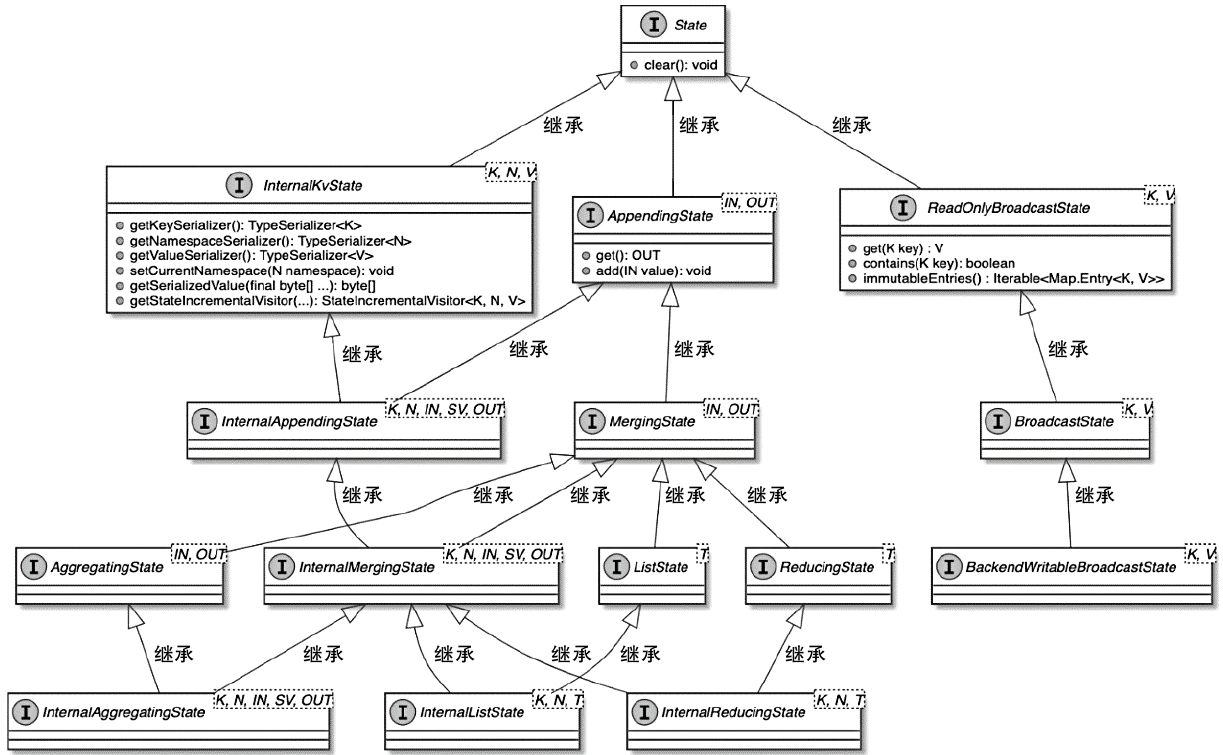
InternalKvState接口 类图
- 用于在运行时将获取内部的状态
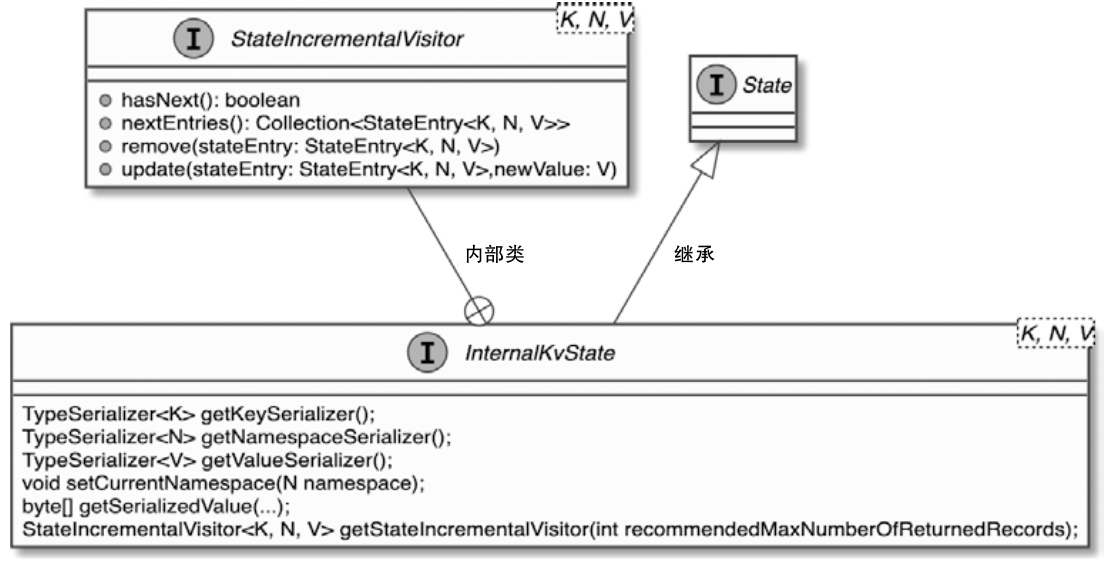
InternalKvState 相关类图
- 有基于堆内存存储的状态类型
- 基于RocksDB存储的状态类型
KeyedState和OperatorState
- 根据DataStream数据集是否基于Key进行分组
- KeyedState 类型
- OperatorState 类型
KeyedState与OperatorState的区别 如下:
| Feature | KeyedState | OperatorState |
|---|---|---|
| Scope | Scoped to a specific key in a KeyedStream (each key has its own state) 1 |
Scoped to an operator instance (all data in the operator shares the same state) 3,5 |
| Applicability | Only usable on KeyedStream operators (e.g., after keyBy()) 1,3 |
Can be used in any operator (e.g., sources, sinks, non-keyed transformations) 3,7 |
| State Structure | Built-in data structures: ValueState, ListState, MapState, etc. 3,7 |
Typically ListState or UnionListState; custom structures require raw bytes 5,7 |
| Access Pattern | Accessed via RuntimeContext in RichFunction (e.g., processElement) 3 |
Accessed via CheckpointedFunction interface (snapshotState, initializeState) 5 |
| Parallelism Handling | Automatically partitioned by key groups for scaling 1,6 | Requires explicit redistribution (e.g., split or union lists) during scaling 1,5 |
| Typical Use Cases | Aggregations (sum, min), window operations, per-key counters 1,4 | Source offsets (e.g., Kafka partitions), sink buffers, operator-wide metrics 5,7 |
| State Backend | Managed by Flink (RocksDB, heap/disk) with automatic serialization 3,7 | Requires manual handling for raw state; managed state uses Flink’s backend 3,5 |
| Fault Tolerance | Part of Flink’s checkpointing mechanism (state snapshots per key group) 6 | Checkpointed as operator-level snapshots (e.g., list redistribution) 1,5 |
| Example | Tracking user session data in a keyed stream (e.g., keyBy(userId)) 4 |
Storing Kafka partition offsets in a source operator 5,7 |
状态初始化
- TaskManager中启动Task线程后,会调用StreamTask.invoke()方法触发当前Task中算子的执行
- 调用: StreamTask.initializeStateAndOpen()
- 只有当所有Operator的状态数据初始化完毕,才会调用StreamOperator.open()方法开启算子,并接入数据进行处理
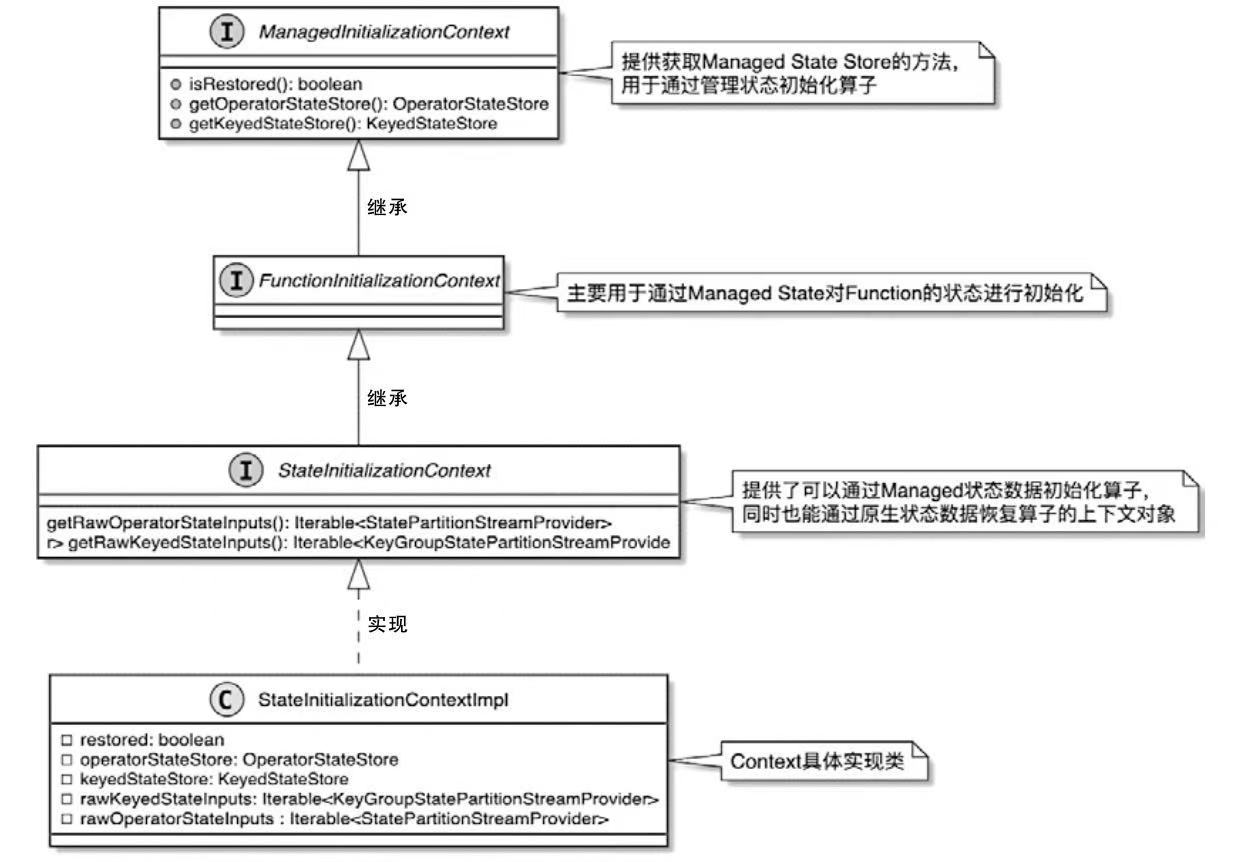
StateInitializationContext 相关类图
- ManagedInitializationContext接口提供了托管状态使用的KeyedStateStore和OperatorStateStore获取方法
- FunctionInitializationContext提供了用户自定义函数状态数据初始化需要的方法
- StateInitializationContext 提供了对托管状态数据的获取和管理,并在内部继承和拓展了获取及管理原生状态数据的方法
- StateInitializationContextImpl 具备操作管理状态和原生状态的能力
初始化过程
- 调用keyedStateBackend()方法创建 KeyedStateBackend,他是 KeyedState 的状态管理后端
- 调用operatorStateBackend()方法创建 OperatorStateBackend,是 OperatorState 的状态管理后端
- 将创建出的 keyedStatedBackend和operatorStateBackend、原生状态存储后端rawKeyedStateInputs和rawOperatorStateInputs及timeServiceManager实例
- 全部封装在StreamOperatorStateContextImpl上下文对象中
- 再返回给 AbstractStreamOperator 使用
- 具体算子可以使用抽象类中的 后端实现
- 最终状态数据会存储在状态管理后端指定的物理介质上,例如堆内存或RocksDB
keyedState
KeyedState
in Apache Flink is a type of state that is scoped to a specific key within a KeyedStream.
It allows stateful operations (e.g., aggregations, counters) to maintain and update data per key, ensuring that computations are partitioned and isolated across keys.
This is essential for distributed processing, as it guarantees consistency and parallelism for keyed operations
KeyedState type
- ValueState: Holds a single value per key (e.g., a user’s total purchases).
- ListState: Stores a list of values per key (e.g., a user’s click history).
- MapState<K, V>: Manages a key-value map per key (e.g., a user’s real-time feature cache).
- ReducingState / AggregatingState: Supports incremental aggregations (e.g., sum or average per key).
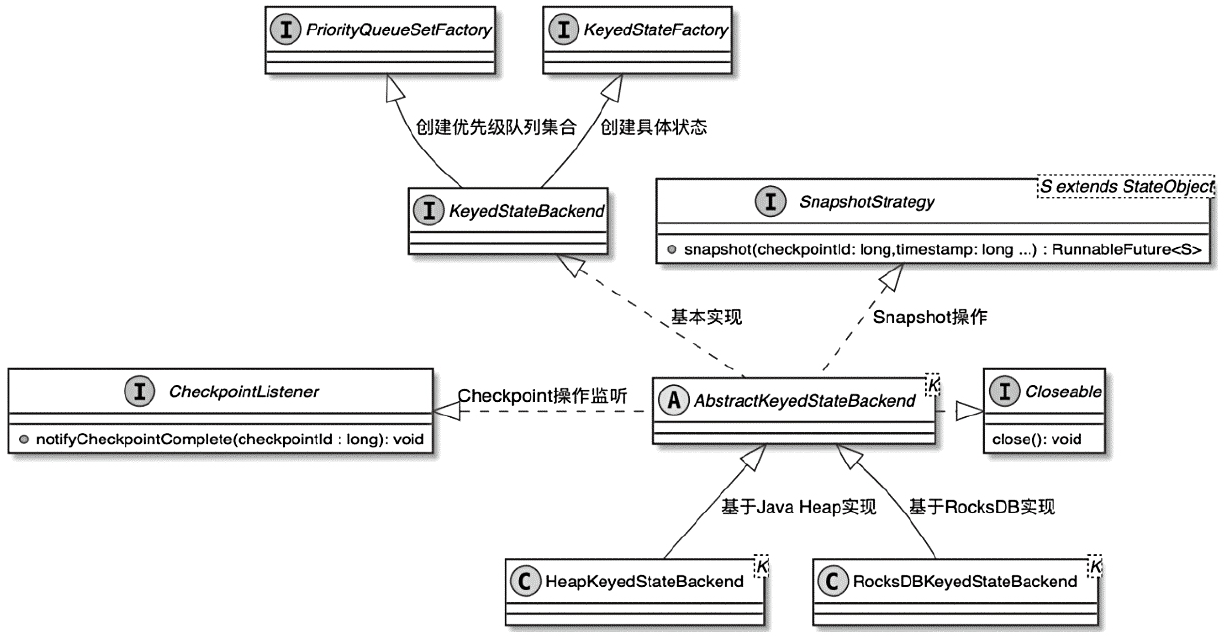
KeyedStateBackend 相关类图
- Flink主要提供了基于JVM堆内存和RocksDB实现的KeyedStateBackend
- AbstractKeyedStateBackend 提供了 snapshot(),将状态数据写入外部系统
- HeapKeyedStateBackend 借助 JVM 堆内存存储 KeyedState 状态数据
- RocksDBKeyedStateBackend 借助 RocksDB 管理的堆外内存存储 KeyedState 状态数据
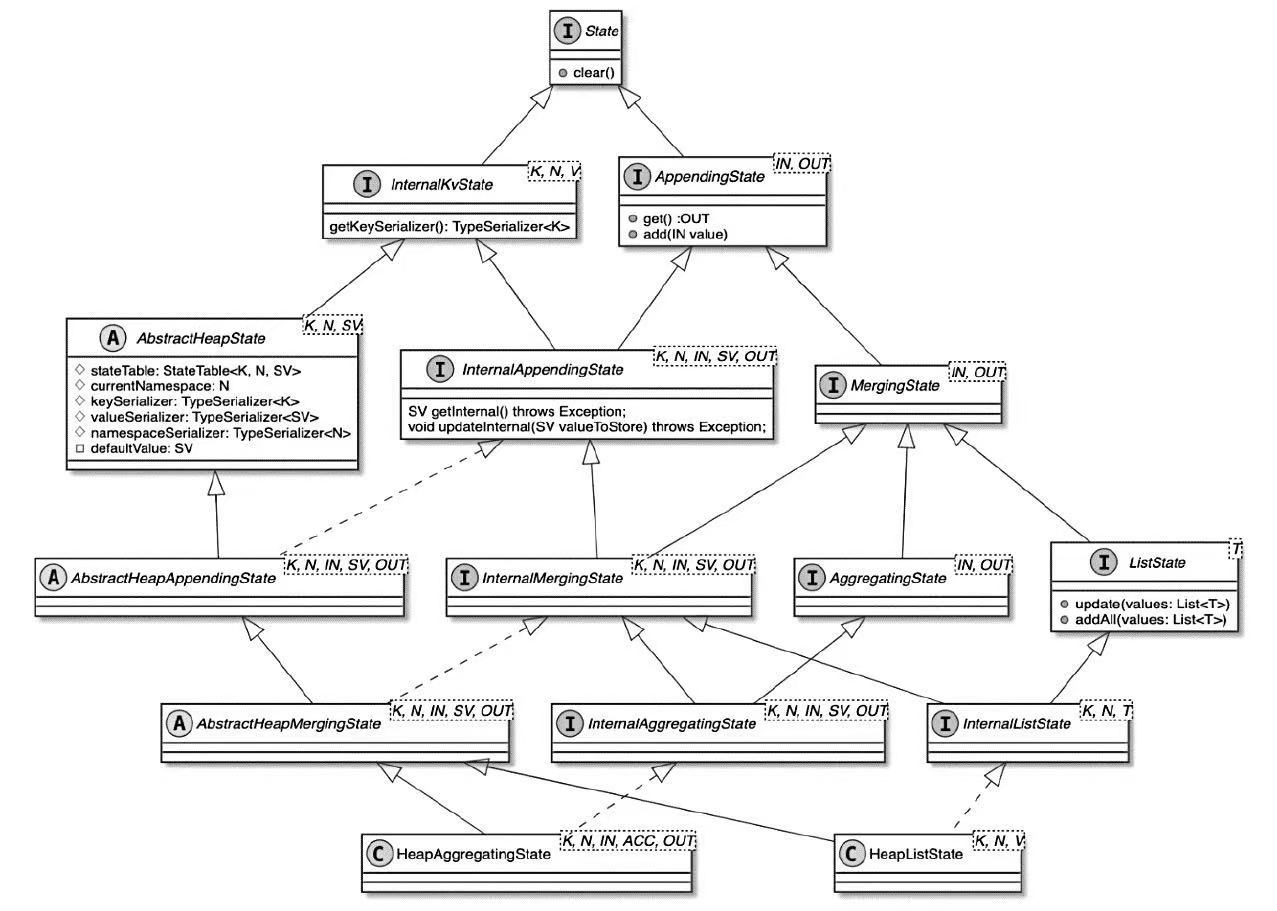
HeapKeyedStateBackend 相关类图
- 这里还实现了 InternalKvState 和具体状态类型的接口
- 基于HeapKeyedStateBackend就可以将全部Keyed State存储在堆内存中
- 当用户实现RichFunction接口时,就可以通过RuntimeContext提供的方法创建指定类型的KeyedState
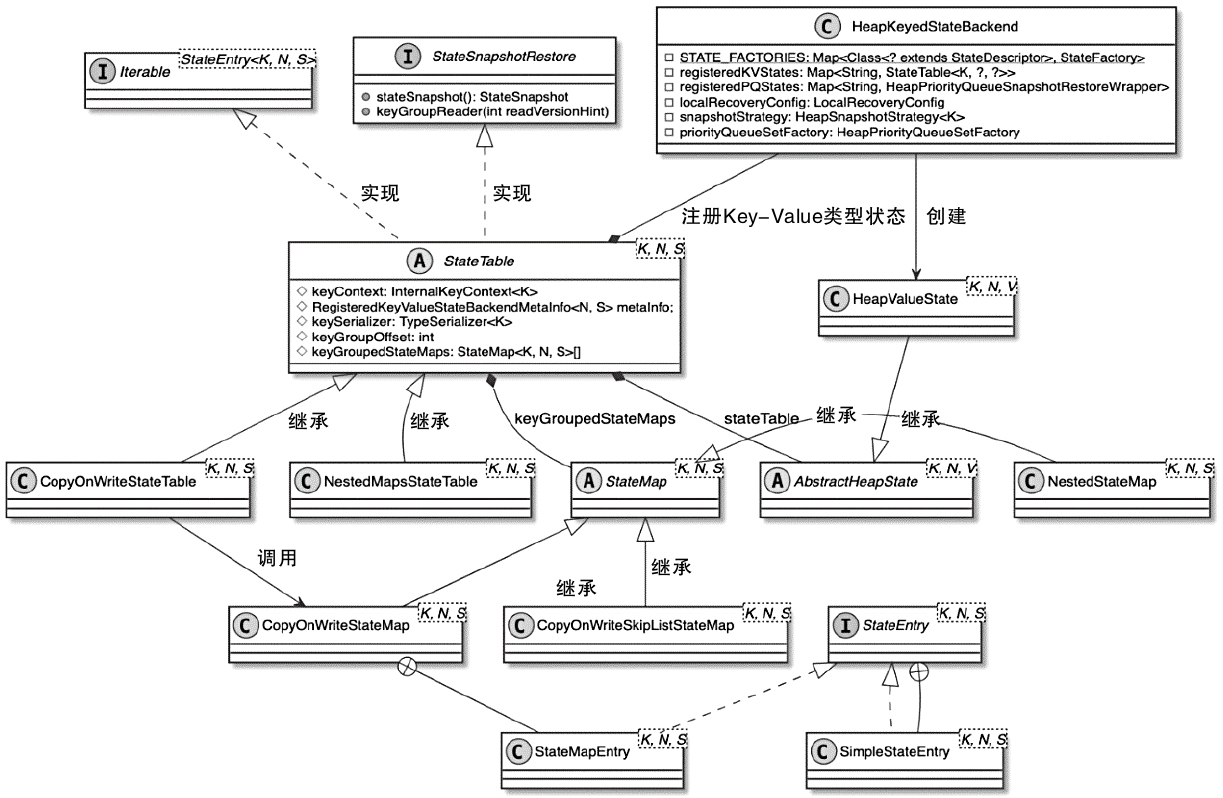
StateTable 相关类图
- 在 HeapKeyedStateBackend 中持有 Map<String, StateTable<K, ?, ?»registeredKVStates 结构来存储 StateName 与 StateTable 之间的映射关系
- StateTable 的实现:CopyOnWriteStateTable,cow 线程实现,checkpoint 支持异步快照
- NestedMapsStateTable底层借助NestedStateMap数据结构存储数据元素
存储结构
|
|
OperatorState
OperatorState 通过以下两种状态管理后端创建
- OperatorStateBackend
- RawKeyedStateInputs
OperatorStateBackend 相关类图
- OperatorStateStore接口提供了获取BroadcastState、ListState
- 以及注册在OperatorStateStore中的StateNames的方法
- SnapshotStrategy接口提供了对状态数据进行快照操作的方法
- 所有算子的状态数据都只能存储在JVM堆内存中
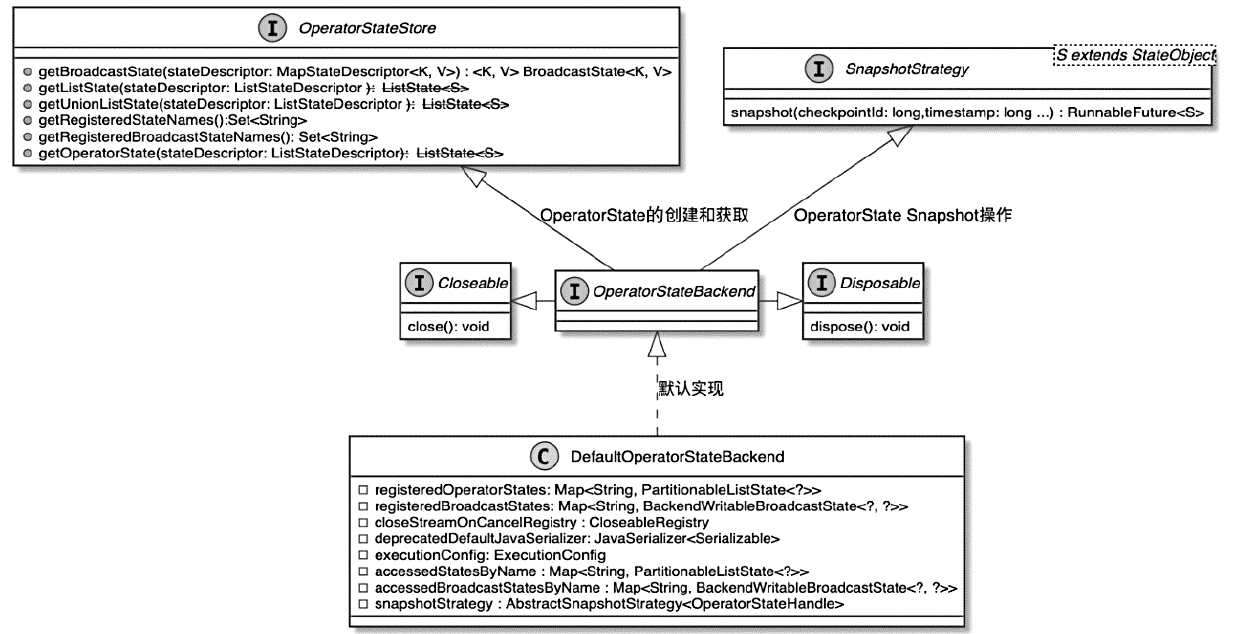
DefaultOperatorStateBackend
- OperatorState Management
- Checkpointing Support
- Memory-Based Storage
| Feature | KeyedStateBackend | OperatorStateBackend |
|---|---|---|
| Scope | Manages state partitioned by keys (e.g., after keyBy()). Each key group corresponds to a specific key. |
Manages state at the operator level, shared across all records processed by an operator instance. |
| State Association | Tied to a specific key in a KeyedStream. State is isolated per key and accessible via keyed operations. |
Not key-specific. State is shared across all data processed by an operator, even without key grouping. |
| Data Structures | Supports rich types: ValueState, ListState, MapState, ReducingState, AggregatingState. |
Primarily uses ListState or UnionListState (raw bytes for custom structures). |
| Parallelism Handling | Automatically partitions state by key groups during scaling. State redistribution is transparent. | Requires manual redistribution logic (e.g., splitting/merging lists) when parallelism changes. |
| Access Interface | Accessed via RuntimeContext in RichFunction (e.g., ValueState updates in processElement). |
Managed through CheckpointedFunction (snapshotState and initializeState methods). |
| Typical Use Cases | Per-key aggregations (e.g., user session counters, windowed sums). | Operator-wide metrics, source/sink offsets (e.g., Kafka partition tracking), broadcast state. |
| Fault Tolerance | Snapshots are key-group-aware, enabling efficient recovery during failures. | Snapshots entire operator state, which may require merging/splitting during recovery. |
StateBackend
Flink支持
- MemoryStateBackend
- FsStateBackend
- RocksDBStateBackend
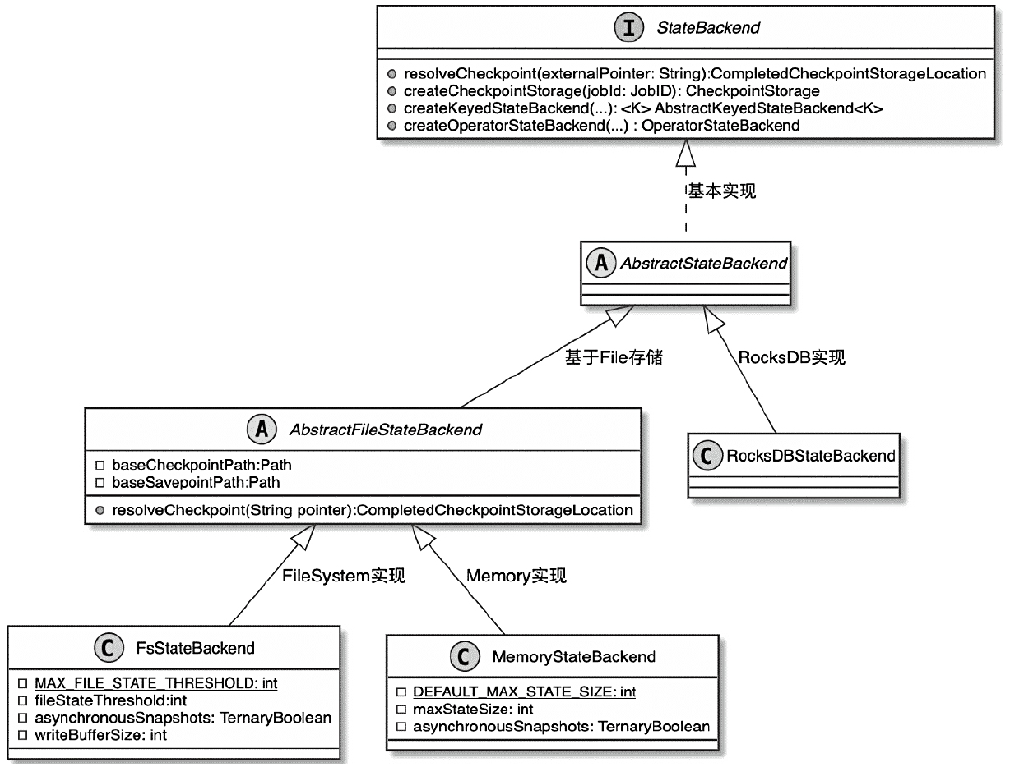
StateBackend 相关类图
- 包括了 文件存储后端、rocksdb 存储
- MemoryStateBackend主要通过JobManager堆内存存储Checkpoint数据
- FsStateBackend通过FsCheckpointStorage将Checkpoint数据存储在指定文件系统中
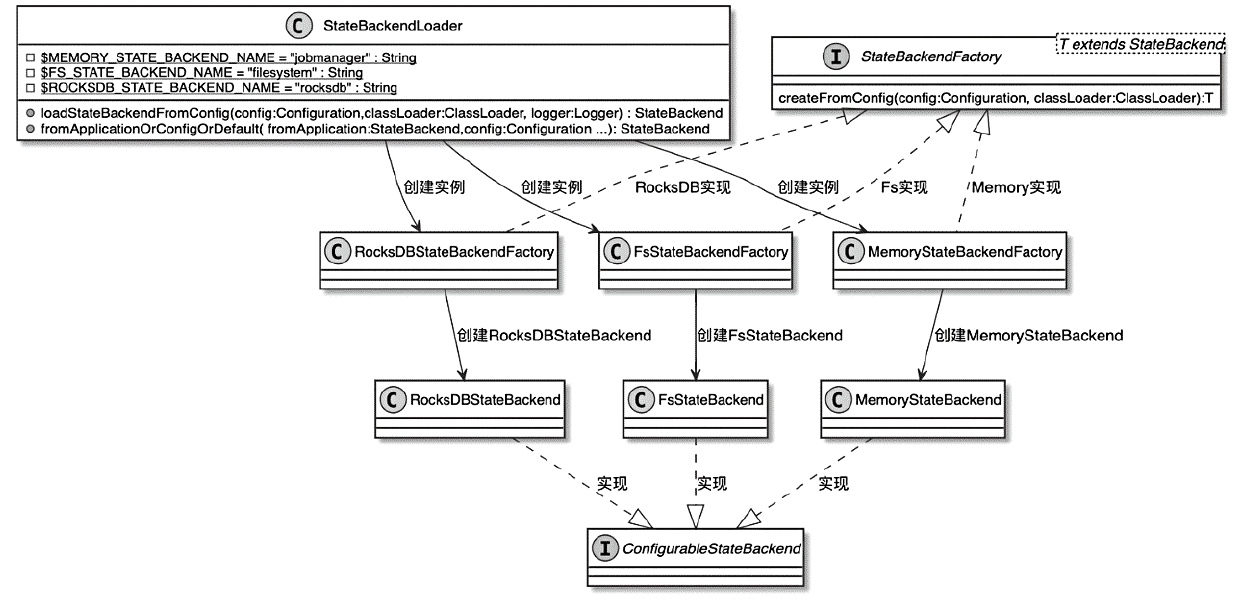
StateBackend 初始化和加载
- 都是通过 StateBackendLoader 加载工厂类,然后通过工厂类创建对应的 后端存储实现
- 并且都继承了 ConfigurableStateBackend 接口
- state.backend的名称使用Java SPI技术加载
StateBackendFactory 相关类图
- JobGraph对象创建ExecutionGraph的过程中会创建StateBackend
- 用于CheckpointCoordinator组件管理状态和Checkpoint操作
- 每个Task实例初始化的过程中会创建StateBackend,用于管理当前Task中的状态和Checkpoint数据
MemoryStateBackend
- 基于MemoryStateBackend创建KeyedStateBackend
- 基于MemoryStateBackend创建OperatorStateBackend
Checkpoint
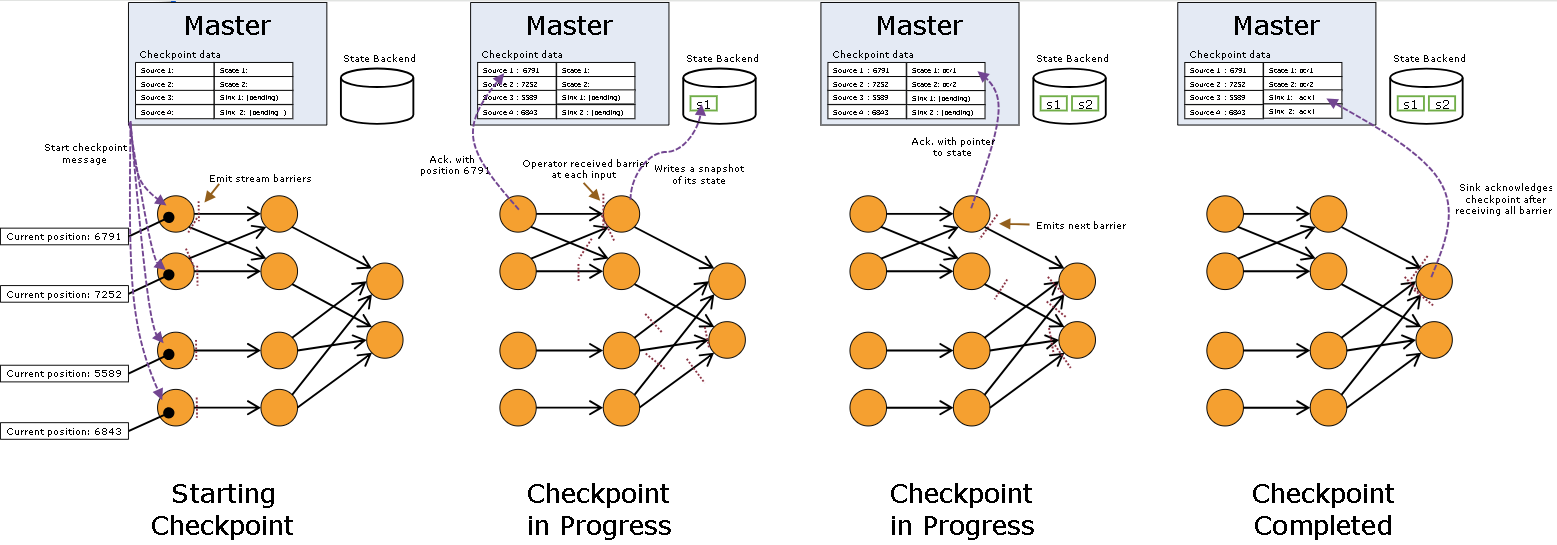
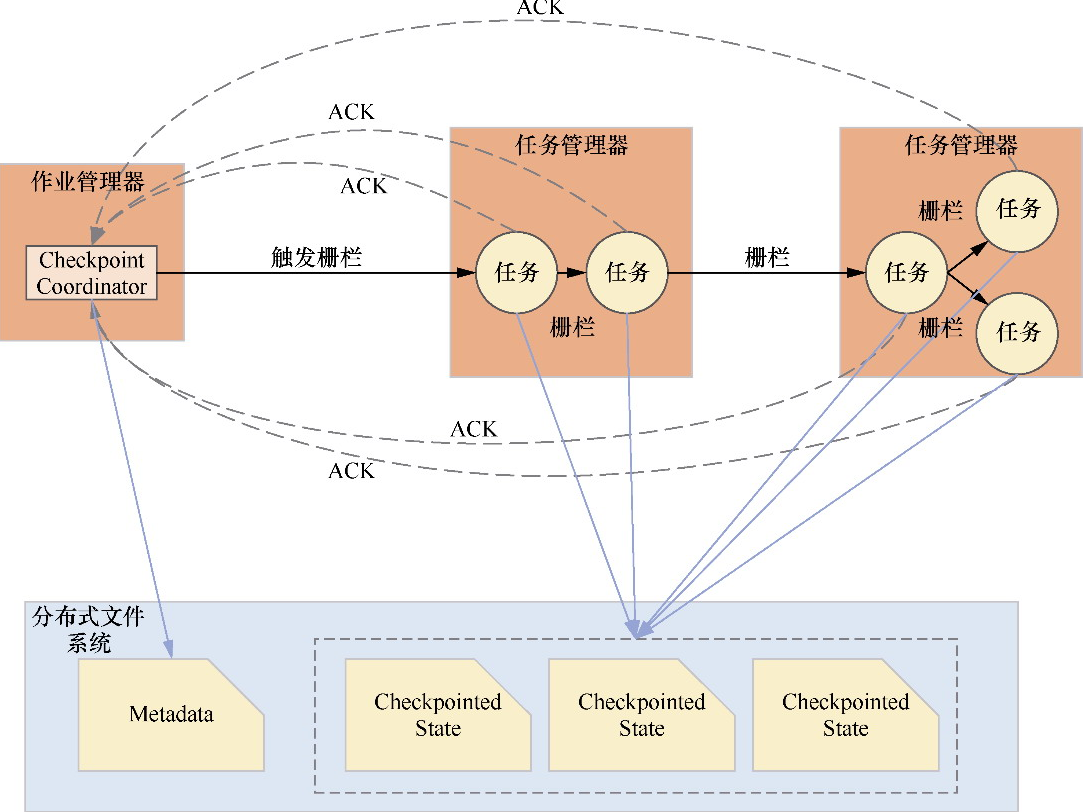
Checkpoint的执行过程分为三个阶段
- 启动
- 执行
- 确认完成
执行过
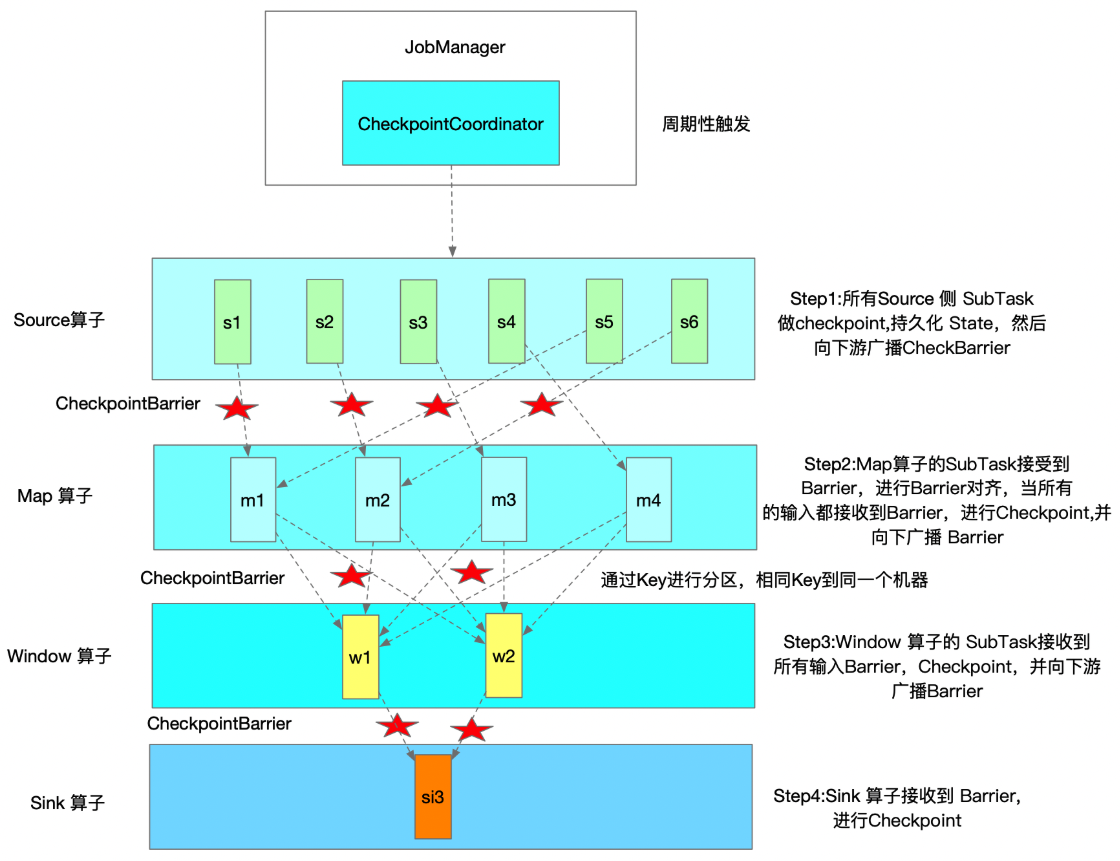
- 首先 job-manager通过 CheckpointCoordinator组件向每个数据源节点发送Checkpoint执行请求
- JobManager节点会存储Checkpoint元数据,用于记录每次执行Checkpoint操作过程中算子的元数据信息
- 如 kafka 的偏移量
- 下游算子通过对齐Barrier事件,触发该算子的Checkpoint操作
- 当下游收到 checkpoint 事件后, block当前算子,等待上游节点其他的 barrier 事件,即 对齐
- 一直持续到 sink,每次算子 checkpoint 也会向 job-manager 发送 ack 事件
- 当所有 sink 发送 ack 后,job-manager 通知所有 task
ExecutionGraph
- 提交时 StreamGraph 会携带 checkpoint 信息
- JobManager 启动时会根据 checkpoint 相关配置创建 ExecutionGraph,然后在JobMaster服务内调度和执行Checkpoint操作
CompletedCheckpointStore 实现
- StandaloneCompletedCheckpointStore
- ZooKeeperCompletedCheckpointStore
Checkpoint的触发方式
- 数据源节点中的Checkpoint操作触发,通过CheckpointCoordinator组件进行协调和控制
- 下游算子节点根据上游发送的Checkpoint Barrier事件控制算子中Checkpoint操作的触发时机
CheckpointCoordinator
- preCheckBeforeTriggeringCheckpoint()方法进行一些前置检查
- 创建 PendingCheckpoint
- 从开始执行Checkpoint操作直到Task实例返回Ack确认成功消息
- Checkpoint会一直处于Pending状态,确保Checkpoint能被成功执行
- 支持 高可用、非高可用
- Checkpoint操作的触发与执行
- 获取coordinator对象锁
- 将PendingCheckpoint存储在pendingCheckpoints键值对中
- 遍历执行executions集合中的Execution节点,判断同步 or 异步执行
- 调用TaskExecutor执行Checkpoint操作
- 在StreamTask中执行Checkpoint操作
CheckpointType 枚举类型
- CHECKPOINT
- SAVEPOINT
- SYNC_SAVEPOINT
对齐 CheckpointBarrier 触发算子Checkpoint操作
- 当下游Task实例接收到上游节点发送的CheckpointBarrier事件消息
- 且接收到所有InputChannel中的CheckpointBarrier事件消息时
- 当前Task实例才会触发本节点的Checkpoint操作
Exactly_Once 和 At_Least_Once 区别
- Exactly_Once 模式,某个算子的 Task 有多个输入通道时,当其中一个输入通道收到 CheckpointBarrier 时,Flink Task 会阻塞该通道
- 其不会处理该通道后续数据,但是会将这些数据缓存起来,一旦完成了所有输入通道的 CheckpointBarrier 对齐,才会继续对这些数据进行消费处理
- At_least_Once,同样针对某个算子的 Task 有多个输入通道的情况下,当某个输入通道接收到 CheckpointBarrier 时
- 即使没有完成所有输入通道 CheckpointBarrier 对齐,At Least Once 也会继续处理后续接收到的数据
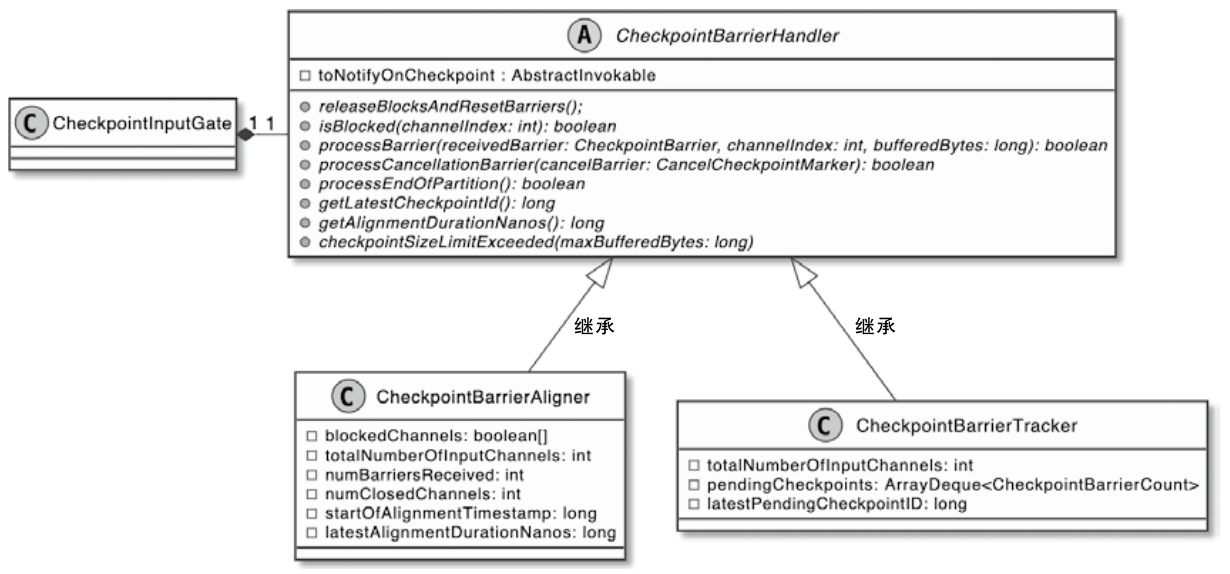
CheckpointBarrierHandler 相关类图
- CheckpointBarrierAligner用于实现Exactly-Once数据的一致性保障
- CheckpointBarrierTracker则实现了At-Least-Once语义处理保障
StreamTask中执行Checkpoint操作
Checkpoint确认过程
checkpoint 流程 1、Checkpoint Initiation (JobManager)
- Entry Point: CheckpointCoordinator (package: org.apache.flink.runtime.checkpoint)
- The triggerCheckpoint() method initiates a new checkpoint.
- Sends TriggerCheckpoint RPC messages to all SourceTasks via Execution#triggerCheckpoint()
- Checkpoint ID Generation:
- Unique IDs are generated via CheckpointIDCounter (persisted in HA storage like Zookeeper).
2、Checkpoint Barrier Injection (Source Tasks)
- Barrier Creation:
- Source tasks (e.g., StreamSource) inject CheckpointBarrier into the data stream via the OperatorChain (class: OperatorChain#broadcastCheckpointBarrier). - Alignment Logic:
- For multi-input operators (e.g., joins), CheckpointBarrierHandler (in StreamTaskNetworkInput) buffers records until all input channels receive the barrier.
3、Task-Level Checkpointing (TaskManager)
- Task Execution: StreamTask#performCheckpoint()
- Suspends processing during the synchronous phase.
- Delegates to StreamOperator#snapshotState() for each operator in the chain (e.g., WindowOperator, ProcessOperator).
- State Snapshot:
- Keyed State: AbstractKeyedStateBackend (e.g., RocksDBKeyedStateBackend) serializes state via SnapshotStrategy#syncPrepareSnapshot().
- Operator State: OperatorStateBackend (e.g., DefaultOperatorStateBackend) writes to ListState or BroadcastState.
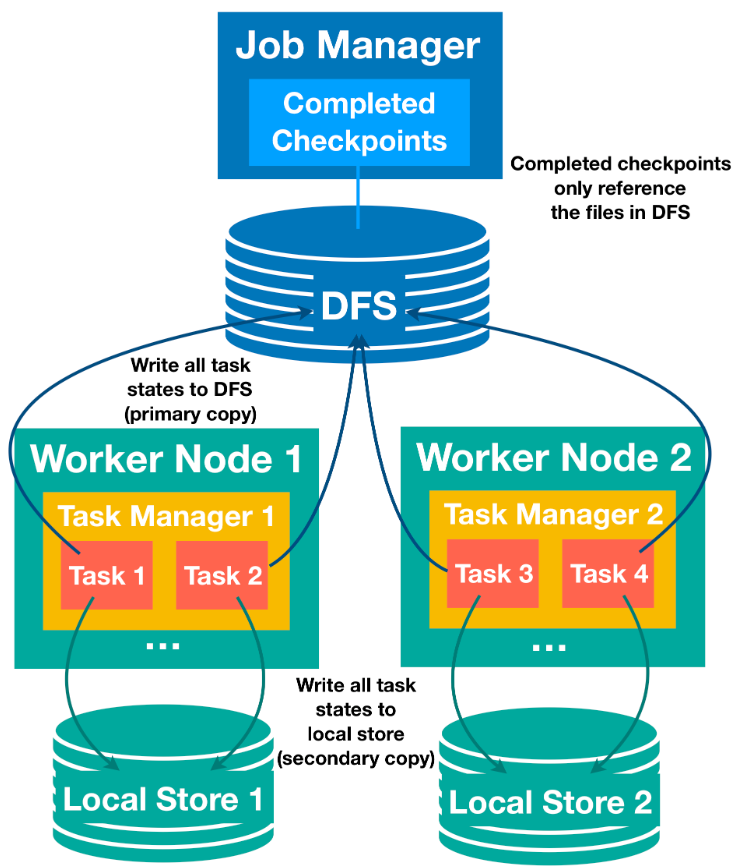
4、Asynchronous Persistence
- Async Thread: AsyncCheckpointRunnable (invoked via StreamTask#asyncCheckpoint())
- Uploads state snapshots to durable storage (e.g., HDFS) using CheckpointStorageWorkers.
- For RocksDB, incremental snapshots are created via RocksDBIncrementalCheckpointUtils
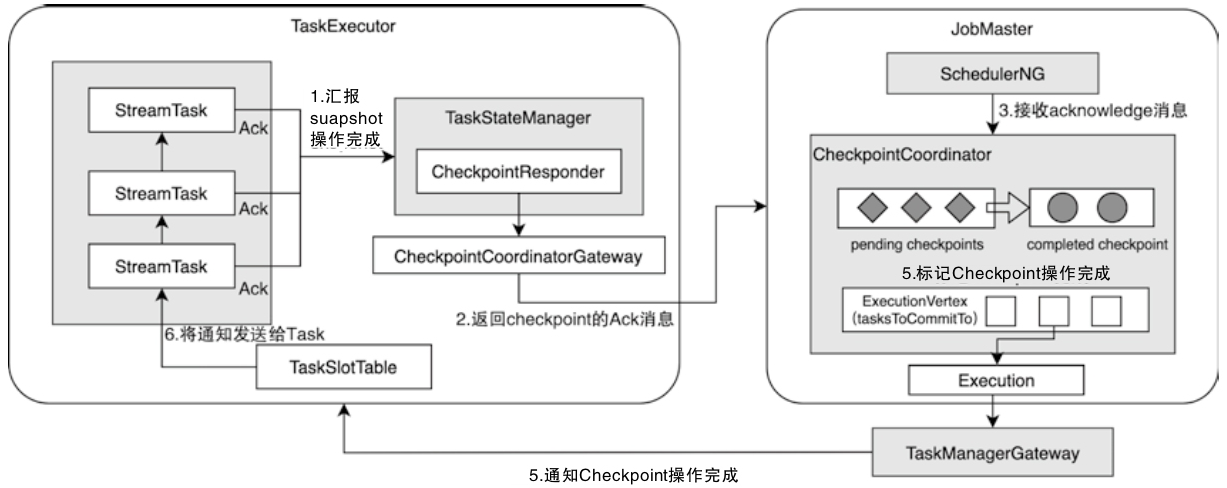
5、Checkpoint Completion & Acknowledgment
- Finalization:
- After all subtasks complete, CheckpointCoordinator finalizes the checkpoint via PendingCheckpoint#complete().
- Updates the CompletedCheckpointStore (persisted in HA storage).
- Acknowledgment:
- TaskExecutor sends AcknowledgeCheckpoint RPC to JobManager, handled by CheckpointCoordinator#receiveAcknowledgeMessage().
6、Recovery & Restore
- State Restoration: TaskStateManagerImpl#restoreLatestCheckpointState()
- Loads state handles from CompletedCheckpointStore during task deployment.
- For keyed state, KeyedStateBackend rebuilds state from RocksDB SST files or heap snapshots.
StateBackend vs OperatorStateBackend vs KeyedStateBackend
- StateBackend
- StateBackend is a configuration-level abstraction that determines how and where Flink stores state data (both keyed and operator state) during computation and checkpoints. It defines the storage mechanism (heap, disk, or hybrid) and checkpoint persistence (e.g., to HDFS, S3).
- OperatorStateBackend
- OperatorStateBackend is a runtime component that manages non-keyed state (OperatorState) for a single operator instance. It handles state that is not partitioned by keys (e.g., Kafka offsets in a source operator).
- KeyedStateBackend
- KeyedStateBackend is a runtime component that manages keyed state (KeyedState) for a KeyedStream. It stores state partitioned by keys (e.g., per-user counters) and is accessible only in keyed contexts (after keyBy()).
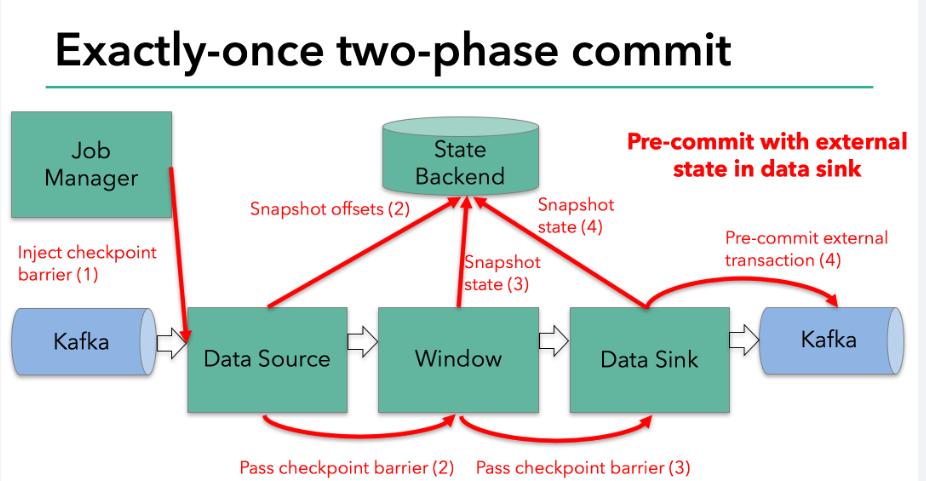
示例
多节点容错对齐
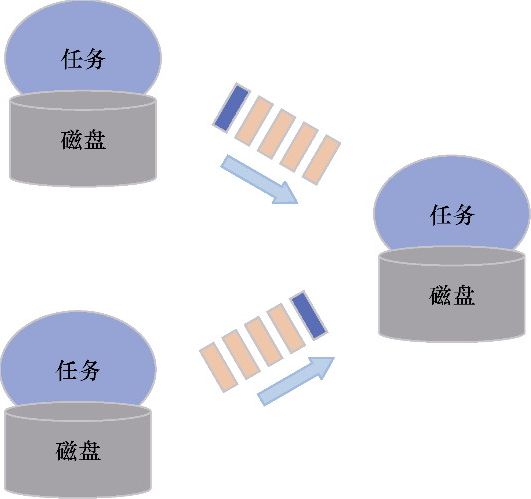
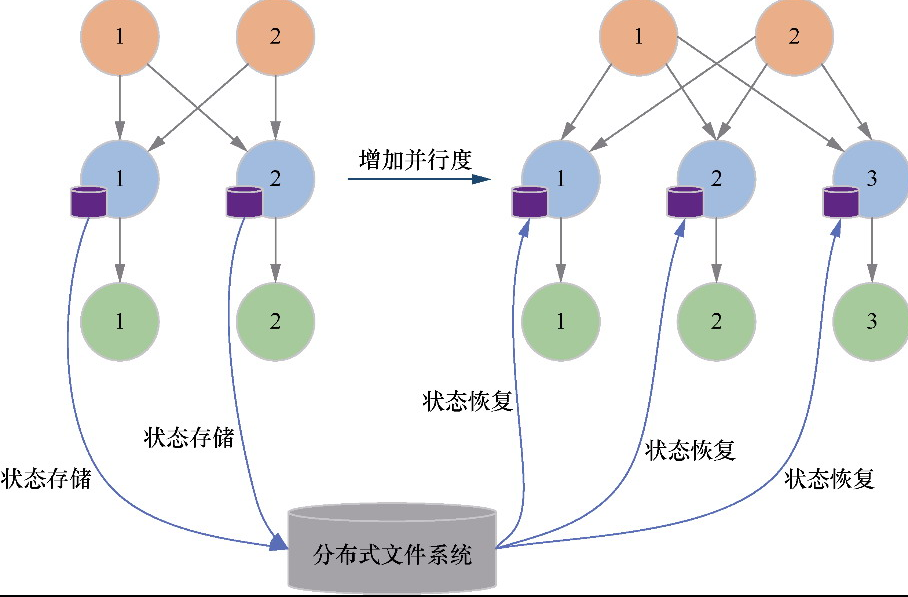
状态存储流程
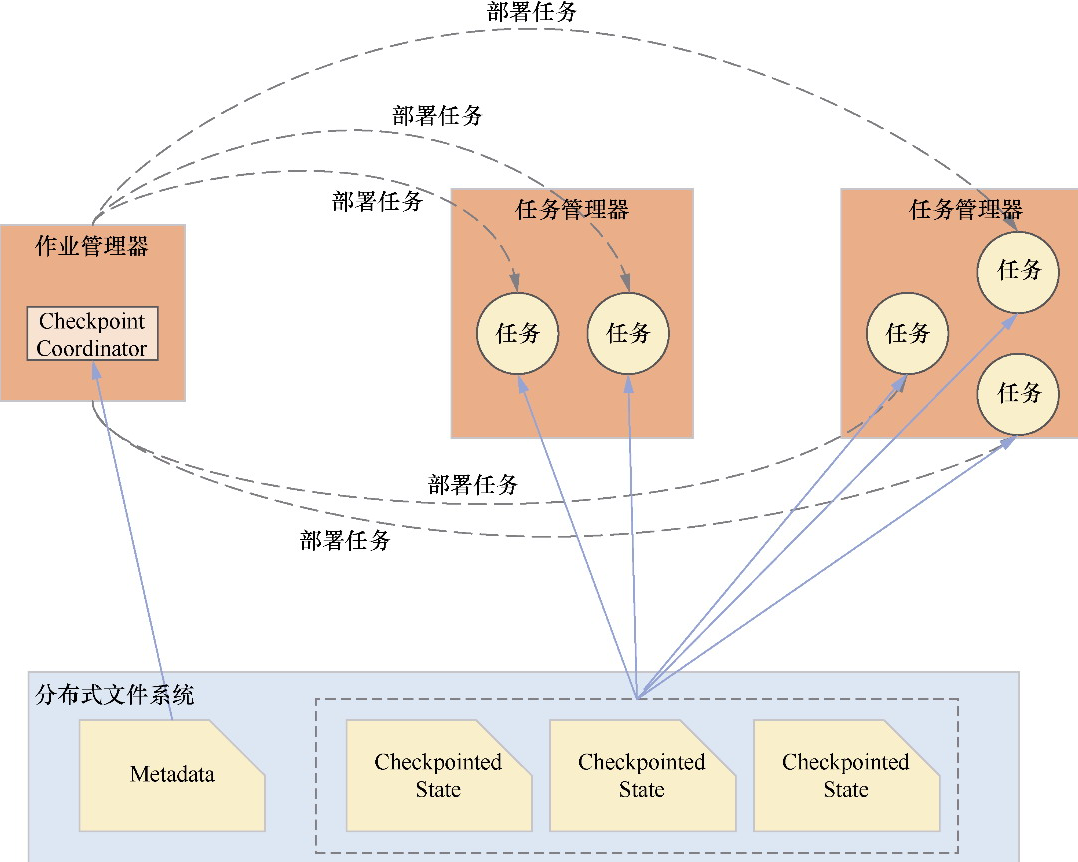
状态恢复流程
无状态流框架
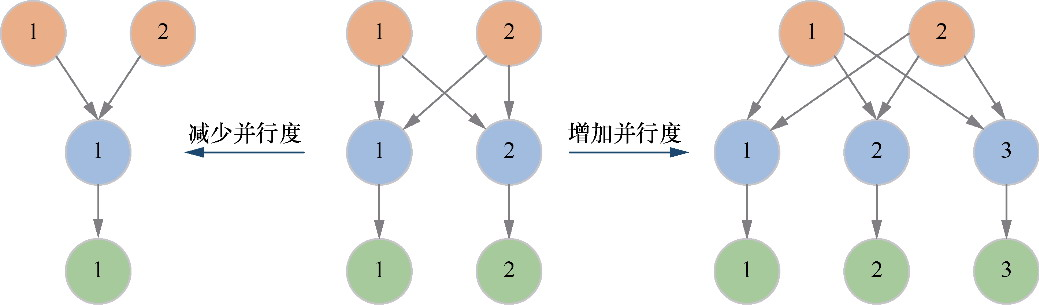
有状态流框架
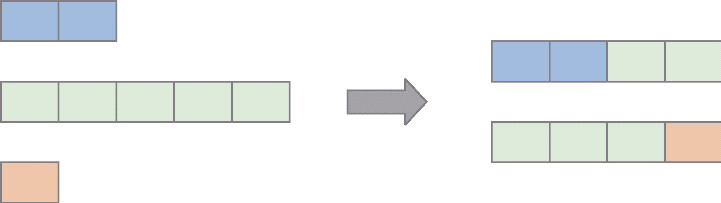
操作符状态的重分配
- SPLIT_DISTRIBUTE
- UNION
- BROADCAST
SPLIT_DISTRIBUTE模式
UNION模式
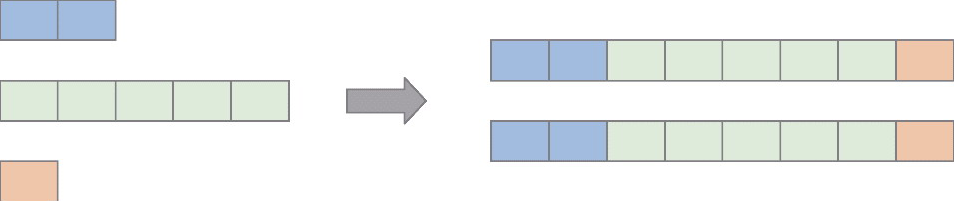
BROADCAST模式
无键组
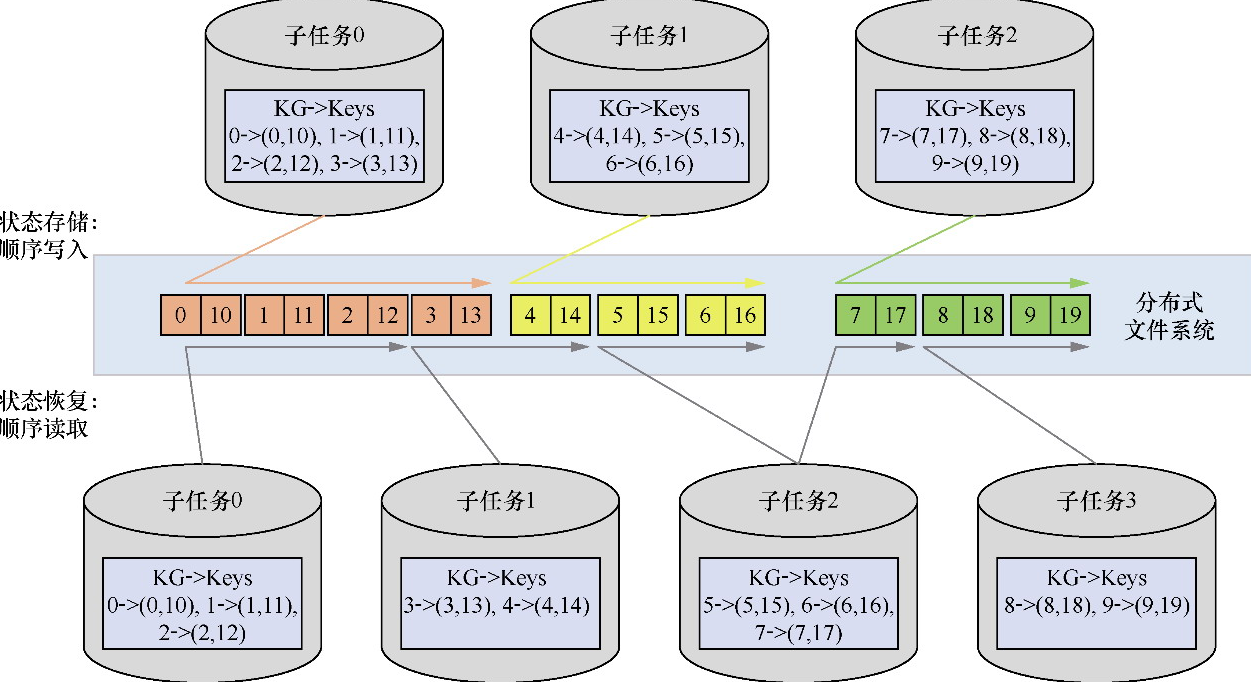
- 并行度从3改成了4,Flink仍然对key取哈希值,再对并行度取余,
- 以此确定状态数据被读取到了哪个并行实例。但是下图可见,状态数据在存储时是顺序写入
- 但是在状态恢复时变成了随机读取
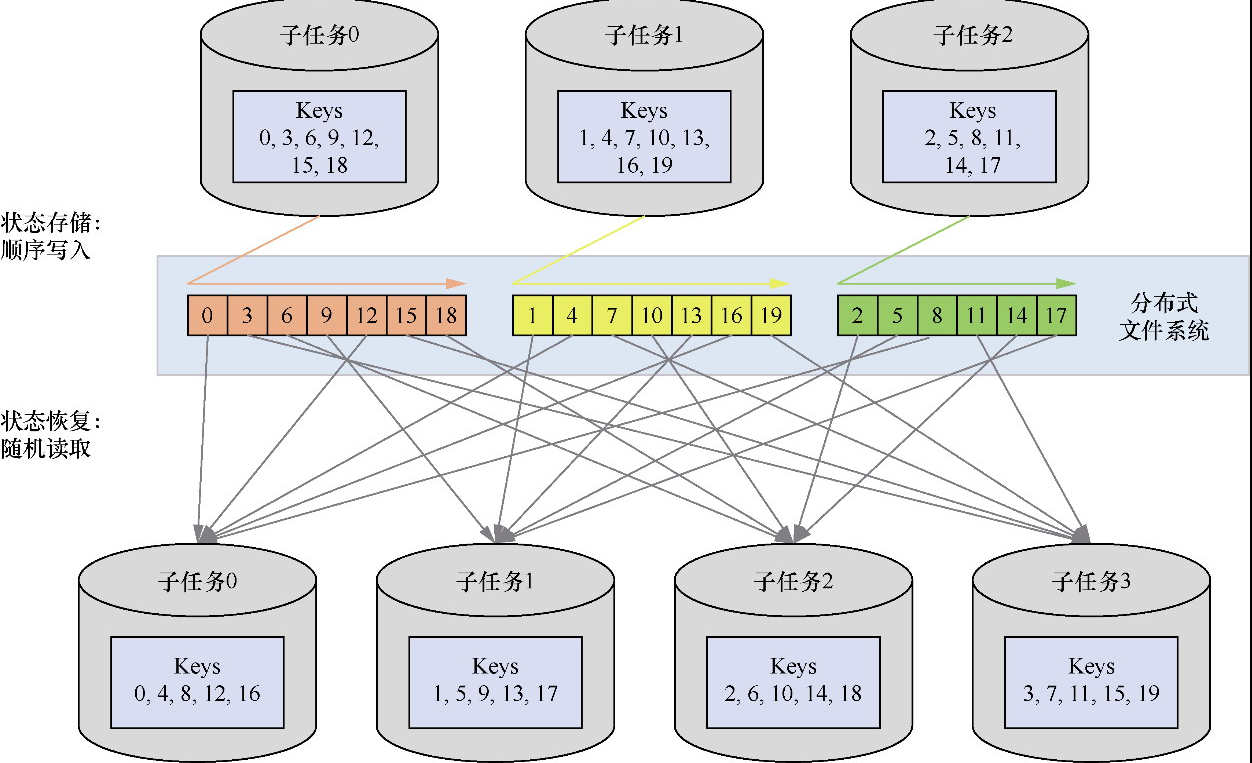
有键组
- 每个key都会按照一定规则被分入某个键组
- 在状态存储时,会以键组为单位进行存储
- 在状态恢复时,会以键组为单位被整体读取到某个新的并行实例中