Flink 任务提交
客户端提交
Flink的作业提交方式
- 本地JVM的伪分布式模式
- 客户端提交到分布式集群运行时运行
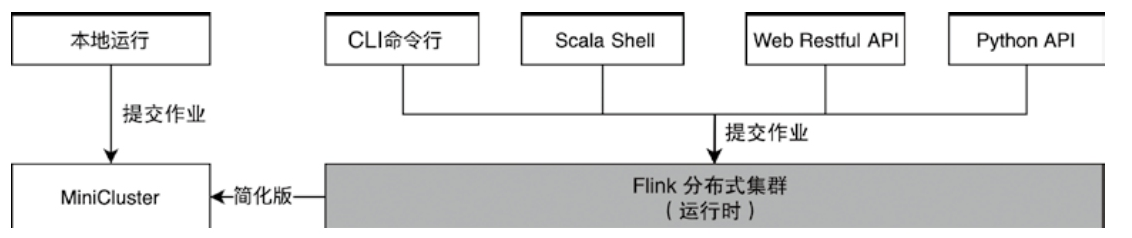
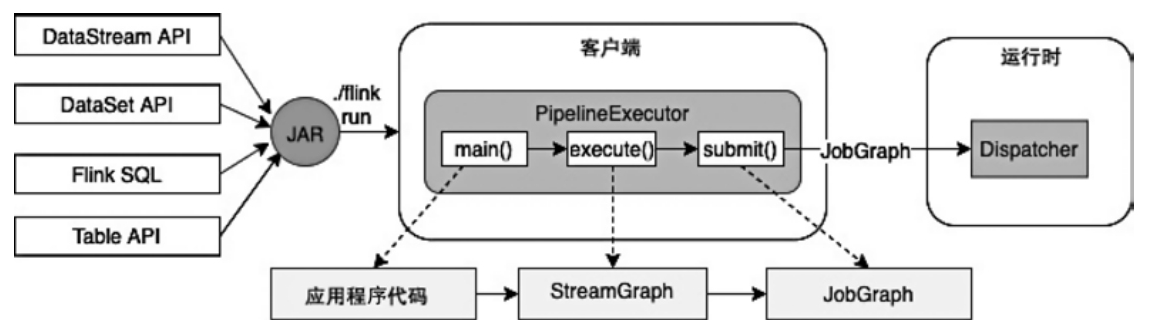
通过 flink bin 运行
|
|
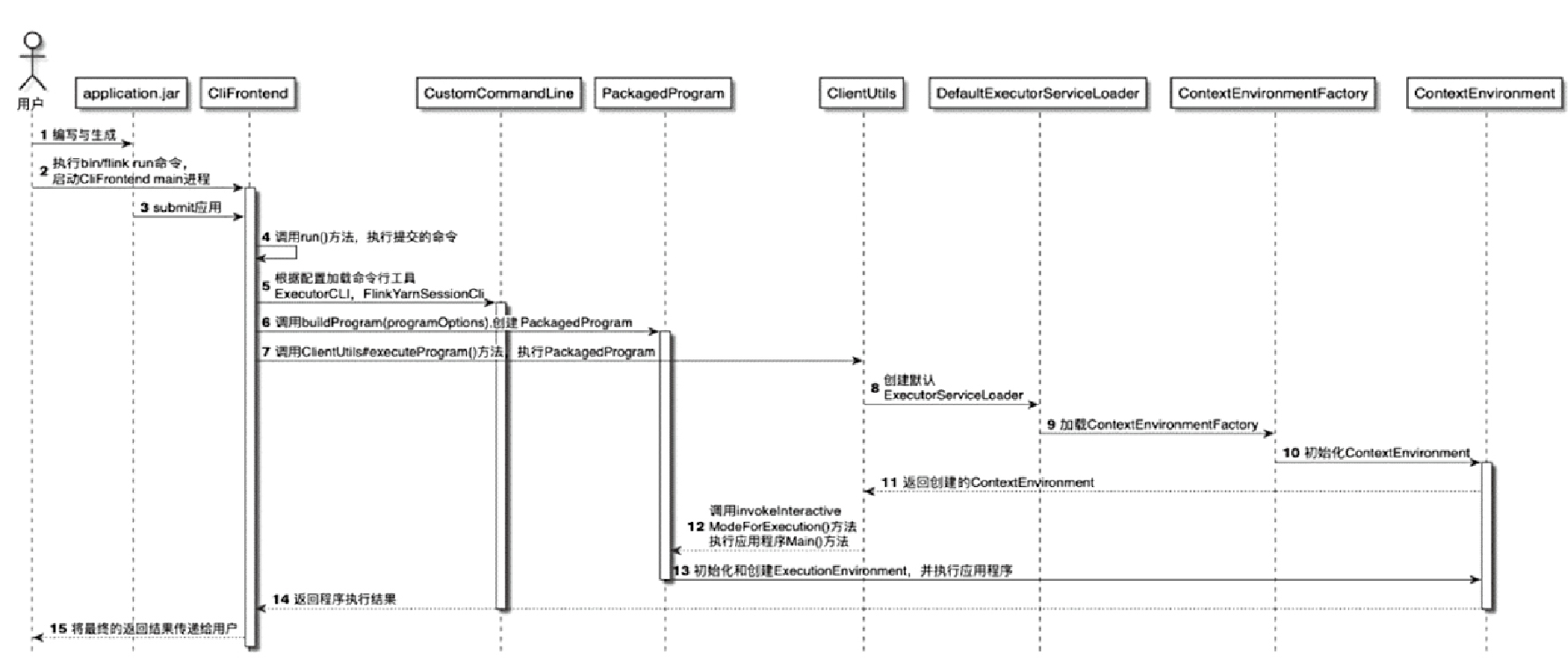
用户将Flink应用程序提交到集群中运行的整个流程
- 启动和初始化CLIFrontend客户端的main程序,将jar 提交到 CLIFrontend
- 调用CLIFrontend中的run()方法,执行应用程序
- 调用CLIFrontend.buildProgram(programOptions)方法,将提交的应用程序打包成PackagedProgram。PackagedProgram包含应用程序中的mainClass、classpaths等信息,实际是在客户端的进程内将用户提交的作业代码打包成的可执行程序
- 调用ClientUtils.executeProgram()方法,执行创建好的PackagedProgram
- 创建和初始化ExecutorServiceLoader接口的实现类DefaultExecutorServiceLoader,加载客户端代码的PipelineExecutor。PipelineExecutor是客户端专门用于执行应用程序代码的执行器,不同类型的集群对应不同的PipelineExecutor实现类
- ExecutorServiceLoader根据不同的服务配置加载ContextEnvironmentFactory
- 在ContextEnvironment初始化完成后,ClientUtils会调用PackagedProgram.invokeInteractiveModeForExecution()方法,通过反射的方式执行Application.jar应用程序中的main()方法
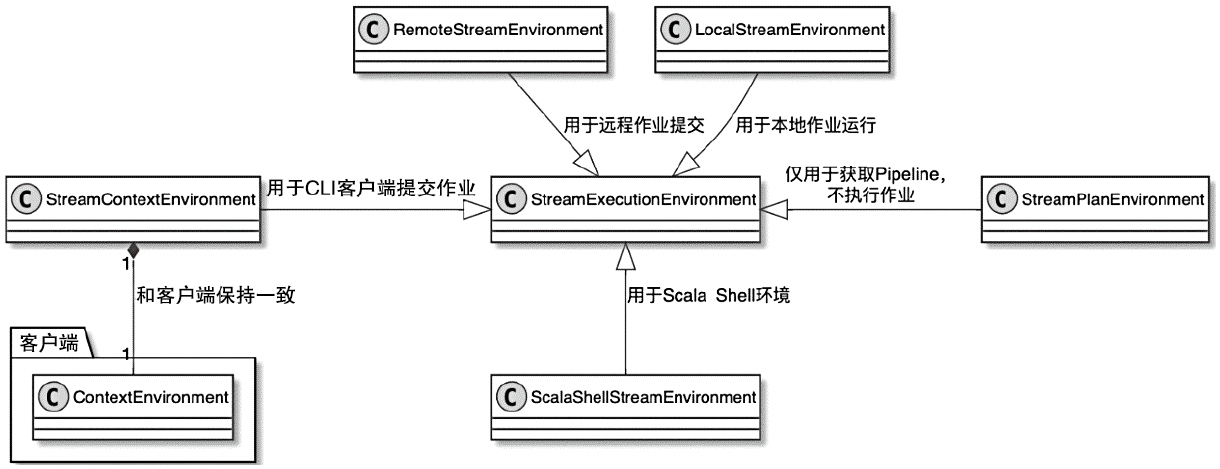
- 创建StreamExecutionContextEnvironment
- 构建JobGraph数据结构,通过ClusterClient将JobGraph提交到集群运行时
CliFrontend
- CliFrontend is the entry point for Flink’s command-line interface (CLI) and handles job submission, configuration parsing, and interaction with Flink clusters
- Key Responsibilities
- Configuration Loading,Loads flink-conf.yaml
- Command Parsing
- Job Submission Workflow:
- Critical Methods:main、parseAndRun、run、list 等
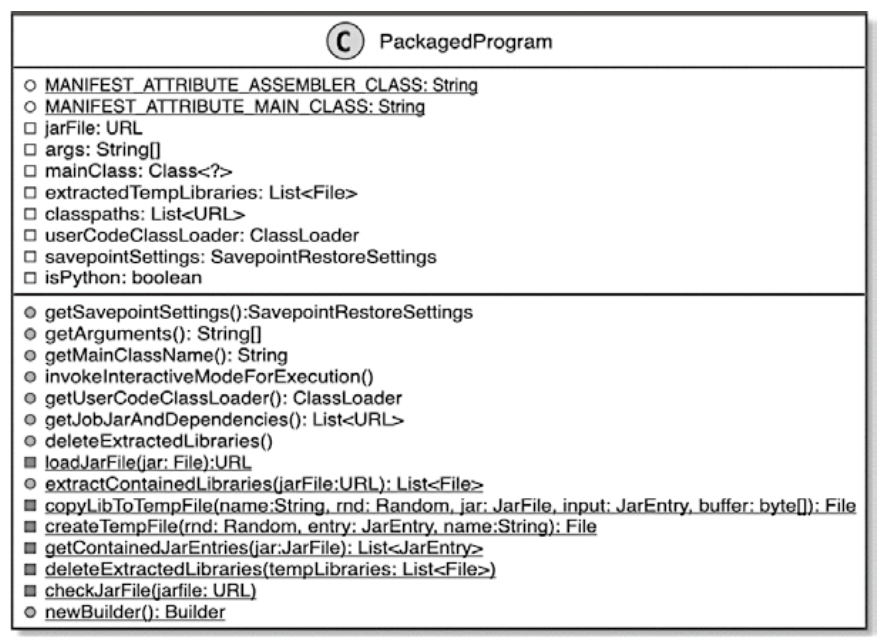
PackagedProgram
- PackagedProgram encapsulates user-submitted JARs, dependencies, entry classes, and runtime arguments, ensuring isolation from Flink’s core dependencies
- Key Features
- Dependency Isolation,Uses a custom URLClassLoader
- Entry Point Execution:Reflectively invokes the user’s main() method to generate the job graph (e.g., StreamGraph, JobGraph)
- Dynamic Configuration
Dynamic Configuration
- CliFrontend parses the run command and initializes PackagedProgram with the user’s JAR and arguments
- The executeProgram() method in CliFrontend triggers PackagedProgram.invokeInteractiveModeForExecution
- User code (e.g., StreamExecutionEnvironment.execute()) generates the job graph and submits it to the cluster
PackagedProgram 类图
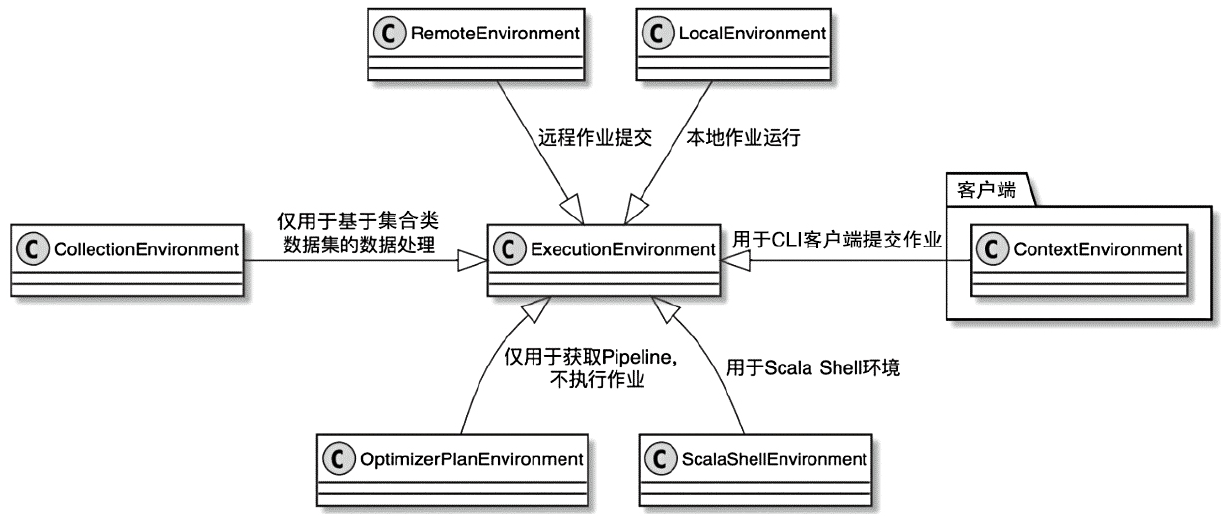
ExecutionEnvironment
ExecutionEnvironment分为
- 支持离线批计算的ExecutionEnvironment
- 支持流计算的StreamExecutionEnvironment
ExecutionEnvironment 相关类图
StreamExecutionEnvironment 相关类图
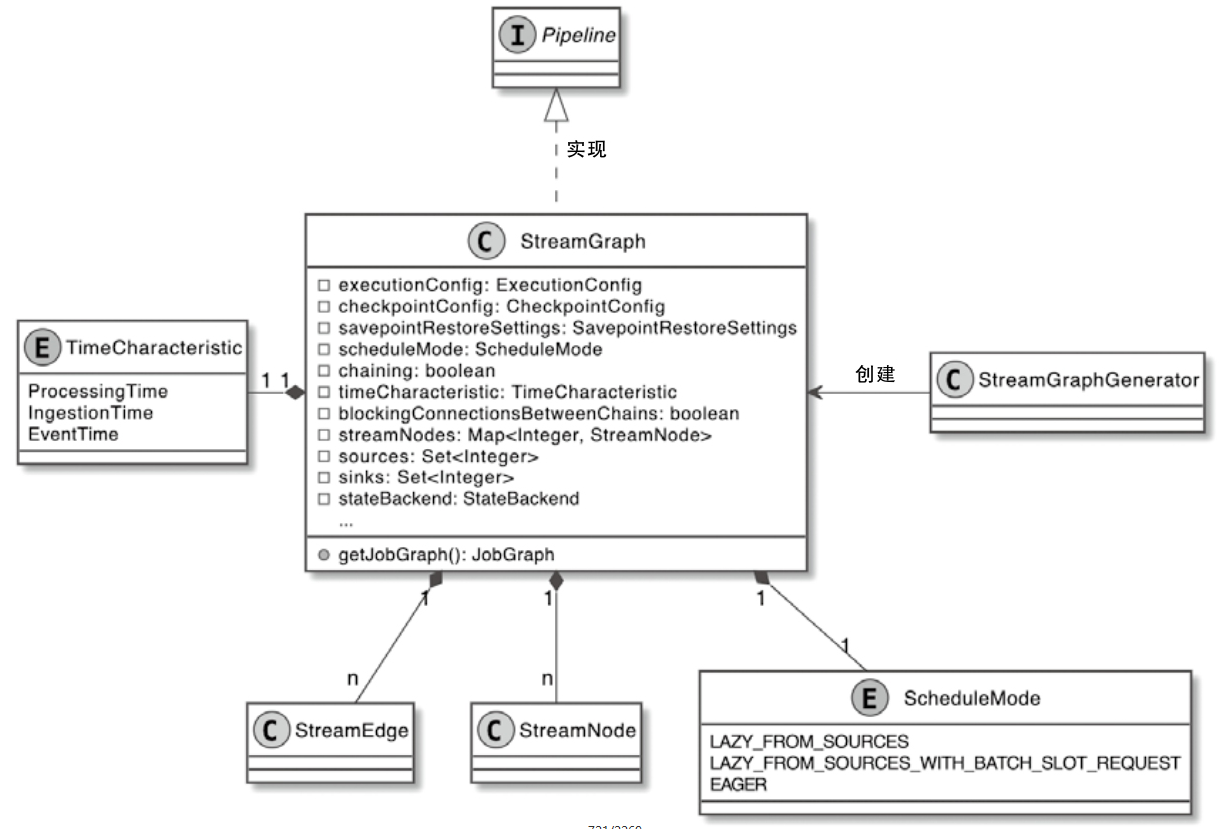
StreamExecutionEnvironment主要成员变量
- transformations,DataStream和DataStream之间的转换操作都会生成Transformation对象
- executorServiceLoader:通过Java SPI技术加载PipelineExecutorFactory的实现类

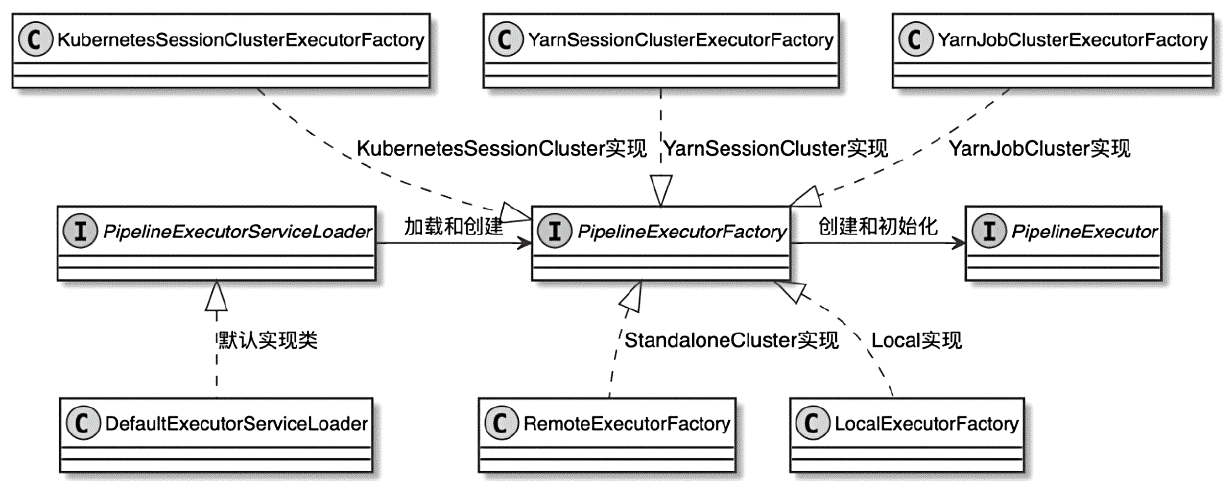
PipelineExecutor 的类图
- PipelineExecutorFactory:是Java Service Provider Interface(SPI)的方式加载
- PipelineExecutorFactory 实现包括
- KubernetesSessionClusterExecutorFactory
- YarnSessionClusterExecutorFactory
- YarnJobClusterExecutorFactory
- RemoteExecutorFactory
- LocalExecutorFactory 实现类
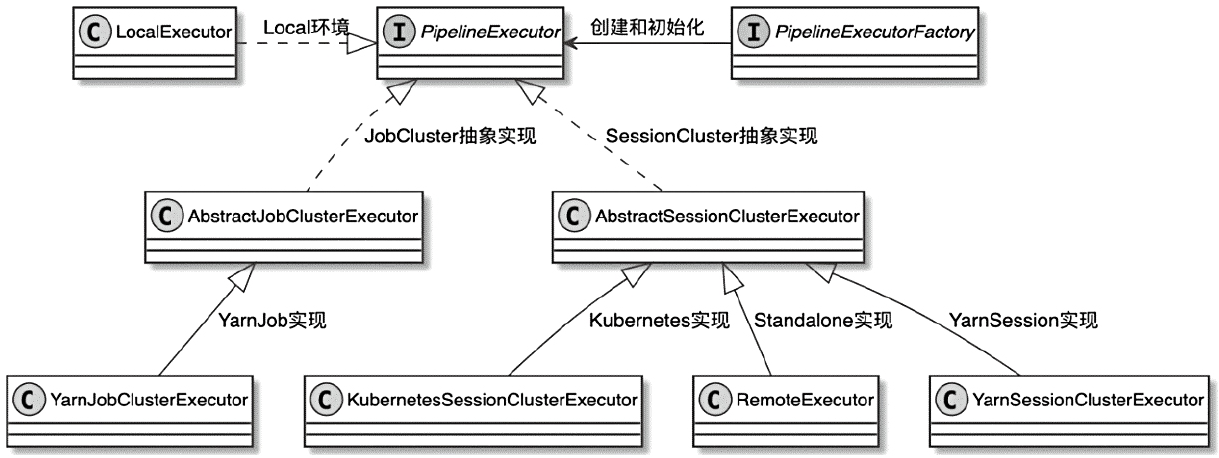
PipelineExecutor分类
- Flink客户端会根据ExecutionTarget参数
- 选择使用哪种类型的PipelineExecutor运行生成的StreamGraph对象
JobGraph
Flink执行图转换过程
- 通过StreamGraphGenerator对象将Transformation集合转换为StreamGraph
- 在PipelineExector中将StreamGraph对象转换成JobGraph数据结构
- 集群运行时接收到JobGraph之后,会通过JobGraph创建和启动相应的JobManager服务,并在JobManager服务中将JobGraph转换为ExecutionGraph
- JobManager会根据ExecutionGraph中的节点进行调度
- 将具体的Task部署到TaskManager中进行调度和执行
StreamGraph 相关类图
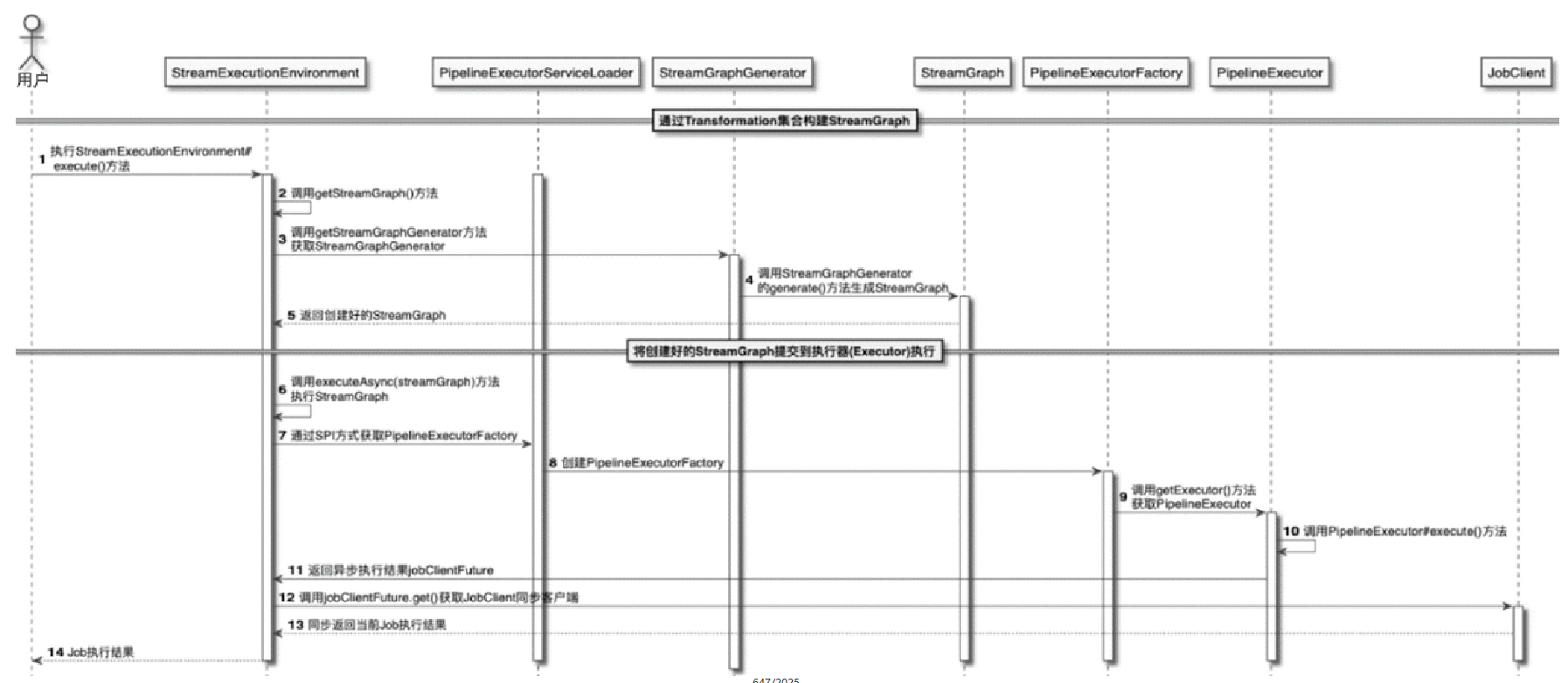
StreamGraph 的时序图
- 调用StreamGraphGenerator.generate()方法生成StreamGraph对象
- 调用StreamExecutionEnvironment.executeAsync(streamGraph)方法,执行创建好的StreamGraph对象
- 调用PipelineExecutorServiceLoader加载PipelineExecutorFactory实例
- 调用PipelineExecutor.execute()方法执行创建好的StreamGraph
- 此时方法会向StreamExecutionEnvironment返回异步客户端jobClientFuture,调用jobClientFuture.get()方法得到同步JobClient对象
- JobClient将Job的执行结果返回到StreamExecutionEnvironment
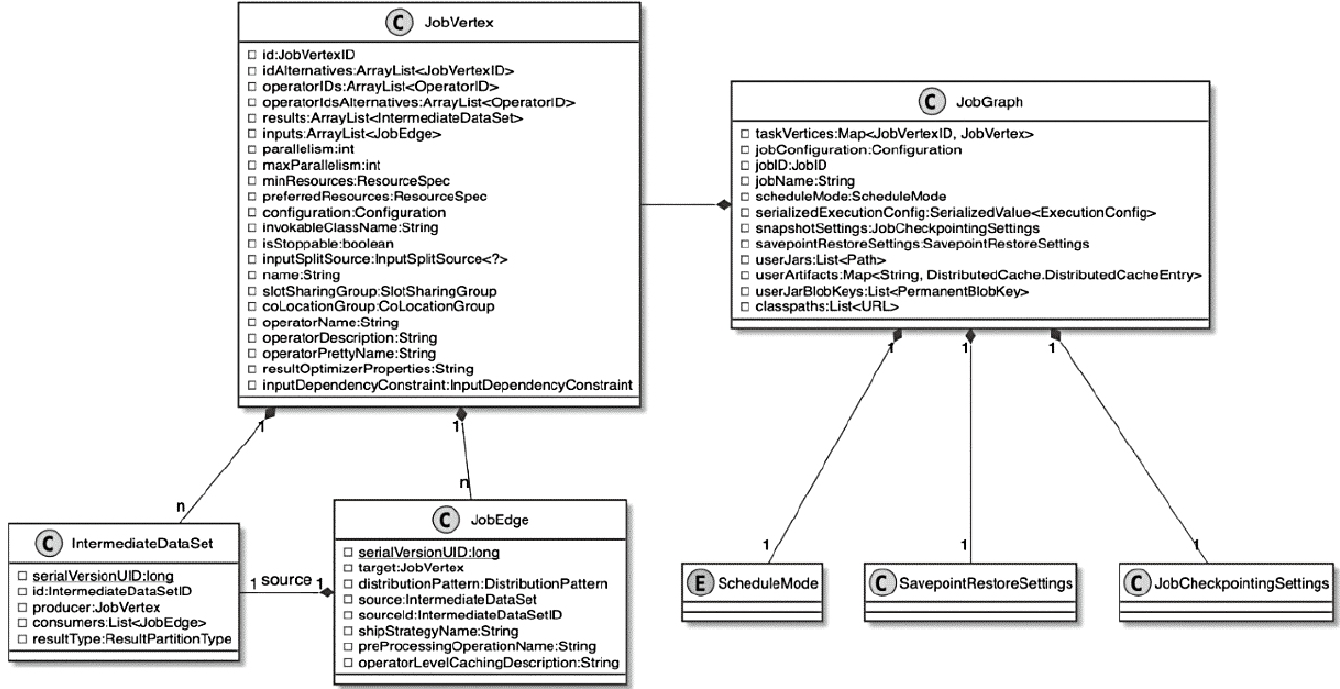
JobGraph
- JobGraph图结构中的单个节点通过JobVertex表示
- JobVertex主要包含JobEdge和IntermediateDataSet
- JobEdge表示当前节点的输入节点信息
- IntermediateDataSet表示当前Job节点对应输出的数据集类型
- 将多个符合条件的StreamNode节点链化在一个JobVertex节点中
- 通过StreamEdge生成JobGraph中的JobEdge信息
ClusterClient
- 构建了与集群运行时中Dispatcher之间的RPC连接
- clusterClient.submitJob()方法将jobGraph提交到指定的集群运行时中
- 然后返回CompletableFuture对象
JobGraph的接收与运行
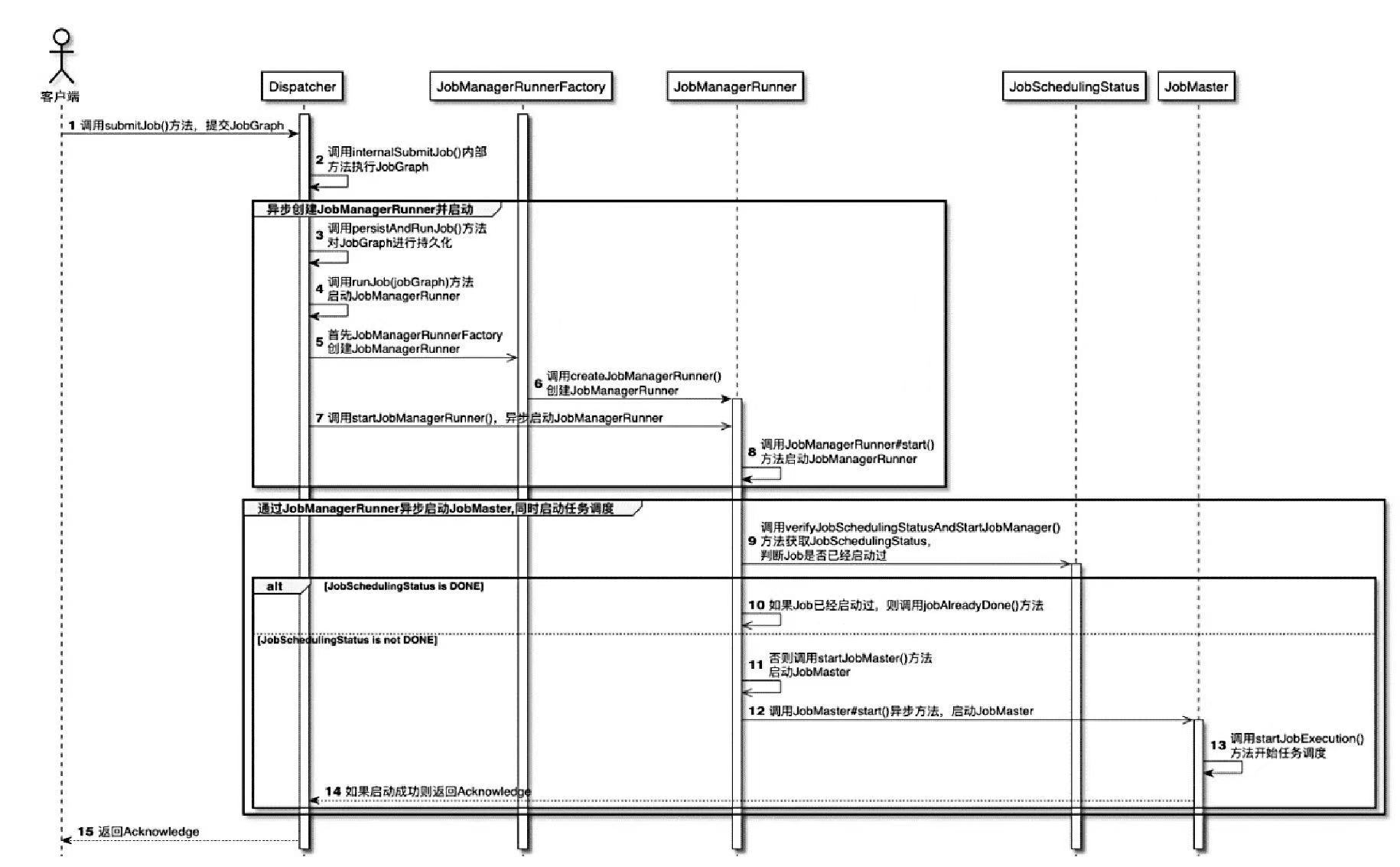
任务提交的时序图
- Dispatcher.submit(JobGraph)的RPC方法,将创建好的JobGraph提交至集群运行时调用Dispatcher.submit(JobGraph)的RPC方法,将创建好的JobGraph提交至集群运行时
- leaderElectionService.start启动 JobmanagerRunner
- 启动JobMaster,对JobGraph中的作业进行调度
- 如果启动成功,会将Acknowledge信息返回给Dispatcher服务,再给客户端
Dispatcher
- Job Submission & Lifecycle Management: Receives jobs (as JobGraph), initializes execution, and handles job cancellation/stopping
- Resource Coordination: Works with the ResourceManager to allocate resources (e.g., slots) for tasks
- High Availability (HA): Integrates with HA services (e.g., ZooKeeper) to recover jobs during failures
- REST API Gateway: Exposes interfaces for job submission, status checks, and metrics via DispatcherGateway
Dispatcher Key Components
- DispatcherRunner: Manages leader election and triggers the creation of DispatcherLeaderProcess upon acquiring leadership
- DispatcherLeaderProcess: Creates and starts the Dispatcher instance. In session mode, it also recovers persisted JobGraphs from storage (e.g., ZooKeeper)
- JobManagerRunner: Spawned per job to manage the job’s lifecycle (e.g., creating JobMaster)
- JobGraph Store: Used in session mode to persist and recover job graphs
JobManagerRunner 相关类图
- 启动JobManagerRunner
- 根据JobManagerRunner启动JobMaster的RPC服务并创建和初始化JobMaster中的内部服务
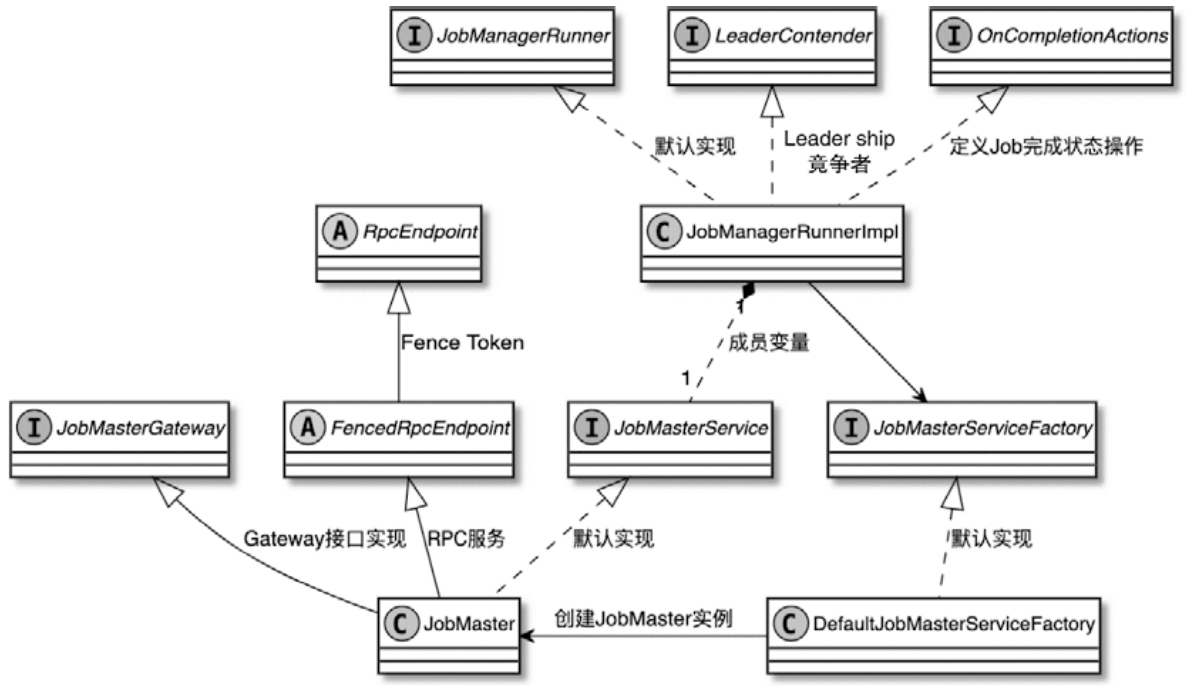
JobManagerRunner 主要功能
- JobMaster Lifecycle Management
- Leader Election and High Availability
- Coordination with Cluster Components
- The JobManagerRunner interacts with the ResourceManager to request resources
- with the Dispatcher to handle job submissions and status updates
- Handling JobGraph Execution
- Integration with Flink’s HA Services
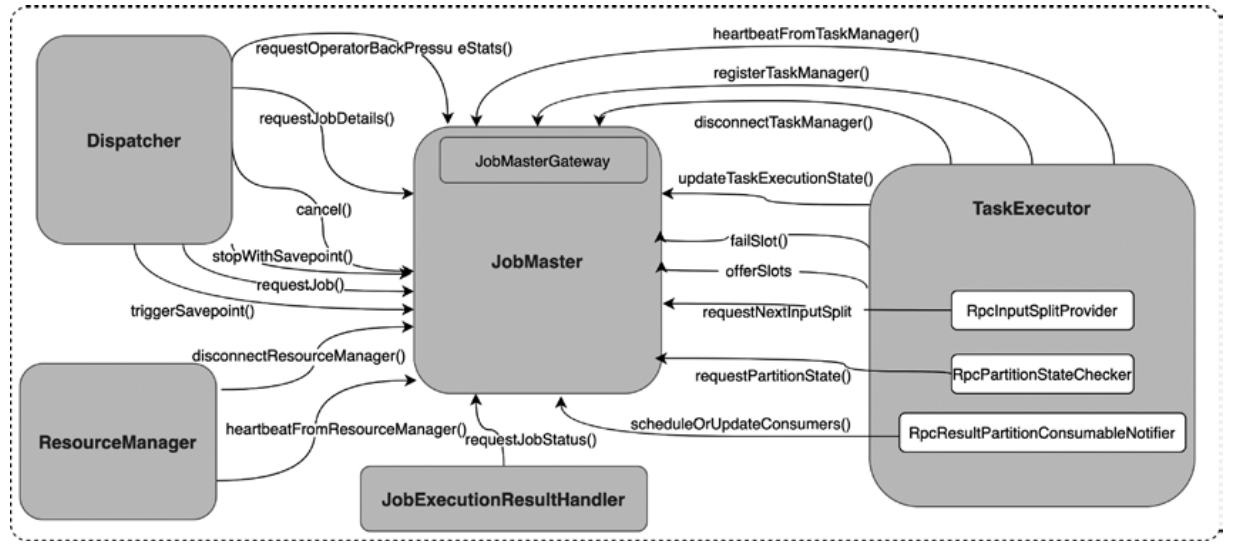
JobMaster 相关类图

JobMaster Core Responsibilities
- Job Execution Management:The JobMaster oversees the entire lifecycle of a Flink job, from scheduling tasks to handling failures。JobGraph ——> ExecutionGraph
- Task Scheduling: It coordinates the deployment of tasks to TaskSlots
- Fault Tolerance:The JobMaster manages Checkpoints and Savepoints
- Resource Coordination:It interacts with the ResourceManager to request and release resources
JobMasterGateway 类图
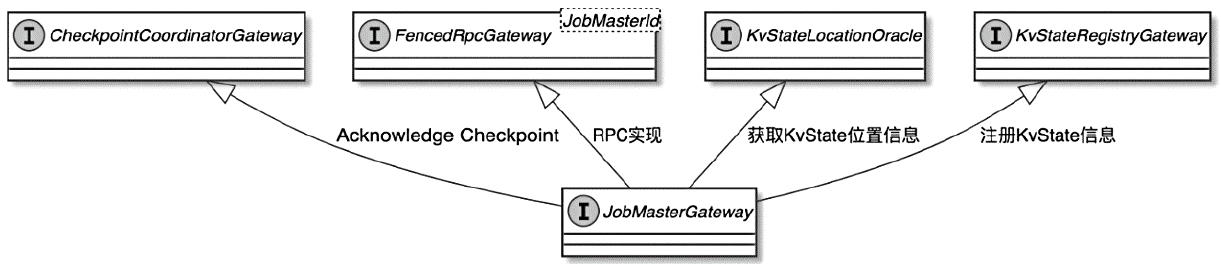
SlotPool资源管理
- JobMasterGateway主要方法
- 跟 Dispathcer、ResourceManager、TaskExecutor 都有交互
- JobManager 会在SlotPool中注册和管理TaskManager信息
- ResourceManager会调用TaskExecutor的RPC方法向JobManager提供申请到的Slot资源
- SlotPool.offerSlots,将消息转为 AllocatedSlot 对象,然后存储在allocatedSlots数据集中
Scheduler 相关类图
- JobMaster中主要通过schedulerFactory创建Scheduler实例
- 这块还是 JobManager master 节点部分,是 逻辑的资源分配
- 物理资源还是在 TaskExecutor中进行分配
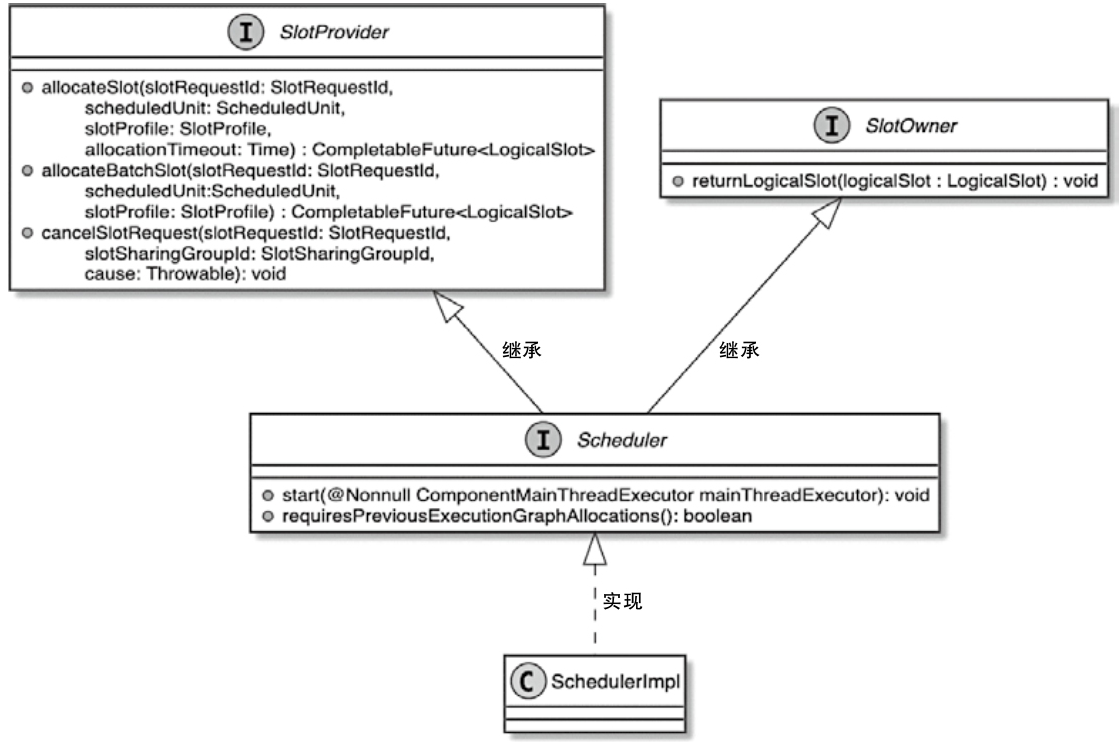
ExecutionGraph
ExecutionGraph Key Characteristics
- Parallel Execution: Each logical operator (e.g., map, filter) in the JobGraph is split into multiple ExecutionVertex instances based on its configured parallelism.
- Physical Representation: It defines the exact deployment of tasks (e.g., which TaskManager slot a task runs on) and data exchange mechanisms (e.g., shuffle, broadcast).
- State Management: Includes checkpointing details (e.g., state snapshots) for fault recovery
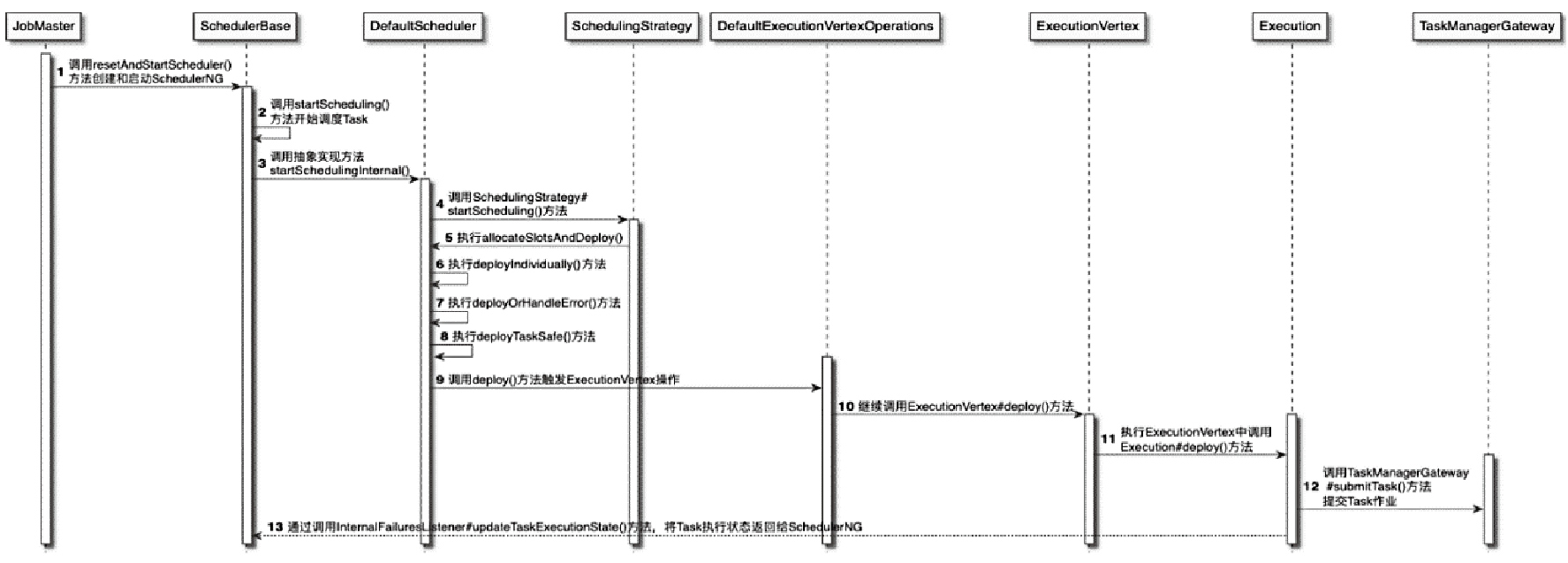
调度过程
- 在JobMaster中创建DefaultScheduler
- 在创建的同时将JobGraph结构转换为ExecutionGraph,用于Task实例的调度
- 然后通过DefaultScheduler对ExecutionGraph中的ExecutionVertex节点进行调度和执行
- 最后将ExecutionVertex以Task的形式在TaskExecutor上运行
JobGraph转换成ExecutionGraph
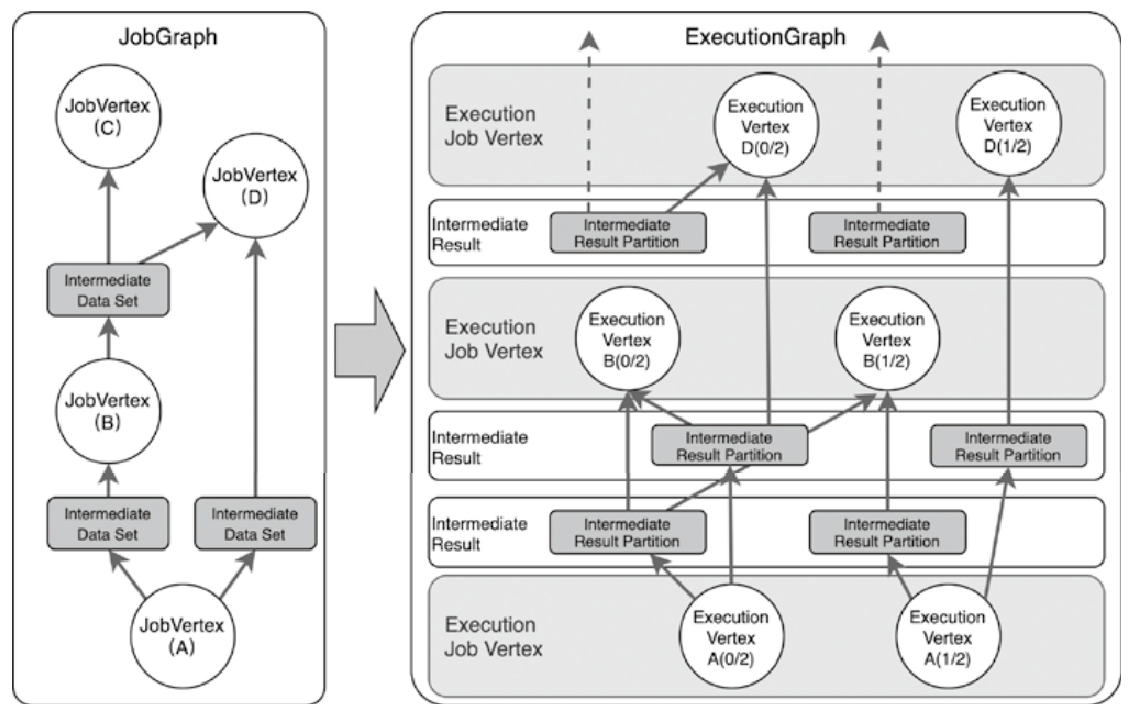
涉及的概念
- JobVertex
- ExecutionJobVertex
- ExecutionVertex
- IntermediateResult
- Execution
ExecutionGraphBuilder.buildGraph()方法主要包含如下参数
- jobGraph:用于构建ExecutionGraph使用的JobGraph对象。
- jobMasterConfiguration:JobMaster的配置信息。
- futureExecutor:ScheduledExecutorService实例,用于定时执行线程。
- slotProvider:Slot资源提供者,实际上就是SlotPool实例。
- userCodeLoader:通过依赖JAR包构建的用户ClassLoader。
- checkpointRecoveryFactory:用于恢复Checkpoint数据的工厂实现类。
- restartStrategy:用于指定Task重启策略
- currentJobManagerJobMetricGroup:用于记录当前JobManager中与Job相关的MetricGroup信息。
- shuffleMaster:当前Job使用的ShuffleMaster管理类,用于注册和管理Shuffle中创建的ResultPartition信息
- partitionTracker:用于监控和跟踪Job中所有Task的分区信息。
- failoverStrategy:获取任务容错配置的工厂类,主要用于创建FailoverStrategy,在Scheduler中会通过FailoverStrategy控制Task的容错策略
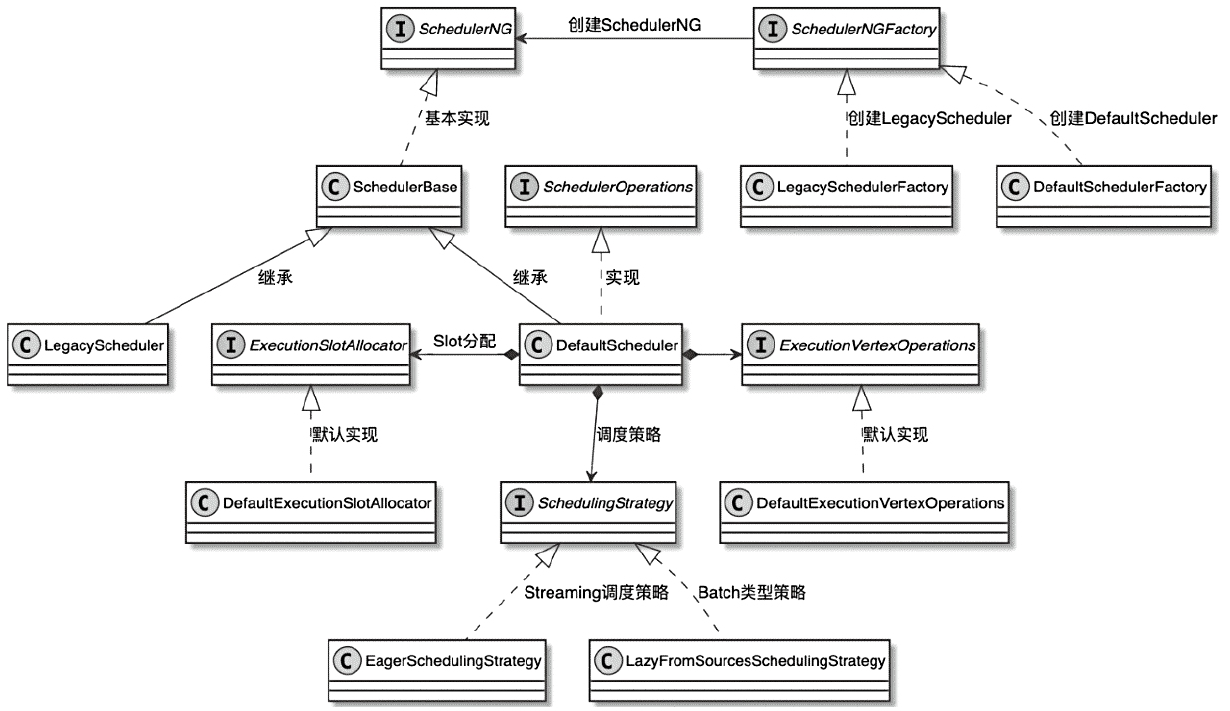
SchedulerNG作为ExecutionGraph任务调度器接口,调度策略
- EagerSchedulingStrategy
- LazyFromSourcesSchedulingStrategy
SchedulerNG 类图
Task
执行
- Execution将TaskDeploymentDescriptor信息提交到TaskManager
- TaskManager中根据TaskDeploymentDescriptor的信息启动Task实例
- 如果Task成功添加至taskSlotTable,就会立即启动Task线程
- Task线程启动后,会返回Acknowledge到Execution所在的节点
- 最终将Ack的消息传递给JobMaster中的SchedulerNG,确定该Task实例被成功调度和执行
执行状态
|
|
Task
- 主要逻辑在 doRun() 函数中
- 分别为初始化 Task 执行环境
- 通过 Bootstrap 启动 Invokablable Class
初始化Task执行环境步骤
- 为当前Task线程激活安全网,用于安全获取FileSystem实例。
- 在blobService中注册当前的jobId。
- 将当前Task依赖的JAR包加载到UserCodeClassLoader中。
- userCodeClassLoader反序列化ExecutionConfig对象,然后从ExecutionConfig中获取taskCancellationInterval和taskCancellationTimeout等参数
启动Invokablable Class计算逻辑
- 通过反射来触发 StreamTask 内部的 Operator 执行
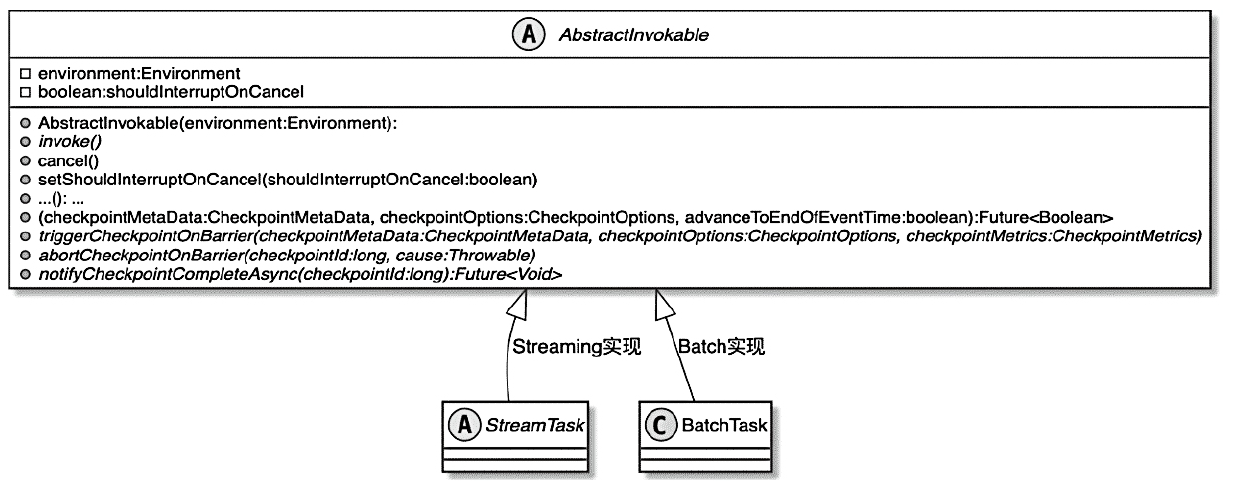
AbstractInvokable 类图
- AbstractInvokable根据计算类型不同分StreamTask、BatchTask
- StreamTask又包含 SourceStreamTask、OneInputStreamTask以及TwoInputStreamTask 等
StreamTask 相关类图
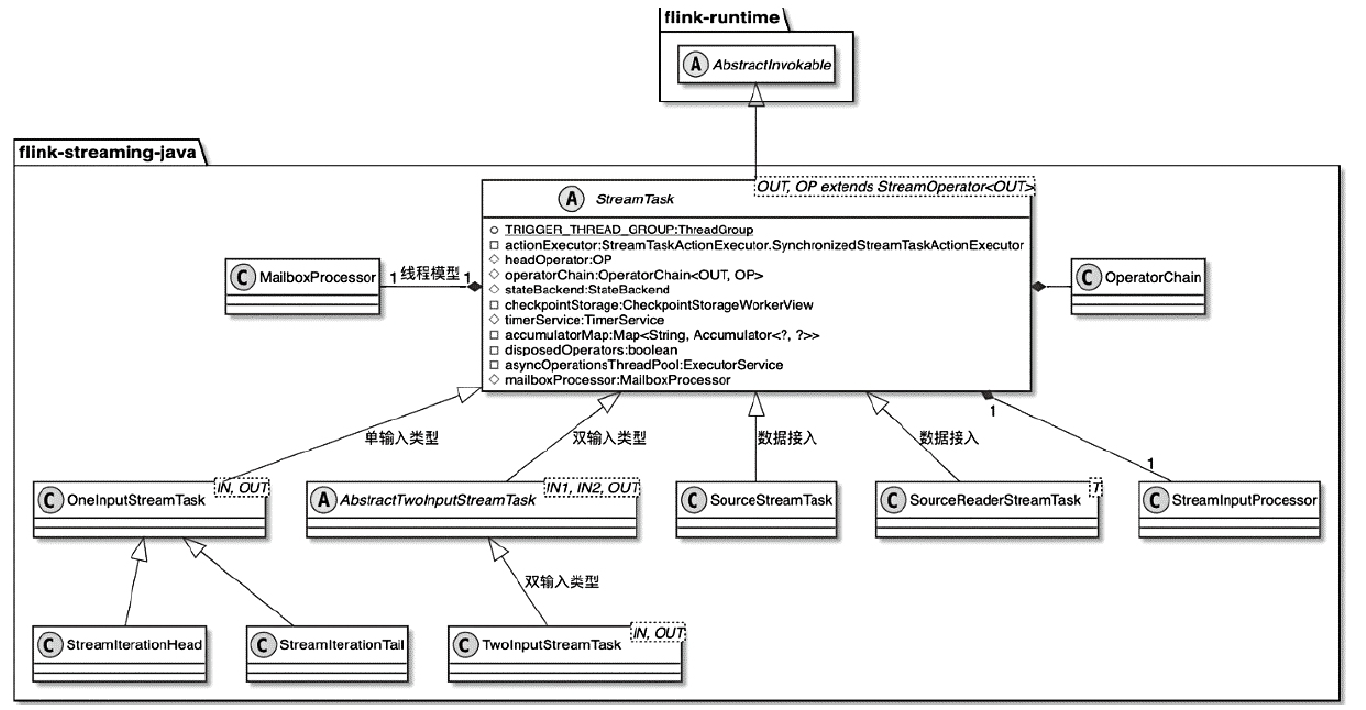
StreamTask的主要成员变量及概念
- headOperator:指定当前StreamTask的头部算子,即operatorChain中的第一个算子
- operatorChain:在StreamTask构建过程中会合并Operator,形成operatorChain
- stateBackend:StreamTask执行过程中使用到状态后端
- checkpointStorage:用于对Checkpoint过程中的状态数据进行外部持久化
- timerService:Task执行过程中用到的定时器服务
- accumulatorMap:用于存储累加器数据,用户自定义的累加器会存放在accumulatorMap中
- asyncOperationsThreadPool:Checkpoint操作对状态数据进行快照操作时所用的异步线程池,目的是避免Checkpoint操作阻塞主线程的计算任务
- mailboxProcessor:采用类似Actor模型的邮箱机制取代之前的多线程模型,让Task执行的过程变为单线程(mailbox线程)加阻塞队列的形式
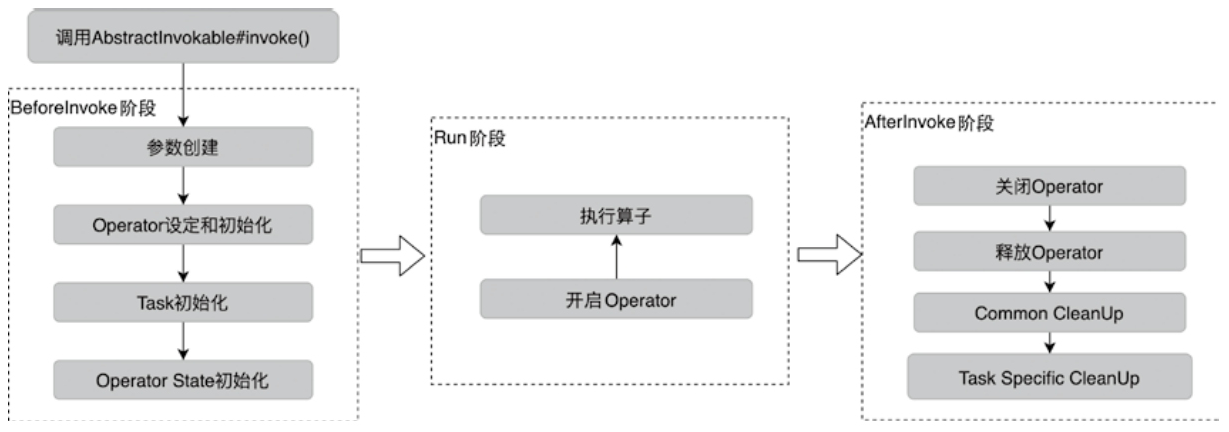
StreamTask触发流程流程图
- BeforeInvoke
- Run
- AfterInvoke
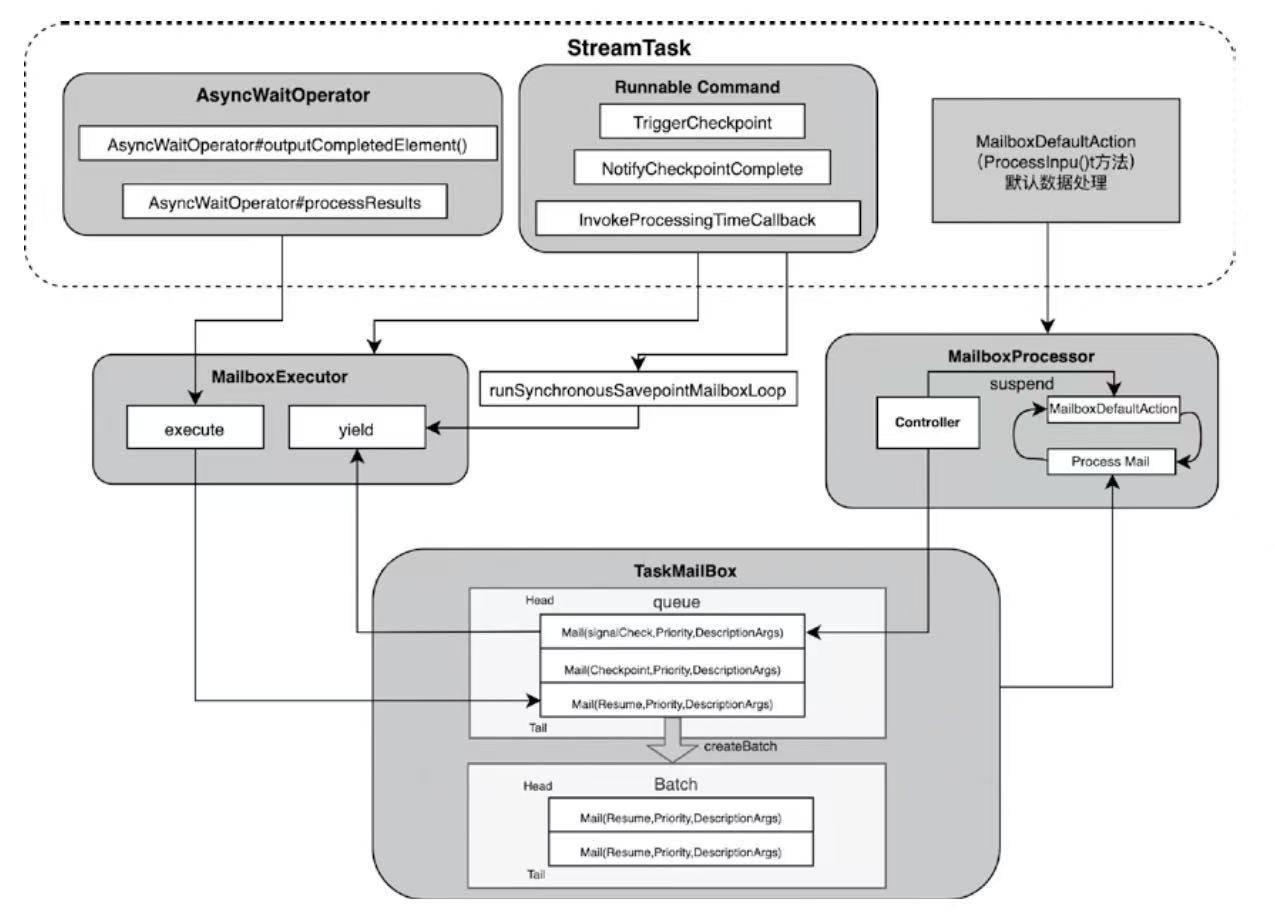
StreamTask线程处理模型主要包含
- Mail:定义具体算子中的可执行操作,Mail主要使用RunnableWithException作为参数,还有priority参数
- MailboxDefaultAction:定义了当前StreamTask的默认数据处理逻辑,包括对Watermark等事件以及StreamElement数据元素的处理
- MalboxProcessor:定义了Mailbox中的Mail和MailboxDefaultAction之间的处理逻辑
- runMailboxLoop()循环方法中处理Mail和DefaultAction,以及用于控制暂时和恢复的逻辑
- MailboxExecutor:提供了直接向TaskMailbox提交Mail的操作
- TaskMailbox:主要用于存储提交的Mail并提供获取接口
StreamTask线程处理模型
StreamInputProcessor数据处理
- StreamTask中对输入数据和输出数据集的处理是通过StreamInputProcessor完成的
- 分为:StreamOneInputProcessor和StreamTwoInputProcessor两种
- StreamInputProcessor实际上包含StreamTaskInput和DataOutput两个组成部分
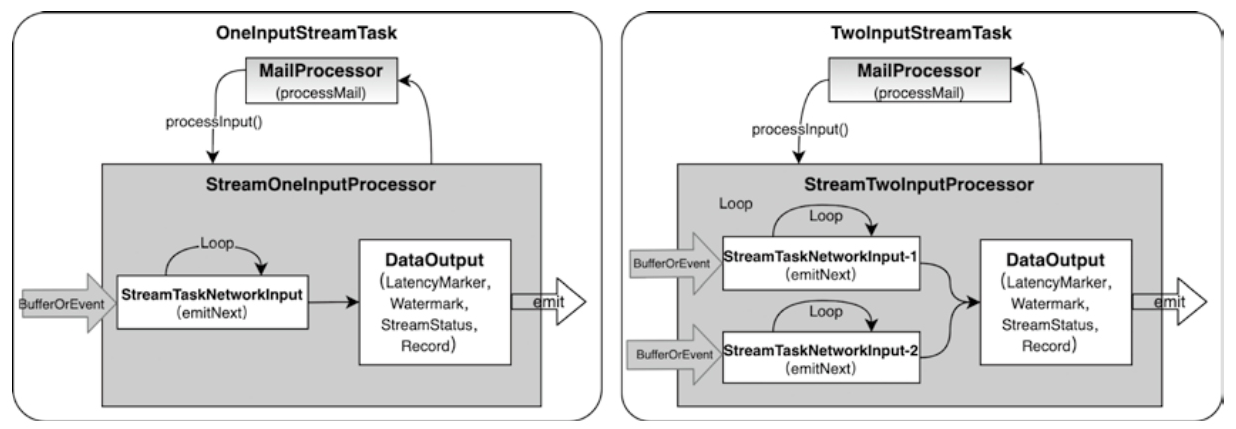
StreamTaskInput的实现
- StreamTaskSourceInput,对于外部数据源
- StreamTaskNetworkInput是算子之间网络传递对应的StreamTaskInput
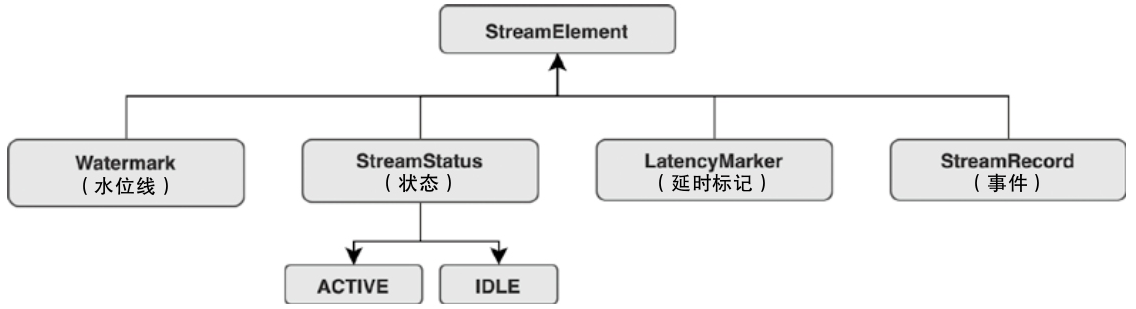
StreamElement分类
- 如果StreamElement是StreamRecord数据,调用output.emitRecord()
- 如果是Watermark事件,则调用 statusWatermarkValve.inputWatermark()
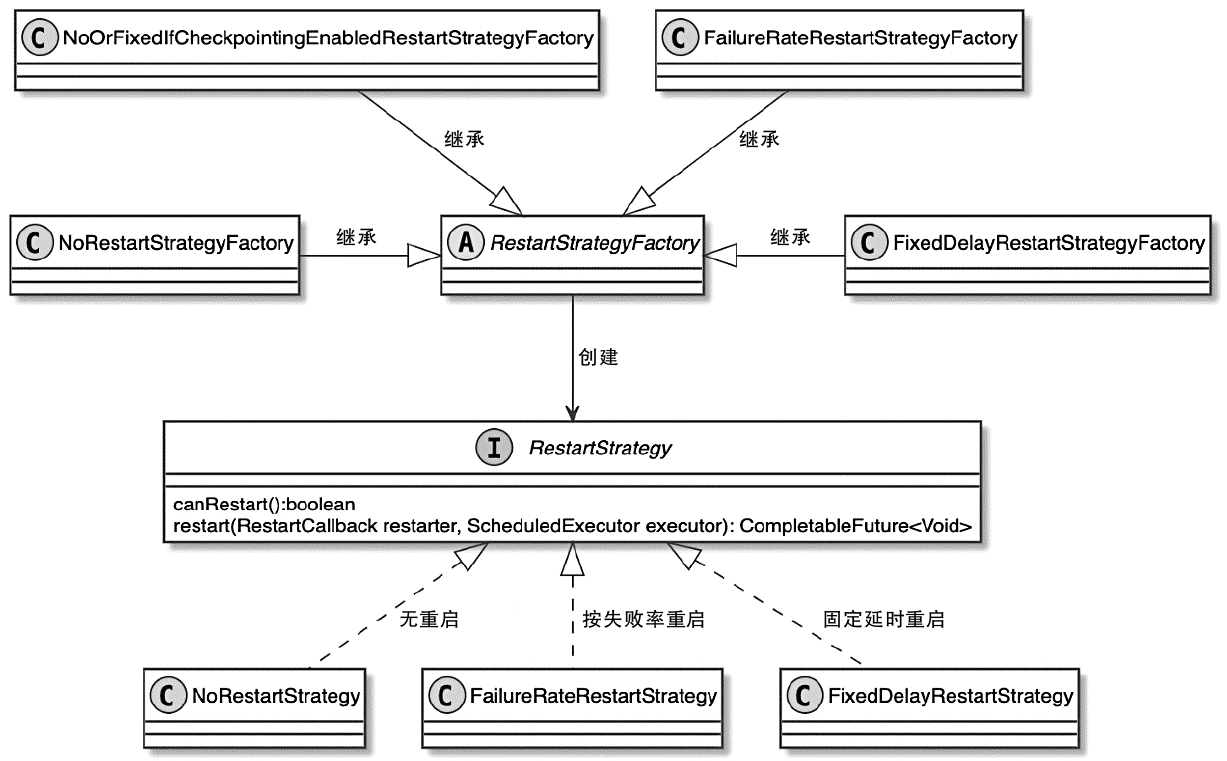
Task重启策略
- 固定延时重启(fixed-delay)
- 按失败率重启(failure-rate)
- 无重启(none)
RestartStrategy 相关类图
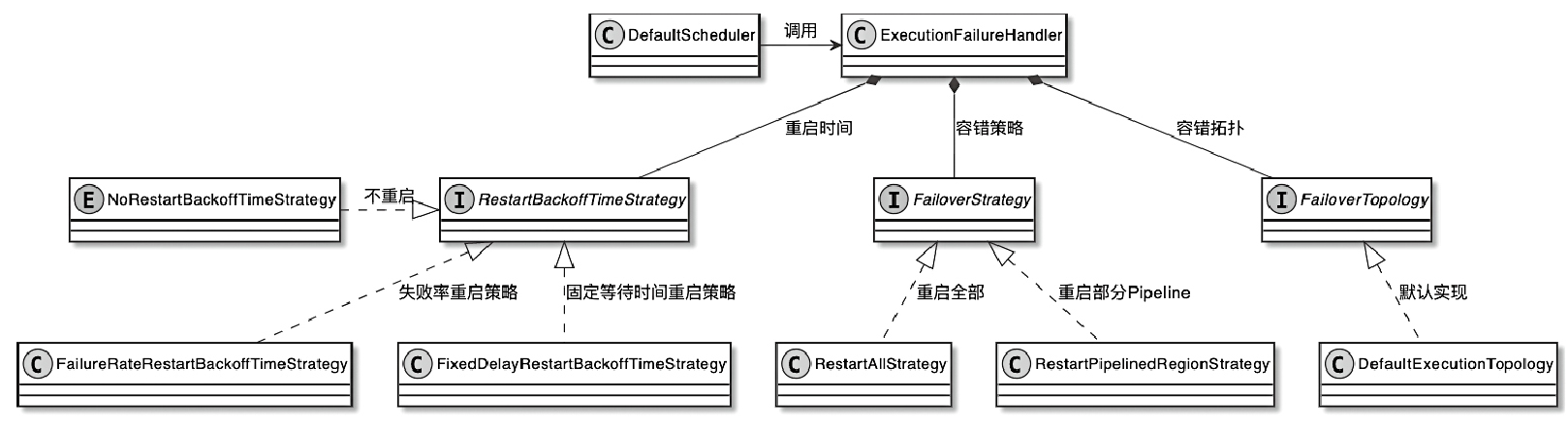
容错
- Task容错主要通过FailoverStrategy控制
- FailoverStrategy主要有两种实现类型
- Restart All策略和重启Pelined Region策略
ExecutionFailureHandler 相关类图
- FailoverStrategy:用于控制Task的重启范围,包括重启全部Task还是重启PipelinedRegion内的相关Task
- RestartBackoffTimeStrategy:用于控制Task是否需要重启以及重启时间和尝试次数。
- FailoverTopology:用于构建Task重启时需要的拓扑、确定异常Task关联的PipelinedRegion,然后重启Region内的Task
- 在Pipeline中通过Region定义上下游中产生数据交换的Task集合,只重启部分
RestartBackoffTimeStrategy接口
- FailureRateRestartBackoffTimeStrategy,是按照失败率重启
- FixeddelayRestartBackoffTimeStrategy,相应的重启等待时间以及尝试次数
- NoRestartBackoffTimeStrategy
作业调度
调度
- 调度层面有一个调度拓扑SchedulingTopology与ExecutionGraph对应
- 整个调度过程是对SchedulingTopology对象进行操作的
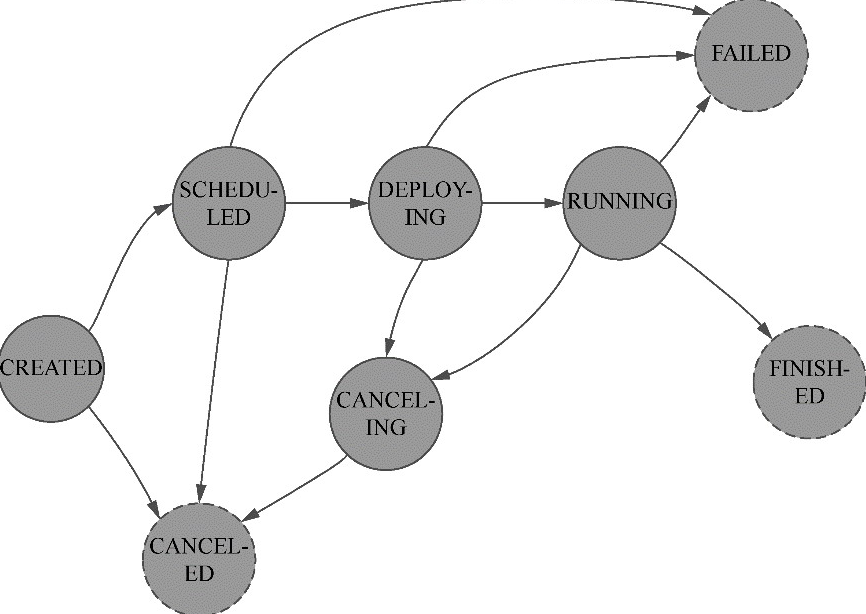
作业状态变化
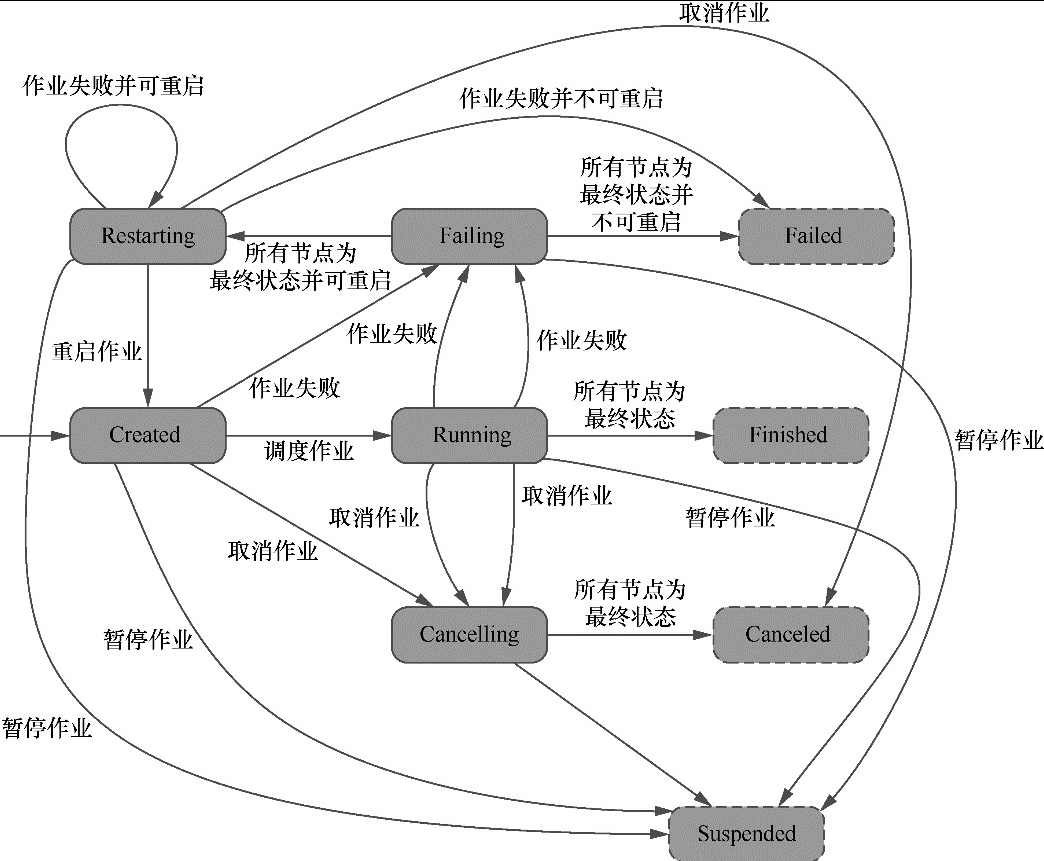
任务状态变化