eBPF 网络
背景
网络
网络类 eBPF 程序可以分为
- XDP 程序
- TC 程序
- 套接字程序
- cgroup 程序
Program Comparison Table
| Program Type | Trigger Event | Running Location | Common Scenarios | Subtypes | Packet Access | Connection Access | Logic Support |
|---|---|---|---|---|---|---|---|
| XDP | When NIC driver receives packets | • Kernel network driver layer • Can be offloaded to NIC hardware | • Firewalls • DDoS protection • Layer 4 load balancing • Packet filtering | N/A | ★★★ (Header only) | ✘ | ★★ |
| TC (Traffic Control) | When NIC queues send/receive data | Kernel protocol stack (Network layer) | • Traffic shaping (QoS) • Bandwidth management • Complex packet processing • Network policy enforcement | N/A | ★★★★ | ★★ | ★★★ |
| Socket | Socket operations: • Creation • Modification • Data transfer | Kernel protocol stack (Transport layer) | • Socket filtering • Connection monitoring • Socket redirection • Protocol analysis | • BPF_PROG_TYPE_SOCK_OPS • BPF_PROG_TYPE_SK_SKB • BPF_PROG_TYPE_SK_MSG | ★★★★ | ★★★★ | ★★★★ |
| cgroup | Socket operations in cgroups: • Creation • Option changes | Kernel cgroup control points | • Container network policies • Process-level firewalls • Connection rate limiting | • BPF_PROG_TYPE_CGROUP_SOCK • BPF_PROG_TYPE_CGROUP_SOCKOPT | ★★ | ★★★★ | ★★★★ |
Processing Flow Sequence
graph LR
XDP[XDP] --> TC[TC]
TC --> Socket[Socket Program]
Socket --> cgroup[cgroup Program]
Capability Rating System
| Capability | Meaning | Rating Scale |
|---|---|---|
| Packet Access | Ability to inspect packet contents | ★★ = Limited (cgroup)★★★★ = Full access (Socket/TC) |
| Connection Access | Access to connection state/metadata | ★★ = Basic awareness (TC)★★★★ = Full control (Socket/cgroup) |
| Logic Support | Support for complex programming constructs | ★★ = Simple conditionals (XDP)★★★★ = Full BPF features (Socket/cgroup) |
Processing Latency Comparison
XDP (10-100ns) < TC (1-10μs) < Socket (10-100μs) < cgroup (100μs-1ms)
Hardware Acceleration:
- Only XDP supports full NIC offload
- TC has limited hardware acceleration (e.g., Intel QAT)
- Socket/cgroup run exclusively in software
Cloud Native Usage:
| Platform | Primary eBPF Program |
|---|---|
| Cilium/Linkerd | Socket + cgroup |
| Facebook Katran | XDP |
| AWS VPC | TC |
Performance Optimization Guidelines
flowchart TD
A[Network Requirement] -->|Line-rate filtering| B[XDP]
A -->|Complex QoS| C[TC]
A -->|Connection optimization| D[Socket]
A -->|Container networking| E[cgroup]
style B stroke:#ff5555,stroke-width:3px
style C stroke:#5555ff,stroke-width:3px
style D stroke:#55ff55,stroke-width:3px
style E stroke:#ffaa00,stroke-width:3px
Why Maps Exist
| Problem | Solution via Maps |
|---|---|
| BPF programs are stateless | Maps provide persistent storage |
| Kernel-user space separation | Maps act as shared memory bridge |
| Inter-program communication | Global data exchange via maps |
| Atomic operations | BPF_ATOMIC_ADD, BPF_XCHG, etc. |
| Event streaming | perf_event, ringbuf maps |
Map Types for Different Use Cases
| Map Type | Communication Scenario |
|---|---|
BPF_MAP_TYPE_HASH |
Sharing metrics between programs |
BPF_MAP_TYPE_PERF_EVENT_ARRAY |
Sending events to user space |
BPF_MAP_TYPE_RINGBUF |
High-throughput event streaming |
BPF_MAP_TYPE_PROG_ARRAY |
Calling between BPF programs |
BPF_MAP_TYPE_SOCKHASH |
Socket redirection |
几个不同模块的交互
graph LR
%% First Row: Network Interface to Kernel Stack
A[Network Interface] -->|XDP| B[Layer 2-3 Processing]
B -->|Pass| C[Kernel Stack]
%% Second Row: TC Processing
C -->|TC Ingress| D[Layer 4 Filtering]
%% Third Row: Container Policy
D -->|cgroup/skb| E[Container Policy]
%% Fourth Row: Application Analysis
E -->|sock_ops| F[Layer 5-7 Analysis]
%% Fifth Row: Security Enforcement
F -->|LSM BPF| G[Security Enforcement]
G --> H{{Applications}}
%% Styling
style B fill:#9f0,stroke:#333
style D fill:#f90,stroke:#333
style F fill:#09f,stroke:#333
style G fill:#f44,stroke:#333
搭建负载均衡
建立基于 nginx 的负载均衡环境
|
|
查询 ip 地址
|
|
更新 nginx 配置
|
|
验证负载均衡是否生效
|
|
测试
|
|
网络问题排查
eBPF 提供了贯穿整个网络协议栈的过滤、捕获以及重定向等丰富的网络功能
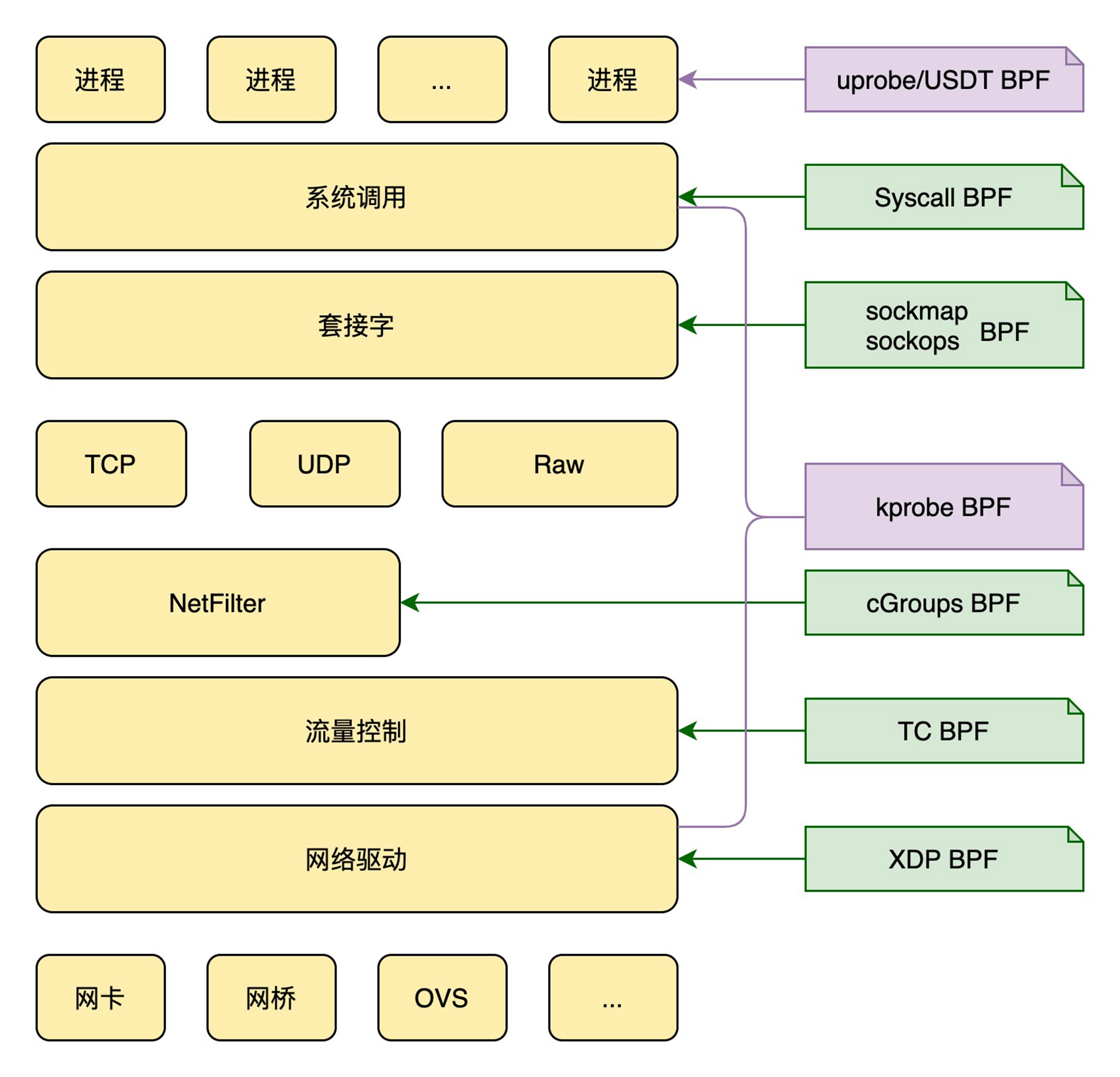
根据调用栈,打印内核执行的堆栈:
|
|
curl 一个网站的结果:
|
|
内核中释放 skb 的两个函数
- consume_skb,在网络异常丢包时调用
- kfree_skb,网络连接完成时调用
完整的程序
|
|
nslookup,或者 dig 查询下 baidu.com 的 ip
|
|
打印结果:
|
|
分析其中的一个调用栈
- 从堆栈可以大致分析出,tcp准备建立连接
- 也可以用:tcpdump -i any port 80 -X,此时是没有数据包的
- 之后触发 tcp 发送逻辑,放到 ip queue中
- 然后是 ip 本地发送
- 再是触发了 nf(NFTables firewall)规则
- 最后是 sk_skb_reason_drop,包丢弃了,那么应该就是跟防火墙规则有关
|
|
Ubuntu 系统,执行下面的命令安装调试信息
|
|
安装 faddr2line 脚本
- Linux 内核维护了一个 faddr2line 脚本,根据函数名+偏移量输出源码文件名和行号
- faddr2line
- 执行:chmod +x faddr2line
使用下面的命令来搜索 vmlinux 开头的文件
|
|
搜索
|
|
对应的内核源码,参考
|
|
基于 socket 的负载均衡
使用套接字映射转发网络包需要以下几个步骤
- 创建套接字映射
- 在 BPF_PROG_TYPE_SOCK_OPS 类型的 eBPF 程序中,将新创建的套接字存入套接字映射中
- 在流解析类的 eBPF 程序(如 BPF_PROG_TYPE_SK_SKB 或 BPF_PROG_TYPE_SK_MSG )中,从套接字映射中提取套接字信息,并调用 BPF 辅助函数转发网络包
- 加载并挂载 eBPF 程序到套接字事件
参考的源码,6.11 内核
bpf_msg_redirect_hash()
|
|
sockops.h 头文件
- 以 BPF_MAP_TYPE_SOCKHASH 类型的套接字映射为例
- 值是 socket 文件的描述符
- 使用 SEC 关键字来定义套接字映射
|
|
sockops.bpf.c 实现
- BPF_PROG_TYPE_SOCK_OPS 类型的 eBPF 程序中跟踪套接字事件
- 并把套接字信息保存到 SOCKHASH 映射中
- 调用 BPF 辅助函数去更新套接字映射
- BPF_NOEXIST 表示键不存在的时候才添加新元素
|
|
sockredir.bpf.c 转发程序 注意一点
- 在套接字转发之前,即便是在同一台机器的两个容器中,负载均衡器和 Web 服务器的两个套接字通信还是需要通过完整的内核协议栈进行处理的
- 而在套接字转发之后,来自发送端套接字 1 的网络包在套接字层就交给了接收端的套接字 2,从而避免了额外的内核协议栈处理过程。
|
|
编译
|
|
Makefile
|
|
打印 section
|
|
BPF Loading Really Works
graph TD
A[Source Code] -->|Compiled| B[ELF Object]
B -->|Contains| C[Sections]
C --> D["SEC('sock_ops')"]
D --> E["Program bytecode"]
E -->|Loaded via| F["bpftool type sockops"]
C --> G["SEC('sk_msg')"]
G --> H["Program bytecode"]
H -->|Loaded via| I["bpftool type sk_msg"]
关于 attach
|
|
Cgroups Control:
- Attaching to the root cgroup (/sys/fs/cgroup/) makes the BPF program affect all containers and processes on the system Socket Lifecycle Hooks:
- sock_ops programs trigger on socket events (creation, connection, teardown) within cgroup-managed processes Docker Integration:
- Since Docker uses cgroups for resource isolation, this ensures BPF hooks:
- Apply to all containers
- Capture socket operations of Nginx and web services
- Work across container boundaries
BPF vs Nginx Data Flow
graph TB
Client-->Nginx[Nginx Userspace]
subgraph Kernel Space
Nginx-->BPF[BPF Socket Redirection]
BPF-->Web1[Web Service 1]
BPF-->Web2[Web Service 2]
end
对比
|
|
回收
- 与 attach 相对应的清理操作为 detach
- bpftool 并没有一个与 load 相对应的 unload 子命令
- eBPF 程序和映射都是与 BPF 文件系统绑定的
- 文件删除后,引用计数降为 0 ,会被系统自动清理了
查看
|
|
强制删除
|
|
观察转发的效果
|
|
传统的转发流程
sequenceDiagram
Client->>Nginx NIC: SYN
Nginx NIC->>Nginx Kernel: Packet
Nginx Kernel->>Nginx Userspace: Copy
Nginx Userspace->>Nginx Kernel: Process + New Connection
Nginx Kernel->>Server NIC: SYN
Server NIC->>Server Kernel: Packet
Server Kernel->>Server App: Copy
Note right of Server App: 4 Copy Operations<br>2 Full TCP Stacks<br>2 Userspace Context Switches
bpf 转发流程
sequenceDiagram
Client->>Nginx NIC: SYN
Nginx NIC->>BPF: Packet
BPF->>Server NIC: SYN (Direct)
Server NIC->>Server App: Packet
Note right of BPF: 0 Copy Operations<br>1 Partial TCP Stack<br>0 Userspace Context Switches
执行流程
sequenceDiagram
participant Kernel as Kernel Network Stack
participant BPF as sockops BPF Program
participant Map as sock_ops_map
Kernel->>BPF: Triggers on socket event (TCP handshake)
BPF->>BPF: Verify IPv4 && Established connection
BPF->>BPF: Build sock_key from skops context
BPF->>Map: Insert socket into sockhash map
Kernel-->>BPF: Return BPF_OK
XDP 转发
参考的一些信息
- 6.10 内核的 struct xdp_md
- 6.11 内核的 BPF_PROG_TYPE_XDP 定义
- 6.11 内核定义的 以太网包头
- 6.11 内核定义的 IP包头
- 由于 修改了 IP 地址,所以需要对 IP 做checksum
- 参考 facebook 的 katran 逻辑
xdp_md
- 开始位置,结束位置,元数据位置
- 后三个表示关联网卡的信息(包括入口网卡、入口网卡队列以及出口网卡的编号)
|
|
xdp-proxy.bpf.c
- 这里会根据 ctx 的开始指针,转为 ethhdr 结构体,也就是以太网包
- 后面会判断长度,是否为 IP 类型
- 通过这样跳过 二层的包头,获取三层的包头
- struct iphdr *iph = data + sizeof(struct ethhdr);
|
|
上述的 ip 和 mac 对应关系
|
|
用户态代码 xdp-proxy.c
- 引入脚手架头文件
- 增大 RLIMIT_MEMLOCK
- 初始化并加载 BPF 字节码
- 挂载 XDP 程序
|
|
编译 bpf 内核代码
|
|
生成骨架 头文件
|
|
编译 用户态代码
|
|
编译生成二进制程序(动态链接)
|
|
静态链接方式生成 二进制程序(按照主机的链接方式load 的静态库)
|
|
静态链接方式
|
|
内核处理流程
sequenceDiagram
participant NIC as Network Interface
participant XDP as XDP Program
participant Driver as NIC Driver
participant Kernel as Kernel Network Stack
NIC->>XDP: Packet Received
XDP->>XDP: Modify Packet (IP/MAC)
XDP->>Driver: Return XDP_TX
Driver->>NIC: Transmit Modified Packet
Note right of Driver: Bypasses Kernel Network Stack
Note left of NIC: Packet Sent Back to Wire
启动docker
|
|
进入 client 容器
反复执行 curl,应该会返回 http1、http2,说明实现了负载均衡
|
|
优化的版本
xdp-proxy.h 头文件
|
|
xdp-proxy.bpf.c
|
|
参考
- bpf 官方文档
- BPF 内核文档
- bcc Reference Guide
- ebpf
- bcc tools
- bpftrace文档
- Application binary interface
- A Manual for the Plan 9 assembler
- About Mermaid
- 整理Markdown 公式编辑常用数学符号
- 《深入高可用系统原理与设计》
- github sockops
- libbpf-bootstrap
- alpine linux
- Linux Networking and Network Devices APIs
- Linux Kernel HTML Documentation
- Operating Systems 2
- linux内核源码
- Bringing TSO/GRO and Jumbo frames to XDP
- Multiple XDP programs per interface: Status and outstanding issues
- 在Ubuntu 24.04上搭建eBPF/XDP开发环境